

Dispensa Calcolatori..
Dispensa Calcolatori..
Dispensa Calcolatori..

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
<strong>Calcolatori</strong> Elettronici II<br />
23/03/2004<br />
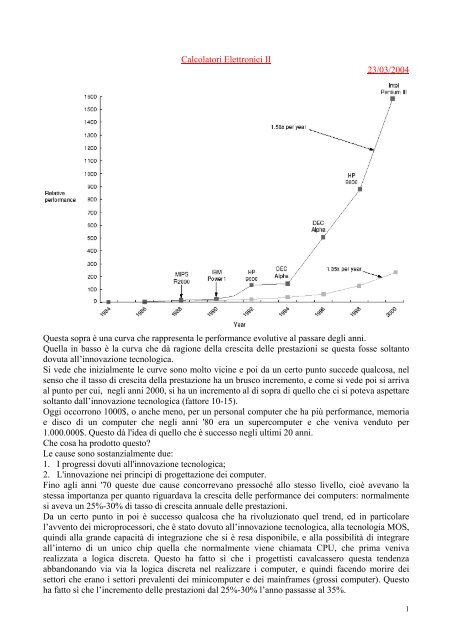
Questa sopra è una curva che rappresenta le performance evolutive al passare degli anni.<br />
Quella in basso è la curva che dà ragione della crescita delle prestazioni se questa fosse soltanto<br />
dovuta all’innovazione tecnologica.<br />
Si vede che inizialmente le curve sono molto vicine e poi da un certo punto succede qualcosa, nel<br />
senso che il tasso di crescita della prestazione ha un brusco incremento, e come si vede poi si arriva<br />
al punto per cui, negli anni 2000, si ha un incremento al di sopra di quello che ci si poteva aspettare<br />
soltanto dall’innovazione tecnologica (fattore 10-15).<br />
Oggi occorrono 1000$, o anche meno, per un personal computer che ha più performance, memoria<br />
e disco di un computer che negli anni '80 era un supercomputer e che veniva venduto per<br />
1.000.000$. Questo dà l'idea di quello che è successo negli ultimi 20 anni.<br />
Che cosa ha prodotto questo?<br />
Le cause sono sostanzialmente due:<br />
1. I progressi dovuti all'innovazione tecnologica;<br />
2. L'innovazione nei principi di progettazione dei computer.<br />
Fino agli anni '70 queste due cause concorrevano pressoché allo stesso livello, cioè avevano la<br />
stessa importanza per quanto riguardava la crescita delle performance dei computers: normalmente<br />
si aveva un 25%-30% di tasso di crescita annuale delle prestazioni.<br />
Da un certo punto in poi è successo qualcosa che ha rivoluzionato quel trend, ed in particolare<br />
l’avvento dei microprocessori, che è stato dovuto all’innovazione tecnologica, alla tecnologia MOS,<br />
quindi alla grande capacità di integrazione che si è resa disponibile, e alla possibilità di integrare<br />
all’interno di un unico chip quella che normalmente viene chiamata CPU, che prima veniva<br />
realizzata a logica discreta. Questo ha fatto sì che i progettisti cavalcassero questa tendenza<br />
abbandonando via via la logica discreta nel realizzare i computer, e quindi facendo morire dei<br />
settori che erano i settori prevalenti dei minicomputer e dei mainframes (grossi computer). Questo<br />
ha fatto sì che l’incremento delle prestazioni dal 25%-30% l’anno passasse al 35%.<br />
1
In realtà però questo salto essenzialmente era dovuto, più che all'innovazione nelle tecniche di<br />
progettare un computer, quasi esclusivamente alla tecnologia. Ad un certo punto c'è stata una<br />
svolta: fino a quel punto si lavorava tipicamente in assembler, e questo significa che non era facile<br />
programmare, e poi quando veniva creato un nuovo microprocessore si cercava di renderlo<br />
compatibile con quello precedente, almeno per quanto riguardava l'esecuzione del codice; un<br />
esempio classico è quello della famiglia Intel (che è nata con l'8080, che era un microprocessore a 8<br />
bit, poi è nato l'8085, l'8086, l'80186, …, l'80486, Pentium), dove un codice sviluppato negli anni<br />
'80 ancora girerebbe su un Pentium. Questo era legato non al fatto che il progettista nel progettare il<br />
prossimo microprocessore era “innamorato” dell'architettura precedente, ma ad un fatto pratico,<br />
cioè al fatto di non sprecare tutte le risorse investite nel progettare il software che girava su quel<br />
microprocessore. Questo era un vincolo fortissimo per il progettista. A metà degli anni '80 però via<br />
via si è cominciato ad abbandonare il linguaggio assembler, perché i programmatori cominciavano<br />
ad usare sempre più i compilatori. Abbandonare il linguaggio assembler significava incominciare ad<br />
eliminare quel vincolo sulla compatibilità del codice: se ho un codice scritto in C e voglio passare<br />
da un processore all'altro ricompilo e non devo rifare il software. Però questo è uno degli aspetti;<br />
l'altro aspetto fondamentale è legato ai sistemi operativi: fino a quel tempo i sistemi operativi erano<br />
essenzialmente i sistemi operativi proprietari, e questo significava che quando l'IBM, per esempio,<br />
vendeva ad una banca un software che girava su quel sistema operativo, questa era bloccata a vita<br />
su quella piattaforma perché il software fa riferimento al sistema operativo.<br />
Poi è stato creato Unix: è stato concepito all'interno di un’università, quindi era un software libero,<br />
non risentiva di logiche di mercato e si poneva quindi come un sistema operativo che non era legato<br />
ad una particolare piattaforma hardware. Unix è stato già dall'inizio progettato, quasi tutto scritto in<br />
C e non più in assembler, per essere indipendente dalla piattaforma. Questo ha fatto sì che il<br />
progettista improvvisamente si trovasse di fronte ad una libertà inaspettata. A questo punto,<br />
Patterson ed Hennessy non dovendo più sottostare a quei vincoli potevano progettare un processore<br />
che aveva delle prestazioni molto più elevate delle architetture che in quel momento erano in<br />
circolazione. Questa logica ha fatto sì che si incominciasse ad affermare la nuova filosofia di<br />
processori, che è quella che si chiama RISC (reduced instruction set computer).<br />
A parità di tecnologia perché una filosofia RISC dovrebbe avere prestazioni migliori?<br />
Patterson ed Hennessy hanno fatto una considerazione: prima si programmava in assembler, e oltre<br />
al problema della compatibilità del codice c'erano altri problemi, cioè un programmatore assembler<br />
da un nuovo processore si aspetta un set di istruzioni molto ricco così ha una certa libertà nello<br />
scegliere il proprio stile di programmazione. Una volta che non si programma più in assembler non<br />
è più programmatore che utilizza il set di istruzioni del processore ma il compilatore, ovvero il<br />
progettista del compilatore; allora ci si è chiesti il perché continuare a progettare un processore con<br />
set di istruzioni ricchissimo (ricchissimo significa che da un punto di vista implementativo più<br />
esteso e complesso è il set di istruzioni più complesso è l'hardware che poi realizza quel set di<br />
istruzioni, e quindi occupa più area sul silicio) se poi nessuno più lo utilizza, o meglio non si sa<br />
quanto è utilizzato. Qual è il modo più semplice e diretto di capire se conviene o no progettare un<br />
set di istruzioni ricco visto che adesso ci sono i compilatori? Si cominciano a compilare tanti<br />
programmi diversi tra loro e vado a vedere ogni per programma compilato quali sono le istruzioni<br />
del processore che utilizza, e magari faccio una statistica. Facendo questo posso scoprire che, per<br />
esempio, un’istruzione pazzesca che qualcuno aveva concepito in quel microprocessore dal<br />
compilatore non veniva mai usata o quasi mai; ma allora se io la tolgo il compilatore entra in crisi<br />
oppure si può sempre trovare una strategia per cui quella istruzione io la faccio la stessa però<br />
usando altre istruzioni? La risposta naturalmente è sì. Siccome progettare un processore significa<br />
innanzitutto definire il suo set di istruzioni, e siccome il progettista sa che più complesso è il set di<br />
istruzioni più complesso è il processore, allora incomincia a vedere un determinato compilatore su<br />
quel processore che ha un set complesso di istruzioni quante ne utilizza, e quindi si fanno delle<br />
statistiche, delle misure sull'utilizzo del set di istruzioni. Facendo queste misure è emerso che<br />
moltissime istruzioni erano praticamente quasi mai utilizzate. Allora a questo punto la cosa più<br />
2
ovvia era ridurre il set di istruzioni all'essenziale; ma riducendo il set di istruzioni qual è il<br />
vantaggio che si ottiene? Se il set di istruzioni è meno complesso significa che l'hardware è meno<br />
complesso e quindi posso andare più veloce. Se io diminuisco il numero di transistor all'interno del<br />
chip per eseguire le istruzioni, i rimanenti transistor li posso utilizzare per metterci dentro la<br />
memoria oppure per realizzare il pipeline (un modo di eseguire più istruzioni contemporaneamente<br />
all'interno dello stesso processore). Normalmente il processore è molto più veloce della memoria,<br />
allora se all'interno del processore si sono liberati tanti transistor potrei utilizzare quell'aria di silicio<br />
libera per mettere un po’ di memoria dentro, per esempio dei registri; questo mi fa andare più<br />
veloce perché si risparmiano un sacco di accessi in memoria.<br />
Un aspetto è la memoria cache. Tutte le volte che si va memoria il processore deve rallentare<br />
moltissimo, allora la possibilità di inventarsi la gerarchia di memoria, cioè la memoria cache, è un<br />
qualcosa che fa pagare molto meno il prezzo al processore sulla lentezza della memoria.<br />
Facendo queste innovazioni si incomincia ad assistere ad un rate di crescita delle prestazioni di oltre<br />
il 50% per anno, e questo è quello che dà la spiegazione dell'andamento di quelle curve.<br />
Conseguenze:<br />
• Un microprocessore di oggi supera le prestazioni di un supercomputer di 10 anni fa<br />
• Dominanza di computer a microprocessore (PC+WS) sull'intero range dei computers<br />
(minicomputer e mainframe sostituiti da multiprocessore).<br />
Tutto questo è dovuto a questa innovazione nell'arte di progettare, innovazione che si basa sul<br />
principio fondamentale che è quello di un approccio quantitativo alla progettazione. Approccio<br />
quantitativo significa che prima di progettare qualcosa vado a fare delle misure vedo quello che già<br />
ho come viene utilizzato, e se ci sono cose che vengono utilizzate raramente queste sono le<br />
candidate ad essere buttate via, e questo significa inventarsi qualcosa di nuovo.<br />
Questa è una possibile rappresentazione della catena alimentare: i pesci più grossi mangiano i pesci<br />
più piccoli:<br />
Questa catena alimentare nel caso dell'informatica è stata ribaltata:<br />
Alcune conseguenze dell'approccio quantitativo sono:<br />
• Le prestazioni delle workstation migliorano del 50% per anno<br />
• Se si tiene conto del fattore costo un miglioramento costo-prestazioni del 70% per anno.<br />
Quando parliamo di computer che cosa intendiamo esattamente?<br />
Oggi ci sono tre segmenti di mercato che è abbastanza facile identificare:<br />
• Desktop computing (PC + WS)<br />
• Servers: file server, web server, ecc…<br />
• Embedded computers: parte più in crescita del mercato.<br />
3
Questi tre segmenti di mercato però hanno caratteristiche diverse da diversi punti di vista:<br />
Nell'ultima riga sono riportate le caratteristiche tipiche di ognuno dei tre settori: nel caso del<br />
desktop due parametri importanti sono il prezzo e le prestazioni (anche sulla grafica); per quanto<br />
riguarda il server si vuole un throughput elevato, cioè che riesca per esempio a processare un certo<br />
numero di milioni di richieste secondo, la disponibilità, che significa la capacità del sistema a<br />
continuare a mantenersi funzionante anche in presenza di guasti, e poi la scalabilità, ovvero la<br />
capacità del sistema ad essere espanso (un server normalmente prevede la possibilità di aumentare<br />
la capacità di memorizzazione, la possibilità di aggiungere processori, ecc…); per quanto riguarda i<br />
sistemi embedded questi sono caratterizzati sicuramente dal prezzo, il consumo di potenza,<br />
prestazioni per quella specifica applicazione.<br />
Dopo aver parlato di questa suddivisione e aver visto come i tre settori richiedono parametri di<br />
performance diversi, il compito del progettista è quello di determinare quali sono gli attributi della<br />
nuova macchina, e progettare per massimizzare la prestazioni rispettando i vincoli di costo e<br />
potenza, naturalmente collocandosi nel settore orientato (desktop, server o embedded).<br />
Un aspetto molto interessante è quello legato alla tendenza della tecnologia: perché un progettista di<br />
computer deve preoccuparsi moltissimo della tendenza tecnologica? Se io progettista ho oggi una<br />
certa tecnologia e il progetto del prossimo processore lo faccio con quello che ho a disposizione,<br />
perché mi devo preoccupare della tecnologia che avrò fra due anni?<br />
Ci sono dei dati che sono abbastanza consolidati che riguardano l'evoluzione della tecnologia:<br />
(capacity = capacità d’integrazione)<br />
C'è un parametro che assume un ruolo cruciale: time to market = 2 anni design + produzione. Il<br />
time to market è il tempo che si impiega ad immettere un nuovo prodotto sul mercato. Se io ho un<br />
time to market, per esempio per una workstation, di due anni e faccio il progetto con la tecnologia<br />
di oggi faccio un errore clamoroso perché se fra due anni il trend tecnologico è quello visto sopra<br />
allora la capacità, per esempio, sarà sicuramente maggiore di quella di oggi. Quindi bisogna<br />
guardare a cosa ci sarà disponibile quando il prodotto andrà in produzione.<br />
Altri aspetti legati alla tecnologia sono:<br />
• Feature size: minima size di un transistor o wire nelle direzioni x e y<br />
10µ (1971) → 0,08µ (2003)<br />
Il numero di transistor incrementa quadraticamente con la diminuzione della feature size,<br />
mentre la performance invece aumenta linearmente con la feature size.<br />
• All'aumentare della capacità di integrazione e della frequenza di funzionamento di questi<br />
dispositivi il ritardo di propagazione (wire delay) dei segnali incomincia ad essere rilevante:<br />
4
molti cicli di clock sono spesi per il ritardo sulle linee, e nel caso del Pentium IV due stage di<br />
pipeline su 20 sono consumati per la propagazione dei segnali attraverso il chip.<br />
• Potenza (power): l'incremento del numero di transistor per chip e la frequenza di switching<br />
comporta un incremento del consumo di potenza (qualche decina di W per un microprocessore<br />
anni '80, 100 W per il Pentium IV a 2GHz).<br />
Nel prossimo futuro la potenza sarà il limite principale.<br />
5
25/03/2004<br />
Abbiamo visto che una delle chiavi fondamentali che spiega l'elevato incremento delle performance<br />
nei computers è un nuovo approccio alla progettazione: un approccio di tipo quantitativo, quindi un<br />
approccio che sostanzialmente assume come paradigma quello di eseguire delle misure e sulla base<br />
di queste misure selezionare quelli che sono gli aspetti più rilevanti, quindi quelli che sono più<br />
suscettibili di essere migliorati garantendo un elevato livello di performance, e trascurando altri<br />
aspetti che, per quanto possono offrire scelte che soddisfano l'utente, magari poi sono molto poco<br />
utilizzati.<br />
Per fare queste misure questo approccio quantitativo utilizza vari strumenti che si basano su un<br />
insieme di programmi che si chiamano Benchmarks, sui Traces (queste informazioni vengono<br />
derivate a fronte dell'esecuzione di un programma, e per esempio questi traces ci dicono<br />
un'istruzione rispetto al totale quante volte viene eseguita), sugli instruction Mixes (mi dicono per<br />
esempio 30% di ALU e così via).<br />
Abbiamo visto, per esempio, nel caso dei sistemi embedded che uno dei requisiti fondamentali,<br />
oltre alla performance per quella determinata applicazione, per esempio era il consumo di potenza,<br />
ma si capisce bene è fondamentale anche l'area consumata sul silicio. Quindi sono stati messi a<br />
punto strumenti per la stima della potenza, dell'aria, del delay (tempo speso per eseguire un<br />
programma), ecc.<br />
Naturalmente poi ci sono strumenti che provano valutare i vari parametri di interesse attraverso<br />
teorie “tradizionali”, quale la teoria delle code, regole di tipo pratico, e leggi fondamentali.<br />
Oggi incominciamo a vedere cosa significa valutare alcuni parametri prestazionali dei sistemi<br />
partendo da alcune definizioni di base. Per noi misurare le prestazioni di un computer, per esempio<br />
in termini di velocità, significa valutare il tempo di esecuzione, cioè all'utente finale quello che<br />
interessa è quanto tempo viene speso da questo oggetto per eseguire una determinata applicazione,<br />
quindi si parla di ExTime (execution time): dire che un computer X è n volte più veloce di un<br />
computer Y significa dire che<br />
(per un web server non ci interessa l’ExTime, ma il throughput). A seconda che si parla di ExTime,<br />
oppure di throughput, oppure di qualsiasi altro parametro, devo stare attento a cosa mettere<br />
numeratore per dire che una cosa è più performante di quella precedente; questa ambiguità si<br />
elimina, quanto meno a livello di linguaggio, parlando di rapporto di prestazioni: se io dico che la<br />
macchina X è più performante della macchina Y di n volte, significa che<br />
Naturalmente in questo caso si ha che , se la mia performance è<br />
espressa in termini di tempo di esecuzione; se invece come performance intento il throughput ecco<br />
che la performance coincide con il throughput.<br />
Se X è n% volte più veloce di Y significa che<br />
dove<br />
> 1<br />
> 1<br />
,<br />
6
Esempio:<br />
Se Y impiega 15 secondi per eseguire un task e X impiega 10 secondi, quanto % X è più veloce?<br />
n=50%.<br />
Legge di Amdahl<br />
Questo è un principio che dovrebbe essere sempre seguito da un progettista, e in verità occorrerebbe<br />
seguirlo sempre a prescindere che il progetto riguardi un computer piuttosto che un'automobile, ecc.<br />
Make the common case fast! (rendi il caso più frequente veloce).<br />
“Più frequente” come va inteso? Va inteso che quando io utilizzo il sistema c'è una sua parte che è<br />
responsabile di molto del tempo di lavoro del sistema, allora intuitivamente un miglioramento<br />
apportato a questa parte ci ripaga sufficientemente.<br />
In miglioramento di prestazioni che può essere ottenuto migliorando una qualche attività, quindi<br />
rendendola più veloce, è limitato dalla frazione di tempo in cui tale attività ha luogo.<br />
SPEEDUP: misura di quanto più veloce un task gira sulla macchina enhanced. Quindi se io misuro<br />
uno Speedup = 1.5 significa che ho migliorato le performance del 50%.<br />
Vediamo come si ricava una qualche relazione che ci consenta quantitativamente di misurare qual è<br />
lo Speedup che si ottiene quando si apporta un miglioramento ad un sistema.<br />
Supponiamo di avere un programma che impiega il seguente tempo (la ExTime) per essere<br />
eseguito; analizzando il sistema vedo che c'è una sua parte che si<br />
può migliorare e in termini di tempo di esecuzione è<br />
responsabile di quella frazione di tempo (parte colorata) rispetto al totale. Questa parte a cui applico<br />
il miglioramento posso renderla più veloce, e questo significa che nel nuovo sistema quella parte si<br />
contrarrà, e quindi il tempo di esecuzione totale si accorcerà:<br />
Il rapporto tra il primo tempo di esecuzione e il secondo mi dà lo Speedupoverall (cioè Speedup<br />
complessivo).<br />
Le due grandezze che ci interessano sono: Speedupenhanced (Speedup Enhanced, cioè lo Speedup che<br />
posso ottenere solo della parte a cui applico il miglioramento); il rapporto tra il tempo da migliorare<br />
e l’ExTime totale si chiama FractionEnhanced (cioè la frazione di tempo a cui posso applicare il<br />
miglioramento, si misura sul sistema originario).<br />
Avendo definito queste due grandezze possiamo vedere come si misura lo Speedupoverall.<br />
Quest'ultimo non è altro che:<br />
(woE = without enhancement, wE = with<br />
enhancement).<br />
Il nuovo tempo di esecuzione è dato da:<br />
Così lo Speedupoverall è:<br />
Questa formula ci consente di fare un sacco di valutazioni per scoprire se un determinato<br />
miglioramento ripaga oppure no in termini di guadagno complessivo che si può ottenere.<br />
Nelle annunciato della legge di Amdahl abbiamo detto che il performance improvement è limitato<br />
dalla frazione di tempo in cui l'attività ha luogo; questa frazione di tempo è proprio la<br />
FractionEnhanced; ovvero il massimo Speedup ottenibile è limitato dalla FractionEnhanced. In che senso?<br />
7
Immaginiamo, caso irrealizzabile, di trovare un’idea che fa sì che una certa parte del sistema possa<br />
andare infinitamente più veloce di quanto va adesso; questo significa che lo Speedupenhanced sarebbe<br />
infinito e quindi il rapporto FractionEnhanced/Speedupenhanced tenderebbe a 0; più elevata è la<br />
FractionEnhanced maggiore è lo Speedupoverall.<br />
Da questa analisi semplicissima si può concludere che quello che in effetti ha un impatto enorme<br />
dal punto di vista di guadagno di prestazioni complessivo è la FractionEnhanced, ovvero la frazione di<br />
tempo suscettibile di essere migliorata: maggiore è questa frazione di tempo maggiore è il guadagno<br />
che si può ottenere, e questo ragionamento lo si fa indipendentemente da quanto veloce si vuole<br />
rendere.<br />
Esempio<br />
Prendiamo un computer che ha un certo processore in cui la parte relativa all’esecuzione delle<br />
istruzioni in floating point può essere migliorata facendola andare al doppio di velocità rispetto a<br />
quella attuale, quindi abbiamo uno Speedupenhanced pari a 2; qual è il guadagno che possiamo<br />
ottenere? Per rispondere a questa domanda dobbiamo stimare la FractionEnhanced. L’unità floating<br />
point viene utilizzata dai programmi, quindi non devo parlare in astratto, ma prendo un programma,<br />
suppongo che è il programma che mi interessa, e vedo quanto tempo viene speso (da questo<br />
programma) durante l’esecuzione sull’unità floating point rispetto al totale. In questo caso<br />
supponiamo che soltanto il 10% delle istruzioni eseguite sono di tipo floating point, ed è come dire<br />
che soltanto il 10% del tempo rispetto al totale del tempo di esecuzione, di un determinato<br />
programma, viene speso per la parte floating point. Questo 10% rappresenta la FractionEnhanced.<br />
Applicando le formule abbiamo:<br />
Quindi viene fuori che lo Speedup è pari al 5,3%.<br />
Esempio<br />
Dato un computer cerchiamo di rendere più veloce la CPU di 5 volte, ma questo ci costa 5 volte il<br />
costo originale della CPU. Quanto ci guadagno?<br />
Per vedere se questo investimento è economicamente vantaggioso devo vedere quanto ci guadagno<br />
in termini di performance e quanto mi costa questo guadagno di performance.<br />
I dati che abbiamo sono:<br />
la CPU nel sistema originario è responsabile del 50% del tempo totale di esecuzione (di un<br />
determinato programma); questo significa che l’altro 50% è dedicato all’I/O. Il costo della CPU è<br />
di 1/3 del costo totale del sistema.<br />
La prima cosa che facciamo è valutare lo Speedup:<br />
Quindi ottengo un miglioramento di performance complessivo pari al 67%.<br />
Quanto mi costa questo investimento? I 2/3 del sistema continueranno a costare quanto prima,<br />
mentre l’altro 1/3 costerà 5 volte di più:<br />
Quindi mi costerà 2,33 volte il costo originario.<br />
Così ho che il costo cresce molto di più delle performance.<br />
8
Esempio<br />
Supponiamo di avere un computer su cui viene eseguito una determinata applicazione. Questa<br />
applicazione ha delle operazioni in floating point alcune delle quali sono radici quadrate (FPSQR).<br />
In totale l’unità floating point è responsabile del 50% del tempo di esecuzione, e la sola FPSQR è<br />
responsabile del 10% del tempo di esecuzione totale. A questo punto c’è una gara tra due tipi di<br />
progettazione diversi:<br />
1) l’hardwareista dice che riesce a migliorare l’hardware del FPSQR in modo tale da farlo andare<br />
10 volte più veloce;<br />
2) il softwareista dice che può ottenere il doppio di velocità dell’intera unità floating point.<br />
Nel primo caso ho una FractionEnhanced che è pari a 0,2 e uno Speedup di 10, e allora ne segue che:<br />
Nel secondo caso ho una FractionEnhanced che è pari a 0,5 e uno Speedup di 2, e allora ne segue che:<br />
Quindi migliorano di più le prestazioni se aumento la velocità di tutta l’unità floating point anche se<br />
solo del doppio, rispetto al miglioramento della sola FPSQR anche se di 10 volte.<br />
Abbiamo detto che uno dei dilemmi che fa diventare matti i progettisti di computer è quello della<br />
lentezza della memoria. È un problema perché il computer nasce come una macchina per eseguire<br />
programmi e la CPU non fa altro che andare a leggere l'istruzione della memoria ed eseguirla.<br />
Quindi sicuramente per ogni istruzione bisogna fare quanto meno un accesso in memoria; questo<br />
significa che tutti i miglioramenti di prestazioni che si riescono ad apportare al processore possono<br />
essere vanificate dalla lentezza della memoria. Cosa si può fare per cercare di risolvere questo<br />
problema, o quanto meno di farlo pesare poco?<br />
Non potendo fare niente la tecnologia, qualcuno si è inventato una soluzione estremamente<br />
intelligente. Questa soluzione fa riferimento ad un principio che è il cosiddetto principio di<br />
località, e ad un altro principio che è molto legato all'elettronica. Per quanto riguarda l'elettronica<br />
c'è un principio che dice che: “smaller is faster” (più piccolo è più veloce). Sappiamo che quando<br />
parliamo di memorie RAM ci sono due tipologie: RAM statiche e RAM dinamiche. Le RAM<br />
statiche sono caratterizzate da una velocità più elevata delle RAM dinamiche, però le prime hanno il<br />
problema che consumano di più, perché sono più veloci, e la loro capacità di integrazione è molto<br />
più bassa delle seconde.<br />
Il principio di località è un principio che fa riferimento ad una considerazione base: quando eseguo<br />
un programma vado in memoria legge un istruzione, la eseguo e vado all'istruzione successiva, ecc.;<br />
queste istruzioni quando un programma viene caricato in memoria si succedono una dopo l'altra<br />
nella memoria; quindi quando io eseguo l'istruzione i-esima è probabile che la prossima da eseguire<br />
sta nella locazione di memoria immediatamente successiva. Questo è quello che ha fatto pensare a<br />
qualcuno che allora c'è una località nell'esecuzione del programma, e questo è quello che viene<br />
chiamato principio di località spaziale, ovvero quando io vado a referenziare un item<br />
probabilmente referenzierò gli item che stanno là intorno.<br />
C'è un altro aspetto di questo principio di località che, piuttosto che guardare alla località spaziale,<br />
guarda alla località temporale, ovvero se io vada referenziare un item (istruzione) in questo tempo, è<br />
probabile che nel prossimo futuro la referenzierò di nuovo (si pensi ai loop).<br />
Questa considerazione che tipo di idea potrebbe fare venire al progettista per risolvere questo<br />
problema del gap di prestazioni tra processore e memoria?<br />
9
Se io vado ad interporre una memoria statica, quindi una piccola memoria, tra processore e RAM<br />
dinamica, e in questa piccola memoria di volta in volta ci metto, sfruttando il principio di località, la<br />
parte di codice che viene referenziata, essendo veloce diminuisco in termini di velocità il gap tra<br />
processore e memoria. Quest’idea è furba soltanto se capita poco spesso che il processore andando<br />
in questa piccola memoria (memoria cache) non trova quello che cerca. Per verificare se questa cosa<br />
succede poco spesso oppure no si fanno delle misure su dei programmi di uso molto frequente. Ci<br />
sono delle misure su programmi molto utilizzati e si va scoprire che l’80%-90% dei riferimenti<br />
generati dal processore durante l'esecuzione di un programma cadono all'interno del 10%-20%<br />
dell'intero codice. Se questo è vero quel 20% di codice lo piglio e lo metto nella memoria statica.<br />
Da un punto di vista architetturale il nostro sistema si organizza nel seguente modo:<br />
abbiamo il processore all'interno del quale c'è un certo insieme di registri (che si può vedere come<br />
una piccola memoria incorporata all'interno del processore), poi quando il processore ma all'esterno<br />
per leggere dalla memoria qualcosa, incontra come prima cosa la memoria cache, che sta prima<br />
della main memory, e naturalmente dopo c’è la memoria di massa. Vista in questi termini è come se<br />
avessimo creato una gerarchia di memoria. Più alto è il livello, più questo è prossimo al processore<br />
più veloce è, e più costoso è.<br />
Esempio<br />
Cache cinque volte più veloce della main memory, e il 90% del tempo di CPU è speso in una<br />
frazione di codice che può interamente essere posto in cache.<br />
Lo Speedup che posso ottenere è:<br />
Questo significa che il sistema complessivamente sarà più veloce di 3,6 volte, cioè delle 360%.<br />
(secondo me del 260%)<br />
La formula che sintetizza il principio di Amdahl e che fa riferimento allo Speedupenhanced e alla<br />
FractionEnhanced ci serve a valutare il rapporto tra il vecchio ExTime e il nuovo ExTime. Laddove<br />
questi ExTime io potessi valutarli attraverso altre grandezze che magari in alcuni casi sono più<br />
facilmente misurabili è ovvio che ricorro ad un altro modo per valutarli.<br />
Cycles per Instruction<br />
A noi interessa vedere qual è il CPU time, cioè il tempo speso dalla CPU per eseguire un<br />
programma. Naturalmente in questo CPU time non è presente la parte eventualmente legata<br />
all’input/output.<br />
Il CPU time lo possiamo esprimere attraverso il seguente prodotto:<br />
10
Il tempo del processore durante il suo lavoro viene scandito da un clock con un periodo pari a Tck.<br />
Se io voglio misurare quanto tempo ho speso per eseguire un programma, ovviamente se conosco<br />
quant'è il periodo di clock, misuro quanti cicli di clock dall'inizio alla fine del programma sono<br />
trascorsi.<br />
CK cycles for a program a sua volta si può esprimere come Ic × CPI, dove Ic sta per Instruction<br />
Count, e CPI è il clock per instruction.<br />
Supponiamo di potere sapere quante istruzioni sono state eseguite, Ic, e conosco il numero di cicli di<br />
clock eseguiti per ogni istruzione, allora il numero di cicli di clock richiesti per un’istruzione<br />
moltiplicati per il numero di istruzioni mi dà il numero totale di cicli di clock del programma, che<br />
moltiplicato per il tempo di clock mi dà il CPUtime:<br />
Il CPI in realtà non è altro che un valore medio, ed è ottenuto come:<br />
Qua si parla di CPI medio. In realtà molto spesso io posso calcolare il CPI attraverso una media<br />
pesata che fa riferimento a categorie diverse di istruzioni: quando viene eseguito un programma ci<br />
saranno istruzioni che implicano l’esecuzione di operazioni logico-aritmetiche (ALU), poi ci<br />
saranno istruzioni di Branch (salto condizionato), poi ci saranno istruzioni di scambio di<br />
informazioni tra la memoria e il processore (Load/Store), ecc…; ammettendo che ogni categoria sia<br />
omogenea dal punto di vista del numero di cicli di clock richiesta per essere eseguita posso<br />
calcolare il CPI attraverso una media pesata:<br />
dove n rappresenta il numero di categorie distinte di istruzioni, ed Fi è la frequenza con cui la<br />
categoria i-esima è presente all’interno del running; la frequenza non è altro che il numero di volte<br />
in cui quella categoria di istruzioni è stata eseguita rispetto al numero di istruzioni totali eseguite:<br />
Ovviamente il CPUtime in questo caso è pari a:<br />
Il problema è stimare Fi, cioè durante un runnig quante volte è stata eseguita una determinata classe<br />
di istruzioni; questo si chiama instruction mix.<br />
È da notare che il CPIi dovrebbe essere misurato e non dedotto da quello che normalmente viene<br />
chiamato CPU technical reference manual, perché questo assume che tutto vada alla velocità del<br />
processore e non considera che alcuni cicli di clock possono essere spesi per degli accessi in<br />
memoria che è più lenta.<br />
Se è vero che il CPUtime è una misura delle prestazioni del nostro sistema ed è esprimibile dal<br />
prodotto di Ic, CPI e Tck, noi possiamo pensare che se vogliamo apportare un miglioramento,<br />
