

Unser Gehirn verknüpft Gesicht und Stimme - Schnecke Online
Unser Gehirn verknüpft Gesicht und Stimme - Schnecke Online
Unser Gehirn verknüpft Gesicht und Stimme - Schnecke Online

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
FORSCHUNG | WISSENSCHAFT<br />
<strong>Unser</strong> <strong>Gehirn</strong> <strong>verknüpft</strong> <strong>Gesicht</strong> <strong>und</strong> <strong>Stimme</strong><br />
Absehen von den Lippen: neue Erkenntnisse zur <strong>Gesicht</strong>s-/<strong>Stimme</strong>rkennung<br />
Während wir mit anderen Menschen sprechen, verbinden wir ständig<br />
Informationen von <strong>Gesicht</strong> <strong>und</strong> <strong>Stimme</strong>, um die Identität unseres<br />
Gesprächspartners zu erkennen <strong>und</strong> seine Sprachnachricht zu<br />
verstehen. Selbst wenn wir eine Person nur sprechen hören, aktiviert<br />
das <strong>Gehirn</strong> gelernte Assoziationen des <strong>Gesicht</strong>s, um die <strong>Stimme</strong>rkennung<br />
zu verbessern. Das ist möglich, weil <strong>Gesicht</strong>s- <strong>und</strong><br />
<strong>Stimme</strong>rkennungsareale direkt miteinander <strong>verknüpft</strong> sind. Umgekehrt<br />
werden akustische Vorinformationen genutzt, um die visuelle<br />
Sprachverarbeitung, etwa beim Lippenlesen, zu verbessern.<br />
<strong>Stimme</strong>n wiedererkennen, werden im <strong>Gehirn</strong> Areale<br />
aktiviert, die beim Erkennen von <strong>Gesicht</strong>ern eine zentrale<br />
Rolle spielen [1, 2]. Auch im Bereich der Sprachverarbeitung<br />
gibt es Beispiele für solche Verbindungen<br />
zwischen Hören <strong>und</strong> Sehen. So wurde gezeigt, dass<br />
beim Lippenabsehen <strong>Gehirn</strong>areale aktiviert werden,<br />
die vorrangig akustische Information verarbeiten [3].<br />
Wie wir <strong>Gesicht</strong>er nutzen, um <strong>Stimme</strong>n zu erkennen<br />
In traditionellen kognitiven Modellen wurde die Personenerkennung<br />
als ein hierarchischer Verarbeitungsprozess<br />
beschrieben, der mit einer für visuelle <strong>und</strong><br />
akustische Informationen getrennt ablaufenden Analyse<br />
des sensorischen Inputs beginnt (Abb. 1). Daraufhin<br />
würden <strong>Gesicht</strong>er <strong>und</strong> <strong>Stimme</strong>n erkannt <strong>und</strong> Gefühle<br />
der Vertrautheit ausgelöst. Erst in einem späteren Stadium,<br />
nachdem die Identität der Person bereits erkannt<br />
sei, würde die Information von <strong>Gesicht</strong> <strong>und</strong> <strong>Stimme</strong> zusammengeführt.<br />
Dem widersprachen jedoch neuere<br />
Ergebnisse aus Studien mithilfe funktioneller Magnetresonanztomografie,<br />
in denen gezeigt wurde, dass<br />
beim Erkennen bekannter <strong>Stimme</strong>n Hirnareale aktiv<br />
werden, die eigentlich <strong>Gesicht</strong>er verarbeiten. Ein gesichtssensitives<br />
Areal (englisch: Fusiform Face Area<br />
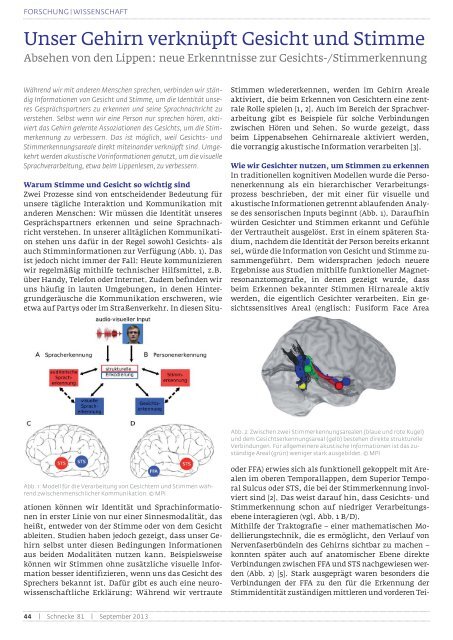
Abb. 2: Zwischen zwei <strong>Stimme</strong>rkennungsarealen (blaue <strong>und</strong> rote Kugel)<br />
