

least squares theory and design of optimal noise shaping filters
least squares theory and design of optimal noise shaping filters
least squares theory and design of optimal noise shaping filters

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
LEAST SQUARES THEORY AND DESIGN OF<br />
OPTIMAL NOISE SHAPING FILTERS<br />
WERNER VERHELST AND DRETEN DE KONING<br />
KULeuven - ESAT, Kasteelpark Arenberg 10, B-3001 Leuven, Belgium<br />
VUB, Faculty <strong>of</strong> Applied Science - ETRO, Pleinlaan 2, B-1050 Brussels, Belgium<br />
Correspondence should be addressed to Werner.Verhelst@esat.kuleuven.ac.be<br />
Signal requantization to reduce the word-length <strong>of</strong> an audio stream introduces distortions. Noise <strong>shaping</strong> can be applied<br />
in combination with a psychoacoustic model in order to make requantization distortions minimally audible. The psychoacoustically<br />
<strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong> curve depends on the time-varying characteristics <strong>of</strong> the input signal. Therefore,<br />
the <strong>noise</strong> <strong>shaping</strong> filter coefficients are to be computed <strong>and</strong> updated on a regular basis. In this paper, we present a new<br />
<strong>theory</strong> for <strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong> <strong>of</strong> audio signals. This <strong>theory</strong> is based on a Least Squares interpretation <strong>of</strong> the problem.<br />
It provides a shorter <strong>and</strong> more straightforward pro<strong>of</strong> <strong>of</strong> known properties <strong>of</strong> dithered <strong>and</strong> non-dithered <strong>noise</strong> <strong>shaping</strong>.<br />
Moreover, <strong>and</strong> in contrast with the st<strong>and</strong>ard <strong>theory</strong>, this new approach does show how <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> that attain the<br />
theoretical optimum can be <strong>design</strong>ed in practice. Experimental results illustrate the proposed method. The link with two<br />
popular <strong>noise</strong> <strong>shaping</strong> requantization techniques (F-weighted <strong>noise</strong> <strong>shaping</strong> <strong>and</strong> Super Bit Mapping) is also discussed.<br />
INTRODUCTION<br />
Signal requantization is applied in digital audio systems<br />
whenever the word-length <strong>of</strong> audio samples needs to be<br />
reduced. This is the case for instance when an audio signal<br />
has to be stored on a CD <strong>and</strong> was originally produced<br />
at the output <strong>of</strong> a digital audio system that operates with<br />
more than 16 bit precision.<br />
When audio is produced synthetically, the precision <strong>of</strong><br />
the sampled data that is generated is <strong>of</strong>ten extremely high<br />
(basically, it can be as large as the precision <strong>of</strong> the computing<br />
equipment used to generate the signal). To reduce<br />
the required storage room, it will be likely that the data<br />
will have to be requantized to a shorter wordlength (typically<br />
24 or 16 bit) at some point in the audio chain.<br />
In entertainment audio, <strong>and</strong> especially in gaming, requantization<br />
to 8 bit or 12 bit could be an economically interesting<br />
alternative to other forms <strong>of</strong> data compression<br />
because requantized data can be send directly to the D/A<br />
converter, while encoded data needs to be decoded first.<br />
Since decoding can be computational intensive, this could<br />
mean an important advantage for using requantized data<br />
in cheaply prized gaming devices.<br />
Signal requantization inevitably introduces an error, which<br />
can cause two types <strong>of</strong> audible problems. The first is a<br />
background <strong>noise</strong> that may be audible by itself. It can<br />
usually occur when (part) <strong>of</strong> the error signal is uncorrelated<br />
with the original audio. When the error is correlated<br />
with the signal, linear or nonlinear distortions may cause<br />
alterations in the perceived quality <strong>of</strong> the signal itself. At<br />
low signal levels, this second problem is usually much<br />
more serious [1].<br />
Dither <strong>noise</strong> can be used to remove the correlation between<br />
the error <strong>and</strong> the signal at the expense <strong>of</strong> increased<br />
Magnitude (dB)<br />
100<br />
50<br />
0<br />
-50<br />
-100<br />
0 500 1000 1500 2000 2500 3000 3500 4000<br />
100<br />
50<br />
0<br />
-50<br />
-100<br />
0 500 1000 1500 2000 2500 3000 3500 4000<br />
100<br />
50<br />
0<br />
-50<br />
-100<br />
0 500 1000 1500 2000<br />
Frequency (Hz)<br />
2500 3000 3500 4000<br />
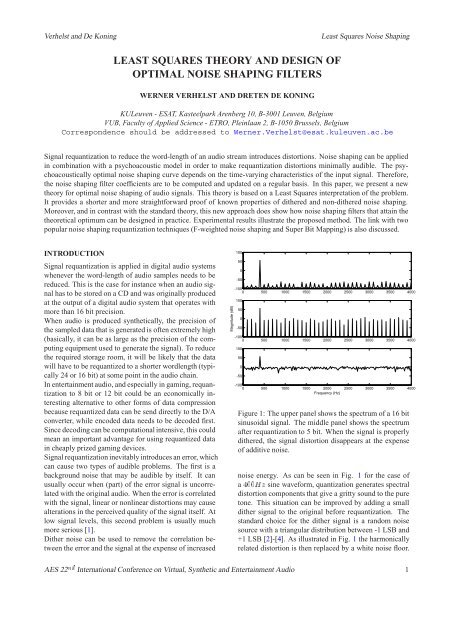
Figure 1: The upper panel shows the spectrum <strong>of</strong> a 16 bit<br />
sinusoidal signal. The middle panel shows the spectrum<br />
after requantization to 5 bit. When the signal is properly<br />
dithered, the signal distortion disappears at the expense<br />
<strong>of</strong> additive <strong>noise</strong>.<br />
<strong>noise</strong> energy. As can be seen in Fig. 1 for the case <strong>of</strong><br />
a � ÀÞ sine waveform, quantization generates spectral<br />
