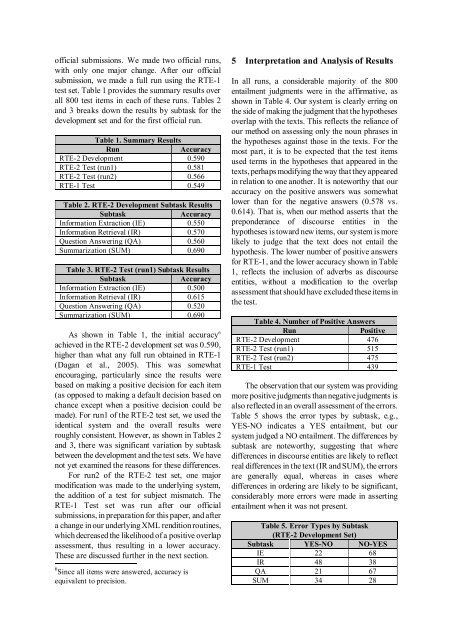
official submissions. We made two official runs,with only one major change. After our officialsubmission, we made a full run using the RTE-1test set. Table 1 provides the summary results overall 800 test items in each of these runs. Tables 2and 3 breaks down the results by subtask <strong>for</strong> thedevelopment set and <strong>for</strong> the first official run.Table 1. Summary ResultsRunAccuracyRTE-2 Development 0.590RTE-2 Test (run1) 0.581RTE-2 Test (run2) 0.566RTE-1 Test 0.549Table 2. RTE-2 Development Subtask ResultsSubtaskAccuracyIn<strong>for</strong>mation Extraction (IE) 0.550In<strong>for</strong>mation Retrieval (IR) 0.570Question Answering (QA) 0.560Summarization (SUM) 0.690Table 3. RTE-2 Test (run1) Subtask ResultsSubtaskAccuracyIn<strong>for</strong>mation Extraction (IE) 0.500In<strong>for</strong>mation Retrieval (IR) 0.615Question Answering (QA) 0.520Summarization (SUM) 0.690As shown in Table 1, the initial accuracy 6achieved in the RTE-2 development set was 0.590,higher than what any full run obtained in RTE-1(Dagan et al., 2005). This was somewhatencouraging, particularly since the results werebased on making a positive decision <strong>for</strong> each item(as opposed to making a default decision based onchance except when a positive decision could bemade). For run1 of the RTE-2 test set, we used theidentical system and the overall results wereroughly consistent. However, as shown in Tables 2and 3, there was significant variation by subtaskbetween the development and the test sets. We havenot yet examined the reasons <strong>for</strong> these differences.For run2 of the RTE-2 test set, one majormodification was made to the underlying system,the addition of a test <strong>for</strong> subject mismatch. TheRTE-1 Test set was run after our officialsubmissions, in preparation <strong>for</strong> this paper, and aftera change in our underlying XML rendition routines,which decreased the likelihood of a positive overlapassessment, thus resulting in a lower accuracy.These are discussed further in the next section.6 Since all items were answered, accuracy isequivalent to precision.5 Interpretation and <strong>Analysis</strong> of ResultsIn all runs, a considerable majority of the 800entailment judgments were in the affirmative, asshown in Table 4. Our system is clearly erring onthe side of making the judgment that the hypothesesoverlap with the texts. This reflects the reliance ofour method on assessing only the noun phrases inthe hypotheses against those in the texts. For themost part, it is to be expected that the test itemsused terms in the hypotheses that appeared in thetexts, perhaps modifying the way that they appearedin relation to one another. It is noteworthy that ouraccuracy on the positive answers was somewhatlower than <strong>for</strong> the negative answers (0.578 vs.0.614). That is, when our method asserts that thepreponderance of discourse entities in thehypotheses is toward new items, our system is morelikely to judge that the text does not entail thehypothesis. The lower number of positive answers<strong>for</strong> RTE-1, and the lower accuracy shown in Table1, reflects the inclusion of adverbs as discourseentities, without a modification to the overlapassessment that should have excluded these items inthe test.Table 4. Number of Positive AnswersRunPositiveRTE-2 Development 476RTE-2 Test (run1) 515RTE-2 Test (run2) 475RTE-1 Test 439The observation that our system was providingmore positive judgments than negative judgments isalso reflected in an overall assessment of the errors.Table 5 shows the error types by subtask, e.g.,YES-NO indicates a YES entailment, but oursystem judged a NO entailment. The differences bysubtask are noteworthy, suggesting that wheredifferences in discourse entities are likely to reflectreal differences in the text (IR and SUM), the errorsare generally equal, whereas in cases wheredifferences in ordering are likely to be significant,considerably more errors were made in assertingentailment when it was not present.Table 5. Error Types by Subtask(RTE-2 Development Set)Subtask YES-NO NO-YESIE 22 68IR 48 38QA 21 67SUM 34 28
