

Handleiding voor beginners in Microsoft SQL Server - Nederlandse ...
Handleiding voor beginners in Microsoft SQL Server - Nederlandse ...
Handleiding voor beginners in Microsoft SQL Server - Nederlandse ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Geplaatst door Henk Schreij op 12-10-04<br />
Henk Schreij<br />
Nu met <strong>in</strong>gang van Delphi 8 de MS <strong>SQL</strong> <strong>Server</strong> standaard wordtmeegeleverd met Delphi, is dit naast Interbase en Midas (xml/cds),<br />
een goed alternatief om je programma met een database uit te rusten. Voor mensen die gewend zijn met Paradox te werken, is MS<br />
<strong>SQL</strong> <strong>Server</strong> eenvoudig aan te leren omdat de overeenkomsten groot zijn (o.a. de aanwezigheid van Auto<strong>in</strong>crement-fields en een soort<br />
Database Desktop). Ook is er bij MS <strong>SQL</strong> <strong>Server</strong> een uitgebreide Help aanwezig, met veel <strong>voor</strong>beeld code.<br />
Vooraf<br />
Als je MS <strong>SQL</strong> <strong>Server</strong> <strong>in</strong>stalleert, en de defaultsaccepteert, dan zal de <strong>Server</strong> vanzelfopgestart worden als je de computerstart. Er<br />
verschijntrechtsonder<strong>in</strong> de tray een icoon met een groen (run) driehoekje en als h<strong>in</strong>t"MS <strong>SQL</strong> <strong>Server</strong> runn<strong>in</strong>g". Bij de <strong>in</strong>stallatievanMS<br />
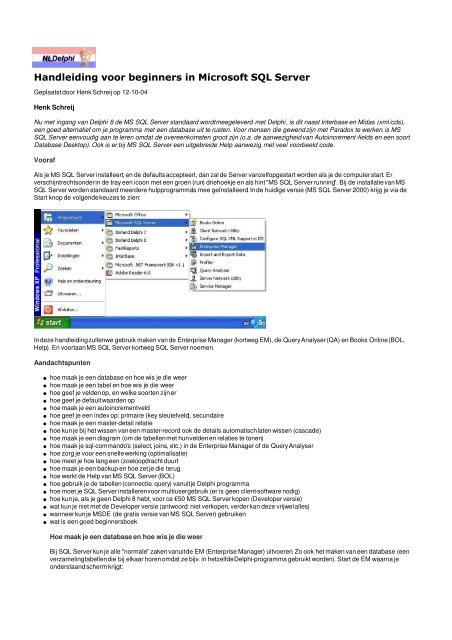
<strong>SQL</strong> <strong>Server</strong> worden standaard meerdere hulpprogramma's mee geïnstalleerd. Inde huidige versie (MS <strong>SQL</strong> <strong>Server</strong> 2000) krijg je via de<br />
Start knop de volgendekeuzes te zien:<br />
Indeze handleid<strong>in</strong>gzullenwe gebruik maken van de Enterprise Manager (kortweg EM), de QueryAnalyser(QA) en Books Onl<strong>in</strong>e(BOL,<br />
Help). En <strong>voor</strong>taanMS <strong>SQL</strong> <strong>Server</strong> kortweg <strong>SQL</strong> <strong>Server</strong> noemen.<br />
Aandachtspunten<br />
hoe maak je een database en hoe wis je die weer<br />
hoe maak je een tabel en hoe wis je die weer<br />
hoe geef je veldenop, en welke soorten zijner<br />
hoe geef je defaultwaarden op<br />
hoe maak je een auto<strong>in</strong>crementveld<br />
hoe geef je een <strong>in</strong>dex op: primaire (key sleutelveld), secundaire<br />
hoe maak je een master-detail relatie<br />
hoe kun je bij het wissen van een master-record ook de details automatischlaten wissen (cascade)<br />
hoe maak je een diagram (om de tabellenmet hunveldenen relaties te tonen)<br />
hoe maak je sql-commando's (select, jo<strong>in</strong>s, etc.) <strong>in</strong> de Enterprise Manager of de QueryAnalyser<br />
hoe zorg je <strong>voor</strong> een snellewerk<strong>in</strong>g (optimalisatie)<br />
hoe meet je hoe lang een (zoek)opdracht duurt<br />
hoe maak je een backup en hoe zet je die terug<br />
hoe werkt de Help van MS <strong>SQL</strong> <strong>Server</strong> (BOL)<br />
hoe gebruik je de tabellen(connectie, query) vanuitje Delphi programma<br />
hoe moet je <strong>SQL</strong> <strong>Server</strong> <strong>in</strong>stalleren<strong>voor</strong> multiusergebruik (er is geen client-software nodig)<br />
hoe kun je, als je geen Delphi 8 hebt, <strong>voor</strong> ca €50 MS <strong>SQL</strong> <strong>Server</strong> kopen (Developer versie)<br />
wat kun je niet met de Developer versie (antwoord: niet verkopen, verder kan deze vrijwelalles)<br />
wanneerkunje MSDE (de gratis versie vanMS <strong>SQL</strong> <strong>Server</strong>) gebruiken<br />
wat is een goed <strong>beg<strong>in</strong>ners</strong>boek<br />
Hoe maak je een database en hoe wis je die weer<br />
Bij <strong>SQL</strong> <strong>Server</strong> kun je alle "normale" zaken vanuitde EM (Enterprise Manager) uitvoeren. Zo ook het maken van een database (een<br />
verzamel<strong>in</strong>gtabellendie bij elkaar horenomdat ze bijv. <strong>in</strong> hetzelfdeDelphi-programma gebruikt worden). Start de EM waarna je<br />
onderstaandscherm krijgt:
Na een klik op de plus knop krijg je de <strong>SQL</strong> <strong>Server</strong> Group, bij de volgendeplusklik de server (local, ofwel de computerwaarop <strong>SQL</strong><br />
<strong>Server</strong> staat). Dan moet je even wachtentot er verb<strong>in</strong>d<strong>in</strong>gis (het rondje wordt dan groen) waarna je op Databases kuntklikken.<br />
Doe dat niet te vlug(<strong>voor</strong> de verb<strong>in</strong>d<strong>in</strong>ger is), want dan moet je de boel afsluitenen opnieuwbeg<strong>in</strong>nen. Je scherm vertoontnuhet<br />
volgendebeeld:<br />
Van master, model en msdb moet je afblijven, daar<strong>in</strong> zit de structuurvande database (net zoals Delphi <strong>in</strong> Delphi is geschreven).<br />
Northw<strong>in</strong>den pubs zijnmeegeleverde demo-databases. Tempdb is ook van <strong>SQL</strong> <strong>Server</strong> zelf, en verbodenterre<strong>in</strong>. Zet daar niet zelf<br />
een tabel <strong>in</strong>, want <strong>SQL</strong> <strong>Server</strong> beslist zelfwanneerdeze database wordt opgeruimd (en je zultniet de eerste zijndie een moeizaam<br />
opgebouwde test-tabel de volgendedag niet meer kan terugv<strong>in</strong>den).<br />
Stel dat je een oefen-database wilt aanmakenmet de naam Kanweg, dan gaat dat heel eenvoudigdoor met de rechtermuistoets<br />
op Databases te klikken en <strong>in</strong> de popup "New Database" te kiezen. Inhet dan verschenen<strong>in</strong>vulschermvulje bij Name de naam<br />
Kanweg <strong>in</strong>, en laat je (als beg<strong>in</strong>ner) de overige defaultwaarden staan. Zie onderstaande <strong>voor</strong>beeld:<br />
Na OK heb je een nieuwe database met de naam Kanweg <strong>in</strong> het lijstje onder Databases staan. Mocht dat niet zo zijndan moet je<br />
even de EM afsluitenen opnieuw opstarten om een Refreshte forceren; de EM wil nog wel eens "vergeetachtig" zijnbij het<br />
toevoegen vaneen Database. Het weghalenis even eenvoudig: rechtsklik op Kanweg, kies Delete(Verwijderen) en sla Yes(Ja)<br />
aan.
Wees overigens <strong>voor</strong>zichtigmet dergelijke opdrachten<strong>in</strong> de EM, de complete Database wordt gewist, met <strong>in</strong>houden al, en zonder<br />
verdere waarschuw<strong>in</strong>g. Dat geldt <strong>voor</strong> wel meer plaatsen <strong>in</strong> de EM; het is een bijzonderkrachtige tool, maar het werkt zonder<br />
pardon en je moet wel weten wat je doet.<br />
Hoe maak je een tabel en hoe wis je die weer<br />
Als je het plusje aanklikt <strong>voor</strong> de databasenaam dan krijg je te zien uit welke zaken een database is opgebouwd, waaronder de<br />
Tables (tabellen). Het aanmakenvan een nieuwe tabel gaat vrijwelnet zo als het aanmakenvaneen database: Rechtsklikop het<br />
woord Tables en kies <strong>in</strong> de verschenenpopup: "New Table" (je kuntook <strong>in</strong> het rechtse scherm rechtsklikken, dan krijg je dezelfde<br />
popup).<br />
Je aangemaakte tabel (bijv. Test) zal straks rechts te midden van een tw<strong>in</strong>tigtalsysteem-tabellenverschijnen. Mocht het later een<br />
ratjetoe worden met User en System tabellendoor elkaar, dan kun je door op de knop Type te drukken(zie het driehoekje<br />
bovenaan) de boel netjes bij elkaar zetten(druk op Name om de User-tabellendaarna te sorteren). Inde systeemtabellenzit de<br />
opbouw van je database, ze beg<strong>in</strong>nenalle met sys, behalvedtproperties (dt = design tools verzorgtde koppel<strong>in</strong>g naar Visual Studio<br />
of Visio). Maar <strong>voor</strong>dat je tabel <strong>in</strong> de lijst verschijntmoet je eerst de velden(en tot slot de naam) opgeven. Daar<strong>voor</strong> krijg je eerst<br />
(automatisch) het volgendescherm:<br />
Over het opgeven van de velden<strong>voor</strong> de tabel gaat de volgendeparagraaf (zie aldaar). Na het opgeven vande veldendruk je op<br />
het Save (diskette) symbool, of druk je op de sluit-knop, waarna je een naam <strong>voor</strong> de tabel moet <strong>in</strong>vullenen alles wordt opgeslagen.<br />
Het verwijderenvaneen tabel is ook eenvoudig. Rechtsklikop de te verwijderentabel en kies <strong>in</strong> de afrollijstDelete (Verwijderen).<br />
Er verschijnteen bevestig<strong>in</strong>gsvraag<strong>in</strong> een scherm:
Het is een goede gewoonte om <strong>voor</strong> het <strong>in</strong>drukkenvande knop "Drop All" eerst de knop "Show Dependencies" <strong>in</strong> te drukken om te<br />
kijken of het verwijderenvan de tabel geen neveneffectenheeft. Denk bij<strong>voor</strong>beeld aan een Master-detail-relatie of aan een View<br />
gebaseerd op deze tabel.<br />
Merk op dat <strong>in</strong> het popup-menuook nog de keuze "Design Table" staat, deze is <strong>voor</strong> het wijzigen vaneen bestaande tabel (zie<br />
later), je hoeftdus niet <strong>in</strong> één keer alles goed te doen.<br />
Hoe geef je velden op, en welkesoorten velden zijn er<br />
Als je een veld opgeeft dan moet je vier zaken <strong>in</strong>vullen: de veldnaam, het Datatype, de Lengte (niet bij getallen) en AllowNulls(of het<br />
veld een NULL waarde mag bevatten). Hierna wordt elk apart toegelicht (zie ook <strong>voor</strong>gaande figuur"[New Table <strong>in</strong> Kanweg]"):<br />
Veldnamen<br />
Het is goed als je op een consequentemanier de veldnaamopgeeft, bij<strong>voor</strong>beeld:<br />
Veldnamenaltijd <strong>in</strong> enkelvoud(vb Achternaam, Straat, Woonplaats) tegenovertabelnamenaltijd als meervoud(vb Personen,<br />
Klanten, Orders).<br />
Sleutelveld(Keyveld) e<strong>in</strong>digend op ID (vb PersoonID, OrderID; ID=Identity), nooit een tussen-s (geen PersoonsID, maar<br />
PersoonID). Hoe je een sleutelveldopgeeft, en wat dat is, komt later.<br />
Een datumveldaltijd op het woord Datum latene<strong>in</strong>digen (vb OrderDatum, Pr<strong>in</strong>tDatum)<br />
Samengestelde woorden op Pascal-wijze schrijven(vb OrderDatum, EmailZakelijk, EmailPrive)<br />
Bovenstaandeschrijfwijzeis als <strong>voor</strong>beeld gegeven (naar de wijze waarop de database Northw<strong>in</strong>dis opgezet), elke andere<br />
schrijfwijzeis evengoed, mits deze maar consequentwordt toegepast. Wantzo is het een stuk eenvoudigerom sql opdrachtente<br />
schrijvenen zijndeze opdrachtenlater gemakkelijker te lezen.<br />
Datatype<br />
