


Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
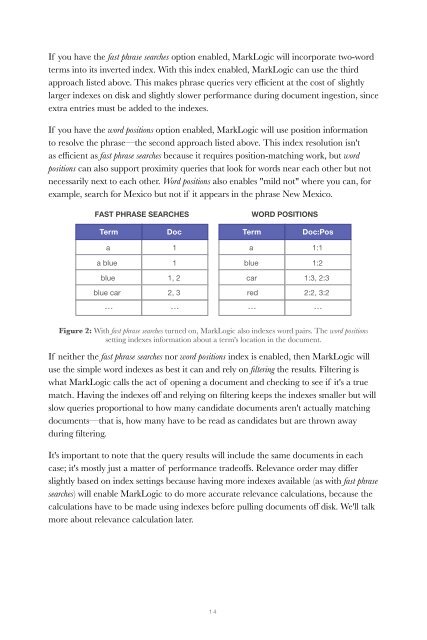
If you have the fast phrase searches option enabled, MarkLogic will incorporate two-word<br />
terms into its inverted index. With this index enabled, MarkLogic can use the third<br />
approach listed above. This makes phrase queries very efficient at the cost of slightly<br />
larger indexes on disk and slightly slower performance during document ingestion, since<br />
extra entries must be added to the indexes.<br />
If you have the word positions option enabled, MarkLogic will use position information<br />
to resolve the phrase—the second approach listed above. This index resolution isn't<br />
as efficient as fast phrase searches because it requires position-matching work, but word<br />
positions can also support proximity queries that look for words near each other but not<br />
necessarily next to each other. Word positions also enables "mild not" where you can, for<br />
example, search for Mexico but not if it appears in the phrase New Mexico.<br />
FAST PHRASE SEARCHES<br />
WORD POSITIONS<br />
Term Doc<br />
Term Doc:Pos<br />
a 1<br />
a blue 1<br />
blue<br />
1, 2<br />
blue car 2, 3<br />
…<br />
…<br />
a 1:1<br />
blue 1:2<br />
car<br />
1:3, 2:3<br />
red 2:2, 3:2<br />
…<br />
…<br />
Figure 2: With fast phrase searches turned on, MarkLogic also indexes word pairs. The word positions<br />
setting indexes information about a term's location in the document.<br />
If neither the fast phrase searches nor word positions index is enabled, then MarkLogic will<br />
use the simple word indexes as best it can and rely on filtering the results. Filtering is<br />
what MarkLogic calls the act of opening a document and checking to see if it's a true<br />
match. Having the indexes off and relying on filtering keeps the indexes smaller but will<br />
slow queries proportional to how many candidate documents aren't actually matching<br />
documents—that is, how many have to be read as candidates but are thrown away<br />
during filtering.<br />
It's important to note that the query results will include the same documents in each<br />
case; it's mostly just a matter of performance tradeoffs. Relevance order may differ<br />
slightly based on index settings because having more indexes available (as with fast phrase<br />
searches) will enable MarkLogic to do more accurate relevance calculations, because the<br />
calculations have to be made using indexes before pulling documents off disk. We'll talk<br />
more about relevance calculation later.<br />
14