diminuire l’Ic del 30% è la stessa cosa, in termini di guadagno di performance, di fare più veloce il<br />
clock del 30% oppure ridurre del 30% il CPI medio. Allora si potrebbe pensare di investire sulla<br />
cosa che viene più facile migliorare. C’è un problema: questi tre fattori non sono tra di loro<br />
indipendenti, ma cercare di migliorare uno dei tre porta al peggioramento di qualcuno degli altri due<br />
o di entrambi. Quindi come sempre succede nella pratica bisogna trovare un compromesso tra<br />
esigenze molto spesso tra di loro in conflitto.<br />
11
Di seguito mostriamo una tabella che fa vedere da cosa dipendono l’Ic, il CPI e il Clock Rate:<br />
L’Ic dipende dal compilatore perché ogni compilatore lo stesso programma lo può tradurre in<br />
diversi modi; dipende dall’Instruction Set perché per esempio un’istruzione di Branch in alcuni<br />
processori è un’unica istruzione, e ci sono processori in cui il loro set di istruzioni non prevede di<br />
fare sia la verifica della condizione che il salto in un’unica istruzione, ma sono splittate su due<br />
istruzioni diverse.<br />
Il CPI indirettamente dipende dal compilatore perché a seconda di come compilo, e quindi dalla<br />
sequenza di istruzioni che produco, questo può portare a richiedere più cicli di clock per eseguire<br />
un’istruzione; dipende dall’Instruction Set perché se nel mio set di istruzioni includo un’istruzione<br />
che fa un insieme di operazioni è ovvio che ha bisogno di più cicli di clock per essere eseguita;<br />
dipende dall’Organizzazione che è l’organizzazione architetturale che io scelgo per implementare<br />
tutte le attività che deve eseguire il processore.<br />
Il Clock Rate dipende dall’Organizzazione perché più semplice è l’hardware più veloce si può<br />
rendere; ed è ovvio che la Tecnologia incide sulla frequenza di clock.<br />
Si vede che il miglioramento della tecnologia porta solo benefici.<br />
Come si vede se io penso di abbassare il CPI agendo sull’organizzazione bisogna capire cosa<br />
succede al clock rate; per esempio se io trovo una soluzione che mi porta le istruzioni dell’ALU da<br />
1.5 cicli di clock ad 1 ciclo di clock, e però per implementare questa soluzione scopro che<br />
l’hardware si è complicato e quindi la frequenza di clock con cui opero devo abbassarla,<br />
automaticamente ho migliorato il CPI ed ho peggiorato il Clock Rate.<br />
12
30/04/2004<br />
Esempio<br />
Facciamo riferimento ad una macchina base A in cui all’interno dell’instruction set tutte le volte che<br />
dobbiamo implementare un if, cioè un salto condizionato, in realtà per come è fatto l’instruction set<br />
questo richiede l’esecuzione di due istruzioni: COMPARE + BRANCH.<br />
Immaginando di avere un programma che giri su questa macchina, attraverso delle misure sono<br />
state dedotte le seguenti frequenze di esecuzione delle varie classi di istruzioni:<br />
alla fine otteniamo un CPI<br />
medio di 1,2. Significa che<br />
per eseguire quel<br />
programma mediamente<br />
spendiamo 1,2 cicli di<br />
clock per ogni istruzione.<br />
A questo punto un progettista pensa di apportare una modifica: proviamo a modificare l’instruction<br />
set di questo processore in modo tale che l’istruzione COMPARE venga incorporata all’interno<br />
dell’istruzione di BRANCH, cioè in poche parole la fase di valutazione della condizione appartiene<br />
all’istruzione di BRANCH. Per fare questo però l’organizzazione interna del processore,<br />
l’organizzazione hardware, è tale che la frequenza di clock operativa deve modificarsi; in<br />
particolare a seguito di questa modifica bisogna allungare, rispetto alla versione base, il periodo di<br />
clock di 1,25, cioè del 25%. La domanda è: conviene questa modifica?<br />
Supponendo di ignorare il problema legato al costo, cioè quanto costa fare questa modifica, ma ci<br />
concentriamo soltanto sulla performance, noi dobbiamo andare a vedere se il tempo speso per<br />
eseguire lo stesso programma sulla macchina A o sulla macchina B (quella modificata) varia, e<br />
come varia.<br />
Cercando di ricavarsi di nuovo quel tipo di tabella, però per la nuova macchina, adesso dobbiamo<br />
vedere qual è la nuova frequenza di BRANCH, e la frequenza delle rimanenti istruzioni:<br />
Sappiamo che il CPUtime della macchina base è: CPUtimeA = IcA × 1,2 × TckA.<br />
Noi sappiamo che sulla macchina B l’IcB varia rispetto a quello della macchina A perché in<br />
quest’ultima c’erano due istruzioni per ogni BRANCH; questo significa che adesso il numero di<br />
istruzioni si contrae del 20%: IcB = IcA – 20%IcA = 0,8IcA.<br />
La frequenza di BRANCH è data dal numero di occorrenze del BRANCH rispetto all’IcB<br />
complessivo:<br />
Così la tabella che si ottiene è:<br />
quindi il nuovo CPI medio è 1,25.<br />
13
A questo punto il CPUtimeB è:<br />
CPUtimeB = IcB × CPIB × 1,25 × TckA = 0,8IcA × 1,25 × 1,25TckA = 1,25 × IcA × TckA.<br />
Questo significa che il programma viene eseguito più velocemente nella macchina A.<br />
Quando si parla di misure delle performance c'è un indice, che è stato utilizzato moltissimo un po'<br />
di anni fa, tuttora viene ancora utilizzato, ma è caduto in disuso, che è il cosiddetto MIPS: milioni di<br />
istruzioni per secondo. MIPS = instruction count / Time × 10 6 = Clock Rate / CPI × 10 6 .<br />
Se io confronto due CPU è una ha un numero di MIPS maggiore dell'altra allora la prima è più<br />
veloce della seconda. Questa cosa non è detto che sia una cosa vera: è facilmente dimostrabile che<br />
una CPU con un numero di MIPS può portare ad un CPUtime maggiore piuttosto che minore. Se<br />
due CPU hanno un set diverso di istruzioni, lo stesso programma compilato su una macchina<br />
potrebbe presentare un MIPS, quando viene eseguito, maggiore perché per esempio sono istruzioni<br />
semplici quindi maggiori come numero di istruzioni piuttosto che in un'altra macchina dove ci sono<br />
istruzioni più complesse.<br />
I MFLOP/s sono milioni di floating point operation per second.<br />
MFLOP/s = FP Operation / Time × 10 6 . Anche in questo caso vale lo stesso ragionamento fatto<br />
prima.<br />
Esempio<br />
Supponiamo di avere una macchia base di cui sono state ottenute, a fronte dell'esecuzione di un<br />
programma, le seguenti statistiche:<br />
Questa macchina base che tipo di set di istruzioni ha?<br />
Ha un set di istruzioni che si chiamano register/register, oppure si può dire che è una macchina di<br />
tipo Load/Store. Una macchina di tipo Load/Store è una macchina in cui qualsiasi operazione che<br />
coinvolge l'unità logica-aritmetica (ALU) può essere eseguita soltanto se gli operandi stanno<br />
entrambi all'interno del processore, cioè sono nei registri del processore. Questo significa che, per<br />
esempio, quando scriviamo un programma in C e c’è la somma fra due variabili, queste variabili se<br />
quando è stato compilato il programma stanno in memoria, prima di potere eseguire la somma<br />
bisogna prevedere che il valore di queste variabili venga caricato con un’operazione di load<br />
all’interno di registri del processore, e successivamente può essere eseguita la somma; il risultato<br />
della somma presuppone che poi ci sia un’operazione di store, cioè venga scritto in memoria.<br />
Questa è un’architettura load/store. In un’architettura di questo tipo non è possibile eseguire, per<br />
esempio, la somma tra un operando che sta all’interno di un registro del processore e un operando<br />
che sta all’interno della memoria.<br />
Adesso rispetto ad una macchina di tipo load/store supponiamo di voler modificare l’architettura di<br />
questa macchina modificando l’instruction set e aggiungendo una nuova classe di istruzioni di tipo<br />
register/memory ovvero che mi consentono di fare operazioni ALU anche con operandi che stanno<br />
uno in un registro e uno in memoria. Questo tipo di istruzioni richiedono due cicli di clock, a<br />
differenza di una qualunque istruzione ALU che invece richiedeva un ciclo di clock.<br />
14
Il problema è: a fronte dello stesso programma, compilato sulle due macchine, cosa ci guadagno<br />
modificando il set di istruzioni introducendo questo tipo di istruzione? In particolare la domanda è:<br />
quale frazione di load nella macchina base deve essere eliminata perché questa modifica incominci<br />
a dare un guadagno?<br />
Questo significa che, se adesso ho istruzioni di tipo register/memory, tutta una parte di operazioni<br />
che facevo nella macchina base, operazioni che coinvolgevano l’ALU, che richiedevano delle load<br />
verranno eliminate nella nuova macchina perché non è necessario fare delle load esplicite.<br />
In pratica probabilmente riduco l’Ic, e riducendo l’Ic, siccome CPUtime = Ic × CPI × Tck, se non<br />
peggiorano le altre due componenti può darsi che avrò un CPUtime più basso, quindi che la nuova<br />
macchina con questo nuovo set di istruzioni sia più performante della vecchia macchina.<br />
È ovvio che in qualche modo la performance di una macchina dipenderà da quante load<br />
scompaiono; allora in questo caso il nostro obiettivo è valutare qual è la percentuale di load che<br />
deve essere eliminata perché questo tipo di instruction set architecture possa incominciare a fornire<br />
un guadagno rispetto alla macchina base. I dati relativi alla macchina base sono riportati sopra.<br />
Se io metto anche l’istruzione RegMem e chiamiamo X il numero di istruzioni RegMem eseguite<br />
abbiamo che X è il numero di load che si riducono rispetto alla macchina originaria, ma queste<br />
istruzioni di tipo RegMem le utilizzo per fare operazioni di tipo ALU, quindi anche le istruzioni<br />
ALU si riducono di X:<br />
facendo questa<br />
modifica purtroppo<br />
il branch avrà<br />
2 bisogno di tre cicli<br />
di clock.<br />
Calcolando il nuovo CPI otterrei 1.7-X; in realtà X è la frazione di istruzioni espressa però rispetto<br />
al vecchio instruction count. Noi vogliamo calcolare il CPI della nuova macchina, quindi questo<br />
CPI deve essere normalizzato rispetto al nuovo instruction count, ovvero il vecchio instruction<br />
count moltiplicato per 1-X, questo perché ognuna delle nuove frequenze è divisa per 1-X:<br />
F’ALU=N’ALU/I’C=(NALU–NRegMem )/IC(1–X)=NALU/IC(1–X)–NRegMem/IC(1–X)=FALU/(1–X)–X/(1–X).<br />
Vado a trovare il valore di X per cui i due CPUtime sono uguali:<br />
⇒ 1.00 × 1.5 = (1 – X) × (1.7 – X)/(1 – X) (ClockOld = ClockNew)<br />
⇒ 1.5 =1.7 – X ⇒ X = 0.2<br />
X deve essere almeno uguale a 0.2, cioè tutte le load che erano presenti dovrebbero essere<br />
eliminate, affinché la modifica non produca una perdita di performance.<br />
Noi abbiamo considerato il CPUtime immaginando che tutto vada alla velocità della CPU, e quindi<br />
che la CPU non debba aspettare memoria, ecc.<br />
In realtà le cose non stanno così: quando la CPU accede in memoria normalmente deve aspettare.<br />
Abbiamo visto che per mitigare questo problema è stata inventata la memoria cache. Allora tutte le<br />
volte che andando in memoria la CPU trova quello che sta cercando nella cache di fatto non deve<br />
aspettare (immaginando che la cache vada alla stessa velocità del processore); naturalmente questo<br />
non può succedere sempre perché la cache è piccola e quindi difficilmente riuscirà a contenere tutto<br />
quello che serve; questo significa che delle volte ci sarà un miss (mancato successo); in tal caso si<br />
/<br />
15
deve aspettare che il dato che non sta in cache debba essere reperito nel livello di memoria<br />
successivo, main memory, spostato nella cache e quindi il processore può leggere quel dato se si<br />
trattava di un’operazione di lettura. Questo significa che il CPUtime, se lo devo calcolare<br />
correttamente quando c’è una gerarchia di memoria, lo devo esprimere nel seguente modo:<br />
Quindi il tempo di CPU per eseguire un determinato programma sarà pari al numero di cicli della<br />
CPU se tutto andasse bene dilatato di un numero di cicli di stallo, nel senso che il processore deve<br />
bloccare la propria attività aspettando che qualcosa arrivi dalla memoria. Questo come si vede fa sì<br />
che il numero di cicli di clock totale per eseguire quel programma in presenza di una memoria reale<br />
aumenti rispetto al numero di cicli di clock strettamente richiesti dal processore.<br />
Proviamo a esprimere il MemoryStallCycles in qualche modo: questi cicli di clock di stallo si<br />
verificano tutte le volte che andando in memoria si verifica un miss. Se moltiplico il numero di miss<br />
per il miss penalty, ovvero per la penalità che pago per spostare il dato dalla main memory alla<br />
cache espresso in numero di cicli di clock, ottengo il numero totale di cicli di clock di stallo. Se io<br />
voglio mettere in evidenza l’instruction count, il numero di miss non è altro che una frazione di Ic,<br />
ovvero il numero di miss per instruction. Posso definire una nuova grandezza: il cosiddetto miss<br />
rate. Il miss rate non è altro che la frazione di miss che sperimento rispetto al numero totale di<br />
accessi in memoria: se vado 100 volte in memoria (cache) e 15 volte su queste 100 volte c’è un<br />
miss allora il miss rate è il 15%. Allora possiamo scrivere:<br />
dove mem.ref.per.instr. è il numero di riferimenti medio per istruzione, cioè per ogni istruzione<br />
quanti riferimenti in memoria si fanno.<br />
Esempio<br />
Supponiamo di avere una macchina A e supponiamo di avere un programma in cui ci sono il 40% di<br />
istruzioni load/store, un CPI medio pari a 2, in cui però ci siano tutti cache hits (tutti gli accessi in<br />
memoria hanno successo). Questa macchina la voglio confrontare con una macchina B che ha il 2%<br />
di miss rate, cioè il 2% delle volte che vado in cache non trovo quello che voglio; tutte le volte che<br />
succede questo il miss penalty è di 25 cicli di clock.<br />
Nel caso della macchina A abbiamo:<br />
Per quanto riguarda la macchina B abbiamo:<br />
Il mem.ref.per.instr. sarà 1 perché tutte le istruzioni eseguite richiedono un accesso in memoria, e<br />
poi ci sono il 40% delle istruzioni che sono di tipo load/store che richiedono due accessi: uno per<br />
leggere l’istruzione e un altro per eseguire o la load o la store, quindi il numero di riferimenti medi è<br />
1+0,4.<br />
Così il CPUtime è:<br />
Se facciamo il rapporto otteniamo:<br />
Così abbiamo un degrado di performance del 35%.<br />
,<br />
16
Abbiamo parlato di approcci quantitativi alla progettazione basati su misure per vedere quanto una<br />
certa alternativa piuttosto che un’altra è utilizzata, e abbiamo visto come valutare.<br />
Siccome parliamo di computer, cos’è che ci consente di valutare le prestazioni?<br />
Fare girare dei programmi e vedere quanto tempo impiega il computer per eseguirlo.<br />
Se ci mettiamo nella prospettiva in cui normalmente si mettono i produttori di computer si capisce<br />
che è auspicabile che il proprio prodotto è migliore di quello che produce qualcun altro. Solo che<br />
dire “migliore” non è facile.<br />
Incominciamo da un punto di vista logico a definire cosa ci consentirebbe di dire se un computer è<br />
migliore oppure no. Il produttore per dire che un computer è meglio di un altro dovrebbe dimostrare<br />
che per eseguire certi programmi il suo computer impiega meno tempo di un altro; però non si sa a<br />
quali programmi fare riferimento, perché non si sa ogni utente quali programmi usa.<br />
Il primo problema quindi è: quali programmi usare per valutare le prestazioni? E per quali tipologie<br />
di utenti?<br />
Qual è la condizione ideale impossibile da realizzare?<br />
La condizione è quella di utilizzare un workload reale, quindi fatto da programmi reali, che non è<br />
altro che l’insieme di applicazioni e di comandi di sistema operativo che vengono dati durante<br />
l’utilizzo normale da parte di quell’utente. Questo perché gli utenti sono tanti e ognuno ha esigenze<br />
abbastanza diverse.<br />
La soluzione che è stata individuata già da un po’ di anni è quella di utilizzare le cosiddette<br />
benchmark suites, cioè delle collezioni di programmi che in qualche modo siano rappresentativi<br />
dei diversi scenari di utilizzo dei computer.<br />
Che tipo di programmi costituiscono una benchmark suite? Ci sono varie tipologie di programmi.<br />
• Toy benchmarks, sono dei software semplicissimi, 10-100 linee di programma, fatti per<br />
stimolare certi parti del sistema: sieve, puzzle, quicksort.<br />
• Synthetic benchmark, che non sono dei programmi reali, cioè che non risolvono nessun<br />
problema reale: whetstone, dhrystone.<br />
• Kernels, che sono dei pezzi di programmi reali, tipicamente per esempio pezzi di programmi di<br />
un sistema operativo o kernel di qualche applicazione particolare: livermore loops.<br />
• Programmi reali: gcc, spice, ecc.<br />
Dopo aver litigato per tanti anni alla fine i costruttori sempre cercano di trovare un accordo, e in<br />
genere lo scenario in cui si cerca di sintetizzare queste liti e questo accordo è quello degli organismi<br />
di standardizzazione internazionali. A livello di standardizzazione è stato proposto il cosiddetto<br />
SPEC (Standard Performance Evaluation Corporation), che è riconosciuto da tutti i costruttori e che<br />
specifica quali sono i programmi che bisogna utilizzare per valutare le prestazioni di una macchina.<br />
Considerando il tipo di differenziazione del mercato nel settore dei computer (desktop, server ed<br />
embedded) SPEC ha cercato di differenziare le suites per valutare le prestazioni dei vari settori:<br />
CPU intensive significa che stimolano prevalentemente la CPU, quindi valutano le prestazioni<br />
prevalentemente del processore. I Graphic intensive che cercano di valutare le prestazioni dal punto<br />
di vista della grafica. Gli SPEC FS (spec filesystem) sono basati sulla valutazione del numero di<br />
transazioni per secondo che è in grado di eseguire un server.<br />
17
Tipicamente un benchmark esce ogni 3 anni.<br />
SPEC CPU2000<br />
Naturalmente c’è un ampio settore di mercato, che è il settore di mercato più promettente, che è<br />
quello dei PC, per cui sono nati anche i benchmark per PC:<br />
• Business Winstone: è uno script che lancia Netscape e diversi prodotti di Office per cercare di<br />
simulare un workload reale di un tipico pc user;<br />
• CC Winstone: simula un ambiente di applicazioni per la creazione di contenuti multimediali<br />
(Photoshop, Premiere, Navigator, ecc.);<br />
• Winbench: insieme di kernel per il test di CPU, sistema video, dischi.<br />
Per quanto riguarda i sistemi embedded è nato il consorzio EEMBC che ha creato la suite chiamata<br />
EDN che include: automotive industrial, consumer, networking, office automation,<br />
elecommunication.<br />
Si fanno molti giochi con i benchmark:<br />
• ottenere dei risultati migliori su una macchina rispetto ad un’altra facendo girare lo stesso<br />
benchmark suite sui due sistemi senza dire come sono equipaggiati;<br />
• ottenere performance migliori ottimizzando dei compilatori per determinati programmi;<br />
18
• workload utilizzati in modo arbitrario: quando per esempio ho una suite di benchmark con i<br />
programmi A, B, C, D, e il programma A è quello più veloce allora quando faccio girare questa<br />
suite di benchmark, se non ho delle costrizioni particolari, potrei fare girare molte volte il<br />
programma A e poche volte gli altri programmi; quindi prevale la performance del programma<br />
A.<br />
19
01/04/2004<br />
Abbiamo detto che proprio perché è abbastanza complicato individuare un workload che sia<br />
rappresentativo per ogni utente sono nati dei benchmark suites. Un benchmark suite abbiamo detto<br />
che è costituito da un insieme di programmi molto diversi tra di loro, quindi si capisce che non è<br />
facile stabilire qual è il giusto mixing di questi programmi per valutare le prestazioni.<br />
Allora c’è il problema di cercare di stabilire quando si fa girare un benchmark che tipo di rapporto<br />
di prestazioni devo andare ad ottenere.<br />
Una delle cose che molto raramente avviene nel campo dei computer è quello di rispettare il<br />
cosiddetto principio di riproducibilità: includere tutto ciò che consente ad altri di replicare gli<br />
esperimenti fatti.<br />
Nel caso degli SPEC benchmark un report richiede:<br />
- una descrizione quasi completa della macchina (configurazione hardware e software);<br />
- flag di compilazione: quando si usa un programma come gcc per compilare, per esempio, è<br />
necessario settare dei flag in modo tale che tutti devono utilizzare quei flag per compilare;<br />
- pubblicazione dei risultati sia delle performance di base (baseline) sia quelle ottimizzate.<br />
Nella performance baseline viene imposto di utilizzare un particolare tipo di compilatore e un set<br />
di flag da utilizzare nella compilazione per tutti i programmi nello stesso linguaggio.<br />
Per quanto riguarda la performance di picco (peak performance) c’è una maggiore libertà in modo<br />
da potere fare un tuning delle prestazioni attraverso, per esempio, compilatori proprietari o flag<br />
specifici, cioè che non sono imposti.<br />
Esempio di baseline performance<br />
Per quanto riguarda l’affidabilità dei benchmark come predittori della performance reale riportiamo<br />
un esempio:<br />
c’è un programma che si chiama matrix300 (SPEC 89), un software che fa il prodotto tra matrici,<br />
che spende il 99% del tempo di esecuzione su una linea di codice. ottimizzando il loop più interno<br />
attraverso un compilatore per una IBM PowerStation 550 si ottiene un miglioramento di un fattore 9<br />
20
nella performance. In questo modo però non sto testando la macchina ma sto semplicemente<br />
testando la performance del compilatore.<br />
Andiamo ora a capire come si possono misurare le prestazioni a fronte dell’esecuzione di alcuni<br />
programmi.<br />
Quando faccio girare un programma posso dire che la performance è il tempo di esecuzione del<br />
programma; quando mi pongo il problema di trovare un indice globale di prestazione per la mia<br />
macchina è ovvio che non mi conviene dire che la mia macchina per fare girare, per esempio, il gcc<br />
piuttosto che un’altra applicazione impiega tot tempo; poi se quella applicazione non è<br />
rappresentativa per l’utente questo di per sé non è un’informazione che è appetibile per il mercato.<br />
Quindi bisognerebbe tirare fuori un indice di performance globale ricavato dal running di una suite<br />
di benchmark, cioè di programmi abbastanza rappresentativi. Ma qual è quest’indice globale?<br />
Vediamo quali si potrebbero utilizzare, e sulla base di questi eventuali indici globali cercare di<br />
capire se è possibile rispondere ad una domanda: quest’indice globale di performance mi consente<br />
di dire che una macchina è più veloce di un’altra?<br />
Esempio<br />
Abbiamo tre computer e supponiamo di avere una suite di benchmark fatta da due programmi: P1 e<br />
P2. Facendo girare questi due programmi sui tre computer impiego i secondi indicati nella seguente<br />
tabella:<br />
A questo punto bisognerebbe cercare di capire qual è l’indice globale di performance utile ai fini di<br />
dire quale delle tre macchine è più veloce.<br />
Ovviamente per il programma P1 la macchina più veloce è A, e a sua volta B è più veloce di C; per<br />
il programma P2 la macchina più veloce è C, e B è più veloce di A. Quindi non c’è una tendenza<br />
che mi porta a dire che una macchina è più veloce delle altre.<br />
Una misura più consistente è quella, per esempio, di considerare il total execution time. Se io vado a<br />
considerare questo indice trovo i tempi indicati nella tabella sopra. Questo mi porterebbe a dire che<br />
il computer C è 2,75 volte più veloce del computer B e 25 volte del computer A; e il computer B è<br />
9,1 volte più veloce del computer A.<br />
Quindi in questo caso il tempo di esecuzione totale è una misura consistente e ci consente di<br />
affermare quello detto sopra; però questa cosa è vera solo se io faccio girare su queste tre macchine<br />
i programmi P1 e P2 lo stesso numero di volte.<br />
Il problema è che non è detto che io faccia girare lo stesso numero di volte P1 e P2.<br />
Se il numero di running di ogni singolo programma costituente la benchmark allora il total<br />
execution time oppure la media dei tempi di esecuzione sono abbastanza rappresentativi delle<br />
performance.<br />
Nel caso in cui il numero di running di P1 è diverso dal numero di running di P2 si può ricorrere a<br />
due soluzioni:<br />
1) media aritmetica pesata<br />
2) media geometrica.<br />
La media aritmetica pesata è uguale a: , dove Ti è il tempo di esecuzione del programma<br />
i-esimo all’interno del benchmark.<br />
21
Se io ho ni che è il numero di running di Pi nel workload e ∑i ni = n, il peso o la frequenza relativa<br />
del programma i-esimo non è altro che wi = ni / n.<br />
Vediamo alcuni esempi relativamente alle macchine A, B e C:<br />
La pesatura w(1) fa si che pesa nello stesso modo i due programmi: così otteniamo quello che<br />
avevamo ottenuto prima, cioè che il computer C è più veloce di B, e B è più veloce di A, e se si<br />
fanno i rapporti si ottengono gli stessi valori di prima.<br />
Nella pesatura w(2) fisso i pesi in modo tale che siano inversamente proporzionali ai tempi di<br />
esecuzione dei programmi P1 e P2 sul computer B, cioè faccio girare più volte il programma che<br />
richiede meno tempo. In questo modo ottengo che il computer B è più veloce di A e di C, e C è più<br />
veloce di A.<br />
Con la pesatura w(3) fisso i pesi in modo inversamente proporzionale al tempo di esecuzione di P1<br />
e P2 sulla macchina A. In questo modo ottengo che il computer A è più veloce di B e C, e B è più<br />
veloce di C.<br />
Sempre parlando di indici di prestazione globale quando il numero di running dei vari programmi è<br />
diverso piuttosto che la media aritmetica pesata un altro tipo di media che si potrebbe utilizzare è<br />
quella geometrica. In particolare si considera normalmente la media geometrica dei tempi di<br />
esecuzione normalizzati: ho una suite di benchmark e voglio misurare le prestazioni sulla macchina<br />
A, allora devo fare girare il programma sulla macchina A e ottengo un tempo di esecuzione che<br />
devo normalizzare rispetto al tempo di esecuzione dello stesso programma su una macchina<br />
campione (per esempio come macchina campione viene utilizzata per la SPEC una SPARCstation).<br />
In questo caso la media geometrica dei tempi normalizzati è:<br />
Si potrebbe erroneamente pensare che si possa predire la performance di un programma sulla mia<br />
macchina moltiplicando π per la performance del programma sulla macchina campione, essendo<br />
noti sia il primo che la seconda.<br />
Un’altra cosa da notare è che quando si utilizzano i tempi di esecuzione normalizzati e si utilizza la<br />
media aritmetica di questi ultimi si può arrivare a dei paradossi. Per esempio: supponiamo di avere<br />
al solito i computer A, B e C, e i due programmi P1 e P2; normalizzando i tempi di esecuzione<br />
22
considerando le varie macchine come macchina campione si ottengono i valori riportati in tabella.<br />
Se io considero la media aritmetica dei tempi normalizzati o rispetto ad A, B o C, questa fornisce<br />
delle misure assolutamente inconsistenti, nel senso che nel primo caso viene fuori che A è il<br />
computer più veloce, nel secondo caso è B il più veloce, è nel terzo caso e C il più veloce; quindi il<br />
computer più veloce è quello rispetto a cui normalizzo. Quindi non bisogna mai considerare la<br />
media aritmetica dei tempi di esecuzione normalizzati, ma considerare la media geometrica. Infatti<br />
la media geometrica è consistente: indipendentemente dalla macchina campione otteniamo sempre<br />
misure consistenti, in questo caso C è sempre il computer più veloce, e anche i rapporti sono sempre<br />
uguali.<br />
Quindi la media geometrica dei tempi di esecuzione normalizzati è consistente indipendentemente<br />
dalla macchina di riferimento, e non dipende dal numero di running dei programmi individuali.<br />
Uno dei problemi con la media geometrica è che non consente di predire il tempo di esecuzione. Un<br />
altro problema è che quando si considerano tre o più macchine non esiste nessun workload che sia<br />
compatibile con la performance predetta dalla media geometrica. Questo significa che in qualche<br />
modo si vanifica la ragione per cui questa media è stata introdotta.<br />
Un altro problema con la media geometrica è: se per esempio io voglio fare un’ottimizzazione,<br />
ovvero voglio migliorare sulla mia macchina le prestazioni e ho due possibilità, per esempio passare<br />
da 2s a 1s per un programma piuttosto che da 1000s a 500s per un altro programma, se io considero<br />
la media geometrica il miglioramento che io vado a valutare è identico, cioè dire dato lo stesso peso<br />
ai due abbattimenti dei tempi di esecuzione. Quindi se io mi metto nei panni di quello che vuole<br />
truccare le carte e volessi ottenere quello stesso miglioramento di performance globale valutato<br />
attraverso la media geometrica, supponendo che voglio dimezzare il tempo di esecuzione, fra tutti i<br />
programmi vado a scegliere quello su cui è più facile farlo.<br />
Cosa bisogna fare per cercare di dare delle informazioni consistenti e corrette? Bisogna misurare un<br />
workload reale e pesare i programmi con nelle loro frequenze di esecuzione reali.<br />
Quando si dà come misura delle prestazioni un indice globale, questo tende a nascondere delle<br />
informazioni importanti, e in alcuni casi potrebbe non essere il migliore indicatore della<br />
performance per un'applicazione d'utente. Per cui assieme all'indice globale sarebbe bene fornire<br />
anche i risultati (tempo di esecuzione, frequenza con cui è stato fatto girare un programma del<br />
benchmark, ecc…) dei singoli benchmark costituenti il workload.<br />
Sistema di elaborazione<br />
Un sistema di elaborazione per noi non è altro che costituito da tre entità:<br />
statica<br />
In particolare un sistema di elaborazione lo possiamo definire come una macchina in grado di<br />
eseguire programmi espressi in un determinato linguaggio di programmazione.<br />
23
La macchina è un'entità attiva, dinamica (che evolve nel tempo), mentre il programma è una entità<br />
statica. Durante l'esecuzione di un programma questo rimane quello che è, mentre la macchina,<br />
rappresentata da tastiera, monitor e dall'insieme di variabili (che dobbiamo considerare appartenenti<br />
alla macchina) viene modificata (ad esempio il valore delle variabili viene modificato).<br />
Nel nostro modello noi assumiamo normalmente che un'istruzione costituisce una azione atomica<br />
per il nostro sistema, cioè significa che se noi facciamo riferimento allo stato della nostra macchina<br />
(insieme di variabili, e in generale tutto ciò che ha all'interno della macchina memorizza<br />
informazioni) l’istruzione ci fa passare da uno stato all'altro; quindi significa che eseguire un<br />
programma equivale a fare compiere alla nostra macchina una traiettoria di stati all'interno dello<br />
spazio dei possibili stati che la macchina può assumere.<br />
Quello a cui siamo stati abituati a vedere come modello di un sistema di elaborazione è quello che<br />
viene chiamato modello funzionale: il modello che descrive la macchina come un puro esecutore<br />
del proprio linguaggio. Da questo punto di vista tutte le macchine Pascal, oppure C, ecc…, sono<br />
funzionalmente identiche.<br />
Il modello realizzativo di un sistema di elaborazione fa riferimento a come quest’ultimo è fatto,<br />
cioè che tipo di componenti fisici ci sono, come sono collegati tra di loro, ecc.<br />
Questo significa che due macchine che hanno lo stesso modello funzionale non è affatto detto che<br />
abbiano lo stesso modello realizzativo:<br />
Parlando del modello funzionale possiamo dire che la traiettoria di stato che viene percorsa dalla<br />
