

Verteilte Auswertung von RDF-Graphen mit MapReduce und ...
Verteilte Auswertung von RDF-Graphen mit MapReduce und ...
Verteilte Auswertung von RDF-Graphen mit MapReduce und ...

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
4.2 Auswerten der Anfragen<br />
4.2 Auswerten der Anfragen<br />
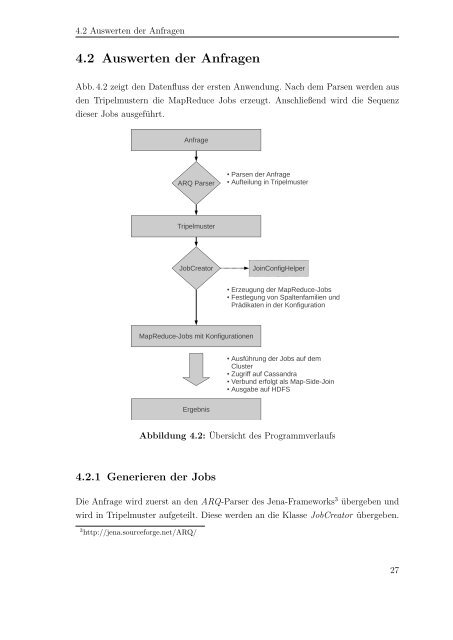
Abb. 4.2 zeigt den Datenfluss der ersten Anwendung. Nach dem Parsen werden aus<br />
den Tripelmustern die <strong>MapReduce</strong> Jobs erzeugt. Anschließend wird die Sequenz<br />
dieser Jobs ausgeführt.<br />
Anfrage<br />
ARQ Parser<br />
●<br />
Parsen der Anfrage<br />
●<br />
Aufteilung in Tripelmuster<br />
Tripelmuster<br />
JobCreator<br />
JoinConfigHelper<br />
●<br />
Erzeugung der <strong>MapReduce</strong>-Jobs<br />
●<br />
Festlegung <strong>von</strong> Spaltenfamilien <strong>und</strong><br />
Prädikaten in der Konfiguration<br />
<strong>MapReduce</strong>-Jobs <strong>mit</strong> Konfigurationen<br />
●<br />
Ausführung der Jobs auf dem<br />
Cluster<br />
●<br />
Zugriff auf Cassandra<br />
●<br />
Verb<strong>und</strong> erfolgt als Map-Side-Join<br />
●<br />
Ausgabe auf HDFS<br />
Ergebnis<br />
Abbildung 4.2: Übersicht des Programmverlaufs<br />
4.2.1 Generieren der Jobs<br />
Die Anfrage wird zuerst an den ARQ-Parser des Jena-Frameworks 3 übergeben <strong>und</strong><br />
wird in Tripelmuster aufgeteilt. Diese werden an die Klasse JobCreator übergeben.<br />
3 http://jena.sourceforge.net/ARQ/<br />
27