

Betriebssysteme II - Betriebssysteme und verteilte Systeme
Betriebssysteme II - Betriebssysteme und verteilte Systeme
Betriebssysteme II - Betriebssysteme und verteilte Systeme

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
2.2 (Shared-Memory-)Multiprozessoren ...<br />
2.2.5 Besonderheiten bei BSen für CC-NUMA <strong>Systeme</strong><br />
➥ Speicherverwaltung<br />
<strong>Betriebssysteme</strong> <strong>II</strong><br />
SS 2007<br />
Roland Wismüller, Univ. Siegen<br />
roland.wismueller@uni-siegen.de<br />
Tel.: 0271/740-4050, Büro: H-B 8404<br />
Stand: 8. Mai 2007<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> i<br />
➥ Zuteilung von Kacheln auf möglichst nahem Knoten<br />
➥ Auslagerung von Seiten pro Speicherzone (Knoten)<br />
➥ jeder Knoten lagert nur lokale Seiten aus<br />
➥ Scheduling mit hoher Prozessor-Affinität<br />
➥ Prozeß/Thread möglichst nahe bei seinen Daten starten<br />
➥ Processor Pinning: feste Zuordnung einer CPU<br />
➥ Teilweise statische Ressourcenzuteilung möglich<br />
➥ Threads <strong>und</strong> Bereichen des log. Adreßraums können bei<br />
Programmstart (über Konfigurationsdatei) feste Knoten<br />
zugeordnet werden<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 138<br />
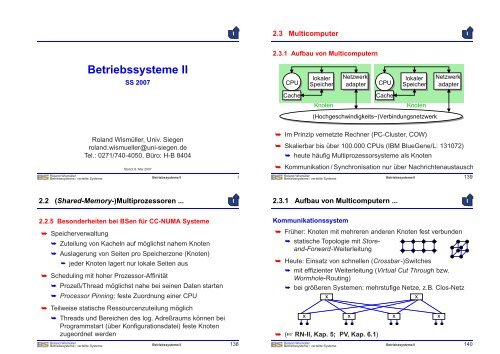
2.3 Multicomputer<br />
2.3.1 Aufbau von Multicomputern<br />
CPU<br />
Cache<br />
lokaler Netzwerk<br />
lokaler<br />
Speicher adapter CPU Speicher<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 139<br />
2.3.1 Aufbau von Multicomputern ...<br />
Kommunikationssystem<br />
➥ Früher: Knoten mit mehreren anderen Knoten fest verb<strong>und</strong>en<br />
➥ statische Topologie mit Storeand-Forward-Weiterleitung<br />
➥ Heute: Einsatz von schnellen (Crossbar-)Switches<br />
➥ mit effizienter Weiterleitung (Virtual Cut Through bzw.<br />
Wormhole-Routing)<br />
➥ bei größeren <strong>Systeme</strong>n: mehrstufige Netze, z.B. Clos-Netz<br />
x<br />
x<br />
x x x x<br />
➥ (☞ RN-<strong>II</strong>, Kap. 5; PV, Kap. 6.1)<br />
Cache<br />
Knoten Knoten<br />
(Hochgeschwindigkeits−)Verbindungsnetzwerk<br />
➥ Im Prinzip vernetzte Rechner (PC-Cluster, COW)<br />
Netzwerk<br />
adapter<br />
➥ Skalierbar bis über 100.000 CPUs (IBM BlueGene/L: 131072)<br />
➥ heute häufig Multiprozessorsysteme als Knoten<br />
➥ Kommunikation / Synchronisation nur über Nachrichtenaustausch<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 140
2.3 Multicomputer ...<br />
2.3.2 Low-Level Kommunikationssoftware<br />
➥ Klassisch: Netzwerkkarte im BS-Adreßraum<br />
➥ Senden/Empfangen muß über Systemaufruf erfolgen<br />
➥ BS muß zwischen Prozeß- <strong>und</strong> BS-Adreßraum kopieren<br />
➥ Bei modernen Multicomputern: Netzwerkkarte wird in den<br />
Prozeßadreßraum abgebildet (☞ RN-<strong>II</strong>, 5.3.3)<br />
➥ Prozeß kann Auftrag direkt an Netzwerkkarte geben<br />
➥ Daten per DMA aus/in Prozeßadreßraum gelesen/geschrieben<br />
➥ Problem: DMA nutzt physische Adressen ⇒ Seiten<br />
müssen im Speicher verriegelt werden<br />
➥ einfachster Fall: nur ein Prozeß die Netzwerkkarte nutzen<br />
➥ eigene Netzwerkkarte für BS-Kommunikation<br />
➥ oder: Netzwerkkarte mit VIA (Virtual Interface Architecture)<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 141<br />
2.3 Multicomputer ...<br />
2.3.3 Kommunikation auf Benutzerebene<br />
➥ Nachrichtenversand mit send() / receive() (☞ BS-I, 3.2.2)<br />
➥ blockierendes Senden (synchron)<br />
➥ erlaubt direktes Kopieren in Speicher des Empfängers<br />
➥ aber: Sender wird blockiert, bis Empfänger bereit ist<br />
➥ nicht-blockierendes Senden (asynchron)<br />
➥ Puffer darf nicht verändert werden, bis Nachricht gesendet<br />
➥ ggf. Kopie in Zwischenpuffer beim Sender oder Empfänger<br />