Als je geen datatype kiest dan zal <strong>SQL</strong> <strong>Server</strong> er een Char(10) veld van maken. Dit is meestal een ongunstigekeuzeomdat het<br />
beter is om een str<strong>in</strong>gveldals Varchar op te slaan. Bij een Char wordt namelijkde tekst uitgevuldmet spaties, waardoor je later de<br />
uitkomstweer moet trimmen; heel onhandig. Veel gebruikte Datatypes zijn:<br />
varchar<br />
max 8000 tekens lang waarvaner max 900 getoond worden <strong>in</strong> de EM (anders staat er ). Er mogen CR/LF (#13#10)<br />
<strong>in</strong> <strong>voor</strong>komen(dus ook bruikbaar <strong>voor</strong> korte Memo teksten)<br />
<strong>in</strong>t geheel getal (is <strong>in</strong>t32, op ruim 10 cijfers nauwkeurig, nl -2147483648 tot +2147483647)<br />
bit een 0 of een 1 (vaak <strong>voor</strong> Booleans gebruikt)<br />
float<br />
een double (8 byte double precision, "drijvendekomma" gebroken getal) max 308 cijfers <strong>voor</strong> of na de komma,<br />
waarvan15 cijfers nauwkeurig<br />
smallmoney geld-bedrag op 0,1 cent nauwkeurig(max/m<strong>in</strong> +/-200.000.000,001)<br />
money geld, bedrag op 0,1 cent nauwkeurig, zo groot dat zelfsde omzet van<strong>Microsoft</strong> er<strong>in</strong> past<br />
decimal gebroken getal net als een float, maar nu met elk cijfer betrouwbaar, zie later (bij default) <strong>voor</strong> meer uitleg<br />
numeric synoniem<strong>voor</strong> decimal<br />
smalldatetimedatum+tijd, op 1 m<strong>in</strong> nauwkeurig<br />
datetime datum+tijd, op 0,03 sec nauwkeurig<br />
text <strong>voor</strong> tekst tot max 2GB groot. Bij meer dan 900 tekens toont de EM<br />
image blob (plaatje) tot max 2GB groot<br />
<strong>SQL</strong> <strong>Server</strong> kent geen datatype <strong>voor</strong> de datum alleen(geen Date type), dan gebruik je smalldatetimeen zet je de tijd op 0:00. <strong>SQL</strong><br />
<strong>Server</strong> kent overigens ook geen Time type. Het nvarchartype (de n staat <strong>voor</strong> national, ook geschikt <strong>voor</strong> arabisch, ch<strong>in</strong>ees, etc.) is<br />
een Unicode lettertypedat 2 bytes per gebruikte letter opslaat. Deze kun je (nu) beter niet gebruiken, hetzelfdegeldt <strong>voor</strong> het ntext<br />
type. Alhoewel, ... <strong>in</strong> de DotNet omgev<strong>in</strong>g (Delphi 8) volgtUnicode de ANSI standaard uit W<strong>in</strong>32 op, zodat op termijnde nvarchar<br />
en ntextde gebruikelijke veldtypenzullenzijn.<br />
Lengte<br />
Bij een varcharmoet je de lengte opgeven (het maximaal aantal tekens dat <strong>in</strong> het veld getypt mag worden), bij alle andere types zet<br />
<strong>SQL</strong> <strong>Server</strong> er zelfeen lengte neer, waarvanje de waarde niet kuntveranderen. veldtypenzullenzijn.
AllowNulls<br />
Onder andere bij getallen, maakt het een groot verschilof je wel of niet NULL waarden toestaat. Denk aan een kolom die of "leeg"<br />
kan zijn(niet <strong>in</strong>gevuldofwel onbekend) of het getal 0,00 bevatten(niets). Waar mogelijk moet je NULL waarden niet toestaan (het<br />
v<strong>in</strong>kjebij AllowNullsweghalen). Wantbij<strong>voor</strong>beeld <strong>in</strong> een optell<strong>in</strong>gkan het een onverwachteuitkomst opleveren. (Wat is de som van<br />
10,00 + 20,00 + NULL? Het antwoord is NULL, immers onbekend + 30,00 = onbekend). AllowNullsuitzettenhoudt<strong>in</strong> dat de <strong>in</strong>vull<strong>in</strong>g<br />
verplichtwordt. Tenzijje een default-waarde opgeeft, waarover later meer.<br />
Wijzigen<br />
Je kuntlater, via Design Table, altijd nog veldentoevoegen en wijzigen. Zolanger nog geen gegevens <strong>in</strong> zittenkun je de lengte<br />
kle<strong>in</strong>er zetten, of andere wijzig<strong>in</strong>genaanbrengen. Als er al gegevens <strong>in</strong>staan controleert<strong>SQL</strong> <strong>Server</strong> bij het opslaan van de<br />
wijzig<strong>in</strong>genof dit geen problemengeeft. Zo nee, dan voert hij de wijzig<strong>in</strong>g door. Zo ja, dan krijg je een waarschuw<strong>in</strong>g. Bij<strong>voor</strong>beeld,<br />
als je varchar(10) omzet<strong>in</strong> varchar(5) en er is ergens een tekst <strong>in</strong>gevuldvan 6 of langer dan moet je de wijzig<strong>in</strong>g bevestigen (en<br />
kapt hij af na de 5e positie).<br />
Overigens, wil je met de EM wat testjes <strong>in</strong>vullendan gaat dat via een rechtsklik op de tabel, en dan de keuze "Open table" en<br />
"Returnall rows" (later meer hierover).<br />
Een dubbelklik op de tabel opent niet (zoals bij veel andere merken database) de tabel: dan krijg je het scherm Table Properties<br />
(Eigenschappen).<br />
Bij Eigenschappen staat achter Rows ook het aantal records <strong>in</strong> de tabel (2). Pas op, dat je dit aantal niet zo zondermeer gebruikt.<br />
Het is een geschat aantal en bij een groter aantal records klopt het ongeveer, maar niet precies (je zultniet de eerste zijndie met<br />
een SELECT COUNT(*) er een paar meer of m<strong>in</strong>der krijgt, en daarna alle <strong>in</strong>vull<strong>in</strong>gengaat controleren).<br />
De kolom Key geeft aan of het veld een sleutelveld(primary key) is, de kolom ID of het een Identity(=auto<strong>in</strong>crement) veld is en<br />
Defaultof het veld een defaultwaarde heeft. In<strong>voor</strong>gaand <strong>voor</strong>beeld is daar geen sprake van, <strong>in</strong> onderstaand<strong>voor</strong>beeld zijnze wel<br />
gebruikt.<br />
Veld TestIDis een auto<strong>in</strong>crementsleutelveld, veld Testtekstheeft als defaulteen lege str<strong>in</strong>g. Meer uitleg volgtlater.
Hoe voer je testgegevens <strong>in</strong><br />
Met de EM kunje prima gegevens <strong>in</strong>voeren<strong>in</strong> een tabel. Rechtsklikop de tabel en kies "Open table" en "Returnall rows". De<br />
eerste keer zie je een lege regel (met een * er<strong>voor</strong>) alwaar je zo gegevens kunt<strong>in</strong>typen. Als je daarna met pijlneernaar de volgende<br />
regel gaat, slaat hij hetgeen je <strong>in</strong>gevoerd hebt op. Tenzijje een veld met verplichte<strong>in</strong>vull<strong>in</strong>g(bij Allow Nullsstaat geen v<strong>in</strong>kje) leeg<br />
laat, dan weigert hij met een foutboodschap. Ook krijg je een foutboodschapals je uit een veld gaat en er klopt iets niet aan de<br />
<strong>in</strong>vull<strong>in</strong>gervan(bijv. te veel tekens <strong>in</strong>gevoerd).<br />
Nog wat opmerk<strong>in</strong>genen tips:<br />
Je kunteen kolom breder maken door <strong>in</strong> de kop de muis boven de veldscheid<strong>in</strong>gte houden, en naar rechts te slepen.<br />
Een datum voer je <strong>in</strong> volgensde W<strong>in</strong>dows datum<strong>in</strong>stell<strong>in</strong>g, dat is <strong>in</strong> Nederlandmeestal 3 getallengescheiden door een<br />
streepje. Bij het jaar hoef je niet de 2000 er<strong>voor</strong> te typen. En de slash mag ook ipv het streepje. Bijv. als je 31/2/4 typt krijg je<br />
de datum 31-2-2004.<br />
Ineen text veld kun je via een truc meerregelige <strong>in</strong>voer (bijv. 3 regels onder elkaar) <strong>in</strong>voeren. Namelijk door de regels (bijv. uit<br />
een txt bestand, waar<strong>in</strong> 3 regels onder elkaar staan) naar het klembord te kopiÙren en dan <strong>in</strong> het veld te plakken. Dit werkt<br />
ook <strong>in</strong> een varcharveld.<br />
Bij meerregelige <strong>in</strong>voerzie je alleende bovensteregel. Door <strong>in</strong> het veld te klikken en daarna pijlneeraan te slaan zie je de<br />
volgenderegel.<br />
Voorbeeld: <strong>in</strong> het bovensterecord staan <strong>in</strong> het veld Tekst twee regels: 'Handig: pijlneer' en er onder 'toont regel2'. Als je <strong>in</strong> het<br />
hokje Tekst gaat staan en je slaat pijlneeraan dan zie je de 2e regel ('toont regel2'). Overigens, je moet het veld <strong>in</strong> Edit mode<br />
hebben staan door er op te klikken (en niet met tab of pijltoets er heen gaan) anders ga je met pijlneernaar het volgende<br />
record.<br />
Een leeg veld toont de tekst , maar als je de cursor <strong>in</strong> dat hokje zet toont hij niets. Mocht je een NULL waarde willen<strong>in</strong>voeren,<br />
dan kan dat met de toetsencomb<strong>in</strong>atie: Ctrl + 0.<br />
Een veld waar<strong>in</strong> meer dan 900 tekens staan toont .<br />
Een float, decimal of moneyveld vulje <strong>in</strong> met de decimaalscheider volgensde W<strong>in</strong>dows <strong>in</strong>stell<strong>in</strong>g, dat is <strong>in</strong> Nederland<br />
meestal een komma. Eventuelenullenachter de komma worden niet getoond.<br />
Een record (hele regel) wissen gaat door op het driehoekje <strong>voor</strong> de regel te klikken om de hele regel te selecterenen dan de<br />
Delete toets aan te slaan (of na een rechtsklik Delete <strong>in</strong> de popup te kiezen).<br />
Hoe geef je default waarden op<br />
Zoals eerder uitgelegd moet je, als het niet persé nodig is, er <strong>voor</strong> zorgendat er geen NULL-waarden kunnen<strong>voor</strong>komen<strong>in</strong> je tabel.<br />
NULL waarden kunnenonverwachte(foute) uitkomstenopleveren, maken je SELECT-opdracht onnodig <strong>in</strong>gewikkeld omdat ze een<br />
extra test vragen(WHERE Naam = '' OR Naam IS NULL) en maken een <strong>SQL</strong>-opdracht langzamer(bij NULL waarden kan geen<br />
primaire <strong>in</strong>dex gebruikt worden). Zet dus waar mogelijk het v<strong>in</strong>kjebij "Allow Nulls" uit. Het gevolg is daardoor dan wel dat je altijd<br />
wat moet <strong>in</strong>vullen<strong>voor</strong> dat veld, en dat is ook weer onhandig. De oploss<strong>in</strong>g is, om <strong>voor</strong> deze veldeneen defaultwaarde mee te<br />
geven. Te weten een lege str<strong>in</strong>g <strong>voor</strong> ('') <strong>voor</strong> een tekstveld, een 0 <strong>voor</strong> een getalveld, en misschien zelfsde huidige datum <strong>voor</strong> een<br />
datumveld. Of een 'j' <strong>voor</strong> een j/n-veld (waar een 'j' of 'n' <strong>in</strong>komt), een 'm' <strong>voor</strong> een m/v veld, etc.<br />
Het <strong>in</strong>vullenvaneen defaultwaarde gaat heel eenvoudigtijdens het opgeven vande velden(zie een eerdere paragaaf). Onderaan<br />
staat namelijknog een schermdeelwaarmee je per veld aanvullendegegevens kuntopgeven, te weten achter "DefaultValue" de<br />
defaultwaarde. Inonderstaandefiguuris dat bij<strong>voor</strong>beeld twee apostrofs, een lege str<strong>in</strong>g.