nostra macchina è di tipo deterministica, cioè è predicibile sapere quali sono tutti gli stati che<br />
attraverserà la nostra macchina se noi conosciamo tre elementi: programma in esecuzione, i dati che<br />
forniamo al nostro programma e lo stato iniziale. Questa affermazione assume un’importanza<br />
notevole perché non è detto che sia così.<br />
Da un punto di vista schematico quello che abbiamo detto sul modello funzionale è rappresentabile<br />
nel seguente modo:<br />
Esempio<br />
dove M = macchina, L = linguaggio, P = programma.<br />
In generale in realtà un sistema di elaborazione è costituito da una gerarchia di macchine, non da<br />
una singola macchina. Questa gerarchia di macchine è organizzata attraverso il seguente principio:<br />
se io mi metto ad un certo livello di questa gerarchia di macchine posso salire di livello, e realizzo<br />
una macchina che sta ad un livello superiore a partire dalla macchina del livello immediatamente<br />
inferiore. Questa affermazione che sembra banale è quella che è stata uno dei motivi della<br />
rivoluzione nel campo dell’informatica, o quantomeno che ha consentito di estendere l’uso dei<br />
calcolatori ad una quantità di utenti maggiore.<br />
24
Realizzo una macchina sopra un’altra macchina a partire o da un compilatore (traduttore) o da un<br />
interprete. (Il compilatore traduce il nostro codice in un altro linguaggio, l’interprete legge il codice<br />
lo interpreta e lo esegue). Il compilatore è più efficiente perché questo traduce il codice una sola<br />
volta, mentre l’interprete ogni volta che si deve far girare il programma interpreta il codice.<br />
In che senso realizzo una macchina sopra un’altra macchina?<br />
Supponiamo di avere una macchina M1 caratterizzata da un proprio<br />
linguaggio L1; su questa macchina posso realizzare una macchina M2,<br />
che gerarchicamente è superiore ad essa, con un linguaggio L2<br />
semplicemente costruendo un programma P12(L1) espresso nel<br />
linguaggio L1, e questo programma non è altro che o un compilatore o<br />
un interprete. Ovviamente il programma che può girare sulla macchina<br />
M2 sarà scritto nel linguaggio L2: P(L2).<br />
Il senso di realizzare una gerarchia di macchine è quello di fare sì che<br />
la macchina sia più facilmente utilizzabile.<br />
Naturalmente se salire di livello significa rendere più facile l’utilizzo<br />
all’uomo, questo allo stesso tempo può penalizzare le prestazioni.<br />
Adesso scendiamo di livello e arriviamo nell’ambito della gerarchia di macchine a quella che viene<br />
chiamata macchina processo. La macchina processo è quella macchina che esegue i programmi<br />
che tipicamente producono i compilatori. Il linguaggio della macchina processo è un linguaggio di<br />
tipo binario. Una caratteristica della macchina processo è che si incomincia a perdere quella che<br />
viene chiamata identità funzionale tra le varie macchine: noi abbiamo detto che tutte le macchine C,<br />
per esempio, sono funzionalmente identiche, mentre la stessa cosa non vale più per le macchine<br />
processo, cioè un programma espresso nel linguaggio di una macchina processo non può girare su<br />
un’altra macchina processo; questo avviene perché la macchina processo è quel livello all’interno<br />
della gerarchia al di sotto del quale non è più possibile nascondere i dettagli realizzativi della<br />
macchina, cioè le differenze reali tra le varie macchine. Questo significa che ogni macchina<br />
processo ha un proprio linguaggio binario, che dipende dal sistema di elaborazione. Sebbene questo<br />
sia vero tutte le macchine processo sono caratterizzate da un insieme di elementi che le rendono<br />
simili. Questi elementi sono:<br />
• sono dotate di una memoria di processo, che sostanzialmente è uguale un po’ per tutte;<br />
• richiedono che il programma, che poi verrà eseguito dalla stessa macchina processo, debba<br />
risiedere nella memoria di processo;<br />
• sono caratterizzate dal fatto che utilizzano per eseguire i programmi un registro che si chiama<br />
Program Counter;<br />
• sono dotate di un meccanismo di esecuzione delle istruzioni del programma che è analogo;<br />
• stato del processo: contenuto di memoria + contenuto dei registri.<br />
La memoria di processo su per giù è la seguente:<br />
25
La memoria non è altro che un sistema che è in grado di memorizzare informazioni espresse in<br />
formato binario. Se il suo scopo è quello di memorizzare informazioni significa che è un sistema<br />
che per essere usato mi deve offrire dei servizi; questi servizi mi devono consentire di memorizzare<br />
informazioni, ma se memorizzo informazioni lo faccio perché poi voglio andare a reperirle. Questo<br />
sistema è organizzato come un insieme di locazioni (ognuna è una riga), e ciascuna locazione (o<br />
cella di memoria, o parola di memoria) è in grado di memorizzare un certo insieme di bit. Una<br />
caratteristica del sistema memoria è che tutte le locazioni di memoria costituenti il sistema hanno la<br />
stessa dimensione in bit, nel nostro caso k bit (k=1, 8 ,16, 32, 64).<br />
Per utilizzare i servizi che vengono offerti dal sistema memoria è necessario specificare alcune<br />
cose. Quando voglio andare a memorizzare un informazione, poiché questo sistema ha N diverse<br />
locazioni, devo specificare al sistema dove voglio che l’informazione venga memorizzata; questo lo<br />
specifico attraverso un indirizzo, utilizzando la porta degli indirizzi che il sistema memoria mette a<br />
disposizione. Inoltre se si vuole depositare una specifica informazione, questa la si dà al sistema<br />
memoria attraverso la porta dei dati.<br />
La capacità di memoria esprime la quantità di informazioni in bit che è memorizzabile in essa<br />
(1Mbyte = 2 20 byte, ovvero 2 20 word di un byte).<br />
Quando avviene la scrittura di una particolare locazione, questa fa sì che il contenuto precedente<br />
scompaia, cioè si altera il contenuto informativo di quella locazione. La lettura, viceversa, mi<br />
consente di accedere ad una locazione ottenere l’informazione che c'è all'interno di quella locazione<br />
mantenendo nella stessa locazione la stessa informazione; quindi significa che la lettura non altera<br />
l’informazione contenuta all'interno di una locazione di memoria.<br />
In scrittura:<br />
• sulla porta degli indirizzi devo fornire l'indirizzo, ovvero la posizione su cui memorizzare la<br />
parola;<br />
• sulla porta dei dati devo fornire l'informazione da scrivere.<br />
A questo punto la memoria prende quello che c'è sulla porta dei dati è lo va a memorizzare<br />
all'interno della locazione selezionata dall'indirizzo presente sulla porta degli indirizzi:<br />
In lettura:<br />
• sulla porta degli indirizzi devo specificare l'indirizzo della locazione da leggere;<br />
• sulla porta dei dati si ottiene la parola memorizzata in quell'indirizzo.<br />
L’indirizzo deve specificare in modo univoco ogni singola locazione di memoria. Ad esempio se<br />
ho una memoria da 1 Kbyte (2 10 byte) occorrono 10 bit (log2 2 10 = 10) per specificare un indirizzo.<br />
26
Come fa il sistema memoria sulla base di quei 10 bit a dire a quale locazione si fa riferimento? Non<br />
fa altro che usare un decodificatore, che è un circuito combinatorio che riceve un ingresso, in questo<br />
caso di 10 bit, e fornisce un’uscita, in questo caso 1024. Facciamo un esempio con un decodificare<br />
binario a 3 bit:<br />
bit più significativo<br />
0<br />
0<br />
1<br />
DEC<br />
bit meno significativo<br />
0<br />
1<br />
2<br />
3<br />
4<br />
5<br />
6<br />
7<br />
Della macchina processo la parte che esegue i programmi è l’unità centrale di processamento<br />
(CPU). Essa non è altro che l’esecutore di cui si serve la macchina processo per eseguire i<br />
programmi che stanno nella memoria di processo; nello svolgere questo ruolo di esecutore coordina<br />
anche tutti i vari blocchi che costituiscono la nostra macchina.<br />
Questa CPU è caratterizzata da un proprio set di istruzioni, ovvero dall’insieme di istruzioni che<br />
essa è in grado di eseguire. Ognuna di queste istruzioni è codificata in binario, e ovviamente questa<br />
codifica binaria deve essere riconoscibile da quella particolare CPU. Questo ci fa capire perché<br />
macchine processo diverse hanno linguaggi binari diversi. Ovviamente un programma può essere<br />
eseguito dalla CPU se è costituito da istruzioni appartenenti al set di istruzioni della CPU, e inoltre<br />
se tutte le istruzioni che costituiscono il programma sono codificate in quel linguaggio binario e<br />
memorizzate sequenzialmente nella memoria centrale. Quindi un programma eseguibile dalla<br />
macchina processo lo possiamo immaginare fatto così:<br />
Il modo stesso di andare a memorizzare il programma in memoria<br />
implicitamente per l’esecutore contiene l’informazione di quale è<br />
l’ordine di esecuzione delle istruzioni.<br />
Formato delle istruzioni<br />
Abbiamo detto che è codificata in binario; questo significa che ogni istruzione del set di istruzioni<br />
di una determinata CPU è costituita da una stringa di 1 e 0 con una certa lunghezza. Tutte le<br />
macchine processo, per quanto ognuna ha un linguaggio binario diverso e tecniche di codifica<br />
diverse, si assomigliano su degli elementi comuni, ovvero tutte utilizzano una tecnica di codifica<br />
che consente di individuare sempre due campi all’interno dell’istruzione codificata: un campo che si<br />
chiama codice operativo e un campo che si chiama operandi<br />
codice operativo operandi<br />
27
La prima parte dell’istruzione (codice operativo) specifica all’esecutore di che tipo di istruzione si<br />
tratta, cioè caratterizza l’istruzione; gli operandi specificano gli oggetti su cui quell’operazione deve<br />
essere eseguita. Gli operandi o rappresentano i dati stessi o rappresentano il modo di riferimento ai<br />
dati su cui fare l’operazione; per esempio se un dato sta in memoria e l’altro sta in un registro il<br />
campo operandi dell’istruzione conterrà l’indirizzo del dato che sta in memoria e l’indirizzo del<br />
registro, ovvero il nome del registro (qualcosa che individui il registro su cui sta il dato su cui fare<br />
l’operazione). Il codice operativo per ogni istruzione dello stesso tipo (per esempio somma) non è<br />
sempre lo stesso perché deve specificare sì il tipo di istruzione, ma specifica anche come<br />
interpretare il campo operandi.<br />
La CPU normalmente è costituita da due componenti: unità di controllo e unità logico-aritmentica<br />
(ALU). L’unità di controllo non fa altro che essere la parte attiva della CPU e a tutti gli effetti è la<br />
parte “intelligente” dell’esecutore: legge l’istruzione, la interpreta, la esegue, decide quale sarà la<br />
prossima istruzione da eseguire, ecc.<br />
L’unità logico-aritmentica è una sorta di “schiavetto” asservito all’unità di controllo, cioè<br />
quest’ultima a fronte dell’istruzione che sta eseguendo decide cosa farle fare.<br />
All’interno di questa CPU ci sono un insieme di registri, che servono per memorizzare le<br />
informazioni; ci sono in particolare due registri che hanno un ruolo particolare: Program Counter e<br />
Instruction Register. Questi registri sono presenti all’interno di qualsiasi CPU per quanto diverse<br />
queste siano. Il PC contiene l’indirizzo della prossima istruzione da eseguire; l’IR è un registro che<br />
viene utilizzato dall’unità di controllo ogni qualvolta quest’ultima si accinge ad eseguire una nuova<br />
istruzione. L’unità di controllo legge l’istruzione dalla memoria e la deposita nell’IR.<br />
L’unità centrale e l’ALU cooperano per eseguire istruzioni; normalmente cooperano e utilizzano la<br />
memoria in un processo che possiamo distinguere in quattro fasi che porta al completamento di un<br />
ciclo macchina. Un ciclo macchina racchiude un insieme di attività che sono caratteristiche durante<br />
il processo di esecuzione dell’istruzione.<br />
Questo ciclo macchina è fatto da quattro fasi:<br />
1) la prima fase è quella in cui l’unità di controllo va a prelevare dalla memoria la prossima<br />
istruzione da eseguire; questa istruzione letta dalla memoria viene all’interno dell’unità di<br />
controllo depositata nel registro IR;<br />
2) poi avviene la decodifica dell’istruzione;<br />
3) la fase 3 è quella dell’esecuzione, dove per esempio se ci sono da fare dei conti vado ad usare la<br />
parte di ALU coinvolta per l’esecuzione di quell’istruzione;<br />
4) la fase 4 è quella di memorizzazione dei risultati, ovviamente laddove ci siano dei risultati da<br />
memorizzare.<br />
28
02/04/2004<br />
Ritorniamo al meccanismo di esecuzione e diamo qualche dettaglio in più: supponiamo che la<br />
seguente sia la nostra memoria di processo e all’interno di questa a partire da questa locazione sia<br />
memorizzato un programma che deve essere<br />
PC<br />
}<br />
} 1a<br />
2 a<br />
}<br />
3 a<br />
eseguito e supponiamo che ogni istruzione<br />
codificata in linguaggio binario di quella<br />
macchina processo in lunghezza coincida<br />
con la dimensione di una locazione di<br />
memoria. Vediamo di capire cosa avviene<br />
durante l’esecuzione. Abbiamo detto che<br />
l’unità di controllo utilizza il PC per<br />
stabilire da quale locazione di memoria<br />
andare a leggere la prossima istruzione.<br />
Questo significa che durante il ciclo<br />
macchina di esecuzione di un istruzione ci<br />
deve essere un’attività specifica che va ad aggiornare il PC. Quando viene fatto questo? Quando c’è<br />
la fase di lettura dell’istruzione e di caricamento all’interno dell’IR la CPU sa che la prossima<br />
istruzione da eseguire starà all’indirizzo successivo perché si assume che la successione in memoria<br />
delle istruzioni coincida con l’ordine di esecuzione del programma stesso; per cui se ho letto<br />
quell’indirizzo la prossima istruzione la andrò a leggere al prossimo indirizzo. Quindi tra la fase di<br />
lettura dell’istruzione e caricamento all’interno dell’IR e la fase di decodifica avviene sempre<br />
l’aggiornamento del PC: incremento di 1 del PC. Questo è vero solo se io vado sempre in sequenza,<br />
però noi sappiamo che non sempre avviene questo all’interno di un programma perché ogni tanto ci<br />
può essere qualche diramazione (branch). Come può funzionare il fatto intanto il PC si incrementa<br />
di 1 e poi magari non devo andare a leggere l’istruzione successiva, ma devo andare a un certo<br />
numero di locazioni dopo? Tutto questo è compatibile perché tutto sommato non conviene fare delle<br />
eccezioni, cioè se io ho già l’hardware implementato che ogni volta che leggo un’istruzione<br />
incrementa il PC non devo preoccuparmi di non farlo quando si verifica che l’istruzione appena<br />
letta per esempio è un branch, perché questo significa fare delle aggiunte che spesso complicano la<br />
parte realizzativa. La CPU continua a comportarsi sempre nello stesso modo, cioè incrementa il PC;<br />
però abbiamo detto che questo avviene tra la fase di lettura e quella di decodifica, poi c’è la fase di<br />
esecuzione dell’istruzione, ma nel caso in cui l’istruzione è un’istruzione di branch la fase di<br />
esecuzione è quella di testare una condizione, e se questa è vera allora devo eseguire il salto, ma<br />
eseguire il salto vuol dire andare a caricare nel PC il valore dell’indirizzo target di salto.<br />
Le cose funzionano così in tutte le macchine processo.<br />
Non necessariamente dobbiamo fare l’assunzione che l’istruzione occupi un’unica locazione di<br />
memoria; ci sono casi, ed è tipico delle architetture CISC, in cui l’istruzione non ha una lunghezza<br />
fissa: ci può essere un’istruzione che per essere codificata richiede 32 bit e un’istruzione che<br />
richiede 64 bit per esempio. Quindi immaginando che ognuna delle locazioni della memoria<br />
disegnata sopra sia di 32 bit, si può avere che la prima istruzione richieda 3 locazioni di memoria<br />
(96 bit), la seconda richieda 2 locazioni e la terza 1 locazione, ecc. In questo caso sembrerebbe che<br />
ci sia una difficoltà aggiuntiva, ovvero il PC non si deve incrementare sempre della stessa quantità<br />
per passare all’istruzione successiva in memoria. Questo come si gestisce? L’aggiornamento del PC<br />
avviene sempre nella fase di decodifica dell’istruzione; questo perché quando ho letto l’istruzione,<br />
l’ho depositata nell’IR e a partire da questo l’ho decodificata, e averla decodificata significa averla<br />
identificata, cioè ho capito che istruzione è, e quindi so anche quanto è lunga questa istruzione. Se il<br />
codice operativo è più lungo di una parola, nella prima parola deve essere contenuta l’informazione<br />
di quanto è lunga l’istruzione e quante altre locazioni si devono leggere per avere a disposizione<br />
l’intero codice operativo.<br />
29
Abbiamo visto che il linguaggio della macchina processo è un linguaggio binario; si capisce che per<br />
chi deve fare programmi nel linguaggio della macchina processo questa è una cosa scocciante.<br />
Proprio per questa ragione e per superare questa difficoltà c’è uno strato che sta immediatamente<br />
prima della macchina processo, e che quindi realizza una macchina sopra la macchina processo, che<br />
si chiama macchina assembler.<br />
La macchina assembler sostanzialmente mantiene quasi tutte le caratteristiche della macchina<br />
processo, nel senso che macchine assembler di modelli realizzativi diversi sono diverse, però<br />
rispetto alla macchina processo offre una maggiore facilità di programmazione. Questa facilità<br />
deriva dal fatto che tutte le istruzioni previste nella macchina processo vengono codificate nella<br />
macchina assembler in modo mnemonico: se nella macchina processo l’istruzione somma è 1100,<br />
per esempio, nella macchina assembler dico che quest’istruzione si chiama “somma”, cioè associo<br />
ai codici operativi un codice mnemonico, cioè ci ricorda l’operazione che fa l’istruzione e quindi<br />
rende più facilmente usabile questa istruzione. L’istruzione somma non solo contiene il codice<br />
operativo che ci dice che è un’istruzione di somma, ma contiene ovviamente degli operandi, che<br />
nella macchina processo non sono altro che un insieme di bit che possono rappresentare un<br />
indirizzo piuttosto che gli operandi veri e propri dell’istruzione, ecc. Nella macchina assembler per<br />
eliminare questa scocciatura si dà la possibilità di identificare gli operandi con dei simboli. Questo<br />
comporta che la realizzazione della macchina assembler sulla macchina processo avviene attraverso<br />
uno strato di software che è ancora una volta un traduttore; quindi significa che quando faccio un<br />
programma in assembler per generare il codice per la macchina processo devo passare attraverso un<br />
processo di traduzione, in questo caso si dice attraverso una fase di assemblaggio.<br />
Parliamo dello strato che sta ancora sotto la macchina processo, cioè la macchina hardware. Noi<br />
abbiamo detto che una macchina viene realizzata sopra un’altra macchina per effetto di un software;<br />
se diciamo che al di sotto della macchina processo c’è la macchina HW significa che la macchina<br />
processo non era l’ultima nella gerarchia, ma allora qual è lo strato software che fa sì che io realizzi<br />
la macchina processo sulla macchina HW? Lo strato software è il sistema operativo. Il sistema<br />
operativo è un programma fatto da tanti pezzi ognuno responsabile di determinate attività. Il sistema<br />
operativo più che realizzare la macchina processo sulla stessa macchina HW è in grado di realizzare<br />
tante macchine processo, ognuna con la propria memoria e il proprio PC, sulla stessa macchina<br />
HW.<br />
Da un punto di vista logico l’architettura la possiamo immaginare in questo modo: ho un<br />
programma 1 che viene eseguito dalla macchina processo 1, un programma 2 che viene eseguito<br />
dalla macchina processo 2, …, un programma N che viene eseguito dalla macchina processo N.<br />
Naturalmente questi programmi sono espressi in linguaggio binario.<br />
Le N macchine processo attraverso questo strato di software, che è il sistema operativo, vengono<br />
realizzate a partire dalla macchina hardware:<br />
30
Naturalmente se stiamo parlando di quel modello architetturale, in cui c’è la gerarchia di macchine,<br />
ogni macchina è caratterizzata da un proprio linguaggio, quindi se c’è la macchina HW ci deve<br />
essere il linguaggio della macchina HW. Anche il linguaggio della macchina HW è un linguaggio<br />
binario.<br />
Se il sistema operativo realizza N macchine processo sulla stessa macchina HW significa che un<br />
programma che viene eseguito da una macchina processo ha come visibilità il fatto che tutte le<br />
risorse sono dedicate ad un altro programma. Il programma che viene eseguito da una determinata<br />
macchina processo fa sì che questa evolva in funzione delle istruzioni del programma; ma se la<br />
macchina processo funziona così come abbiamo detto significa anche che un’istruzione di quel<br />
programma viene eseguita attraverso il meccanismo del PC; quindi se ci sono N processi significa<br />
che ci saranno N PC, e non solo perché un programma spesso fa riferimento alle operazioni di I/O,<br />
quindi da un punto di vista logico è come se ogni macchina processo fosse dotata del proprio PC, da<br />
una propria memoria di processo dove sta caricato il programma in esecuzione e poi da unità<br />
ingresso/uscita (come se avesse l’unità monitor, l’unità tastiera, ecc…):<br />
Realizzando N macchine processo sulla stessa macchina HW si sfruttano al meglio le risorse<br />
hardware, cioè le risorse disponibili nella macchina HW vengono sfruttate al meglio; questo<br />
significa che normalmente si fa in modo che non stiano ferme o inutilizzate inutilmente.<br />
Durante l’esecuzione di un programma se c’è ad un certo punto un operazione di input/output per<br />
esempio, devo congelare quel programma e attivarne un altro; però poi non ho finito perché quel<br />
programma che era stato congelato si potrebbe scongelare, ma se si scongela un programma si deve<br />
congelare un altro programma. Una cosa del genere come può avvenire e dov’è la complessità nel<br />
far avvenire questo?<br />
Una macchina HW ha un solo esecutore reale, quindi stiamo cercando di inventare la possibilità di<br />
condividere quest’esecutore fra più programmi, però deve valere una regola: se l’esecutore è<br />
dedicato ad un programma, non può essere dedicato ad un altro programma.<br />
Tutte le volte che certe istruzioni della macchina processo devono essere eseguite dalla macchina<br />
HW, si ha che la loro esecuzione è “truccata”, cioè quella che per la macchina processo è<br />
l’istruzione “leggi” in realtà la macchina HW la interpreta come un salto ad un certo indirizzo dove<br />
31
c’è un pezzo di software del sistema operativo; quindi viene congelato il programma e il sistema<br />
operativo può decidere di scongelarne un altro; ma congelare il programma vuol dire che poi perché<br />
tutto funzioni prima o poi quando lo riscongelo questo non si deve essere accorto di essere stato<br />
congelato, quindi il sistema operativo deve salvare tutto un insieme di informazioni che poi<br />
consentono di svegliare di nuovo il programma e ridargli il suo contesto (PC, registri, variabili,<br />
ecc…).<br />
Il sistema operativo è in buona parte costituito da sequenze di istruzioni che sono i servizi di<br />
sistema, che svolgono azioni richieste da un processo garantendo che l’esecuzione del servizio sia<br />
per il processo equivalente all’esecuzione di una normale istruzione (anche quando il processo<br />
viene momentaneamente sospeso).<br />
A livello di macchina HW non esiste più il principio del determinismo. Esiste il meccanismo delle<br />
interruzioni asincrone che ci danno il non determinismo.<br />
Il meccanismo delle interruzioni porta la macchina ad eseguire un salto ad un indirizzo prefissato<br />
ogni qual volta si verificano particolari eventi (battere un tasto). Si parla di interruzioni asincrone<br />
quando non sono prevedibili, cioè sono relative ad eventi esterni.<br />
Quindi esistono due meccanismi di interruzione di interruzione:<br />
• sincrona: causata da un evento interno all’esecuzione del programma e che determina un salto a<br />
un servizio di sistema;<br />
• asincrona: causata da un evento esterno alla macchina; essa interrompe il flusso di istruzioni che<br />
la macchina stava eseguendo e determina un salto a un indirizzo del sistema operativo.<br />
La macchina HW è costituita da sottosistemi funzionali collegati dal sistema di comunicazione:<br />
Ciascun sottosistema è realizzato con dei componenti elementari, le porte logiche, la cui<br />
combinazione da luogo a circuiti più complessi, quali reti combinatorie e sequenziali. Non si può<br />
comunque affermare che i livelli inferiori alla macchina HW sono certamente hw mentre i livelli<br />
superiori sono certamente software.<br />
32
06/04/2004<br />
Noi non studieremo un intero sistema di elaborazione, ma l’attenzione sarà focalizzata soltanto su<br />
un blocco principale che è il processore, la CPU. Quale CPU scegliere come caso di studio? Non si<br />
fa riferimento ad un’architettura commerciale, ma si utilizza un’architettura finta: DLX. Questo<br />
processore è simile a molte architetture commerciali.<br />
Il processore DLX è pronunciato delux, e la sigla deriva da: (AMD 29K, DECstation 3100, HP 850,<br />
IBM 801, Intel i860, MIPS M/120A, MIPS M/1000, Motorola 88K, RISC I, SGI 4D/60,<br />
SPARCstation-1, Sun-4/110, Sun-4/260)/13 = 560 = DLX.<br />
Il DLX è un’architettura RISC, quindi semplicissimo dal punto di vista hardware; una cosa che<br />
caratterizza le architetture RISC è che sono macchine Load/Store, che significa che poiché il set di<br />
istruzioni deve essere molto limitato le operazioni possono essere eseguite soltanto tra operandi<br />
contenuti all’interno del processore (nei registri).<br />
Il DLX ha due banchi di registri: un banco di registri lo chiameremo da ora in poi GPR (generalpurpose<br />
registers) e l’altro lo chiameremo FPR (floating-point registers). Entrambi i banchi di<br />
registri sono formati da 32 registri. I registri hanno tutti la stessa dimensione e questa dimensione è<br />
di 32 bit; si dice quindi che questo processore ha un parallelismo di 32 bit, cioè le operazioni<br />
vengono eseguite su numeri codificati con 32 bit. La memoria è indirizzabile a byte, il suo<br />
ordinamento è di tipo Big Endian, e gli indirizzi sono a 32 bit, cioè abbiamo uno spazio di<br />
indirizzamento di 32 bit.<br />
Concentriamo la nostra attenzione sui registri GPR.<br />
I registri GPR contengono gli operandi delle istruzioni, cioè le istruzioni del set di istruzioni di<br />
questo processore operano su dati contenuti nei registri. Il DLX può eseguire sia calcoli con numeri<br />
interi che calcoli con numeri reali. GPR è il banco dei registri che contiene gli operandi interi,<br />
mentre FPR è quello che contiene gli operandi reali.<br />
Come abbiamo detto il banco GPR contiene 32 registri di 32 bit, e ogni registro verrà identificato da<br />
una lettera seguito da un indice: R0, R1, …, R31. Abbiamo istruzioni del DLX che consentono di<br />
modificare il contenuto di qualsiasi registro ad esclusione del registro R0, che è un registro che può<br />
essere soltanto letto e contiene il valore 0.<br />
Vediamo a cosa può essere utile il registro R0:<br />
supponiamo di voler inizializzare un registro con un valore; se io ho un’istruzione di somma si può<br />
evitare di usare un’istruzione di “move”, cioè di spostamento di una costante in un registro? La<br />
risposta è no. Supponiamo di voler inizializzare registro R1 con il valore 7: R1 ← 7. Se non<br />
conoscessi l’assembly potrei pensare che ci sia un’istruzione del tipo: MOVE R1, 7, cioè<br />
un’istruzione in cui specifico un registro di destinazione e una costante numerica. (Molti processori<br />
hanno questa istruzione). Hennessy e Patterson hanno detto che questa istruzione non è<br />
indispensabile perché può essere simulata con un’altra istruzione: ADDI Rd, Rs, immediate;<br />
questa istruzione somma il contenuto del registro Rs con la costante immediate e il risultato lo<br />
deposita nel registro Rd. Quindi se io voglio scrivere 7 nel registro R1 posso fare così: ADDI R1,<br />
R0, 7. Un registro speciale è anche il registro R31: esistono delle istruzioni di jump and link, e il<br />
registro R31 serve per ricordare l’indirizzo a cui ritornare dopo queste istruzioni.<br />
I bit di ogni registro li indicheremo in questo modo: il bit più a sinistra sarà il bit 0 e quello più a<br />
destra sarà il bit 31. I 32 bit li posso partizionare in 4 byte e anche questi sono ordinati nello stesso<br />
modo dei bit:<br />
Le istruzioni ALU sono le istruzioni che coinvolgono l’unità logico-aritmetica, ed operano<br />
sull’intero registro, cioè sui 32 bit; non ci sono istruzioni ALU che operano su parti di registro.<br />
Le istruzioni Load/Store sono le istruzioni di comunicazione con la memoria e possono operare sia<br />
sull’intero registro (word), sia sul mezzo registro (half word) e sia su un byte:<br />
33
Le istruzioni load/store su mezza parola o su un byte utilizzeranno sempre i byte meno significativi.<br />
Passiamo ai registri FPR.<br />
Il DLX contiene istruzioni per effettuare calcoli in virgola mobile sia in precisione singola (32 bit),<br />
sia in precisione doppia (64 bit). Ma se abbiamo registri a 32 bit come facciamo a memorizzare<br />
operandi a 64 bit? Le istruzioni che operano su operandi a 64 bit considerano i registri come<br />
appaiati l’uno con l’altro: cioè un banco di 32 registri a 32 bit lo posso anche vedere come un banco<br />
di 16 registri a 64 bit; dico che F0 ed F1 li considero uniti e formano un registro a 64 bit che<br />
chiamerò F0<br />
Esistono istruzioni che operano con operandi a 64 bit. Per esempio:<br />
ADDD F0, F8, F12<br />
F8 F9<br />
(F0 è un registro come gli altri e non contiene lo 0 come R0). In questo caso F0 = F0 + F1, F8 = F8<br />
+ F9, F12 = F12 + F13.<br />
Oltre ai registri considerati abbiamo anche altri registri speciali che non possiamo manipolare<br />
direttamente:<br />
• PC (Program Counter), è un registro che contiene l’indirizzo della prossima istruzione da<br />
eseguire; non abbiamo istruzioni che lo modificano esplicitamente, però esistono tante altre<br />
istruzioni, tipicamente le istruzioni di salto, che lo modificano;<br />
• IAR (Interrupt Address Registrer);<br />
• FPSR (Floating-Point Status Register).<br />
Come vengono ordinati i byte in memoria?<br />
Il DLX ordina i byte in memoria in un modo che si chiama Big Endian. Tipicamente i dati possono<br />
essere ordinati in due modi: una modalità si chiama Big Endian e un’altra modalità si chiama Little<br />
Endian. Supponiamo di voler scrivere all’indirizzo 0 della memoria il numero in esadecimale<br />
0×AABBCCDD, e consideriamo che quest’ultima sia divisa in byte:<br />
34
Nel DLX la memoria è indirizzata al byte, cioè la più piccola quantità che posso indirizzare è il<br />
byte. Il byte lo posso scrivere a qualsiasi indirizzo della memoria. Invece ho limitazioni per la<br />
scrittura delle half-word e per la scrittura delle word. Una half-word non la posso scrivere a partire<br />
da un indirizzo qualsiasi della memoria, ma le posso scrivere soltanto a partire da indirizzi pari. Per<br />
esempio consideriamo la seguente istruzione: store half-word<br />
SH indp, R5 (indp indica l’indirizzo di memoria in cui voglio scrivere, R5 è il registro che<br />
contiene il dato che voglio scrivere in memoria). L’indirizzo deve essere multiplo di 2. Si può<br />
scrivere SH 31, R5, però il contenuto di R5 verrà memorizzato a partire dalla locazione 30. Quindi<br />
l’indirizzo reale a partire dal quale vengono scritti i 16 bit è:<br />
indr = indp & 0×FFFFFFFE<br />
cioè viene fatto un and logico tra l’indizzo che dà il programmatore e il numero 0×FFFFFFFE.<br />