<strong>und</strong> dem <strong>Gesicht</strong>serkennungsareal (gelb) bestehen direkte strukturelle<br />
Verbindungen. Für allgemeinere akustische Informationen ist das zuständige<br />
Areal (grün) weniger stark ausgebildet. © MPI<br />
Abb. 1: Modell für die Verarbeitung von <strong>Gesicht</strong>ern <strong>und</strong> <strong>Stimme</strong>n während<br />
zwischenmenschlicher Kommunikation. © MPI<br />
Warum <strong>Stimme</strong> <strong>und</strong> <strong>Gesicht</strong> so wichtig sind<br />
Zwei Prozesse sind von entscheidender Bedeutung für<br />
unsere tägliche Interaktion <strong>und</strong> Kommunikation mit<br />
anderen Menschen: Wir müssen die Identität unseres<br />
Gesprächspartners erkennen <strong>und</strong> seine Sprachnachricht<br />
verstehen. In unserer alltäglichen Kommunikation<br />
stehen uns dafür in der Regel sowohl <strong>Gesicht</strong>s- als<br />
auch Stimminformationen zur Verfügung (Abb. 1). Das<br />
ist jedoch nicht immer der Fall: Heute kommunizieren<br />
wir regelmäßig mithilfe technischer Hilfsmittel, z.B.<br />
über Handy, Telefon oder Internet. Zudem befinden wir<br />
uns häufig in lauten Umgebungen, in denen Hintergr<strong>und</strong>geräusche<br />
die Kommunikation erschweren, wie<br />
etwa auf Partys oder im Straßenverkehr. In diesen Situationen<br />
können wir Identität <strong>und</strong> Sprachinformationen<br />
in erster Linie von nur einer Sinnesmodalität, das<br />
heißt, entweder von der <strong>Stimme</strong> oder von dem <strong>Gesicht</strong><br />
ableiten. Studien haben jedoch gezeigt, dass unser <strong>Gehirn</strong><br />
selbst unter diesen Bedingungen Informationen<br />
aus beiden Modalitäten nutzen kann. Beispielsweise<br />
können wir <strong>Stimme</strong>n ohne zusätzliche visuelle Information<br />
besser identifizieren, wenn uns das <strong>Gesicht</strong> des<br />
Sprechers bekannt ist. Dafür gibt es auch eine neurowissenschaftliche<br />
Erklärung: Während wir vertraute<br />
oder FFA) erwies sich als funktionell gekoppelt mit Arealen<br />
im oberen Temporallappen, dem Superior Temporal<br />
Sulcus oder STS, die bei der <strong>Stimme</strong>rkennung involviert<br />
sind [2]. Das weist darauf hin, dass <strong>Gesicht</strong>s- <strong>und</strong><br />
<strong>Stimme</strong>rkennung schon auf niedriger Verarbeitungsebene<br />
interagieren (vgl. Abb. 1 B/D).<br />
Mithilfe der Traktografie – einer mathematischen Modellierungstechnik,<br />
die es ermöglicht, den Verlauf von<br />
Nervenfaserbündeln des <strong>Gehirn</strong>s sichtbar zu machen –<br />
konnten später auch auf anatomischer Ebene direkte<br />
Verbindungen zwischen FFA <strong>und</strong> STS nachgewiesen werden<br />
(Abb. 2) [5]. Stark ausgeprägt waren besonders die<br />
Verbindungen der FFA zu den für die Erkennung der<br />
Stimmidentität zuständigen mittleren <strong>und</strong> vorderen Tei-<br />
44 | <strong>Schnecke</strong> 81 | September 2013
FORSCHUNG | WISSENSCHAFT<br />
len des STS. Zu Arealen im hinteren STS, die eher akustische<br />
Merkmale der <strong>Stimme</strong> extrahieren, war die Verbindung<br />
