Analisis Lexico - GIAA
Analisis Lexico - GIAA
Analisis Lexico - GIAA

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
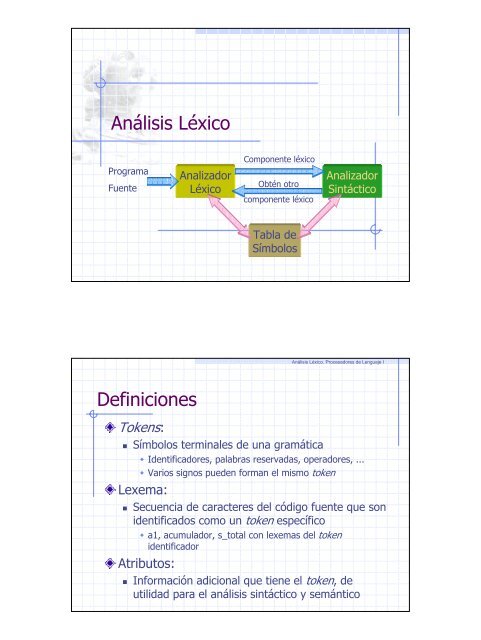
Análisis Léxico<br />
Componente léxico<br />
Programa<br />
Fuente<br />
Analizador<br />
Léxico<br />
Obtén otro<br />
componente léxico<br />
Analizador<br />
Sintáctico<br />
Tabla de<br />
Símbolos<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Definiciones<br />
Tokens:<br />
• Símbolos terminales de una gramática<br />
• Identificadores, palabras reservadas, operadores, ...<br />
• Varios signos pueden forman el mismo token<br />
Lexema:<br />
• Secuencia de caracteres del código fuente que son<br />
identificados como un token específico<br />
• a1, acumulador, s_total con lexemas del token<br />
identificador<br />
Atributos:<br />
• Información adicional que tiene el token, de<br />
utilidad para el análisis sintáctico y semántico
Análisis Léxico. Procesadores de Lenguaje I<br />
Funciones del Análisis Léxico<br />
Manejar el fichero fuente<br />
Leer los caracteres de la entrada<br />
Generar una secuencia de componentes léxicos<br />
(TOKENS)<br />
Eliminar comentarios, delimitadores (espacios,<br />
símbolos de puntación, fin de línea)<br />
Relacionar los mensajes de error con las líneas del<br />
programa fuente<br />
Introducir los identificadores en la tabla de símbolos<br />
Manejar macros<br />
Controlar si es de formato libre o no<br />
• Libre: PASCAL, ALGOL<br />
• No libre: FORTRAN, BASIC<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Aspectos del Análisis Léxico<br />
Diseño más sencillo<br />
• Los símbolos que trata el scanner se describe con una<br />
gramática más simple que la del parser, gramática regular<br />
Mejora la eficiencia<br />
• Gran parte del tiempo de compilación se consume en la<br />
lectura y exploración de caracteres<br />
Mejora la portabilidad<br />
• Se pueden tener varias versiones del scanner una para<br />
distintos códigos (EBCDID, ASCII, ...), con el mismo parser<br />
Descarga el análisis sintáctico<br />
• Ejemplo; no puedo distinguir en FORTRAN hasta después del<br />
1<br />
• DO 5 I=1.25<br />
• DO 5 I=1,25
Análisis Léxico. Procesadores de Lenguaje I<br />
Tokens, patrones y lexemas, I<br />
Dos cuestiones:<br />
• ¿Cómo especificar tokens?<br />
• ¿Cómo reconocer los tokens dada una<br />
especificación de tokens?<br />
Especificar tokens<br />
• Todos los elementos básicos en un lenguaje<br />
deben ser tokens por lo tanto deben reconocerse<br />
Main() {<br />
int I, j;<br />
for (I=0; I3 then a:=b+x1<br />
Tokens<br />
relación<br />
asign<br />
Lexemas<br />
if<br />
x1,a,b<br />
><br />
+<br />
:=<br />
then<br />
3<br />
• Los atributos de los identificadores se pueden guardar en la<br />
tabla de símbolos<br />
• Los otros se pueden guardar en otra tabla o devolverlos<br />
junto al token<br />
if<br />
id<br />
op<br />
then<br />
num
Análisis Léxico. Procesadores de Lenguaje I<br />
Tokens, patrones y lexemas, IV<br />
Componente<br />
Léxico<br />
Const<br />
If<br />
Relación<br />
Identificador<br />
Número<br />
Literal<br />
Lexemas de<br />
Ejemplo<br />
Const<br />
If<br />
<br />
Pi, cuenta, D2<br />
3.1416, 0<br />
“el resultado:”<br />
Descripción del<br />
Patrón<br />
Const<br />
If<br />
< O = o ><br />
[a-zA-z]+<br />
[0-9]+(\.[0-9]+)?<br />
