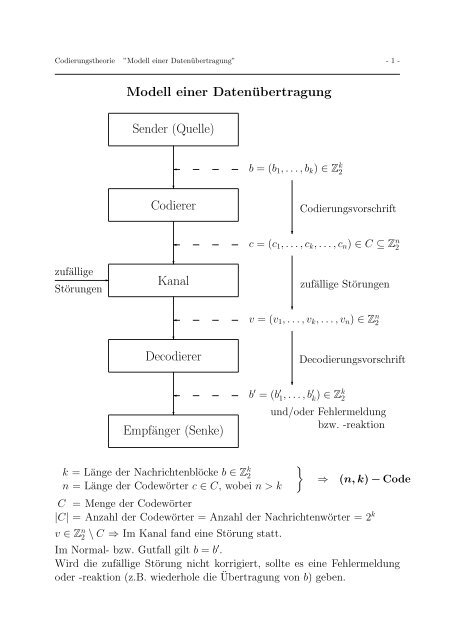
Modell einer Datenübertragung Sender (Quelle) Codierer Kanal ...
Modell einer Datenübertragung Sender (Quelle) Codierer Kanal ...
Modell einer Datenübertragung Sender (Quelle) Codierer Kanal ...

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
Codierungstheorie ”<strong>Modell</strong> <strong>einer</strong> <strong>Datenübertragung</strong>” - 1 -<br />
zufällige<br />
Störungen<br />
✲<br />
<strong>Modell</strong> <strong>einer</strong> <strong>Datenübertragung</strong><br />
<strong>Sender</strong> (<strong>Quelle</strong>)<br />
✛<br />
❄<br />
b = (b1, . . . , bk) ∈ Z k 2<br />
<strong>Codierer</strong> Codierungsvorschrift<br />
✛<br />
❄<br />
❄<br />
c = (c1, . . . , ck, . . . , cn) ∈ C ⊆ Z n 2<br />
<strong>Kanal</strong> zufällige Störungen<br />
✛<br />
❄<br />
❄<br />
v = (v1, . . . , vk, . . . , vn) ∈ Z n 2<br />
Decodierer Decodierungsvorschrift<br />
✛<br />
❄<br />
Empfänger (Senke)<br />
k = Länge der Nachrichtenblöcke b ∈ Z k 2<br />
n = Länge der Codewörter c ∈ C, wobei n > k<br />
❄<br />
b ′ = (b ′ 1, . . . , b ′ k ) ∈ Zk 2<br />
und/oder Fehlermeldung<br />
bzw. -reaktion<br />
�<br />
⇒ (n, k) − Code<br />
C = Menge der Codewörter<br />
|C| = Anzahl der Codewörter = Anzahl der Nachrichtenwörter = 2 k<br />
v ∈ Z n 2 \ C ⇒ Im <strong>Kanal</strong> fand eine Störung statt.<br />
Im Normal- bzw. Gutfall gilt b = b ′ .<br />
Wird die zufällige Störung nicht korrigiert, sollte es eine Fehlermeldung<br />
oder -reaktion (z.B. wiederhole die Übertragung von b) geben.
Codierungstheorie ”Bemerkungen” - 2 -<br />
<strong>Kanal</strong> = z.B. physikalische Leitung oder<br />
ein Speicher, aus dem die Zeichen nach <strong>einer</strong><br />
gewissen Zeit wieder abgerufen werden.<br />
Zufällige Störungen werden verursacht z.B. durch<br />
-) den sporadischen Einfluss von elektromagnetischen Feldern auf<br />
elektrische Datenleitungen,<br />
-) den α-Teilchen Beschuss von Speicherbausteinen,<br />
-) Kratzer oder Fingerabdrücke auf CDs oder DVDs.<br />
Beispiele für Anwendungsgebiete von Codierungsverfahren sind:<br />
-) <strong>Datenübertragung</strong> (Häufig werden verwendet:<br />
CRC-Codes = Cyclic Redundancy Check Codes)<br />
-) RAM-Chipsätze und L2-Cache ab Pentium-II, 300 Mhz<br />
(ECC = Error Correcting Code<br />
auf Basis eines binären Hamming-Codes.<br />
Literaturhinweis: c’t 12/1998, S. 232)<br />
-) CDs (CIRC = Cross Interleaved Read-Solomon Code)<br />
-) DVDs (RS-PC = Read-Solomon-Produkt-Code)<br />
Vereinfachung der Notation in diesem Kapitel:<br />
Statt (b1, . . . , bk) und (c1, . . . , cn) wird häufig einfacher b1 . . . bk<br />
bzw. c1 . . . cn geschrieben.<br />
Die Addition modulo 2 wird in diesem Kapitel mit ⊕ bezeichnet.<br />
Zwei Bitblöcke werden bzgl. ⊕ bitweise addiert, z.B.<br />
10011 ⊕ 11001 = 01010. (kein Übertrag !)<br />
Die Verknüpfung ⊕ ist selbstinvers, da z.B. gilt<br />
10011 ⊕ 10011 = 00000.