schwächer ausgeprägt. Die Nervenfaserbahnen<br />
scheinen also tatsächlich vorrangig dem Informationsaustausch<br />
zwischen auditorischer <strong>und</strong> visueller Personenerkennung<br />
zu dienen. Diese Erkenntnisse erweitern<br />
die traditionellen Modelle der Personenerkennung <strong>und</strong><br />
erklären, auf welche Weise gelernte Assoziationen von<br />
<strong>Gesicht</strong>ern <strong>und</strong> <strong>Stimme</strong>n bei der Personenerkennung<br />
selbst dann zusammen genutzt werden können, wenn<br />
nur Informationen aus einer Sinnesmodalität zur Verfügung<br />
stehen. Im Alltag könnte uns dies dabei helfen,<br />
vertraute Personen schnell <strong>und</strong> unter widrigen Bedingungen<br />
zu identifizieren.<br />
Wie wir akustische Informationen nutzen, um das<br />
Absehen von den Lippen zu verbessern<br />
Auch bei der Sprachverarbeitung verwenden wir wenn<br />
möglich visuelle Information, um unser Sprachverständnis<br />
zu unterstützen [6], z.B. mit dem Absehen von den<br />
Lippen. Dabei handelt es sich um einen sehr anspruchsvollen<br />
Prozess, bei dem es große individuelle Unterschiede<br />
gibt. Die Fähigkeit, von den Lippen abzusehen, kann<br />
einerseits durch zusätzliche akustische Informationen<br />
verbessert <strong>und</strong> beeinflusst werden, andererseits durch<br />
visuelle Vorinformationen, indem man z.B. auf den<br />
Gegenstand zeigt, über den gesprochen wird.<br />
Im <strong>Gehirn</strong> ist ein Netzwerk von Regionen für das Lippenabsehen<br />
relevant. Eine Region im linken hinteren<br />
STS scheint besonders wichtig für den Abgleich von<br />
visueller <strong>und</strong> akustischer Information zu sein: Sie<br />
Personenerkennung <strong>und</strong> des Verstehens von Sprache<br />
eng zusammen. Studien der letzten Jahre haben das<br />
Wissen über die zugr<strong>und</strong>e liegenden Prozesse vermehrt.<br />
Die Ergebnisse können dazu beitragen, Defizite in der<br />
Personenerkennung, wie etwa Prosopagnosie oder<br />
Phonagnosie, die Unfähigkeit, andere an <strong>Gesicht</strong> oder<br />
<strong>Stimme</strong> zu erkennen, besser zu verstehen. Im weiteren<br />
Bereich der klinischen Anwendung könnten sie zur<br />
Entwicklung wirksamer Behandlungen <strong>und</strong> Kompensationsstrategien<br />
für hörgeschädigte Menschen beitragen.<br />
Literatur<br />
[1] von Kriegstein, K.; Dogan, O.; Gruter, M.; Giraud, A. L.;<br />
Kell, C. A.; Gruter, T.; et al., Simulation of talking faces in the<br />
human brain improves auditory speech recognition, Proceedings<br />
of the National Academy of Sciences USA 105, 6747-6752 (2008). [2]<br />
von Kriegstein, K.; Giraud, A. L. Implicit multisensory associations<br />
influence voice recognition, PLoS Biology 4(10), e326 (2006).<br />
[3] Calvert, G. A.; Bullmore, E. T.; Brammer, M. J.; Campbell,<br />
R.; Williams, S. C.; McGuire, P. K.; et al., Activation of auditory<br />
cortex during silent lipreading, Science 276, 593-596 (1997). [4] Bruce,<br />
V.; Young, A., Understanding face recognition, British Journal<br />
of Psychology 77, 305-327 (1986). [5] Blank, H.; Anwander, A.; von<br />