Cualquier carácter<br />
entre “” menos \“<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Análisis Léxico, representación<br />
Expresión Regular<br />
• [a-zA-Z][a-zA-Z0-9]*<br />
Autómata finito (diagrama o tabla de transición)<br />
(no exactamente)<br />
a ... z A ... Z 0 ... 9<br />
→q 0<br />
q 1 ... q 1<br />
*q 1 ...<br />
q 1<br />
q 1<br />
q 1<br />
q 1<br />
...<br />
...<br />
q 1<br />
q 1<br />
φ<br />
q 1<br />
...<br />
...<br />
φ<br />
q 1<br />
Gramática Lineal (regular)<br />
• S::= aR | ... | zR | AR | ... | ZR<br />
• R::= aR | ... | zR | AR | ... | ZR | 0R | ... | 9R | λ
Análisis Léxico. Procesadores de Lenguaje I<br />
Diagrama de Transiciones (DT)<br />
Para especificar el funcionamiento de un AL<br />
• Lee caracteres hasta completar un token<br />
(alcanzado un estado de aceptación) entonces:<br />
• Devuelve el token leído<br />
• Deja el buffer de entrada listo para la siguiente llamada<br />
• No tiene estados de error<br />
• Las entradas para las que no hay transición se<br />
consideran de error<br />
• De los estados de aceptación no salen transiciones<br />
• Para cadenas no específicas, se realiza una<br />
transición más (delimitador), que no pertenece al<br />
token<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Reconocedor de números enteros<br />
[0-9] + q 0<br />
[0-9]<br />
q 1<br />
[0-9]<br />
AFD: el estado q 1<br />
reconoce números<br />
enteros<br />
[0-9]<br />
[0-9]<br />
q 0 q 1<br />
otro<br />
q 2<br />
DT: el estado q 2<br />
devuelve el token<br />
num_entero<br />
*<br />
El asterisco significa que el carácter<br />
debe ser devuelto a la entrada
Análisis Léxico. Procesadores de Lenguaje I<br />
Analizador de relaciones matemáticas<br />
q 2<br />
q 0<br />
<<br />
q 1<br />
=<br />
q Devuelve<br />
q 8<br />
9<br />
><br />
=<br />
><br />
q 3<br />
><br />
otro<br />
otro<br />
q 5<br />
q 4<br />
q 6<br />
=<br />
Devuelve<br />
q 7 =><br />
otro<br />
Devuelve<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Paso de una ER a un AFND<br />
1. Reconocer {λ}:<br />
λ<br />
i f<br />
2. Reconocer un símbolo {a} en Σ:<br />
3. Dadas las ER s y t<br />
Para s|t:<br />
Para s•t:<br />
i<br />
i<br />
i<br />
λ<br />
λ<br />
λ<br />
a<br />
f<br />
s<br />
t<br />
s<br />
t<br />
λ<br />
λ<br />
f<br />
λ<br />
f<br />
4. Dada la ER s, para s*<br />
λ<br />
i<br />
λ<br />
s<br />
λ<br />
λ<br />
f<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Ejemplo: identificador<br />
ER: letra (letra|dígito)*<br />
λ<br />
i<br />
letra<br />
λ<br />
λ<br />
λ<br />
letra<br />
dígito<br />
λ<br />
λ<br />
λ<br />
f<br />
λ
Análisis Léxico. Procesadores de Lenguaje I<br />
Paso del AFND al AFD<br />
Construcción por subconjuntos del AFD D que pasa por los<br />
estados del AFND N “en paralelo”<br />
Para s∈N, cierre(s) ={t∈N, hay transición λ de s a t}<br />
Para T en N, cierre(T)=U cierre(s i )<br />
s i ∈T<br />
Para T en N, mover(T,a)=U {estados en N a los que llega<br />
s i ∈T transición en a desde s i }<br />
Algoritmo: construcción de estados D E , tabla D T<br />
1. Inicializar D E<br />
con cierre(s 0<br />
)<br />
2. Mientras haya estado T en D E<br />
sin marcar<br />
1. Marcar T<br />
2. Para cada símbolo a∈Σ :<br />
1. U=cierre(mover(T,a))<br />
2. Si U no está en D E :<br />
3. Fin<br />
1. Añadir U a D E<br />
2. DT(T,a)=U<br />
