A Comparison of Hadoop and BitDew-MapReduce
A Comparison of Hadoop and BitDew-MapReduce
A Comparison of Hadoop and BitDew-MapReduce

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Assessing <strong>MapReduce</strong> for Internet Computing: A <strong>Comparison</strong> <strong>of</strong> <strong>Hadoop</strong> <strong>and</strong><strong>BitDew</strong>-<strong>MapReduce</strong>Lu Lu, Hai Jin, Xuanhua ShiCluster <strong>and</strong> Grid Computing LabServices Computing Technology <strong>and</strong> System LabHuazhong University <strong>of</strong> Science <strong>and</strong> TechnologyWuhan, 430074, China{llu, hjin, xhshi}@hust.edu.cnGilles FedakINRIA/Uni e i <strong>of</strong> yonLyon, 69364, Francegilles.fedak@inria.frAbstract—<strong>MapReduce</strong> is emerging as an importantprogramming model for data-intensive application. Adaptingthis model to desktop grid would allow taking advantage <strong>of</strong> thevast amount <strong>of</strong> computing power <strong>and</strong> distributed storage toexecute new range <strong>of</strong> application able to process enormousamount <strong>of</strong> data. In 2010, we have presented the firstimplementation <strong>of</strong> <strong>MapReduce</strong> dedicated to Internet DesktopGrid based on the <strong>BitDew</strong> middleware. In this paper, wepresent new optimizations to <strong>BitDew</strong>-<strong>MapReduce</strong> (<strong>BitDew</strong>-MR): aggressive task backup, intermediate result backup, taskre-execution mitigation <strong>and</strong> network failure hiding. Wepropose a new experimental framework which emulates keyfundamental aspects <strong>of</strong> Internet Desktop Grid. Using theframework, we compare <strong>BitDew</strong>-MR <strong>and</strong> the open-source<strong>Hadoop</strong> middleware on Grid5000. Our experimental resultsshow that 1) <strong>BitDew</strong>-MR successfully passes all the stress-tests<strong>of</strong> the framework while <strong>Hadoop</strong> is unable to work in typicalwide-area network topology which includes PC hidden behindfirewall <strong>and</strong> NAT; 2) <strong>BitDew</strong>-MR outperforms <strong>Hadoop</strong>performances on several aspects: scalability, fairness, resilienceto node failures, <strong>and</strong> network disconnections.Keywords-desktop grid computing, <strong>MapReduce</strong>, dataintensiveapplication, cloud computingI. INTRODUCTIONResearchers in various fields have the willingness to uselarge numbers <strong>of</strong> computing resources to attack theirproblems <strong>of</strong> enormous scale. Desktop grid has shown itscapability to address this problem by using computing,network <strong>and</strong> storage resources <strong>of</strong> idle PCs distributed overmultiple LANs or the Internet, especially for CPU-intensiveapplications. We believe that applications could benefit notonly from the vast CPU processing power but also from thehuge data storage potential <strong>of</strong>fered by desktop grid [3].Distributed data processing has been widely used <strong>and</strong> studied,especially after Google shows the feasibility <strong>and</strong> simplicity<strong>of</strong> <strong>MapReduce</strong> for h<strong>and</strong>ling massive amount <strong>of</strong> web searchdata on their internal commodity clusters [11]. Recently,<strong>Hadoop</strong> [1] has emerged as the industrial st<strong>and</strong>ard <strong>of</strong> paralleldata processing on enterprise data centers. Many projects areexploring ways to support <strong>MapReduce</strong> on different types <strong>of</strong>environment (e.g. Mars [16] for GPU, Phoenix [26] for largeSMPs), <strong>and</strong> for wider range <strong>of</strong> applications [9].Implementing the <strong>MapReduce</strong> programing model fordesktop grid raises many challenges due to the low reliability<strong>of</strong> these infrastructures. In 2010, we have proposed [5] thefirst implementation <strong>of</strong> <strong>MapReduce</strong> for desktop grid basedon the <strong>BitDew</strong> middleware [14]. Typical system, such asBOINC [2] or XtremWeb [7] are oriented towards Bag-<strong>of</strong>-Tasks application <strong>and</strong> are built following simple master/slavearchitecture, where the workers pull tasks from a centralserver when they are idle. The architecture we proposeradically differs from traditional desktop grid system inmany aspects. Following a data-centric approach files <strong>and</strong>tasks are scheduled now independently by two differentschedulers. Communication patterns are now more complexthan the regular workers to master one because collectivecommunications happen at several steps <strong>of</strong> the computation:initial distribution <strong>of</strong> file chunks, shuffle <strong>and</strong> the finalreduction. Because <strong>of</strong> the tremendous amount <strong>of</strong> data toprocess, some components such as the results checker arenow decentralized. As a result, a strict methodology isneeded to assess the viability <strong>of</strong> this complex architecturewhen running on realistic Internet conditions.We summarize the main contributions <strong>of</strong> this paper asfollows: We implement a novel sophistical <strong>MapReduce</strong>scheduling strategy for dynamic <strong>and</strong> volatileenvironment, which tolerates data transfer <strong>and</strong>communication faults, avoids unnecessary tasks reexecution<strong>and</strong> aggressively backup slow tasks. We propose a new experimental framework whichemulates key fundamental aspects <strong>of</strong> InternetDesktop Grid (faults, hosts churn, firewall,heterogeneity, network disconnection, etc.) based onthe analysis <strong>of</strong> real desktop grid traces. In the paper,we present a large variety <strong>of</strong> execution scenarioswhich emulate up to 100,000 nodes.
