ment and the counting of phrases are done separatelyfor each block and then accumulated tobuild the updated phrase model.4 <strong>Phrase</strong> Model <strong>Training</strong>The produced phrase alignment can be given as asingle best alignment, as the n-best alignments oras an alignment graph representing all alignmentsconsidered by the decoder. We have developedtwo different models for phrase translation probabilitieswhich make use of the force-aligned trainingdata. Additionally we consider smoothing bydifferent kinds of interpolation of the generativemodel <strong>with</strong> the state-of-the-art heuristics.4.1 ViterbiThe simplest of our generative phrase models estimatesphrase translation probabilities by their relativefrequencies in the Viterbi alignment of thedata, similar to the heuristic model but <strong>with</strong> countsfrom the phrase-aligned data produced in trainingrather than computed on the basis of a word alignment.The translation probability of a phrase pair( ˜f, ẽ) is estimated asp F A ( ˜f|ẽ) = C F A( ˜f, ẽ)∑C F A ( ˜f ′ , ẽ)˜f ′(5)where C F A ( ˜f, ẽ) is the count of the phrase pair( ˜f, ẽ) in the phrase-aligned training data. This canbe applied to either the Viterbi phrase alignmentor an n-best list. For the simplest model, eachhypothesis in the n-best list is weighted equally.We will refer to this model as the count model aswe simply count the number of occurrences of aphrase pair. We also experimented <strong>with</strong> weightingthe counts <strong>with</strong> the estimated likelihood of thecorresponding entry in the the n-best list. The sumof the likelihoods of all entries in an n-best list isnormalized to 1. We will refer to this model as theweighted count model.4.2 Forward-backwardIdeally, the training procedure would consider allpossible alignment and segmentation hypotheses.When alternatives are weighted by their posteriorprobability. As discussed earlier, the run-time requirementsfor computing all possible alignmentsis prohibitive for large data tasks. However, wecan approximate the space of all possible hypothesesby the search space that was used for the alignment.While this might not cover all phrase translationprobabilities, it allows the search space andtranslation times to be feasible and still containsthe most probable alignments. This search spacecan be represented as a graph of partial hypotheses(Ueffing et al., 2002) on which we can computeexpectations using the Forward-Backward algorithm.We will refer to this alignment as the fullalignment. In contrast to the method described inSection 4.1, phrases are weighted by their posteriorprobability in the word graph. As suggested inwork on minimum Bayes-risk decoding for SMT(Tromble et al., 2008; Ehling et al., 2007), we usea global factor to scale the posterior probabilities.4.3 <strong>Phrase</strong> Table InterpolationAs (DeNero et al., 2006) have reported improvementsin translation quality by interpolation ofphrase tables produced by the generative and theheuristic model, we adopt this method and also reportresults using log-linear interpolation of the estimatedmodel <strong>with</strong> the original model.The log-linear interpolations p int ( ˜f|ẽ) of thephrase translation probabilities are estimated asp int ( ˜f|ẽ) =(˜f|ẽ)) 1−ω (p H ( · p gen ( ˜f|ẽ)) (ω)(6)where ω is the interpolation weight, p H theheuristically estimated phrase model and p gen thecount model. The interpolation weight ω is adjustedon the development corpus. When interpolatingphrase tables containing different sets ofphrase pairs, we retain the intersection of the two.As a generalization of the fixed interpolation ofthe two phrase tables we also experimented <strong>with</strong>adding the two trained phrase probabilities as additionalfeatures to the log-linear framework. Thisway we allow different interpolation weights forthe two translation directions and can optimizethem automatically along <strong>with</strong> the other featureweights. We will refer to this method as featurewisecombination. Again, we retain the intersectionof the two phrase tables. With good loglinearfeature weights, feature-wise combinationshould perform at least as well as fixed interpolation.However, the results presented in Table 5