3. Fin<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Ejemplo: identificador<br />
ER: letra (letra|dígito)*<br />
λ<br />
1<br />
letra<br />
2<br />
λ<br />
letra<br />
λ 4<br />
3<br />
5 λ<br />
dígito<br />
λ 6 7 λ<br />
8<br />
λ<br />
9<br />
λ<br />
{5,8,3,4,9}<br />
letra<br />
{1}<br />
letra<br />
{2,3,4,6,9}<br />
letra<br />
dígito<br />
dígito<br />
dígito<br />
{7,8,3,6,9}
Análisis Léxico. Procesadores de Lenguaje I<br />
Minimización de estados de un AFD<br />
Construcción del AFD M’ equivalente a M con<br />
mínimo nestados (proceso divisivo)<br />
1. Dividir estados en partición Π dos grupos: F (acp), S (no)<br />
2. Construcción de Π n :<br />
1. Para cada grupo G en Π, dividir G en subgrupos hasta que<br />
cualquier par de estados s, t que estén en el mismo subgrupo,<br />
los estados s,t tienen transiciones en a a estados en el mismo<br />
subgrupo para cualquier a∈Σ<br />
3. Si Π n =Π, pasar a 4; si no: hacer Π ←Π n y volver a 3.<br />
4. Los grupos en Π son los estados de M’<br />
1. Construir tabla de transiciones<br />
2. Eliminar estados no alcanzados<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Ejemplo: identificador<br />
ER identificador: letra (letra|dígito)*<br />
letra<br />
I<br />
letra<br />
F<br />
dígito<br />
ER: a*<br />
F<br />
a
Análisis Léxico. Procesadores de Lenguaje I<br />
Implementación de un AL<br />
Utilizando un generador de Analizadores Léxicos<br />
(LEX)<br />
• Ventajas<br />
• Comodidad<br />
• Rapidez de desarrollo<br />
• Inconvenientes<br />
• Ineficiencia<br />
• Dificultad de mantenimiento del código generado<br />
• Consejo: Ordenar las reglas/transiciones de acuerdo a la<br />
frecuencia de utilización<br />
Utilizando ensamblador<br />
• Ventajas<br />
• Más eficiente y compacto<br />
• Inconvenientes<br />
• Más difícil de desarrollar<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Implementación de un AL<br />
Utilizando un lenguaje de alto nivel<br />
• Ventajas<br />
• Eficiente<br />
• Compacto<br />
• Inconveniente<br />
• Realizar todo a mano<br />
• Técnicas<br />
• Programación<br />
• Tabla compacta<br />
• Hasing<br />
• DT programado
Análisis Léxico. Procesadores de Lenguaje I<br />
Tabla de Transiciones del DT<br />
[0-9]<br />
[0-9]<br />
q 0 q 1<br />
otro<br />
q 2 *<br />
Entradas<br />
estado 0-9 Otro token Retroceso<br />
q 0 q 1 Error - -<br />
q 1 q 1 q 2 - -<br />
q 2 - - Num_entero 1<br />
El AL recorre la tabla con un bucle ejecutando<br />
la sentencia:<br />
Estado := TablaTransiciones [ Estado , Entrada ];<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Programación de un AL<br />
Dos punteros de lectura:<br />
• Puntero actual (PA, “current pointer”): El último carácter aceptado<br />
• Puntero de búsqueda (PB, “lookahead pointer”): El último carácter<br />
leído<br />
Funciones de lectura:<br />
• GetChar: mueve el PB hacia delante y devuelve el siguiente<br />
carácter<br />
• Fail: mueve el PB a donde está el PA<br />
• Retract: mueve el PB un carácter hacia atrás<br />
• Accept: mueve el PA a donde está el PB<br />
Predicados:<br />
• IsLetter(x):= x∈ [A..Za..z]<br />
• IsDigit(x):= x∈ [0..9]<br />
• IsDelimiter(x):= x∈ [.,;]<br />
Acciones:<br />
• InstallName(id): introduce un nombre en la tabla de símbolos
Análisis Léxico. Procesadores de Lenguaje I<br />
Ejemplo con Identificador<br />
