

Verteilte Auswertung von RDF-Graphen mit MapReduce und ...
Verteilte Auswertung von RDF-Graphen mit MapReduce und ...
Verteilte Auswertung von RDF-Graphen mit MapReduce und ...

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
4.2 Auswerten der Anfragen<br />
Abb. 4.3 veranschaulicht diesen Sachverhalt in einem Cluster <strong>mit</strong> 9 Knoten. 8 der 9<br />
Knoten sind nach wenigen Sek<strong>und</strong>en fertig, während der letzte Knoten sehr lange<br />
rechnet. Der Kreis in der Grafik verdeutlicht, dass der 9. Map-Task noch nicht<br />
fertiggestellt worden ist. Bei der <strong>Auswertung</strong> der Anfrage Q3A auf 25 Millionen<br />
Tripel dauerte der Verb<strong>und</strong> 39 Minuten, da eine Teilung des Rechenaufwands nicht<br />
stattfand.<br />
Beim Zugriff auf Cassandra wird die Spaltenfamilie so gewählt, dass der Zeilenschlüssel<br />
festgelegt werden kann. Ändert man das Verfahren so ab, dass der Zeilenschlüssel<br />
nicht festgelegt wird <strong>und</strong> so<strong>mit</strong> eine andere Spaltenfamilie festgelegt wird, werden alle<br />
Knoten am Verb<strong>und</strong> beteiligt. Bei dem obigen Beispiel wird auf die Spaltenfamilie<br />
„OSP“ zugegriffen. Es wird ein SlicePredicate <strong>mit</strong> dem Namen „ex:Thomas“ festgelegt<br />
<strong>und</strong> außerdem ein Subspaltenname „ex:userknows“. Es wird auf allen Knoten<br />
über alle Objekte iteriert.<br />
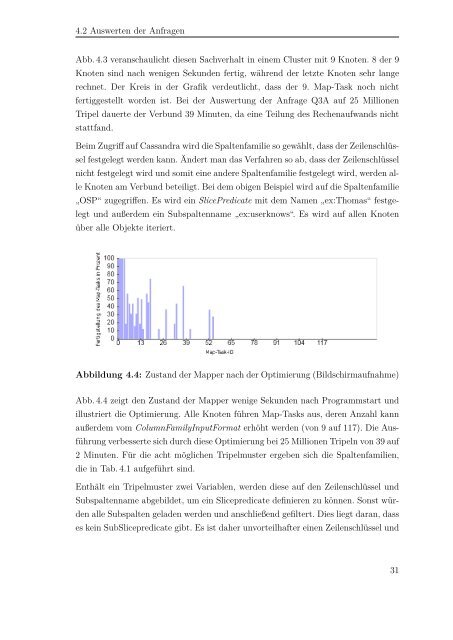
Abbildung 4.4: Zustand der Mapper nach der Optimierung (Bildschirmaufnahme)<br />
Abb. 4.4 zeigt den Zustand der Mapper wenige Sek<strong>und</strong>en nach Programmstart <strong>und</strong><br />
illustriert die Optimierung. Alle Knoten führen Map-Tasks aus, deren Anzahl kann<br />
außerdem vom ColumnFamilyInputFormat erhöht werden (<strong>von</strong> 9 auf 117). Die Ausführung<br />
verbesserte sich durch diese Optimierung bei 25 Millionen Tripeln <strong>von</strong> 39 auf<br />
2 Minuten. Für die acht möglichen Tripelmuster ergeben sich die Spaltenfamilien,<br />
die in Tab. 4.1 aufgeführt sind.<br />
Enthält ein Tripelmuster zwei Variablen, werden diese auf den Zeilenschlüssel <strong>und</strong><br />
Subspaltenname abgebildet, um ein Slicepredicate definieren zu können. Sonst würden<br />
alle Subspalten geladen werden <strong>und</strong> anschließend gefiltert. Dies liegt daran, dass<br />
es kein SubSlicepredicate gibt. Es ist daher unvorteilhafter einen Zeilenschlüssel <strong>und</strong><br />
31