Zo ook kun je een 0 (nul) opgeven <strong>voor</strong> een getalveld(<strong>in</strong>teger, float, decimal).<br />
Wil je de huidige datum opgeven als default<strong>voor</strong> een datumvelddan kun je getdate() <strong>in</strong>typen. Let op de open- en sluithaakachter<br />
getdate, waartussenniets moet komen te staan (weer een ontwerperbezig geweest met een C-tick). Alleen, geeft getdate() de<br />
huidige datum+tijd, wil je de datum zondertijd dan moet je iets meer opgeven, namelijk:<br />
convert(char(8),getdate(),112)<br />
Overigens, er zijnook andere manierenom de datum zondertijd op te geven, deze is er een die mij goed bevalt, <strong>voor</strong> de werk<strong>in</strong>g<br />
verwijs ik naar BOL, de <strong>SQL</strong> <strong>Server</strong> Help (wordt later behandeld).<br />
Precision en Scale<br />
Bij een decimal veld (gebroken getal waarvanalle cijfers vastgelegd worden) kun je Precision en Scale opgeven. Inbovenstaande<br />
figuurkunje bovenaanop het veld Prijs klikken (er komt een driehoekje <strong>voor</strong> te staan) waarna onderaan de woorden Precision en<br />
Scale zwartworden. Bij precision kun je het aantal significante cijfers opgeven, bij scale het aantal cijfers achter de komma.<br />
Bij<strong>voor</strong>beeld als je op 2 cijfers na de komma nauwkeurigwilt werken en het grootst <strong>voor</strong>komendegetal is 999.999,99 moet je een<br />
precision van 8 en een scale van 2 opgeven. Dan wordt het getal <strong>in</strong> 5 bytes opgeslagen hetgeen je kuntzien omdat er bij Length<br />
een 5 komt te staan. Overigenshad je net zo goed een precision van9 kunnenopgeven, dan wordt het ook <strong>in</strong> 5 bytes opgeslagen<br />
(maar niet 10, dan komt het <strong>in</strong> 6 bytes). Het is gunstig (en dus gebruikelijk) om een precision van9 (opslag <strong>in</strong> 5 bytes), 19 (opslag <strong>in</strong><br />
9 bytes, de default), 28 (13 bytes) of 38 (17 bytes) te gebruiken.<br />
Hoe maak je een auto<strong>in</strong>crementveld<br />
Een auto<strong>in</strong>crementveld is een getalvelddat automatischbij elk nieuwrecord opgehoogd wordt. Meestal beg<strong>in</strong> je bij het eerste<br />
record met de waarde 1 en hoog je het getal bij elk nieuwrecord met 1 op. <strong>SQL</strong> <strong>Server</strong> noemt dit een Identity-veld met Identity<br />
Seed <strong>voor</strong> de startwaarde en IdentityIncrement<strong>voor</strong> de ophog<strong>in</strong>g (beide mogen best een grotere waarde dan 1 krijgen). Het<br />
opgeven is eenvoudig(zie onderaan bij Design Table): Zet bij een Integer-veld de Identityop Yes en vuleen 1 <strong>in</strong> bij Seed en<br />
Increment. Overigenszal <strong>SQL</strong> <strong>Server</strong> zelfAllow Nullsuitzetten, mochtje dat vergetenzijn, omdat een lege waarde natuurlijknooit<br />
<strong>voor</strong>komtbij auto<strong>in</strong>crement.<br />
Het is gebruikelijk om <strong>voor</strong> een auto<strong>in</strong>crement-veld het eerste veld te gebruiken.<br />
Hoe geef je een primaire<strong>in</strong>dex (key, sleutelveld) op<br />
Als je vaneen veld een primaire <strong>in</strong>dex (primary key of kortweg key) maakt, zorg je er<strong>voor</strong> dat <strong>in</strong> dat veld alleeneen unieke waarde<br />
(nooit twee maal dezelfde) <strong>voor</strong>komt. Dit is vaak essentieel, bij<strong>voor</strong>beeld bij een master-detail-relatie (zie later).<br />
Het opgeven dat een veld een Key is, gaat eenvoudig(zie figuur):<br />
Eerst klik je ergens <strong>in</strong> het veld dat de key moet worden (het eerste veld is daar<strong>voor</strong> gebruikelijk), dan klik je bovenaanop het<br />
sleuteltje(met als H<strong>in</strong>t: Set primary key) en er verschijnteen sleuteltje<strong>voor</strong> het veld. De eerste keer is het even zoeken naar het<br />
sleuteltje, het staat namelijkniet <strong>in</strong> het design scherm, of het Console scherm, maar <strong>in</strong> het scherm van<strong>SQL</strong> <strong>Server</strong> zelf. Maar dat<br />
went snel, ook <strong>voor</strong> de andere knoppen en de menu-keuzes. Overigenszal <strong>SQL</strong> <strong>Server</strong> zelfAllow Nullsuitzetten, mocht je dat<br />
vergetenzijn, omdat een lege waarde natuurlijknooit <strong>voor</strong>komtbij een primaire <strong>in</strong>dex (Key).<br />
Wil je een primaire <strong>in</strong>dex op meerdere velden(bijv. Postcode en huisnr) dan moet je meerdere veldenselecteren <strong>voor</strong>dat je op de<br />
sleutel-knop drukt. Dat gaat op de bekende W<strong>in</strong>dows wijze met het klikken op deze veldenterwijl de Ctrl-toets <strong>in</strong>gedruktwordt<br />
gehouden, waarbij de aangeklikte regels een andere kleurkrijgen, zie de figuurhieronder:<br />
Standaard <strong>in</strong>stell<strong>in</strong>gvan<strong>SQL</strong> <strong>Server</strong> is, dat de records ook fysiek <strong>in</strong> de volgorde van de primairy key <strong>in</strong> de database worden<br />
opgeslagen. Dat wordt Clustered genoemd. Het <strong>voor</strong>deel daarvan is dat SELECT opdrachtensnellerwerken, <strong>voor</strong>al <strong>in</strong> comb<strong>in</strong>atie<br />
met een secundaire <strong>in</strong>dex (zie later). Het nadeel is dat de INSERTopdrachteniets langzamerzijn(hetgeen eigenlijk nooit een<br />
probleem is, omdat je daar pas wat vanmerkt als je duizendenrecords <strong>in</strong> één bulk opdracht toevoegt).
Je kuntClustered zelfop Trueof False zettenmet de Properties knop, 2e l<strong>in</strong>ks vanboven (handjemet wijzendev<strong>in</strong>ger), waarna je <strong>in</strong><br />
het vervolgschermhet tabblad Indexeskiest, zie onderstaande figuur. Het is echter verstandig om elke tabel een clustered primaire<br />
<strong>in</strong>dex te geven. Enige uitzonder<strong>in</strong>gis een lookup tabel (een tabel met maar we<strong>in</strong>ig records die nooit gewijzigd worden). Een<br />
SELECT naar een lookup tabel kan door het gebruik van een <strong>in</strong>dex langzamerworden (het zoeken <strong>in</strong> een kle<strong>in</strong> stapeltje (heap) is<br />
snellerdan via de tussenstapvan een <strong>in</strong>dex). Maar <strong>in</strong> de praktijk valtdat best mee omdat de loopup operatie op zich heel snel is.<br />
Overigenskun je bij Order ook nog de volgorde (op/aflopend) opgeven. En de automatischgegeven naam PK_Test (PK = Primary<br />
Key) kun je wijzigen (bijv. <strong>in</strong> PK_Test_Postcode_HuisNr).<br />
Hoe geef je een niet-primaire(secundaire) <strong>in</strong>dex op<br />
Inhetzelfdeproperties-scherm (via de handje-knop te bereiken) kunje bij de tab Indexes/Keys met de knop New een <strong>in</strong>dex<br />
opgeven. Alhoewel dat ongebruikelijkis, kun je een <strong>in</strong>dex opgeven, zonderdat er een primaire <strong>in</strong>dex is. Ik ga ervanuit dat bij het<br />
opgeven vaneen <strong>in</strong>dex altijd een primaire <strong>in</strong>dex is, daarom noem ik deze <strong>in</strong>dex <strong>voor</strong>taande secundaire <strong>in</strong>dex.<br />
Bij het opgeven vaneen secundaire <strong>in</strong>dex krijgt deze automatischde naam IX_Tabelnaam(een volgende<strong>in</strong>dex IX_Tabelnaam1,<br />
etc.). Zie onderstaandefiguur. Het is aan te bevelenom deze <strong>in</strong> een z<strong>in</strong>vollenaam om te zetten, bijv. IX_Test_Prijs (<strong>in</strong>dex op het<br />
veld Prijs).<br />
Het veld waarop de <strong>in</strong>dex moet komen geef je op onder Columnname. Je kunthet kiezen uit een afrollijstjemet mogelijke namen<br />
waar<strong>in</strong> de veldenwaarop geen <strong>in</strong>dex mogelijk is (image, text, e.d.) niet <strong>voor</strong>komen. Je kuntook meer dan 1 veld opgeven <strong>voor</strong> de<br />
<strong>in</strong>dex, bijv. Achternaamen Voornaam, door na opgave van het 1e veld naar de regel eronder te gaan, alwaar weer een afrollijstje<br />
verschijnt.<br />
Onderaanstaan nog twee opties: Create UNIQUEen Create as CLUSTERED.<br />
Om met de laatste te beg<strong>in</strong>nen, een tabel kan maar één clustered<strong>in</strong>dex hebben. Omdat i.h.a. de primaire <strong>in</strong>dex dat al is, zulje een<br />
foutboodschapkrijgen als je deze optie aanv<strong>in</strong>kt.<br />
Tot slot nog "Create UNIQUE", hiermee kun je er<strong>voor</strong> zorgendat er geen dubbele waarden <strong>voor</strong>komen<strong>in</strong> veld/kolom van de tabel.<br />
V<strong>in</strong>k "Create UNIQUE" aan en kies het rondje <strong>voor</strong> Index(Constra<strong>in</strong>tsbehandelik niet <strong>in</strong> dit artikel). Hierdoor is, behalvedat de<br />
sorteervolgordeis opgegeven, ook elke <strong>in</strong>vull<strong>in</strong>guniek <strong>voor</strong> de opgegeven kolom(men). Het verschilmet de eerder behandelde<br />
primaire <strong>in</strong>dex is dat er daar maar één vanmag bestaan, tegenovermeerdere secundaire <strong>in</strong>dexen. En dat er nuook NULL<br />
waarden mogen <strong>voor</strong>komen(als bij "Allow nulls" een v<strong>in</strong>kjestaat). Ignoreduplicate key is <strong>voor</strong>al handig als je veld(en) uniek maakt<br />
<strong>in</strong> een bestaande tabel. Daarmee worden dubbelengewist zodat je geen foutboodschapkrijgt.