Codierungstheorie ”Definition des Hamming-Abstandes” - 3 -<br />
Definition 5.1<br />
Definition des Hamming-Abstandes<br />
a) Es seien a = a1a2 . . . an ∈ Z n 2 und b = b1b2 . . . bn ∈ Z n 2.<br />
Dann definieren<br />
i) d(a, b) = ”Anzahl der Bits, in denen sich<br />
a und b unterscheiden ”<br />
den Abstand von a und b,<br />
ii) w(a) = ”Anzahl der Einsen von a ”<br />
das Gewicht von a.<br />
b) Es sei C ⊆ Z n 2. Dann definiert<br />
d(C) = min{ d(a, b) : a, b ∈ C , a �= b }<br />
den Hamming-Abstand eines Codes (mit Codewörtern<br />
aus) C.<br />
Der Abstand und das Gewicht hängen wie folgt zusammen:<br />
Satz 5.1<br />
Für alle a = a1a2 . . . an ∈ Z n 2 und b = b1b2 . . . bn ∈ Z n 2 gilt:<br />
Beweis:<br />
d(a, b) = w(a ⊕ b).<br />
Wegen 0 ⊕ 0 = 0, 1 ⊕ 0 = 1, 0 ⊕ 1 = 1 und 1 ⊕ 1 = 0<br />
gilt für jeden Index i mit 1 ≤ i ≤ n:<br />
ai und bi sind verschieden ⇔ ai ⊕ bi = 1.
Codierungstheorie ”Das ML-Prinzip” - 4 -<br />
Das Maximum-Likelihood-Decodierungsprinzip<br />
Bei der Decodierung gehen wir von folgender Annahme aus:<br />
Annahme:<br />
Ein Zeichen in einem Bitblock wurde eher richtig als falsch empfangen.<br />
Somit ist es sinnvoll, (fehlerhafte) Bitblöcke nach folgendem Prinzip<br />
zu decodieren:<br />
Maximum-Likelihood-Decodierungsprinzip (ML-Prinzip):<br />
Wir ordnen einem empfangenen v ∈ Z n 2 das c ′ ∈ C zu, für das der<br />
Abstand d( v, c ′ ) über C minimal ist, d.h.<br />
d( v, c ′ ) = min{ d( v, c) : c ∈ C },<br />
und decodieren dann c ′ ∈ C.<br />
Ist c ′ ∈ C nicht eindeutig, so decodieren wir nicht (und geben z.B.<br />
stattdessen eine Fehlermeldung aus) oder wir legen uns auf eine<br />
Möglichkeit fest (evtl. nach anderen Kriterien).<br />
Unter der Annahme des ML-Prinzips bestimmt der Hamming-<br />
Abstand die Anzahl der Fehler, die (mit Sicherheit) korrigiert bzw.<br />
erkannt werden können:<br />
Satz 5.2<br />
Es sei ein Code gegeben, dessen Codewörter C den Hamming-Abstand<br />
d haben.<br />
a) Ist d = 2m + 1 ungerade, so können m Fehler nach dem<br />
ML-Prinzip eindeutig korrigiert werden.<br />
b) Ist d = 2m + 2 gerade, so können m Fehler nach dem ML-<br />
Prinzip eindeutig korrigiert werden und zusätzlich Bitblöcke<br />
mit m + 1 Fehlern erkannt werden.
