

Parallelized Critical Path Search in Electrical Circuit Designs
Parallelized Critical Path Search in Electrical Circuit Designs
Parallelized Critical Path Search in Electrical Circuit Designs

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
exist<strong>in</strong>g code uses a standard Dijkstra algorithm. We compile<br />
the code with the same optimization level.<br />
Figure 4 compares the runtime of the path search described<br />
<strong>in</strong> List<strong>in</strong>g 1. From this figure, the Intel compiler<br />
performs better <strong>in</strong> the first half of the experiment, by up<br />
to 28 seconds faster. However, as more samples are taken,<br />
the ga<strong>in</strong> is greatly reduced with<strong>in</strong> 5 seconds of each other.<br />
Overall, with 40 measurements, the Intel compiler offers a<br />
better performance of approximately 4.5 seconds on average<br />
compared to gcc.<br />
Due to the highly recursive implementation, we do not<br />
expect to much speed-up on the Intel compiler. The result,<br />
shown <strong>in</strong> Figure 4, confirms our assumption. To achieve<br />
a better performance, manual changes to the code us<strong>in</strong>g<br />
pragma directives can assist the compiler to parallelize the<br />
code. However, this would need an <strong>in</strong> deep <strong>in</strong>vestigation of<br />
the source code and is a very time consum<strong>in</strong>g task. Therefore,<br />
this experiment emphasizes the need to adapt shortest<br />
path algorithms runn<strong>in</strong>g on multi-core systems.<br />
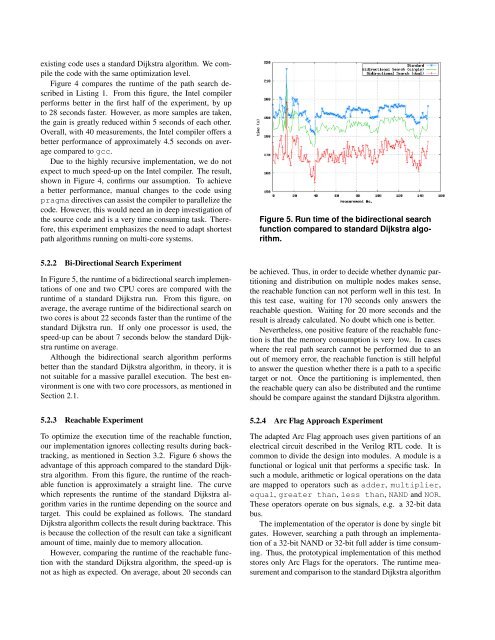
5.2.2 Bi-Directional <strong>Search</strong> Experiment<br />
In Figure 5, the runtime of a bidirectional search implementations<br />
of one and two CPU cores are compared with the<br />
runtime of a standard Dijkstra run. From this figure, on<br />
average, the average runtime of the bidirectional search on<br />
two cores is about 22 seconds faster than the runtime of the<br />
standard Dijkstra run. If only one processor is used, the<br />
speed-up can be about 7 seconds below the standard Dijkstra<br />
runtime on average.<br />
Although the bidirectional search algorithm performs<br />
better than the standard Dijkstra algorithm, <strong>in</strong> theory, it is<br />
not suitable for a massive parallel execution. The best environment<br />
is one with two core processors, as mentioned <strong>in</strong><br />
Section 2.1.<br />
5.2.3 Reachable Experiment<br />
To optimize the execution time of the reachable function,<br />
our implementation ignores collect<strong>in</strong>g results dur<strong>in</strong>g backtrack<strong>in</strong>g,<br />
as mentioned <strong>in</strong> Section 3.2. Figure 6 shows the<br />
advantage of this approach compared to the standard Dijkstra<br />
algorithm. From this figure, the runtime of the reachable<br />
function is approximately a straight l<strong>in</strong>e. The curve<br />
which represents the runtime of the standard Dijkstra algorithm<br />
varies <strong>in</strong> the runtime depend<strong>in</strong>g on the source and<br />
target. This could be expla<strong>in</strong>ed as follows. The standard<br />
Dijkstra algorithm collects the result dur<strong>in</strong>g backtrace. This<br />
is because the collection of the result can take a significant<br />
amount of time, ma<strong>in</strong>ly due to memory allocation.<br />
However, compar<strong>in</strong>g the runtime of the reachable function<br />
with the standard Dijkstra algorithm, the speed-up is<br />
not as high as expected. On average, about 20 seconds can<br />
Figure 5. Run time of the bidirectional search<br />
function compared to standard Dijkstra algorithm.<br />
be achieved. Thus, <strong>in</strong> order to decide whether dynamic partition<strong>in</strong>g<br />
and distribution on multiple nodes makes sense,<br />
the reachable function can not perform well <strong>in</strong> this test. In<br />
this test case, wait<strong>in</strong>g for 170 seconds only answers the<br />
reachable question. Wait<strong>in</strong>g for 20 more seconds and the<br />
result is already calculated. No doubt which one is better.<br />
Nevertheless, one positive feature of the reachable function<br />
is that the memory consumption is very low. In cases<br />
where the real path search cannot be performed due to an<br />
out of memory error, the reachable function is still helpful<br />
to answer the question whether there is a path to a specific<br />
target or not. Once the partition<strong>in</strong>g is implemented, then<br />
the reachable query can also be distributed and the runtime<br />
should be compare aga<strong>in</strong>st the standard Dijkstra algorithm.<br />
5.2.4 Arc Flag Approach Experiment<br />
The adapted Arc Flag approach uses given partitions of an<br />
electrical circuit described <strong>in</strong> the Verilog RTL code. It is<br />
common to divide the design <strong>in</strong>to modules. A module is a<br />
functional or logical unit that performs a specific task. In<br />
such a module, arithmetic or logical operations on the data<br />
are mapped to operators such as adder, multiplier,<br />
equal, greater than, less than, NAND and NOR.<br />
These operators operate on bus signals, e.g. a 32-bit data<br />
bus.<br />
The implementation of the operator is done by s<strong>in</strong>gle bit<br />
gates. However, search<strong>in</strong>g a path through an implementation<br />
of a 32-bit NAND or 32-bit full adder is time consum<strong>in</strong>g.<br />
Thus, the prototypical implementation of this method<br />
stores only Arc Flags for the operators. The runtime measurement<br />
and comparison to the standard Dijkstra algorithm


