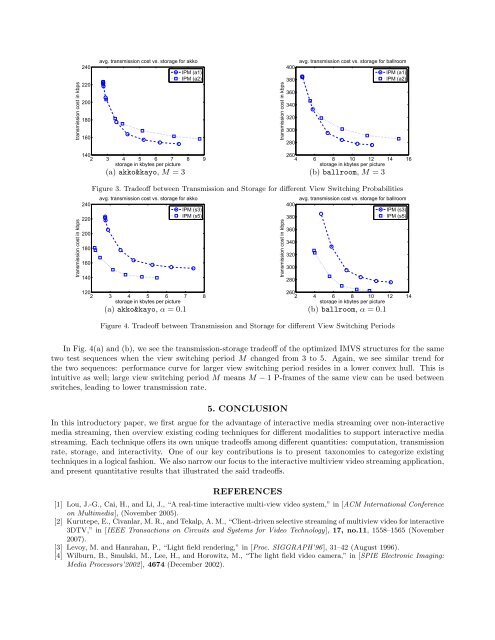
MV VideoSourceK camerasMV encod<strong>in</strong>gvideo servermultiviewdataview demandsrequested MV videoview demandsrequested MV video(a) IMVS System Overview<strong>in</strong>teractiveclient...<strong>in</strong>teractiveclientFi−1,1Fi−1,2Fi−1,1Fi−1,2F i,2F i,2Fi−1,3Fi−1,3i) redundant P−frames ii) M−frame(b) Frame Types <strong>for</strong> IMVSFigure 2. IMVS System Overview and Example Frame Types<strong>in</strong>teraction. By IMVS <strong>in</strong>teraction, we mean both the view switch<strong>in</strong>g period M (small M leads to faster viewswitches and more <strong>in</strong>teractivity), and likelihood that a user is to switch view given M. We def<strong>in</strong>e α to be theprobability that a user would choose to switch to a neighbor<strong>in</strong>g view at a view switch<strong>in</strong>g po<strong>in</strong>t; large α means auser is more likely to switch views, lead<strong>in</strong>g to more <strong>in</strong>teractivity.As build<strong>in</strong>g blocks to build an IMVS frame structure, we have previously proposed to use comb<strong>in</strong>ationsof redundant P-frames 22 and DSC-based merge-frames (M-frames). 21 Examples of these tools are shown <strong>in</strong>Fig. 2(b). Redundant P-frames encode one P-frame <strong>for</strong> each frame just prior to a view switch, us<strong>in</strong>g the previousframe as a predictor <strong>for</strong> differential cod<strong>in</strong>g, result<strong>in</strong>g <strong>in</strong> multiple frame representations <strong>for</strong> a given orig<strong>in</strong>al picture.In Fig. 2(b)(i), we see that there are three P-frames F i,2 ’s represent<strong>in</strong>g the same orig<strong>in</strong>al picture F1,2 o of time<strong>in</strong>stant 1 and view 2, each us<strong>in</strong>g a different frame <strong>in</strong> previous time <strong>in</strong>stant—one of F i−1,1 , F i−1,2 and F i−1,3 —aspredictor. While redundant P-frames result <strong>in</strong> low transmission bandwidth, it is obvious that us<strong>in</strong>g it alonewould lead to exponential growth <strong>in</strong> storage as the number of view switches across time <strong>in</strong>crease.As an alternative cod<strong>in</strong>g tool, we have proposed an M-frame, where a s<strong>in</strong>gle version F i,j of the orig<strong>in</strong>alpicture Fi,j o can be decoded no matter from which frame a user is switch<strong>in</strong>g from. In Fig. 2(b)(ii), the sameF i,2 can be decoded no matter which one of F i−1,1 F i−1,2 and F i−1,3 a user is switch<strong>in</strong>g from. <strong>On</strong>e straight<strong>for</strong>wardimplementation of M-frame is actually an I-frame. We have previously shown, however, that DSC-basedcod<strong>in</strong>g tools exploit<strong>in</strong>g the correlations between previous frames F i−1,k ’s and target frame F i,j can result <strong>in</strong>implementations that outper<strong>for</strong>m I-frame <strong>in</strong> both storage and transmission rate. An M-frame, however, rema<strong>in</strong>sa fair amount larger than a correspond<strong>in</strong>g P-frame.It should be obvious that a frame structure composed of large portions of redundant P-frames relative toM-frames will result <strong>in</strong> low transmission rate but large storage, while a structure composed of small portions ofredundant P-frames relative to M-frames will result <strong>in</strong> higher transmission rate but smaller storage. We referreaders to Cheung et al 23 <strong>for</strong> details on how an optimal structure is found <strong>for</strong> a desire transmission-storagetradeoff us<strong>in</strong>g comb<strong>in</strong>ation of redundant P-frames and M-frames, <strong>for</strong> given desired IMVS <strong>in</strong>teraction. We focus<strong>in</strong>stead on observ<strong>in</strong>g how the noted tradeoffs were manifested quantitatively <strong>in</strong> the IMVS context.4.2 IMVS TradeoffsWe now show quantitatively tradeoffs among transmission rate, storage and <strong>in</strong>teractivity. In Fig. 3(a) and (b),we see the per<strong>for</strong>mance of our optimized structures as different tradeoff po<strong>in</strong>ts between transmission and storage,<strong>for</strong> two test sequences akko&kayo and ballroom. They are coded at 320 ×240 resolution at 30 and 25 frames persecond, respectively. Quantization parameters (QP) were selected so that visual quality <strong>in</strong> peak Signal-to-noiseratio (PSNR) was about 34dB. View switch<strong>in</strong>g period M was fixed at 3. For each sequence, two trials wereper<strong>for</strong>med where the view switch<strong>in</strong>g probability α was set at 0.1 and 0.2.For both sequences, we see that at low storage, the difference between the two curves correspond<strong>in</strong>g to thetwo view switch<strong>in</strong>g probabilities is quite small. This agrees with our <strong>in</strong>tuition; at low storage, large portions ofthe frame structures are M-frames, which by design <strong>in</strong>duce the same transmission rate no matter from whichdecod<strong>in</strong>g path it is switch<strong>in</strong>g from. At high stroage, however, we see the difference between the two curvesbecomes larger. As more redundant P-frames are used, P-frames can selectively be deployed <strong>for</strong> decod<strong>in</strong>g pathswith high probabilities, lead<strong>in</strong>g to large reduction <strong>in</strong> transmission cost per P-frame encoded.