Input DataSpilt 0 Mapper 0Spilt 1 Mapper 1Spilt 2 Mapper 2Spilt 3 Mapper 3Intermidiate DataPartition 0Partition 1Partition 0Partition 1Partition 0Partition 1Partition 0Partition 1Reducer 0Reducer 1Figure 1. Execution overview <strong>of</strong> <strong>MapReduce</strong>.Final ResultsOutput 0Output 1 Using the emulation framework on Grid5000, weevaluate experimentally <strong>BitDew</strong>-<strong>MapReduce</strong> against<strong>Hadoop</strong>, the reference implementation which alsohave fault-tolerant capabilities. Results show that<strong>BitDew</strong>-MR successfully passes all the tests <strong>of</strong> theframework while <strong>Hadoop</strong> would be unable to run onInternet Desktop Grid. More, thanks to the newscheduling optimizations, <strong>BitDew</strong>-MR outperforms<strong>Hadoop</strong> performances on several aspects: scalability,fairness, resilience to node failures, <strong>and</strong> networkdisconnection.The rest <strong>of</strong> the paper is organized as follows. In section IIwe give the background <strong>of</strong> our research. In section III, wedetail the runtime system design <strong>and</strong> implementation. Insection IV <strong>and</strong> V we report the performance evaluation. Wegive related work in section VI <strong>and</strong> finally we conclude insection VII.II.BACKGROUNDA. <strong>MapReduce</strong>The <strong>MapReduce</strong> programing model [11] borrowsconcepts <strong>of</strong> tow list-processing combinators, map <strong>and</strong> reduce,know from Lisp <strong>and</strong> many other functional languages. Thisabstraction isolates the computation expression <strong>of</strong> users’applications from the details <strong>of</strong> massively parallel dataprocessing on distributed systems, which will be h<strong>and</strong>led bythe <strong>MapReduce</strong> runtime system. The execution processconsists <strong>of</strong> three phases: The runtime system reads input (typically from adistributed file system) <strong>and</strong> parses it into key/valuepairrecords. The map function iterates the records<strong>and</strong> maps each <strong>of</strong> them into a set <strong>of</strong> intermediatekey/value pairs. The intermediate pairs are partitioned by thepartition function, then grouped <strong>and</strong> sorted accordingto their keys. An optional combine function can beinvoked to reduce the size <strong>of</strong> intermediate data. The reduce function reduces the results <strong>of</strong> theprevious phase, once for a unique key in the sortedlist, to arrive at a final result.B. <strong>Hadoop</strong><strong>Hadoop</strong> is the reference <strong>MapReduce</strong> [11] implementationtargeting to commodity clusters <strong>and</strong> enterprise data centers[1]. It consists <strong>of</strong> two fundamental subprojects: the <strong>Hadoop</strong>Distributed File System (HDFS) <strong>and</strong> the <strong>Hadoop</strong><strong>MapReduce</strong> framework.HDFS is a master/slave architectural distributed filesystem inspired by GFS, which provides high throughputaccess to application data. A NameNode daemon, running onthe master server, manages the system metadata, logicallysplits files into equal-sized blocks <strong>and</strong> controls the blockdistribution across the cluster from user clients taking intoaccount the replication factor <strong>of</strong> the file for fault tolerance.Several DataNode daemons, running on slave nodes that areactually storing the data blocks, execute management taskswhich are assigned by the NameNode <strong>and</strong> serve read/writerequests from user clients.The <strong>Hadoop</strong> <strong>MapReduce</strong> framework runs on top <strong>of</strong>HDFS <strong>and</strong> is also based on the traditional master/slavearchitecture. The master node runs a single JobTrackerdaemon to manage job status <strong>and</strong> task assignment. On eachslave node, a TaskTracker daemon is responsible forlaunching new JVM processes for executing a task whileperiodically reporting tasks’ progresses <strong>and</strong> idle task slots(slots number refereed to the maximum map/reduce taskswhich can concurrently run in the slave) to the JobTrackerthrough heartbeat signals. The JobTracker then updates thestatus <strong>of</strong> the TaskTracker <strong>and</strong> assigns new tasks to itconsidering the slot availability <strong>and</strong> data locality.C. <strong>BitDew</strong>-<strong>MapReduce</strong><strong>BitDew</strong> [14] is an open source data managementmiddleware which can be easily integrated within fullfledgeddesktop grid systems such as XtremWeb [7] <strong>and</strong>BOINC [2] as a subsystem. It provides simple APIs with ahigh level abstraction <strong>of</strong> data named Attributes to control thelife cycle, distribution, placement, replication <strong>and</strong> faulttolerance<strong>of</strong> their data in highly dynamic <strong>and</strong> volatileenvironments. The <strong>BitDew</strong> runtime environment adopts aflexible style <strong>of</strong> distributed service architecture: 1) it uses anopen source objects persistence module <strong>and</strong> does not rely ona specific relational database for data catalog; 2) it integratesvarious asynchronous <strong>and</strong> synchronous data transferprotocols including FTP, http <strong>and</strong> BitTorrent; giving theusers the freedom to select the most suitable one accordingto their applications.Our <strong>BitDew</strong>-<strong>MapReduce</strong> (<strong>BitDew</strong>-MR) prototype [5]contains three main components: the API <strong>of</strong> the <strong>MapReduce</strong>programing model, the <strong>MapReduce</strong> library that includesmaster <strong>and</strong> worker daemon programs, <strong>and</strong> a benchmark<strong>MapReduce</strong> wordcount application. Figure 2 illustrates thearchitecture <strong>of</strong> <strong>BitDew</strong>-MR runtime system. It separates thenodes in two groups: stable nodes run various independentservices which compose the runtime environment, <strong>and</strong>volatile nodes provide the storage <strong>and</strong> computing resourcesto run the map <strong>and</strong> reduce tasks. Normally, programmerswill not use the various services directly; instead they call theAPI which encapsulates the complexity <strong>of</strong> internal protocols.They can use the <strong>BitDew</strong> API (or the comm<strong>and</strong> tool) toupload input data to workers <strong>and</strong> the <strong>MapReduce</strong> API tobuild their applications. The master <strong>and</strong> worker daemons <strong>of</strong><strong>MapReduce</strong> library will h<strong>and</strong>le the interactive with <strong>BitDew</strong>services for data management.