Codierungstheorie ”Lineare Codes” - 5 -<br />
Lineare Codes<br />
Definition 5.2<br />
Lässt sich die Codierungsvorschrift eines (n, k)−Codes durch eine<br />
k × n−Matrix G beschreiben,<br />
d.h. gilt für alle Nachrichtenblöcke b und ihre dazugehörigen Codeworte<br />
c die Beziehung c = b · G bzw. ausführlich<br />
⎛<br />
⎞<br />
g11 g12 · · · g1k · · · g1n<br />
(c1, . . . , ck, . . . , cn)<br />
� �� �<br />
c<br />
= (b1, . . . , bk) ·<br />
� �� �<br />
b<br />
⎜<br />
⎝<br />
g21 g22 · · · g2k · · · g2n<br />
· · · · · · · · · · · · · · · · · ·<br />
gk1 gk2 · · · gkk · · · gkn<br />
⎟<br />
⎟,<br />
⎠<br />
� �� �<br />
G<br />
so heißt G Generatormatrix dieses Codes und der Code wird<br />
als linearer Code bezeichnet.<br />
Die Codewörter C eines von <strong>einer</strong> Generatormatrix G erzeugten<br />
Codes haben folgende Eigenschaft:<br />
(5.1) c, f ∈ C ⇒ c ⊕ f ∈ C,<br />
denn:<br />
c, f ∈ C ⇒ es existieren b, a ∈ Z k 2 mit c = b · G und f = a · G<br />
⇒ c ⊕ f = b · G ⊕ a · G = (b ⊕ a) · G ∈ C<br />
Da außerdem (0, . . . , 0)<br />
� �� �<br />
n−mal<br />
= (0, . . . , 0) · G ∈ C gilt, folgt:<br />
� �� �<br />
k−mal<br />
Satz 5.3<br />
Die Codewörter C eines linearen (n, k)−Codes bilden eine<br />
Untergruppe der Gruppe (Z n 2, ⊕).
Codierungstheorie ”Der Hamming-Abstand eines linearen Codes” - 6 -<br />
Der Hamming-Abstand eines linearen Codes<br />
Satz 5.4<br />
Für einen linearen Code mit Codewörtern C gilt<br />
Beweis:<br />
d(C) = min{ w(c) : c ∈ C , c �= 0 }<br />
d(a, b) = w(a ⊕ b) gemäß Satz 5.1 und<br />
{ a ⊕ b : a, b ∈ C, a �= b }<br />
� �� �<br />
M1<br />
= { c : c ∈ C, c �= 0 }<br />
� �� �<br />
Diese Mengengleichheit ergibt sich aus folgenden Überlegungen:<br />
”⊇”: c ∈ M2 ⇒ c = c<br />
����<br />
=a<br />
⊕ ���� 0 ∈ M1<br />
=b<br />
Dies gilt, da C linear ist und somit 0 ∈ C.<br />
Außerdem ist ���� c �=<br />
=a<br />
0 , da c ∈ M2.<br />
����<br />
=b<br />
”⊆”: a ⊕ b ∈ M1 ⇒ c = a ⊕ b ∈ M2<br />
Dies gilt, da C linear ist und somit c = a ⊕ b ∈ C.<br />
Außerdem ist c = a ⊕ b �= 0, da a �= b.<br />
Insgesamt folgt:<br />
d(C) = min{ d(a, b) : a, b ∈ C , a �= b }<br />
= min{ w(a ⊕ b) : a, b ∈ C , a �= b } (Satz 5.1)<br />
= min{ w(c) : c ∈ C , c �= 0 } (M1 = M2)<br />
M2
Codierungstheorie ”Die Kontrollmatrix” - 7 -<br />
Die Kontrollmatrix<br />
Definition 5.3<br />