Hoe maak je een master-detail-relatie<br />
Een master-detail-relatie komt bij<strong>voor</strong>beeld <strong>voor</strong> bij klantendie meerdere orders hebben. Dan is er sprake vantwee tabellenmet<br />
klantresp. ordergegevens, die een gemeenschappelijkveld hebben (bijv. KlantID) waarop de order gegevens die bij een klant<br />
horente v<strong>in</strong>denzijn. Zie de figuur.<br />
Zo zijnhet nog twee onafhankelijketabellen, zodat er klantnummers(KlantID's) <strong>in</strong> de ene tabel kunnenbestaan die <strong>in</strong> de andere<br />
tabel niet <strong>voor</strong>komen, waardoor er orders kunnenbestaan zonderdat er een klantbijhoort. Wat nodig is dat er een relatie wordt<br />
afgedwongentussendeze twee tabellen, zodat de <strong>in</strong>voer vaneen order niet kan zonderdat er een bestaand klantnummeris. In<br />
Paradox noemdenze dat referentiÙle<strong>in</strong>tegriteit. In<strong>SQL</strong> <strong>Server</strong> ook (referential<strong>in</strong>tegrity), of ze noemenhet een "one to many<br />
relationship". Het is veruithet gemakkelijkst om een dergelijke relatie op te geven <strong>in</strong> een diagram (zie de paragraaf "hoe maak je<br />
een diagram") maar het kan ook tijdens "design table". Voordat je dat doet moet je <strong>in</strong> de master tabel (hier Klanten) er<strong>voor</strong> gezorgd<br />
hebben dat er een ID-veld bestaat (hier KlantID) dat uniek is (hier een Key veld, maar het mag ook een unieke <strong>in</strong>dex zijn).<br />
De referentiÙle<strong>in</strong>tegriteit geef je op <strong>voor</strong> het koppelveldvan de detail tabel (hier KlantIDvanOrders). Zorg er<strong>voor</strong> dat de detail<br />
tabel <strong>in</strong> design mode is en rechtsklik op een willekeurige plaats en kies Relationships. Dan verschijnthet Properties scherm met de<br />
tab Relationsen eerst nog helemaalleeg. Druk daar<strong>in</strong> op de knop New waarna de relatie wordt aangemaakt, zie de figuur.
Bij "Selected relationship" zie je <strong>voor</strong> de automatischaangemaakte naam een symbool staan vantwee rondjes aan elkaar. Dat is<br />
het teken <strong>voor</strong> one<strong>in</strong>dig, wat symbool staat <strong>voor</strong> dat er vele (many) Orders kunnenhorenbij één klant. Het beg<strong>in</strong> vande naam, FK<br />
staat <strong>voor</strong> Foreign Key, en geeft aan dat er <strong>in</strong> een andere tabel een Key <strong>voor</strong> deze tabel bestaat. Welke tabel dat is geef je op <strong>in</strong><br />
een afrollijstbij "Primary key table" (die staat <strong>in</strong> dit <strong>voor</strong>beeld automatischgoed omdat er maar 2 tabellenzijn). Daaronder staan de<br />
veldnamenvande tabel, waaruit je de primary key (KlantID) kiest. Evenzokies je rechts onder Orders dezelfdeveldnaamuit de<br />
detail tabel (KlantIDuit Orders). Dat is alles.<br />
De drie v<strong>in</strong>kjesbij Check exist<strong>in</strong>g data, Enforce for replication en Enforce Insertsand Updates laat je staan. Exist<strong>in</strong>g data heb je<br />
niets mee te maken als je een lege tabel hebt. Replication zorgt er<strong>voor</strong> dat als je de tabel ooit kopieert naar een andere database<br />
de relatie dan mee gaat. En de laatste is het meest belangrijk, die zorgt er<strong>voor</strong> dat geen orders geplaatst of gewijzigd kunnen<br />
worden zonderdat er een bijbehorende KlantIDbestaat.<br />
Cascade komt <strong>in</strong> een volgendeparagraaf ter sprake.<br />
Als je het design-scherm (van de detail, de Orders-tabel) sluit, of de save-knop <strong>in</strong>drukt, krijg je een scherm met een extra<br />
bevestig<strong>in</strong>gsvraag. Het laat zien dat behalvede wijzig<strong>in</strong>gen<strong>in</strong> de detail-tabel ook de master (de Klanten-) tabel opnieuw wordt<br />
gesaved. Dat klopt, want ook <strong>in</strong> deze tabel wordt de relatie vastgelegd, sla dus Yes aan.<br />
Nog één opmerk<strong>in</strong>g:<br />
Alhoewelhet prima mogelijk is om relaties <strong>in</strong> de design mode te leggen zoals hier<strong>voor</strong>beschreven, raad ik aan om <strong>voor</strong> relaties<br />
leggen de diagram-mode te gebruiken, zie later bij de paragraaf ''Hoe maak je een Diagram".<br />
Hoe kun je bij het wissenvan een master-record ook de detailsautomatischlaten wissen(cascade)
Onderaande tab Relationships<strong>in</strong> het scherm Properties (zie de eerdere figuur: Design Table met Properties - Relationships) kun<br />
je "Cascade Delete Related Records" aanv<strong>in</strong>ken. Dan worden als <strong>in</strong> de master-tabel een record (een klant) wordt gewist<br />
automatischalle details (alle orders) meegewist. Omdat zonderdit v<strong>in</strong>kje er details overblijvenzondermaster (orders die vangeen<br />
enkele klantzijn), zulje dit vrijwelaltijd aanv<strong>in</strong>ken.<br />
Evenzozulje vrijwelaltijd een v<strong>in</strong>kjemoeten zettenbij "Cascade Update Related Fields". Bij een auto<strong>in</strong>crement-veld als primary<br />
key heeft het eigenlijk geen nut(auto<strong>in</strong>crement-veldenkun je niet wijzigen), maar kwaad kan het niet. En anders krijg je rare effecten<br />
(orders van een andere klantof zonderklant).<br />
Hoe maak je een diagram(velden en relaties tonen)<br />
Via een rechtsklik op Diagrams kun je met de keuze New Database Diagram een diagram <strong>voor</strong> je database maken.<br />
Dan krijg je een wizard waar<strong>in</strong> je de tabellen<strong>voor</strong> het diagram kuntopgeven (dat hoeftniet precies <strong>in</strong> een keer goed, want je kunt<br />
later altijd nog toevoegen met een rechtsklik en "Add New Table"). Je kuntoverigens door de Ctrl-toets <strong>in</strong>gedruktte houden<br />
meerdere tabellentegelijk selecterenen opgeven.<br />
Na een druk op de knop Add, de knop Volgende en de knop Voltooien, is je diagram <strong>in</strong> eerste opzet, aangemaakt. Je krijgt dan de<br />
tabellenmet hunrelaties (zie figuuronder l<strong>in</strong>ks), die je met wat slepen kuntverduidelijken(zie figuuronder rechts, waar de master<br />
boven en de detail beneden is gezet). Ook de lijn van de relatie kunje goed <strong>voor</strong> (of achter) de veldenpositioneren om de relatie<br />
nog meer <strong>in</strong>zichtelijkte maken, daar<strong>voor</strong> sleep je met die lijn naar boven/onder of l<strong>in</strong>ks/rechts.<br />
Tot slot, als je het diagram afsluitmoet je nog een naam er<strong>voor</strong> opgeven. Later, wanneerje een hele grote database <strong>in</strong> gebruik<br />
hebt, kan het de moeite lonenom niet de gehele database <strong>in</strong> één diagram te zetten, maar delen ervan, die je dan ook elk een<br />
aparte naam kuntgeven (bijv. DiagramKlanten, DiagramProducten, DiagramPersoneel).
In<strong>voor</strong>gaande figuuris er sprake van een al een eerder aangemaakte relatie, die wordt dan automatischgetoond.<br />
Als er nog geen relatie is, en je wilt er een aanmaken, dan kan dat het gemakkelijkst <strong>in</strong> een diagram.<br />
Na een klik op het driehoekje <strong>voor</strong> het koppelveld (KlantID) vande detail-tabel (Orders) kunje vandaarslepen (de muistoets<br />
<strong>in</strong>gedrukthouden) naar de master-tabel en daar de muis loslaten. Er verschijntdan een relatie-lijn tussende twee tabellen(nog<br />
zondersleuteltjeen one<strong>in</strong>dig-teken) en een scherm waar de relatie al correct is <strong>in</strong>gevuld, waarna je nog alleenOK hoeftaan te<br />
klikken (na desgewenst Cascade eerst aangev<strong>in</strong>ktte hebben). Dat is alles. Deze methode is, gezien de eenvoud, veruitte<br />
prefererenboven de eerder genoemde methode via het "Design Table" scherm. Als je het diagram sluit krijg je nog een<br />
bevestig<strong>in</strong>gsvraag<strong>voor</strong> het Saven van de Klanten- en Orders-tabel (zie een eerdere figuur<strong>voor</strong> deze save-bevestig<strong>in</strong>g). Dat klopt,<br />
want een diagram is niet alleeneen scherm waar<strong>in</strong> het een en ander getoond wordt, je kunter relaties (en zelfsook tabellen) <strong>in</strong><br />
wijzigen (of zelfstoevoegen). Overigenskunje <strong>voor</strong> het ontwerp vande relatie ook <strong>in</strong> de primaire key van de master-tabel beg<strong>in</strong>nen<br />
en naar de detail-tabel slepen, maar de eerste methode is iets zekerder met name als je verschillendenamenhanteert<strong>voor</strong> het<br />
koppelveld <strong>in</strong> de twee tabellen.<br />
Hoe maak je sql commando's (select, jo<strong>in</strong>s, etc.) <strong>in</strong> Enterprise Manager<br />
Voor het testen vansql, die je later <strong>in</strong> je Delphi programma wilt gebruiken, is de EM, maar ook de QA (QueryAnalyser) de<br />
aangewezenweg. Eerst de aanpak via de EM: De aanpak via de EM kent ook weer twee mogelijkheden:<br />
Via het <strong>SQL</strong> venster (pane)<br />
Zoals eerder uitgelegd: Rechtsklikop een tabel, kies "Open Table" en dan "ReturnAll Rows". Dan verschijnener behalvede <strong>in</strong>houd<br />
vande tabel ook een aantal knoppen, bovenaan<strong>in</strong> de EM. Zoek daar de knop <strong>SQL</strong> met de h<strong>in</strong>t"Show/Hide <strong>SQL</strong> Pane", druk erop,<br />
en er verschijnteen extra vensterboven de gegevens met daar<strong>in</strong> (zie de figuur):<br />
SELECT *<br />
FROM
Daar kunje de <strong>SQL</strong> aanpassen (bijv. een WHERE Prijs > 12 toevoegen) en dan de <strong>SQL</strong> uitvoerenmet de knop het uitroepteken<br />
(bovenaan<strong>in</strong> de EM). Of, eerst de syntaxtesten met de knop met "een v<strong>in</strong>kjemet <strong>SQL</strong> er<strong>in</strong>", en daarna pas de <strong>SQL</strong> uitvoeren.<br />
Nog wat opmerk<strong>in</strong>gen:<br />
<strong>SQL</strong> hoeft niet over de tabel te gaan die je eerst gekozen hebt, het mag best over een andere tabel gaan of meerdere<br />
tabellen(een JOIN).<br />
Je kuntnog een tweede keer een tabel openen en daar<strong>in</strong> een <strong>SQL</strong>-venstergebruiken. En een derde keer, etc. Inhet menu<br />
krijg je bij Venster een lijstje met alle geopende tabellenzodat je wat kuntexperimenterenmet meerdere <strong>SQL</strong>-commando's<br />
naast elkaar.<br />