➥ oder: copy on write<br />
➥ Seiten des Sendepuffers schreibschützen<br />
➥ erst bei Schreibzugriff: Kopie der Seite erstellen<br />
➥ Empfang blockierend <strong>und</strong> nicht-blockierend (Polling)<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 142<br />
2.3.3 Kommunikation auf Benutzerebene ...<br />
2.3.3 Kommunikation auf Benutzerebene...<br />
➥ Pop-Up-Threads: bei Eingang der Nachricht wird neuer Thread<br />
im Empfängerprozeß erzeugt<br />
➥ führt vordefinierte Prozedur aus, die die Nachricht behandelt<br />
➥ Active Messages: Empfängercode wird direkt im Interrupt-<br />
Handler aufgerufen<br />
➥ Nachricht entählt Adresse des Handlers<br />
➥ Handler liest Nachricht direkt aus der Netzwerkkarte <strong>und</strong><br />
bearbeitet sie<br />
➥ nur möglich, wenn Empfänger dem Sender vertrauen kann<br />
➥ Remote Procedure Call (RPC) (☞ BS-I, 3.2.4)<br />
➥ Gemeinsamer Speicher: (Software) Distributed Shared Memory<br />
➥ siehe Kap. 3<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 143<br />
2.3 Multicomputer ...<br />
2.3.4 Multicomputer-Scheduling <strong>und</strong> Lastverteilung<br />
➥ Jeder Knoten hat seinen eigenen Speicher / sein eigenes BS<br />
➥ daher: jeder Knoten hat seine festen Prozesse<br />
➥ beliebige Scheduling-Verfahren möglich<br />
➥ Scheduling auf globaler Ebene<br />
➥ oft Space Sharing: Knoten werden exklusiv an eine<br />
Anwendung zugeteilt<br />
➥ auch Gang Scheduling ist möglich / sinnvoll<br />
➥ erfordert Synchronisation aller Knoten<br />
➥ wichtigste Frage: welchem Knoten wird ein neuer Prozeß<br />
zugewiesen (Processor Allocation)?<br />
➥ Ziele: Lastausgleich, Minimierung der Kommunikation, ...<br />
➥ (i.a. realisiert in systemnaher Software bzw. Middleware)<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 144
2.3.4 Multicomputer-Scheduling <strong>und</strong> Lastverteilung ...<br />
(Animierte Folie)<br />
Lastverteilung durch Graphpartitionierung<br />
= 30<br />
➥ Gegeben: Prozeßsystem mit<br />
➥ CPU- / Speicheranforderungen<br />
➥ Angabe der Kommunikationslast<br />
zwischen je 2 Prozessen<br />
i.a. dargestellt als Graph<br />
A<br />
6<br />
G<br />
3<br />
2<br />
E<br />
3<br />
1<br />
2<br />
B C<br />
3<br />
1<br />
2 8 D<br />
F<br />
5<br />
4 5 4<br />
1<br />
4 2<br />
H I<br />
2 3<br />
➥ Gesucht: Aufteilung (Partitionierung) des Graphen so, daß<br />
➥ CPU- <strong>und</strong> Speicheranforderungen für jeden Knoten erfüllt<br />
➥ Partitionen in etwa gleich groß (Lastausgleich)<br />
➥ Gewichte-Summe der geschnittenen Kanten minimal<br />
➥ d.h. möglichst wenig Kommunikation zwischen Knoten<br />
➥ NP-vollständig, daher viele heuristische Verfahren<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 145<br />
2.3.4 Multicomputer-Scheduling <strong>und</strong> Lastverteilung ...<br />
Weitere Verfahren zur Lastverteilung<br />
➥ Senderinitiierte Lastverteilung<br />
➥ Prozeß i.a. auf eigenem Knoten gestartet<br />
➥ falls Knoten überlastet: Last anderer Knoten ermitteln <strong>und</strong><br />
Prozess auf niedrig belastetem Knoten starten<br />
➥ z.B. frage zufällig ausgewählten Knoten nach Last, sende<br />
Prozeß falls Last ≤ Schwellwert, sonst: nächster Knoten<br />
➥ Nachteil: zusätzliche Arbeit für ohnehin überlasteten Knoten!<br />
➥ Empfängerinitiierte Lastverteilung<br />
➥ bei Terminierung eines Prozesses: prüfe ob noch genügend<br />
Arbeit (Prozesse) vorhanden sind<br />
➥ falls nicht: frage andere Knoten nach Arbeit<br />
➥ Bieter-Algorithmus nach dem Vorbild der Ökonomie<br />
Roland Wismüller<br />
<strong>Betriebssysteme</strong> / <strong>verteilte</strong> <strong>Systeme</strong> <strong>Betriebssysteme</strong> <strong>II</strong> 146













