

Evaluating the pronunciation component of text-to-speech systems ...
Evaluating the pronunciation component of text-to-speech systems ...
Evaluating the pronunciation component of text-to-speech systems ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
168 R. I. Damper et al.<br />
% words correct<br />
% words correct<br />
% words correct<br />
100<br />
80<br />
60<br />
40<br />
20<br />
0<br />
0<br />
80<br />
60<br />
40<br />
20<br />
(a)<br />
100 (b)<br />
2 4 6 8 10 12 14 16 18<br />
Thousands<br />
size <strong>of</strong> word set<br />
0<br />
0 2 4 6 8 10 12 14 16 18<br />
Thousands<br />
size <strong>of</strong> word set<br />
100<br />
(c)<br />
80<br />
60<br />
40<br />
20<br />
Same size<br />
Total dict.<br />
Unseen<br />
Seen<br />
Same size<br />
Total dict.<br />
0<br />
0 2 4 6 8 10 12 14 16 18<br />
Thousands<br />
size <strong>of</strong> word set<br />
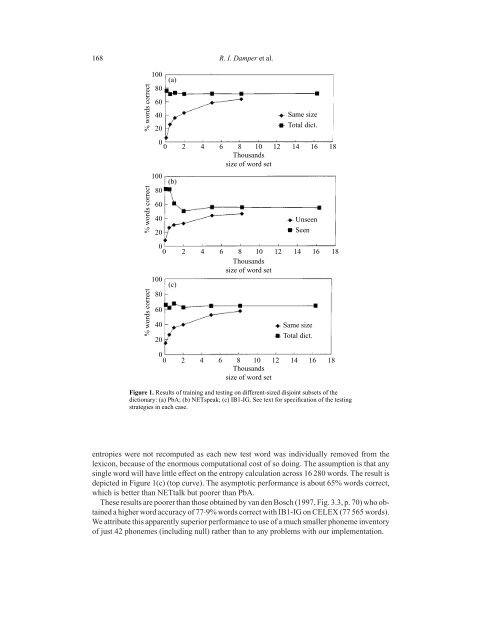
Figure 1. Results <strong>of</strong> training and testing on different-sized disjoint subsets <strong>of</strong> <strong>the</strong><br />
dictionary: (a) PbA; (b) NETspeak; (c) IB1-IG. See <strong>text</strong> for specification <strong>of</strong> <strong>the</strong> testing<br />
strategies in each case.<br />
entropies were not recomputed as each new test word was individually removed from <strong>the</strong><br />
lexicon, because <strong>of</strong> <strong>the</strong> enormous computational cost <strong>of</strong> so doing. The assumption is that any<br />
single word will have little effect on <strong>the</strong> entropy calculation across 16 280 words. The result is<br />
depicted in Figure 1(c) (<strong>to</strong>p curve). The asymp<strong>to</strong>tic performance is about 65% words correct,<br />
which is better than NETtalk but poorer than PbA.<br />
These results are poorer than those obtained by van den Bosch (1997, Fig. 3.3, p. 70) who obtained<br />
a higher word accuracy <strong>of</strong> 77·9% words correct with IB1-IG on CELEX (77 565 words).<br />
We attribute this apparently superior performance <strong>to</strong> use <strong>of</strong> a much smaller phoneme inven<strong>to</strong>ry<br />
<strong>of</strong> just 42 phonemes (including null) ra<strong>the</strong>r than <strong>to</strong> any problems with our implementation.