Kriegstein, K., Direct structural connections between voice- and<br />
face-recognition areas, The Journal of Neuroscience 31, 12906-<br />
12915 (2011). 6] Sumby, W. H.; Pollack, I., Visual contribution to<br />
speech intelligibility in noise, Journal of the Acoustical, Society of<br />
America 26, 212-215 (1954). [7] Blank, H.; von Kriegstein, K., Mechanisms<br />
of enhancing visual-speech recognition by prior auditory<br />
information, Neuroimage 65C, 109-118 (2012) © 2003-2013, Max-<br />
Planck-Gesellschaft, München.<br />
Dr. Helen Blank<br />
Prof. Dr. Katharina von Kriegstein<br />
Max-Planck-Institut für<br />
Kognitions- <strong>und</strong> Neurowissenschaften Leipzig<br />
Stephanstr. 1a, 04103 Leipzig<br />
Erklärungen der Fachbegriffe<br />
im Glossar auf Seite 9<br />
Abb. 3: Ein Areal im linken „Superior Temporal Sulcus“ (STS, blau) reagierte<br />
mit erhöhter Aktivität, wenn beim Lippenlesen die M<strong>und</strong>bewegung nicht<br />
mit erwarteten Wörtern zusammenpasste. Es war funktionell mit einem<br />
auditorischen Sprachareal im vord./mittleren STS (rot) verb<strong>und</strong>en. © MPI<br />
zeigt erhöhte Aktivität, wenn akustische Vorinformation<br />
nicht mit der visuellen Sprachinformation übereinstimmt.<br />
Bei besseren Lippenlesern fällt dieses Fehlersignal<br />
besonders stark aus (Abb. 3) [7]. Interessant ist,<br />
dass auch hier zwischen auditorischen <strong>und</strong> visuellen<br />
Spracharealen im STS eine funktionelle Verbindung besteht.<br />
Auch in diesem Fall könnten direkte Verbindungen<br />
zwischen auditorischen <strong>und</strong> visuellen Arealen es<br />
unserem <strong>Gehirn</strong> ermöglichen, Vorinformationen zu<br />
nutzen, um Lippenabsehen zu optimieren.<br />
Wie wir dieses Wissen nutzen können<br />
Hirnregionen, die auf die Verarbeitung von <strong>Stimme</strong>n<br />
<strong>und</strong> <strong>Gesicht</strong>ern spezialisiert sind, arbeiten während der<br />
Dr. Helen Blank, Doktorandin Max-Planck-<br />
Forschungsgruppe „Neuronale Mechanismen<br />
zwischenmenschlicher Kommunikation“;<br />
2004-2009 Psychologiestudium Westfälische<br />
Wilhelms-Univ. Münster; 2009-2013 Promotion<br />
am Max-Planck-Institut für Kognitions<strong>und</strong><br />
Neurowissenschaften in Leipzig; seit<br />
2013 PostDoc-Stelle an der Cognitive Brain<br />
Sciences Unit, Cambridge, UK.<br />
Prof. Dr. Katharina von Kriegstein,<br />
1994-2001 Stud. Humanmedizin, Göttingen;<br />
1995-1997 Stud. Philosophie, Gött.; 1996-2000<br />
Doktorandin u. Hilfswissensch. Mitarb. Abt.<br />
Molekulare Neurobiologie, MPI für Experimentielle<br />
Medizin, Gött.; 2001 Dr. med.; 2001-2004<br />
Assistenzärztin Klinik für Neurologie, J.W.G.-<br />
Univ. FFM; 2004-2009 Wissensch. Mitarb.<br />
Funct. Imaging Laboratory, castle, GB; 02/09<br />
Leiterin MPI „Neuronale Mechanismen...“ MPI f.<br />
Kognitions- <strong>und</strong> Neurowissenschaften, Leipzig; 02/13 Prof. f. Kognitive<br />
u. Klin. Neurowiss., Inst. Psychologie, Humb.-Univ. Berlin.<br />
<strong>Schnecke</strong> 81 | September 2013 | 45