Je kuntbehoorlijk <strong>in</strong>gewikkelde <strong>SQL</strong> maken <strong>in</strong> de EM, met GROUP BY, ORDER BY, UNION's, etc. Maar er is een grens aan<br />
wat de EM aankan, als het echt super <strong>in</strong>gewikkeld wordt (1 kantje A4 aan <strong>SQL</strong>) dan trekt de EM het niet meer, en moet je de<br />
QA gebruiken.<br />
Je kunt, als je tevredenbent met de <strong>SQL</strong> deze naar je Delphi programma kopiÙren. Bij<strong>voor</strong>beeld met een rechtermuistoetsklik<br />
op de <strong>SQL</strong>, dan Select All (alles selecteren), daarna Copy (kopiÙren) naar het klembord en vervolgens<strong>in</strong> Delphi met<br />
Paste(plakken). Ook de sneltoetsen(Ctrl+A, Ctrl+C, Ctrl+V) kun je gebruiken<br />
De uitkomstenvande <strong>SQL</strong> komen eronder <strong>in</strong> het Grid te staan. Daar kun je doorheen bladeren (met Ctrl + End ga je naar het<br />
laatste record)<br />
Je kuntdie uitkomstkopiÙren naar Word of Excel. Klik, terwijl je de Shift-toets <strong>in</strong>gedrukthoudtop de kolomkoppen boven de<br />
uitkomsten zie dat de kolommengeselecteerd worden. Gebruik Ctrl+C en ga naar een geopend Word-documentof Excelbestand<br />
en gebruik Ctrl+V om de uitkomst <strong>in</strong> Word of Excel te zetten. InWord moet je meestal nog wel de hele uitkomst<br />
selecterenen bovenaanwat tabs plaatsen om de boel netjes onder elkaar te krijgen. InExcel hoeftdat niet, en het is een<br />
wonder hoe daar de uitkomsteni.h.a. op correcte wijze uitgelijndworden.<br />
Via de Query mogelijkheid<br />
Rechtsklikop een tabel, kies "Open Table" en "Query" om een <strong>SQL</strong> generator te krijgen (zie figuur):
Je krijgt dan vier subvensters, vanboven naar beneden: Table, Column, Sql en Output. Je kunt<strong>in</strong> de tabel kolommenaanv<strong>in</strong>ken, die<br />
dan <strong>in</strong> de lijst kolomnamendaaronder en <strong>in</strong> de SELECT vande <strong>SQL</strong> daar weer onder komen. Inhet Grid kunje een Alias (een<br />
andere veldnaamwaaronder het <strong>in</strong> de outputverschijnt), Criteria (<strong>voor</strong> het WHERE deel vande <strong>SQL</strong>), etc. opgeven.<br />
Je kuntmet een rechtsklik <strong>in</strong> het lege deel boven, en daar<strong>in</strong> de keuze Add Table, een tabel toevoegen. Ook kun je met een<br />
rechtsklik op een tabelkop (bijv. Test) en de keuzeRemove een tabel verwijderen(Delete aanslaanwerkt overigens ook). Als je een<br />
tweede tabel toevoegt die een relatie heeft met de eerste tabel zal automatischeen INNERJOINop de goede veldenverschijnen,<br />
etc., zie de figuur.<br />
De <strong>SQL</strong> <strong>in</strong> deze figuuris geheel automatischaangemaakt, er zijnalleentwee v<strong>in</strong>kjesgezet (bij Klant en Email), er is een Alias<br />
getypt (Naam) en een Sort gekozen uit een afrollijst, een criterium getypt (LIKE 'S%') en een tabel toegevoegd (Orders). Maar ook<br />
als je de <strong>SQL</strong> zelf<strong>in</strong>typtof wijzigt worden de vensterserbovenautomatischaangepast.<br />
Ook het opgeven vaneen GROUP BY (voegt alle relevanteveldentoe en zet WHEREom <strong>in</strong> HAVING), het veranderenvan de soort<br />
JOIN(van INNER<strong>in</strong> LEFT OUTER, etc.), het opgeven vaneen Tabel Alias (KlantenK), en nog vele andere zaken worden je<br />
gemakkelijk gemaakt. Maar daar ga ik nu niet op <strong>in</strong> omdat <strong>in</strong>houdelijkmet <strong>SQL</strong> werken niet de bedoel<strong>in</strong>g is van dit artikel.<br />
Parameters
Inje Delphi programma wil je misschien gebruik maken vanparameters <strong>in</strong> een <strong>SQL</strong> opdracht, bijv.<br />
SELECT Test FROM Testen WHERE Prijs < :Prijs<br />
InDelphi is het gebruikelijk om een parameter te laten beg<strong>in</strong>nenmet een dubbelpunt(vanafDelphi 8 wordt een vraagteken<br />
gebruikt). Het is mogelijk om deze en dergelijke parameters te gebruiken <strong>in</strong> EM. Open een tabel (via "ReturnAll Rows" of "Query",<br />
beide kan) en druk bovenaanop de Properties knop (handjemet wijzendev<strong>in</strong>ger), waarna je een scherm krijgt waar je het tabblad<br />
Parameters kiest.<br />
Bij Prefix vulje de dubbelpunt<strong>in</strong> (vanafDelphi 8 een vraagteken) en als je dan de <strong>SQL</strong> uitvoert(op uitroeptekenknopdrukt) dan<br />
moet je een parameter <strong>in</strong>vullenwaarna de <strong>SQL</strong> wordt uitgevoerd <strong>voor</strong> de waarde vandie parameter, zie figuur:<br />
Ook meerdere parameters zijnmogelijk, mits ze een verschillendenaam hebben (<strong>in</strong> Delphi 8 dus ?1 en ?2). Je geeft de parameter<br />
op volgensde W<strong>in</strong>dows-<strong>in</strong>stell<strong>in</strong>gvanje computer(<strong>in</strong> Nederlanddus meestal met een komma als decimaalscheider), dit <strong>in</strong><br />
tegenstell<strong>in</strong>gtot wanneerje de waarde rechtstreeks<strong>in</strong> de <strong>SQL</strong> zet (dan moet je als decimaalscheider een puntgebruiken).<br />
Nog even een tip:<br />
Als je een <strong>in</strong>gewikkelde <strong>SQL</strong> samengesteldhebt zorg er dan <strong>voor</strong> dat je die even kopieert (bijv. naar het klembord) <strong>voor</strong>dat je de<br />
parameter-prefix opgeeft. Wantbij het opgeven van de prefix wordt de <strong>SQL</strong> gewist.<br />
Enterprise Manager (EM) of Query Analyser (QA) gebruiken?<br />
Een nadeel van de EM is dat die de layouthelemaal<strong>voor</strong> je regelt door (veel) spaties en CR/LF's (nieuwe regels) <strong>voor</strong> je <strong>in</strong> te<br />
voegen, hetgeen die zijnzachtsgezegd, ietwat onhandiggebeurt. Als je de <strong>SQL</strong> naar je Delphi programma wilt kopiÙren, ben je<br />
veel tijd kwijt met verbeterenvan de layout(<strong>voor</strong>al spaties verwijderen). Een tweede nadeel van de EM is, dat als er iets foutgaat,<br />
er we<strong>in</strong>ig ondersteun<strong>in</strong>gis. Daarom kunje beter de QA (QueryAnalyser) gebruiken als de <strong>SQL</strong> wat <strong>in</strong>gewikkelder wordt. Het<br />
nadeel van de QA is dat je niet zoals <strong>in</strong> de EM gemakkelijk parameters kuntopgeven. En dat het kopiÙren-plakken vande uitkomst<br />
naar Word en Excel niet mogelijk is.<br />
Hoe maak je sql commando's (select, jo<strong>in</strong>s, etc.) <strong>in</strong> de Query Analyser<br />
Allereerstde vraag: hoe start je de QA? Dat gaat het eenvoudigstals je eerst de EM opstart, daar de database kiest (bv Kanweg)<br />
en dan bij Tools <strong>in</strong> de afrollijstde QueryAnalyserkiest.
Na opstarten vande QueryAnalyserkrijg je het volgendete zien:<br />
Overigens, mochtje <strong>in</strong> het menuvande EM niet Tools zien staan, dan heb je een tabel geopend o.i.d.; klik dan ergens naast de<br />
geopende tabel en je ziet de keuze Tools <strong>in</strong> het menuverschijnen.<br />
De QA is <strong>in</strong> eerste <strong>in</strong>stantie alleeneen leeg scherm met een knipperende cursor. Omdat het handig is als je ook de tabellenmet<br />
hunopbouw kuntzien, kun je het best de Object Browser aanzetten, via het menu(Tools | ObjectBrowser | Show) of de sneltoets<br />
(met het plaatje van een doos waaruit een bol, kegel en kubusspr<strong>in</strong>gen) gebruiken. Dan krijg je l<strong>in</strong>ks je databases te staan, die je<br />
kuntuitklappentotdat je de veldenmet hunproperties kuntzien, zie figuur:<br />
Wanneerje <strong>SQL</strong> <strong>in</strong> dit scherm typt zie je dat gereserveerde woorden <strong>in</strong> blauwof paars worden weergegeven (str<strong>in</strong>gs <strong>in</strong> het rood,<br />
handig <strong>voor</strong> het matchenvande apostrofs-paren).<br />
Je kuntmet de groene run-knop de <strong>SQL</strong> laten uitvoeren(of eerst controlerenmet de blauwe v<strong>in</strong>kje-knop). Als er een fout<strong>in</strong> zit krijg<br />
je een nette foutmeld<strong>in</strong>g<strong>in</strong> een apart Messages-scherm onderaan (zie de figuur), waarbij als je dubbelkliktop de foutmeld<strong>in</strong>gde<br />
cursor op de fout-regel gaat staan.
Als er geen fout<strong>in</strong>zit, krijg je de uitkomstte zien <strong>in</strong> het onder-scherm <strong>in</strong> een Grid waarvande kolommenniet zoals bij de EM een<br />
vaste breedte hebben, maar zich aanpassen aan de breedte vande kolomkop of breedste uitkomst<strong>in</strong> de kolom (zie de figuur). Je<br />
kuntoverigens ook de uitkomst als tekst latenzien, of wegschrijvennaar een bestand, maar dat zou ik niet doen omdat alles<br />
uitgelijndwordt mbv spaties en het Courier lettertype.<br />
Hoe zorg je <strong>voor</strong> een snellewerk<strong>in</strong>g (optimalisatie)<br />
Optimalisatie is een belangrijk onderwerp, waarover meer bladzijdenzijnte schrijvendan er nual <strong>in</strong> deze handleid<strong>in</strong>gstaan.<br />
Daarom geef ik hier alleenwat basis-tips, waarmee je een langdurende<strong>SQL</strong>-opdracht kuntonderzoekenwaarom, en op waar, je<br />
<strong>SQL</strong> langzaamis.<br />
Inhet algemeen kun je zeggen dat het toevoegenvan <strong>in</strong>dexenbij grote tabellende <strong>SQL</strong> snellerkan maken. Je kuntalleenniet<br />
expliciet opgeven hoe <strong>SQL</strong> <strong>Server</strong> die <strong>in</strong>dexenmoet gebruiken, dat doet <strong>SQL</strong> <strong>Server</strong> zelf(dit is overigens niet helemaalwaar, je<br />
kuntz.g. H<strong>in</strong>ts opgeven, maar je moet dan wel precies weten wat je doet omdat je anders de werk<strong>in</strong>g juist vertraagd). Wat wel<br />
belangrijk is om te weten is of <strong>SQL</strong> <strong>Server</strong> de <strong>in</strong>dexenook gebruikt, en hoe.<br />
Om te onderzoekenhoe de <strong>SQL</strong>-opdracht wordt uitgevoerd, kun je <strong>in</strong> de QA de wijze vanuitvoer<strong>in</strong>gtonen, mbv de knop met een<br />
Grid plaatje erop en de keuze "Show Executionplan", zie de figuur.<br />
Er verschijntdan onderaan, naast de tab "Grids" en "Messages", een derde tab "ExecutionPlan" waar<strong>in</strong> je (als je opdracht foutloos<br />
is uitgevoerd) de uitvoer<strong>in</strong>gkuntbekijken. Inde figuurhieronderheb ik een <strong>SQL</strong>-opdracht uit de Northw<strong>in</strong>d<strong>voor</strong>beeld-database<br />
(daar zittentenm<strong>in</strong>stewat gegevens <strong>in</strong>) laten uitvoerenmet zo'n ExecutionPlan.