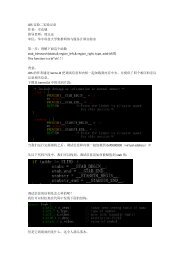
<strong>BitDew</strong> Application<strong>BitDew</strong>, Transfer Manager, ActivateDataIII.DC DR DT DS DMhttp ftp SQL<strong>MapReduce</strong> Application<strong>MapReduce</strong>MasterFigure 2. General overview <strong>of</strong> the system.<strong>MapReduce</strong>SYSTEM DESIGN AND IMPLEMENTATION<strong>MapReduce</strong>WorkerIn this section we describe the runtime techniques <strong>of</strong><strong>BitDew</strong>-MR. We focus in our discussion on the new <strong>BitDew</strong>attribute processing algorithms <strong>and</strong> the implementation <strong>of</strong>the main s<strong>of</strong>tware components <strong>and</strong> their features.A. Event-driven Task SchedulingThe key feature <strong>of</strong> <strong>BitDew</strong> is to leverage on dataattributes that not only used to index <strong>and</strong> search data files,but also to dynamically control repartitioning <strong>and</strong>distribution <strong>of</strong> data onto the storage nodes. Programmers canalso use data transfer events by manipulating data attributesto trigger task assignment actions; therefore avoid buildingtheir own scheduling component from scratch. For moredetails about these six abstractions defined by <strong>BitDew</strong>, see[14].Unfortunately, it is not trivial to implement <strong>MapReduce</strong>task scheduling by just manipulating the <strong>BitDew</strong> dataattributes. We summarize four core functionalities <strong>of</strong> the<strong>MapReduce</strong> scheduling design: a) data location aware taskselection; b) idle-worker-pull-based dynamic taskassignment; c) fault tolerance scheduling by re-executingfailed tasks; d) speculative execution by backing up slowtasks. <strong>Hadoop</strong> implements all these functionalities <strong>and</strong>improves them in two ways: task slot abstraction to specifythe number <strong>of</strong> concurrent tasks for efficient multi-co e node ’resources utilization, <strong>and</strong> conservative task backup withaggle de ec ion by compa ing each a k’ p og e co ewith the average value.The traditional data processing approach on desktop girdsdistributes input files just at the beginning <strong>of</strong> the jobexecution which makes data-local scheduling meaningless.We define a new data attribute MUTAFF - st<strong>and</strong>s for mutualaffinity - to support separating input data distribution fromtheir execution process; thus allowing users to cache theirdata into the worker nodes before launching their jobs.According to its literal meaning, MUTAFF is thebidirectional version <strong>of</strong> the original AFFINITY attribute.An intuitive approach is using DISTRIB to simulate thetask slot abstraction; FT is used to implement task reexecution<strong>and</strong> REPLICAT is used to backup tasks. Butconsidering the user sets the REPLICA value to n for his jobinput data: at the beginning <strong>of</strong> the job execution, each workergets n file chunks. Then, whenever they finish process thesechunks, they should un-register data <strong>of</strong> the chunks to triggerDS scheduling new data chunks to them, which makes reexecutions<strong>of</strong> the corresponding tasks impossible. TheREPLICAT is mainly designed for result checking by majorvoting, whereas running redundant backups for all tasks is anunacceptable resource waste (we do not take result checkinginto account in this paper because it is a challenging problemaddressed in our other work [24]). We use the combinedeffect <strong>of</strong> REPLICA <strong>and</strong> MUTAFF to implement tasksbackup. The actual control logic we implement within thedata scheduler is a little subtle because the mutual affinity isnot symmetrical relationship. For convenience <strong>of</strong> discussion,suppose there are data a, b <strong>and</strong> set a.mutaff = b, we refer tothe data a as strong MUTAFF data, data b as weakMUTAFF data. The DS will schedule strong MUTAFF dataaccording to MUTAFF attribute firstly then schedules theremaining replicas according to the REPLICA attribute <strong>and</strong>vice-versa.Algorithm 1 SCHEDU ING A GORITHMRequire:Require:ho kRequire:collec ionRequire:Ensure:ho khe e <strong>of</strong> da a managed by he chedulehe da a cache managed by he e e oihe e <strong>of</strong> da a belong o he ame da ahe e <strong>of</strong> e e oi ho owning da ahe new da a e managed by he e e oi1: ∅2: ched_coun 03: {Re ol e mu ual affini y }4: for all do5: { }6: if (k Ω( )) then7: { }8: end if9: end for10: main:11: for all (Θ ) do12: {Re ol e mu ual affini y dependence}13: for all do14: if (( .mutaff == ) ( )) then15: { }16: continue main17: end if18: end for19: {Schedule eplica}20: if (( .mutaff.replica < Ω( ) ) ( .replica < Ω( ) )) then21: di _coun 022: for all do23: if (( ) then24: di _coun di _coun + 125: end if26: end for27: if (di _coun .distrib) then28: { }29: ched_coun ched_coun + 130: end if31: end if32: if ( ched_coun MaxDataSchedule) then33: b eak34: end if35: end for36: return
Algorithm 1 presents the pseudo-code <strong>of</strong> the modifieddata scheduling algorithm. Whenever a worker programsreports the set <strong>of</strong> data held locally through heartbeat message,the Data Scheduler iterates the worker’s local data list <strong>and</strong>the global data list in order to make the scheduling decisionaccording to their attributes, <strong>and</strong> uses a MaxDataSchedulethreshold to limit the size <strong>of</strong> the set <strong>of</strong> the new data to beassigned per heartbeat, <strong>and</strong> thereby balancing the datadistribution among all the workers. We omit the detailswhich are less relative to our event-driven task scheduling.The scheduler firstly adds all the data should be kept in thewo ke ’ local data list to the new assigned data set bytheir life-cycle attributes, while checks whether these keptdata have mutual affinitive data in the global data list(strong MUTAFF data). If it is, the scheduler just adds theaffinitive data (weak MUTAFF data) to . The schedulerthen finds all the weak MUTAFF data from the wo ke ’local data list, <strong>and</strong> adds their affinitive strong MUTAFF datato . The remaining strong MUTAFF data in the globaldata list will be assigned according to their DISTRIB <strong>and</strong>REPLICA attributes regardless <strong>of</strong> MUTAFF. As theoriginally algorithm, the DISTRIB attribute is alwaysstronger than MUTAFF <strong>and</strong> REPLICA. The old DISTRIBcan only limit the number <strong>of</strong> data simultaneously hold by aworker that have the same DISTRIB attribute (with the sameattr id), we also extend it to restrict the number <strong>of</strong> data thatbelongs to the same DataCollection [5].B. The <strong>BitDew</strong>-<strong>MapReduce</strong> RuntimeOur previous work [8] mainly aimed at showing thefeasibility <strong>of</strong> building a <strong>BitDew</strong> based <strong>MapReduce</strong> runtimefor large scale <strong>and</strong> loosely connected Internet Desktop