distortion components that give a gritty sound to the pure<br />
tone. This situation can be improved by adding a small<br />
dither signal to the original before requantization. The<br />
st<strong>and</strong>ard choice for the dither signal is a r<strong>and</strong>om <strong>noise</strong><br />
source with a triangular distribution between -1 LSB <strong>and</strong><br />
+1 LSB [2]-[4]. As illustrated in Fig. 1 the harmonically<br />
related distortion is then replaced by a white <strong>noise</strong> floor.<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 1
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
It can be noted that digitizing a � ÀÞ tone at ��� �ÀÞ<br />
does indeed result in a sequence with a period <strong>of</strong> 441 samples<br />
explaining the harmonics <strong>of</strong> ÀÞ seen in Fig. 1a.<br />
Most energy is in the fourth harmonic (� ÀÞ). When<br />
the quantization step-size increases, the amount <strong>of</strong> energy<br />
outside this main harmonic increases (Fig. 1b). The use<br />
<strong>of</strong> dither <strong>noise</strong> before quantization works to destroy the<br />
quantized signals harmonicity (Fig. 1c).<br />
With or without dither, the requantization error can be<br />
made minimally audible by proper <strong>noise</strong> <strong>shaping</strong>. It suffices<br />
to change the shape <strong>of</strong> the error spectrum such that<br />
it becomes minimally audible in the presence <strong>of</strong> the audio<br />
signal. The specifications for the <strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong><br />
filter can be determined from the input signal using a psychoacoustic<br />
model. However, these <strong>design</strong> specifications<br />
are time-varying since they depend on the global masking<br />
properties <strong>of</strong> the audio input. Thus, because the <strong>noise</strong><br />
<strong>shaping</strong> filter coefficients need to be updated on-line, it<br />
is crucial that an efficient filter <strong>design</strong> technique be used<br />
that is reliable (for example, that is guaranteed to produce<br />
stable <strong>filters</strong>). In Super Bit Mapping (SBM) [5] for<br />
example, the <strong>optimal</strong> filter coefficients are obtained by<br />
¯ approximating the inverse <strong>of</strong> the desired transfer<br />
function with an LPC synthesis filter (stable allpole<br />
filter)<br />
¯ inverting the LPC synthesis filter, which results in<br />
a minimum phase FIR filter.<br />
More simple <strong>noise</strong> <strong>shaping</strong> with a fixed <strong>noise</strong> <strong>shaping</strong> filter<br />
has also been proposed [2], [3], [5]. There, it is considered<br />
that quantization errors are likely to be most audible<br />
<strong>and</strong> disturbing when the input signal level is low.<br />
Therefore, a fixed <strong>noise</strong> <strong>shaping</strong> can be used that shapes<br />
the error spectrum according to an equi-loudness curve<br />
(the hearing threshold in SBM-1 [5] <strong>and</strong> the 15 phon<br />
curve in F-weighting [3]). While the resulting fixed <strong>noise</strong><br />
<strong>shaping</strong> <strong>filters</strong> lead to a much simpler system, it is clear<br />
that the time varying strategy is preferable from the point<br />
<strong>of</strong> view <strong>of</strong> the overall sound quality: that strategy minimizes<br />
the audibility <strong>of</strong> the error in the presence <strong>of</strong> the<br />
actual audio signal, while the fixed <strong>noise</strong> <strong>shaping</strong> minimizes<br />
the audibility <strong>of</strong> the error itself (when played in<br />
quiet).<br />
In this paper, we present a new <strong>theory</strong> for <strong>optimal</strong> <strong>noise</strong><br />
<strong>shaping</strong> <strong>of</strong> audio signals. This <strong>theory</strong> is based on a Least<br />
Squares interpretation <strong>of</strong> the problem. It provides a shorter<br />
<strong>and</strong> more straightforward pro<strong>of</strong> <strong>of</strong> known properties <strong>of</strong><br />
dithered <strong>and</strong> non-dithered <strong>noise</strong> <strong>shaping</strong>.<br />
Moreover, <strong>and</strong> in contrast with the st<strong>and</strong>ard <strong>theory</strong>, this<br />
new approach does show how <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> that<br />
attain the theoretical optimum can be <strong>design</strong>ed in practice.<br />
It turns out that the method used in SBM is an optimum<br />
method. Specifically, our <strong>theory</strong> proves that given<br />
an allowed filter order, the filter <strong>design</strong> method <strong>of</strong> SBM<br />
x(n) x’(n)<br />
+<br />
-<br />
H(z)<br />
dither<br />
+<br />
-<br />
e(n)<br />
+<br />
Q<br />
y(n)={<br />
x’(n)+e(n)<br />
x(n)+e’(n)<br />
Figure 2: Dithered requantization with error feedback filter<br />
À Þ <strong>and</strong> requantization error � Ò<br />
will produce the FIR filter that does minimize the perceptually<br />
weighted error spectrum. In fact, we independently<br />
arrived at the very same <strong>design</strong> method in [6].<br />
Finally, we also present results from an experimental <strong>noise</strong><br />