Identificador::= letra·(letra+dígito)*<br />
Pseudocódigo<br />
c:= GetChar<br />
If IsLetter(c) Then<br />
identificador:=“”<br />
Repeat<br />
identificador:=identificador+c<br />
c:=GetChar<br />
Until not(IsLetter(c) OR IsDigit(c))<br />
Retract<br />
token:=(Id, Install(identificador))<br />
Accept<br />
Return (token)<br />
Else Fail<br />
¿Qué ocurre con? x1, temp, 102<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Ejemplo con Constante Entera<br />
Entero::= dígito +<br />
Pseudocódigo c:= GetChar<br />
If IsDigit(c) Then<br />
Valor:=Convertir(c)<br />
c:=GetChar<br />
While IsDigit(c) do<br />
Valor:=10 * Valor + Convertir(c)<br />
c:=GetChar<br />
EndWhile<br />
Retract<br />
token:=(Entero, Valor)<br />
Accept<br />
Return (token)<br />
Else Fail<br />
¿Qué ocurre con? x1, 102, 10.3
Análisis Léxico. Procesadores de Lenguaje I<br />
Implementación con tabla compacta I<br />
q 6<br />
b<br />
L={dda$, ab * ca$|n>=0}<br />
q 1<br />
a<br />
q 2<br />
c<br />
q 3<br />
a<br />
q 4<br />
$<br />
q<br />
a b c d $<br />
5<br />
M<br />
1 2 - - 5 -<br />
d d<br />
2 - 2 3 - -<br />
3 4 - - - -<br />
4 - - - - 6<br />
5 - - - 3 -<br />
6 - - - - -<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Implementación con tabla compacta II<br />
Para ahorrar memoria se guardan los elementos no nulos en<br />
una matriz VALOR de dos valores y con tantos elementos como<br />
posiciones no nulas de M<br />
Se crea otra tabla, PRIFIL, con el primer VALOR de cada línea<br />
Número de elementos (no nulos) de VALOR para esa línea<br />
1<br />
2<br />
3<br />
4<br />
5<br />
VALOR<br />
2<br />
5<br />
2<br />
3<br />
4<br />
COL<br />
1<br />
4<br />
2<br />
3<br />
1<br />
1<br />
2<br />
3<br />
4<br />
5<br />
PRIFIL<br />
1<br />
3<br />
5<br />
6<br />
7<br />
FIL<br />
2<br />
2<br />
1<br />
1<br />
1<br />
•M(2,3)?<br />
•PRIFIL(2)=3<br />
•FIL=2, esto significa que los<br />
elementos 3 y 4 de VALOR contienen<br />
las transiciones del estado 2, de los<br />
dos el que tiene valor COL=3 tiene<br />
una transición a 3<br />
6<br />
6<br />
5<br />
6<br />
0<br />
0<br />
7<br />
3<br />
4
Análisis Léxico. Procesadores de Lenguaje I<br />
Programación con Tabla Hash<br />
Otra forma de programar un analizador léxico es creando una<br />
tabla hash con el DT<br />
a ... z A ... Z 0 ... 9 < = ...<br />
→q 0<br />
q 1 ... q 1 q 1 ... q 1 φ ... φ q 2 q 6 ...<br />
*q 1 q 1 ... q 1 q 1 ... q 1 q 1 ... q 1 q 0 q 0 ...<br />
*q 2 q 0 ... q 0 q 0 ... q 0 q 0 ... q 0 q 0 q 0 ...<br />
En cada iteración, se lee un carácter de la entrada y se transita<br />
a un estado dependiendo de la tabla de transiciones<br />
Si el DT es determinista, sólo habrá una transición posible para<br />
cada símbolo de entrada y no hace falta retroceso<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Autómata programado<br />
Representa directamente con un programa al DT<br />
en cuestión<br />
estado:=1<br />
while estado6 do<br />
Leecar {devuelve en car el siguiente carácter leído}<br />
case estado of<br />
1: if car=“a” then estado:=2 else<br />
if car=“d” then estado:=5 else error<br />
2: if car=“c” then estado:=3 else<br />
if car=“b” then estado:=2 else error<br />
3: if car=“a” then estado:=4 else error<br />
4: if car=“$” then estado:=6 else error<br />
5: if car=“d” then estado:=3 else error<br />