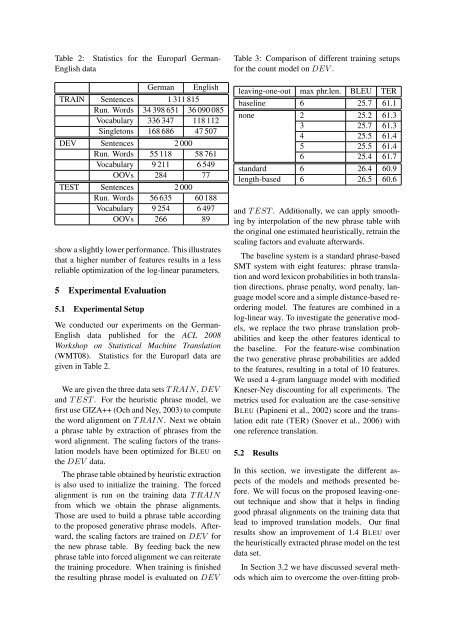
Table 2: Statistics for the Europarl German-English dataGermanEnglishTRAIN Sentences 1 311 815Run. Words 34 398 651 36 090 085Vocabulary 336 347 118 112Singletons 168 686 47 507DEV Sentences 2 000Run. Words 55 118 58 761Vocabulary 9 211 6 549OOVs 284 77TEST Sentences 2 000Run. Words 56 635 60 188Vocabulary 9 254 6 497OOVs 266 89show a slightly lower performance. This illustratesthat a higher number of features results in a lessreliable optimization of the log-linear parameters.5 Experimental Evaluation5.1 Experimental SetupWe conducted our experiments on the German-English data published for the ACL 2008Workshop on Statistical Machine <strong>Translation</strong>(WMT08). Statistics for the Europarl data aregiven in Table 2.We are given the three data sets T RAIN, DEVand T EST . For the heuristic phrase model, wefirst use GIZA++ (Och and Ney, 2003) to computethe word alignment on T RAIN. Next we obtaina phrase table by extraction of phrases from theword alignment. The scaling factors of the translationmodels have been optimized for BLEU onthe DEV data.The phrase table obtained by heuristic extractionis also used to initialize the training. The forcedalignment is run on the training data T RAINfrom which we obtain the phrase alignments.Those are used to build a phrase table accordingto the proposed generative phrase models. Afterward,the scaling factors are trained on DEV forthe new phrase table. By feeding back the newphrase table into forced alignment we can reiteratethe training procedure. When training is finishedthe resulting phrase model is evaluated on DEVTable 3: Comparison of different training setupsfor the count model on DEV .leaving-one-out max phr.len. BLEU TERbaseline 6 25.7 61.1none 2 25.2 61.33 25.7 61.34 25.5 61.45 25.5 61.46 25.4 61.7standard 6 26.4 60.9length-based 6 26.5 60.6and T EST . Additionally, we can apply smoothingby interpolation of the new phrase table <strong>with</strong>the original one estimated heuristically, retrain thescaling factors and evaluate afterwards.The baseline system is a standard phrase-basedSMT system <strong>with</strong> eight features: phrase translationand word lexicon probabilities in both translationdirections, phrase penalty, word penalty, languagemodel score and a simple distance-based reorderingmodel. The features are combined in alog-linear way. To investigate the generative models,we replace the two phrase translation probabilitiesand keep the other features identical tothe baseline. For the feature-wise combinationthe two generative phrase probabilities are addedto the features, resulting in a total of 10 features.We used a 4-gram language model <strong>with</strong> modifiedKneser-Ney discounting for all experiments. Themetrics used for evaluation are the case-sensitiveBLEU (Papineni et al., 2002) score and the translationedit rate (TER) (Snover et al., 2006) <strong>with</strong>one reference translation.5.2 ResultsIn this section, we investigate the different aspectsof the models and methods presented before.We will focus on the proposed leaving-oneouttechnique and show that it helps in findinggood phrasal alignments on the training data thatlead to improved translation models. Our finalresults show an improvement of 1.4 BLEU overthe heuristically extracted phrase model on the testdata set.In Section 3.2 we have discussed several methodswhich aim to overcome the over-fitting prob-