Je leest een ExecutionPlan van rechts naar l<strong>in</strong>ks en vanboven naar onder.<br />
Inhet ExecutionPlan zie je horizontalepijlen waarvande dikte maat staat <strong>voor</strong> het aantal records. Indit <strong>voor</strong>beeld 25 resp. 830,<br />
hetgeenje kuntzien (als H<strong>in</strong>t) als je de muis boven de pijl houdt. Tussende pijlen staan de bewerk<strong>in</strong>gen en hunrelatieve aandeel <strong>in</strong><br />
de tijd (als Cost met een percentage). Meer uitleg over de bewerk<strong>in</strong>gen is ook hier te krijgen door de muis erboven te houden, zie<br />
de figuur.<br />
Bij het analyserenvan de tijdsduurgaat de aandachtnatuurlijkuit naar de delen met de hoogste percentages. Bijna altijd is de<br />
eerste bewerk<strong>in</strong>g het lezenvanuiteen tabel, een scan. Dat kan zijneen (gewone) Scan, een IndexScan of een Clustered Index<br />
Scan. Een Scan gebruikt geen <strong>in</strong>dex. Dat hoeft niet altijd verkeerd te zijn, bij<strong>voor</strong>beeld wanneerhet een kle<strong>in</strong>e tabel is, of wanneer<br />
alle records worden opgehaald, heefteen <strong>in</strong>dex geen nut. Inbovenstaand<strong>voor</strong>beeld wordt een "clustered<strong>in</strong>dex scan" gebruikt,<br />
hetgeenbij een grote tabel iha het snelstis. Voor een JOINis de Nested Loop <strong>in</strong> het algemeen het snelst(gebruikt twee <strong>in</strong>dexen).<br />
Wanneerje <strong>voor</strong> de JOINeen zgn"Hash Jo<strong>in</strong>" ziet staan dan valter meestal snelheid te w<strong>in</strong>nen. Wantdeze bewerk<strong>in</strong>g wordt door<br />
<strong>SQL</strong> <strong>Server</strong> gekozen als laatste redmiddel. Een Sort maakt waar mogelijk gebruik van een <strong>in</strong>dex. Bij een grote tabel kan het veel (I/<br />
O) tijd vragen(dan kan zelfsde tempdb database <strong>in</strong>gezetworden), dus moet je dit niet onnodig laten doen. Kwestie van de ORDER<br />
BY met mate (en zo laat mogelijk) gebruiken en een goede <strong>in</strong>dex opgeven (denk ook aan de keuze ASC (A>Z) versusDESC<br />
(Z>A)).<br />
Om nog even op de dikte vande pijlen terug te komen, dikke pijlen vragenveel I/O tijd. Blijvende pijlen dik na de bewerk<strong>in</strong>g,<br />
overweeg dan je <strong>SQL</strong> anders op te zetten. Vooral als er vande grote aantallenrecords er aan het e<strong>in</strong>d maar we<strong>in</strong>ig overblijven(de<br />
WHERE goed aansturen).<br />
Hoe meet je hoe lang een (zoek)opdracht duurt<br />
Inde QueryAnalyser(QA) kunje op twee manierenmeten hoe lang een zoekopdrachtduurt. Beide zijnniet exact omdat het<br />
bestur<strong>in</strong>gssysteemW<strong>in</strong>dows de tijd niet exclusiefaan <strong>SQL</strong> <strong>Server</strong> toedeelt, omdat er altijd meerdere processen tegelijk lopen.<br />
Denk maar aan je Outlookdie een piepje geeft op de tijd vanje afspraak, of je Virusscannerdie permanentbezig is, etc.<br />
De eerste methode is dat je <strong>in</strong> QA de tijd vastlegtbij het beg<strong>in</strong> van een (SELECT) opdracht, de opdracht uitvoert, de tijd weer<br />
vastlegt, en de twee tijden van elkaar aftrekt om tot een tijdverschilte komen<br />
De tweede methode is het gebruik vanSTATISTICSvan de QA.<br />
Bij beide methodenmoet je niet de eerste keer dat je de <strong>SQL</strong> uitvoertde tijd meten. De eerste keer is nog <strong>in</strong>clusiefhet aanmaken<br />
vaneen ExecutionPlan. Dat ExecutionPlan komt <strong>in</strong> de Cache en daardoor zal de tweede keer (en daarna) de tijd korter uitvallen,<br />
en deze laatste tijd is maatgevend.<br />
Tijdverschil<br />
Hieronder een <strong>voor</strong>beeld vanhet meten van de tijd volgensde eerste methode (tijdstip vastleggen): Inde QA worden twee<br />
variabelen(die beg<strong>in</strong>nenmet een enkele @) gedeclareerd. Die worden <strong>voor</strong>afgaanden na afloop van de <strong>SQL</strong>-opdracht <strong>in</strong>gevuld<br />
waarna de verschiltijdwordt gepresenteerd:
Er zijntwee Grids met uitkomsten, bovenaanvan de <strong>SQL</strong> en onderaan vande tijd.<br />
De betrouwbaarheid vande uitkomst is 3 msec en vergeet niet de <strong>SQL</strong> een aantal keren uit te voeren, <strong>voor</strong> de uitkomstals<br />
def<strong>in</strong>itief aan te nemen.<br />
Statistics gebruiken<br />
<strong>SQL</strong> <strong>Server</strong> houdtpermanentdiverse statistieken bij. Die <strong>voor</strong> de verstrekentijd kun je eenvoudiguitlezen<strong>in</strong> de QA als je SET<br />
STATISTICSTIMEON opgeeft (zie de figuurhierna <strong>voor</strong> hoe je dat doet) <strong>voor</strong>dat je de <strong>SQL</strong> uitvoert. Je hoeftdat overigens maar<br />
eenmalig te doen, het blijft aan tot je SET STATISTICSTIMEOFF opgeeft (of tot <strong>SQL</strong> <strong>Server</strong> stopt).<br />
De tijd staat nubij de Messages, waarbij het nog even de kunstis om uit te v<strong>in</strong>denwelke Executiontime je moet hebben. Vooral als<br />
je ook nog het Executionplan presenteert(die vraagt ook executiontime) staan er verschillendetijden onder elkaar. De oploss<strong>in</strong>g<br />
is eenvoudig, je moet de regel hebben onder de regel met<br />
(... row(s) affected).<br />
Indit <strong>voor</strong>beeld dus 30 msec. Deze elapsed time is de CPU plus de I/O tijd, wil je de CPU tijd alleenweten dan kun je die er<strong>voor</strong><br />
uitlezen.<br />
Hoe maak je een backup en hoe zet je die terug
Als je met de Verkennergaat kijken naar de mappen (directories) die <strong>SQL</strong> <strong>Server</strong> gebruikt dan zie je dat er een map C:\Program<br />
Files\<strong>Microsoft</strong> <strong>SQL</strong> <strong>Server</strong>\MS<strong>SQL</strong>\Data bestaat <strong>voor</strong> de gegevens en een map C:\Program Files\<strong>Microsoft</strong> <strong>SQL</strong><br />
<strong>Server</strong>\MS<strong>SQL</strong>\Backup <strong>voor</strong> de backup van de gegevens. Dit zijnoverigens de defaultmappen, niets let je om hier<strong>voor</strong>andere<br />
mappen te gebruiken.<br />
Neem aan dat je de defaultmappen en namen<strong>voor</strong> de database Kanweg gebruikt hebt, dan zie je <strong>in</strong> C:\Program Files\<strong>Microsoft</strong><br />
<strong>SQL</strong> <strong>Server</strong>\MS<strong>SQL</strong>\Data twee bestanden staan:<br />
Kanweg_Data.mdf <strong>voor</strong> de data, en<br />
Kanweg_Log.ldf <strong>voor</strong> de log-gegevens.<br />
De data zijnde gegevens zoals ze op dit momentzijnopgeslagen, <strong>in</strong> de log staan alle wijzig<strong>in</strong>gendie er zijngeweest (zo kun je tot<br />
op een bepaald punt<strong>in</strong> de tijd terug gaan om die situatie te herstellen). Als je een backup maakt krijg je één bestand waar<strong>in</strong> zowel<br />
de data als de log zitten. Een backup maken kan terwijl de database volop <strong>in</strong> gebruik is. <strong>SQL</strong> <strong>Server</strong> maakt een snapshoten zet<br />
deze <strong>in</strong> de backup. Terugzetten(restore) luktechter niet als de database <strong>in</strong> gebruik is. Een backup van <strong>SQL</strong> <strong>Server</strong> 7 kunje <strong>in</strong> <strong>SQL</strong><br />
<strong>Server</strong> 2000 (is versie 8) <strong>in</strong>lezenen wonderbaarlijkgenoeg kunje een backup van versie 2000 terugzetten<strong>in</strong> 7 (mits je niet de<br />
nieuwstesnufjesvan2000 gebruikt hebt). Omdat <strong>SQL</strong> server versies zo'n 5 jaar meegaan heb je niet gauw compatibiliteitsproblemen.<br />
Bij het maken vaneen backup onderscheid ik twee varianten(er zijner nog veel meer mogelijk):<br />
Een backup maken vande productie database. Dan zulje bijv. dagelijks een complete backup maken en eventueelelk uur<br />
een differentiÙlebackup (alleende verschillenmet de vorige backup). Meestal laat je dit automatischdoen door de Service<br />
Manager (zie de eerste figuur<strong>voor</strong> hoe die te bereiken)<br />
een backup maken <strong>voor</strong> testen (bijv. <strong>voor</strong>dat je de design vande database gaat veranderen)<br />
Voor een Delphi programmeuris de laatste varianthet meest <strong>in</strong>teressant.<br />
Backup <strong>voor</strong> testen<br />
Het maken vaneen Backup gaat het handigst vanuitde EM. Rechtsklikop de database (Kanweg) en kies "Alle taken" en dan<br />
"Backup Database".<br />
Dan krijg je een <strong>in</strong>vulschermom je keuzes<strong>voor</strong> de Backup op te geven.
Controleerof daar is aangev<strong>in</strong>kt"Database Complete" (Database differentialis <strong>voor</strong> elk uurvan de productie database, o.i.d.) en<br />
kies bij Overwrite"Overwrite Exist<strong>in</strong>g media" want de defaultkeuze "Append to media" is <strong>voor</strong>al bedoeld <strong>voor</strong> de differential<br />
database op tape wegschrijven(de backup van elk uurachter de dag-backup). Klik daarna op de Add-knop om op te geven waar<br />
de backup moet komen.<br />
Inhet dan verschenenscherm "Select Backup Dest<strong>in</strong>ation" druk je de puntjesknopachter File name <strong>in</strong>, zoek je (als je tenm<strong>in</strong>stede<br />
Defaultmap wilt gebruiken) de Backup directory op vanMS <strong>SQL</strong> <strong>Server</strong>, en vulje bij "File name" <strong>in</strong>: Kanweg.bak. Ook hier kunje<br />
een andere naam en extensie opgeven, maar het is wel zo handig om de naam van de database te gebruiken, met de bij MS <strong>SQL</strong><br />
<strong>Server</strong> gebruikelijke .bak erachter, zie de figuur.<br />
Na een druk op de OK-knop, komt de directory+map bij File name te staan, en na nogmaals OK sta je weer <strong>in</strong> het hoofd-backupscherm,<br />
nu met een bestemm<strong>in</strong>g <strong>in</strong> het hokje "Backup to". Daar zorgt een druk op de volgendeOK-knop er<strong>voor</strong> dat de backup<br />
wordt gemaakt. Het is een wonder hoe snel je dan de boodschap "Backup successfully" krijgt. Mocht je <strong>in</strong> de Backup-directory het<br />
bestand Kanweg.bak bekijken dan merk je dat dit aanzienlijkkle<strong>in</strong>er is dan de oorspronkelijke mdf en log bestanden, en als je het<br />
Kanweg.bak bestand wilt versturen, dan blijkt het mbv zip nog weer een factor 2 Ó 3 kle<strong>in</strong>er te kunnen.<br />
Restore (terugzetten eerdere backup)<br />
Via een rechtsklik op de database (Kanweg) de keuze "Alle taken" en dan "Restore Database" kunje de Backup weer terugzetten.<br />
Je krijgt dan een scherm waar<strong>in</strong> je evenmoet controlerenof de gegevens kloppen en er een v<strong>in</strong>kjestaat bij Restore, en als je op<br />
OK drukt wordt de backup teruggezet. Dit gebeurt overigens zonderverdere bevestig<strong>in</strong>gsvraag, dus wees <strong>voor</strong>zichtigmet dit<br />
scherm.
