

Parallelizing the Construction of Static Single Assignment Form
Parallelizing the Construction of Static Single Assignment Form
Parallelizing the Construction of Static Single Assignment Form

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
speedup<br />
1.6<br />
1.4<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
1 10 100 1000 10000<br />
montecarlo<br />
raytracer<br />
method length threshold<br />
search<br />
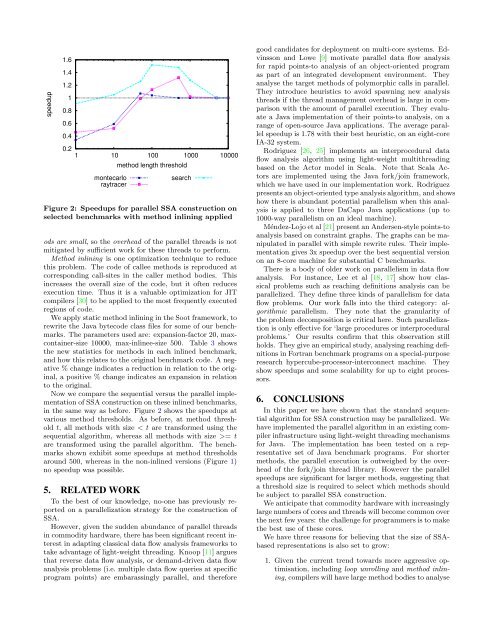
Figure 2: Speedups for parallel SSA construction on<br />
selected benchmarks with method inlining applied<br />
ods are small, so <strong>the</strong> overhead <strong>of</strong> <strong>the</strong> parallel threads is not<br />
mitigated by sufficient work for <strong>the</strong>se threads to perform.<br />
Method inlining is one optimization technique to reduce<br />
this problem. The code <strong>of</strong> callee methods is reproduced at<br />
corresponding call-sites in <strong>the</strong> caller method bodies. This<br />
increases <strong>the</strong> overall size <strong>of</strong> <strong>the</strong> code, but it <strong>of</strong>ten reduces<br />
execution time. Thus it is a valuable optimization for JIT<br />
compilers [30] to be applied to <strong>the</strong> most frequently executed<br />
regions <strong>of</strong> code.<br />
We apply static method inlining in <strong>the</strong> Soot framework, to<br />
rewrite <strong>the</strong> Java bytecode class files for some <strong>of</strong> our benchmarks.<br />
The parameters used are: expansion-factor 20, maxcontainer-size<br />
10000, max-inlinee-size 500. Table 3 shows<br />
<strong>the</strong> new statistics for methods in each inlined benchmark,<br />
and how this relates to <strong>the</strong> original benchmark code. A negative<br />
% change indicates a reduction in relation to <strong>the</strong> original,<br />
a positive % change indicates an expansion in relation<br />
to <strong>the</strong> original.<br />
Now we compare <strong>the</strong> sequential versus <strong>the</strong> parallel implementation<br />
<strong>of</strong> SSA construction on <strong>the</strong>se inlined benchmarks,<br />
in <strong>the</strong> same way as before. Figure 2 shows <strong>the</strong> speedups at<br />
various method thresholds. As before, at method threshold<br />
t, all methods with size < t are transformed using <strong>the</strong><br />
sequential algorithm, whereas all methods with size >= t<br />
are transformed using <strong>the</strong> parallel algorithm. The benchmarks<br />
shown exhibit some speedups at method thresholds<br />
around 500, whereas in <strong>the</strong> non-inlined versions (Figure 1)<br />
no speedup was possible.<br />
5. RELATED WORK<br />
To <strong>the</strong> best <strong>of</strong> our knowledge, no-one has previously reported<br />
on a parallelization strategy for <strong>the</strong> construction <strong>of</strong><br />
SSA.<br />
However, given <strong>the</strong> sudden abundance <strong>of</strong> parallel threads<br />
in commodity hardware, <strong>the</strong>re has been significant recent interest<br />
in adapting classical data flow analysis frameworks to<br />
take advantage <strong>of</strong> light-weight threading. Knoop [11] argues<br />
that reverse data flow analysis, or demand-driven data flow<br />
analysis problems (i.e. multiple data flow queries at specific<br />
program points) are embarassingly parallel, and <strong>the</strong>refore<br />
good candidates for deployment on multi-core systems. Edvinsson<br />
and Lowe [9] motivate parallel data flow analysis<br />
for rapid points-to analysis <strong>of</strong> an object-oriented program<br />
as part <strong>of</strong> an integrated development environment. They<br />
analyse <strong>the</strong> target methods <strong>of</strong> polymorphic calls in parallel.<br />
