

Competition, product and process innovation: an empirical ... - Ivie

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
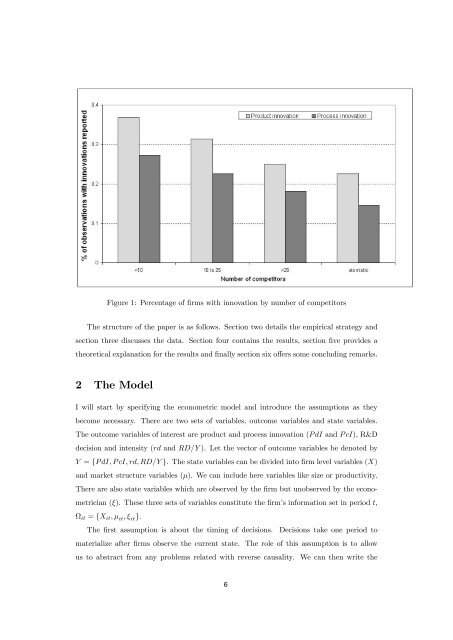
Figure 1: Percentage of …rms with <strong>innovation</strong> by number of competitors<br />
The structure of the paper is as follows. Section two details the <strong>empirical</strong> strategy <strong><strong>an</strong>d</strong><br />
section three discusses the data. Section four contains the results, section …ve provides a<br />
theoretical expl<strong>an</strong>ation for the results <strong><strong>an</strong>d</strong> …nally section six o¤ers some concluding remarks.<br />
2 The Model<br />
I will start by specifying the econometric model <strong><strong>an</strong>d</strong> introduce the assumptions as they<br />
become necessary. There are two sets of variables, outcome variables <strong><strong>an</strong>d</strong> state variables.<br />
The outcome variables of interest are <strong>product</strong> <strong><strong>an</strong>d</strong> <strong>process</strong> <strong>innovation</strong> (P dI <strong><strong>an</strong>d</strong> P cI), R&D<br />
decision <strong><strong>an</strong>d</strong> intensity (rd <strong><strong>an</strong>d</strong> RD=Y ). Let the vector of outcome variables be denoted by<br />
Y = fP dI; P cI; rd; RD=Y g. The state variables c<strong>an</strong> be divided into …rm level variables (X)<br />
<strong><strong>an</strong>d</strong> market structure variables (). We c<strong>an</strong> include here variables like size or <strong>product</strong>ivity.<br />
There are also state variables which are observed by the …rm but unobserved by the econometrici<strong>an</strong><br />
(). These three sets of variables constitute the …rm’s information set in period t,<br />
it = fX it ; it ; it g.<br />
The …rst assumption is about the timing of decisions. Decisions take one period to<br />
materialize after …rms observe the current state. The role of this assumption is to allow<br />
us to abstract from <strong>an</strong>y problems related with reverse causality. We c<strong>an</strong> then write the<br />
4