Restore (backup van een ander)<br />
Mocht je van iemand anders een backup gekregen hebben, dan zulje moeten opgeven waar dat bestand staat. Stel je hebt dat<br />
bestand <strong>in</strong> de eerder genoemde Backup directory gezet. Dan kies je het rondje <strong>voor</strong> "From device" waarna je bij Parameters een<br />
compleet ander uiterlijkkrijgt, zie de figuur.<br />
Je drukt daar de knop Select devices <strong>in</strong>, en <strong>in</strong> het volgendescherm de Add-knop, waarna je het bestand opzoekt, net als bij het<br />
maken van de Backup. Daarna verschijntde naam <strong>in</strong> het Devices-hokje. Ook wordt de View Contentsknop enabled (je kunt<br />
daarmee nog even de <strong>in</strong>houdcontroleren). Voordat je nu op de OK-knop drukt moet je nog één d<strong>in</strong>g doen: Bij de Options-knop het<br />
item "Force Restore over excist<strong>in</strong>g database" aanv<strong>in</strong>ken. Deze beveilig<strong>in</strong>g wordt snel vergetenuit te zettenen dan weigert <strong>SQL</strong><br />
<strong>Server</strong> de Restore.<br />
Een Backup wordt ook vaak gebruikt om iemand (<strong>voor</strong> het eerst) een database te geven. Als je een Backup vaneen nieuwe<br />
database krijgt kun je (op de manier zoals aan het beg<strong>in</strong> van dit artikel vermeld) een lege database aanmakenmet de naam vande<br />
nieuwe database. En daarna verder te werk gaan zoals hier<strong>voor</strong>is uitgelegd. Er zijnook andere manierenmogelijk, maar deze<br />
methode werkt <strong>in</strong> ieder geval.<br />
Hoe werkt de Help van <strong>SQL</strong> <strong>Server</strong>
Overal<strong>in</strong> de EM of QA kunje op de F1-toets drukkenom Help te krijgen, waarbij <strong>SQL</strong> <strong>Server</strong> BOL (Books Onl<strong>in</strong>e) opent en zijn<br />
best doet om daaruit de relevantegegevens te tonen. Mocht je iets anders willenweten dan kunje <strong>in</strong> BOL de tab Indexaanklikken<br />
en een woord <strong>in</strong>typenwaar<strong>voor</strong> je hulpwilt. Of de tab Zoeken gebruiken waarmee alle items waar<strong>in</strong> dat woord <strong>voor</strong>komt<strong>in</strong> een lijst<br />
komen.<br />
De moeilijkheid zit meestal niet <strong>in</strong> de uitleg maar om temidden van zoveel<strong>in</strong>formatie de goede uitleg te v<strong>in</strong>den. Vooral ook omdat<br />
de help vande hulp-programma's er tussenstaat. Eventueelkunje bovenaan<strong>in</strong> plaats van (de gehele collectie) kiezen <strong>voor</strong> wat<br />
<strong>voor</strong> je zoekonderwerprelevantis. Als programmeurheb je meestal het meest aan het item "<strong>SQL</strong> programmer: Transac-<strong>SQL</strong>" ,<br />
<strong>voor</strong> uitleg over de <strong>SQL</strong> items.<br />
De beschrijv<strong>in</strong>g<strong>in</strong> BOL heeftvaak een standaard opbouw. Zie onderstaandefiguurwaar<strong>in</strong> vaneen <strong>SQL</strong> item (DATEDIFF) de<br />
syntax, de argumenten(met per argumenteen toelicht<strong>in</strong>g), het resultaaten een aantal opmerk<strong>in</strong>gen staan. En, vervolgens, na de<br />
uitleg zijner altijd één of meer <strong>voor</strong>beeldenaanwezig, waar<strong>in</strong> vaak de essenties pas duidelijk worden.<br />
Toegift<br />
Nog een leuk weetje uit <strong>SQL</strong> <strong>Server</strong>: Als je <strong>in</strong> de EM een tabel uit een database aanklikt, vervolgensdeze kopieert (bijv. met<br />
Ctrl+C), en dan <strong>in</strong> een tekstverwerkerdeze weer plakt (Ctrl+V) dan krijg je de complete CREATE code van die tabel te zien.<br />
Bij<strong>voor</strong>beeld de Klantenen de Orders tabel van hier<strong>voor</strong>:<br />
CREATE TABLE [Klanten] (<br />
[KlantID] [<strong>in</strong>t] IDENTITY (1, 1) NOT NULL ,<br />
[Klant] [varchar] (20) COLLATE Lat<strong>in</strong>1_General_CI_AS NOT NULL ,<br />
[Email] [varchar] (50) COLLATE Lat<strong>in</strong>1_General_CI_AS NOT NULL<br />
CONSTRAINT [DF_Klanten_Email] DEFAULT (''),<br />
CONSTRAINT [PK_Klanten] PRIMARY KEY CLUSTERED<br />
(<br />
[KlantID]<br />
) ON [PRIMARY]<br />
) ON [PRIMARY]<br />
CREATE TABLE [Orders] (<br />
[OrderID] [<strong>in</strong>t] IDENTITY (1, 1) NOT NULL ,<br />
[KlantID] [<strong>in</strong>t] NOT NULL ,<br />
[Product] [varchar] (20) COLLATE Lat<strong>in</strong>1_General_CI_AS NOT NULL ,<br />
[Prijs] [decimal](9, 2) NOT NULL CONSTRAINT [DF_Orders_Prijs] DEFAULT (0),<br />
CONSTRAINT [PK_Orders] PRIMARY KEY CLUSTERED<br />
(
[OrderID]<br />
) ON [PRIMARY] ,<br />
CONSTRAINT [FK_Orders_Klanten] FOREIGN KEY<br />
(<br />
[KlantID]<br />
) REFERENCES [Klanten] (<br />
[KlantID]<br />
) ON DELETE CASCADE ON UPDATE CASCADE<br />
) ON [PRIMARY]<br />
Kan handig zijn, bij<strong>voor</strong>beeld om een tabel <strong>in</strong> code aan te maken, of als documentatie. Overigens, als je wilt dat de karakterset niet<br />
wordt meegenomen, dan kunje het deel "COLLATE Lat<strong>in</strong>1_General_CI_AS" weglaten. Lat<strong>in</strong>1 staat <strong>voor</strong> ANSI, de standaard die <strong>in</strong><br />
Nederland(en West-Europa, Amerika) al op alle computers aanwezig is.<br />
Hoe gebruik je tabellen(connectie, query) vanuit je Delphi programma<br />
De aangewezenweg om <strong>SQL</strong> <strong>Server</strong> te gebruiken is via ADO. Op het gebruik van<strong>SQL</strong> <strong>Server</strong> vanuitDotNet (Delphi 8 en later) ga<br />
ik hier niet <strong>in</strong>; ik ga er vanuitdat je Delphi (professional), versie 6 of 7 hebt. Voordien had je de Enterprise versie (ook wel Client<br />
<strong>Server</strong> genaamd) vanDelphi nodig, die via de BDE (met het onderdeel <strong>SQL</strong> L<strong>in</strong>ks) verb<strong>in</strong>d<strong>in</strong>gmaakt met <strong>SQL</strong> <strong>Server</strong>. Maar deze<br />
methode wordt nu door Borland afgeraden omdat de BDE aan het e<strong>in</strong>d vanzijnlevensduuris.<br />
Behalvevia ADO bestaat er <strong>in</strong> Delphi ook nog de mogelijkheid om via DBExpress een verb<strong>in</strong>d<strong>in</strong>gnaar <strong>SQL</strong> <strong>Server</strong> te leggen,<br />
maar waarom zou je dat doen. Wantde ADO toegang wordt door <strong>Microsoft</strong> ontwikkeld en onderhoudenen werkt het gemakkelijkst<br />
<strong>in</strong> multi-user omgev<strong>in</strong>g (hieroverlater meer).<br />
Als <strong>voor</strong>beeld laat ik zien hoe je de tabel Employees van de database Northw<strong>in</strong>dkuntlaten zien. Zet op een Form uit de tab ADO<br />
een ADOConnectionen een ADODataSet (eigenlijk kunje ze beter op een DataModule zetten, maar gemakshalvekomen ze nuop<br />
het Form zelf). Zet uit de tab DataAccess een DataSource erbij en uit de tab DataControls een DBGrid, zie de figuur:<br />
Selecteer de ADOConnectionen zet <strong>in</strong> de Object InspectorLog<strong>in</strong>Prompt op False. Dan klik je op de Property ConnectionStr<strong>in</strong>g,<br />
vervolgensop de puntjesknoperachter en dan op de Build-knop.<br />
Inde dan verschenenWizard kies je "<strong>Microsoft</strong> OLE DB Provider for <strong>SQL</strong> <strong>Server</strong>" <strong>in</strong> de tab Voorzien<strong>in</strong>g (Provider). Inde tab<br />
Verb<strong>in</strong>d<strong>in</strong>g (Connection) kies je bij punt1 uit een afrollijstjede <strong>Server</strong>naam(daar staat vaak maar één naam, die vanje Computer).<br />
Heb je geen netwerk dan kunje de <strong>Server</strong>naamook leeg laten. Je kuntde naam ook opzoeken via het Bureablad | Mijn Computer |<br />
Eigenschappen | Computernaam. Of via een rechtsklik op het <strong>SQL</strong>-icoon <strong>in</strong> de tray en daar na "Open Sql <strong>Server</strong> Manager" achter<br />
<strong>Server</strong>. Bij punt2 kies je Ge´ntegreerde W<strong>in</strong>dows NT-beveilig<strong>in</strong>g (NT Security), ik ga er tenm<strong>in</strong>stevanuitdat je Computer op<br />
W<strong>in</strong>dows 2000 of XP of NT draait. Alternatiefis om via Gebruikersnaam+Wachtwoord<strong>voor</strong> <strong>SQL</strong> <strong>Server</strong> toegang te verkrijgen.<br />
(Deze heb je opgegeven bij de <strong>in</strong>stallatievan<strong>SQL</strong> <strong>Server</strong>, of je hebt de defaultsgeaccepteeerd: Gebruikersnaam= sa,<br />
Wachtwoord= ) Bij punt3 kies je uit het afrollijstjeNorthw<strong>in</strong>d.
Na een druk op de OK knop krijg je de aangemaakte verb<strong>in</strong>d<strong>in</strong>gs-str<strong>in</strong>g te zien (<strong>in</strong> plaats van MijnComputernaamstaat er natuurlijk<br />
je eigen gekozen naam):<br />
Provider=<strong>SQL</strong>OLEDB.1;Integrated Security=SSPI;Persist Security Info=False;<br />
Initial Catalog=Northw<strong>in</strong>d;Data Source=MijnComputernaam<br />
En na nog een OK is de ConnectionStr<strong>in</strong>g<strong>in</strong> de Object Inspector<strong>in</strong>gevuld, waarna je nog wel Connected op Truemoet zetten, om<br />
de verb<strong>in</strong>d<strong>in</strong>gte leggen (als je Connected op Truezet, krijg je nog de andere Default-<strong>in</strong>stell<strong>in</strong>genvan de verb<strong>in</strong>d<strong>in</strong>gte zien).<br />
Nu nog de gegevens uit de tabel tonen. Geef bij de ADODataSet de Connection(mbv de afrollijst) op als ADOConnection1. Er<br />
wordt overigens een ADODataSet gebruikt (een drie-<strong>in</strong>-één component, die de Table, Queryen Stored-Procedure vervangt) maar<br />
je kuntook een ADOQuerygebruiken. Dat raad ik echter af, omdat de ADOQueryer nog alleenvanwege compatibiliteit <strong>in</strong>zit, en <strong>in</strong><br />
de toekomst vervalt.<br />
Bij de property CommandStr<strong>in</strong>g, druk je de puntjesknop<strong>in</strong>, waarna je een QueryBuilderte zien krijgt. Daar typ je de <strong>SQL</strong>:<br />
SELECT * FROM Employees<br />
(je kuntook via de Add-knoppen de <strong>SQL</strong> opgeven, zie de figuur)<br />
Rest nog de gegevens te tonen:<br />
Koppel de Datasource bij de property DataSet aan de ADODataSet. Koppel het DBGrid via de property DataSource aan de<br />
DataSource en zet vande ADODataSet de property Active op True. De gegevens verschijnennu <strong>in</strong> het DBGrid.