Facendo così approssimiamo al numero pari immediatamente precedente (se è dispari).<br />
Ragionamento analogo avviene per le store word (SW) che possono essere memorizzate a partire da<br />
un indirizzo multiplo di 4: per fare questo si fa così ⇒ indr = indp & 0×FFFFFFFC.<br />
L’instruction set del DLX conta 92 istruzioni divise in 6 classi:<br />
• Load & Store instructions<br />
• Move instructions<br />
• Arithmetic and logical instructions<br />
• Floating-point instructions<br />
• Jump & branch instructions<br />
• Special instructions<br />
Un’altra caratteristica delle macchine RISC è che il formato delle istruzioni, nella maggior parte dei<br />
casi, ha un formato delle istruzioni fisso. Nel DLX il formato delle istruzioni è di 32 bit.<br />
Abbiamo tre tipi di istruzioni:<br />
• I-type (Immediate)<br />
• R-type (Register)<br />
• J-type (Jamp)<br />
I-type Instruction<br />
I primi 6 bit rappresentano il codice operativo dell’istruzione, e questo vale per tutti e tre i tipi di<br />
istruzioni. Poi abbiamo 5 bit che codificano l’indirizzo sorgente e 5 bit per il registro destinazione;<br />
gli ultimi 16 bit codificano l’immediate.<br />
Alle istruzioni di tipo I appartengono tutte le istruzioni che ammettono come operando un<br />
immediate (immediato, costante numerica).<br />
Consideriamo l’istruzione: AND R1, R2, R3, che vuol dire fare un and logico tra R2 ed R3 e<br />
memorizzare il risultato in R1 ⇒ R1 ← R2 & R3; un’istruzione di questo tipo non è un’istruzione<br />
di tipo I, perché nessuno dei due operandi è una costante. Le istruzioni di tipo I sono istruzioni del<br />
tipo: ANDI R1, R2, 94 oppure ANDI R1, R2, 423000. Quest’ultimo esempio non lo posso tradurre<br />
in un’istruzione perché 423000 non posso codificarlo in 16 bit.<br />
35
Esempi<br />
addi r1, r2, 5 ; r1 = r2 + signext(5), rd = r1 e rs1 = r2, immediate = 0000000000000101<br />
5 è un numero a 16 bit, mentre r2 è un numero a 32 bit, quindi dentro al processore ci sarà un<br />
sommatore i cui ingressi saranno a 32 bit; allora verrà esteso in segno il numero a 16 bit:<br />
16<br />
immediate<br />
sign<br />
Ext<br />
addi r1, r2, -5 ; r1 = r2 + signext(-5), rd = r1 e rs1 = r2, immediate = 1111111111111011.<br />
32<br />
32<br />
+<br />
36
13/04/2004<br />
R-type Instruction<br />
Nelle istruzioni di tipo R entrambi gli operandi si trovano all’interno di un registro. Il formato delle<br />
istruzioni di tipo R è il seguente:<br />
Abbiamo 6 bit che codificano il codice operativo dell’istruzione, 5 bit che codificano<br />
rispettivamente i registri sorgente e il registro destinazione, 5 bit che non vengono utilizzati, e gli<br />
ultimi 6 bit rappresentano la funzione. Questo significa che le istruzioni di tipo R, che sono per<br />
esempio le istruzioni di tipo somma, sottrazione, le operazioni logiche che avvengono sui registri,<br />
sono caratterizzate da un unico codice operativo, cioè il codice operativo dell’add, per esempio, è<br />
uguale al codice operativo della sub, così come è uguale a quello della and, e così via. Per<br />
discriminare l’una dall’altra si utilizzano gli ultimi 6 bit dell’istruzione.<br />
Esistono due tipi di istruzioni di tipo R:<br />
1. Istruzioni di tipo R che operano sui registri GPR<br />
2. Istruzioni di tipo R che operano sui registri FPR<br />
Queste sono caratterizzate da un codice operativo diverso. Nel caso delle istruzioni di tipo R che<br />
operano sui registri FPR solo 5 bit sono utilizzati per discriminare tra le varie funzioni.<br />
J-type Instruction<br />
Il formato delle istruzioni di tipo J è il seguente:<br />
Abbiamo che 6 bit codificano il tipo di istruzione: jump (J), jump & link (JAL), TRAP, ecc…; i<br />
restanti 26 bit individuano una sorta di spiazzamento, che è l’indirizzo target del salto. Per esempio<br />
un’istruzione del tipo “J target”, dove target è una costante numerica, non fa altro che modificare il<br />
PC di una quantità pari a target, cioè deve spostarsi della quantità target, avanti o indietro (se target<br />
è negativo), rispetto a dove si trova in quel momento: PC = PC + sigext(target).<br />
Vediamo alcune istruzioni dell’instruction set.<br />
Load & Store Instruction<br />
Abbiamo due categorie di istruzioni Load/Store:<br />
1. Load/Store che operano sui registri GPR<br />
2. Load/Store che operano sui registri FPR<br />
Tutte le istruzioni load/store appartengono alla classe delle istruzioni di tipo I.<br />
Sia per una load che per una store io devo indirizzare la memoria, e l’indirizzo viene calcolato in<br />
questo modo: viene sommato al contenuto dell’indirizzo sorgente l’immediate ⇒<br />
effective_address = (rs) + sigext(immediate).<br />
Abbiamo in tutto 5 tipi di load e 3 tipi di store:<br />
• LB (load byte), LBU (load byte unsigned), LH (load half-word), LHU (load half-word<br />
unsigned), LW (load word). Per le load che agisco sui byte o sulle half-word dobbiamo<br />
considerare che questi devono essere scritti nei registri che però sono a 32 bit:<br />
Reg<br />
0 0 0<br />
32<br />
8<br />
37
questi 8 bit vengono scritti nella parte meno significativa del registro. Con la LBU i rimanenti<br />
bit vengono scritti con 0, mentre con la LB vengono settati col bit più significativo degli otto bit<br />
che prelevo dalla memoria. Lo stesso vale per le LH e LHU.<br />
• SB (store byte), SH (store half-word), SW (store word): si preleva dal registro un byte, una halfword<br />
o una word e si scrive in memoria.<br />
Il formato delle istruzioni di load e store è il seguente:<br />
LB/LBU/LH/LHU/LW rd, immediate(rs1)<br />
SB/SH/SW immediate(rs1), rd<br />
Per le load il primo parametro identifica il registro di destinazione, e il secondo parametro identifica<br />
l’indirizzo della memoria.<br />
Esempio: LW R7, 54(R0) Questa istruzione accede all’indirizzo di memoria 54 + R0 (ovvero 0),<br />
preleva una word a quest’indirizzo e la memorizza in R7.<br />
Le store memorizzano all’indirizzo immediate(rs1) della memoria il contenuto del registro passato<br />
come secondo parametro (rd).<br />
Esempio: SW 4(R2), R7 Se R2 vale 20 ed R7 vale 10, questa istruzione va all’indirizzo 20+4=24<br />
in memoria, e a partire da questo scrive la word 10.<br />
Esempio di Store Byte<br />
sb 5(r1), r2<br />
supponiamo che r1=9 ed r2=ff. Quello che avviene è la seguente cosa:<br />
Esempio di Load Byte e Load Byte Unsigned<br />
lb r3, 5(r1)<br />
supponiamo che r1=9. Quello che accade è la seguente cosa:<br />
Move Instructions<br />
Le istruzioni move sono istruzioni di tipo R, e servono a trasferire il contenuto di un registro in un<br />
altro registro entrambi appartenenti allo stesso banco dei registri; oppure sono istruzioni che<br />
permettono di trasferire il contenuto di un registro FPR in un registro GPR o viceversa.<br />
• movi2s, movs2i: GPR ↔ IAR<br />
movi2s rd, rs1 ; rd ∈ RS, rs1∈ IAR<br />
movs2i rd, rs1 ; rd ∈ GPR, rs1∈ SR<br />
38
• movf, movd: FPR ↔ FPR<br />
movf rd, rs1 ; rd, rs1∈ FPR<br />
movd rd, rs1 ; rd, rs1∈ FPR even-numbered<br />
per esempio “movf f0, f4” non fa altro che copiare il contenuto del registro f4 nel registro f0:<br />
f0<br />
f1<br />
f2<br />
f3<br />
f4<br />
f5<br />
.<br />
f31<br />
“movd f0, f4” copia i registri f4-f5 nei registri f0-f1<br />
f0<br />
f1<br />
f2<br />
f3<br />
f4<br />
f5<br />
. .<br />
f31<br />
• movfp2i, movi2fp: GPR ↔ FPR<br />
movfp2i rd, rs1 ; rd ∈ GPR, rs1∈ FPR<br />
movi2fp rd, rs1 ; rd ∈ FPR, rs1∈ GPR<br />
. .<br />
. .<br />
per esempio “movi2fp f4, r9” prende il contenuto del registro r9 e lo copia nel registro f4;<br />
questa è una copia bit a bit e non una conversione; quindi per esempio se r9 contiene il numero<br />
72 dentro f4 ho la codifica binaria di 72 e non ho 72 espresso in floating-point.<br />
Arithmetic and Logical Instructions<br />
Abbiamo 4 categorie che ricadono nella classe delle istruzioni aritmetico-logiche:<br />
• istruzioni aritmetiche;<br />
• istruzioni logiche;<br />
• istruzioni di shift dei dati (spostamento dei dati);<br />
• istruzioni di confronto.<br />
Di ogni istruzione abbiamo sia la versione di tipo R che la versione di tipo I.<br />
add, sub: somma e sottrazione. Il formato, ad esempio per la somma, è: add r1, r2, r3. Quello<br />
che fa è sommare i contenuti di r2 ed r3 e il risultato lo mette in r1. Il contenuto dei registri<br />
sorgente è considerato come rappresentato in complemento a due.<br />
Di queste due esistono anche le versioni unsigned.<br />
addu, subu. I contenuti dei registri è visto come numeri senza segno, ovvero è visto come<br />
numero binario naturale puro, e non in complemento a due. Il formato è come quello di prima:<br />
addu r1, r2, r3.<br />
39
Per tutte e quattro le istruzioni sopra abbiamo la versione di tipo I:<br />
addi, subi, addui, subui. Per esempio: addi r1, r2, #17.<br />
Abbiamo anche le istruzioni di moltiplicazione e divisione:<br />
mult, multu, div, divu. Queste operano soltanto su registri di tipo FPR. Il formato è il seguente:<br />
mult f1, f2, f3.<br />
Istruzioni logiche<br />
Le istruzioni logiche sono delle istruzioni che operano a livello di bit.<br />
and, or, xor. Il formato è il seguente: and r1, r2, r3, dove r1 è il registro destinazione ed r2 e r3<br />
sono i registri sorgente.<br />
Di queste abbiamo anche la versione di tipo I.<br />
andi, ori, xori. Il formato è: andi r1, r2, #16, per esempio.<br />
Un’altra istruzione che appartiene a questa classe è l’istruzione<br />
LHI (load high immediate). In questo caso load non si riferisce alla memoria. È un’istruzione di<br />
tipo I. Quando abbiamo visto le istruzioni di tipo I abbiamo detto che l’immediate è un numero<br />
a 16 bit; come facciamo a caricare in un registro un numero più grande di 16 bit? Per caricare un<br />
immediate lungo in un registro si utilizza questa istruzione. Il formato è: lhi r1, 0×ff00, dove r1<br />
è il registro destinazione. L’immediate viene caricato non nella parte meno significativa di r1,<br />
ma nella parte più significativa. Quindi se io scrivo lhi r1, 0×AABB, questa farà la seguente<br />
cosa:<br />
AA BB 00 00 R1<br />
Quindi se io volessi caricare nel registro R1 il numero 0×AABBCCDD basterebbe prima<br />
caricare la parte alta del numero nella parte alta del registro attraverso la lhi e poi fare:<br />
addui r1, r1, 0×CCDD, oppure ori r1, r1, 0×CCDD<br />
AA BB 00 00 R1<br />
OR<br />
00 00 CC DD<br />
AA BB CC DD<br />
Istruzioni di shift<br />
Queste istruzioni fanno scorrere il contenuto di un registro; questo può essere fatto scorrere o a<br />
destra o a sinistra. Abbiamo tre tipi di shift:<br />
sll (shift left logico), srl (shift right logico), sra (shift right aritmetico).<br />
Il formato è: sll r1, r2, r3, dove r1 è il registro destinazione, r2 è il registro sorgente, e r3 è la<br />
quantità di bit da far scorrere.<br />
Abbiamo anche la versione con immediate:<br />
slli, srli, srai. Il formato è: slli r1, r2, #3. A seguito di questa istruzione accade:<br />
R2 0 …………… 0 0 1 0 1<br />
tutti i bit vengono spostati di tre posti a sinistra, e i tre<br />
bit lasciati vuoti vengono settati a 0.<br />
R1<br />
……… 0 0 1 0 1 0 0 0<br />
Per lo shift a destra è lo stesso: se ho il numero 1011 e faccio lo shift di una posizione a destra<br />
srl(1)<br />
ottengo ⇒ 1011 → 0101. Anche in questo caso i bit lasciati vuoti vengono settati a 0.<br />
40
Se io ho un numero e ne faccio lo shift di n posti a sinistra, è come se moltiplicassi quel numero<br />
per 2 n . Analogamente se io faccio lo shift di un numero di n posti a destra è come dividere il<br />
numero per 2 n ; questo vale se il numero è rappresentato in binario naturale.<br />
Nello shift aritmetico la posizione che viene liberata verrà inizializzata col bit che ha<br />
sra(1)<br />
abbandonato quella posizione: 1011 → 1101.<br />
Se il numero è rappresentato in complemento a due con questa istruzione è come dividere il<br />
numero per una potenza di 2:<br />
1 0 1 1 -5<br />
0 1 0 1 5<br />
1 1 0 1 -3<br />
srl(1)<br />
sra(1)<br />
Istruzioni di confronto<br />
slt (set less than), sgt (set greater than), sle (set less equal), sge (set greater equal), seq (set<br />
equal), sne (set not equal).<br />
slt r1, r2, r3 ; (r2
Il formato è il seguente: ltf f0, f1. Riportiamo soltanto gli operandi da confrontare; il risultato di<br />
questa operazione viene memorizzato implicitamente in un registro ad un solo bit, ed è il registro<br />
FPSR (float-point status register): (f0
.float f1, f2, …, fn Con questa alloco float<br />
.double d1, d2, …, dn Con questa alloco double<br />
C’è una direttiva che forza l’allineamento dei dati ad indirizzi di memoria multipli di una certa base:<br />
.align Esempio:<br />
.data 100<br />
.byte 0×ff<br />
.align 2 ; allinea ad un indirizzo multiplo di 2 2<br />
.word 0×aabbccdd<br />
Quello che avviene in memoria è:<br />
.ascii Memorizza la stringa in memoria. Per esempio:<br />
.data 100<br />
.ascii “Hello!”<br />
Quello che accade è:<br />
.asciiz Memorizza la stringa in memoria e pone l’ultimo byte a 0. Per esempio:<br />
.data 100<br />
.ascii “Hello!”<br />
Quello che accade è:<br />
.space Riserva n byte in memoria senza inizializzarli. Per esempio:<br />
.data 100<br />
.space 5<br />
.byte 0×ff<br />
Quello che accade è:<br />
43
15/04/2004<br />
Nella seguente figura è illustrato quello che è chiamato datapath del processore, la via dei dati:<br />
Questo include tutto il percorso che i dati all’interno del processore possono seguire. Quando parlo<br />
di dati è in senso lato, cioè le istruzioni che vengono lette per il processore di fatto sono dei dati da<br />
manipolare opportunamente. Gli elementi che vengono rappresentati sono: tutti gli elementi che<br />
sono in grado di memorizzare informazioni durante questo percorso, e alcuni elementi che<br />
manipolano i dati. Abbiamo due elementi ALU; i rettangoli sono degli elementi di memoria dove<br />
possono essere memorizzate delle informazioni, e gli ovali con la scritta MUX sono dei multiplexer.<br />
In questo disegno non è rappresentata la parte di controllo del processore.<br />
Vediamo passo passo come viene letta, decodificata ed eseguita ognuna delle istruzioni del DLX<br />
che utilizzano questo datapath. In realtà dobbiamo vederla al contrario: noi abbiamo definito il set<br />
di istruzioni del DLX, questo datapath nasce dopo aver definito questo set di istruzioni.<br />
Partiamo dalla prima fase (figura a<br />
sinistra): la prima cosa di cui ci<br />
occupiamo è la lettura dell’istruzione.<br />
C’è un PC che indirizza la memoria,<br />
l’informazione letta dalla memoria<br />
viene prelevata e va a finire all’interno<br />
del processore e in particolare va a<br />
finire nel registro IR. (I collegamenti<br />
fra i vari blocchi dobbiamo<br />
immaginare che siano tante linee<br />
quanti sono i bit del PC).<br />
È da precisare che la Instruction<br />
Memory e la Data Memory<br />
normalmente non stanno all’interno<br />
del processore.<br />
Si vede che l’uscita del PC va ad<br />
blocco ALU, che in questo caso viene<br />
utilizzato solo come un sommatore;<br />
nell’altro input dell’ALU c’è il<br />
numero 4; quindi viene fatta la somma<br />
del contenuto del PC e il numero 4.<br />
Viene considerato 4 perché ogni<br />
44
istruzione occupa 4 byte, e quindi poi si punterà alla prossima istruzione. In parallelo alla lettura<br />
dell’istruzione il sommatore entra in<br />
azione e produce la somma tra il<br />
valore del PC e 4; questo valore<br />
calcolato viene memorizzato in un<br />
registro che si chiama NPC (new<br />
PC).<br />
Questa parte appena descritta si<br />
chiama Instruction fetch: le<br />
operazioni sopra descritte sono<br />
quelle relative al fetch<br />
dell’istruzione, cioè alla lettura<br />
dell’istruzione dalla memoria e alla<br />
memorizzazione al proprio interno<br />
con l’aggiornamento del PC.<br />
Adesso andiamo nella fase di Instruction decode/register fetch. All’interno di questa parte di<br />
architettura che è quella preposta ad eseguire l’operazione di decodifica c’è il banco dei registri del<br />
DLX. La decodifica avviene in una parte non rappresentata qui, che è la logica di controllo. La<br />
decodifica presuppone che il codice operativo contenuto nell’IR venga decodificato e come risultato<br />
di questa decodifica vengono prodotti i segnali di controllo che abilitano alcune parti del processore<br />
a fare alcune cose. La cosa interessante è che mentre faccio la decodifica io posso in parallelo<br />
quello che viene chiamato register<br />
fetch: è quello che riguarda la lettura<br />
di quei registri (operandi sorgente)<br />
all’interno del banco dei registri per<br />
potere utilizzare questi valori durante<br />
l’esecuzione dell’istruzione. Se<br />
ancora non è avvenuta la decodifica<br />
dell’istruzione come faccio a leggere<br />
gli operandi sorgenti? Questo è<br />
possibile nel caso del DLX per un<br />
motivo molto semplice: la codifica<br />
dell’istruzione nel DLX è tale che se<br />
ci dovessero essere degli operandi<br />
sorgenti questi sicuramente saranno<br />
codificati in un campo di bit che<br />
sono sempre gli stessi (dal bit 6 al<br />
10, e da 11 a 15). Si fa questo perché<br />
un pezzo del processore sta facendo<br />
la decodifica e nel frattempo nel caso<br />
in cui dovessero servire quei registri<br />
io li prelevo; nel caso non servono<br />
45
non vengono utilizzati. Lo stesso non si può dire delle scritture, perché se io scrivo su un registro<br />
perdo il vecchio contenuto che non è più recuperabile.<br />
I valori letti dai potenziali registri sorgenti vengono memorizzati nei due registri A e B, che non<br />
appartengono al banco dei registri accessibili all’utente; in particolare in A viene messo il valore del<br />
registro sorgente codificato nei bit da 6 a 10, e in B quello del registro sorgente codificato nei bit da<br />
11 a 15. Se si dovesse trattare di un’istruzione in cui devo utilizzare un’immediate, questo sta nei bit<br />
da 16 a 31 del registro IR, lo prelevo,<br />
lo estendo in segno (da 16 bit a 32<br />
bit) e questi 32 bit vengono<br />
memorizzati all’interno del registro<br />
Imm (immediate); anche questo è un<br />
registro che l’utente non vede, ma<br />
serve solo per eseguire le istruzioni.<br />
Quindi in questa fase ho prodotto tre<br />
informazioni: registro A, registro B e<br />
Immediate. Queste tre informazioni<br />
potenzialmente, qualcuna di queste o<br />
nessuna di queste, potrebbero essere<br />
utilizzate nella fase successiva.<br />
Finita questa fase si passa alla fase<br />
che si chiama Execution/effective<br />
address calculation.<br />
L’istruzione appena decodificata può<br />
essere: un branch, un’istruzione<br />
ALU (register-register ALU<br />
instruction, oppure un’istruzione con<br />
operando immediato), oppure<br />
un’istruzione di load/store. A<br />
seconda di quale tipologia di<br />
istruzione è stata decodificata, nella fase di execution verranno effettuate alcune operazioni.<br />
Vediamo per ognuna di queste quale<br />
parte di architettura viene coinvolta.<br />
Branch:<br />
dobbiamo calcolare se la condizione<br />
è vera o falsa e calcolare l’indirizzo<br />
di salto. Nelle istruzioni di branch il<br />
salto è indicato col displacement:<br />
all’indirizzo a cui punta il PC, che è<br />
quello dell’istruzione seguente,<br />
bisogna sommare il displacement, lo<br />
spiazzamento che mi va ad<br />
individuare l’istruzione target del<br />
salto.<br />
La prima operazione eseguita è la<br />
verifica che il registro A valga 0 o se<br />
sia diverso da 0 e questo lo si fa<br />
attraverso un comparatore. Il<br />
risultato di questa verifica viene<br />
posto in un registro che si chiama<br />
Cond, ed è un registro ad un solo bit.<br />
46
In parallelo viene calcolato<br />
l’indirizzo target del salto sommando<br />
l’immediate al NPC. Il risultato della<br />
somma viene messo all’interno di un<br />
registro, anche questo un registro di<br />
lavoro, che si chiama ALUOutput.<br />
Quindi se si tratta di un’istruzione di<br />
branch alla fine si producono questi<br />
due risultati: l’indirizzo del salto e la<br />
condizione, che a seconda che sia<br />
vera o falsa farà fare il salto oppure<br />
no.<br />
Register-register ALU instruction:<br />
in A e in B ho i due operandi sorgenti. Nel caso di una istruzione di questo tipo Func è codificata<br />
nella parte finale dell’IR (bit da 21 a<br />
31); questo campo decodificato<br />
durante la fase di decodifica non fa<br />
altro che andare a dire all’ALU quale<br />
operazione effettuare. Alla fine il<br />
risultato di queste operazioni viene<br />
memorizzato dentro il registro<br />
ALUOutput.<br />
I-type instruction:<br />
in questo caso vengono considerati i registri A e Imm, e viene effettuata un’operazione tra questi.<br />
L’operazione da fare al solito è codificata nel codice operativo, e attraverso la decodifica viene<br />
generato un opportuno segnale di controllo che fa sì che l’ALU effettui questa operazione.<br />
47
Al solito il risultato viene<br />
memorizzato nel registro<br />
ALUOutput.<br />
Nel caso di un’istruzione di load o di<br />
store devo utilizzare l’ALU per<br />
calcolare l’indirizzo di memoria a cui<br />
devo accedere. In questo caso ad<br />
ALUOutput assegno la somma tra A<br />
ed Imm:<br />
ALUOutput A + Imm.<br />
Ognuna di queste fasi che si stanno descrivendo avviene in un ciclo di clock. Quindi finora sono<br />
trascorsi tre cicli di clock. Nel quarto ciclo di clock viene coinvolta la parte di architettura che<br />
riguarda il Memory access. In questa fase viene eseguita la fase di load o di store se si tratta di<br />
un’operazione di load o di store, mentre se si tratta di un’operazione I-type o R-type in questa fase,<br />
quindi durante questo ciclo di clock, non si deve fare niente. Se l’istruzione era un branch in Cond<br />
avevamo la condizione, e in ALUOutput avevamo l’indirizzo target del salto. Supponendo che si<br />
tratti di un branch vediamo cosa succede: se la condizione è vera dobbiamo aggiornare il PC col<br />
valore che c’è in ALUOutput; se la<br />
condizione è falsa il PC viene<br />
aggiornato col contenuto di NPC.<br />
48
Se si tratta di un’operazione di load<br />
(nel caso di load/store ALUOutput<br />
contiene l’indirizzo di memoria su<br />
cui fare o la load o la store)<br />
ALUOutput indirizza la Data<br />
memory, il contenuto della locazione<br />
indirizzata viene letto e memorizzato<br />
in un registro temporaneo LMD<br />
(load memory data).<br />
Se si tratta di un’operazione di store<br />
l’operando che deve essere scritto in<br />
memoria si troverà sicuramente nel<br />
registro B, e l’indirizzo dove<br />
memorizzare questo operando si<br />
trova in ALUOutput.<br />
Nel caso di una load o di una store in<br />
ogni caso il PC viene aggiornato col<br />
valore del NPC. Il PC viene<br />
aggiornato al quarto ciclo di clock<br />
perché l’esito del brach per come è<br />
fatto questo datapath lo sappiamo<br />
solo alla fine della fase di execution.<br />
Questa che stiamo descrivendo si<br />
chiama versione sequenziale del<br />
DLX.<br />
Al quinto ciclo di clock che cosa rimane da fare?<br />
Se ho un’istruzione di branch questa viene completata nel quarto ciclo di clock. In tutti gli altri casi<br />
il risultato va a finire in un registro. La fase di memorizzazione del risultato se si tratta di<br />
un’istruzione ALU va eseguita andando ad individuare qual è il registro di destinazione e andandovi<br />
a copiare il risultato che sta in ALUOutput. Se invece non è un’istruzione ALU ma un’istruzione di<br />
load il dato che ho letto sta in LMD:<br />
49
questa è quella che si chiama fase di<br />
Write back.<br />
Il registro di destinazione viene<br />
individuato grazie al fatto che in IR è<br />
ancora presente l’istruzione, e questa<br />
contiene il registro destinazione.<br />
Questo è come è fatto un processore sequenziale RISC. Se non fosse RISC più o meno le parti sono<br />
simili, e quello che è molto più complicato è la parte di controllo, perché tipicamente i processori<br />
CISC non hanno un formato delle istruzioni fisso, quindi c’è una quantità di opzioni elevata, e tutte<br />
queste opzioni devono essere tenute in conto nella logica di controllo.<br />
Quella che abbiamo visto viene chiamata implementazione multiciclo del DLX. Multiciclo perché<br />
le varie operazioni sulla stessa istruzione avvengono in un certo numero di cicli. In particolare<br />
normalmente ogni istruzione viene eseguita in cinque cicli di clock. Questo è vero tranne che per<br />
due istruzioni: branch e store finiscono in quattro cicli di clock.<br />
Dato questo tipo di implementazione del DLX e noto che è il set di istruzioni del DLX, se io volessi<br />
calcolare il CPI medio per l’esecuzione di un programma, probabilmente questo CPI è prossimo a 5.<br />
Se per esempio avessi un programma in esecuzione e scopro che c’è un 12% di istruzioni di branch,<br />
naturalmente il CPI non sarà pari a 5, ma sarà CPI = 4*12/100 + 5*88/100 = 4.88. Naturalmente se<br />
questo programma presentasse il 15% di store il CPI medio sarebbe:<br />
CPI = 0.15*4 + 0.12*4 + 0.73*5 = 4.73.<br />
Ci sono delle soluzione che fanno impiegare meno tempo per eseguire le istruzioni del DLX?<br />
Ovvero si può riorganizzare il datapath in modo diverso per guadagnarci in termini di velocità?<br />
La risposta è che si possono fare diverse cose. Una delle cose che si può fare è: abbiamo visto che<br />
nel caso di istruzioni ALU (sia R-type che I-type), il quarto ciclo di clock, ovvero la fase di MEM,<br />
dove normalmente avviene una load o una store, per questo tipo di istruzioni è una fase<br />
assolutamente inutile perché non viene svolta alcuna operazione. Una modifica che si potrebbe fare<br />
all’architettura vista prima è quella che se si sa che è un’istruzione ALU la fase di write back la si fa<br />
al quarto ciclo di clock. In tal caso per esempio se di istruzioni ALU ne abbiamo il 44% otteniamo<br />
un CPI pari a: CPI = 4.44.<br />
Altri miglioramenti che si possono apportare sono dal punto di vista hardware. Abbiamo visto che<br />
nel datapath del DLX sequenziale ci sono due ALU: nell’instruction fetch e nella fase di execute.<br />
Questi due ALU possono essere unificati perché sono utilizzati in periodi di tempo distinti. Se viene<br />
fatta questa modifica i multiplexer davanti all’ALU dovrebbero permettere un ingresso in più.<br />
Un’altra cosa che si potrebbe fare è quella di unificare la memoria. Noi abbiamo utilizzato due<br />
50
memorie: Instruction memory e Data memory. Risparmiamo perché c’è un unico bus di indirizzi e<br />
un solo bus di dati che partono dal processore; quindi risparmiamo hardware.<br />
Tutte queste cose che si potrebbero fare in realtà non le facciamo, perché passare dalla versione che<br />
abbiamo alla versione pipeline è estremamente semplice.<br />
Pipeline<br />
Immaginiamo di avere una<br />
lavanderia organizzata in tre fasi:<br />
lavaggio, asciugatura e stiratura.<br />
Supponiamo di avere quattro<br />
utenti che richiedono questo<br />
servizio, e supponiamo che la fase<br />
di lavaggio duri 30 minuti, la fase<br />
di asciugatura duri 40 minuti e la<br />
fase di stiratura duri 20 minuti.<br />
Vediamo cosa succede come<br />
tempo di smaltimento degli utenti<br />
se lavoriamo in modo<br />
sequenziale.<br />
Ogni utente può entrare solo<br />
quando quello prima di lui è uscito, cioè quando ha eseguito tutte e tre le fasi. Per avere che l’utente<br />
D esca bisogna aspettare un tempo pari a: 30+40+20+30+40+20+30+40+20+30+40+20= 6 ore.<br />
Nella versione pipeline ogni<br />
utente entra in una fase quando<br />
l’utente precedente ha finito<br />
questa fase. Ovviamente il tutto<br />
è molto più veloce e il tempo<br />
impiegato affinché esca l’utente<br />
D è di 3 ore e 30 minuti.<br />
Quello che varia non è il tempo<br />
per eseguire le tre fasi, ma il<br />
tempo d’attesa per essere<br />
servito.<br />
La condizione ideale è che il pipeline sia bilanciato, cioè tutti gli stadi consumino lo stesso tempo.<br />
In questo caso è come se io producessi un’unità di prodotto ogni frazione di tempo che è la stessa<br />
frazione di tempo che viene consumata in uno qualunque degli stadi del pipeline. Se ci mettiamo<br />
all’uscita del sistema e supponiamo che per produrre un’automobile ci sono 6 stadi di 1 ora<br />
ciascuno a regime abbiamo che viene prodotta un’auto ogni ora. Quindi bisogna bilanciare per<br />
quanto possibile gli stadi del pipeline, perché se gli stadi non sono bilanciati e c’è uno stadio che<br />
dura molto più degli altri questo diventa la latenza che condiziona la performance complessiva del<br />
sistema; quindi è inutile ridurre il tempo di uno stadio solo, perché comunque se c’è uno stadio che<br />
è molto lento è questo che condiziona il pipeline. In ogni caso bisogna minimizzare la latenza per<br />
ogni stadio, ma bisogna anche cercare di renderli uguali.<br />
Quali sono i concetti fondamentali del pipeline?<br />
Posso eseguire una sovrapposizione temporale tra diverse fasi di lavoro che vengono svolte su unità<br />
di prodotto diverse. Ma per le istruzioni?<br />
Per una stessa istruzione le varie fasi devono essere svolte in sequenza, però fasi di esecuzioni<br />
diverse possono essere svolte in parallelo su istruzioni diverse: per esempio mentre si fa la<br />
51
decodifica di un’istruzione si può fare il fetch dell’istruzione successiva. Naturalmente il tempo di<br />
esecuzione della singola istruzione non varia, però il tempo medio di esecuzione delle istruzioni si<br />
riduce di un fattore N (nel caso ideale) se tutte le fasi richiedessero lo stesso tempo di esecuzione.<br />
Nel caso del DLX che abbiamo esaminato, se questo potesse andare bene per il pipeline, tutte le fasi<br />
richiedono un periodo di clock e quindi sembrerebbe che tutti gli stadi sono tra di loro bilanciati,<br />
quindi il tempo di esecuzione medio si ridurrebbe di N. Il throughput migliorerebbe di N perché nel<br />
caso pipeline vedremmo uscire un’istruzione ogni ciclo di clock (a regime); questo significa che<br />
avremmo un CPIpipe = 1 (contro un CPIunpipe = N). Se scriviamo la formula del CPUtime nei due casi<br />
abbiamo:<br />
Quindi sostanzialmente abbiamo un fattore di miglioramento pari ad N. Naturalmente questo<br />
avviene nel caso ideale.<br />
Vediamo come si può organizzare il pipeline per l’esecuzione delle istruzioni. In verticale abbiamo<br />
le istruzioni che devono<br />
essere eseguite e in<br />
orizzontale abbiamo i cicli di<br />
clock.<br />
Immaginiamo di fare<br />
riferimento alla versione<br />
sequenziale del DLX.<br />
Nel primo ciclo di clock<br />
viene fatto il fetch<br />
dell’istruzione i; nel secondo<br />
ciclo di clock l’istruzione i passa alla fase di decode, e siccome le risorse hardware che fanno il<br />
fetch sono libere faccio il fetch della seconda istruzione; così dentro il processore ci sono<br />
contemporaneamente due istruzioni:<br />
Procedendo con i cicli di clock arriviamo al quinto ciclo di clock dove esce l’istruzione i. Da questo<br />
momento in poi ogni ciclo di clock ci sarà un write back:<br />
quindi ogni colpo di clock<br />
esce un’istruzione, e di<br />
conseguenza ho un CPI<br />
medio pari a 1.<br />
Bisogna capire se ci sono dei potenziali conflitti sulle risorse.<br />
52
Se manteniamo l’instruction memory e il data memory separati non possono esserci conflitti. In<br />
questo caso l’instruction memory deve essere rispetto a prima 5 volte più veloce perché prima al<br />
massimo leggevo un’istruzione ogni 5 cicli di clock.<br />
Abbiamo visto che nella versione sequenziale durante l’esecuzione il banco dei registri del DLX<br />
veniva usato nella fase di register fetch (secondo ciclo di clock) e nella fase di write back (quinto<br />
ciclo di clock); con una pipeline piena l’istruzione che è nella fase di write back richiederebbe di<br />
accedere al banco dei registri per andare a scrivere un risultato su un registro destinazione, ma<br />
