

GPU Acceleration in LAMMPS
GPU Acceleration in LAMMPS
GPU Acceleration in LAMMPS
- No tags were found...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
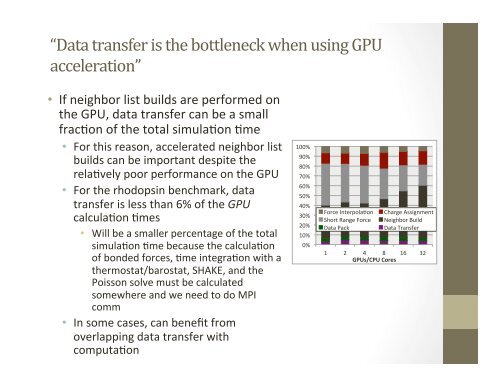
“Data transfer is the bottleneck when us<strong>in</strong>g <strong>GPU</strong> acceleration” • If neighbor list builds are performed on the <strong>GPU</strong>, data transfer can be a small frac1on of the total simula1on 1me • For this reason, accelerated neighbor list builds can be important despite the rela1vely poor performance on the <strong>GPU</strong> • For the rhodops<strong>in</strong> benchmark, data transfer is less than 6% of the <strong>GPU</strong> calcula1on 1mes • Will be a smaller percentage of the total simula1on 1me because the calcula1on of bonded forces, 1me <strong>in</strong>tegra1on with a thermostat/barostat, SHAKE, and the Poisson solve must be calculated somewhere and we need to do MPI comm • In some cases, can benefit from overlapp<strong>in</strong>g data transfer with computa1on 100% 90% 80% 70% 60% 50% 40% 30% 20% 10% 0% Force Interpola1on Short Range Force Data Pack Charge Assignment Neighbor Build Data Transfer 1 2 4 8 16 32 <strong>GPU</strong>s/CPU Cores