Grid.We rewrite the upper layer <strong>MapReduce</strong> API to allow users toisolate their application- specified map <strong>and</strong> reduce functionswith the data management code. Users can use the <strong>BitDew</strong>comm<strong>and</strong>-line tool to submit input data <strong>and</strong> launch jobsseparately. The pre-uploaded input data can be distributed to<strong>and</strong> cached in worker machines before execution <strong>of</strong> thecorresponding data processing job. It significantly improvesthe data locality <strong>of</strong> post-submitted jobs if the running maptasks already have their input data chunks on local machines.We also re-implement the master <strong>and</strong> worker daemons usingthe MUTAFF attribute, <strong>and</strong> adopt a new event-h<strong>and</strong>le-threaddesign to cope with worker-side network failures.MasterIf a user uses the comm<strong>and</strong>-line tool to upload his inputfile, it will automatically split the file into equal-sized datachunks <strong>and</strong> returns an id <strong>of</strong> the correspondingDataCollection. Because we do not need cache multiplereplicas on worker machines to guarantee the accessibility <strong>of</strong>the input file, all data in this DataCollection should be setattr = {replicat = 1, ft = true}. When a job launches, themaster daemon initializes job configuration, fetches all data<strong>of</strong> input chunks from DC service by the input DataCollectionid, <strong>and</strong> creates task token data that used to trigger workerdaemons launch corresponding map/reduce tasks. All maptokens will be set MUTAFF to their corresponding inputchunk: map_token_i.attr = {replicat = 2, distrib = 1, affmut= input_data_i}. The combination <strong>of</strong> REPILCA, DISTRIBFigure 3. Worker h<strong>and</strong>les.<strong>and</strong> MUTAFF makes the scheduler to dynamically assignmap tokens to workers <strong>and</strong> balance the load. When the job isclosed to the end <strong>of</strong> the map phase, the scheduler replicatesthe remaining map tasks indicated by REPLICA values <strong>of</strong>the map tokens on idle workers, thereby shortening the jobmake-span. The mutual affinity triggers workers receive newmap token to download the required task input files.At the end <strong>of</strong> the computation, several result files will begenerated by reduce tasks which have to be retrieved by themaster. Master creates an empty data, a Collector <strong>and</strong> everyWorker sets an AFFINITY attribute from Result data toCollector data. By this way, results are automaticallytransferred to the master node.WorkerThe worker daemon periodically gets data from DSservice using ActiveData API, <strong>and</strong> then determines theactions to be performed according to the type <strong>of</strong> datareceived <strong>and</strong> their attributes. If a user submits an input file,all the workers will download spitted chunks that assigned tothem after get the corresponding data from DS. Weimplement a multi-threaded transfer component which canprocess several concurrent files transfers especially for thesynchronous protocols. After a user launches the job, themap tokens will be sent to the workers according to theirMUTAFF attributes, while the reduce tokens will bescheduled in a round-robin way. We borrow the task slotabstraction from <strong>Hadoop</strong> to efficiently utilize the computingcapacity <strong>of</strong> the modern multi-core hardware, each slot will beassigned to a separated map/reduce executing thread in theworker daemon, the number <strong>of</strong> maximum concurrent threads(slots number) <strong>of</strong> map <strong>and</strong> reduce tasks can be configured.Once a map task is finished, the worker daemon invokes theunpin method to un-associate the token data with its host tomake scheduler assigning new map tokens limited by theDISTRIB attribute to it. After the output file <strong>of</strong> this task hasbeen sent to the stable storage, the worker daemon unregistersthe task token with DC <strong>and</strong> DS services to avoidany re-execution <strong>of</strong> this task in the future.We use two different threads to invoke the ActiveDatacallbacks <strong>and</strong> process file transfers: one for transfermanagement <strong>and</strong> the other for data control. The mainprinciple is to avoid putting time-consuming works <strong>and</strong>blocking I/O procedures in the bodies <strong>of</strong> ActiveData callbackmethods. Otherwise they may punctually prevent the
ActiveData main loop from sending heartbeats to DS, whichin turn could make the DS service mistakenly marking theworker as “dead”. We do not put any actual process logicinto the active callbacks – they only generate event that areadded to the proper thread-safe event queues. To makeworker programs resilient to temporary network failures,whenever the threads catch a remote communicationexception (or any other kind <strong>of</strong> exceptions), they just skip theprocessing event <strong>and</strong> add it to the tail <strong>of</strong> its queue. TheTransferManager API has also been modified to supportautomatic file retransmission. The TransferManager mainloop just re-initializes a transfer if a failure occurs.IV.EXPERIMENTAL METHODOLOGYA. Platform <strong>and</strong> ApplicationWe perform all our experiments in the GdX <strong>and</strong> NetGdXclusters which are part <strong>of</strong> the Grid5000 infrastructure. Thetwo clusters are composed <strong>of</strong> 356 IBM eServer nodesfeatured with one 2-core 2.0GHz AMD Opteron CPU <strong>and</strong>2GB RAM. All the nodes are running Debian with kernel2.6.18, <strong>and</strong> interconnected by gigabit Ethernet network. Allresults described in this paper are obtained using <strong>Hadoop</strong>version 0.21.0, while the data is stored with 2 replicas perblock in <strong>Hadoop</strong> Distributed File System. We perform ourexperiments by repeatedly executing the word countbenchmark, with 50GB dataset generated by <strong>Hadoop</strong>R<strong>and</strong>omTextWriter application. The block size is set to64MB <strong>and</strong>, tasks slots for the map <strong>and</strong> reduce tasks are set to2 <strong>and</strong> 1 respectively. We fix the number <strong>of</strong> reducers per jobto 10 reducers. The job make-span baselines <strong>of</strong> <strong>Hadoop</strong> <strong>and</strong><strong>BitDew</strong>-MR in normal case are 399 seconds <strong>and</strong> 246 secondsrespectively.B. Emulation ScenariosIt is difficult to conduct experiments on large-scale <strong>and</strong>distributed systems such as desktop grids <strong>and</strong> re-produce theoriginal results due to: 1) the implementation <strong>of</strong> systemruntime plays an important role in the overall performance; 2)the resources <strong>of</strong> different machines <strong>of</strong> desktop grids can beheterogeneous, hierarchical, or dynamic; 3) machine failures<strong>and</strong> uses’ usage behaviors make the system performancevery hard to predict. We design seven experiment scenariosto emulate Internet-scale desktop grid environment on theGrid5000 platform. This environment emulation is based onthe analysis <strong>of</strong> both: desktop grid system implementations<strong>and</strong> traces represent node availability <strong>of</strong> real desktop grids.