l’istruzione che è al secondo colpo di clock accede ai registri per fare il register fetch; così ho che<br />
due istruzioni diverse usano la stessa risorsa, cioè il banco dei registri, per fare cose diverse.<br />
Un altro problema è quello che riguarda il PC. Prima succedeva che il PC veniva aggiornato al<br />
quarto ciclo di clock; nel caso del pipeline ogni colpo di clock deve essere aggiornato il PC. Ma se<br />
si aggiorna il PC ogni colpo di clock, e per esempio entra un’istruzione di branch che ha la<br />
condizione vera (ma che si sa al quarto ciclo di clock) succede che dopo di questa entrano altre<br />
istruzioni che non dovevano entrare nel processore.<br />
I registri A, B e Imm nello stesso ciclo di clock sono utilizzati nella fase di execution dall’istruzione<br />
i e scritti nella fase di decode dall’istruzione i+1.<br />
L’IR viene scritto nella fase di fetch; questo viene usato in tempi diversi: nella fase di write back un<br />
pezzo di IR serve per dirci qual è il registro destinazione, ma IR nel frattempo è stato sovrascritto<br />
altre quattro volte quindi non ho come recuperare il registro dove scrivere.<br />
Di conseguenza per la versione pipeline il datapath che abbiamo presentato così come è non può<br />
essere utilizzato.<br />
Vediamo una rappresentazione in cui andiamo a rappresentare piuttosto che il nome della fase la<br />
risorsa coinvolta per eseguire quella fase:<br />
entra un’istruzione che coinvolge<br />
l’instruction memory, poi passa<br />
ad utilizzare la risorsa registro e<br />
la risorsa memoria viene usata<br />
dall’istruzione successiva.<br />
Andando avanti, al quarto colpo<br />
di clock se avessimo usato una<br />
memoria unificata avremmo<br />
avuto un conflitto. Al quinto<br />
colpo di clock abbiamo un<br />
conflitto sui registri. Questo si<br />
chiama conflitto strutturale.<br />
Questo conflitto strutturale da<br />
questo punto in poi potrebbe<br />
esserci sempre se c’è una write<br />
back.<br />
Il conflitto strutturale si ha ogni volta che una risorsa viene utilizzata in due fasi diverse per due<br />
istruzioni diverse.<br />
53
Vediamo un programma scritto in assembly:<br />
16/04/2004<br />
; Inizializza un vettore con 5 valori interi e ne visualizza la<br />
somma<br />
; Sezione dati<br />
.data<br />
vett: .word 12<br />
.word 6<br />
.word 19<br />
.word 7<br />
.word 6<br />
msg_somma: .asciiz "\nLa somma e' %d"<br />
.align 2<br />
msg_sm_addr: .word msg_somma<br />
somma: .space 4<br />
.text<br />
.global main<br />
corrisponde a questo indirizzo<br />
main: addi r3,r0,5<br />
addi r2,r0,0<br />
addi r4,r0,0<br />
loop_somma: lw r5,vett(r2)<br />
subi r3,r3,1<br />
add r4,r4,r5<br />
addi r2,r2,4<br />
bnez r3,loop_somma<br />
stampa: sw somma(r0),r4<br />
addi r14,r0, msg_sm_addr<br />
trap 5<br />
fine: trap 0<br />
Ogni programma assembly, in questo caso DLX, inizia con una direttiva specifica: .data.<br />
Questa direttiva vuol dire che da quel punto sta cominciando la sezione in cui noi andiamo ad<br />
allocare i dati del programma, e non le istruzioni. Un’altra cosa importante oltre alle direttive sono<br />
le etichette, che sono delle parole, degli identificatori, con cui noi per comodità indichiamo delle<br />
zone del codice. Quando questo programma verrà trasformato in una serie di parole da mettere in<br />
memoria queste etichette corrisponderanno a degli indirizzi di memoria.<br />
Questo programma memorizza in memoria 5 valori interi, quindi 5 valori a 32 bit. Siccome noi<br />
vogliamo descrivere qual è la zona del codice dove andiamo a depositare questo vettore mettiamo<br />
l’etichetta vett:; è inutile mettere 5 etichette perché con quella sola sappiamo dove si trovano tutti<br />
gli altri elementi del vettore. Subito dopo questa etichetta ci sono delle direttive, .word, che ci<br />
dicono che quello che segue è un numero che deve essere codificato con una parola di 32 bit da<br />
mettere in memoria. Quindi quando il programma verrà avviato se andiamo all’indirizzo di<br />
memoria corrispondente all’etichetta “vett” troveremo quei 5 valori interi. Dopo segue un’altra<br />
54
etichetta: msg_somma:. Questo è un altro dato perché siamo dentro la sezione “.data”. Siccome noi<br />
vogliamo che questo programma ci visualizzi un output abbiamo bisogno di invocare una qualche<br />
funzione. In C abbiamo la printf: questa come parametri ha una stringa di formattazione (“il numero<br />
è: %d”, per esempio) e l’argomento che è il numero da stampare (quello a cui si riferisce %d).<br />
Questa stringa di formattazione non può stare nella parte del codice, ma deve stare da qualche parte<br />
in memoria e poi in qualche modo verrà invocata. Dopo le 5 word del vettore inizia l’allocazione,<br />
tramite la direttiva .asciiz, di una stringa (ci serve la .asciiz perché dobbiamo dire dove finisce la<br />
stringa). Questa stringa può finire in un byte qualunque di una word, quindi ho bisogno di una<br />
direttiva di allineamento, .align 2, perché vogliamo che la prossima cosa che allochiamo, sempre tra<br />
i dati, venga allocata in un indirizzo che è multiplo di 4, cioè all’inizio di una word. In generale la<br />
direttiva .align n fa sì che il successivo indirizzo sia multiplo di 2 n . Subito dopo abbiamo una word<br />
che contiene il valore dell’etichetta msg_somma, ovvero l’indirizzo a cui abbiamo iniziato ad<br />
allocare la stringa (puntatore in C). Successivamente indichiamo che vogliamo lasciati 4 byte liberi<br />
con la direttiva .space 4.<br />
Con la direttiva .text finisce la sezione dei dati e inizia quella del codice vero e proprio del<br />
programma. La direttiva .global dice che l’etichetta che segue è un’etichetta che deve essere visibile<br />
anche ad altri moduli eventualmente linkati col nostro programma.<br />
A partire dall’etichetta main: abbiamo le istruzioni vere e proprie. Siccome noi vogliamo scandire<br />
un vettore e sommarne gli elementi, abbiamo bisogno di un indice che ci dice quanti sono gli<br />
elementi da leggere (in C: for(i=0;i
; Equivalente assembly DLX del codice C :<br />
; printf("Hello! \n real %f , integer %d\n", 1.234, 43543);<br />
.data<br />
msg: .asciiz "Hello! \n real %f , integer %d\n"<br />
.align 2<br />
msg_addr: .word msg<br />
.double 1.234<br />
.word 43543<br />
.text<br />
addi r14,r0,msg_addr<br />
trap 5<br />
trap 0<br />
20/04/2004<br />
N.B. La chiamata della trap altera il valore del registro r1.<br />
Vediamo adesso l’utilizzo di una routine esterna. Immaginiamo che abbiamo la necessità di leggere<br />
da tastiera un numero intero senza segno. Noi teoricamente dovremmo utilizzare la trap associata<br />
alla read. Qualcuno ha utilizzato le chiamate di sistema e ha realizzato il codice il cui risultato è<br />
leggere in un certo registro un valore intero che noi immettiamo da tastiera. Il sorgente di questo<br />
programma è il seguente:<br />
;*********** WINDLX Ex.1: Read a positive integer number *************<br />
;*********** (c) 1991 Günther Raidl *************<br />
;*********** Modified 1992 Maziar Khosravipour *************<br />
;-----------------------------------------------------------------------------<br />
;Subprogram call by symbol "InputUnsigned"<br />
;expect the address of a zero-terminated prompt string in R1<br />
;returns the read value in R1<br />
;changes the contents of registers R1,R13,R14<br />
;-----------------------------------------------------------------------------<br />
.data<br />
;*** Data for Read-Trap<br />
ReadBuffer: .space 80<br />
ReadPar: .word 0,ReadBuffer,80<br />
;*** Data for Printf-Trap<br />
PrintfPar: .space 4<br />
SaveR2: .space 4<br />
SaveR3: .space 4<br />
SaveR4: .space 4<br />
SaveR5: .space 4<br />
InputUnsigned:<br />
.text<br />
.global InputUnsigned<br />
;*** save register contents<br />
sw SaveR2,r2<br />
56
sw SaveR3,r3<br />
sw SaveR4,r4<br />
sw SaveR5,r5<br />
;*** Prompt<br />
sw PrintfPar,r1<br />
addi r14,r0,PrintfPar<br />
trap 5<br />
;*** call Trap-3 to read line<br />
addi r14,r0,ReadPar<br />
trap 3<br />
;*** determine value<br />
addi r2,r0,ReadBuffer<br />
addi r1,r0,0<br />
addi r4,r0,10 ;Decimal system<br />
Loop: ;*** reads digits to end of line<br />
lbu r3,0(r2)<br />
seqi r5,r3,10 ;LF -> Exit<br />
bnez r5,Finish<br />
subi r3,r3,48 ;´0´<br />
multu r1,r1,r4 ;Shift decimal<br />
add r1,r1,r3<br />
addi r2,r2,1 ;increment pointer<br />
j Loop<br />
Finish: ;*** restore old register contents<br />
lw r2,SaveR2<br />
lw r3,SaveR3<br />
lw r4,SaveR4<br />
lw r5,SaveR5<br />
jr r31 ; Return<br />
Noi vogliamo utilizzare questo codice in modo tale da evitare che ogni volta che dobbiamo leggere<br />
un intero senza segno dobbiamo andare ad implementare tutta una serie di cose scomode.<br />
Questo programma definisce un’etichetta globale, in modo tale che se saltiamo a questa etichetta<br />
comincia ad essere eseguito tutto il codice che svolge per noi il compito di leggere da tastiera un<br />
numero senza segno. Per invocare questa procedura faremo un jal (nel registro r31 viene<br />
memorizzato l’indirizzo a cui si dovrà ritornare) : jal InputUnsigned. Noi dobbiamo conoscere<br />
alcune cose: prima che lo chiamiamo dobbiamo settare dei registri e poi dobbiamo sapere in quale<br />
registro memorizza il numero letto da tastiera. Per quanto riguarda l’input dobbiamo mettere in r1<br />
l’indirizzo della stringa di formattazione usata per fare la domanda: R1 indirizzo stringa; per<br />
quanto riguarda l’output abbiamo che il numero letto da tastiera viene memorizzato sempre in r1.<br />
Quando viene utilizzata questa routine avviene che vengono utilizzati dei registri e quindi vengono<br />
cambiati i valori di questi registri: r13 ed r14.<br />
Esempio:<br />
; Questo programma legge 5 numeri e ne visualizza la somma<br />
; Sezione dati<br />
57
.data<br />
vett: .space 20<br />
msg_lett: .asciiz "\nInserire un numero:"<br />
msg_somma: .asciiz "\nLa somma e' %d"<br />
.align 2<br />
msg_sm_addr: .word msg_somma<br />
somma: .space 4<br />
.text<br />
.global main<br />
main: addi r3,r0,5<br />
addi r2,r0, 0<br />
loop_lett: addi r1,r0,msg_lett<br />
jal InputUnsigned<br />
sw vett(r2), r1<br />
addi r2,r2,4<br />
subi r3,r3,1<br />
bnez r3, loop_lett<br />
calcolo: addi r3,r0,5<br />
addi r2,r0,0<br />
addi r4,r0,0<br />
loop_somma: lw r5,vett(r2)<br />
subi r3,r3,1<br />
add r4,r4,r5<br />
addi r2,r2,4<br />
bnez r3,loop_somma<br />
stampa: sw somma(r0),r4<br />
addi r14,r0, msg_sm_addr<br />
trap 5<br />
fine: trap 0<br />
Vediamo adesso un esempio di utilizzo di registri FPR.<br />
Esempio:<br />
;*********** WINDLX Ex.3: Factorial *************<br />
;*********** (c) 1991 Günther Raidl *************<br />
;*********** Modified: 1992 Maziar Khosravipour*************<br />
;--------------------------------------------------------------------------<br />
; Program begin at symbol main<br />
; requires module INPUT<br />
; read a number from stdin and calculate the factorial (type: double)<br />
; the result is written to stdout<br />
;--------------------------------------------------------------------------<br />
.data<br />
Prompt: .asciiz "An integer value >1 : "<br />
58
PrintfFormat: .asciiz "Factorial = %g\n\n"<br />
.align 2<br />
PrintfPar: .word PrintfFormat<br />
PrintfValue: .space 8<br />
main:<br />
.text<br />
.global main<br />
;*** Read value from stdin into R1<br />
addi r1,r0,Prompt<br />
jal InputUnsigned<br />
;*** init values<br />
movi2fp f10,r1 ;R1 -> D0 D0..Count register<br />
cvti2d f0,f10<br />
addi r2,r0,1 ;1 -> D2 D2..result<br />
movi2fp f11,r2<br />
cvti2d f2,f11<br />
movd f4,f2 ;1-> D4 D4..Constant 1<br />
;*** Break loop if D0 = 1<br />
Loop: led f0,f4 ;D0
Vediamo la versione pipeline del DLX:<br />
22/04/2004<br />
Questa versione somiglia molto a quella sequenziale, ma tra i vari stadi vengono interposti dei<br />
blocchi che si chiamano pipeline register. Molti dei problemi che abbiamo evidenziato la scorsa<br />
volta sono relativi al fatto che contemporaneamente io utilizzo la stessa risorsa per istruzioni di<br />
verse. Per evitare questo tipo di problema, se io per esempio sono nello stadio di execution e quindi<br />
mi servono i valori di A e di B che avevo scritto nella fase di register fetch, se questi valori li<br />
conservo da qualche parte libero A e B per poterci scrivere di nuovo. Ogni volta che io leggo<br />
un’istruzione il registro IR viene scritto, e allora questo IR lo conservo e lo faccio viaggiare assieme<br />
all’istruzione, così quello che serve all’istruzione se lo porta dietro. È come se questo parallelismo<br />
nell’esecuzione delle istruzioni da un punto di vista logico richiedesse che ogni fase eseguita<br />
all’interno della pipe su una determinata istruzione avesse bisogno del proprio contesto. Per<br />
realizzare questo tipo di operazione sono stati introdotti questi pipiline register. Quando io scrivo su<br />
IR, questo diventa un campo del pipeline register. Questi pipeline register hanno come campi i<br />
registri che usavamo nella versione sequenziale. Ogni pipeline register ha un suo nome: IF/ID<br />
(instruction fetch/instruction decode), cioè il registro pipeline interfaccia tra lo stadio di fetch e<br />
quello di decode; ID/EX (instruction decode/execute); EX/MEM; MEM/WB.<br />
Facendo in questo modo molti dei problemi visti vengono risolti, ma non tutti.<br />
Adesso passo passo andiamo ad analizzare<br />
cosa succede nella versione pipeline.<br />
All’inizio ho il PC che indirizza<br />
l’instruction memory; il contenuto di<br />
questa va copiato all’interno del pipeline<br />
register, e in particolare nel campo IR di<br />
questo registro: IF/ID.IR Mem[PC].<br />
Questo significa che IR, che è un registro<br />
a 32 bit è un campo di IF/ID, e a questo<br />
campo gli assegno come valore quello che<br />
ho letto dalla memoria all’indirizzo del<br />
PC.<br />
60
A differenza di quanto avveniva nella<br />
versione sequenziale del DLX stavolta<br />
sono costretto ad aggiornare il PC<br />
immediatamente, cioè dopo aver letto<br />
l’istruzione. Questo lo devo fare perché<br />
il prossimo colpo di clock devo leggere<br />
un’altra istruzione. In particolare a<br />
seconda del valore della condizione che<br />
c’è nel registro EX/MEM devo<br />
aggiornare il PC o con PC+4 o con un<br />
altro indirizzo se la condizione<br />
dell’istruzione, che si trova nella fase di<br />
execute e che vado a valutare nella fase<br />
di MEM, è vera (quindi avevo un<br />
branch):<br />
IF/ID.NPC,PCif(EX/MEM.cond)(EX/<br />
MEM.ALUOutput) else (PC+4).<br />
Quindi ogni volta che leggo<br />
un’istruzione devo aggiornare sia il PC che il NPC; entrambi li aggiorno o sommando 4 al quello<br />
che già era il PC oppure andando a copiare il valore di indirizzo target calcolato per un’istruzione<br />
che eventualmente già era entrata nel pipeline e che era un’istruzione di branch. Questo significa<br />
che l’esito di un’istruzione di branch lo conosco soltanto qua; ma così nel frattempo sono entrate<br />
altre istruzioni agli indirizzi successivi che non dovevano entrare.<br />
Nella fase di decodifica in parallelo avvengono due cose: la decodifica dell’istruzione e il register<br />
fetch.<br />
Adesso l’IR che si trova nel pipeline<br />
register IF/ID mi serve per indirizzare il<br />
banco dei registri, fare il register fetch e<br />
andare a produrre i valori da memorizzare<br />
su A, B e Imm (preceduto dall’estensione<br />
in segno):<br />
ID/EX.A Regs[IF/ID.IR6..10]<br />
ID/EX.B Regs[IF/ID.IR11..15]<br />
ID/EX.Imm(IF/ID.IR16)##IF/ID.IR16..32<br />
Se succedesse solo questo quando vado<br />
avanti entra una nuova istruzione che va a<br />
scrivere su IR, quindi perderei l’IR<br />
dell’istruzione che si trova nella fase di<br />
decode. Per evitare questo nella fase di<br />
decode ricopio anche l’IR e il NPC.<br />
Andiamo alla fase di execution. Come sappiamo questa fase può riguardare diverse operazioni a<br />
seconda del codice operativo. In particolare possiamo avere un’istruzione ALU (register-register<br />
oppure register-immediate), un’istruzione Load/Store, oppure un Branch.<br />
Vediamo cosa accade in ognuno di questi casi.<br />
61
Se è un’istruzione ALU register-register<br />
nel campo ALUOutput del registro<br />
pipeline EX/MEM viene messo il<br />
risultato dell’operazione; nel caso in cui<br />
è un’istruzione ALU register-immediate<br />
avviene la stessa cosa con la differenza<br />
che non vengono utilizzati gli operandi<br />
A e B, ma A e Imm:<br />
1) EX/MEM.ALUOutput ID/EX.A<br />
func ID/EX.B<br />
2) EX/MEM.ALUOutput ID/EX.A<br />
op ID/EX.Imm<br />
Sempre nell’ipotesi che si tratti di un’istruzione ALU devo propagare IR e devo settare a 0 il<br />
registro di condizione; setto a zero questo registro perché essendo un’istruzione ALU non devo<br />
preoccuparmi di verificare la<br />
condizione, però da questo valore<br />
dipende l’aggiornamento del PC e<br />
settando a 0 questo registro il PC<br />
verrà incrementato di 4:<br />
EX/MEM.IR ID/EX.IR<br />
EX/MEM.Cond 0<br />
N.B. Non è necessario copiare il NPC<br />
perché questo se serve serve nella<br />
fase di execution per calcolare<br />
l’indirizzo di salto e non nelle<br />
successive.<br />
Se non è una ALU instruction ma una Load/Store avviene la stessa cosa che avveniva per la<br />
versione sequenziale (calcolare l’indirizzo<br />
per accedere al prossimo stadio alla<br />
memoria); inoltre essendo un’istruzione di<br />
load/store devo settare a 0 il registro di<br />
condizione e portare avanti il campo B:<br />
EX/MEM.IR ID/EX.IR<br />
EX/MEM.ALUOutput ID/EX.A +<br />
ID/EX.Imm<br />
EX/MEM.cond 0<br />
EX/MEM.B ID/EX.B<br />
62
Nell’ipotesi in cui sia un’istruzione di<br />
salto nella fase di execution calcolerò il<br />
valore della condizione e il valore<br />
dell’indirizzo effettivo a cui saltare nel<br />
caso si verifichi la condizione:<br />
EX/MEM.ALUOutput ID/EX.NPC +<br />
ID/EX.Imm<br />
EX/MEM.cond ID/EX.A op 0<br />
Ovviamente ricopio anche l’IR:<br />
EX/MEM.IR ID/EX.IR<br />
Passando alla fase di Memory access mi sposto il registro IR; se l’istruzione che è entrata nella fase<br />
di MEM è un’istruzione ALU sposto il campo ALUOutput:<br />
MEM/WB.IR EX/MEM.IR<br />
MEM/WB.ALUOutput EX/MEM.ALUOutput<br />
Se è un’istruzione di Load/Store nella fase di MEM devo o leggere o scrivere la memoria:<br />
MEM/WB.IR EX/MEM.IR<br />
MEM/WB.LMD Mem[EX/MEMALUOutput]<br />
oppure<br />
Mem[EX/MEMALUOutput] EX/MEM.B<br />
63
Nella fase di Write Back possono succedere due cose a seconda che sia un’istruzione ALU o<br />
un’istruzione Load. In entrambi i casi vado a fare la scrittura del risultato sul banco dei registri.<br />
Nel caso di un’istruzione ALU abbiamo:<br />
Nel caso di un’istruzione di Load abbiamo:<br />
Regs[MEM/WB.IR 16..20] MEM/WB.ALUOutput<br />
oppure<br />
Regs[MEM/WB.IR 11..15] MEM/WB.ALUOutput<br />
Regs[MEM/WB.IR11..15] MEM/WB.LMD<br />
Nella fase di write back per indirizzare il registro destinazione sul banco dei registri ho bisogno di<br />
alcuni bit del registro IR di questa stessa istruzione; ecco perché mi trasporto il registro IR fino alla<br />
fase di write back.<br />
Dobbiamo vedere come passare dall’architettura sequenziale a quella pipeline.<br />
Ci sono vari problemi. Sostanzialmente ci sono tre problemi che sono quelli che vengono chiamati<br />
Hazards.<br />
I registri vengono letti ogni volta nella fase di decode e vengono scritti ogni colpo di clock per<br />
l’istruzione che si trova nella fase di write back; questo ci dà un conflitto strutturale. Lo stesso tipo<br />
di conflitto c’è se la memoria è unificata. Questi si chiamano structural hazards (hazards<br />
strutturali), cioè sostanzialmente legati al problema che la stessa risorsa viene utilizzata per<br />
istruzioni diverse per fare operazioni diverse.<br />
Poi ci sono i control hazards, che sono legati all’aggiornamento del PC: come si fa quando è<br />
entrata un’istruzione di branch, visto che l’esito di questa istruzione lo conosco nella fase di MEM e<br />
nel frattempo sono entrate altre tre istruzioni? L’azzardo consiste nell’aver fatto un fetch ogni ciclo<br />
di clock.<br />
Infine c’è quello che viene chiamato data hazard, che è legato al problema della dipendenza fra i<br />
dati: se per esempio ho due istruzioni consecutive che utilizzano un registro, e l’istruzione che entra<br />
64
per prima produce il valore di questo registro (operando destinazione), mentre l’istruzione che entra<br />
per seconda consuma il valore di questo registro (operando sorgente), si ha che il valore di quel<br />
registro viene prodotto nella fase di write back per la prima istruzione, ma quando questa istruzione<br />
è nella fase di write back la seconda istruzione è nella fase di execution, quindi ha già utilizzato il<br />
contenuto del registro che non è quello corretto<br />
i add r1,r2,r3 ← r1 viene utilizzato come registro destinazione<br />
i+1 add r5,r6,r1 ← r1 viene utilizzato come registro sorgente<br />
Quindi l’architettura pipeline avrebbe sconvolto la logica di esecuzione rispetto a quella prevista nel<br />
programma fatto dal programmatore.<br />
Hazard Strutturali<br />
Vediamo per ogni colpo di clock quali sono le risorse del processore utilizzate dalle varie istruzioni<br />
all’interno della pipe.<br />
Al primo ciclo di clock viene coinvolta la memoria (che immaginiamo unificata); al secondo colpo<br />
di clock la prima istruzione entra nella fase di decode, e quindi la risorsa coinvolta è Reg, e la<br />
seconda istruzione coinvolge la MEM per il fetch; al terzo colpo di clock abbiamo tre istruzioni<br />
dentro il pipeline: la prima istruzione utilizza l’ALU, la seconda coinvolge i registri e la terza<br />
utilizza la MEM. Al quarto colpo di clock se la prima istruzione è una Load o una Store utilizzerà la<br />
MEM, e quindi ci sarà un conflitto con l’istruzione che deve fare il fetch. Questo è un hazard<br />
strutturale.<br />
Poiché la prima istruzione è già dentro, quello che si può<br />
fare è ritardare il fetch di un ciclo di clock, in modo tale<br />
che la prima istruzione faccia l’accesso in memoria, la<br />
libera e poi si può fare il fetch dell’altra; questo significa<br />
ritardare tutto di un colpo di clock. Così la quarta<br />
istruzione entrerà nel quinto ciclo di clock. Si dice che<br />
abbiamo introdotto uno stallo, ovvero è stato stallato per<br />
un ciclo di clock il pipeline. Se la seconda istruzione<br />
fosse una Load/Store si introdurrebbero due stalli.<br />
65
Un’altra rappresentazione è la seguente:<br />
Vediamo da un punto di vista concreto come si fa ad introdurre uno stallo.<br />
Supponiamo che nel nostro pipeline sia entrata un’istruzione di Load o di Store e che sia arrivata<br />
nella fase di execution:<br />
Non appena questa istruzione arriva nella fase di MEM si genererebbe un conflitto con l’istruzione<br />
che entra nella fase di fetch (i+3):<br />
Per introdurre uno stallo noi dobbiamo fare in modo che il fetch dell’istruzione i+3 venga fatto al<br />
prossimo colpo di clock. Il PC contiene l’indirizzo dell’istruzione i+3 e con questo indirizzerebbe la<br />
66
memoria, ma non lo deve fare perché nel frattempo la memoria è indirizzata dall’ALUOutput che<br />
mi dice se deve fare una Load o una Store; quindi è come se io disabilitassi l’indirizzamento della<br />
memoria da parte del PC; ma il PC quando finisce la fase di fetch si incrementerebbe all’indirizzo<br />
di i+4, ma così i+3, che non è stata fatta avanzare, verrebbe persa. Quindi devo impedire che il PC<br />
si incrementi, e per fare questo invece che sommare 4 gli sommo 0. Quindi al prossimo colpo di<br />
clock faccio il fetch dell’istruzione i+3 che prima non era riuscito a fare; ovvero l’istruzione i+3<br />
non è stata scritta sul registro IR, ma su questo è stata scritta una Not operation (un’istruzione che<br />
non fa niente):<br />
Per eliminare il conflitto sulla memoria basta utilizzare memorie saparate. Per quanto riguarda i<br />
registri abbiamo un conflitto strutturale perché un’istruzione li usa nella fase di decode e una nella<br />
fase di write back. Per risolvere questo problema vengono utilizzate delle tecniche per<br />
implementare i registri che consentono a questi di essere letti e scritti all’interno di un ciclo di<br />
clock; in particolare nella prima metà del ciclo di clock si esegue la scrittura (write back) e nella<br />
seconda si esegue la lettura (register fetch). Con queste due tecniche abbiamo eliminato qualsiasi<br />
tipo di hazard strutturale.<br />
Data hazard<br />
Supponiamo di avere il seguente segmento di codice:<br />
nella prima istruzione r1 è<br />
un operando destinazione;<br />
in tutte le altre istruzioni r1<br />
è un operando sorgente. Il<br />
valore di r1 viene prodotto<br />
nella fase di write back<br />
della prima istruzione<br />
(viene aggiornato il<br />
registro), ovvero nel quinto<br />
ciclo di clock. Alla<br />
seconda istruzione r1 serve<br />
nella fase di register fetch<br />
ovvero nel terzo ciclo di<br />
clock, quindi il valore di r1<br />
che vado a leggere non è<br />
quello aggiornato e di<br />
conseguenza la seconda<br />
istruzione non verrà<br />
67
eseguita correttamente. Alla terza istruzione r1 serve nel quarto ciclo di clock quindi anche questa<br />
istruzione non viene eseguita correttamente. Alla quarta istruzione r1 serve al quinto ciclo di clock,<br />
e se utilizziamo la tecnica di scrivere nella prima metà del ciclo di clock e leggere nella seconda<br />
metà questa istruzione viene eseguita correttamente. La quinta istruzione viene eseguita<br />
correttamente.<br />
Siccome non posso permettermi di eseguire le istruzioni in modo non corretto devo introdurre degli<br />
stalli: quando faccio il register fetch di un registro ancora non corretto devo evitare che questo<br />
valore si propaghi alla fase successiva; questo è come dire che io ritardo la fese di register fetch fino<br />
a quando non sono sicuro che il valore che andrò a leggere non sia quello corretto:<br />
una volta che ho il valore corretto di r1 posso andare avanti con l’istruzione sub r4,r1,r5:<br />
Facendo così ho perso due colpi di clock (ho introdotto due stalli), perché piuttosto che fare un<br />
decode ne ho dovuti fare tre.<br />
Supponiamo di avere una situazione del seguente tipo:<br />
l’istruzione I–2 nella fase di<br />
MEM, l’istruzione I–1 nella<br />
fase di execution, l’istruzione<br />
I nella fase di decode e<br />
l’istruzione I+1 nella fase di<br />
fetch.<br />
Se c’è un data hazard si<br />
verifica con qualcosa che<br />
avviene nella fase di decode,<br />
perché è qui che faccio il<br />
register fetch, e mi preoccupo<br />
che il register fetch che sto<br />
per fare possa non essere<br />
quello corretto, ovvero leggo<br />
un registro sorgente che deve essere ancora prodotto, cioè è destinazione in un’istruzione che è più<br />
avanti nel pipeline. L’istruzione da cui c’è una dipendenza può stare o nella fase di execution o<br />
nella fase di MEM. Quindi potenzialmente io so che in questo tipo di pipeline il problema del data<br />
hazard si può porre tra l’istruzione che è nella fase di decode e le istruzioni che sono nelle fasi di<br />
execution e MEM. Come faccio a scoprire se c’è un problema di data hazard? Basta andare a vedere<br />
se gli operandi sorgenti dell’istruzione I sono operandi destinazione delle istruzioni I–1 e I–2. Se c’è<br />
68
una dipendenza tra I e I–2 devo aspettare un colpo di clock, mentre se la dipendenza è tra I e I–1<br />
devo aspettare due colpi di clock. Supponiamo che la dipendenza sia tra I e I–1, quando la I–1 si<br />
sposta in avanti la I non può spostarsi, ma qualcosa deve avanzare, e questo qualcosa è una not<br />
operation. Quando viene eseguita la fase di write back per l’istruzione I–1 posso fare il register<br />
fetch per la I, ma per fare questo mi occorre che nel registro pipeline IF/ID ci sia l’istruzione I;<br />
allora devo impedire che IR venga scritto a causa delle instruction fetch che possono avvenire<br />
durante quei due cicli di clock, e poi devo impedire che il PC venga incrementato per non perdere le<br />
istuzioni I+1 e I+2. Per fare questo bisogna “prendere in giro” tutto un pezzo di hardware: quando<br />
la logica di controllo andando a controllare se gli operandi sorgente dell’istruzione I dipendono<br />
dagli operandi destinazione di I–1 e di I–2, trova questa dipendenza (e quindi sa che deve introdurre<br />
uno o due stalli), impedisce all’istruzione I e all’istruzione I+1 di propagarsi, e mette 0 al posto di 4<br />
(per l’incremento del PC).<br />
69
23/04/2004<br />
Abbiamo detto che riusciamo a capire se ci può essere un data hazard analizzando la dipendenza tra<br />
l’istruzione che si trova nella fase di decode e le istruzioni che sono negli stage di execution e di<br />
MEM. Poi a fronte della detection di un hazard bisogna provvedere a introdurre degli stalli (può<br />
essere uno o possono essere due). Introdurre uno stallo significa fare in modo che il register fetch<br />
avvenga soltanto quando il write back l’istruzione con cui c’è la dipendenza è avvenuto.<br />
Vediamo come si fa: supponiamo che tra l’istruzione i+1 e l’istruzione i ci sia un data hazard,<br />
quindi ci mettiamo nelle condizioni in cui bisogna introdurre due cicli di stallo<br />
A questo punto nello stadio di fetch bisogna impedire che s’incrementi il PC (il 4 bisogna farlo<br />
diventare 0),e bisogna impedire che venga scritto il campo IR del registro IF/ID; nella fase di<br />
decode si forza una not operation e bisogna impedire che la fase di register fetch venga completata,<br />
cioè che i registri che vengono letti a fronte della decodifica vanno a finire sul pipeline register<br />
ID/EX, e lo stesso vale per l’immediate:<br />
Dopodiché la not operation va nello stadio di execution e si ripete la stessa procedura di prima:<br />
70
a questo punto ho due not operation che si propagano, e quindi sto perdendo due cicli di clock:<br />
A questo punto si può sbloccare tutto e la i+2 può avanzare:<br />
Quello che abbiamo illustrato è un modo per tamponare situazioni di emergenza che potrebbero<br />
portare alla non corretta esecuzione del programma. L’unico rimedio che abbiamo evidenziato è<br />
quello di introdurre dei cicli di stallo, cioè penalizzare le prestazioni.<br />
C’è qualche soluzione alternativa all’introduzione dei cicli di stallo? C’è qualcos’altro che penalizzi<br />
meno le prestazioni, ovvero che introduca meno cicli di stallo?<br />
Una di queste soluzioni, che poi tipicamente è la soluzione che si utilizza, è la seguente: quando<br />
abbiamo la dipendenza tra l’istruzione che si trova nella fase di decode e quella che si trova nello<br />
stadio di execution normalmente bisogna aspettare fintanto che l’istruzione che è più avanti non<br />
arrivi alla fase di write back e scriva il risultato nei registri e a quel punto può avanzare l’istruzione<br />
successiva; ma quando l’istruzione che produce il risultato si trova alla fine della fase di execution<br />
mette il risultato nel campo ALUOutput del registro EX/MEM; quindi perché bisogna aspettare altri<br />
due cicli di clock per averlo? C’è qualche soluzione per cui lo prendo subito e quindi aspetto meno?<br />
Questo viene fatto, cioè se il risultato di un’operazione è già disponibile si riesce a prendere<br />
anticipando la fase di write back, che nonostante ciò avviene correttamente lo stesso:<br />
71
supponiamo di avere la situazione<br />
a sinistra; si vede che c’è una<br />
dipendenza tra la prima istruzione<br />
e tutte le seguenti. Quando la<br />
prima istruzione arriva nella fase<br />
di execution e quindi<br />
l’ALUOutput contiene il valore<br />
corretto di R1, prendo questo<br />
valore e lo forzo all’ingresso<br />
dell’ALU in modo tale che sia<br />
disponibile per l’istruzione<br />
successiva. Questa tecnica si<br />
chiama forwarding, cioè anticipo<br />
la fornitura del risultato<br />
all’istruzione successiva. Lo<br />
stesso discorso si fa per la terza<br />
istruzione con la differenza che<br />