They introduce heuristics to avoid spawning new analysis<br />
threads if <strong>the</strong> thread management overhead is large in comparison<br />
with <strong>the</strong> amount <strong>of</strong> parallel execution. They evaluate<br />
a Java implementation <strong>of</strong> <strong>the</strong>ir points-to analysis, on a<br />
range <strong>of</strong> open-source Java applications. The average parallel<br />
speedup is 1.78 with <strong>the</strong>ir best heuristic, on an eight-core<br />
IA-32 system.<br />
Rodriguez [26, 25] implements an interprocedural data<br />
flow analysis algorithm using light-weight multithreading<br />
based on <strong>the</strong> Actor model in Scala. Note that Scala Actors<br />
are implemented using <strong>the</strong> Java fork/join framework,<br />
which we have used in our implementation work. Rodriguez<br />
presents an object-oriented type analysis algorithm, and shows<br />
how <strong>the</strong>re is abundant potential parallelism when this analysis<br />
is applied to three DaCapo Java applications (up to<br />
1000-way parallelism on an ideal machine).<br />
Méndez-Lojo et al [21] present an Andersen-style points-to<br />
analysis based on constraint graphs. The graphs can be manipulated<br />
in parallel with simple rewrite rules. Their implementation<br />
gives 3x speedup over <strong>the</strong> best sequential version<br />
on an 8-core machine for substantial C benchmarks.<br />
There is a body <strong>of</strong> older work on parallelism in data flow<br />
analysis. For instance, Lee et al [18, 17] show how classical<br />
problems such as reaching definitions analysis can be<br />
parallelized. They define three kinds <strong>of</strong> parallelism for data<br />
flow problems. Our work falls into <strong>the</strong> third category: algorithmic<br />
parallelism. They note that <strong>the</strong> granularity <strong>of</strong><br />
<strong>the</strong> problem decomposition is critical here. Such parallelization<br />
is only effective for ‘large procedures or interprocedural<br />
problems.’ Our results confirm that this observation still<br />
holds. They give an empirical study, analysing reaching definitions<br />
in Fortran benchmark programs on a special-purpose<br />
research hypercube-processor-interconnect machine. They<br />
show speedups and some scalability for up to eight processors.<br />
6. CONCLUSIONS<br />
In this paper we have shown that <strong>the</strong> standard sequential<br />
algorithm for SSA construction may be parallelized. We<br />
have implemented <strong>the</strong> parallel algorithm in an existing compiler<br />
infrastructure using light-weight threading mechanisms<br />
for Java. The implementation has been tested on a representative<br />
set <strong>of</strong> Java benchmark programs. For shorter<br />
methods, <strong>the</strong> parallel execution is outweighed by <strong>the</strong> overhead<br />
<strong>of</strong> <strong>the</strong> fork/join thread library. However <strong>the</strong> parallel<br />
speedups are significant for larger methods, suggesting that<br />
a threshold size is required to select which methods should<br />
be subject to parallel SSA construction.<br />
We anticipate that commodity hardware with increasingly<br />
large numbers <strong>of</strong> cores and threads will become common over<br />
<strong>the</strong> next few years: <strong>the</strong> challenge for programmers is to make<br />
<strong>the</strong> best use <strong>of</strong> <strong>the</strong>se cores.<br />
We have three reasons for believing that <strong>the</strong> size <strong>of</strong> SSAbased<br />
representations is also set to grow:<br />
1. Given <strong>the</strong> current trend towards more aggressive optimisation,<br />
including loop unrolling and method inlining,<br />
compilers will have large method bodies to analyse













