

Design and development of a concept-based multi ... - Citeseer
Design and development of a concept-based multi ... - Citeseer
Design and development of a concept-based multi ... - Citeseer

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Shiyan Ou, Christopher S.G. Khoo <strong>and</strong> Dion H. Goh<br />
Dissertation Abstracts<br />
International database<br />
--<br />
-<br />
-<br />
-<br />
-<br />
Connexor Parser<br />
ProQuest Web Interface<br />
Sentences<br />
Word tokens<br />
A set <strong>of</strong> dissertation<br />
abstracts<br />
Data Pre-processing<br />
Module<br />
Discourse<br />
Parsing Module<br />
Working database<br />
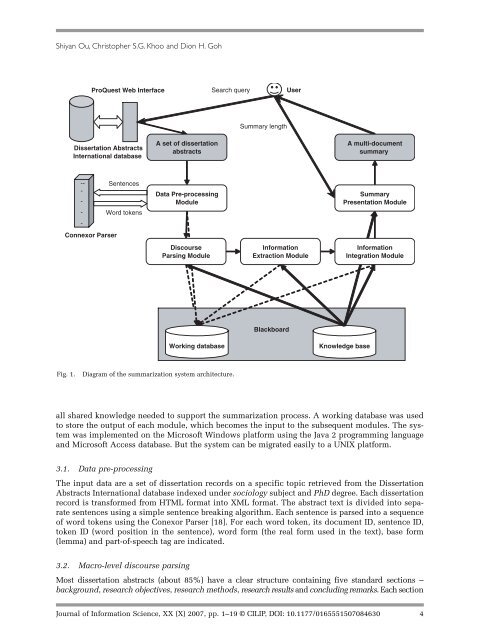
Fig. 1. Diagram <strong>of</strong> the summarization system architecture.<br />
Search query User<br />
Summary length<br />
Information<br />
Extraction Module<br />
Blackboard<br />
Knowledge base<br />
A <strong>multi</strong>-document<br />
summary<br />
Summary<br />
Presentation Module<br />
Information<br />
Integration Module<br />
all shared knowledge needed to support the summarization process. A working database was used<br />
to store the output <strong>of</strong> each module, which becomes the input to the subsequent modules. The system<br />
was implemented on the Micros<strong>of</strong>t Windows platform using the Java 2 programming language<br />
<strong>and</strong> Micros<strong>of</strong>t Access database. But the system can be migrated easily to a UNIX platform.<br />
3.1. Data pre-processing<br />
The input data are a set <strong>of</strong> dissertation records on a specific topic retrieved from the Dissertation<br />
Abstracts International database indexed under sociology subject <strong>and</strong> PhD degree. Each dissertation<br />
record is transformed from HTML format into XML format. The abstract text is divided into separate<br />
sentences using a simple sentence breaking algorithm. Each sentence is parsed into a sequence<br />
<strong>of</strong> word tokens using the Conexor Parser [18]. For each word token, its document ID, sentence ID,<br />
token ID (word position in the sentence), word form (the real form used in the text), base form<br />
(lemma) <strong>and</strong> part-<strong>of</strong>-speech tag are indicated.<br />
3.2. Macro-level discourse parsing<br />
Most dissertation abstracts (about 85%) have a clear structure containing five st<strong>and</strong>ard sections –<br />
background, research objectives, research methods, research results <strong>and</strong> concluding remarks. Each section<br />
Journal <strong>of</strong> Information Science, XX (X) 2007, pp. 1–19 © CILIP, DOI: 10.1177/0165551507084630 4