stavolta il valore di R1 si trova nel campo ALUOutput del registro MEM/WB. Facendo in questo<br />
modo non ho bisogno di introdurre alcuno stallo.<br />
C’è un caso in cui non riusciamo ad eliminare completamente gli stalli.<br />
Supponiamo che il processore pipeline è stato dotato di forwarding, e supponiamo che il codice sia<br />
il seguente:<br />
in questo caso il problema è che<br />
mi serve R1 all’ingresso<br />
dell’ALU al quarto ciclo di<br />
clock; ma R1 viene prodotto<br />
dalla load alla fine della sua<br />
fase di MEM, cioè alla fine del<br />
quarto ciclo di clock, quindi a<br />
me serve qualcosa che avverrà<br />
nel futuro. Questo comporta che<br />
non posso fare il forwarding,<br />
quindi devo fare scattare un<br />
altro ciclo; quello che si fa<br />
allora è introdurre una bolla, e<br />
quindi la fase di execution la<br />
faccio avvenire un colpo di<br />
clock dopo:<br />
fatto questo fornisco all’ingresso<br />
dell’ALU il valore dopo averlo<br />
calcolato e quindi alla fine pago un<br />
ciclo di clock. Questo significa che<br />
malgrado sia attivo il forwarding ci<br />
sono dei casi, in particolare quando<br />
ho una load seguita da un’altra<br />
istruzione che usa il risultato della<br />
load, in cui devo introdurre un ciclo<br />
di clock di stallo.<br />
72
Vediamo come si implementa il forwarding:<br />
Sia quando c’è una dipendenza fra due istruzioni adiacenti sia tra due istruzioni distanziate (di due)<br />
noi ci troviamo a fare, quando usiamo il forwarding, una retroazione dal registro ALUOutput verso<br />
l’ingresso dell’ALU; il registro ALUOutput può stare o sul registro pipeline EX/MEM oppure sul<br />
MEM/WB; questo registro può andare o in un ingresso dell’ALU o nell’altro. Per fare questo metto<br />
due multiplexer più grandi rispetto a quelli che c’erano prima in modo tale che posso decidere cosa<br />
fare arrivare all’ingresso dell’ALU.<br />
Quindi ci sono dei casi in cui quando ci sono dei data hazard bisogna introdurre uno stallo; si può<br />
trovare una qualche soluzione che anche in questa eventualità io posso risparmiarmi questo ciclo di<br />
clock di stallo? A livello hardware no. A livello software c’è qualcosa che si può fare? Ovvero il<br />
compilatore può fare qualcosa? Il compilatore è qualcosa che ha progettato qualcuno che sa che<br />
sotto c’è un’architettura pipeline e di conseguenza sa come funziona, e sa che ogni volta che c’è<br />
un’istruzione del tipo LW Rc, c e dopo un’istruzione del tipo ADD Ra, Rb, Rc ci sarà un data<br />
hazard dovuto al fatto che Rc nella prima è un registro destinazione e nella seconda è un registro<br />
sorgente. Siccome il compilatore ha la responsabilità, ma anche il potere di decidere quali istruzioni<br />
del set d’istruzioni utilizzare e in quale sequenza, se ci sono delle alternative nella compilazione che<br />
possono produrre un’ottimizzazione, potrebbe adottare queste alternative. Vediamo quali sono le<br />
alternative che si possono fare.<br />
Supponiamo che il compilatore deve tradurre le seguenti istruzioni C:<br />
a = b + c;<br />
d = e – f;<br />
Il modo più semplice di tradurre questo codice in Assembler, tipo quello del DLX, è il seguente<br />
(ricordiamo che il processore ha un’architettura di tipo load/store e quindi le variabili sono in<br />
memoria):<br />
LW Rb, b<br />
LW Rc, c<br />
ADD Ra, Rb, Rc<br />
SW a, Ra<br />
LW Re, e<br />
LW Rf, f<br />
SUB Rd, Re, Rf<br />
SW d, Rd<br />
73
In questo codice ci sono dei data hazard che non riesco a risolvere col forwarding. Quello sopra è<br />
quello che si chiama slow code, cioè è quello che produce dei cicli di stallo. Vediamo la versione<br />
ottimizzata, fast code:<br />
LW Rb, b<br />
LW Rc, c<br />
LW Re, e al posto di fare ADD Ra, Rb, Rc faccio LW Re, e, cioè ho messo<br />
ADD Ra, Rb, Rc un’istruzione nel mezzo tra le due istruzioni che creano il data<br />
LW Rf, f hazard<br />
SW a, Ra metto questa tra LW Rf, f e SUB Rd, Re, Rf in modo che non si<br />
SUB Rd, Re, Rf crei il data hazard<br />
SW d, Rd<br />
Questo codice è più veloce e impiega due cicli di clock in meno rispetto al primo.<br />
Vediamo delle analisi fatte su campo per capire cosa significa utilizzare queste tecniche di<br />
compilazione per ridurre gli stalli:<br />
In rosso c’è l’ottimizzazione,<br />
in verde non c’è<br />
l’ottimizzazione. Abbiamo<br />
tre benchmark: gcc, spice,<br />
tex. Sulle ascisse abbiamo la<br />
percentuale di load che<br />
stallano il pipeline. Si vede<br />
come nel caso del gcc si<br />
passa dal 54% al 31% di load<br />
che stallano il pipeline. Nel<br />
caso di spice si passa dal<br />
42% al 14% e nel caso di tex<br />
dal 65% al 25%.<br />
Vediamo come si misura la performance in un pipeline. Nel nostro caso il tipo di ragionamento che<br />
utilizziamo è il seguente: se abbiamo una versione sequenziale, per esempio del DLX, in cui si<br />
impiegano da 4 a 5 cicli di clock per eseguire un’istruzione; quando questa versione la si rende<br />
pipeline cosa ci si guadagna? Ragioniamo in termini di speedup:<br />
I due periodi di clock sono normalmente diversi perché il pipeline richiede hardware aggiuntivo<br />
rispetto alla versione sequenziale, e questa aggiunta significa anche probabilmente latenze<br />
maggiori. Ciononostante trascuriamo questa differenza tra i due periodi dei cicli di clock. Il CPIPIPE<br />
è il CPI che mediamente ottengo nella versione pipeline. Questo lo posso scrivere come la somma<br />
di due contributi: caso ideale CPIIDEAL = 1 e CPI non ideale (numero di clock per istruction dovuti<br />
agli stalli: per esempio se avessi 327 stalli su un totale di un milione di cicli di clock questo numero<br />
vale 327/1.000.000):<br />
Il CPIUNP, che vale tra 4 e 5, lo approssimiamo con la profondità del pipeline, ovvero col numero di<br />
stage, che è 5.<br />
Questa formula è stata ricavata per un caso particolare: pipeline bilanciato.<br />
Il pipeline produce un aumento del throughput: incrementa il numero di istruzioni eseguite<br />
nell’unità di tempo e questo comporta una diminuzione del tempo medio di esecuzione delle<br />
(*)<br />
74
istruzioni, e questo significa che un programma gira in meno tempo anche se la singola istruzione<br />
non viene eseguita più velocemente.<br />
Control hazard<br />
Abbiamo detto che il control hazard si verifica quando c’è un branch. In questo caso bisogna<br />
stallare il pipeline:<br />
Facendo così ho perso tre cicli di clock: il primo fetch e i due stalli.<br />
Supponiamo che in un programma ci sono il 30% di branch; questo significa che nel 30% dei casi<br />
devo introdurre tre clock di stallo. Applichiamo la formula del pipeline per misurare lo speedup (*):<br />
Speedup = 5/(1 + 3*0.3) ≅ 2.5, cioè ho una penalizzazione delle prestazioni di circa il 50% a causa<br />
dei branch.<br />
Una prima cosa che si può fare per cercare di minimizzare questa penalizzazione è quella di fare<br />
una modifica all’hardware del DLX: il problema dei tre cicli di stallo nasce dal fatto che io conosco<br />
nella fase di MEM l’esito del salto; se io lo conoscessi prima introdurrei meno stalli. Quando potrei<br />
sapere se il salto è preso oppure no? Intanto devo sapere che è un salto e poi pormi il problema se è<br />
preso oppure no. Quindi non posso che farlo nella fase di decode. Nella fase di decode so che ho un<br />
salto, ma nel frattempo potrei calcolare la condizione e l’indirizzo target; questo lo posso fare<br />
soltanto se metto dell’hardware aggiuntivo nella fase di decode:<br />
75
Quindi sposto il calcolo della condizione nella fase di decode e metto un altro ALU per calcolare<br />
l’indirizzo target. A questo punto se io so che è un branch ho già l’esito, ho l’indirizzo target, e<br />
quindi devo introdurre solo un ciclo di clock di stallo: Speedup = 5/(1 + 1*0.3) ≅ 3.9.<br />
Ci sono diversi modi per cercare di ridurre ulteriormente gli stalli.<br />
Predict not taken<br />
Da questo momento l’architettura che consideriamo è l’ultima vista: faccio la detection dello zero e<br />
il calcolo dell’indirizzo target nel secondo ciclo di clock; nel frattempo il fetch che avevo fatto lo<br />
dovrei ripetere, è questo lo stallo; se questo fetch è stato fatto e scopro nel frattempo che questo<br />
fetch è quello giusto, perché il salto non è preso, perché devo rifare il fetch? È come dire che faccio<br />
funzionare il processore come se lui si aspettasse che il salto non venga preso. Per questo si chiama<br />
“predict not taken”, cioè io predico che il salto non sia preso. Se effettivamente il salto non è preso<br />
non si perde nessun ciclo di clock:<br />
Dovessi scoprire nella fase di decode che il salto è preso si deve far propagare una not operation e si<br />
fa il fetch all’indirizzo target:<br />
Abbiamo visto che se io introducessi sempre lo stallo lo speedup sarebbe: Speedup = 5/(1+0.3)≅3.9.<br />
Supponiamo che ho il 30% di branch e scopro che il 50% è taken e il 50% è untaken. Con la tecnica<br />
del predict not taken posso abbattere ulteriormente questo valore, che mi esprime il numero di cicli<br />
di clock di stallo per instruction; in questo caso quando il salto non è preso non ho dei cicli di clock<br />
di stallo, quindi nel 50% del 30% invece devo introdurre uno stallo; quindi il denominatore diventa:<br />
1 + 0.3 × 0.5 × 1. Questo significa che sto migliorando ulteriormente le performance.<br />
Nel data hazard abbiamo scoperto che se riuscivamo a riorganizzare il codice potevamo ridurre il<br />
numero di stalli. È possibile anche nel caso del control hazard ristrutturare il codice per cercare di<br />
diminuire il numero di cicli di clock di stallo da introdurre? La risposta è sì. La tecnica del Delayed<br />
branch (delay slot) dice questo: quando si fa un branch e si è nella sua fase di decode nel frattempo<br />
si fa un fetch di un’altra istruzione; non si può fare in modo che sia sempre un fetch utile anche se<br />
non è il fetch dell’indirizzo target, se il salto è preso? Questo clock che viene subito dopo il branch<br />
si chiama delay slot. Se il salto viene preso verrà preso due colpi di cicli di clock dopo, ma quel<br />
ciclo ci clock intermedio è stato usato per un’istruzione che doveva comunque essere eseguita; il<br />
risultato è che dal pipeline io vedo uscire sempre un’istruzione e non uno stallo.<br />
Supponiamo che abbiamo un’istruzione di branch, di cui conosco l’esito nella fase di decode, se io<br />
(compilatore) ristrutturo il codice in modo che dopo il branch metto un’istruzione che comunque ha<br />
76
senso fare, sia che il salto sia preso sia che il salto non sia preso, ho risolto il problema.<br />
Consideriamo il caso del salto non preso:<br />
Mentre faccio il decode del branch vado a fare il fetch dell’istruzione successiva che può andare<br />
avanti; se il salto è non preso dovrò fare l’istruzione successiva al branch, cioè l’istruzione i+2, che<br />
è quella che seguiva il branch prima della ristrutturazione del codice.<br />
Se il salto invece viene preso non cambia niente:<br />
L’istruzione che segue l’istruzione che il compilatore ha messo subito dopo il branch sarà il branch<br />
target.<br />
Quindi nei due casi io comunque ho eseguito l’istruzione i+1, cioè ho fatto entrare nella pipe<br />
quell’istruzione, che ha fatto sì che non mi ha fatto introdurre nessun ciclo di stallo.<br />
Vediamo quali sono i casi che si possono verificare.<br />
Supponiamo di avere il seguente segmento di codice:<br />
subito dopo il branch (if R2=0 then) c’è un delay slot che sarebbe il ciclo di<br />
clock successivo in cui bisogna decidere quale istruzione fare entrare nel<br />
pipeline. Il compilatore vede che l’istruzione ADD R1,R2,R3 è indipendente<br />
dall’istruzione successiva dato che genera R1 come operando destinazione.<br />
Allora se questa istruzione la metto subito dopo il branch, cioè significa che<br />
ogni volta che eseguo il branch sicuramente eseguo anche questa, cambia<br />
qualcosa nel programma? Cambierebbe qualcosa se a volte la eseguo e a<br />
volte no, ma viene eseguita sempre. Quindi tutte le<br />
volte che il compilatore trova che l’istruzione che precede il branch non<br />
dipende da quest’ultimo la mette subito dopo e quindi ha risolto il problema.<br />
In poche parole inverte il branch con l’istruzione che la precede, e quindi<br />
quello slot di tempo che potrebbe provocare uno stallo, a questo punto non<br />
provoca alcuno stallo, perché tanto vado ad eseguire un’istruzione che<br />
comunque doveva essere eseguita. Quando ho un codice di questo tipo nel<br />
100% dei casi non ho bisogno di introdurre stalli.<br />
Supponiamo di avere il seguente codice:<br />
stavolta non è possibile fare quello fatto sopra perché l’istruzione che<br />
precede il branch produce un risultato che è sorgente nell’istruzione<br />
successiva, quindi di fatto c’è una dipendenza, di conseguenza non posso<br />
mettere l’istruzione ADD R1,R2,R3 dopo il branch perché non saprei come<br />
fare a vedere se R1 è uguale a zero oppure no. Supponiamo che il<br />
compilatore sappia che è molto probabile che il salto venga preso, allora<br />
77
prende l’istruzione che è all’indirizzo target e la mette subito dopo il branch<br />
ricordando che non deve saltare più alla stessa istruzione, ma all’indirizzo<br />
successivo, perché altrimenti verrebbe eseguita due volte per ogni ciclo.<br />
Quindi il compilatore copia quell’istruzione anche dopo il branch, e non la<br />
sposta perché a quell’istruzione posso arrivare anche da altre vie del<br />
programma. Si pone un problema: se il salto non viene preso? Viene<br />
eseguita una SUB R4,R5,R6 che prima non doveva essere eseguita; questo<br />
può provocare problemi perché la SUB modifica R4, e se questo serve dopo è chiaro che questa<br />
cosa non si può fare, ma il compilatore l’ha fatta e quindi il programma non viene eseguito<br />
correttamente. Ma il compilatore sa se può azzardare questa cosa perché conosce il codice. Se per<br />
caso R4 viene utilizzato in seguito il compilatore non può mettere quell’istruzione e mette al suo<br />
posto una not operation (è come se stesse introducendo uno stallo).<br />
Consideriamo il caso duale, cioè quello in cui scommetto sul fatto che il salto non sia preso:<br />
se io ho indicazione per cui il salto non è preso a questo punto il compilatore<br />
prende un’istruzione successiva al branch, che tanto dovrà essere eseguita<br />
visto che il salto non viene preso, e la sposto come istruzione nel delay slot.<br />
Se il salto non viene preso risparmio un ciclo di<br />
clock di stallo; se il salto viene preso prima di<br />
eseguire l’istruzione target eseguo un’istruzione che<br />
non doveva essere eseguita. Anche in questo caso ci<br />
potrebbero essere problemi; ma anche in questo caso<br />
il compilatore ha il codice e quindi sa se questa cosa si può fare oppure no, e<br />
se non si può fare potrebbe andare a scegliere un’istruzione che è innocua<br />
(se c’è), nel senso che non va a modificare nulla di quello che segue<br />
l’istruzione target se il salto viene preso; altrimenti va a mettere una not operation.<br />
Nell’ipotesi in cui il processore deve introdurre uno stallo come si fa?<br />
A sinistra abbiamo il caso in cui ancora<br />
non è stata fatta l’ottimizzazione,<br />
ovvero in cui bisogna introdurre tre<br />
cicli di clock di stallo. Supponiamo che<br />
il branch sia nella fase di decode, e<br />
quindi l’istruzione i+1 sta facendo il<br />
fetch, quello che devo fare è non fare<br />
avanzare la i+1, ma una not operation, e<br />
quindi a questo punto io devo stallare<br />
per un numero di cicli di clock che è<br />
quello richiesto nel nostro caso;<br />
ovviamente non devo far modificare il<br />
PC finché non sa l’esito del branch.<br />
Vediamo in dettaglio:<br />
78
entra il branch nella fase di decode e si fa il fetch dell’istruzione i+1. A questo punto non faccio<br />
l’incremento del PC, blocco l’accesso in memoria e anche la scrittura dell’IR e faccio entrare una<br />
not operation:<br />
A questo punto la not operation si propaga e nello stadio di fetch entra un’altra not operation:<br />
Si ripete lo stesso di prima per un altro ciclo di clock:<br />
A questo punto le cose sono due: il branch o è preso o non è preso; naturalmente questo lo scopro<br />
nello stadio di MEM.<br />
Consideriamo il caso in cui il branch è preso:<br />
naturalmente vado a finire all’istruzione target<br />
79
Se il salto non è preso:<br />
entrerà nello stadio di fetch l’istruzione i+1<br />
80
29/04/2004<br />
Abbiamo già visto che c’è una grande differenza nel trend di crescita delle performance del<br />
processore rispetto alla crescita delle RAM dinamiche. Di seguito sono riportate le performance del<br />
microprocessore, che crescono del 60% circa ogni anno, e che rispetto all’evoluzione delle<br />
prestazioni della RAM dinamica, che vede crescere in modo significativo la densità ma vede<br />
crescere poco la sua performance, c’è una differenza (CPU-DRAM Gap) di circa il 50% per anno:<br />
Da un punto di vista relativo è come se la memoria fosse sempre più lenta rispetto al processore, e<br />
quindi c’è il rischio che questo gap vanifichi i progressi che si possono ottenere nel campo dei<br />
computer. Abbiamo visto che questo problema è stato affrontato ed è stata trovata una soluzione.<br />
Questa soluzione fa leva su due concetti fondamentali:<br />
1. principio di località, temporale e spaziale: quella temporale dice che se sto referenziando un<br />
item nel prossimo futuro esso sarà referenziato con alta probabilità; quella spaziale dice che se<br />
sto referenziando un item è probabile che gli item che sono nella zona verranno refernziati;<br />
2. misure sperimentali.<br />
Questi due concetti hanno di mostrato che nell’80% degli accessi durante l’esecuzione di un<br />
programma, anche molto grosso, si fa riferimento soltanto al 10%-15% del codice. Questa è una<br />
grande scoperta perché a questo punto prendendo i vantaggi che vengono dall’elettronica che dice<br />
che un hardware più piccolo è anche più veloce, possiamo dire che, se riesco a concentrare in questa<br />
piccola memoria questo 10%-15% di codice, sto diminuendo questo gap di performance tra CPU e<br />
memoria. Tutto questo, località più riscontro di tipo tecnologico sulla memoria, porta a pensare di<br />
organizzare il sistema memoria come una gerarchia. In questa organizzazione della gerarchia le<br />
cose stanno come sono mostrate nella seguente figura:<br />
questa gerarchia è costituita da un insieme di livelli, il primo<br />
dei quali (quello più vicino alla CPU) si chiama memoria<br />
Cache, poi abbiamo la Main Memory, poi abbiamo i Dischi,<br />
e poi eventualmente i Tape. Il concetto sostanzialmente è<br />
quello che se io mi metto su un livello della gerarchia, su<br />
questo è come se avessi una finestra di dimensione limitata<br />
sul livello successivo. La cosa fondamentale è che le<br />
informazioni scambiate tra il processore e la cache sono<br />
istruzioni e dati, cioè significa che il processore quando<br />
81
accede alla memoria, e quindi quando accede in cache, lo fa o per andare a leggere un’istruzione o<br />
per andare a leggere, attraverso un’istruzione di load, o per andare a scrivere, attraverso<br />
un’istruzione di store, un dato (word, byte, ecc…). Per quanto riguarda l’informazione che può<br />
essere scambiata tra cache e main memory, abbiamo che l’unità di informazione è il blocco (ha<br />
come dimensione un’insieme di word). Questo significa che nella cache l’organizzazione è a<br />
blocchi, e la dimensione di ognuno di questi è uguale a quella dei blocchi della main memory.<br />
Quando succede che il processore accede in cache e vuole fare riferimento a una word, se questa<br />
non è presente (miss) succede che tutto il blocco che la contiene deve essere rimpiazzato da un<br />
blocco di main memory che contiene quell’informazione. La comunicazione tra memoria e disco è<br />
a pagine.<br />
Il livello più basso della gerarchia è il più ampio dal punto di vista di capacità di memorizzazione,<br />
ma è anche il più lento, mentre man mano che saliamo nella gerarchia le cose si invertono. Se<br />
consideriamo anche i costi abbiamo che man mano che saliamo nella gerarchia anche i costi<br />
salgono.<br />
Se è vero che l’organizzazione nella cache è a blocchi allora significa anche che per accedere a una<br />
word all’interno di un blocco l’indirizzo, sia per quanto riguarda la main memory sia per quanto<br />
riguarda la cache, è fatto nel seguente modo:<br />
Immaginiamo che la main memory organizzi le informazioni nel seguente modo:<br />
×<br />
ognuno di questi è una word, e ognuno di quelli orizzontali è un<br />
blocco; questo significa che per accedere alla word (×) devo<br />
indirizzare il blocco su cui sta la word e poi dire all’interno del<br />
blocco quale word mi interessa. La cache è anch’essa organizzata<br />
in blocchi della stessa dimensione di quelli della main memory:<br />
quando succede un miss, cioè<br />
quando accedendo ad un blocco<br />
della cache il processore sta<br />
andando ad accedere a questa<br />
word, per esempio, e non la trova, quello che avviene è che il<br />
blocco dove il dato cercato dal processore sta rimpiazzerà questo.<br />
Per gestire in questo modo la memoria l’indirizzo ha una parte che<br />
viene chiamata indirizzo di blocco (block address), e una parte che viene chiamata block offset.<br />
L’indirizzo di blocco identifica il blocco, mentre il block offset identifica quale word all’interno del<br />
blocco sto andando a referenziare. Se il blocco è costituito da quattro word, per esempio, il block<br />
offset è costituito da 2 bit.<br />
Per quanto riguarda i parametri che caratterizzano una gerarchia di memoria abbiamo:<br />
• hit rate: frazione di accessi fatti alla cache che hanno portato ad un accesso positivo;<br />
• miss rate: è il complementare dell’hit rate;<br />
• tempo medio di accesso alla memoria (average memory-access time): se io volessi misurare il<br />
tempo medio di accesso al sistema memoria immaginando che all’interno di questo sistema ci<br />
sia una gerarchia costituita da due livelli (cache e main memory), questo è dato dalla formula<br />
Average memory-access time = Hit time + Miss rate × Miss penalty, dove hit time è il tempo di<br />
accesso alla memoria cache;<br />
• miss penalty: è o il numero di cicli di clock o il tempo speso per andare a reperire il blocco<br />
dalla main memory e portarlo nella cache.<br />
Il miss penalty a sua volta può essere visto come somma di due termini:<br />
• tempo di accesso (access time): è il tempo per accedere ad una word nella main memory;<br />
• tempo di trasferimento (transfer time): è il tempo che si impiega per trasferire questo dato<br />
selezionato sulla cache. Questo tempo dipende dalla banda disponibile tra la main memory e la<br />
×<br />
82
cache, ovvero dall’ampiezza del data bus tra main memory e cache; più ampio è il data bus<br />
minore è il transfer time.<br />
Vediamo cosa succede al tempo medio di accesso applicando la formula:<br />
Questi diagrammi sono tracciati per una determinata dimensione di cache. Abbiamo detto che miss<br />
penalty è costituito dalla somma di due contributi: tempo di accesso che è costante, perché la<br />
selezione di un blocco e all’interno di questo una word con l’offset non dipende dalla dimensione<br />
del blocco; tempo di trasferimento che varia linearmente con la dimensione del blocco, a parità di<br />
data bus. Il miss rate presente l’andamento della figura centrale: quando il block size cresce il miss<br />
rate diminuisce perché se è vero il principio di località spaziale quando io accedo e trovo un dato,<br />
siccome è probabile che accederò ai dati sequenziali a quello, significa che probabilmente starò<br />
all’interno dello stesso blocco, e quindi più ampio è il blocco più località spaziale sto catturando;<br />
c’è un punto che si chiama pollution point in cui si inverte la pendenza: all’aumentare la dimensione<br />
del blocco diminuisce il numero di blocchi presenti in cache e quindi si incomincia a penalizzare la<br />
località temporale, rischiando di fare continuamente swap tra main memory e cache. Se applica la<br />
formula Average memory-access time = Hit time + Miss rate × Miss penalty otteniamo l’ultimo<br />
grafico.<br />
Per spiegare la nostra gerarchia di memoria il progettista quando si appresta ad eseguire il progetto<br />
di una gerarchia di memoria deve rispondere a quattro domande:<br />
1. Dove può essere posto nel livello superiore, nel caso nostro nella memoria cache? Questo si<br />
chiama Block placement, ovvero quando io devo portare un blocco di main memory nella<br />
cache, questo blocco dove lo vado a mettere?<br />
2. Quando io processore voglio andare ad accedere ad un’informazione lo faccio attraverso il suo<br />
indirizzo, che corrisponde ad una word nella main memory; come faccio a vedere se<br />
quest’informazione e presente nella cache dato che ho quell’indirizzo che va a referenziare<br />
l’informazione nella main memory? Ovvero come faccio ad utilizzare l’indirizzo del processore<br />
per andare a vedere se il dato cercato sta nella cache? Questo si chiama Block identification.<br />
3. Quando il processore cerca un’informazione in cache e si verifica un miss, bisogna andare a<br />
recuperare il blocco di main memory dove l’informazione risiede e portarlo in cache. Se io<br />
porto un blocco in cache, immaginando che sia sempre piena, quale dei blocchi butto per far<br />
spazio al blocco caricato dalla main memory? Questo problema si chiama Block replacement.<br />
4. Cosa avviene quando c’è una scrittura? Quando il processore deve scrivere e vuole modificare<br />
un dato (in cache), supponendo che lo trova modifica questo dato, e da questo momento in poi<br />
ho una copia che non è più consistente con quello che c’è in main memory. Questo può essere<br />
un problema? Siccome la risposta è sì, quale strategia di scrittura utilizzo (Write strategy)?<br />
Rispondere a queste quattro domande è sufficiente a progettare, se siamo nell’ottica della<br />
progettazione, o a comprendere, se siamo nell’ottica dello studio, un sistema di gerarchia di<br />
memoria.<br />
83
Guardiamo la seguente figura:<br />
in basso abbiamo la main memory dove ognuna delle barrette rappresenta un blocco di<br />
informazione (stiamo considerando 32 blocchi); sopra abbiamo la cache costituita da 8 blocchi. Se<br />
io voglio accedere al blocco 12 della main memory e posizionarlo in cache, in quale degli 8 blocchi<br />
può andare a finire? Ci sono tre strategie possibili:<br />
1. Direct mapped: si prende l’indirizzo di blocco di main memory, in questo caso 12, si fa<br />
l’operazione in modulo col numero di blocchi che ci sono in cache, in questo caso 8, e si piazza<br />
il blocco nel risultato di quest’operazione ⇒ 12 mod 8 = 4. Facendo così scopriamo che i primi<br />
8 blocchi vengono mappati negli 8 blocchi della cache (blocco 0 della main memory nel blocco<br />
0 della cache, blocco 1 nel blocco 1, ecc…); il blocco 8 verrà mappato nel blocco 0 della cache<br />
(8 mod 8 = 0), e così via. Questo significa che dato un blocco di main memory questo può<br />
andare a finire in uno e uno solo posto in cache.<br />
2. Fully associative: quando ho un blocco di main memory e lo voglio piazzare in cache posso<br />
farlo in uno qualunque dei blocchi della cache.<br />
3. Set associative: si divide la memoria cache in un certo numero di insiemi; ciascun insieme<br />
contiene più blocchi. Immaginiamo che la cache fatta da 8 blocchi la suddividiamo in 4 insiemi<br />
contenenti 2 blocchi. Un blocco di main memory può finire in uno e uno solo degli insiemi della<br />
cache; in questo caso l’operazione di modulo si fa con 4, perché tale è il numero di insiemi.<br />
All’interno dell’insieme la strategia è fully associative, nel senso che il blocco lo posso mettere<br />
dove voglio.<br />
Come si fa quando il processore emette un indirizzo a sapere dove in cache potrebbe stare quello<br />
che sta cercando?<br />
Vediamo di risolvere questo problema<br />
nel caso in cui la strategia di placement<br />
sia il direct mapped. Supponiamo che<br />
quella a destra sia la main memory: è<br />
costituita da 32 blocchi ciascuno<br />
costituito da 4 word. Supponiamo che la<br />
cache sia fatta da 8 blocchi. I blocchi 0,<br />
8, 16 e 24 vanno a finire nel blocco 0<br />
della cache; quindi nel blocco 0 della<br />
cache potrebbero alloggiare 4 blocchi<br />
della main memory in base a questa<br />
84
strategia di placement. Lo stesso discorso si fa per i blocchi 7, 15, 23 e 31 della main memory che<br />
vanno a finire nel blocco 7 della cache. Lo stesso vale per tutti gli altri blocchi: ciascun blocco della<br />
cache può potenzialmente ospitare 1 su 4 possibili blocchi di main memory. Il processore può<br />
accedere ad una word che ha un suo indirizzo; quest’indirizzo abbiamo visto che viene splittato in<br />
due campi: block address e block offset. Come si fa a partire da quest’indirizzo a sapere dove<br />
cercare all’interno della cache se quel dato è presente oppure no? Supponiamo che il dato che sta<br />
cercando il processore sta nel blocco 0 della main memory; in base alla strategia di mapping<br />
sappiamo che dobbiamo andare a cercare nel blocco 0 della cache. Supponiamo che vogliamo<br />
leggere la seconda word, e quindi andiamo a leggere la seconda word del blocco 0 della cache. In<br />
cache c’è il blocco 0 o il blocco 8, oppure gli altri blocchi possibili?<br />
Quindi ho bisogno nella cache di aggiungere dell’informazione che non sia soltanto l’informazione<br />
che dalla main memory ho portato sulla cache, ma devo ricordare quel blocco a quale blocco di<br />
main memory si riferisce. Questa informazione aggiuntiva è quello che viene chiamato tag. Nel<br />
nostro caso siccome ogni blocco della cache può provenire da 4 diverse alternative di main memory<br />
per il campo tag basteranno solo 2 bit. La caratteristica dei 4 blocchi di main memory è che hanno<br />
soltanto i due bit più significativi dell’indirizzo di blocco che si differenziano; questi due bit sono<br />
quelli che costituiranno il tag di quel blocco nella cache. Questo significa che pago un prezzo<br />
perché non è vero che la cache è soltanto la copia di un pezzo di main memory, ma devo aggiungere<br />
dell’informazione che non sarebbe necessaria se usassi solo la main memory.<br />
L’indirizzo del processore, nel caso in cui il suo sistema di memoria è quello che abbiamo visto,<br />
come lo utilizziamo per andare ad identificare l’informazione all’interno della cache?<br />
Supponiamo di avere uno spazio d’indirizzamento che ha 32 blocchi, ciascuno con 4 word e di<br />
conseguenza con 128 word totali. Immaginiamo di avere un processore che in totale possa<br />
indirizzare 128 word. Questo significa che il campo degli indirizzi del processore deve essere di 7<br />
bit:<br />
sappiamo che, se c’è una cache di 8 blocchi, e se abbiamo ogni<br />
blocco di dimensione 4 word, due bit servono per il block offset,<br />
e verranno utilizzati quando andrò in cache per andare a<br />
selezionare la word interessata se trovo il blocco cercato, due bit<br />
mi servono per il tag, e tre bit che servono per identificare il<br />
blocco della cache dove dovrebbe essere il dato. Una volta<br />
selezionato il blocco della cache grazie al campo index vengono<br />
confrontati i due bit di tag (della cache e dell’indirizzo) per<br />
vedere se sono uguali, e se è così vuol dire che ho trovato l’informazione trovata, altrimenti c’è un<br />
miss.<br />
Proviamo a rispondere alla terza domanda: quale blocco sostituire quando c’è un miss?<br />
Tipicamente si fa riferimento a due strategie: random e LRU (less recent used).<br />
Quando c’è un miss e si va in main memory a prendere un blocco non è detto che si può scegliere.<br />
Nel caso direct mapped la politica di sostituzione è imposta: l’unico posto dove il blocco può andare<br />