Eine (n−k)×n−Matrix H heißt Kontrollmatrix eines linearen<br />
(n, k)−Codes mit Codewörtern C, falls für alle v ∈ Zn 2 gilt:<br />
v ∈ C ⇔ H · vT ⎛ ⎞ ⎫<br />
0.<br />
⎬<br />
= 0 = ⎝ ⎠ (n − k) − mal<br />
⎭<br />
0<br />
Für lineare Codes, die eine spezielle Generatormatrix haben, kann<br />
man sehr leicht eine Kontrollmatrix finden.<br />
Satz 5.5<br />
Ein linearer (n, k)−Code mit Codewörtern C habe die Generatormatrix<br />
G = (Ek | A). Dann ist die Matrix<br />
H = (A T | En−k)<br />
eine Kontrollmatrix dieses Codes.<br />
Beweisidee:<br />
Da jedes v ∈ C eine Linearkombination von Zeilenvektoren der Generatormatrix<br />
G ist, reicht es H·v T = 0 für die Zeilenvektoren von G nachzuweisen.<br />
Wir zeigen dies exemplarisch für den 1. Zeilenvektor von G, d.h.<br />
v = � �<br />
1 0 · · · 0 a11 a12 · · · a1(n−k) Es gilt:<br />
⎛<br />
1<br />
⎞<br />
⎛<br />
a11 a21 · · · ak1<br />
⎜ a12 a22 · · · ak2<br />
⎜<br />
⎝ . . . .<br />
a1(n−k) a2(n−k) · · · ak(n−k) � ��<br />
=H<br />
⎜<br />
⎞ ⎜ 0.<br />
⎟ ⎛<br />
⎞<br />
1 0 · · · 0 ⎜ ⎟<br />
⎜ ⎟ a11 ⊕ a11<br />
0 1 · · · 0<br />
⎟ ⎜ ⎟ ⎜<br />
⎟ ⎜ 0 ⎟ ⎜ a12 ⊕<br />
⎟<br />
a12 ⎟<br />
⎟ · ⎜ ⎟ = ⎜<br />
⎟<br />
. . . . ⎠ ⎜ a11 ⎟ ⎝ . ⎠<br />
⎜ ⎟<br />
0 0 · · · 1 ⎜ a12 ⎟<br />
� ⎜ ⎟<br />
a1(n−k) ⊕ a1(n−k) ⎝ . ⎠ � �� �<br />
=0<br />
a1(n−k)
Codierungstheorie ”Nebenklassen von Codewörtern” - 8 -<br />
Nebenklassen von Codewörtern<br />
Für den Rest dieses Kapitels ist ein linearer (n, k)−Code mit<br />
Codewörtern C und (fester) Kontrollmatrix H gegeben.<br />
Satz 5.3 ⇒ (C, ⊕) ist eine Untergruppe der Gruppe (Z n 2, ⊕)<br />
Definition 4.6 ⇒ a ⊕ C = {a ⊕ c : c ∈ C} heißt<br />
(Links-)Nebenklasse von a bzgl. C<br />
Da ⊕ kommutativ ist, gilt a ⊕ C = C ⊕ a für alle a ∈ Z n 2 und<br />
daher sprechen wir nur von Nebenklassen.<br />
Satz 4.5, b) ⇒ Nebenklassen sind entweder<br />
disjunkt oder identisch<br />
Satz 4.5, c) ⇒ |a ⊕ C| = |C| für alle a ∈ C<br />
Satz 4.6 ⇒ I = Anzahl der Nebenklassen = |Zn 2|<br />
|C|<br />
2n<br />
= = 2n−k<br />
2k Somit kann Z n 2 in I = 2 n−k gleich große Nebenklassen zerlegt<br />
werden:<br />
(5.2) Z n 2 = (a1 ⊕ C) ∪ (a2 ⊕ C) ∪ . . . (aI ⊕ C)<br />
a1 ⊕ C<br />
(= C)<br />
e�<br />
v�<br />
a2 ⊕ C<br />
a4 ⊕ C<br />
a3 ⊕ C<br />
Venn-Diagramm zur Zerlegung von Z n 2 in 4 gleich große Nebenklassen<br />
Z n 2
Codierungstheorie ”Nebenklassen und Fehlervektoren” - 9 -<br />
