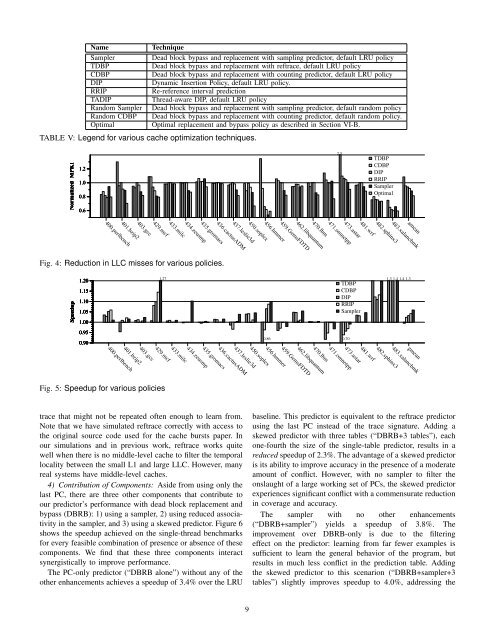
Namemix1mix2mix3mix4mix5mix6mix7mix8mix9mix10CacheSensitivityBenchmarksCurve43.5mcf hmmer libquantumomnetpp 25.5gobmk soplex libquantum lbm22.012.614.6zeusmp leslie3d libquantumxalancbmk 9.419.0gamess cactusADM soplexlibquantum 9.5bzip2 gamess mcf sphinx336.416.69.7gcc calculix libquantumsphinx3 6.6perlbench milc hmmer lbmbzip2 gcc gobmk lbmgamess mcf tonto xalancbmkmilc namd sphinx3 xalancbmk10.49.66.75.437.016.612.4TABLE IV: Multi-core workload mixes with cache sensitivitycurves giving LLC misses per 1000 instructions (MPKI)on the y-axis <strong>for</strong> last-level cache sizes 128KB through32MB on the x-axis.For the multi-core workloads, we report the weighted speedupnormalized to LRU. That is, <strong>for</strong> each thread i sharing the 8MBcache, we compute IPC i . Then we find SingleIPC i as the IPCof the same program running in isolation with an 8MB cachewith LRU replacement. Then we compute the weighted IPCas ∑ IPC i /SingleIPC i . We then normalize this weighted IPCwith the weighted IPC using the LRU replacement policy.B. Optimal Replacement and Bypass PolicyFor simulating misses, we also compare with an optimalblock replacement and bypass policy. That is, we enhanceBelady’s MIN replacement policy [3] with a bypass policythat refuses to place a block in a set when that block’s nextaccess will not occur until after the next accesses to all otherblocks in the set. We use trace-based simulation to determinethe optimal number of misses using the same sequence ofmemory accesses made by the out-of-order simulator. The outof-ordersimulator does not include the optimal replacementand bypass policy so we report optimal numbers only <strong>for</strong> cachemiss reduction and not <strong>for</strong> speedup.4.5VII. EXPERIMENTAL RESULTSIn this section we discuss results of our experiments. Inthe graphs that follow, several techniques are referred to withabbreviated names. Table V gives a legend <strong>for</strong> these names.For TDBP and CDBP, we simulate a dead block bypass andreplacement policy just as described previously, dropping inthe reftrace and counting predictors, respectively, in place ofour sampling predictor.A. <strong>Dead</strong> <strong>Block</strong> Replacement with LRU BaselineWe explore the use of sampling prediction to drive replacementand bypass in a default LRU replaced cache comparedwith several other techniques <strong>for</strong> the single-thread benchmarks.1) LLC Misses: Figure 4 shows LLC cache misses normalizedto a 2MB LRU cache <strong>for</strong> each benchmark. On average,dynamic insertion (DIP) reduces cache misses to 93.9% ofthe baseline LRU, a reduction of by 6.1%. RRIP reducesmisses by 8.1%. The reftrace-predictor-driven policy (TDBP)increases average misses on average by 8.0% (mostly dueto 473.astar), decreasing misses on only 11 of the 19benchmarks. CDBP reduces average misses by 4.6%. Thesampling predictor reduces average misses by 11.7%. Theoptimal policy reduces misses by 18.6% over LRU; thus, thesampling predictor achieves 63% of the improvement of theoptimal policy.2) Speedup: Reducing cache misses translates into improvedper<strong>for</strong>mance. Figure 5 shows the speedup (i.e. newIPC divided by old IPC) over LRU <strong>for</strong> the predictor-drivenpolicies with a default LRU cache.DIP improves per<strong>for</strong>mance by a geometric mean of 3.1%.TDBP provides a speedup on some benchmarks and a slowdownon others, resulting in a geometric mean speedup ofapproximately 0%. The counting predictor delivers a geometricmean speedup of 2.3%, and does not significantly slowdown any benchmarks. RRIP yields an average speedup of4.1%. The sampling predictor gives a geometric mean speedupof 5.9%. It improves per<strong>for</strong>mance by at least 4% <strong>for</strong> eight ofthe benchmarks, as opposed to only five benchmarks <strong>for</strong> RRIPand CDBP and two <strong>for</strong> TDBP. The sampling predictor deliversper<strong>for</strong>mance superior to each of the other techniques tested.Speedup and cache misses are particularly poor <strong>for</strong>473.astar. As we will see in Section VII-C, dead blockprediction accuracy is bad <strong>for</strong> this benchmark. However, thesampling predictor minimizes the damage by making fewerpredictions than the