transmission cost <strong>in</strong> kbps240220200180160avg. transmission cost vs. storage <strong>for</strong> akkoIPM (a1)IPM (a2)transmission cost <strong>in</strong> kbps400380360340320300280avg. transmission cost vs. storage <strong>for</strong> ballroomIPM (a1)IPM (a2)transmission cost <strong>in</strong> kbps1402 3 4 5 6 7 8 9storage <strong>in</strong> kbytes per picture2402202001801601402604 6 8 10 12 14 16storage <strong>in</strong> kbytes per picture(a) akko&kayo, M = 3 (b) ballroom, M = 3Figure 3. Tradeoff between Transmission and Storage <strong>for</strong> different View Switch<strong>in</strong>g Probabilitiesavg. transmission cost vs. storage <strong>for</strong> akkoIPM (s3)IPM (s5)1202 3 4 5 6 7 8storage <strong>in</strong> kbytes per picturetransmission cost <strong>in</strong> kbps400380360340320300280avg. transmission cost vs. storage <strong>for</strong> ballroomIPM (s3)IPM (s5)2602 4 6 8 10 12 14storage <strong>in</strong> kbytes per picture(a) akko&kayo, α = 0.1 (b) ballroom, α = 0.1Figure 4. Tradeoff between Transmission and Storage <strong>for</strong> different View Switch<strong>in</strong>g PeriodsIn Fig. 4(a) and (b), we see the transmission-storage tradeoff of the optimized IMVS structures <strong>for</strong> the sametwo test sequences when the view switch<strong>in</strong>g period M changed from 3 to 5. Aga<strong>in</strong>, we see similar trend <strong>for</strong>the two sequences: per<strong>for</strong>mance curve <strong>for</strong> larger view switch<strong>in</strong>g period resides <strong>in</strong> a lower convex hull. This is<strong>in</strong>tuitive as well; large view switch<strong>in</strong>g period M means M − 1 P-frames of the same view can be used betweenswitches, lead<strong>in</strong>g to lower transmission rate.5. CONCLUSIONIn this <strong>in</strong>troductory paper, we first argue <strong>for</strong> the advantage of <strong>in</strong>teractive media stream<strong>in</strong>g over non-<strong>in</strong>teractivemedia stream<strong>in</strong>g, then overview exist<strong>in</strong>g cod<strong>in</strong>g techniques <strong>for</strong> different modalities to support <strong>in</strong>teractive mediastream<strong>in</strong>g. Each technique offers its own unique tradeoffs among different quantities: computation, transmissionrate, storage, and <strong>in</strong>teractivity. <strong>On</strong>e of our key contributions is to present taxonomies to categorize exist<strong>in</strong>gtechniques <strong>in</strong> a logical fashion. We also narrow our focus to the <strong>in</strong>teractive multiview video stream<strong>in</strong>g application,and present quantitative results that illustrated the said tradeoffs.REFERENCES[1] Lou, J.-G., Cai, H., and Li, J., “A real-time <strong>in</strong>teractive multi-view video system,” <strong>in</strong> [ACM International Conferenceon Multimedia], (November 2005).[2] Kurutepe, E., Civanlar, M. R., and Tekalp, A. M., “Client-driven selective stream<strong>in</strong>g of multiview video <strong>for</strong> <strong>in</strong>teractive3DTV,” <strong>in</strong> [IEEE Transactions on Circuits and Systems <strong>for</strong> Video Technology], 17, no.11, 1558–1565 (November2007).[3] Levoy, M. and Hanrahan, P., “Light field render<strong>in</strong>g,” <strong>in</strong> [Proc. SIGGRAPH’96], 31–42 (August 1996).[4] Wilburn, B., Smulski, M., Lee, H., and Horowitz, M., “The light field video camera,” <strong>in</strong> [SPIE Electronic Imag<strong>in</strong>g:<strong>Media</strong> Processors’2002], 4674 (December 2002).