- Scalability. Volunteer computing projects such asSETI@home may have millions <strong>of</strong> participants, but thenumbers <strong>of</strong> the server machines which <strong>of</strong>fer the core systemmanagement services are relatively small. If large amount <strong>of</strong>the participant clients simultaneously connect to the centralservers, a disastrous overload could occur. The first scenarioevaluates the scalability <strong>of</strong> the core master services <strong>of</strong><strong>Hadoop</strong> <strong>and</strong> <strong>BitDew</strong>-MR. We run central service daemonson one master node, <strong>and</strong> multi-threads clients thatperiodically perform remote meta-data creating operationsin the master on 100 worker nodes. We tune the concurrentthreads number <strong>of</strong> each clients <strong>and</strong> the operation interval.- Fault Tolerance. Google <strong>MapReduce</strong> usesstraightforward task re-execution strategy to h<strong>and</strong>le frequentbut small fractional <strong>of</strong> machine failures based on theobservation <strong>of</strong> their commodity clusters [11]. However, themajor contributor to resource volatility in desktop grid is notthe machine failures but the users’ personal behaviors suchas shutting down their machines. Moreover, typical desktopgrid systems including BOINC [2] <strong>and</strong> Condor [27] justsuspend the running tasks when detecting other active jobsthrough keyboard or mouse events, which in turn aggravatethe problem. CPU availability traces <strong>of</strong> participating nodesgathered from a real enterprise desktop grid [21] show that:a) the independent single node unavailability rate is about40% on average; b) up to 90% <strong>of</strong> the resources can beunavailable simultaneously, which may create catastrophiceffect on the running jobs. We emulate this kind <strong>of</strong> machineunavailability by killing worker <strong>and</strong> task processes on 25worker nodes at different progress points <strong>of</strong> the map phase<strong>of</strong> job execution.<strong>Hadoop</strong> <strong>MapReduce</strong> runtime system can h<strong>and</strong>le twodifferent kinds <strong>of</strong> failures: child task processes failure <strong>and</strong>TaskTracker daemons failure. We conduct threeexperimental scenarios for different failure modes: 1) kill allchild map task processes; 2) kill TaskTracker processes; 3)kill all Java processes including DataNode daemons - toemulate the whole machine crash. At the meantime,considering that the common case <strong>of</strong> desktop gridenvironment is not process fail but the crash or leaving <strong>of</strong>whole machines, we make the <strong>BitDew</strong>-MR worker daemonmulti-threaded within a single-process, which simplifies thedata sharing <strong>of</strong> different system modules. We just kill thesingle worker process on each <strong>of</strong> the 25 chosen nodes toemulate the machine.- Host Churn. The independent arrival <strong>and</strong> departure <strong>of</strong>thous<strong>and</strong>s or even millions <strong>of</strong> peer machines leads to hostchurn. We periodically kill the <strong>MapReduce</strong> worker processon one node <strong>and</strong> launch it on a new node to emulate the hostchurn effect. To increase the survival probability <strong>of</strong> <strong>Hadoop</strong>job completion, we increase the HDFS chunk replica factorto 3, <strong>and</strong> set the DataNode heartbeat timeout value to 20seconds.- Network Connectivity. We set firewalls <strong>and</strong> NAT ruleson all the worker nodes to disable all server-initiated <strong>and</strong>inter-worker network connections.- CPU heterogeneity. We emulate CPU heterogeneity byadjusting half worker nodes CPU frequency to 50% withWrekavoc [10].- Straggler. Straggler is a machine that takes anunusually long time to complete one <strong>of</strong> the last few tasks inthe computation [11]. We emulate stragglers by adjustingCPU frequency <strong>of</strong> target nodes to 10% with Wrekavoc.- Network Failure Tolerance. The runtime system mustbe resilient to the temporary network isolation <strong>of</strong> a portion <strong>of</strong>the machines, which is very common in the Internetenvironment for the sake <strong>of</strong> users' behaviors <strong>and</strong> networkhardware failures. We inject temporary <strong>of</strong>f-line 25-secondwindow periods in 25 worker nodes at different job progresspoints. To make sure the system master will mark the <strong>of</strong>flineas dead, we set the worker heartbeat timeout to 10 seconds.
Figure 4. Scalability evaluation <strong>of</strong> core system service: (a) <strong>Hadoop</strong> creates empty files <strong>and</strong> (b) <strong>BitDew</strong> creates data.TABLE I.PERFORMANCE EVALUATION OF FAULT TOLERANCE SCENARIOJob progress <strong>of</strong> the crash points 12.5% 25% 37.5% 50% 62.5% 75% 87.5% 100%<strong>Hadoop</strong><strong>BitDew</strong>-MRKilltasksKillTTsKillallRe-executed map tasks 50 50 50 50 50 50 50 50Job make-span (sec.) 425 425 423 427 426 429 431 453Re-executed map tasks 50 100 150 200 250 300 350 400Job make-span (sec.) 816 823 809 815 820 819 812 814Kill allFailedRe-executed map tasks 50 0 50 0 50 0 50 0Job make-span (sec.) 450 411 389 351 331 299 279 247V. EXPERIMENT RESULTSA. ScalabilityFigure 4 presents the operation throughput when varyingthe number <strong>of</strong> concurrent threads <strong>and</strong> the time intervalbetween them in <strong>Hadoop</strong> <strong>and</strong> <strong>BitDew</strong>-MR. As shown inFigure 2, increasing the number <strong>of</strong> concurrent clients resultsin dramatic decrease in the number <strong>of</strong> meta-data operationper second for both <strong>Hadoop</strong> <strong>and</strong> <strong>BitDew</strong>-MR. However,<strong>BitDew</strong>-MR shows better scalability in contrast to <strong>Hadoop</strong> asit can achieve acceptable throughputs under typical DesktopGrid configuration, 1,000,000 PCs create meta-data everyfew minutes.At the start, we think that the significant decrease inthroughput under 1,000,000 concurrent emulated clients iscontributed by the bottleneck <strong>of</strong> disk IO operations. Butconsidering that the <strong>Hadoop</strong> NameNode persists its memorystructures image into a write-ahead log file to group smallr<strong>and</strong>om disk IO operations into big sequential IO, <strong>and</strong> thatwe are using a pure in-memory database as the <strong>BitDew</strong>backend data store during the experiments; the actualperformance bottleneck <strong>of</strong> both systems is due to thesynchronization overhead <strong>of</strong> highly concurrent RPCinvocations. The <strong>Hadoop</strong> team also reported a similarscalability issue that occurs when the cluster size reaches upto tens or hundreds <strong>of</strong> thous<strong>and</strong>s <strong>of</strong> nodes. A feasiblesolution is replacing the threads based RPC model with theevent-driven asynchronous IO model.B. Fault ToleranceTable I shows the jobs’ make-span time <strong>and</strong> the number<strong>of</strong> re-executed map tasks in fault tolerance scenario. In the<strong>Hadoop</strong> case: for the first test, whenever we kill the runningchild tasks on 25 nodes, the JobTracker just re-schedules the50 killed map tasks <strong>and</strong> prolongs the job make span time forabout 6.5% in contrast to the normal case. For the second test,the JobTracker blindly re-executes all successfullycompleted <strong>and</strong> progressing map tasks on the failedTaskTrackers. Which indicates that all 25 chosen workernodes just contribute zero to the whole job executionprogress, resulting the job make-span time is almost doubledin contrast to the baseline. Finally, when killing all the Javaprocesses on half <strong>of</strong> the worker nodes, jobs just fail due tothe permanently loss <strong>of</strong> input chunks.On the other h<strong>and</strong>, <strong>BitDew</strong>-MR avoids substantialunnecessary fault tolerant works. Because, in <strong>BitDew</strong>-MR,the intermediate outputs <strong>of</strong> completed map tasks are safelystored on the stable central storage server, thus, the masterdoes not re-execute the successfully completed map tasks <strong>of</strong>failed workers. However, the main reason <strong>of</strong> the additionaljobs’ make-span time in <strong>BitDew</strong>-MR when worker nodesfailure is the loss <strong>of</strong> half <strong>of</strong> the total amount <strong>of</strong> computingresources <strong>and</strong> the waiting time needed for re-downloadingthe input chunks to the survived worker nodes.C. Host ChurnAs Table II shows, for the tests <strong>of</strong> 5, 10, <strong>and</strong> 25 seconds<strong>of</strong> host churn intervals, <strong>Hadoop</strong> jobs could only progress upto the 80% <strong>of</strong> the map phase before they fail. The reason isthat when the job enters the last stage, a great mass <strong>of</strong> inputfile chunks concentrate to the few rest old survival workernodes. When new nodes join, they can only afford a smallfraction <strong>of</strong> chunks. Eventually, HDFS cannot maintain thereplica level resulting in permanently loss <strong>of</strong> data. For thetests <strong>of</strong> 30 <strong>and</strong> 50 seconds <strong>of</strong> interval, once an old workerleaves; the JobTracker will re-assign all the completed map
tasks <strong>of</strong> it to other nodes, which significantly delays the totaljob execution time.TABLE II.PERFORMANCE EVALUATION OF HOST CHURN SCENARIOChurn Interval (sec.) 5 10 25 30 50<strong>Hadoop</strong> job makespan(sec.)<strong>BitDew</strong>-MR jobmake-span (sec.)failed failed failed 2357 1752457 398 366 361 357Similar to fault tolerance scenario, the <strong>BitDew</strong>-MRruntime does not waste the completed works done by theeventually failed worker nodes, therefore the host churnexerts very little effects on the jobs’ execu ion performance.D. Network ConnectivityIn this test, <strong>Hadoop</strong> could not even launch a job becausethe HDFS needs inter-communication between twoDataNodes. On the other h<strong>and</strong>, <strong>BitDew</strong>-MR works properly<strong>and</strong> the performance is almost the same as the baseline in thenormal case <strong>of</strong> network conditions.E. CPU Heterogeneity <strong>and</strong> StragglerAs Figure 5 shows, <strong>Hadoop</strong> works very well withdynamic task scheduling approach when worker nodes havedifferent classes <strong>of</strong> CPU. Nodes from the fast group process20 tasks on average <strong>and</strong> the ones from the slow group getabout 11 tasks. Although, <strong>BitDew</strong>-MR has same schedulingheuristic but it does not perform well according to Figure 6.The nodes from the two groups get almost the same number<strong>of</strong> tasks. The reason is that we only maintain one chunk copyon the worker nodes for the sake <strong>of</strong> the assumption that thereare no inter-worker communication <strong>and</strong> data transfer. Thus,although fast nodes spend half <strong>of</strong> time to process their localchunks compare to the slow nodes, they still need to takemuch time to download new chunks before launchingadditional map tasks.TABLE III.PERFORMANCE EVALUATION OF STRAGGLERS SCENARIOStraggler Number 1 2 5 10<strong>Hadoop</strong> job makespan(sec.)<strong>BitDew</strong>-MR jobmake-span (sec.)477 481 487 490211 245 267 298Figure 5. <strong>Hadoop</strong> map task distribution over 50 workers.Figure 6. <strong>BitDew</strong>-<strong>MapReduce</strong> map task distribution over 50 workers.F. Network Failure ToleranceIn case <strong>of</strong> network failures, as shown in Table IV,<strong>Hadoop</strong> JobTracker just marks all the temporarydisconnected nodes as “dead” - although they are stillrunning tasks, <strong>and</strong> blindly removes all the tasks done bythese nodes from the successful task list. Re-executing thesetasks significantly prolongs the job make-span. Meanwhile,the <strong>BitDew</strong>-MR clearly allows workers to go temporarily<strong>of</strong>fline without any performance penalty.The key idea behind map tasks re-execution avoidancewhich makes <strong>BitDew</strong>-MR outperforms <strong>Hadoop</strong> undermachine <strong>and</strong> network failure scenarios is allowing reducetasks to re-download map outputs that have already beenuploaded to the central stable storage rather than re-generatethem. Another benefit <strong>of</strong> this method is that it does notintroduce any extra overhead since all the intermediate datashould be always transferred through the central storageregardless <strong>of</strong> whether or not use the fault tolerant strategy.However, the overhead <strong>of</strong> data transfer to the central stablestorage makes desktop grid more suitable for the applicationswhich generate a few intermediate data, such as Word Count<strong>and</strong> Distributed Grep. To mitigate the data transfer overhead,we can use a storage cluster with large aggregated b<strong>and</strong>width.The emerging public cloud storage services also provide analternative solution, which can be included in our futurework.VI.RELATED WORKThere have been many studies on improving <strong>MapReduce</strong>performance [17, 18, 19, 28] <strong>and</strong> exploring ways to support<strong>MapReduce</strong> on different architectures [16, 22, 23, 26]. Aclosely related work is MOON [23] which st<strong>and</strong>s for<strong>MapReduce</strong> On Opportunistic eNvironments. Unlike ourwork, MOON limits the system scale within a campus area<strong>and</strong> assumes the underlying resources are hybrid <strong>and</strong>organized by provisioning a fixed fraction <strong>of</strong> dedicated stablecomputers to supplement other volatile personal computers,which is much more difficult to implement in the Internetscale desktop grids. The main idea <strong>of</strong> MOON is prioritizingnew tasks <strong>and</strong> important data blocks <strong>and</strong> assigning them tothe dedicated stable machines to guarantee smoothlyprogressing <strong>of</strong> jobs even many volatile PCs join <strong>and</strong> leavethe system dynamically. MOON also makes some tricky