a finire è quello che si deve liberare, perché non c’è alcuna scelta. Il problema si pone su quelle<br />
strategie di placement che lasciano libertà: set associative o fully associative.<br />
LRU è la politica che dice: in base al concetto di località temporale se c’è un blocco presente in<br />
cache e non lo si usa da un sacco di tempo, più tempo passa e meno probabilmente vi si accederà;<br />
questo significa che laddove c’è libertà se il mio blocco può andare a finire all’interno di un set<br />
verrà scartato il blocco meno recentemente utilizzato.<br />
La politica random dice: se si può scegliere tra più possibilità il blocco da sostituire verrà scelto in<br />
maniera random.<br />
Si può vedere che se si considera la strategia set associative a due vie (cioè con due blocchi<br />
all’interno del set) la LRU presenta un miss rate del 5,18%, mentre se si utilizza una politica<br />
random il miss rate peggiora a 5,69% (per una cache di 16 KB); la stessa cosa si nota anche<br />
85
all’aumentare dell’associatività. La cosa che si può osservare è che man mano che aumenta la<br />
dimensione della cache la differenza dei miss rate tra le due politiche si attenua:<br />
Quindi per cache di dimensioni adeguate le due politiche danno risultati simili, di conseguenza si<br />
sceglie quella più economica, ovvero quella random. Se dovessi implementare la LRU dovrei, in<br />
ogni blocco della cache, non solo avere il campo tag, ma anche un qualcosa che mi segna l’età del<br />
blocco, e quindi un overhead nella ricerca del blocco da sostituire.<br />
L’ultima domanda è quella legata al write.<br />
Il processore deve scrivere (store) e supponiamo che ci sia un hit (trova in cache la word da<br />
modificare); abbiamo detto che facendo questa operazione di scrittura stiamo violando la<br />
consistenza tra le due copie, quella in cache e quella in main memory; questo potrebbe essere un<br />
problema. Per risolvere questo problema la tecnica più semplice a cui si può pensare è: tutte le volte<br />
che si scrive in cache si va a scrivere anche sulla main memory (write through); questo significa<br />
che il processore scrive in cache, e contemporaneamente il cache controller utilizza l’indirizzo<br />
fornito dal processore per andare a scrivere quel dato sulla copia che c’è in main memory.<br />
Ovviamente facendo così tutte le volte che c’è una scrittura penalizzo il processore perché devo<br />
aspettare di finire la scrittura sulla main memory che è più lenta. In questo caso si risolve il<br />
problema attraverso di un write buffer: il processore scrive in cache e contemporaneamente il dato<br />
viene copiato nel write buffer (buffer fatto di un certo insieme di blocchi o di word), fatto questo il<br />
processore può andare avanti, e poi il cache controller si occupa di copiare quello che c’è nel write<br />
buffer sulla main memory, sgravando il processore da questo compito.<br />
La write through, in generale nei sistemi, mi mantiene la consistenza tra le due copie, ma accede<br />
spesso alla main memory, il che significa consumare banda disponibile sulla main memory che oltre<br />
dal processore può essere acceduta anche da altri dispositivi (per esempio il DMA).<br />
L’altra politica di scrittura quando si verifica un hit è quella che viene chiamata write back: quando<br />
si deve effettuare un’operazione di scrittura si scrive solo nella cache, non interessandoci della<br />
consistenza; non aggiornando il dato nella main memory può succedere che se c’è un miss prendo<br />
un blocco della cache e lo butto, e se su quel blocco erano avvenute delle scritture, tutti gli<br />
aggiornamenti non presenti in main memory li ho persi; quindi la write back così semplicemente<br />
non può funzionare. Allora quello che si fa è che tutte le volte che si deve buttare un blocco, prima<br />
di buttarlo si deve andare a copiare sulla main memory. Ovviamente si può migliorare il tutto<br />
pensando che non si deve fare sempre: non è detto che il blocco che butto è stato modificato e<br />
quindi non è necessario copiarlo sulla main memory. Per fare questo è necessario aggiungere<br />
un’informazione sulla cache, ovvero un bit che dice se il blocco è stato modificato oppure no;<br />
questo bit tipicamente si chiama clean or dirty. Questo significa che il cache controller si deve<br />
preoccupare quando c’è un replacement di copiarlo oppure no sulla main memory.<br />
Pro e contro delle due tecniche:<br />
• non succede mai che un miss in lettura, quando utilizzo una politica write through, provoca una<br />
scrittura in main memory, perché la main memory è sempre aggiornata;<br />
• nel caso di write back un miss in lettura può implicare una scrittura sulla main memory;<br />
86
• i vantaggi del write back sono: se su un blocco in cache ho fatto molte scritture quando questo<br />
viene sostituito si riflette in una sola scrittura sulla main memory, cioè consuma pochissima<br />
banda.<br />
Vediamo come funziona il write through:<br />
quando il processore scrive in cache, il dato<br />
viene copiato anche nel write buffer, il<br />
quale essendo un piccolo buffer fa sì che la<br />
scrittura può avvenire alla stessa velocità<br />
della scrittura sulla cache; dopodiché il<br />
write buffer viene scaricato nella main<br />
memory. Naturalmente il write buffer diventa una struttura FIFO, e il problema del progettista del<br />
sistema memoria è di quanto deve essere lungo il write buffer: c’è un servente che svuota il buffer<br />
con la velocità tipica di come una scrittura può avvenire sulla DRAM, e c’è un produttore che<br />
riempie il buffer potenzialmente con la velocità del processore, quindi se il buffer è pieno bisogna<br />
far aspettare il processore per un tempo pari alla scrittura di un intero blocco sulla main memory.<br />
Per fortuna la frequenza delle scritture normalmente in un programma è abbastanza bassa rispetto<br />
alle letture.<br />
Se devo fare un’operazione di write e c’è un miss che cosa dovrebbe succedere normalmente? Si<br />
prende il blocco dalla main memory, lo si porta in cache e poi si scrive. Se si segue questa logica si<br />
dice che si sta utilizzando una politica di write allocate. Si può anche seguire un’altra tecnica:<br />
write not allocate. Questa tecnica fa riferimento ad un’osservazione di tipo pratico: siccome le<br />
scritture hanno una bassa frequenza (si verificano raramente), è vero che se si verifica un miss si<br />
dovrebbe prendere il blocco portalo in cache e scriverlo, ma questo miss si è verificato su una<br />
scrittura, allora forse questo dato che è stato modificato può darsi che non verrà utilizzato per tanto<br />
tempo; questo potrebbe giustificare l’idea che quando si presenta una scrittura si va a modificare<br />
soltanto l’informazione sulla main memory (non si pone il problema di modificarlo in cache perché<br />
non c’è, si è verificato un miss) e non si alloca il blocco sulla cache; in questo caso si scommette sul<br />
fatto che probabilmente quel blocco nel prossimo futuro non sarà acceduto.<br />
Vediamo come un blocco viene identificato in cache:<br />
in alto abbiamo l’indirizzo di<br />
CPU; quando la CPU emette<br />
l’indirizzo non dice quale parte è<br />
il campo tag, quale l’index e quale<br />
l’offset, perché non sa come sarà<br />
fatta la cache, ma è il cache<br />
controller che attribuisce il<br />
significato ai campi dell’indirizzo.<br />
Con l’index il cache controller<br />
seleziona dove dovrebbe stare<br />
l’informazione che sta cercando il<br />
processore. Si vede che sono state<br />
separate la parte della cache che<br />
contiene il tag e la parte della<br />
cache che contiene i dati, però<br />
questo è stato fatto mettendoli in corrispondenza: la parola 0 del chip dei tag contiene i bit per il<br />
blocco 0, ecc. L’offset serve a selezionare la word all’interno del blocco selezionato. Attraverso<br />
l’index viene selezionato oltre al blocco anche il suo tag (ci dice quale blocco di main memory, dei<br />
possibili, è presente nella cache) che deve essere uguale al campo tag dell’indirizzo del processore<br />
per verificarsi un hit; di conseguenza c’è un comparatore, e a seconda se c’è un hit o un miss il dato<br />
87
selezionato che proviene dalla cache passa e va a finire alla CPU. Se le due parti della cache fossero<br />
unite sequenzialerei il confronto del tag e il prelevamento del blocco: prima faccio il confronto e poi<br />
se il blocco è quello giusto vuol dire che devo leggere i dati (indirizzo la word); questo significa che<br />
si peggiorano le performance in termini di tempo di accesso alla cache.<br />
88
06/05/2004<br />
Esempio: fully associative.<br />
Non ci sono regole sul placement, quindi potenzialmente il blocco cercato può stare in qualunque<br />
punto della cache. Come faccio a dire dove può stare una cosa che cerca il processore? Se la<br />
scansione è sequenziale, la fully associative promette una performance migliore della direct mapped<br />
e inoltre il miss rate migliora. Perché? Nella direct mapped non ho alcuna scelta di dove mettere il<br />
blocco e quindi se ho un miss devo buttare il blocco dove andrà a finire quello preso dalla main<br />
memory: ci sono dei conflitti, o ci sta uno oppure un altro. Nella fully associative questo problema<br />
non c’è, potrei decidere di allocare quattro blocchi e potrei metterli tutti e quattro in cache. Come<br />
faccio la fase di ricerca del blocco? Se la faccio sequenziale devo fare tanti accessi. Alternativa: la<br />
faccio in parallelo.<br />
Il campo index si è ridotto, il campo tag si allarga (perché qualunque blocco della main memory<br />
può finire in qualunque punto della cache ⇒ ho bisogno di maggiore informazione per sapere dove<br />
è finito).<br />
Organizzo la cache come parte dati e parte tag:<br />
A livello hardware è difficile farlo; inoltre si spende tempo. Ne segue che la fully associative si può<br />
parallelizzare, però costa in termini economici e di tempo. Ciò nonostante la fully associative non<br />
viene esclusa del tutto. Non si può fare una scelta a priori. Bisogna vedere quale programma deve<br />
girare su quella macchina.<br />
Set associative cache<br />
Poiché l’index individua il set devo procedere in parallelo per vedere quale tra i blocchi del set è<br />
quello che contiene l’informazione che voglio. Suppongo di avere una cache associativa a due vie<br />
(ogni insieme ha due blocchi). Il numero di vie significa quanti blocchi ci sono dentro un insieme, il<br />
campo index mi dice dove cercare in cache e il campo tag mi dice quello che c’è dentro la cache<br />
(quale blocco è). La cache viene divisa in due parti: in una mettiamo i blocchi 0 di tutti i set,<br />
nell’altra i blocchi 1 di tutti i set (un set quindi è in orizzontale).<br />
Ogni blocco di dati ha<br />
associato il corrispondente tag.<br />
Seleziono entrambi i blocchi e<br />
in parallelo accedo anche ai<br />
tag di quei blocchi, li<br />
confronto, quindi li mando in<br />
un comparatore che farà uscire<br />
1 o 0 a seconda che il blocco è<br />
presente oppure no. C’è un<br />
multiplexer (il dato può<br />
arrivare da una delle due vie), che seleziona il blocco che ha dato l’hit; l’hit tramite l’OR ci dice se<br />
il blocco è presente oppure no.<br />
89
2-way Set Associative, address to select word<br />
Qui le due vie sono una sull’altra:<br />
confronto con due comparatori diversi i<br />
tag; se uno dei due confronti è vero,<br />
tramite il multiplexer preleverò il dato<br />
da ricercare e lo porterò in CPU.<br />
Questo multiplexer che non è presente<br />
nella direct mapped introduce un ritardo<br />
e questo può dare problemi e portare<br />
alla necessità di dilatazione del clock<br />
della CPU. Questa dilatazione può far sì<br />
che la direct mapped, che ha un miss<br />
rate più alto, ma non ha questo<br />
multiplexer, potrebbe avere un TCPU più<br />
piccolo di quello della set associativa.<br />
Quindi il miss rate più elevato non<br />
sempre significa avere TCPU più alti.<br />
Il dato è disponibile solo dopo che sono<br />
terminati tutti i confronti. Nel caso del<br />
direct mapped il dato può uscire in<br />
parallelo al compare perché non deve<br />
attraversare il multiplexer ⇒ si anticipa<br />
la fornitura del dato al processore ⇒ la direct mapped è più semplice ⇒ è più veloce della set<br />
associativa.<br />
All’aumentare dell’associatività aumenta la complessità, quindi aumentano dimensione e latenza.<br />
Riepilogando gli svantaggi di una set associativa rispetto ad una direct mapped sono:<br />
• abbiamo bisogno di N comparatori rispetto ad uno;<br />
• maggiori ritardi dovuti al multiplexer;<br />
• il dato arriva dopo l’Hit/Miss decision e la selezione del set; ne segue che la velocità di accesso<br />
al dato da parte del processore è penalizzata (oltretutto per considerare un dato sicuro è<br />
necessario che il processore lo possieda per un certo tempo).<br />
Structural hazard<br />
Nel caso di gerarchia di memoria è preferibile, dal punto di vista del miss rate, una cache unificata o<br />
separata?<br />
Usare una cache unificata per dati e istruzioni può essere non conveniente. Come abbiamo visto una<br />
memoria unificata presenta un hazard strutturale con le load/store. Un modo per risolvere il<br />
problema è dividere la cache in cache dati e cache istruzioni. La CPU sa se l’indirizzo riguarda dati<br />
o istruzioni. La cache separata ci permette di ottimizzare separatamente ogni singola cache:<br />
differenti capacità, dimensioni dei blocchi, associatività.<br />
La seguente tabella mostra i vari miss rate per i vari tipi di cache:<br />
poiché i valori sono riferiti alla cache<br />
unificata bisogna confrontare i dati<br />
nell’instruction cache e data cache di 16k con<br />
quelli della cache unificata di 32k.<br />
90
Per calcolare il miss rate medio della cache separata dobbiamo conoscere la percentuale di accesso<br />
in memoria per i due tipi di cache.<br />
Con cache separate raddoppia l’hardware, replico i segnali di controllo, ecc… I miss sui dati e sulle<br />
istruzioni non avvengono contemporaneamente. Se le unisco avrei un miss rate più basso di quello<br />
dei dati, ma più alto di quello delle istruzioni, ne segue che devo separale, altrimenti tutte le volte<br />
che accedo in memoria perdo un colpo di clock.<br />
Cache performance<br />
Vediamo come valutare l’impatto che ha la gerarchia di memoria sul CPU time. Il nostro obiettivo è<br />
ottimizzare la performance dal punto di vista della CPU.<br />
CPU time = (CPU execution clock cycles + Memory stall clock cycles) × clock cycle time<br />
Memory stall clock cycles = Memory accesses × Miss rate × Miss penalty<br />
(In questa formula il miss penalty deve essere espresso in cicli di clock)<br />
CPU time = Ic × (CPIexecution + Mem accesses per instruction × Miss rate × Miss penalty) × Clock<br />
cycle time<br />
Supponiamo di dimezzare il periodo di clock:<br />
• Ic non varia<br />
• CPIexecution, non varia perché è in termini di numero di cicli di clock e non in termini di<br />
frequenza<br />
• Mem. accesses per instruction, non varia (a parità di programma) perché dipende dal benchmark<br />
che è lo stesso per entrambe le versioni<br />
• Miss rate, non varia perché è la frazione di volte in cui non trova il dato rispetto agli accessi<br />
totali<br />
• Miss penalty, varia perché in questa formula è misurato in cicli di clock.<br />
In particolare il miss penalty raddoppia perché raddoppia il numero di cicli per raggiungere il<br />
ritardo introdotto dalla main memory.<br />
Importantissimo:<br />
CPUtime = Ic × (CPIexecution + Misses per instruction × Miss penalty) × Clock cycle time<br />
Se dimezziamo la frequenza del ciclo di clock: CPIexecution non varia perché dipende dal numero di<br />
cicli di clock, il numero di miss non varia perché dipende dal benchmark, il miss penalty (è espresso<br />
in cicli di clock) raddoppia perché è un numero diviso il periodo, perciò si avrebbe:<br />
new CPU time = Ic× CPIexecution × T/2 + Ic × miss per instruction × 2 miss penalty × T/2<br />
Il secondo addendo rimane invariato, il primo si dimezza ma se il contributo del CPI non era elevato<br />
non è cambiato molto! Se diminuisco il numero di cicli di clock varia il CPI ma non gli altri<br />
elementi. Il CPU time migliora (ma di poco perché il secondo addendo è predominante rispetto al<br />
primo). Il secondo addendo infatti non varia perché il miss penalty raddoppia e il periodo di clock si<br />
dimezza.<br />
91
Esercizio<br />
.data<br />
vett: .space 20<br />
msg_input: .asciiz “\nNum?”<br />
msg_output: .asciiz “\nN: %d”<br />
.align 2<br />
arg_printf .word msg_output<br />
num: .space 4<br />
.text<br />
.global main<br />
main:<br />
addi r2,r0,0<br />
addi r5,r0,5<br />
loop_input:<br />
addi r1,r0,msg_input<br />
jal InputUnsigned<br />
slei r7,r1,7<br />
andi r8,r1,1<br />
or r9,r7,r8<br />
beqz r9,falso<br />
sw vett(r2),r1<br />
addi r2,r2,4<br />
falso:<br />
subi r5,r5,1<br />
bnez r5,loop_input<br />
srli r10,r2,2<br />
addi r2,r0,0<br />
loop_output:<br />
beqz r10,fine<br />
lw r11,vett(r2)<br />
sw num,r11<br />
addi r14,r0,arg_printf<br />
trap 5<br />
subi r10,r10,1<br />
addi r2,r2,4<br />
j loop_output<br />
fine: trap 0<br />
Cicli di clock totali = 356<br />
Ic = 224<br />
FCK = 1 GHz<br />
1) Caso ideale (dati presi dal DLX): TCPU = Ncicli_totali × TCK = 356 × 1 ns =356 ns<br />
CPI = Ncicli_totali / Ic = 356/224 = 1,59<br />
11/05/2004<br />
92
2) Cache unificate: cache da 1k, blocco da 16 byte, associatività 2 e miss penalty pari a 30 cicli di<br />
clock. Col dinero ottengo Nmiss = 450<br />
TCPU = (Ncicli_totali + Nload/store + Nmiss × miss penalty) × TCK = (356+65+450×30) × 1 ns = 1,39 µs<br />
CPI = (Ncicli_totali + Nload/store + Nmiss × miss penalty)/Ic = 13921/224 = 62,1<br />
3) Cache separate: cache dati da 1k, blocco della cache dei dati da 32 byte, associatività 4 della<br />
cache dei dati e miss_penalty_dati pari a 30 cicli di clock; cache delle istruzioni da 2k, blocco<br />
della cache delle istruzioni da 32 byte, associatività 4 della cache delle istruzioni e<br />
miss_penalty_istru pari a 40 cicli di clock. Col dinero ottengo: Nmiss_dati = 17 e Nmiss_istr = 114<br />
TCPU=(Ncicli_totali+Nmiss_dati×miss_penalty_dati+Nmiss_istr×miss_penalty_istr)×TCK=<br />
=(356+17×30+114×40) × 1 ns = 5,43 µs<br />
CPI = (Ncicli_totali + Nload/store + Nmiss × miss penalty)/Ic = 5426/224 = 24,22<br />
93
Esempi su come calcolare lo speedup.<br />
Esempio<br />
Tv<br />
Tn<br />
CT<br />
1 h 4 h<br />
CT Roma<br />
1 h 2 h<br />
Calcoliamo lo SE e la FE :<br />
FE = 4/5<br />
SE = 4/2<br />
Speedup = 1/(1- FE + FE / SE) = 5/3<br />
13/05/2004<br />
Esempio:<br />
ponendoci nel caso visto la scorsa lezione con le cache unificate, calcolare lo Speedup complessivo<br />
qualora la miss penalty della cache unificata diventi 15 cicli.<br />
FE = (450 • 30 • TCK)/[(356 + 65 + 450 • 30) • TCK] = 13500/13921 = 0,97<br />
SE = (450 • 30 • TCK)/(450 • 15 • TCK) = 2<br />
Speedup = 1/(1 - FE + FE / SE) = 1,94<br />
Esempio<br />
Calcolare lo speedup ottenuto qualora si faccia una modifica che abbia come effetto il ridurre a 1/3<br />
il numero di miss nella cache dei dati (caso cache separate dell’esercizio della scorsa lezione).<br />
TCPU<br />
Roma<br />
TCPU<br />
FI<br />
FI<br />
(356 + 65 + 450×30) × TCK<br />
TCPU_ideale hazard strutturali (load/store) Nmiss • miss penalty<br />
(356 + 17 × 30 + 114 × 40) × TCK<br />
TCPU_ideale Nmiss_dati • miss_penalty_dati Nmiss_istr • miss_penalty_istr<br />
FE = (17 • 30 • TCK)/[(356 + 17 • 30 + 114 • 40) • TCK] = 13500/13921 = 0,09<br />
SE = (17 • 30 • TCK)/(17/3 • 30 • TCK) = 3<br />
Speedup = 1/(1 - FE + FE / SE) = 1,05<br />
Utilizzando dinero, che è un cache simulator, abbiamo visto come è possibile andare a vedere come<br />
variano le performance della gerarchia di memoria al variare dei vari parametri della gerarchia<br />
stessa. Questi parametri quali potrebbero essere? Se io ho una cache organizzata con un certo<br />
numero di blocchi, che cosa succede per esempio al miss rate, o all’average memory-access time, se<br />
faccio variare la dimensione del blocco a parità di dimensione di cache? Oppure ho una cache direct<br />
mapped di una certa dimensione, che cosa succede a parità di dimensione se la faccio diventare set<br />
associative a 2 vie, oppure a 4 vie? In poche parole che cosa succede se aumento il livello di<br />
associatività?<br />
Ci sono delle tecniche che posso individuare per migliorare il miss rate, il miss penalty e l’hit time?<br />
Ricordiamo che l’average memory-access time è dato dalla somma dell’hit time e del prodotto di<br />
miss rate e miss penalty. È ovvio che per migliorare l’average memory-access time, quindi per<br />
diminuire il tempo di accesso, posso intervenire cercando di abbassare l’hit time, oppure posso<br />
94
intervenire sul miss rate o sul miss penalty, perché abbassando uno o l’altro il prodotto miss rate per<br />
miss penalty diminuisce.<br />
Proviamo a vedere quali tecniche promettono di ridurre il miss rate.<br />
A questo punto bisogna parlare delle origini dei misses: quando voglio inventare una tecnica per<br />
cercare di migliorare le prestazioni, mi devo chiedere perché si verificano i misses. Sono state<br />
identificate tre cause che possono produrre un miss; queste cause vanno sotto il nome delle 3 C:<br />
• Compulsory: è chiamato anche cold start misses. Quando per la prima volta si va a<br />
referenziare un item, questo potrebbe benissimo non essere in cache; questo succede perché<br />
sfruttiamo il principio di località, e quindi diciamo che se accediamo a qualcosa, nel caso della<br />
località spaziale, sicuramente gli item vicini hanno un’alta probabilità di essere acceduti; ma la<br />
prima volta che si accede a qualcosa e che non era vicino a qualcos’altro probabilmente ancora<br />
in cache non c’è.<br />
• Capacity: i misses dovuti a questa causa sono spiegabili col principio di località; se ho una<br />
cache da 4k avrò un miss rate legato a questa capacità; se utilizzo una cache da 256k piuttosto<br />
che da 4k significa che posso mettervi dentro molti più blocchi di main memory, e quindi la<br />
probabilità di miss diminuisce.<br />
• Conflict: è legato al conflitto che si va a generare su certi tipi di organizzazioni di cache; per la<br />
direct mapped abbiamo visto che ci sono blocchi di main memory che vanno a finire sullo stesso<br />
blocco di cache. Questa competizione genera un conflitto perché nel caso in cui un programma<br />
va ad accedere a blocchi in conflitto tra di loro ogni volta solo uno di questi può stare in cache.<br />
Questo fenomeno si attenua man mano che aumenta l’associatività, perché se c’è un conflitto a<br />
livello di blocchi e non di set, all’interno di un set di una set associativa abbiamo più alternative<br />
di dove piazzare un singolo blocco; questo significa che ho una minore competitività tra i<br />
blocchi e questo significa anche che laddove due blocchi acceduti da un programma dovessero<br />
finire sullo stesso set non avrei problemi di conflitto. Aumentando l’associatività il problema<br />
diventa sempre minore perché il conflitto diminuisce e quindi significa che i misses legati a<br />
questo problema diminuiscono.<br />
Per quanto riguarda queste tre cause abbiamo un diagramma che riporta al variare della dimensione<br />
della cache il miss rate:<br />
riportiamo il miss rate facendo<br />
variare all’interno della cache<br />
l’associatività (partiamo da<br />
una direct mapped (1-way) e<br />
arriviamo ad una set<br />
associativa a 8 vie). La fully<br />
associativa è quella che<br />
elimina ogni tipo di conflitto.<br />
Abbiamo visto anche che per<br />
una fully associativa gestire<br />
l’hardware è complicato. Si è<br />
dimostrato che il<br />
miglioramento è significativo<br />
in termini di conflitto man<br />
mano che si passa da una<br />
direct mapped verso la fully<br />
associativa. Andando oltre le 8 vie si vede che non si ha più nessun tipo di miglioramento, e questo<br />
si vede al solito con l’approccio basato su misure, ovvero si vede che con moltissimi programmi<br />
con una set associativa a 8 vie di fatto non ci sono più quasi completamente conflitti. Questo<br />
significa che una memoria pienamente associativa non ha motivo di esistere, ma al massimo si<br />
arriverà ad una set associativa a 8 vie.<br />
95
Nel grafico si vedono le varie componenti di miss. La linea in rosso rappresenta il compulsory miss:<br />
si vede che al variare della dimensione della cache i misses legati al compulsory restano costanti;<br />
questo succede perché il compulsory non dipende dalla dimensione della cache, ma è legato al fatto<br />
che quando si va a referenziare per la prima volta qualcosa in cache si ha un miss.<br />
Un’altra componente è quella relativa al coflict miss: le strisce di colore diverso fanno vedere cosa<br />
sommo in termini di misses legati ai conflitti alla curva legata alla memoria set associativa a 8 vie;<br />
spostandoci verso la direct mapped il miss rate aumenta. Tutta la striscia compresa tra la direct<br />
mapped e la set associativa a 8 vie (colori: blu, giallo, viola e azzurro) è quella legata ai conflitti.<br />
La striscia in verde è quella legata al capacity miss. Ovviamente tutte le curve assumono un<br />
andamento decrescente all’aumentare della dimensione della cache.<br />
Vediamo una regola pratica:<br />
consideriamo per esempio una cache da 4k organizzata in modo direct mapped; su questa<br />
sperimentiamo un determinato miss rate.<br />
Ma se aumentassimo l’associatività per<br />
caso lo stesso miss rate lo potremmo<br />
sperimentare con una cache più piccola?<br />
La risposta è sì: se consideriamo la set<br />
associativa a 2 vie abbiamo una cache di<br />
dimensione circa 2k. Questo significa<br />
che il miss rate che ottengo con una<br />
cache direct mapped di 4k è pari al miss<br />
rate che ottengo con una cache di 2k<br />
organizzata in modo set associativo a 2<br />
vie.<br />
A questo punto cominciamo a vedere quali tecniche possiamo inventarci per ridurre il miss rate,<br />
sapendo che quest’ultimo è dovuto alle tre cause viste sopra.<br />
Poniamoci delle domande:<br />
• se a parità di dimensione della cache faccio variare la dimensione del blocco, qualcuna delle tre<br />
cause è influenzata?<br />
• se io cambio l’associatività quale delle tre cause è coinvolta?<br />
• se agisco a livello di compilatore quale delle tre cause è influenzata?<br />
Cominciamo con la prima tecnica: variamo la dimensione dei blocchi.<br />
Abbiamo 5 casi, corrispondenti<br />
a 5 dimensioni di cache.<br />
Osserviamo che c’è una fase<br />
iniziale, comune a tutte e 5 le<br />
curve, in cui all’aumentare della<br />
dimensione del blocco<br />
diminuisce il miss rate.<br />
Aumentare la dimensione dei<br />
blocchi provoca il fatto che<br />
dentro ognuno di essi ci entrano<br />
più informazioni; questo<br />
significa che la componente di<br />
miss che probabilmente<br />
miglioro è il compulsary: se io<br />
ho un cold start miss e<br />
trasferisco sulla cache un blocco<br />
grande è probabile che anche gli altri item che non sono stati referenziati li trovo in cache proprio in<br />
96
virtù del principio di località, e quindi per questi item non avrò un cold start miss. Tutto questo è<br />
vero fino ad un certo punto, perché tutto va relazionato alla dimensione della cache: se continuo a<br />
far crescere la dimensione del blocco il risultato è che all’interno della cache avrò pochissimi<br />
blocchi per cui comincia il problema del conflict miss.<br />
Siamo sicuri che riducendo il miss rate gli altri due componenti, hit time e miss penalty, non<br />
peggiorino? La cosa che peggiora sicuramente è il miss penalty: fare un blocco più ampio significa<br />
che quando c’è un miss aumenta la quantità di informazione che si deve trasferire dalla main<br />
memory alla cache, e quindi aumenta il miss penalty.<br />
La seconda tecnica per diminuire il miss rate è quella di aumentare l’associatività. Se aumento<br />
l’associatività diminuiscono i conflict miss. Però all’aumentare dell’associatività peggiora l’hit<br />
time: in una set associativa ci deve essere un multiplexer tra cache e CPU, quindi mi trovo una<br />
latenza che sperimento nella maggior parte delle volte (tutte le volte che c’è un hit quel multiplexer<br />
deve essere attraversato).<br />
Osserviamo la seguente tabella: vediamo come varia l’average memory-access time (A.M.A.T.) al<br />
variare della dimensione della cache e al variare dell’associatività. Per una cache da 1k<br />
all’aumentare dell’associatività il<br />
tempo medio di accesso alla cache<br />
diminuisce perché diminuisce il<br />
conflict miss. Tutto questo è vero<br />
finché non arriviamo ad una cache<br />
da 8k dove si vede che passando da<br />
una direct mapped ad una set<br />
associativa a 2 vie peggiora<br />
l’A.M.A.T. perché peggiora l’hit<br />
time (questo è legato al periodo di<br />
clock del processore che si allunga<br />
passando da direct mapped a set<br />
associativa a 2 vie, a 4 vie, ecc…).<br />
si vede che a partire da una cache<br />
da 16k aumentare l’associatività<br />
non porta alcun beneficio.<br />
La seguente tecnica è una tecnica che segna un punto di svolta rispetto alle tecniche precedenti,<br />
perché fa migliorare il miss rate senza intervenire né sull’hit time né sul miss penalty.<br />
Questa tecnica si chiama Victim cache (cache vittima). Ho la mia cache (tag e dati); quando ho un<br />
miss devo sostituire un blocco il che implica<br />
prendere questo blocco e portarlo in main memory e<br />
quello giusto dalla main memory lo porto in cache.<br />
Qualcuno ha pensato: il blocco che tolgo piuttosto<br />
che portarlo in main memory lo lascio vicino alla<br />
cache, perché se era in cache vuol dire che era stato<br />
acceduto, e se lo si toglie può essere causa di miss.<br />
Allora si organizza una piccola memoria fully<br />
associativa da associare alla cache in modo tale che<br />
quando si scarta un blocco dalla cache lo piazzo in<br />
questa cache fully associativa piuttosto che nella<br />
main memory. Questo significa che adesso quando<br />
si ha un miss piuttosto che andare in main memory a<br />
cercare il blocco prima si va a vedere se si trova in<br />
questa cache fatta da pochi blocchi.<br />
Jouppi, che è quello che un po’ ha inventato questa<br />
memoria vittima, ha dimostrato che con una<br />
97
memoria associativa con soltanto 4 entry, cioè con solo 4 blocchi, organizzata in maniera fully<br />
associativa, si rimuoveva dal 20% al 95% dei conflitti di una cache direct mapped da 4KB. Questa<br />
tecnica è stata utilizzata concretamente in macchine reali.<br />
La quarta tecnica è quella che si chiama pseudo-associativa. Abbiamo già visto che in una<br />
memoria set associativa, per esempio a 2 vie, abbiamo bisogno di un multiplexer e di fare in<br />
parallelo i due confronti dei tag; tutto questo fa si che il tempo di accesso a quella memoria sia più<br />
lungo che un accesso ad una memoria direct mapped; d’altra parte è anche vero che la set<br />
associativa a 2 vie ha meno conflitti. Quindi a me piacerebbe avere il tempo di accesso di una direct<br />
mapped e i conflitti di una set associativa. Organizzo una memoria associativa a 2 vie, ma il cache<br />
controller la gestisce come se fosse direct mapped. Quando si va ad individuare il set attraverso<br />
l’index, ma nel set ci sono due blocchi (se è associativa a 2 vie) e di conseguenza viene fatto un<br />
confronto dei tag in parallelo; allora diamo una sorta di default: si va a cercare sempre il primo dei<br />
due blocchi, così è come se si facesse sempre un accesso diretto. Quello che può succedere è che se<br />
ci va bene risparmiamo tempo, mentre se ci va male dobbiamo andare a controllare l’altro blocco.<br />
Sicuramente beneficiamo di una riduzione dei miss legati ai conflitti, sicuramente il tempo medio<br />
legato di accesso è più basso, però c’è un problema: se ci va bene impieghiamo un tempo, mentre se<br />
