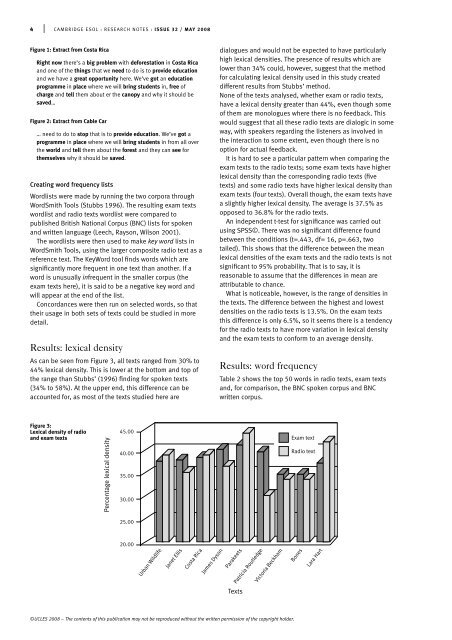
4 | CAMBRIDGE ESOL : RESEARCH NOTES : ISSUE 32 / MAY 2008Figure 1: Extract from Costa RicaRight now <strong>the</strong>re’s a big problem with deforestation <strong>in</strong> Costa Ricaand one of <strong>the</strong> th<strong>in</strong>gs that we need to do is to provide educationand we have a great opportunity here. We’ve got an educationprogramme <strong>in</strong> place where we will br<strong>in</strong>g students <strong>in</strong>, free ofcharge and tell <strong>the</strong>m about er <strong>the</strong> canopy and why it should besaved…Figure 2: Extract from Cable Car… need to do to stop that is to provide education. We’ve got aprogramme <strong>in</strong> place where we will br<strong>in</strong>g students <strong>in</strong> from all over<strong>the</strong> world and tell <strong>the</strong>m about <strong>the</strong> forest and <strong>the</strong>y can see for<strong>the</strong>mselves why it should be saved.Creat<strong>in</strong>g word frequency listsWordlists were made by runn<strong>in</strong>g <strong>the</strong> two corpora throughWordSmith Tools (Stubbs 1996). The result<strong>in</strong>g exam textswordlist and radio texts wordlist were compared topublished British National Corpus (BNC) lists for spokenand written language (Leech, Rayson, Wilson 2001).The wordlists were <strong>the</strong>n <strong>use</strong>d to make key word lists <strong>in</strong>WordSmith Tools, us<strong>in</strong>g <strong>the</strong> larger composite radio text as areference text. The KeyWord tool f<strong>in</strong>ds words which aresignificantly more frequent <strong>in</strong> one text than ano<strong>the</strong>r. If aword is unusually <strong>in</strong>frequent <strong>in</strong> <strong>the</strong> smaller corpus (<strong>the</strong>exam texts here), it is said to be a negative key word andwill appear at <strong>the</strong> end of <strong>the</strong> list.Concordances were <strong>the</strong>n run on selected words, so that<strong>the</strong>ir usage <strong>in</strong> both sets of texts could be studied <strong>in</strong> moredetail.Results: lexical densityAs can be seen from Figure 3, all texts ranged from 30% to44% lexical density. This is lower at <strong>the</strong> bottom and top of<strong>the</strong> range than Stubbs’ (1996) f<strong>in</strong>d<strong>in</strong>g for spoken texts(34% to 58%). At <strong>the</strong> upper end, this difference can beaccounted for, as most of <strong>the</strong> texts studied here aredialogues and would not be expected to have particularlyhigh lexical densities. The presence of results which arelower than 34% could, however, suggest that <strong>the</strong> methodfor calculat<strong>in</strong>g lexical density <strong>use</strong>d <strong>in</strong> this study createddifferent results from Stubbs’ method.None of <strong>the</strong> texts analysed, whe<strong>the</strong>r exam or radio texts,have a lexical density greater than 44%, even though someof <strong>the</strong>m are monologues where <strong>the</strong>re is no feedback. Thiswould suggest that all <strong>the</strong>se radio texts are dialogic <strong>in</strong> someway, with speakers regard<strong>in</strong>g <strong>the</strong> listeners as <strong>in</strong>volved <strong>in</strong><strong>the</strong> <strong>in</strong>teraction to some extent, even though <strong>the</strong>re is nooption for actual feedback.It is hard to see a particular pattern when compar<strong>in</strong>g <strong>the</strong>exam texts to <strong>the</strong> radio texts; some exam texts have higherlexical density than <strong>the</strong> correspond<strong>in</strong>g radio texts (fivetexts) and some radio texts have higher lexical density thanexam texts (four texts). Overall though, <strong>the</strong> exam texts havea slightly higher lexical density. The average is 37.5% asopposed to 36.8% for <strong>the</strong> radio texts.An <strong>in</strong>dependent t-<strong>test</strong> for significance was carried outus<strong>in</strong>g SPSS©. There was no significant difference foundbetween <strong>the</strong> conditions (t=.443, df= 16, p=.663, twotailed). This shows that <strong>the</strong> difference between <strong>the</strong> meanlexical densities of <strong>the</strong> exam texts and <strong>the</strong> radio texts is notsignificant to 95% probability. That is to say, it isreasonable to assume that <strong>the</strong> differences <strong>in</strong> mean areattributable to chance.What is noticeable, however, is <strong>the</strong> range of