TABLE IV.PERFORMANCE EVALUATION OF NETWORK FAULT TOLERANCE SCENARIOJob progress <strong>of</strong> the crash points 12.5% 25% 37.5% 50% 62.5% 75% 87.5% 100%<strong>Hadoop</strong><strong>BitDew</strong>-MRRe-executed map tasks 50 100 150 200 250 300 350 400Job make-span (sec.) 425 468 479 512 536 572 589 601Re-executed map tasks 0 0 0 0 0 0 0 0Job make-span (sec.) 246 249 243 239 254 257 274 256modifications to <strong>Hadoop</strong> in order to solve the problem thatthe heartbeat reporting <strong>and</strong> data serving <strong>of</strong> native <strong>Hadoop</strong>worker daemons can be blocked by the PC users’ actions,this is not an issue for the systems that originally designedfor volunteer computing. Ko et al. [22] replicates inter<strong>and</strong>inner- job intermediate data among workers throughlow priority TCP transfers to utilize idle networkb<strong>and</strong>width. We focus on inner-job intermediate dataavailability in this paper <strong>and</strong> only replicate them on centralstorage for the sake <strong>of</strong> prohibition <strong>of</strong> inter-workercommunication <strong>of</strong> desktop grids.There are existing works on simulation <strong>and</strong> emulation<strong>of</strong> distributed systems. Well known general-purpose gridsimulators include GridSim [4] <strong>and</strong> SimGrid [25].OptorSim [6] focuses on studying <strong>and</strong> validating dynamicreplication techniques. Simulation is commonly strongenough for designing <strong>and</strong> validating algorithms but not forevaluating real large-scale distributed systems. EmBOINC[13] uses a hybrid approach that simulates the population<strong>of</strong> volunteered BOINC clients. We use the samemethodology to evaluate the scalability <strong>of</strong> <strong>BitDew</strong> servicesusing one hundred nodes to simulate a huge number <strong>of</strong>concurrent clients. Wrekavoc [8] is a heterogeneityemulator that controls environment by degrading the nodes’performance that is similar to our approach, which is usedin the heterogeneity scenarios.Kondo et al. [21] measures a real enterprise desktopgrid to analyze how the temporal characteristics <strong>of</strong> PCsaffect the utility <strong>of</strong> desktop grids. Javadi et al. [20] usesclustering methods to identify hosts whose availability isindependent <strong>and</strong> identically distributed according to theavailability traces from real systems. Nurmi et al. [12]develops an automatic method for modeling theavailability <strong>of</strong> Internet resources. The traces <strong>and</strong> modelsextracted from the real environment can be used as theworkload input for more strict <strong>and</strong> accurate evaluation <strong>of</strong>the availability aware task-scheduling algorithm, which isalso one <strong>of</strong> our future directions on <strong>BitDew</strong>-MR.VII. CONCLUSIONSDesktop grid computing <strong>of</strong>fers vast amount <strong>of</strong>computing resources, which can be efficiently used forrunning scientific applications. However, as data generatedfrom scientific instruments are continuously increasing,many efforts are done on utilizing Desktop Grid for dataintensiveapplications. Accordingly, in this paper, weextend our <strong>BitDew</strong>-MR framework <strong>and</strong> added newfeatures including: aggressive task backup, intermediateresults replication, task re-execution avoidance, <strong>and</strong>network latency hiding optimization with the aim atfacilitating the usage <strong>of</strong> large-scale desktop grid. We thendesign a new experimental framework which emulates keyfundamental aspects <strong>of</strong> Internet desktop grid to validate<strong>and</strong> evaluate <strong>BitDew</strong>-MR against <strong>Hadoop</strong>.Our evaluation results demonstrates that: 1) <strong>BitDew</strong>-MR successfully passes all the stress-tests <strong>of</strong> theframework while <strong>Hadoop</strong> is unable to work in typicalwide-area network topology which includes PC hiddenbehind firewall <strong>and</strong> NAT; 2) <strong>BitDew</strong>-MR outperforms<strong>Hadoop</strong> performances on several aspects: scalability,fairness, resilience to node failures, <strong>and</strong> networkdisconnections.ACKNOWLEDGMENTExperiments presented in this paper were carried outusing the Grid5000 experimental test bed, being developedunder the INRIA ALADDIN development action withsupport from CNRS, RENATER <strong>and</strong> several universitiesas well as other funding bodies (seehttps://www.grid5000.fr).This work is supported by the NSFC under grant Nos.61133008, 60973037, National Science <strong>and</strong> TechnologyPillar Program under grant 2012BAH14F02, WuhanChenguang Program under grant No. 201050231075,MOE-Intel Special Research Fund <strong>of</strong> InformationTechnology under grant MOE-INTEL-2012-01, <strong>and</strong> theAgence National de la Recherche under contract ANR-10-SEGI-001.REFERENCES[1] Apache <strong>Hadoop</strong>. Available: http://hadoop.apache.org/[2] D. P. Anderson, "BOINC: a system for public-resource computing<strong>and</strong> storage," in Proceedings <strong>of</strong> 5th IEEE/ACM InternationalWorkshop on Grid Computing (GRID’04), 2004.[3] D. P. Anderson <strong>and</strong> G. Fedak, "The Computational <strong>and</strong> StoragePotential <strong>of</strong> Volunteer Computing," in Proceedings <strong>of</strong> 6th IEEEInternational Symposium on Cluster Computing <strong>and</strong> the Grid(CCGrid’06), 2006[4] R. Buyya <strong>and</strong> M. M. Murshed, “GridSim: A Toolkit for theModeling <strong>and</strong> Simulation <strong>of</strong> Distributed Resource Management<strong>and</strong> Scheduling for Grid Computing.,” in CoRR, 2002.[5] T. Bing, M. Moca, S. Chevalier, H. Haiwu, <strong>and</strong> G. Fedak,"Towards <strong>MapReduce</strong> for Desktop Grid Computing," inProceedings <strong>of</strong> Fifth International Conference on P2p, Parallel,Grid, Cloud <strong>and</strong> Internet Computing (3PGCIC’10), 2010.[6] W. H. Bell, D. G. Cameron, L. Capozza, A. P. Millar, K.Stockinger, <strong>and</strong> F. Zini, “OptorSim - A Grid Simulator forStudying Dynamic Data Replication Strategies,” InternationalJournal <strong>of</strong> High Performance Computing Applications, 17(4),2003.