3: error<br />
end case<br />
end while
Análisis Léxico. Procesadores de Lenguaje I<br />
Programación con LEX<br />
Lex: Lexical Analyzer Generator<br />
Lex programa fuente<br />
{definición}<br />
%%<br />
{reglas}<br />
%%<br />
{subrutinas de usuario}<br />
Reglas: acción<br />
Cada expresión regular especifica un token<br />
Acción: fragmentos de código C que especifican que<br />
hacer cuando un token es reconocido<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Errores Léxicos<br />
Hay pocos detectables por el analizador léxico<br />
• then::=3+x1 (¿=if..then?. ¿=identificador?)<br />
Detectables<br />
• Número de caracteres de los identificadores<br />
• Caracteres ilegales<br />
• Otros (si el lenguaje no admite .5 en lugar de<br />
0.5)...<br />
• Utilizar caracteres que no pertenecen al alfabeto<br />
del lenguaje<br />
• Cadena que no concuerda con ningún token
Análisis Léxico. Procesadores de Lenguaje I<br />
Tratamiento de errores<br />
!<br />
En caso de error:<br />
• Anotar el error<br />
• Recuperarse<br />
• Ignorar<br />
• Borrar<br />
• Insertar<br />
• Reemplazar<br />
• Conmutar<br />
• Seguir<br />
¡¡¡ATENCIÓN PRECAUCIÓN!!!<br />
Programa con K errores: hacen falta K cambios para poder ser<br />
correcto<br />
No se suelen utilizar las acciones de corrección de errores por<br />
ser muy costosas<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
AL y Lenguajes de Programación<br />
El AL agrupa caracteres para formar tokens, por tanto es importante definir<br />
el “delimitador”<br />
• Carácter que delimita el token sin pertenecer a él<br />
Otro concepto importante es el de “palabra reservada”<br />
• El lenguaje prohíbe el uso libre al programador de determinadas<br />
palabras que tienen un significado específico y único en el lenguaje<br />
Se pueden clasificar los lenguajes de programación por el uso de los<br />
delimitadores y palabras reservadas:<br />
• Delimitadores blancos con palabras reservadas<br />
• Caso más sencillo de lenguaje (PASCAL, COBOL)<br />
• Delimitadores blancos sin palabras resevadas<br />
• PL/I<br />
• Blancos se ignoran sin palabras reservadas<br />
• El tipo más difícil de lenguaje, aparecen ambigüedades (FORTRAN)<br />
• Blancos se ignoran con palabras reservadas<br />
• Indeterminado
Análisis Léxico. Procesadores de Lenguaje I<br />
Identificación de palabras reservadas<br />
if P.reserv<br />
int P.reserv<br />
... P.reserv<br />
real Identif<br />
... Identif<br />
¿Cómo reconocer las palabras reservadas de<br />
identificadores que concuerdan con el mismo<br />
patrón pero son tokens distintos?<br />
• Resolución implícita:<br />
• En principio, todas son identificadores, antes de devolver<br />
el token “identificador” la comprueba en una lista de<br />
palabras reservadas<br />
• En la tabla de símbolos aparecen al principio las palabras<br />
reservadas<br />
• Resolución explícita:<br />
• Se integran los DT correspondiente a las palabras<br />
reservadas en la máquina reconocedora<br />
Análisis Léxico. Procesadores de Lenguaje I<br />
Prioridad de los tokens<br />
Criterios<br />
• Dar prioridad al token que concuerda con el<br />
lexema más largo<br />
• Ejemplo: “>” o “>=” se quedaría con el segundo<br />
• En el caso que un lexema se pueda concordar a<br />
varios tokens se asocia al que esté definido en<br />
primer lugar