

PDF (1MB) - QUT ePrints
PDF (1MB) - QUT ePrints
PDF (1MB) - QUT ePrints

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
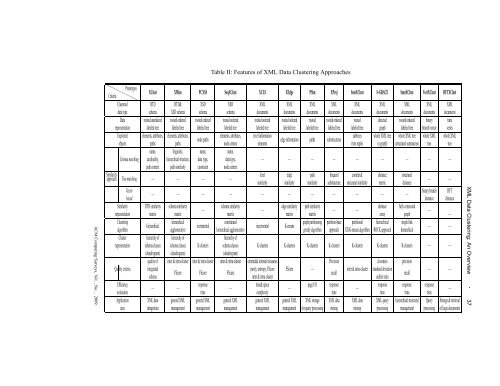
Table II: Features of XML Data Clustering Approaches<br />
ACM Computing Surveys, Vol. , No. , 2009.<br />
Prototypes<br />
❵❵❵❵❵❵❵❵❵❵❵❵<br />
Criteria<br />
XClust XMine PCXSS SeqXClust XCLS XEdge PSim XProj SemXClust S-GRACE SumXClust VectXClust DFTXClust<br />
Clustered DTD DTD& XSD XSD XML XML XML XML XML XML XML XML XML<br />
data type schema XSD schema schema schema documents documents documents documents documents documents documents documents documents<br />
Data rooted unordered rooted ordered rooted ordered rooted ordered rooted ordered rooted ordered rooted rooted ordered rooted directed rooted ordered binary time<br />
representation labeled tree labeled tree labeled tree labeled tree labeled tree labeled tree labeled tree labeled tree labeled tree graph labeled tree branch vector series<br />
Exploited elements, attributes, elements, attributes,<br />
elements, attributes, level information<br />
subtrees whole XML tree whole XML tree whole XML whole XML<br />
node paths<br />
edge information paths substructures<br />
objects paths paths node context elements (tree tuple) (s-graph) (structural summaries) tree tree<br />
name, linguistic, name, name,<br />
Schema matching cardinality, hierarchical structure, data type, data type,<br />
— — — — — — — — —<br />
path context path similarity constraint node context<br />
Similarity<br />
level edge path frequent content & distance structural<br />
approach Tree matching — — — —<br />
similarity similarity similarity substructure structural similarity metric distance<br />
— —<br />
Vector<br />
binary branch DFT<br />
— — — — — — — — — — —<br />
based distance distance<br />
Similarity DTD similarity schema similarity<br />
schema similarity<br />
edge similarity path similarity<br />
distance fully connected<br />
—<br />
—<br />
— —<br />
—<br />
representation matrix matrix matrix matrix matrix array graph<br />
—<br />
Clustering<br />
hierarchical<br />
constrained<br />
graph partitioning partition-base partitional hierarchical single link<br />
hierarchical<br />
incremental<br />
incremental<br />
K-means<br />
algorithm agglomerative hierarchical agglomerative greedy algorithm approach XTrK-means algorithm ROCK approach hierarchical<br />
— —<br />
Cluster hierarchy of hierarchy of<br />
hierarchy of<br />
representation schema classes schema classes K-clusters<br />
schema classes<br />
K-clusters K-clusters K-clusters K-clusters K-clusters K-clusters K-clusters — —<br />
(dendrogram) (dendrogram) (dendrogram)<br />
quality of inter & intra-cluster inter & intra-cluster inter & intra-cluster external& internal measures<br />
Precision<br />
closeness<br />
precision<br />
Quality criteria<br />
integrated<br />
purity, entropy, FScore FScore —<br />
inter & intra-cluster standard deviation<br />
— —<br />
FScore FScore FScore<br />
recall<br />
recall<br />
schema inter & intra cluster outlier ratio<br />
Efficiency<br />
response<br />
time& space<br />
page I/O response<br />
response response response<br />
— —<br />
—<br />
—<br />
—<br />
evaluation time complexity time time time time<br />
—<br />
Application XML data general XML general XML general XML general XML general XML XML storage XML data XML data XML query hierarchical structural Query Storage & retrieval<br />
area integration management management management management management for query processing mining mining processing management processing of large documents<br />
XML Data Clustering: An Overview · 37








