

Comparing the value of Latent Semantic Analysis on two English-to ...
Comparing the value of Latent Semantic Analysis on two English-to ...
Comparing the value of Latent Semantic Analysis on two English-to ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
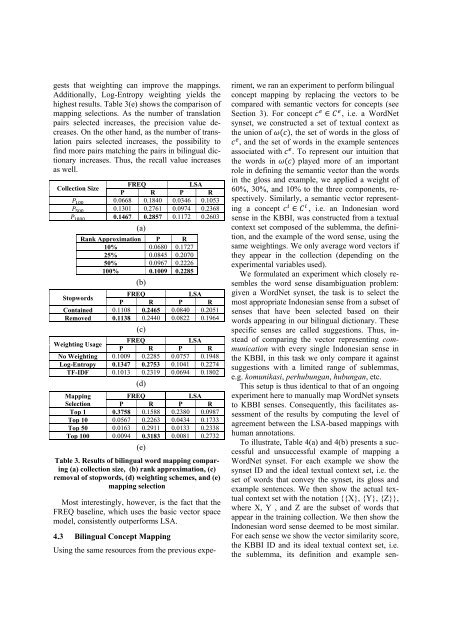
gests that weighting can improve <str<strong>on</strong>g>the</str<strong>on</strong>g> mappings.<br />
Additi<strong>on</strong>ally, Log-Entropy weighting yields <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
highest results. Table 3(e) shows <str<strong>on</strong>g>the</str<strong>on</strong>g> comparis<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
mapping selecti<strong>on</strong>s. As <str<strong>on</strong>g>the</str<strong>on</strong>g> number <str<strong>on</strong>g>of</str<strong>on</strong>g> translati<strong>on</strong><br />
pairs selected increases, <str<strong>on</strong>g>the</str<strong>on</strong>g> precisi<strong>on</strong> <str<strong>on</strong>g>value</str<strong>on</strong>g> decreases.<br />
On <str<strong>on</strong>g>the</str<strong>on</strong>g> o<str<strong>on</strong>g>the</str<strong>on</strong>g>r hand, as <str<strong>on</strong>g>the</str<strong>on</strong>g> number <str<strong>on</strong>g>of</str<strong>on</strong>g> translati<strong>on</strong><br />
pairs selected increases, <str<strong>on</strong>g>the</str<strong>on</strong>g> possibility <strong>to</strong><br />
find more pairs matching <str<strong>on</strong>g>the</str<strong>on</strong>g> pairs in bilingual dicti<strong>on</strong>ary<br />
increases. Thus, <str<strong>on</strong>g>the</str<strong>on</strong>g> recall <str<strong>on</strong>g>value</str<strong>on</strong>g> increases<br />
as well.<br />
Collecti<strong>on</strong> Size<br />
FREQ<br />
LSA<br />
P R P R<br />
0.0668 0.1840 0.0346 0.1053<br />
0.1301 0.2761 0.0974 0.2368<br />
0.1467 0.2857 0.1172 0.2603<br />
(a)<br />
Rank Approximati<strong>on</strong> P R<br />
10% 0.0680 0.1727<br />
25% 0.0845 0.2070<br />
50% 0.0967 0.2226<br />
100% 0.1009 0.2285<br />
(b)<br />
S<strong>to</strong>pwords<br />
FREQ<br />
LSA<br />
P R P R<br />
C<strong>on</strong>tained 0.1108 0.2465 0.0840 0.2051<br />
Removed 0.1138 0.2440 0.0822 0.1964<br />
(c)<br />
Weighting Usage<br />
FREQ<br />
LSA<br />
P R P R<br />
No Weighting 0.1009 0.2285 0.0757 0.1948<br />
Log-Entropy 0.1347 0.2753 0.1041 0.2274<br />
TF-IDF 0.1013 0.2319 0.0694 0.1802<br />
(d)<br />
Mapping<br />
FREQ<br />
LSA<br />
Selecti<strong>on</strong> P R P R<br />
Top 1 0.3758 0.1588 0.2380 0.0987<br />
Top 10 0.0567 0.2263 0.0434 0.1733<br />
Top 50 0.0163 0.2911 0.0133 0.2338<br />
Top 100 0.0094 0.3183 0.0081 0.2732<br />
(e)<br />
Table 3. Results <str<strong>on</strong>g>of</str<strong>on</strong>g> bilingual word mapping comparing<br />
(a) collecti<strong>on</strong> size, (b) rank approximati<strong>on</strong>, (c)<br />
removal <str<strong>on</strong>g>of</str<strong>on</strong>g> s<strong>to</strong>pwords, (d) weighting schemes, and (e)<br />
mapping selecti<strong>on</strong><br />
Most interestingly, however, is <str<strong>on</strong>g>the</str<strong>on</strong>g> fact that <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
FREQ baseline, which uses <str<strong>on</strong>g>the</str<strong>on</strong>g> basic vec<strong>to</strong>r space<br />
model, c<strong>on</strong>sistently outperforms LSA.<br />