Omdat dit verhaalgaat over <strong>SQL</strong> <strong>Server</strong>, houdtde Delphi uitleg hier (bij het tonenvan gegevens) op.<br />
Nog alleeneen korte opmerk<strong>in</strong>g:<br />
Voor het wijzigen/opslaan/verwijderenvangegevens gebruik je niet een ADODataSet, maar een ADOCommand. Of je koppelt de<br />
ADODataSet via een DataProvider aan een ClientDataSet, dan kan het wel via ApplyUpdates. Zie verder de literatuur.<br />
Hoe moet je <strong>SQL</strong> <strong>Server</strong> <strong>in</strong>stalleren<strong>voor</strong> multiusergebruik<br />
Hier<strong>voor</strong> is beschrevenhoe je <strong>voor</strong> het ontwikkelenvan een programma <strong>SQL</strong> <strong>Server</strong> via ADO kuntbereiken. ADO gebruikt het<br />
MDAC toegangsprogramma, dat op je ontwikkelmach<strong>in</strong>eaanwezig is. Maar ook op elke moderne computerwordt tegelijk met<br />
W<strong>in</strong>dows MDAC geïnstalleerd. En ook diverse andere programma's <strong>in</strong>stallerenMDAC, bij<strong>voor</strong>beeld InternetExplorer s<strong>in</strong>ds versie<br />
5.5. Als je dus aangeeft dat op de computerInternetExplorer versie 5.5 of hoger aanwezig moet zijn, dan is de toegangs-software<br />
<strong>voor</strong> <strong>SQL</strong> <strong>Server</strong> gegarandeerd aanwezig en hoefter geen ClientSoftwaregeïnstalleerdte worden. Je programma werkt dan vanaf<br />
elke computer<strong>in</strong> het netwerk.<br />
Hoe koop je, als je geen Delphi 8 hebt, <strong>voor</strong> ca €50 MS <strong>SQL</strong> <strong>Server</strong><br />
Bij Delphi 8 krijg je bij de professional versie en hoger <strong>SQL</strong> <strong>Server</strong> Developer meegeleverd. Dit is de versie die ook hier<strong>voor</strong>is<br />
besproken. Heb je Delphi 6 of 7 dan kunje <strong>voor</strong> een laag bedrag deze versie van<strong>SQL</strong> <strong>Server</strong> aanschaffen. Bij<strong>voor</strong>beeld verkoopt<br />
het Computer Collectief (www.comcol.nl) deze versie <strong>voor</strong> ca € 60,00. Ook Amazonlevertdeze versie, <strong>voor</strong> $43,00 + $5,00<br />
verzendkosten(omgerekend ca € 40,00), zie de figuur.<br />
Overigens, mochtje proberen deze versie te v<strong>in</strong>den, dan moet je wellichteen paar zoekopdrachtenproberen omdat deze<br />
aanbied<strong>in</strong>g vaak <strong>in</strong> eerste <strong>in</strong>stantie niet getoond wordt.<br />
Wat kun je niet met de MS <strong>SQL</strong> <strong>Server</strong> Developer versie?<br />
Met de Developer versie van <strong>SQL</strong> <strong>Server</strong> kunje prima database toepass<strong>in</strong>gen <strong>voor</strong> privé gebruik maken. Of <strong>voor</strong> een bedrijf een<br />
database toepass<strong>in</strong>g ontwikkelen. Het is <strong>in</strong> wezende Enterprise versie van <strong>SQL</strong> <strong>Server</strong> die vrijwelalles kan wat mogelijk is<br />
(Replicatie, multiprocessor-techniek, Dts, etc.). Het enige is dat je de Developper versie niet mag meeleverenmet je toepass<strong>in</strong>g.<br />
De klantmoet dan zelf<strong>SQL</strong> <strong>Server</strong> kopen. De prijs van<strong>SQL</strong> <strong>Server</strong> is behoorlijk hoog, maar je moet niet vergetendat er dan een<br />
versie wordt geleverd waarop zelfseen groot landelijkbedrijf kan functioneren. Voor kle<strong>in</strong>ere bedrijvenis er een goedkopere<br />
oploss<strong>in</strong>g, namelijkhet gebruik van MSDE (MicroSoft Desktop Environment) die gratis is (zie later <strong>voor</strong> meer uitleg). Of de<br />
aanschafvan Small Bus<strong>in</strong>ess <strong>Server</strong>.<br />
Small Bus<strong>in</strong>ess <strong>Server</strong> Premium Edition omvat: W<strong>in</strong>dows <strong>Server</strong> 2003 en Exchange<strong>Server</strong> 2003, plus <strong>SQL</strong> <strong>Server</strong> 2000 en ISA<br />
<strong>Server</strong> 2000 en kost $1500 (bij Amazon$1300) <strong>voor</strong> 5 users (tegen ger<strong>in</strong>ge meerprijs uit te breiden naar bijv. 10, 25 of 100 users).<br />
Een bedrijf kan daarmee jaren <strong>voor</strong>uit. En (bij een nieuwe versie) <strong>voor</strong> ca $600 een upgrade kopen, zodat de jaarlijkse software<br />
kosten (vanuitbedrijfsoogpunt) bijzonderlaag zijn.<br />
Welke versie van <strong>SQL</strong> <strong>Server</strong> er draait is bijzondergemakkelijk uit te lezenmet de <strong>SQL</strong> opdracht SELECT @@VERSION. Dat kan<br />
<strong>in</strong> de EM of QA, deze toont dan bij<strong>voor</strong>beeld: <strong>Microsoft</strong> <strong>SQL</strong> <strong>Server</strong> 7.00 (IntelX86) Oct 24 2000, Small Bus<strong>in</strong>ess <strong>Server</strong> on<br />
W<strong>in</strong>dowNT4, of <strong>Microsoft</strong> <strong>SQL</strong> <strong>Server</strong> 8.00 (IntelX86) Dec 17 2002, Developer on W<strong>in</strong>dowNT5.1, etc.
Wanneer kun je MSDE (gratis versie van MS <strong>SQL</strong> <strong>Server</strong>) gebruiken<br />
MSDE is de gratis versie van<strong>SQL</strong> <strong>Server</strong> en is volledig compatible daarmee, met een kle<strong>in</strong> aantal restricties. Eén ervanis dat een<br />
Database niet groter dan 2 GB (gigabyte) kan worden (per server heb je i.h.a. meerdere databases, die mogen met elkaar best<br />
meer dan 2 GB zijn). Het is onwaarschijnlijkdat dit, <strong>voor</strong> jou als beg<strong>in</strong>ner, een probleem oplevert. Een tweede beperk<strong>in</strong>g is dat er<br />
maar acht bewerk<strong>in</strong>gen gelijkertijd mogen plaatsv<strong>in</strong>den, en dat als er meer <strong>voor</strong>komen, de database steeds langzamerwordt. Let<br />
wel, acht bewerk<strong>in</strong>gen staat niet gelijk aan acht users, omdat users slechtseen kle<strong>in</strong> deel vande tijd daadwerkelijk een bewerk<strong>in</strong>g<br />
laten uitvoeren. Het hangtwat af vanhoe de database gebruikt wordt, maar vaak merk je tot 25 users geen beperk<strong>in</strong>gen bij het<br />
gebruik vanMSDE. En mochtje database te groot worden dan kun je zonderenige aanpass<strong>in</strong>g (de betaalde versie van) <strong>SQL</strong><br />
<strong>Server</strong> <strong>in</strong>stalleren. Zie verder ook www.microsoft.com/sql/msde, oa over wat bewerk<strong>in</strong>gen zijn.<br />
Wat vervelenderis, dat MSDE niet met de <strong>voor</strong>beeld databases Northw<strong>in</strong>den Pubs wordt uitgeleverd, maar <strong>voor</strong>al dat de tools<br />
EM(Enterprise Manager) en QA(QueryAnalyzer) ontbreken. Alhoewelslimme mensende 60 dagen trial versie van<strong>SQL</strong> <strong>Server</strong><br />
downloadenen daaruit de tools <strong>in</strong>stalleren, welke geen 60 dagen beperk<strong>in</strong>g hebben (deze kunnenapart geïnstalleerdworden,<br />
zonder<strong>SQL</strong> <strong>Server</strong> zelf).<br />
Voor de toekomst zijner nog <strong>in</strong>teressantereontwikkel<strong>in</strong>genaangekondigd door <strong>Microsoft</strong>, namelijkdat MSDE wordt opgevolgd<br />
door MS <strong>SQL</strong> <strong>Server</strong> Express Edition, een gratis versie van <strong>SQL</strong> <strong>Server</strong> <strong>in</strong>clusieftools (een EM met ge´ntegreerde QA). Nu met tot<br />
4 GB databases, DotNet ondersteun<strong>in</strong>g, tot 50 opdrachtentegelijkertijd, etc. Het is weliswaar een <strong>voor</strong>lopige aankondig<strong>in</strong>g, maar<br />
het ziet er naar uit dat een behoorlijk goede en volledig werkende versie van<strong>SQL</strong> <strong>Server</strong> gratis ter beschikk<strong>in</strong>g komt. Doel is<br />
natuurlijkde marktleider <strong>voor</strong> gratis databases, MySql, concurrentieaan te doen.<br />
Wat is een goed <strong>beg<strong>in</strong>ners</strong>boek<br />
Er zijn<strong>voor</strong> <strong>SQL</strong> <strong>Server</strong> een paar duizendverschillendeboeken te v<strong>in</strong>den. Een keus eruit te maken valtniet mee. Een groot deel<br />
ervanis echter <strong>voor</strong> Database-Adm<strong>in</strong>istrators, en die zijnniet erg <strong>in</strong>teressant<strong>voor</strong> <strong>beg<strong>in</strong>ners</strong>. Een boek dat ik goed te lezenv<strong>in</strong>d<br />
<strong>voor</strong> <strong>beg<strong>in</strong>ners</strong> is (www.Amazon.com):<br />
Uit de beschrijv<strong>in</strong>g:<br />
If you wantto learn <strong>SQL</strong>, youÆve picked the right book. Unlike most <strong>SQL</strong> books, this one starts by show<strong>in</strong>g howto use <strong>SQL</strong><br />
queries to extract and update the data <strong>in</strong> a database, because that's whatevery programmer needs to know. Then, the book<br />
showshowto design and implement a database, and howto use the server-side features like views, stored procedures, and<br />
transactions. Because its CD <strong>in</strong>cludes everyth<strong>in</strong>g you need for runn<strong>in</strong>g <strong>SQL</strong> on your ownPC, this book worksgreat whetheryou<br />
wantto learn <strong>SQL</strong> or the specifics of <strong>SQL</strong> for <strong>Microsoft</strong> <strong>SQL</strong> <strong>Server</strong>.<br />
Van de auteur:<br />
Like most other programmers, I first learned <strong>SQL</strong> almost by accident, not realiz<strong>in</strong>g all that I wasmiss<strong>in</strong>g. That's whyI th<strong>in</strong>k of this<br />
as the <strong>SQL</strong> book that you didn't knowyou needed. And my goal has been to make it the perfect book for three different types of<br />
<strong>SQL</strong> users. First, if you're an application programmer, this book helps you improve your queries and teaches you the advanced<br />
<strong>SQL</strong> skills that you won't learn on your own. Second, if you're a <strong>SQL</strong> programmer (or wantto be one), this book lets you quickly<br />
learn the basics, then move on to the <strong>SQL</strong> <strong>Server</strong> and database design skills that turn you <strong>in</strong>to a top professional. Third, if you're<br />
develop<strong>in</strong>g a complete database application on your own, this book gives you all the <strong>in</strong>formation you need to design,<br />
implement , and ma<strong>in</strong>ta<strong>in</strong> it. I've found Murach's "paired pages" format to be the perfect wayto deliver the concise explanations,<br />
realistic examples, and quick reference material that I knowyou'll use on the job.<br />
Copyright © 2004 NLDelphi.com