Transform coding techniques for lossy hyperspectral data compression
Transform coding techniques for lossy hyperspectral data compression
Transform coding techniques for lossy hyperspectral data compression

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING (SUBMITTED DEC. 2005) 15<br />
100<br />
90<br />
80<br />
PSNR (dB)<br />
70<br />
60<br />
50<br />
40<br />
KLT1D−DWT2D<br />
DWT1D2D<br />
DCT1D−DWT2D<br />
30<br />
50 55 60 65 70 75 80 85 90 95 100<br />
% <strong>Trans<strong>for</strong>m</strong>ed coefficients set to zero<br />
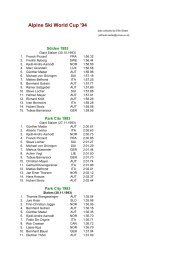
Fig. 8. Per<strong>for</strong>mance comparison of different trans<strong>for</strong>ms, with a separable trans<strong>for</strong>m in the spectral direction: KLT, DWT<br />
and DCT.<br />
in Sect. II-F.8. In the following we propose a low-complexity version of the KLT that alleviates<br />
this problem with virtually no per<strong>for</strong>mance loss with respect to the full-complexity trans<strong>for</strong>m. In<br />
particular, in Sect. IV-A we define the low-complexity one-dimensional KLT; in Sect. IV-B we define<br />
our proposed 3D trans<strong>for</strong>m based on the low-complexity KLT, and evaluate its energy compaction<br />
capability followed the same procedure used with the other trans<strong>for</strong>ms; in Sect. IV-C we provide a<br />
breif overview of JPEG 2000, and in Sect. IV-D we describe the integration of the proposed trans<strong>for</strong>m<br />
within Part 2 of JPEG 2000 [26].<br />
A. One-dimensional trans<strong>for</strong>m<br />
The KLT applies principal components analysis to the spectral dimension evaluating the average<br />
correlation matrix over all spectral vectors. For an AVIRIS scene, this amounts to computing and<br />
averaging over 300000 such matrices. To simplify this process, we note that convergence of the<br />
estimation process may be achieved using fewer matrices.<br />
Using the notation defined in Sect. II-F.8, in the proposed low-complexity trans<strong>for</strong>m all the<br />
processing is not carried out on the complete set of spectral vectors, but rather on a subset of vectors<br />
selected at random. Hence, the sample mean vector is defined as M x ′ =[m ′ x 1,m′ x 2,...,m′ x<br />
], where<br />
B<br />
m ′ x<br />
= 1 ∑<br />
k M ′ N<br />
∑i∈I<br />
′ j∈J xk ij , and I and J are sets containing respectively M ′ and N ′ different<br />
indexes picked at random in the intervals [1,M] and [1,N], with M ′ ≤ M and N ′ ≤ N. This<br />
process is also depicted in Fig. 9, where the different sets of spectral vectors are highlighted.