4.3 Bilingual C<strong>on</strong>cept Mapping<br />
Using <str<strong>on</strong>g>the</str<strong>on</strong>g> same resources from <str<strong>on</strong>g>the</str<strong>on</strong>g> previous expe-<br />
riment, we ran an experiment <strong>to</strong> perform bilingual<br />
c<strong>on</strong>cept mapping by replacing <str<strong>on</strong>g>the</str<strong>on</strong>g> vec<strong>to</strong>rs <strong>to</strong> be<br />
compared with semantic vec<strong>to</strong>rs for c<strong>on</strong>cepts (see<br />
Secti<strong>on</strong> 3). For c<strong>on</strong>cept , i.e. a WordNet<br />
synset, we c<strong>on</strong>structed a set <str<strong>on</strong>g>of</str<strong>on</strong>g> textual c<strong>on</strong>text as<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g> uni<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> , <str<strong>on</strong>g>the</str<strong>on</strong>g> set <str<strong>on</strong>g>of</str<strong>on</strong>g> words in <str<strong>on</strong>g>the</str<strong>on</strong>g> gloss <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
, and <str<strong>on</strong>g>the</str<strong>on</strong>g> set <str<strong>on</strong>g>of</str<strong>on</strong>g> words in <str<strong>on</strong>g>the</str<strong>on</strong>g> example sentences<br />
associated with . To represent our intuiti<strong>on</strong> that<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g> words in played more <str<strong>on</strong>g>of</str<strong>on</strong>g> an important<br />
role in defining <str<strong>on</strong>g>the</str<strong>on</strong>g> semantic vec<strong>to</strong>r than <str<strong>on</strong>g>the</str<strong>on</strong>g> words<br />
in <str<strong>on</strong>g>the</str<strong>on</strong>g> gloss and example, we applied a weight <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
60%, 30%, and 10% <strong>to</strong> <str<strong>on</strong>g>the</str<strong>on</strong>g> three comp<strong>on</strong>ents, respectively.<br />
Similarly, a semantic vec<strong>to</strong>r representing<br />
a c<strong>on</strong>cept , i.e. an Ind<strong>on</strong>esian word<br />
sense in <str<strong>on</strong>g>the</str<strong>on</strong>g> KBBI, was c<strong>on</strong>structed from a textual<br />
c<strong>on</strong>text set composed <str<strong>on</strong>g>of</str<strong>on</strong>g> <str<strong>on</strong>g>the</str<strong>on</strong>g> sublemma, <str<strong>on</strong>g>the</str<strong>on</strong>g> definiti<strong>on</strong>,<br />
and <str<strong>on</strong>g>the</str<strong>on</strong>g> example <str<strong>on</strong>g>of</str<strong>on</strong>g> <str<strong>on</strong>g>the</str<strong>on</strong>g> word sense, using <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
same weightings. We <strong>on</strong>ly average word vec<strong>to</strong>rs if<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g>y appear in <str<strong>on</strong>g>the</str<strong>on</strong>g> collecti<strong>on</strong> (depending <strong>on</strong> <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
experimental variables used).<br />
We formulated an experiment which closely resembles<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g> word sense disambiguati<strong>on</strong> problem:<br />
given a WordNet synset, <str<strong>on</strong>g>the</str<strong>on</strong>g> task is <strong>to</strong> select <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