Having grouped the error types in this generalway, we were able to focus the error analysis inways that otherwise would not have been possible.In particular, it quickly became clear that therewere significant differences in the types of errorsand that different approaches were necessary. Ingeneral, YES answers require different types ofanalysis from NO answers. YES answers imply thatthere is sufficient overlap in the discourse entities,but that after this assessment, it is necessary todetermine if the discourse entities bear similarsynactic and semantic relations to one another. NOanswers, on the other hand, require a furtheranalysis to determine if we have overlookedsynonyms or paraphrases.In examining YES answers which should havebeen NO answers, we were able to observe manycases where the difference was in the subject of averb. That is, the subject of the verb in thehypothesis was different from the subject of thesame verb in the text (even though this subjectappeared somewhere in the text). We termed this acase of “subject mismatch” and implemented thistest <strong>for</strong> those cases where an initial assessment wasentailment. We modified the underlying code tomake this test, working with one item (126, with thehypothesis, “North Korea says it will rejoin nucleartalks”, where the subject of “say” in the text was“Condoleezza Rice”).After making this change on the basis of oneitem, we reran our evaluations <strong>for</strong> all items. This isthe difference between run1 and run2. As indicatedin Table 5, the effect of this change was a reductionin the number of positive answers from 515 to 475.However, as shown in Table 1, the effect on theaccuracy was a decline from 0.581 to 0.566, a netdecline of 12 correct answers. Of the 40 changedanswers, 26 were changed from correct to incorrect.We were able to investigate these cases in detail,making a further assessment of where our systemhad made an incorrect change. Several problemsemerged (e.g., incorrect use of a genitive as themain verb). Making slight changes would haveimproved our results slightly, but were not madebecause of time limitations and because it seemedthat they ought to be part of more general solutions.As indicated, inclusion of the subject mismatchtest (also observed in working with the developmentset) seemed to decrease our per<strong>for</strong>mance. As aresult, it was not included in run1, but only inrun2, with the expectation of a decline, borne outwhen the score was computed.6 Considerations <strong>for</strong> Future WorkSimilar results to that of using the subject mismatchtest seemed likely when considering other possiblemodifications to our system, namely, that althoughthe result <strong>for</strong> some specific items would be changedfrom incorrect to correct, the effect over the full setwould likely result in an overall negative effect. Wedescribe the avenues we investigated.As mentioned earlier, we observed the need <strong>for</strong>different types of tests depending on the initialresult returned by the system. We also observedthat the subtask is significant, and perhaps has abearing on some of the test items. The main concernis the plausibility of a hypothesis and how thismight be encountered in a real system.For summarization, the hypotheses appear to bevalid sentences retrieved from other documents,overlapping to some extent. This task appears to bewell drawn. In this subtask, the key is therecognition of novel elements (similar to the noveltytask in TREC in 2003 and 2004). For our system,this would mean a more detailed analysis of thenovel elements in a hypothesis. The in<strong>for</strong>mationretrieval task appears to be somewhat similar, inthat the hypotheses might be drawn from real texts.For question answering, the task appears to beless well-drawn. Many of the non-entailedhypotheses are unlikely to appear in real texts. Webelieve this is reflected in the many NO-YES errorsthat appeared in our results. A similar situationoccurs <strong>for</strong> the in<strong>for</strong>mation extraction task, where itis unlikely that non-entailed hypotheses would befound in real text, since they are essentiallycounterfactual. (The non-entailed hypotheses initem 209, Biodiesel produces the 'Beetle', and item226, Seasonal Affective Disorder (SAD) is aworldwide disorder, are unlikely to occur in realtext.)We reviewed material from RTE-1 (Dagan etal.) to identify areas <strong>for</strong> exploration. As indicated,this led to our major approach of using overlapanalysis as employed in KMS’ summarizationroutines. We considered the potential <strong>for</strong> various<strong>for</strong>ms of syntactic analysis, particularly asdescribed in Vanderwende et al. (2005), since manyof these constructs are similar to what KMSemploys in its question answering routines (i.e.,appositives, copular constructions, predicatearguments, and active-passive alternations.However, when we examined instances where theseoccurred in the development set and were relevant