other predictors.3) Poor Per<strong>for</strong>mance <strong>for</strong> Trace-Based Predictor: Note thatthe reftrace predictor per<strong>for</strong>ms quite poorly compared withits observed behavior in previous work [15]. In that work,reftrace was used <strong>for</strong> L1 or L2 caches with significant temporallocality in streams of reference reaching the predictor. Reftracelearns from these streams of temporal locality. In this work, thepredictor optimizes the LLC in which most temporal localityhas been filtered by the 256KB middle-level cache. In thissituation, it is easier <strong>for</strong> the predictor to try to simply learnthe last PC to reference a block rather than a sparse reference8
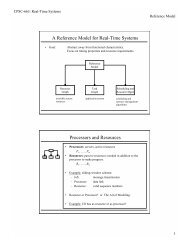
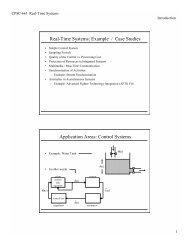
NameTechniqueSampler<strong>Dead</strong> block bypass and replacement with sampling predictor, default LRU policyTDBP<strong>Dead</strong> block bypass and replacement with reftrace, default LRU policyCDBP<strong>Dead</strong> block bypass and replacement with counting predictor, default LRU policyDIPDynamic Insertion Policy, default LRU policy.RRIPRe-reference interval predictionTADIPThread-aware DIP, default LRU policyRandom Sampler <strong>Dead</strong> block bypass and replacement with sampling predictor, default random policyRandom CDBP <strong>Dead</strong> block bypass and replacement with counting predictor, default random policy.OptimalOptimal replacement and bypass policy as described in Section VI-B.TABLE V: Legend <strong>for</strong> various cache optimization techniques.Normalized MPKI1.21.00.80.62.5TDBPCDBPDIPRRIPSamplerOptimal450.soplexamean433.milc403.gcc481.wrf400.perlbench436.cactusADM435.gromacs462.libquantum459.GemsFDTD471.omnetpp483.xalancbmk434.zeusmp437.leslie3d482.sphinx3401.bzip2473.astar429.mcf470.lbm456.hmmerFig. 4: Reduction in LLC misses <strong>for</strong> various policies.Speedup1.201.151.101.051.000.950.901.27 1.3 1.4 1.4 1.30.86 0.70TDBPCDBPDIPRRIPSampler450.soplexgmean433.milc403.gcc481.wrf400.perlbench436.cactusADM435.gromacs462.libquantum459.GemsFDTD471.omnetpp483.xalancbmk434.zeusmp437.leslie3d482.sphinx3401.bzip2473.astar429.mcf470.lbm456.hmmerFig. 5: Speedup <strong>for</strong> various policiestrace that might not be repeated often enough to learn from.Note that we have simulated reftrace correctly with access tothe original source code used <strong>for</strong> the cache bursts paper. Inour simulations and in previous work, reftrace works quitewell when there is no middle-level cache to filter the temporallocality between the small L1 and large LLC. However, manyreal systems have middle-level caches.4) Contribution of Components: Aside from using only thelast PC, there are three other components that contribute toour predictor’s per<strong>for</strong>mance with dead block replacement andbypass (DBRB): 1) using a sampler, 2) using reduced associativityin the sampler, and 3) using a skewed predictor. Figure 6shows the speedup achieved on the single-thread benchmarks<strong>for</strong> every feasible combination of presence or absence of thesecomponents. We find that these three components interactsynergistically to improve per<strong>for</strong>mance.The PC-only predictor (“DBRB alone”) without any of theother enhancements achieves a speedup of 3.4% over the LRUbaseline. This predictor is equivalent to the reftrace predictorusing the last PC instead of the trace signature. Adding askewed predictor with three tables (“DBRB+3 tables”), eachone-fourth the size of the single-table predictor, results in areduced speedup of 2.3%. The advantage of a skewed predictoris its ability to improve accuracy in the presence of a moderateamount of conflict. However, with no sampler to filter theonslaught of a large working set of PCs, the skewed predictorexperiences significant conflict with a commensurate reductionin coverage and accuracy.The sampler with no other enhancements(“DBRB+sampler”) yields a speedup of 3.8%. Theimprovement over DBRB-only is due to the filteringeffect on the predictor: learning from far fewer examples issufficient to learn the general behavior of the program, butresults in much less conflict in the prediction table. Addingthe skewed predictor to this scenarion (“DBRB+sampler+3tables”) slightly improves speedup to 4.0%, addressing the9