densities <strong>in</strong><strong>the</strong> texts. The difference between <strong>the</strong> highest and lowestdensities on <strong>the</strong> radio texts is 13.5%. On <strong>the</strong> exam textsthis difference is only 6.5%, so it seems <strong>the</strong>re is a tendencyfor <strong>the</strong> radio texts to have more variation <strong>in</strong> lexical densityand <strong>the</strong> exam texts to conform to an average density.Results: word frequencyTable 2 shows <strong>the</strong> top 50 words <strong>in</strong> radio texts, exam textsand, for comparison, <strong>the</strong> BNC spoken corpus and BNCwritten corpus.Figure 3:Lexical density of radioand exam textsPercentage lexical density45.0040.0035.0030.00Exam textRadio text25.0020.00Urban WildlifeJanet EllisCosta RicaJames DysonParakeetsPatricia RoutledgeVictoria BeckhamBonesLara HartTexts©UCLES 2008 – The contents of this publication may not be reproduced without <strong>the</strong> written permission of <strong>the</strong> copyright holder.
CAMBRIDGE ESOL : RESEARCH NOTES : ISSUE 32 / MAY 2008 | 5Table 2: Top 50 words <strong>in</strong> radio texts, exam texts, BNC spoken corpusand BNC written corpusRadio texts Exam texts BNC spoken BNC written1 <strong>the</strong> <strong>the</strong> <strong>the</strong> <strong>the</strong>2 and and I of3 a a you and4 I I and a5 you to it <strong>in</strong>6 to of a to7 it <strong>in</strong> ’s is8 of it to to9 that that of was10 ’s you that it11 was was n’t for12 <strong>in</strong> ’t <strong>in</strong> that13 ’t we we with14 but but is he15 we so do be16 is what <strong>the</strong>y on17 on is er I18 <strong>the</strong>y ’s was by19 for my yeah ’s20 she for have at21 have <strong>the</strong>y what you22 so about he are23 very on that had24 erm as to his25 at have but not26 know at for this27 well when erm have28 with all be but29 what me on from30 th<strong>in</strong>k do this which31 as like know she32 do people well <strong>the</strong>y33 this be so or34 <strong>the</strong>re from oh an35 all really got were36 he this ’ve as37 about well not we38 er know are <strong>the</strong>ir39 be <strong>the</strong>re if been40 not an with has41 had one no that42 ’ve with ’re will43 really had she would44 her if at her45 when don’ <strong>the</strong>re <strong>the</strong>re46 my th<strong>in</strong>k th<strong>in</strong>k n’t47 beca<strong>use</strong> did yes all48 yes very just can49 been are all if50 if can can whoIf we take a closer look at <strong>the</strong> top ten items, we can seethat all of <strong>the</strong> top ten words <strong>in</strong> all four corpora are functionwords. The same top ten words appear <strong>in</strong> <strong>the</strong> radio texts as<strong>in</strong> <strong>the</strong> BNC spoken corpus, although <strong>in</strong> a different order.These results <strong>in</strong>dicate that <strong>the</strong> corpus of radio texts may beas representative of spoken <strong>English</strong> as <strong>the</strong> BNC, andsuggests that although we may consider radio programmesto be a specialised genre, <strong>the</strong>y are not too narrowly def<strong>in</strong>edor restricted <strong>in</strong> language <strong>use</strong>.The top four items <strong>in</strong> <strong>the</strong> exam texts list are <strong>the</strong> same and<strong>in</strong> <strong>the</strong> same order as <strong>the</strong> radio texts list; overall n<strong>in</strong>e of <strong>the</strong>top ten words are <strong>the</strong> same <strong>in</strong> both lists. The exceptions are<strong>in</strong>, which is at position 7 <strong>in</strong> <strong>the</strong> exams texts list and 12 <strong>in</strong><strong>the</strong> radio list, and ‘s which is at position 10 <strong>in</strong> <strong>the</strong> radio listand 18 <strong>in</strong> <strong>the</strong> exam texts list.Lexical itemsThere are two lexical words <strong>in</strong> <strong>the</strong> top fifty of <strong>the</strong> BNCspoken corpus know and th<strong>in</strong>k, whereas <strong>the</strong>re are no lexicalwords <strong>in</strong> <strong>the</strong> top fifty of <strong>the</strong> BNC written corpus. There arefour lexical words <strong>in</strong> <strong>the</strong> top fifty <strong>in</strong> <strong>the</strong> radio texts, very,know, th<strong>in</strong>k and really. The fact that <strong>the</strong>re are more lexicalwords here than <strong>in</strong> <strong>the</strong> BNC top fifty can be accounted for by<strong>the</strong> smaller corpus size. Two of <strong>the</strong>se, th<strong>in</strong>k and know, arewords which are <strong>use</strong>d with<strong>in</strong> discourse markers: I th<strong>in</strong>k, youknow. They are also <strong>use</strong>d to vocalise mental processes,which was ano<strong>the</strong>r feature of spoken language that Chafe(1982) noted. Really and very are words which have someoverlap <strong>in</strong> mean<strong>in</strong>g so it is <strong>in</strong>terest<strong>in</strong>g that <strong>the</strong>y both appearhigh up on <strong>the</strong> radio texts wordlist.All four of <strong>the</strong> lexical words <strong>in</strong> <strong>the</strong> top fifty <strong>in</strong> <strong>the</strong> radiotexts also occur <strong>in</strong> <strong>the</strong> top fifty <strong>in</strong> <strong>the</strong> exam texts although<strong>the</strong> order is a little different. There are two o<strong>the</strong>r itemswhich occur <strong>in</strong> <strong>the</strong> top fifty exam texts but not <strong>in</strong> <strong>the</strong> topfifty radio texts: people and like.Filled pa<strong>use</strong>s, <strong>in</strong>terjections and discourse markersThese do not appear <strong>in</strong> <strong>the</strong> BNC written corpus as <strong>the</strong>y are apurely spoken phenomenon. Accord<strong>in</strong>gly, <strong>in</strong> <strong>the</strong> BNCspoken corpus: er, yeah, erm, well, so, oh, no and yesappeared. In <strong>the</strong> radio texts corpus yes, well, really, so,erm and er occurred. It is not possible to say from <strong>the</strong> listalone whe<strong>the</strong>r so, well and really are <strong>use</strong>d as discoursemarkers or what part of speech <strong>the</strong>y are, which could be<strong>in</strong>vestigated with concordances.It is <strong>in</strong>terest<strong>in</strong>g to note <strong>the</strong> absence of oh from <strong>the</strong> radiotexts top fifty. Leech et al. (2001) f<strong>in</strong>d that‘Most <strong>in</strong>terjections (e.g. oh, ah, hello) are much more characteristicof everyday conversation than of more formal/public “taskoriented” speech. However, <strong>the</strong> voiced hesitation fillers er and ermand <strong>the</strong> discourse markers mhm and um prove to be morecharacteristic of formal/public speech. We recognise er, erm andum as common thought pa<strong>use</strong>s <strong>in</strong> careful public speech. Mhm islikely to be a type of feedback <strong>in</strong> formal dialogues both <strong>in</strong>dicat<strong>in</strong>gunderstand<strong>in</strong>g and <strong>in</strong>vit<strong>in</strong>g cont<strong>in</strong>uation. In conversation, people<strong>use</strong> yeah and yes much more, and overwhelm<strong>in</strong>gly prefer <strong>the</strong><strong>in</strong>formal pronunciation yeah to yes. In formal speech, on <strong>the</strong> o<strong>the</strong>rhand, yes is slightly preferred to yeah.’The absence of oh and <strong>the</strong> presence of er and erm <strong>in</strong> <strong>the</strong>radio texts suggest that <strong>the</strong>y lie more <strong>in</strong> <strong>the</strong> area of formalor public speech than conversation. This is also backed upby <strong>the</strong> much greater <strong>use</strong> of yes than yeah <strong>in</strong> <strong>the</strong> radio textscorpus. In <strong>the</strong> exam texts corpus only so and well occurred,both of which also have <strong>use</strong>s o<strong>the</strong>r than as <strong>in</strong>terjections ordiscourse markers. There are no non-lexical filled pa<strong>use</strong>s <strong>in</strong><strong>the</strong> exam texts top fifty list. This shows that <strong>the</strong> exam textsare miss<strong>in</strong>g this element of natural speech.These results suggest that <strong>the</strong> radio texts corpus is tosome extent composed of more formal speech than <strong>the</strong> BNCspoken corpus. There are <strong>in</strong>dications that radio <strong>in</strong>terviewsare, as suspected, somewhere towards <strong>the</strong> literate end of<strong>the</strong> oral/literate cont<strong>in</strong>uum. However, <strong>the</strong>y are stillrepresentative of spoken language and do not showsimilarities with written language. The exam texts seem tomirror <strong>the</strong> radio texts fairly well, although <strong>the</strong>re is anoticeable absence of non-lexical filled pa<strong>use</strong>s.©UCLES 2008 – The contents of this publication may not be reproduced without <strong>the</strong> written permission of <strong>the</strong> copyright holder.