Nebenklassen und Fehlervektoren<br />
Annahme:<br />
v ∈ Z n 2 wurde (evtl. verfälscht) empfangen.<br />
Wegen (5.2) existiert dann ein ai mit v ∈ ai ⊕ C, d.h.<br />
(5.3) v = ai ⊕ ˜c für ein ˜c ∈ C.<br />
Sei c ∈ C das ursprüngliche Codewort und e ∈ Z n 2 der bei der<br />
Übertragung aufgetretene Fehlervektor. Dann gilt:<br />
(5.4) v = e ⊕ c<br />
Zusammen ergeben (5.3) und (5.4):<br />
e ⊕ c = v = ai ⊕ ˜c<br />
⇒ e = e ⊕ c ⊕ c<br />
� �� �<br />
=0<br />
= ai ⊕ ˜c ⊕ c<br />
� �� �<br />
∈C<br />
∈ ai ⊕ C<br />
Somit haben wir folgendes Resultat gezeigt:<br />
Satz 5.6<br />
Der Fehlervektor e eines empfangenen Bitblocks v ∈ ai ⊕ C liegt<br />
in genau derselben Nebenklasse ai ⊕ C, in der v liegt.<br />
Dieser Satz und das ML-Decodierungsprinzip ergeben folgende<br />
Decodierungsregel (Variante mit Nebenklassenbestimmung)<br />
Bestimme diejenige Nebenklasse ai ⊕ C, für die v ∈ ai ⊕ C gilt.<br />
Wähle dann f ∈ ai ⊕ C mit minimalem Gewicht. Decodiere v<br />
durch c = f ⊕ v.<br />
Begründung, dass diese Regel sinnvoll ist:<br />
Nach dem ML-Prinzip gilt mit hoher Wahrscheinlichkeit f = e<br />
und damit folgt wegen (5.4):<br />
f ⊕ v = e ⊕ v = e ⊕ e ⊕ c = c.
Codierungstheorie ”Das Standardfeld” - 10 -<br />
Das Standardfeld<br />
Die Decodierung nach der Decodierungsregel der vorherigen Seite<br />
lässt sich mit Hilfe eines Standardfeldes durchführen. Dazu sei<br />
C = {0, c1, c2, c3, . . .}<br />
die Menge der Codewörter und für jede Nebenklasse<br />
ai ⊕ C , wobei 1 ≤ i ≤ I = 2 n−k<br />
gelte die Darstellung, dass ai ein Element mit minimalem Gewicht<br />
in dieser Nebenklasse ist. ai heißt der Klassenanführer<br />
dieser Nebenklasse.<br />
Gibt es mehrere Möglichkeiten für den Klassenanführer, so muss<br />
der Klassenanführer nach zusätzlichen Kriterien oder willkürlich<br />
aus diesen Möglichkeiten ausgewählt werden.<br />
Das Standardfeld hat dann folgende Darstellung:<br />
a1 = 0 c1 c2 c3 . . . C = a1 ⊕ C<br />
a2 a2 ⊕ c1 a2 ⊕ c2 a2 ⊕ c3 . . . a2 ⊕ C<br />
a3 a3 ⊕ c1 a3 ⊕ c2 a3 ⊕ c3 . . . a3 ⊕ C<br />
. . . . . . . . . . . . . . .<br />
aI aI ⊕ c1 aI ⊕ c2 aI ⊕ c3 . . . aI ⊕ C<br />
Ein Vektor v = ai ⊕ cj ∈ ai ⊕ C wird im Standardfeld durch den<br />
Spaltenkopf ai ⊕ v = ai ⊕ ai ⊕ cj = cj decodiert.<br />
Satz 5.7<br />
Die Fehlervektoren, die mit einem Standardfeld korrigiert werden,<br />
sind genau die Klassenanführer.