<strong>shaping</strong> system for minimally audible signal requantization<br />
that is based on our filter <strong>design</strong> method <strong>and</strong> a simple<br />
masking model. In listening experiments, this system<br />
was unanimously prefered over the alternatives which included<br />
straightforward requantization, dithered requantization<br />
<strong>and</strong> optimized fixed <strong>noise</strong> <strong>shaping</strong> [2], [3].<br />
The rest <strong>of</strong> this paper is organized as follows. The st<strong>and</strong>ard<br />
<strong>theory</strong> <strong>of</strong> <strong>noise</strong> <strong>shaping</strong> [7] <strong>and</strong> minimally audible<br />
dither signals [2]-[4] is reviewed in section 1. The newly<br />
proposed <strong>theory</strong> <strong>and</strong> the practical <strong>design</strong> method that it<br />
entails are described in section 2. The experiments described<br />
in section 3 show unanimous preference amongst<br />
listeners for our experimental <strong>noise</strong> <strong>shaping</strong> system. Finally,<br />
section 4 concludes the paper.<br />
1. REQUANTIZATION AND NOISE SHAPING<br />
1.1. General concept<br />
While a white <strong>noise</strong> dither signal can already improve<br />
the quality <strong>of</strong> low level requantized signals, <strong>noise</strong> <strong>shaping</strong><br />
can additionally be applied in order to make the requantization<br />
error minimally audible [2]. Fig. 2 illustrates<br />
the general scheme for signal requantization with <strong>noise</strong><br />
<strong>shaping</strong>. In this scheme, Q represents the quantizer <strong>and</strong><br />
À Þ is the error feedback filter. Due to the requantization<br />
error � Ò , the output Ý Ò differs from Ü Ò <strong>and</strong><br />
from Ü Ò . The error feedback filter has to be controlled<br />
such that the difference between Ý Ò <strong>and</strong> Ü Ò becomes<br />
minimally audible.<br />
With signals defined as shown in Fig. 2, <strong>and</strong> using ztransforms,<br />
we have<br />
� Þ � � Þ À Þ � Þ (1)<br />
� Þ � � Þ � Þ � Þ (2)<br />
where � Þ represents quantizer Q’s error signal <strong>and</strong> � Þ<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 2
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
is the additive quantization distortion at the output <strong>of</strong> the<br />
<strong>noise</strong> <strong>shaping</strong> requantizer. Subtracting equation (2) from<br />
(1), one finds that<br />
� Þ � À Þ � Þ (3)<br />
The requantization error � Ò therefore has power spectrum<br />
È� � �� �� À � �� � È� � ��<br />
(4)<br />
As we can see, the quantizer’s error spectrum gets shaped<br />
by a <strong>noise</strong> <strong>shaping</strong> filter that depends on the error-feedback<br />
filter À Þ .<br />
Note that this result was obtained without reference to the<br />
quantizer Q. Therefore, it applies for any type <strong>of</strong> quantizer,<br />
whether it is dithered or not, linear or nonlinear,<br />
whether it uses rounding or truncating,. . .<br />
In order to achieve minimal audibility <strong>of</strong> the requantization<br />
error, À ��� can be <strong>design</strong>ed to minimize the total<br />
amount <strong>of</strong> perceptually weighted <strong>noise</strong> power Æ Û:<br />
ÆÛ �<br />
� �<br />
�<br />
È� � �� Ï � �� (5)<br />
Ï � is a perceptual weighting function that approximates<br />
the relative audibility <strong>of</strong> <strong>noise</strong> power at the different<br />
frequencies.<br />
If a properly dithered quantizer Q is used, the power spectrum<br />
<strong>of</strong> the quantization error � Ò will be constant<br />
such that eq. (4) then reduces to<br />
È� � �� �� É (6)<br />
È� � �� �� À � �� � � É (7)<br />
1.2. The Gerzon-Craven <strong>theory</strong> [7]<br />
Let us assume that the desired shape � ��� <strong>of</strong> the error<br />
spectrum is given. Thus, from eq. (4), the <strong>noise</strong> <strong>shaping</strong><br />
filter À Þ has to be determined such that<br />
� À � �� � È� � �� �«È� � ��<br />
(8)<br />
with minimal «. In principle, there are several <strong>filters</strong><br />
À Þ that satisfy eq. (8); the different solutions correspond<br />
to <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> À Þ with a same power<br />
spectral shape <strong>and</strong> different phase characteristics. Based<br />
on information theoretic considerations, it was proven by<br />
Gerzon <strong>and</strong> Craven that the <strong>noise</strong> <strong>shaping</strong> filter À Þ<br />
that satisfies (8) with the smallest possible output error<br />
power is the filter that leaves the information capacity<br />
<strong>of</strong> the channel unaltered (maximum), <strong>and</strong> that this is attained<br />
when the filter is minimum phase.<br />
Therefore, it was suggested that a practical method to <strong>design</strong><br />
<strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> would be to use any<br />
filter <strong>design</strong> program to approximate the desired spectral<br />
shape <strong>and</strong> mirroring any zeroes that lie outside the<br />
unit circle (for reasons <strong>of</strong> stability <strong>and</strong> causality, all poles<br />