ci va male impieghiamo un tempo un po’ più lungo.<br />
Questa tecnica ci tornerà utile piuttosto che come cache di primo livello, ma come cache di secondo<br />
livello, dove il processore non accede direttamente.<br />
Un’altra tecnica utilizzata per la riduzione del miss rate è quella che si chiama hardware<br />
prefetching. Se c’è un miss significa che si deve andare nella main memory per prendere un blocco<br />
e portarlo in cache; siccome c’è sempre il principio di località forse anche il blocco successivo di<br />
main memory potrebbe servire; naturalmente non lo prendo per andare a rimpiazzare un blocco che<br />
già c’è in cache, però faccio un prefetching: il blocco su cui c’è stato un miss lo alloco in cache,<br />
mentre il blocco successivo lo vado a mettere in uno stream buffer, che è un buffer piccolo e veloce<br />
che sta vicino alla cache, così è pronto per essere acceduto. Allora quello che si fa è che se c’è un<br />
miss prima di andare in main memory si va a vedere se nello stream buffer c’è qualcosa che ci<br />
interessa. Jouppi ha dimostrato che un data stream buffer si riusciva a catturare il 25% di miss da<br />
una cache di 4KB; con 16 streams fino al 72% dei miss. Il prefetching va a diminuire la banda della<br />
main memory.<br />
L’ultima tecnica è quella che riguarda il compilatore. Abbiamo già visto per esempio nel caso del<br />
pipeline come il compilatore ci può aiutare a ridurre il data hazard ristrutturando il codice. Per<br />
quanto riguarda la località si può fare qualcosa col compilatore? Consideriamo il caso dei dati: un<br />
array se si potesse portare tutto in cache non avrei problemi; ma se l’array è di una certa dimensione<br />
non si riesce a portarlo tutto in cache; ma se io accedo a righe successive e l’array nella main<br />
memory è memorizzato per colonne caricando le colonne commetterei una sciocchezza perché gli<br />
elementi contigui non sono le colonne. Questo significa che c’è un’incompatibilità tra come è<br />
memorizzato l’array e come sarebbe meglio memorizzarlo per cercare la località. Allora il compito<br />
del compilatore è ristrutturare il codice in modo tale che invece che fare l’accesso per righe<br />
successive lo si fa per colonne.<br />
Nella figura accanto è riportato cosa si ottiene<br />
quando il compilatore adotta alcune tecniche<br />
per ottimizzare la località. Si vede come il<br />
perfomance improvement man mano che si<br />
utilizzano diverse tecniche può essere di 1,5-<br />
2,5. E questo è legato solo al compilatore.<br />
98
18/05/2004<br />
Abbiamo visto che l’average memory-access time è dato dalla somma di due contributi: hit time e<br />
prodotto tra miss rate e miss penalty. È chiaro che ridurre l’hit time, il miss rate, e il miss penalty<br />
sono tutti e tre obiettivi nobilissimi, ma non sempre si riesce a ridurne uno senza andare a<br />
influenzarne un altro.<br />
Passiamo alle tecniche per la riduzione del miss penalty.<br />
La prima tecnica è quella che parla del read priority over write on miss. Supponiamo che<br />
utilizziamo una cache con politica di scrittura write through, ovvero quando si fa una scrittura in<br />
cache si scrive anche in main memory, e per evitare di penalizzare il processore a causa della<br />
lentezza di quest’ultima si interpone tra cache e main memory un write buffer; ci sono dei casi in<br />
cui le cose si complicano: c’è un miss in lettura, supponiamo, e quello che dovrebbe accadere è che<br />
il cache controller va in main memory individua il blocco cercato e lo va a piazzare in cache; ma<br />
siamo sicuri che il blocco che va a prendere in main memory e porta in cache è aggiornato?<br />
Potrebbe essere non aggiornato perché magari l’aggiornamento sta ancora nel write buffer e non c’è<br />
stato ancora il tempo di andarlo a copiare sulla main memory. A questo punto se si volesse usare<br />
una politica di tipo conservativo dovrebbe succedere che tutte le volte che c’è un read miss prima di<br />
andare in main memory e prendere il blocco da portare in cache si aspetta che si svuoti tutto il write<br />
buffer; se il write buffer è a quattro posizioni significa che ogni volta che c’è un miss in lettura, che<br />
sono i miss più frequenti dato che le letture sono più frequenti delle scritture, sperimento un miss<br />
penalty che è molto più lungo di quello che sarebbe richiesto se andassi direttamente in main<br />
memory. Per abbassare il miss penalty piuttosto che aspettare di svuotare il write buffer si potrebbe<br />
andare a vedere se c’è conflitto tra il blocco che devo portare in cache dalla main memory e i<br />
blocchi che sono presenti nel write buffer; conflitto significa che il blocco che sto cercando è<br />
presente all’interno del write buffer. La tecnica nominata su ci dice di dare la priorità alle letture<br />
sulle scritture: se c’è quel tipo di conflitto è inevitabile che si deve aspettare di svuotare il write<br />
buffer, mentre se il conflitto non c’è prima di svuotare il write buffer vado ad asservire il read miss,<br />
cioè vado in main memory prendo il blocco e lo porto in cache.<br />
Adesso supponiamo di avere una cache con politica di scrittura write back; quando c’è un miss in<br />
lettura bisogna andare a caricare un blocco dalla main memory e scartarne uno dalla cache; il blocco<br />
scartato dalla cache ha un bit (clean or dirty) attraverso il quale si sa se copiare questo blocco in<br />
main memory per aggiornarlo oppure no. In questo caso se c’è un read miss si scarica tutto il blocco<br />
dalla cache su un write buffer e si fa avanzare il read miss, cioè si dà la priorità alla lettura sulla<br />
scrittura.<br />
La seconda tecnica si chiama subblock placement. Una componente del miss penalty è legata al<br />
tempo di trasferimento delle informazioni del blocco dalla main memory alla cache, e questo<br />
significa che se ho un bus da 32 bit e ho un blocco di 4 word da 32 bit devo fare quattro<br />
trasferimenti. Allora si potrebbe pensare di fare blocchi di dimensione più piccola, però questo<br />
significa che a parità di dimensione di cache aumenta il numero di tag; questo potrebbe non essere<br />
un problema se la cache fosse esterna al processore, ma visto che normalmente c’è un pezzo di<br />
cache integrate nel processore sprecare spazio per i tag potrebbe essere troppo oneroso. Per cui si<br />
cerca di coniugare queste due esigenze (da un lato avere blocchi di piccola dimensione per<br />
diminuire il miss penalty e dall’altro evitare che ci siano troppi bit per i tag) e per questo è nata la<br />
tecnica del subblock placement: ogni blocco della cache (direct mapped) viene diviso in<br />
sottoblocchi, per esempio nel nostro caso in 4<br />
sottoblocchi, e a tutto il blocco viene associato<br />
un unico tag. Facciamo un esempio in lettura:<br />
se accedo ad un’informazione, in parallelo<br />
confronto il tag e accedo alla word; per ognuna<br />
delle word c’è un bit associato, che viene<br />
chiamato bit di validità; se questo bit è 1 e il<br />
confronto dei tag è corretto vuol dire che la<br />
99
word è quella cercata e quindi non si verifica un miss; se il bit di validità è 0 vuol dire che la word<br />
non è valida e quindi c’è un miss; in quest’ultimo caso si accede alla main memory si trasferisce<br />
soltanto il sottoblocco interessato (tipicamente ha la dimensione di una word) e quindi il transfer<br />
time tra main memory a cache è limitato soltanto ad un sottoblocco e di conseguenza sto abbattendo<br />
il miss penalty. Nel caso in cui il confronto dei tag non dà esito positivo vuol dire che c’è un miss;<br />
in questo caso si va in main memory si trasferisce la word cercata e contemporaneamente si cambia<br />
il tag mettendo quello corretto, e si mettono a 0 tutti gli altri bit di validità che eventualmente sono<br />
messi a 1.<br />
La terza tecnica è la seguente: quando ho un miss, in generale, prendo un blocco dalla main<br />
memory lo porto in cache e poi il processore può accedere alla word cercata; per esempio se<br />
abbiamo blocchi di 8 word e il processore sta accedendo alla word 5, quando c’è il miss il<br />
processore deve aspettare che il blocco venga trasferito tutto in cache; in alternativa si potrebbe<br />
pensare: il blocco viene trasferito word dopo word, o a gruppi di word a seconda del parallelismo<br />
tra main memory e cache, e non appena la word cercata è stata copiata in cache il processore vi può<br />
accedere e il cache controller può continuare a copiare il resto del blocco. Questo comporta un<br />
abbassamento del miss penalty. Questa tecnica è quella che viene chiamata Early Restart.<br />
Qualcuno ha detto un’altra cosa ancora: se c’è un miss su una word, perché non si fa in modo che la<br />
prima word del blocco che si deve trasferire non è proprio quella che sta cercando il processore?<br />
Facendo così si trasferisce la prima word, il processore la legge e poi il cache controller continua a<br />
trasferire l’intero blocco dalla main memory. Fare questo significa complicare l’hardware del cache<br />
controller perché deve essere in grado di fare non sempre la stessa operazione, ma l’algoritmo di<br />
trasferimento dipende dalla word cercata. C’è un problema: data la word al processore il cache<br />
controller deve poi continuare a trasferire il resto del blocco nella cache, però questo lo fa alla<br />
velocità della main memory, e quindi se è vero che esiste il principio di località spaziale è probabile<br />
che la prossima word a cui accederà il processore sarà la word vicina a quella per cui c’è stato il<br />
miss, ma questa word non è ancora in cache; quindi probabilmente da un lato diminuisce il miss<br />
penalty, ma dall’altro sto aumentando il miss rate.<br />
Un’altra tecnica è quella di organizzare la cache a più livelli. Il progettista normalmente si trova<br />
davanti ad un dilemma: avere cache molto veloci (di conseguenza piccole), ma grandi per avere un<br />
basso miss rate.<br />
Dalla figura accanto si vede come<br />
all’aumentare della dimensione della cache<br />
aumenti significativamente il tempo di accesso<br />
alla cache.<br />
Quindi dal punto di vista della velocità sarei<br />
portato a scegliere cache piccole perché sono<br />
più veloci, ma cache piccole significa elevato<br />
miss rate. Tra l’altro cache piccole significa che<br />
le posso anche integrare all’interno del<br />
processore, e questo implica che sono ancora<br />
più veloci, perché la maggior parte del tempo<br />
su un accesso in memoria si perde nella latenza<br />
che riguarda la comunicazione esterna tra<br />
processore e memoria.<br />
Qualcuno ha pensato di potere raggiungere entrambi gli obiettivi: sia cache veloci che cache grandi.<br />
Come? Organizzando la cache a due livelli: metto una piccola cache, che è quella che si interfaccia<br />
direttamente al processore (o esterna o interna al processore, e in quest’ultimo caso organizzata in<br />
modo direct mapped, che è la più veloce in assoluto), e tra questa piccola cache e la main memory<br />
interpongo un altro livello di cache. Quest’ultima cattura molti dei miss generati dalla piccola cache<br />
e quindi il miss penalty che pago è quello del trasferimento del blocco dal secondo livello di cache<br />
100
al primo, che essendo una RAM statica mi fa sperimentare un miss penalty più basso di quello che<br />
si sperimenta trasferendo un blocco dalla main memory, che è una RAM dinamica.<br />
Siamo sicuri che questa combinazione tra queste due cache effettivamente abbia un average<br />
memory-access time più basso che una singola cache magari più grande e meno veloce? Siamo<br />
sicuri che il miss rate complessivo sia più basso del miss rate che sperimenterei in una cache a<br />
livello unico?<br />
Facciamo dei conti: (L1 = livello 1, che è quello più vicino al processore; L2 = livello 2)<br />
AMAT = Hit TimeL1 + Miss RateL1 × Miss PenaltyL1<br />
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 × Miss PenaltyL2<br />
Sostituendo otteniamo:<br />
AMAT = Hit TimeL1 + Miss RateL1 × (Hit TimeL2 + Miss RateL2 × Miss PenaltyL2)<br />
In questo caso si definiscono un local miss rate e un global miss rate:<br />
• il local miss rate è la frazione di accessi che producono un miss diviso il numero di accessi a<br />
quello stesso livello di cache. In poche parole il miss rate di livello 2, che sarebbe il local miss<br />
rate per la cache di livello 2, è dato dal numero di accessi al livello 2 che generano un miss<br />
diviso il numero di accessi totali al livello 2. Gli accessi totali al livello 2 non sono tutti gli<br />
accessi del processore, ma sono solo quegli accessi del processore che hanno generato un miss<br />
sul livello 1. Il local miss rate nel livello 1 si definisce sempre allo stesso modo, però questa<br />
volta il numero di accessi a questo livello è il numero totale di accessi che genera il processore;<br />
• il global miss rate per un certo livello di cache è il rapporto tra il numero di miss che si<br />
sperimentano in quel livello diviso il numero totale di accessi in memoria generati dal<br />
processore. Nel caso della cache di livello 1 il local miss rate e il global miss rate coincidono;<br />
nel caso della cache di livello 2 questi due sono completamente diversi, e in particolare il global<br />
miss rate è dato dal prodotto Miss RateL1 × Miss RateL2.<br />
Se io vado a considerare il local miss rate della cache di livello 2, mi aspetto che questo sia elevato,<br />
perché siccome è il rapporto tra il numero di miss sul livello 2 e il numero di accessi sulla cache di<br />
livello 2, questi ultimi vengono scremati dalla cache di livello 1, quindi anche se ci sono pochi miss,<br />
questi diviso un basso numero di accessi mi dà un miss rate che può essere elevato.<br />
Siamo sicuri che miss rate nella cache a due livelli sia confrontabile con quello nella cache a un solo<br />
livello? A noi potrebbe andare bene che sia uguale, perché migliorando il miss penalty ci sto già<br />
guadagnando.<br />
Nel seguente grafico viene riportato il local miss rate del livello 2, che è intorno al 70% e poi va a<br />
scendere, e poi è riportato il confronto tra il global miss rate del livello 2 e il miss rate della cache a<br />
un unico livello della stessa dimensione:<br />
si assume che la cache di livello 1 sia di 32k, e si fa variare<br />
la dimensione della cache di livello 2. Si vede che il local<br />
miss rate fino a quando la dimensione della cache di<br />
secondo livello è minore di 32k è elevatissimo;<br />
all’aumentare della dimensione della cache di secondo<br />
livello il local miss rate diminuisce, però mantenendosi<br />
sempre a livelli di 15%-18%.<br />
Guardando il global miss rate si vede che, fino a quando la<br />
cache di secondo livello è più piccola o uguale alla cache<br />
di primo livello, questo è maggiore del miss rate della<br />
cache ad un solo livello, il che significa che ci stiamo<br />
perdendo. Aumentando la dimensione della cache di<br />
secondo livello il global miss rate diventa praticamente<br />
uguale al miss rate del caso di cache ad un solo livello. Da<br />
256k in su le due curve coincidono.<br />
101
Questi grafici dimostrano che la scommessa di tentare di fare una cache a due livelli si può vincere,<br />
perché in realtà se la cache di secondo livello si fa sufficientemente grande i miss rate sono<br />
confrontabili, e quello che ci guadagno è il miss penalty più basso, e anche il fatto che potendo<br />
integrare il primo livello all’interno del processore posso avere un clock cycle time più veloce.<br />
Il fatto di aver organizzato la cache a due livelli mi dà una maggiore libertà sulle tecniche di<br />
ottimizzazione per ridurre il miss rate che io posso implementare sulla cache di secondo livello.<br />
L’aumento dell’associatività sappiamo che riduce il miss rate, ma fa peggiorare l’hit time. Se io<br />
faccio una cache con un’elevata associatività e questa è la prima cache che vede il processore , il<br />
fatto che peggiora l’hit time significa far andare più lento il processore. Se io però ho un secondo<br />
livello di cache posso organizzare il primo livello come direct mapped, e per il secondo livello<br />
posso incrementare l’associatività per diminuire il miss rate, o le altre tecniche di cui abbiamo<br />
parlato la scorsa lezione, senza impattare negativamente sul processore. Quindi molte delle tecniche<br />
che abbiamo studiato che potrebbero non andare bene per una cache ad un unico livello,<br />
incominciano a trovare applicazione per una cache a due livelli.<br />
Vediamo alcune cose sulla riduzione dell’hit time.<br />
La prima cosa che consente di ridurre l’hit time è quella di fare cache semplici (direct mapped) e<br />
piccole.<br />
Adesso vediamo una tecnica che si propone l’hit time in scrittura. Quando accedo in cache per una<br />
lettura posso fare in parallelo il confronto del tag e l’accesso al dato, mentre se ho l’operazione di<br />
scrittura questo parallelismo non è possibile, perché se io confronto il tag e contemporaneamente<br />
scrivo, se il confronto del tag mi ha dà esito negativo modificherei qualcosa che non avrei dovuto.<br />
Questo vuol dire che mentre un hit per un’operazione di lettura potrebbe richiedere un ciclo di<br />
clock, un write dovrebbe chiederne due. Qualcuno si è inventato un pipeline write: quando si deve<br />
scrivere si organizzano le scritture in pipeline. Come? Supponiamo di avere un dato da scrivere in<br />
cache; utilizziamo un ciclo di clock per vedere se c’è un hit oppure no; in questo ciclo di clock oltre<br />
a fare quest’operazione di ricerca del tag verrà messo il dato da scrivere insieme all’indirizzo che<br />
serve per scrivere in cache in un buffer che si chiama<br />
Delayed Write Buffer. Quando scriverò quello che c’è nel<br />
write buffer in cache? Non appena c’è la prossima scrittura<br />
confronto il tag e in parallelo svuoto il write buffer in<br />
cache (nella parte dati; questa scrittura non è relativa a<br />
questo tag, ma a quello precedente) e il dato da scrivere in<br />
questa scrittura si copia nel delayed write buffer. Lo stesso<br />
si fa per le scritture successive.<br />
Se io accedo in cache in lettura e il dato che mi serve è<br />
quello che si trova ancora nel delayed write buffer leggerei<br />
un dato inconsistente. Quindi non solo devo organizzare<br />
questo pipelining, ma devo anche curarmi tutte le volte che<br />
c’è un miss il lettura di andare a vedere se quello che sto cercando è nel write buffer che ancora non<br />
è stato scaricato. Nella figura si vede che tag e dati sono separati; c’è il delayed write buffer dove si<br />
va a scrivere solo se c’è un hit; c’è un multiplexer all’ingresso della cache perché vi si può accedere<br />
o normalmente o attraverso il delayed write buffer.<br />
L’organizzazione a sottoblocchi della cache si presta a implementare un tecnica per migliorare l’hit<br />
time in scrittura. Confronto il tag e in parallelo scrivo; si possono verificare tre casi:<br />
• Se il bit di validità era 0 significa che ho scritto su qualcosa che non era valido; se il tag era<br />
quello giusto avrei dovuto scrivere proprio in quel punto, e quindi l’unica cosa da fare è mettere<br />
il bit di validità a 1.<br />
• Se il bit di validità era 1 e il tag era quello giusto non devo neppure modificare il bit di validità.<br />
• Il tag non è quello giusto; quello che faccio è scrivere il tag del dato che ho scritto in cache e<br />
metto a 0 tutti i bit di validità che sono a 1.<br />
Il risultato è che riesco a fare una scrittura ogni ciclo di clock.<br />
102
Guardiamo un quadro sinottico utile a rivedere tutto quello che abbiamo fatto per quanto riguarda<br />
le tecniche di ottimizzazione. Abbiamo quattro colonne: miss rate, miss penalty, hit time,<br />
complessità: + (migliora), – (peggiora)<br />
Main memory performance<br />
Nella formula dell’AMAT compare il miss penalty che dipende dall’access time alla main memory<br />
e dal transfer time tra main memory e cache. Posso usare qualche trucco per organizzare la main<br />
memory in modo tale che il miss penalty diminuisca? Si possono fare alcune cose.<br />
Ci sono tre soluzioni:<br />
La prima soluzione (a) è quella banale: abbiamo il processore, un bus della dimensione della word<br />
della CPU, poi c’è la cache che è organizzata a blocchi e ha parallelismo di una word (significa che<br />
con un accesso esce una word, e un blocco significa che occupa più word consecutive), poi un bus<br />
sempre di dimensione di una word e infine la main memory organizzata a blocchi come la cache.<br />
Con questa organizzazione cosa succede quando c’è un miss? Tutto il blocco della cache va<br />
sostituito e quindi si devono fare tanti accessi quante sono le word del blocco (dato che il bus è<br />
grande quanto una word). Quindi sperimento un miss penalty legato a tutti questi tempi di accesso e<br />
tempi di trasferimento.<br />
Un’organizzazione che mi riduca questo miss penalty è la (b): organizzo la cache e la main memory<br />
in modo da aumentare il loro parallelismo, cioè tutta una locazione di main memory e di cache<br />
coincide con un intero blocco, e poi si fa il bus di dimensione pari a tutto il blocco (se è fatto da 4<br />
word da 32 bit il bus deve essere da 128 bit). In questo caso quando c’è un miss faccio un accesso<br />
solo alla main memory; quindi abbasso il miss penalty perché il tempo di accesso lo pago solo una<br />
volta e lo stesso per il tempo di trasferimento. Il problema di questa organizzazione è la<br />
103
ealizzazione del bus. Pago un altro prezzo: quando il processore accede alla cache lo fa per leggere<br />
o per scrivere una word; se la cache adesso ha un parallelismo maggiore di una word quando vi<br />
accedo escono tutte le word della locazione, quindi devo selezionare la word che mi interessa<br />
attraverso un multiplexer. Facendo così peggioro l’hit time che è il caso più frequente, e quindi il<br />
miglioramento del miss penalty potrebbe essere vanificato.<br />
La terza tecnica (c) è quella del memory interleaving: piuttosto che organizzare un bus grande<br />
quanto quello della seconda tecnica, lo facciamo della dimensione di una word, e il parallelismo<br />
della cache anch’esso di una word; facendo così togliamo il multiplexer. Organizzo la main<br />
memory in banchi fisicamente separati; ogni banco ha un parallelismo di una word (ogni blocco ha<br />
una word su ogni banco). Quando si deve selezionare un blocco si deve mandare l’indirizzo di<br />
questo blocco a tutti i banchi della main memory, e questo lo faccio in parallelo; questo significa<br />
che con un solo accesso ottengo quattro word (se ho 4 banchi); quindi il tempo di accesso lo pago<br />
solo una volta, mentre il tempo di trasferimento lo pago 4 volte perché il bus è di una word.<br />
Esempio:<br />
supponiamo che per indirizzare la memoria ci voglia 1 ciclo di clock, 6 cicli per accedere (cioè il<br />
tempo di accesso è di 6 cicli di clock), e 1 ciclo per trasferire il dato; supponiamo che il blocco della<br />
cache sia formata da 4 word. Vediamo nei tre casi cosa succede:<br />
a) miss penalty = 4 × (1 + 6 + 1) = 32 cicli di clock<br />
b) miss penalty = 1 + 6 + 1 = 8 cicli di clock<br />
c) miss penalty = 1 + 6 + 4 × 1 = 11 cicli di clock.<br />
104
25/04/2004<br />
Riduzione del miss rate<br />
L’obiettivo è ridurre il tempo medio di accesso alla memoria che, considerando una gerarchia di<br />
memoria con un solo livello (CPU, cache e main memory), possiamo esprimere con la seguente<br />
formula: AMAT = Hit time + Miss rate × Miss penalty.<br />
Abbiamo visto che una tecnica di riduzione del miss rate è quella di fare i blocchi più grandi.<br />
Un’altra tecnica è quella di utilizzare cache con un più alto grado di associatività. Lo svantaggio di<br />
utilizzare questa tecnica è quello che aumenta l’hit time. Supponiamo di avere il processore che<br />
emette un indirizzo che viene partizionato in un campo offset (spiazzamento della parola all’interno<br />
del blocco), un campo index (che indirizza il set della cache in cui è contenuto il blocco che<br />
contiene la word che stiamo cercando) e un campo tag (permette di stabilire se sul blocco che<br />
abbiamo individuato è effettivamente mappata la parola che stiamo cercando). Consideriamo una<br />
tag index ofs<br />
addr<br />
µP<br />
cache direct mapped. Di solito realmente<br />
abbiamo due banchi suddivisi: banco dei<br />
1 W tag e il banco che contiene i dati. Con<br />
index indirizziamo entrambi i banchi che<br />
tags Block<br />
emettono in uscita tag e blocco; il tag lo<br />
confrontiamo con un comparatore col tag<br />
che viene fuori dall’indirizzo e questo<br />
. .<br />
confronto ci dice se c’è un hit o meno. Il<br />
blocco è composto da N word, in<br />
generale, invece il processore non richiede<br />
blocchi ma word, quindi c’è un<br />
MUX multiplexer che estrae dal blocco la parola<br />
tag Block<br />
che il processore richiede, e questo lo fa<br />
attraverso il campo ofs.<br />
Hit<br />
?<br />
N<br />
Aumentiamo il grado di associatività (per esempio a due vie) di questa cache: ho un altro banco per<br />
addr<br />
tag index ofs µP<br />
?<br />
?<br />
tags block<br />
. .<br />
tags block<br />
MUX<br />
Block<br />
. . MUX<br />
1 W<br />
N<br />
i tag e un altro banco per i<br />
blocchi. Tutti i blocchi 0 di<br />
tutti i set sono mappati nel<br />
primo banco dei dati e tutti<br />
i blocchi 1 sono mappati<br />
nell’altro banco; lo stesso<br />
vale per i tag. Con l’indice<br />
indirizzo parallelamente<br />
sia il banco 0 sia il banco<br />
1, e ognuno dei banchi<br />
risponderà con i tag e i<br />
blocchi. Parallelamente<br />
confronto i tag: uno dei<br />
due restituirà un hit oppure<br />
entrambi un miss; ho una<br />
logica che in base a come<br />
rispondono i due<br />
comparatori mi dà il<br />
105
segnale di selezione del multiplexer che mi fa passare il blocco 0 o il blocco 1. A questo punto ho il<br />
blocco che contiene la word che il processore vuole leggere, e poi un multiplexer mi seleziona la<br />
word interessata. Il multiplexer in più rispetto alla direct mapped fa sì che l’hit time aumenti. Più<br />
aumenta il numero di vie più ingressi ha il multiplexer e di conseguenza più lento è. (N.B. Anche se<br />
ho più comparatori non aumenta l’hit time perché questi lavorano in parallelo).<br />
Un’altra tecnica per ridurre il miss rate (senza effetti collaterali) è quella che utilizza le cache<br />
vittime. Un’altra tecnica che abbiamo visto è quella che fa uso delle cache pseudo-associative.<br />
Esistono altre tecniche per la riduzione del miss rate:<br />
• il prefetching delle istruzioni e/o dei dati (hardware prefetching);<br />
• il prefetching controllato dal compilatore;<br />
(entrambe hanno bisogno di un supporto hardware)<br />
• le ottimizzazioni di compilazione, che non richiedono modifiche hardware:<br />
♦ Merging Arrays;<br />
♦ Loop Interchange;<br />
♦ Loop Fusion;<br />
♦ Blocking.<br />
Hardware Prefetching<br />
Accanto alla cache abbiamo un altro buffer di memoria che può ospitare anche un solo blocco e<br />
funziona nel seguente modo: quando c’è un miss devo caricare un blocco dalla memoria alla cache;<br />
invece che caricare un solo blocco, carico quel blocco, ma ne carico anche un altro che non<br />
memorizzo in cache ma in quel buffer; questo lo faccio per sfruttare la località spaziale.<br />
Vediamo i vantaggi che si possono avere.<br />
Per l’Alpha 21064 con 8 KB di instruction cache, per un benchmark si è sperimentato un miss rate<br />
= 1.10%. Supponiamo di utilizzare un hardware di prefetching. Il miss rate in questo buffer di<br />
prefetch supponiamo sia del 25% (di solito questi sono i valori per un buffer di prefetch che<br />
contiene solo una word). Supponiamo che l’hit time sia di 2 cicli di clock. Supponiamo anche che<br />
quando ho un miss, ma trovo il dato nel buffer di prefetch, sperimento un ciclo di clock.<br />
Consideriamo che il miss penalty sia di 50 cicli di clock.<br />
Calcoliamo l’AMAT:<br />
AMAT = Hit time + (se lo trovo in cache)<br />
Miss rate × Prefetch hit rate × 1 + (se abbiamo un miss però abbiamo un hit sul buffer di prefetch)<br />
Miss rate × (1 – Prefetch hit rate) × Miss penalty= (se un miss anche nel buffer di prefetch)<br />
= 2.415<br />
Se guardiamo il sistema da un punto di vista di più alto non sappiamo che il sistema diciamo che:<br />
AMAT = Hit time + Miss rate × Miss penalty.<br />
Vogliamo paragonare il miss rate di una macchina senza prefetching con una con prefetching; se<br />
sostituiamo i numeri otteniamo:<br />
Effective Miss rate = (AMAT – Hit time)/Miss penalty =0.83%; questo è il miss rate osservato<br />
dall’utente finale a cui non interessa se è un miss dovuto al fatto che non è stato trovato in cache o<br />
nel buffer di prefetch. Quindi abbiamo ottenuto una notevole riduzione del miss rate (da 1,1% a<br />
0.83%). Questo valore è quello che si sarebbe ottenuto se si fosse utilizzata una cache di 16 KB<br />
senza buffer di prefetch (utilizzando sempre lo stesso benchmark).<br />
Compiler-Controlled Prefetching<br />
Un’altra tecnica è quella di arricchire l’instruction set di un’istruzione nuova, che chiamiamo<br />
istruzione di prefetch, in cui noi forziamo il cache controller a prendere un blocco dalla memoria,<br />
anche se non ci sono stati miss, e metterlo in cache. Supponiamo che il nostro instruction set<br />
disponga di istruzioni di questo tipo, che consentono quindi il controllo software dei dati in cache;<br />
supponiamo anche che questa operazione possa essere fatta senza bloccare la cache: mentre<br />
106
abbiamo il dato che si sta spostando dalla memoria alla cache, quest’ultima, che è dotata di più<br />
porte, può continuare a fornire il processore di istruzioni e di dati.<br />
Consideriamo un cache di 8 KB direct mapped, con blocchi di 16 byte. Questo di seguito è un<br />
frammento di codice C: abbiamo due matrici a e b di double (8 byte)<br />
double a[3][100], b[101][3];<br />
...<br />
for(i=0;i
prefetch(b[j+7][0]);<br />
prefetch(a[0][j+7]);<br />
a[0][j]= b[j][0]*b[j+1][0];<br />
}<br />
for(i=1;i
Il numero di cicli di clock nel caso di prefetch è il seguente:<br />
Quindi abbiamo che il codice con le istruzioni di prefetch è 14650/3400 = 4,3 volte più veloce.<br />
Entrambe le tecniche che abbiamo visto sono ottimizzazioni del miss rate che determinano una<br />
modifica dell’hardware o dell’instruction set. Vediamo adesso una tecnica di ottimizzazione del<br />
miss rate che modifica l’hardware, ma modifica soltanto il software. Queste ottimizzazioni possono<br />
agire sia sulla parte del codice sia sulla parte dei dati del programma. Nella parte di codice il linker<br />
può ordinare le funzioni del nostro programma in modo tale che non creino conflitti; per esempio se<br />
ho un ciclo for che chiama due funzioni, il linker può pensare di fare in modo che queste due<br />
funzioni siano allocate in locazioni di memoria in modo tale che vengono mappate nella cache in<br />
zone che non creino tra loro conflitti. Ovviamente il compilatore deve essere conscio dell’hardware<br />
che c’è sotto.<br />
Merging Arrays<br />
Questa tecnica migliora la località spaziale. Molto spesso abbiamo degli array a cui accediamo nello<br />
stesso momento, con gli stessi indici, e hanno la stessa dimensione. Consideriamo il seguente<br />
programma:<br />
int val[SIZE];<br />
int key[SIZE];<br />
for(i=0;i
for(i=0;i
molto probabilmente lo avremo in cache perché l’abbiamo utilizzato nell’istruzione precedente, e lo<br />
stesso vale per c[i][j].<br />
Blocking<br />
Con questa tecnica viene modificato l’algoritmo per ridurre il numero di miss. Questa tecnica<br />
migliora la località temporale.<br />
Se abbiamo un algoritmo che opera su una struttura dati grossa, l’algoritmo viene diviso in tanti<br />
piccoli algoritmi che operano su zone piccole della struttura dati. Per esempio il seguente codice fa<br />
il prodotto di due matrici:<br />
for (i=0; i