most appropriate Ind<strong>on</strong>esian sense from a subset <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
senses that have been selected based <strong>on</strong> <str<strong>on</strong>g>the</str<strong>on</strong>g>ir<br />
words appearing in our bilingual dicti<strong>on</strong>ary. These<br />
specific senses are called suggesti<strong>on</strong>s. Thus, instead<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> comparing <str<strong>on</strong>g>the</str<strong>on</strong>g> vec<strong>to</strong>r representing communicati<strong>on</strong><br />
with every single Ind<strong>on</strong>esian sense in<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g> KBBI, in this task we <strong>on</strong>ly compare it against<br />
suggesti<strong>on</strong>s with a limited range <str<strong>on</strong>g>of</str<strong>on</strong>g> sublemmas,<br />
e.g. komunikasi, perhubungan, hubungan, etc.<br />
This setup is thus identical <strong>to</strong> that <str<strong>on</strong>g>of</str<strong>on</strong>g> an <strong>on</strong>going<br />
experiment here <strong>to</strong> manually map WordNet synsets<br />
<strong>to</strong> KBBI senses. C<strong>on</strong>sequently, this facilitates assessment<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> <str<strong>on</strong>g>the</str<strong>on</strong>g> results by computing <str<strong>on</strong>g>the</str<strong>on</strong>g> level <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
agreement between <str<strong>on</strong>g>the</str<strong>on</strong>g> LSA-based mappings with<br />
human annotati<strong>on</strong>s.<br />
To illustrate, Table 4(a) and 4(b) presents a successful<br />
and unsuccessful example <str<strong>on</strong>g>of</str<strong>on</strong>g> mapping a<br />
WordNet synset. For each example we show <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
synset ID and <str<strong>on</strong>g>the</str<strong>on</strong>g> ideal textual c<strong>on</strong>text set, i.e. <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
set <str<strong>on</strong>g>of</str<strong>on</strong>g> words that c<strong>on</strong>vey <str<strong>on</strong>g>the</str<strong>on</strong>g> synset, its gloss and<br />
example sentences. We <str<strong>on</strong>g>the</str<strong>on</strong>g>n show <str<strong>on</strong>g>the</str<strong>on</strong>g> actual textual<br />
c<strong>on</strong>text set with <str<strong>on</strong>g>the</str<strong>on</strong>g> notati<strong>on</strong> {{X}, {Y}, {Z}},<br />
where X, Y , and Z are <str<strong>on</strong>g>the</str<strong>on</strong>g> subset <str<strong>on</strong>g>of</str<strong>on</strong>g> words that<br />
appear in <str<strong>on</strong>g>the</str<strong>on</strong>g> training collecti<strong>on</strong>. We <str<strong>on</strong>g>the</str<strong>on</strong>g>n show <str<strong>on</strong>g>the</str<strong>on</strong>g><br />
Ind<strong>on</strong>esian word sense deemed <strong>to</strong> be most similar.<br />
For each sense we show <str<strong>on</strong>g>the</str<strong>on</strong>g> vec<strong>to</strong>r similarity score,<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g> KBBI ID and its ideal textual c<strong>on</strong>text set, i.e.<br />
<str<strong>on</strong>g>the</str<strong>on</strong>g> sublemma, its definiti<strong>on</strong> and example sen-