would already have to be inside the unit circle).<br />
x(n) x’(n)<br />
+<br />
-<br />
H(z)<br />
+<br />
-<br />
e(n)<br />
Psycho-Acoustic<br />
Model<br />
dither<br />
+<br />
Q<br />
y(n) = {<br />
x’(n)+e(n)<br />
x(n)+e’(n)<br />
Figure 3: Psychoacoustic requantization with timevarying<br />
<strong>noise</strong> <strong>shaping</strong> filter À Þ derived from a perceptual<br />
masking model<br />
1.3. Some <strong>noise</strong> <strong>shaping</strong> implementations<br />
Super Bit Mapping (SBM) [5] follows this suggested strategy<br />
<strong>and</strong> introduces a clever trick to <strong>design</strong> a minimum<br />
phase FIR <strong>noise</strong> <strong>shaping</strong> filter with a given power spectral<br />
shape.<br />
Note that in order to avoid delayless loops in Fig. 2, itis<br />
required that the FIR <strong>noise</strong> <strong>shaping</strong> filter can be written<br />
as<br />
À Þ �<br />
�<br />
Ò�<br />
� Ò Þ Ò � where � � � (9)<br />
It was observed in [5] that an Š� -order inverse LPC filter<br />
is minimum phase (guaranteed if obtained from the<br />
autocorrelation formulation [8]) <strong>and</strong> satisfies (9). Thus,<br />
the required minimum phase FIR <strong>noise</strong> <strong>shaping</strong> filter can<br />
be obtained by approximating the inverse <strong>of</strong> the desired<br />
<strong>noise</strong> <strong>shaping</strong> spectrum with an LPC synthesis filter <strong>and</strong><br />
inverting the result.<br />
In SBM-1, the desired <strong>noise</strong> <strong>shaping</strong> spectrum is taken<br />
to be the hearing threshold in quiet. Although SBM-1<br />
can be successfully applied to make the quantization error<br />
minimally audible in quiet, it could be preferable to<br />
use a spectral <strong>shaping</strong> that minimizes the audibility <strong>of</strong> the<br />
requantization error in the presence <strong>of</strong> the actual audio.<br />
As illustrated in Fig. 3, in SBM-2 the <strong>noise</strong> <strong>shaping</strong> filter<br />
is a time-varying filter that is <strong>design</strong>ed to approximate the<br />
instantaneous masking threshold <strong>of</strong> the signal. In order to<br />
avoid artifacts from abruptly changing error feedback <strong>filters</strong>,<br />
smoothing <strong>of</strong> the time-varying filter characteristics<br />
is applied in the autocorrelation domain.<br />
The <strong>design</strong> <strong>of</strong> À � �� by optimization <strong>of</strong> (5) with numeric<br />
optimization techniques has also been considered<br />
[2],[3]. As this is a rather difficult problem, only fixed<br />
<strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> have been <strong>design</strong>ed in this way. Because<br />
the <strong>noise</strong> is obviously most audible in quiet fragments,<br />
the perceptual weighting function Ï � was ap-<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 3
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
proximated by the inverse <strong>of</strong> an equi-loudness curve. The<br />
so-called E-weighting <strong>and</strong> F-weighting models for the<br />
15-phon audibility function have been used as the perceptual<br />
weighting function in [2] <strong>and</strong> [3], respectively.<br />
As in SBM-1, this results in quantization <strong>noise</strong> that is<br />
by itself minimally audible (i.e., minimally audible in silence)<br />
<strong>and</strong> makes the <strong>noise</strong> <strong>shaping</strong> filter independent <strong>of</strong><br />
the input signal, thus avoiding the need for on-line optimization<br />
<strong>of</strong> (5). Interestingly, [2] <strong>and</strong> [3] use a dithered<br />
quantizer, while [5] uses non-dithered quantization.<br />
2. A LEAST SQUARES THEORY<br />
From equations (5), (4), <strong>and</strong> (9) the <strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong><br />
filter can be found by minimizing<br />
� � �<br />
�ÆË � � � Ò �<br />
� Ò�<br />
��Ò � È� � �� Ï � ��<br />
(10)<br />
Observe that, while this problem may be difficult to solve<br />
in general, in the case at h<strong>and</strong> Ï � is a perceptual weighting<br />
function. Therefore, Ï � is real <strong>and</strong> positive, such<br />
that this specific problem is actually a <strong>least</strong>-<strong>squares</strong> problem<br />
that can easily Ô be solved. To demonstrate this, let us<br />
define Î � � Ï � È� ��� , 1 <strong>and</strong> denote its inverse<br />
Fourier transform by Ú Ò .<br />
Parseval’s theorem can now be applied to transform the<br />
problem to time domain: �ÆË equals the energy contained<br />
in the sequence that would be obtained by filtering<br />
Ú Ò with the <strong>noise</strong> <strong>shaping</strong> filter, i.e.,<br />
�ÆË �<br />
�<br />
Ò�<br />
� �<br />
��<br />
� � Ú Ò �<br />
�<br />
(11)<br />
This quantity can be straightforwardly minimized by requiring<br />
that<br />
�ÆË<br />
� �<br />
� � � � ���� (12)<br />
which leads to the so-called normal equations:<br />
with<br />
Ê �<br />
�<br />
�<br />
�<br />
Ê� � Ö (13)<br />
Ö Ö ��� Ö Å<br />
Ö Ö Ö Å<br />
.<br />
. .. .<br />
Ö Å Ö Å ��� Ö<br />
�<br />
� � � .<br />
� Å<br />
Ö<br />
�<br />
�<br />
� Ö � .<br />
Ö Å<br />
�<br />
�<br />
�<br />
�<br />