Codierungstheorie ”Das Syndrom” - 11 -<br />
Das Syndrom<br />
Definition 5.4<br />
Gegeben sei ein linearer (n, k)−Code mit Kontrollmatrix H. Dann<br />
ist das Syndron s eines Vektors v ∈ Z n 2 definiert durch<br />
Satz 5.8<br />
s = H · v T .<br />
a) Enthält v ∈ Z n 2 genau an den Stellen i, j, k, . . . Fehler, so gilt<br />
für das Syndrom<br />
s = hi ⊕ hj ⊕ hk ⊕ . . .,<br />
wobei hi, hj, hk, . . . die i-te, j-te, k-te, . . . Spalte der Matrix<br />
H sind.<br />
b) Zwei Vektoren v1, v2 ∈ Z n 2 liegen genau dann in derselben<br />
Nebenklasse von C, wenn sie dasselbe Syndrom haben.<br />
Beweis zu b):<br />
a) v1, v2 liegen in derselben Nebenklasse<br />
⇒ es exist ein ai mit v1, v2 ∈ ai ⊕ C<br />
⇒ es exist c1, c2 ∈ C mit v1 = ai ⊕ c1 und v2 = ai ⊕ c2<br />
⇒ s1 = Hv T 1 = Ha T i ⊕ HcT 1<br />
����<br />
=0<br />
= HaT i = HaTi ⊕ HcT ���� 2 = Hv<br />
=0<br />
T 2 = s2<br />
b) v1, v2 haben dasselbe Syndrom, d.h. Hv T 1 = Hv T 2<br />
⇒ 0 = Hv T 2 ⊕ Hv T 1 = H(v2 ⊕ v1) T ⇒ v2 ⊕ v1 ∈ C<br />
Zu zeigen: v1 ∈ ai ⊕ C ⇒ v2 ∈ ai ⊕ C<br />
denn: v1 ∈ ai ⊕ C ⇒ es exist ein c1 ∈ C mit v1 = ai ⊕ c1<br />
∈C<br />
���� � �� �<br />
⇒ v2 = v1 ⊕ (v2 ⊕ v1) = ai ⊕ c1 ⊕ (v2 ⊕ v1) ∈ ai ⊕ C<br />
� �� �<br />
∈C<br />
∈C
Codierungstheorie ”Die Syndromtabelle” - 12 -<br />
Die Syndromtabelle<br />
Wegen Satz 5.8, b) kann man Nebenklassen durch ihre Syndrome<br />
charakterisieren.<br />
Zur Decodierung mittels Syndromen benötigt man daher anstelle<br />
des Standardfeldes lediglich eine Tabelle, genannt Syndromtabelle,<br />
in der jedem Syndrom der entsprechende Klassenanführer<br />
zugeordnet wird.<br />
Wir erhalten somit folgende<br />
Decodierungsregel (Variante mit Syndromberechnung)<br />
Berechne zu v das Syndrom s = H · v T . Entnehme dann der Syndromtabelle<br />
den zu s gehörigen Klassenanführer ai. Decodiere v<br />
durch c = ai ⊕ v.
Codierungstheorie ”Anhang 1: Der (7,4)-Hamming-Code” - 13 -<br />
Codierungsvorschrift:<br />
Der (7,4)-Hamming-Code<br />
b1 b2 b3 b4 ↦−→ c1 c2 c3 c4 c5 c6 c7<br />
mit c1 = b1, c2 = b2, c3 = b3, c4 = b4 und folgenden 3 Paritätsgleichungen:<br />
c5 = b1 ⊕ b2 ⊕ b3,<br />
Decodierungsvorschrift:<br />
c6 = b1 ⊕ b2 ⊕ b4,<br />
c7 = b1 ⊕ b3 ⊕ b4.<br />
v = v1 v2 v3 v4 v5 v6 v7 wurde empfangen. Aus der Codierungsvorschrift<br />
ergeben sich 3 Kontrollgleichungen:<br />
s1 = v1 ⊕ v2 ⊕ v3 ⊕ v5,<br />
s2 = v1 ⊕ v2 ⊕ v4 ⊕ v6,<br />
s3 = v1 ⊕ v3 ⊕ v4 ⊕ v7.<br />
Diese Kontrollgleichungen liefern folgende Syndromtabelle:<br />
s1 s2 s3<br />
kein Fehler 0 0 0<br />
1. Stelle falsch 1 1 1<br />
2. Stelle falsch 1 1 0<br />
3. Stelle falsch 1 0 1<br />
4. Stelle falsch 0 1 1<br />
5. Stelle falsch 1 0 0<br />
6. Stelle falsch 0 1 0<br />
7. Stelle falsch 0 0 1