[7] F. Cappello, S. Djilali, G. Fedak, T. Herault, F. Magniette, V.N´eri, <strong>and</strong> O. Lodygensky, “Computing on large-scale distributedsystems: Xtremweb architecture, programming models, security,tests <strong>and</strong> convergence with grid,” Future Generation ComputerSystems, vol. 21, pp. 417–437, 2005.[8] L. C. Canon <strong>and</strong> E. Jeannot, "Wrekavoc: a tool for emulatingheterogeneity," in Proceedings <strong>of</strong> 20th International Parallel <strong>and</strong>Distributed Processing Symposium (IPDPS’06), 2006.[9] S. Chen, <strong>and</strong> S. W. Schlosser, “Map-Reduce Meets WiderVarieties <strong>of</strong> Applications,” IRP-TR-08-05, Technical Report, IntelResearch Pittsburgh, May, 2008[10] T. Condie, N.Conway, P. Alvaro, J. M. Hellerstein, K. Elmeleegy,<strong>and</strong> R. Sears, “<strong>MapReduce</strong> Online,” in Proceedings <strong>of</strong> 7th USENIXSymposium on Networked Systems Design <strong>and</strong> Implementation(NSDI’10), 2010.[11] J. Dean <strong>and</strong> S. Ghemawat, "Mapreduce: Simplified data processingon large clusters," Communications <strong>of</strong> the ACM, vol. 51, pp. 107-113, Jan 2008.[12] D. Nurmi, J. Brevik, <strong>and</strong> R. Wolski, "Modeling MachineAvailability in Enterprise <strong>and</strong> Widearea Distributed ComputingEnvironments," in Proceedings <strong>of</strong> 11th International Euro-ParConference (EuroPar’05), 2005.[13] T. Estrada, M. Taufer, K. Reed, <strong>and</strong> D. P. Anderson, "EmBOINC:An emulator for performance analysis <strong>of</strong> BOINC projects," inProceedings <strong>of</strong> 23rd IEEE International Symposium on Parallel<strong>and</strong> Distributed Processing (IPDPS’09), 2009.[14] G. Fedak, H. Haiwu, <strong>and</strong> F. Cappello, "<strong>BitDew</strong>: A programmableenvironment for large-scale data management <strong>and</strong> distribution," inProceedings <strong>of</strong> the International Conference on High PerformanceComputing, Networking, Storage <strong>and</strong> Analysis (SC’08), 2008.[15] S. Ghemawat, H. Gobi<strong>of</strong>f, <strong>and</strong> S.-T. Leung, "The Google filesystem," in Proceedings <strong>of</strong> 19th ACM Symposium on OperatingSystems Principles (SOSP’03), 2003.[16] B. He, W. Fang, Q. Luo, N. K. Govindaraju, <strong>and</strong> T. Wang, "Mars:a <strong>MapReduce</strong> framework on graphics processors," in Proceedings<strong>of</strong> The Seventeenth International Conference on ParallelArchitectures <strong>and</strong> Compilation Techniques (PACT’08), 2008.[17] X. Huaxia, H. Dail, H. Casanova, <strong>and</strong> A. A. Chien, "Theperformance <strong>of</strong> <strong>MapReduce</strong>: an in-depth study," in Proceedings <strong>of</strong>36th International Conference on Very Large Data Bases(VLDB’10), 2010.[18] S. Ibrahim, H. Jin, L. Lu, B. He, G. Antoniu <strong>and</strong> S. Wu, “Maestro:Replica-Aware Map Scheduling for <strong>MapReduce</strong>,” in Proceedings<strong>of</strong> The 12th IEEE/ACM International Symposium on Cluster,Cloud <strong>and</strong> Grid Computing (CCGrid’12), 2012.[19] S. Ibrahim, H. Jin, L. Lu, B. He, <strong>and</strong> S. Wu, “Adaptive disk i/oscheduling for mapreduce in virtualized environment,” inProceedings <strong>of</strong> 2011 International Conference on ParallelProcessing (ICPP’11), 2011[20] B. Javadi, D. Kondo, J. Vincent, <strong>and</strong> D. P. Anderson, “Mining forStatistical Models <strong>of</strong> Availability in LargeScale DistributedSystems: An Empirical Study <strong>of</strong> SETI@home”, In Proceedings <strong>of</strong>17th IEEE/ACM International Symposium on Modelling, Analysis<strong>and</strong> Simulation <strong>of</strong> Computer <strong>and</strong> Telecommunication Systems(MASCOTS’09), 2009.[21] D. Kondo, M. Taufer, C. L. Brooks, H. Casanova, <strong>and</strong> A. A.Chien, "Characterizing <strong>and</strong> evaluating desktop grids: an empiricalstudy," in Proceedings <strong>of</strong> 18th IEEE International Symposium onParallel <strong>and</strong> Distributed Processing (IPDPS’04), 2004.[22] S. Y. Ko, I. Hoque, B. Cho, <strong>and</strong> I. Gupta, “Making CloudIntermediate Data Fault-Tolerant”, in Proceedings <strong>of</strong> ACMSymposium on Cloud Computing (SOCC’10), 2010[23] H. Lin, X. Ma, J. Archuleta, W. C. Feng, M. Gardner, <strong>and</strong> Z.Zhang, "MOON: <strong>MapReduce</strong> On Opportunistic eNvironments," inProceedings <strong>of</strong> 19th International Symposium on HighPerformance Distributed Computing (HPDC’10), 2010.[24] M. Moca, G. C. Silaghi, <strong>and</strong> G. Fedak, "Distributed ResultsChecking for <strong>MapReduce</strong> in Volunteer Computing," inProceedings <strong>of</strong> 2011 IEEE International Symposium on Parallel<strong>and</strong> Distributed Processing Workshops <strong>and</strong> Phd Forum(IPDPSW’11), 2011.[25] M. Quinson, "SimGrid: a generic framework for large-scaledistributed experiments," in Proceedings <strong>of</strong> Ninth InternationalConference on Peer-to-Peer Computing (P2P’09), 2009.[26] C. Ranger, R. Raghuraman, A. Penmetsa, G. Bradski, <strong>and</strong> C.Kozyrakis, "Evaluating <strong>MapReduce</strong> for Multi-core <strong>and</strong>Multiprocessor Systems," in Proceedings <strong>of</strong> 13st InternationalConference on High-Performance Computer Architecture(HPCA’07), 2007.[27] D. Thain, T. Tannenbaum, <strong>and</strong> M. Livny, "Distributed Computingin Practice: The Condor Experience," Concurrency <strong>and</strong>Computation: Practice <strong>and</strong> Experience, Vol. 17, No. 2-4, pp. 323-356, February-April, 2005.[28] M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, <strong>and</strong> I. Stoica,"Improving <strong>MapReduce</strong> Performance in HeterogeneousEnvironments," in Proceedings <strong>of</strong> 8th USENIX Symposium onOperating Systems Design <strong>and</strong> Implementation (OSDI’08), 2008.