�<br />
�<br />
1 This can be simplified to Î � � Ô Ï � if the quantizer’s error<br />
spectrum is white, as in the case <strong>of</strong> properly dithered quantizers or when<br />
the input level is high compared to the quantizer stepsize.<br />
<strong>and</strong><br />
Ö � �<br />
�<br />
Ò�<br />
Ú Ò Ú Ò � (14)<br />
is the autocorrelation function <strong>of</strong> Ú Ò .<br />
Equations (13) <strong>and</strong> (14) are the so-called autocorrelation<br />
formulation <strong>of</strong> the LPC analysis <strong>of</strong> signal Ú Ò . The properties<br />
<strong>of</strong> these equations have been studied for several<br />
digital signal processing applications in the past, e.g., for<br />
speech processing in [8]. For example, it is well known<br />
that, without computation errors, the solution is indeed a<br />
minimum phase filter [9]. Thus, our <strong>theory</strong> provides an<br />
alternative <strong>and</strong> straightforward way to prove Gerzon <strong>and</strong><br />
Craven’s proposition.<br />
As another example, it is also known that the weighted<br />
<strong>and</strong> shaped error spectrum � À � �� � È� � �� Ï �<br />
will be maximally flat, such that the <strong>noise</strong> <strong>shaping</strong> filter<br />
spectrum will approximate the inverse <strong>of</strong> the weighted<br />
error spectrum Ï � È� � �� .<br />
Further, this <strong>least</strong> <strong>squares</strong> <strong>theory</strong> also shows how truly<br />
<strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> can be <strong>design</strong>ed. Indeed,<br />
linear matrix equation (13) can be easily solved with any<br />
<strong>of</strong> a number <strong>of</strong> well-known methods <strong>and</strong> produces the required<br />
<strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong> filter. Furthermore, Ê being<br />
a symmetric Toeplitz matrix, there is a choice <strong>of</strong> efficient<br />
<strong>and</strong> robust solution algorithms for solving (13) (such as<br />
[10], for example).<br />
Traditionally, the quantizer has been assumed to produce<br />
a white error signal � Ò . In that case, the autocorrelation<br />
function <strong>of</strong> Ú Ò is by definition equal to the inverse<br />
Fourier transform <strong>of</strong> the perceptual weighting function<br />
Ï � . In practice, Ö � �� � ���Å can therefore be<br />
approximated by sampling Ï � <strong>and</strong> computing the inverse<br />
FFT:<br />
Ö � � Æ<br />
Æ �<br />
��<br />
Ï �<br />
Æ � �� � Æ �� � � � ���Å (15)<br />
By using enough frequency samples Æ �� Å, the total<br />
approximation error can be made arbitrarily small.<br />
Given a desired filter order Å, the solution <strong>of</strong> matrix<br />
equation (13) produces the filter that does minimize (5).<br />
While numerical optimization <strong>of</strong> (5) is too slow for online<br />
applications <strong>and</strong> may fail to converge in practice, our<br />
method is computationally efficient <strong>and</strong> robust. Furthermore,<br />
this method can also be applied in case <strong>of</strong> nonwhite<br />
quantization error, such as in the non dithered case.<br />
Indeed, in that case it suffices to perform the same operations<br />
on Ï � È� � �� (instead <strong>of</strong> Ï � ).<br />
In SBM the inverse <strong>noise</strong> <strong>shaping</strong> filter is approximated<br />
by applying an LPC modellisation to the inverse <strong>of</strong> the<br />
desired <strong>noise</strong> <strong>shaping</strong> spectrum. If we let Ï � be equal<br />
to the inverse <strong>of</strong> the desired <strong>noise</strong> <strong>shaping</strong> spectrum, then<br />
the above <strong>theory</strong> proves that the SBM filter is the opti-<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 4
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
Magnitude (dB)<br />
30<br />
20<br />
10<br />
0<br />
-10<br />
-20<br />
-30<br />
0 5 10<br />
Frequency (kHz)<br />
15 20<br />
Figure 4: A � � order FIR <strong>noise</strong> <strong>shaping</strong> <strong>design</strong> (dashed<br />
line) compared to the F-weighting equi-loudness curve.<br />
The equi-loudness curve was downward shifted 16 dB for<br />
easy comparison: £ ÐÓ� Ï � � was plotted.<br />
Because the <strong>noise</strong> <strong>shaping</strong> filter is minimum phase, its<br />
spectrum on a log scale averages to zero [7].<br />
mum one. However, this is only valid under the assumption<br />
that � � �� is constant.<br />
Because SBM uses a non-dithered quantizer, it is doubtful<br />
that this would be satisfied for the more critical low<br />
level signals. This suggests that SBM could be improved<br />
by applying the LPC modellisation to the inverse <strong>of</strong> the<br />
desired <strong>noise</strong> <strong>shaping</strong> spectrum multiplied by the quantizer’s<br />
error spectrum � � �� or an estimate there<strong>of</strong>.<br />
3. EXPERIMENTS<br />
3.1. Duplication <strong>of</strong> the F-weighted <strong>design</strong><br />
To illustrate its <strong>optimal</strong>ity, we applied the proposed <strong>design</strong><br />
procedure to the problem <strong>of</strong> <strong>design</strong>ing a minimally<br />
audible dither signal using the F-weighting curve as the<br />
perceptual weighting function Ï � , as was discussed<br />
in section 1.3. Fig. 4 illustrates the result for a sampling<br />
frequency <strong>of</strong> ��� �ÀÞ. A� Ø� order filter approximation<br />
was used. The filter coefficients we obtained differed less<br />
than 0.1% from those obtained by direct optimization <strong>of</strong><br />
(5) that were published in [3]. This small deviation is<br />
probably due to the approximation <strong>of</strong> the autocorrelation<br />
function by inverse FFT, <strong>and</strong> could be further reduced by<br />
using more frequency samples <strong>of</strong> Ï � .<br />
3.2. Noise <strong>shaping</strong> experiment<br />
3.2.1. Experimental setup<br />
A s<strong>of</strong>tware version <strong>of</strong> the psychoacoustical <strong>noise</strong> <strong>shaping</strong><br />
requantizer (Fig. 3) was implemented. 44.1 kHz sampling<br />
frequency <strong>and</strong> � Ø� order FIR <strong>design</strong>s for À Þ were<br />
used. The filter coefficients were obtained by solving (13)<br />
as described above. Ö � was approximated by a 512 point<br />
inverse FFT <strong>of</strong> the sampled weighting function<br />
Ï �� � ��<br />
Æ<br />
�� � ���Æ � Æ ��<br />
Ï �� was updated every 256 input samples <strong>and</strong> corresponded<br />
to the inverse masking curve <strong>of</strong> a simplified<br />
psychoacoustic model:<br />
Ï �� � ¬ÈÜÜ �� ¬ ÈÌÉ ��<br />
(16)<br />
¬ � � Æ � (17)<br />
Here ÈÜÜ �� represents the energy spectrum <strong>of</strong> a 512<br />
point hanning windowed input segment. Its spectral resolution<br />
is comparable to the critical b<strong>and</strong>width <strong>of</strong> hearing<br />
at about �ÀÞ. ÈÌÉ �� is the hearing threshold in<br />
quiet, <strong>and</strong> � is the number <strong>of</strong> bits <strong>of</strong> the input signal representation.<br />
In our experiments � � � <strong>and</strong> È ÌÉ ��<br />
was approximated by the energy spectrum <strong>of</strong> the � � order<br />
F-weighting filter (dashed curve in Fig. 4). As with<br />
other perception models, ¬ depends on the expected sound<br />
pressure level <strong>of</strong> the input signal. The value in (17) compensates<br />
for the scale factor incurred with our choice <strong>of</strong><br />
ÈÌÉ �� <strong>and</strong> is appropriate when the loudest signal portions<br />
are played at 84 dB SPL.<br />
Sixteen bit test data from good-quality CDs was used in<br />
the experiments. Six different fragments were used, containing<br />
different types <strong>of</strong> instruments, vocals, <strong>and</strong> musical<br />
styles. They had a total duration <strong>of</strong> 1 minute 33 seconds.<br />
The fragments were first requantized using straightforward<br />
requantization (i.e., rounding) to a precision where<br />
the requantization errors became clearly audible. The<br />
fragments were then requantized to the same precision<br />
(between 5 <strong>and</strong> 7 bits, depending on the fragment) with<br />
three additional methods, resulting in four different versions:<br />
Version 1. Straightforward requantization<br />
Version 2. Requantization with st<strong>and</strong>ard dither<br />
Version 3. Non-dithered requantization with fixed <strong>noise</strong><br />
<strong>shaping</strong> (F-weighting)<br />
Version 4. Non-dithered requantization with adaptive psychoacoustic<br />
<strong>noise</strong> <strong>shaping</strong><br />
3.2.2. Informal diagnostic evaluation<br />
Two adults with normal hearing participated in this informal<br />
evaluation. They were allowed to listen to the different<br />
quantized <strong>and</strong> original sound fragments in any desired<br />
order <strong>and</strong> as <strong>of</strong>ten as they desired. The experiment<br />
was performed in a quiet <strong>of</strong>fice <strong>and</strong> the sound files were<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 5
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
played from a multimedia PC (Compaq presario 4810)<br />
over headphones (AKG K-300). The experimenters discussed<br />
their findings with one another <strong>and</strong> eventually reported<br />
the following conclusions.<br />
Version 2 (st<strong>and</strong>ard dither) was systematically judged to<br />
have lowest quality due to the very audible presence <strong>of</strong><br />
the high level dither signal.<br />
In version 1, signal distortions <strong>and</strong> quantization <strong>noise</strong>s<br />
were also clearly audible, especially in s<strong>of</strong>ter segments.<br />
Because the <strong>noise</strong> was less prominent than in version 2<br />
<strong>and</strong> distortions occured only intermittently, version 1 was<br />
prefered over version 2 for all cases.<br />
Versions 3 <strong>and</strong> 4 were found to be <strong>of</strong> much higher quality<br />
than versions 1 <strong>and</strong> 2. No nonlinear distortions were<br />
perceived. 2<br />
In version 3 a weak high-frequency <strong>noise</strong> was permanently<br />
audible.<br />
In version 4, a similar but weaker <strong>noise</strong> could be heard<br />
during the s<strong>of</strong>ter signal portions only.<br />
Version 4 was judged to be better in general than all other<br />
versions.<br />
Differences between version 4 on the one h<strong>and</strong> <strong>and</strong> versions<br />
1 <strong>and</strong> 2 on the other h<strong>and</strong> were deemed so clear that<br />
they could be evaluated in a classroom experiment.<br />
3.2.3. Classroom experiment<br />
The classroom experiment was set up as a blind pairwise<br />
comparison experiment with forced choice. It was carefully<br />
<strong>design</strong>ed <strong>and</strong> properly controlled (albeit that recommended<br />
practices <strong>of</strong> normalization bodies were not<br />
used). Thus, for example, the presentation order was<br />
r<strong>and</strong>omized, the different versions occupied all presentation<br />
orders the same number <strong>of</strong> times, etc. Because <strong>of</strong><br />
the clearly identifiable characteristic sound <strong>of</strong> the different<br />
versions involved, the subjects were probably able to<br />
identify that all stimuli belonged to one <strong>of</strong> three possible<br />
classes, but this could not be avoided.<br />
Twenty-one students, aged 20-25, participated in the listening<br />
experiment. Eighteen reported normal hearing,<br />
one better than normal <strong>and</strong> two less than normal hearing.<br />
The same six audio fragments as in the informal diagnostic<br />
evaluation were used. Two fragments were used to<br />
compare version 4 with version 2 (one for each presentation<br />
order), <strong>and</strong> the remaining four fragments were used<br />
to compare version 4 with version 1 (two for each presentation<br />
order). The audio was played in a normal <strong>and</strong><br />
quiet classroom from a portable PC (Toshiba Satellite Pro<br />
CDT-420) using small active loudspeakers (Philips SBC<br />
8237). The original 16 bit version was always played<br />
first, as a reference, before the two test versions. The<br />
subjects indicated their preference for one <strong>of</strong> the test versions<br />
by crossing the corresponding column <strong>of</strong> a table on<br />
2 This lead us to decide to use perceptual <strong>noise</strong> <strong>shaping</strong> without<br />
dither in the classroom experiment.<br />
their response forms.<br />
Twenty properly filled-out response forms were received.<br />
They showed that version 4 had been systematically preferred<br />
by all listeners in every pair that had been presented.<br />
Thus, in a total <strong>of</strong> 120 comparisons (six fragments,<br />
twenty subjects), the adaptive psychoacoustic requantization<br />
method was never defeated.<br />
4. CONCLUSION<br />
Requantization is a common operation in modern audio<br />
equipment. Therefore, it is very important that it is performed<br />
with minimal audible distortion.<br />
With dithered requantization, one can avoid that signal<br />
distortion is perceived at the expense <strong>of</strong> an additive <strong>noise</strong><br />
source. Noise <strong>shaping</strong> had been proposed in the past<br />
to make the requantization error minimally audible, <strong>and</strong><br />
<strong>noise</strong> <strong>shaping</strong> has been applied with dithered <strong>and</strong> nondithered<br />
requantizers, <strong>and</strong> with fixed <strong>and</strong> adaptive psychoacoustic<br />
<strong>noise</strong> <strong>shaping</strong> <strong>filters</strong>.<br />
In this paper, we presented a short review <strong>of</strong> the state <strong>of</strong><br />
affairs in <strong>noise</strong> <strong>shaping</strong> for audio requantization. We discussed<br />
the Gerzon-Craven <strong>theory</strong> <strong>and</strong> two classes <strong>of</strong> <strong>noise</strong><br />
<strong>shaping</strong> that are based on it (fixed <strong>and</strong> adaptive psychoacoustic<br />
<strong>noise</strong> <strong>shaping</strong>).<br />
We introduced a new <strong>theory</strong> for <strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong><br />
<strong>of</strong> audio signals that is based on a Least Squares interpretation<br />
<strong>of</strong> the problem. It provides a shorter <strong>and</strong> more<br />
straightforward pro<strong>of</strong> <strong>of</strong> known properties <strong>of</strong> dithered <strong>and</strong><br />
non-dithered <strong>noise</strong> <strong>shaping</strong>. The <strong>theory</strong> also applies if the<br />
quantizer error is non-white.<br />
Moreover, <strong>and</strong> in contrast with the st<strong>and</strong>ard <strong>theory</strong>, the<br />
new approach does show how <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> that<br />
attain the theoretical optimum can be <strong>design</strong>ed in practice.<br />
We showed that Super Bit Mapping uses a filter<br />
<strong>design</strong> strategy that is <strong>optimal</strong> in the sense that, given a<br />
filter order, it will produce the filter that minimizes the<br />
power <strong>of</strong> the requantization error � Ò provided that the<br />
quantization error � Ò is white. Since SBM does not<br />
use a dithered quantizer, we suggested using our <strong>design</strong><br />
method for the non-white case as a possible improvement.<br />
We described an efficient method that allows for on-line<br />
<strong>design</strong> <strong>of</strong> <strong>optimal</strong> <strong>noise</strong> <strong>shaping</strong> <strong>filters</strong> <strong>and</strong> that also applies<br />
in case <strong>of</strong> a non-white quantizer error signal � Ò .In<br />
a testcase, the filter coefficients obtained with our method<br />
agreed to within 0.1% with those that were obtained by<br />
direct numeric minimization <strong>of</strong> the perceptually weighted<br />
error power.<br />
Our experiments showed that there is a clear preference<br />
for signal-adaptive psychoacoustic <strong>noise</strong> <strong>shaping</strong> without<br />
dithering when compared to straightforward requantization,<br />
to requantization with st<strong>and</strong>ard dithering <strong>and</strong> to requantization<br />
with fixed <strong>noise</strong> <strong>shaping</strong>.<br />
It was noted that some <strong>of</strong> the existing <strong>noise</strong> <strong>shaping</strong> sys-<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 6
Verhelst <strong>and</strong> De Koning Least Squares Noise Shaping<br />
tems use a dithered quantizer <strong>and</strong> others use non-dithered<br />
quantizers. With our proposed <strong>theory</strong>, we are basically<br />
able to cope with both situations. It is at present, however,<br />
not clear whether a dithered or non-dithered quantizer<br />
should be used with <strong>noise</strong> <strong>shaping</strong>.<br />
Dither increases the error power, but decorrelates the error<br />
from the signal. On the other h<strong>and</strong>, not all types <strong>of</strong><br />
correlated error would necessarily be harmful (as an example,<br />
the correlation would be at the extreme if the error<br />
is a fraction <strong>of</strong> the signal itself, but this error would not<br />
distort the signal). Also considering that the requantization<br />
error can be spectrally shaped such that it is <strong>optimal</strong>ly<br />
masked, the strategy <strong>of</strong> psychoacoustic <strong>noise</strong> <strong>shaping</strong><br />
could perhaps allow for minimally audible requantization<br />
without dithering.<br />
Further experience <strong>and</strong> experiments should be used to decide<br />
which perception models can best be applied, what<br />
type <strong>of</strong> quantizers should be used (e.g., dithered or nondithered),<br />
what <strong>noise</strong> <strong>shaping</strong> filter orders to use, etc.<br />
These <strong>and</strong> similar questions relating to parameter optimization<br />
are still open for further research. It is our impression<br />
that different <strong>optimal</strong> conditions could apply for<br />
different applications (bit precision, signal type <strong>and</strong> b<strong>and</strong>width,<br />
...).<br />
ACKNOWLEDGMENTS<br />
Support from the Flemish Community through grants from<br />
IWT <strong>and</strong> FWO is gratefully acknowledged.<br />
The first author thanks Robert Bristow-Johnson from Wave<br />
Mechanics for the stimulating e-mail correspondence that<br />
we had on the subject.<br />
REFERENCES<br />
[1] Roads, C., The Computer Music Tutorial, third<br />
printing, pp. 33-38, MIT Press, Cambridge, Massachussets,<br />
1998.<br />
[2] Lipshitz, S.P., V<strong>and</strong>erkooy, J., <strong>and</strong> Wannamaker<br />
R.A.,”Minimally Audible Noise Shaping”, J. Audio<br />
Eng. Soc. 39 (11): 836-852, 1991.<br />
[3] Wannamaker, R.A., ”Psychoacoustically Optimal<br />
Noise Shaping”, J. Audio Eng. Soc. 40 (7/8): 611-<br />
620, 1992 - presented at the 89th AES Convention,<br />
Los Angeles, September 21-25, 1990.<br />
[4] Wannamaker, R.A., Lipshitz, S.P., V<strong>and</strong>erkooy, J.,<br />
<strong>and</strong> Wright J.N., ”A Theory <strong>of</strong> Nonsubtractive<br />
Dither”, IEEE Trans. on Signal Processing 48 (2):<br />
499-516, February 2000.<br />
[5] Akune, M., Heddle, R.M., <strong>and</strong> Akagiri, K., ”Super<br />
Bit Mapping: Psychoacoustically Optimized Digital<br />
Recording”, AES preprint 3371, presented at the<br />
93rd AES Convention, San Fransisco, October 1-4,<br />
1992.<br />
[6] Verhelst W., <strong>and</strong> De Koning D., ”Noise Shaping Filter<br />
Design for Minimally Audible Signal Requantization”,<br />
proceedings <strong>of</strong> WASPAA-01, 21-24 October<br />
2001, New Paltz, New York.<br />
[7] Gerzon, M., <strong>and</strong> Craven, P.G., ”Optimal Noise<br />
Shaping <strong>and</strong> Dither <strong>of</strong> Digital Signals”, AES<br />
preprint 2822, presented at the 87th AES Convention,<br />
New York, October 18-21, 1989.<br />
[8] Markel, J.D., <strong>and</strong> Gray, A.H.Jr., Linear prediction<br />
<strong>of</strong> speech, Springer Verlag, New York, 1976.<br />
[9] Deller, J.R. Jr., Proakis, J.G., <strong>and</strong> Hansen, J.H.L.,<br />
Discrete-Time Processing <strong>of</strong> Speech Signals, Chapter<br />
5, Macmillan, New York, 1993.<br />
[10] LeRoux, J., <strong>and</strong> Gueguen, C., ”A fixed point computation<br />
<strong>of</strong> partial correlation coefficients”, IEEE<br />
Transactions on Acoust., Speech <strong>and</strong> Signal Processing:<br />
257-259, June 1977.<br />
AES 22 Ò� International Conference on Virtual, Synthetic <strong>and</strong> Entertainment Audio 7



