Técnicas Estad´ısticas y Neuronales de Agrupamiento Adaptativo ...
Técnicas Estad´ısticas y Neuronales de Agrupamiento Adaptativo ...
Técnicas Estad´ısticas y Neuronales de Agrupamiento Adaptativo ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Técnicas Estadísticas y <strong>Neuronales</strong> <strong>de</strong><br />
<strong>Agrupamiento</strong> <strong>Adaptativo</strong> para la Predicción<br />
Probabilística <strong>de</strong> Fenómenos Meteorológicos<br />
Locales. Aplicación en el Corto Plazo y en la<br />
Predicción Estacional.<br />
Tesis Doctoral<br />
Presentada por<br />
D. Antonio S. Cofiño González<br />
bajo la dirección <strong>de</strong><br />
Dr. José M. Gutiérrez<br />
en el<br />
Dpto. <strong>de</strong> Matemática Aplicada y Ciencias <strong>de</strong> la Computación.<br />
E.T.S.I. Caminos, Canales y Puertos<br />
<strong>de</strong> la<br />
Universidad <strong>de</strong> Cantabria.<br />
Santan<strong>de</strong>r, Octubre <strong>de</strong> 2003
Statistical and Neural Adaptive Clustering<br />
Downscaling Techniques in Meteorology.<br />
Application to Short-Range and Seasonal Forecast.<br />
Antonio S. Cofiño<br />
antonio.cofino@unican.es<br />
Dept. of Applied Mathematics and Computer Science<br />
University of Cantabria<br />
2003 Santan<strong>de</strong>r, Spain
Prefacio<br />
Des<strong>de</strong> comienzos <strong>de</strong>l siglo XX, el problema <strong>de</strong> la predicción meteorológica<br />
se ha abordado <strong>de</strong> forma numérica, utilizando mo<strong>de</strong>los <strong>de</strong> circulación<br />
atmosférica (sistemas <strong>de</strong> ecuaciones en <strong>de</strong>rivadas parciales, o aproximaciones<br />
<strong>de</strong> estos) integrados sobre rejillas espaciales apropiadas, y a partir <strong>de</strong><br />
unas condiciones iniciales conocidas. La predicción numérica se vió favorecida<br />
con el comienzo <strong>de</strong> la era <strong>de</strong> los or<strong>de</strong>nadores en la década <strong>de</strong> los 50, y<br />
por los sucesivos avances computacionales, que han producido una evolución<br />
vertiginosa en la predicción numérica <strong>de</strong>l tiempo. A partir <strong>de</strong>l estado futuro<br />
<strong>de</strong> la atmósfera predicho por el mo<strong>de</strong>lo, los predictores humanos ofrecen<br />
diariamente pronósticos regionales y locales, en los núcleos <strong>de</strong> población,<br />
y <strong>de</strong> fenómenos meteorológicos <strong>de</strong> interés, principalmente fenómenos producidos<br />
en superficie (meteoros como precipitación, temperatura, etc.). Por<br />
otra parte, se han realizado intentos <strong>de</strong> pre<strong>de</strong>cir meteoros locales aplicando<br />
directamente técnicas estadísticas a los registros históricos <strong>de</strong> observaciones<br />
disponibles <strong>de</strong> estos fenómenos (mo<strong>de</strong>los auto-regresivos, etc.). Sin embargo,<br />
para <strong>de</strong>terminados elementos meteorológicos (especialmente los relacionados<br />
con la humedad y precipitación) estas técnicas tienen gran<strong>de</strong>s limitaciones.<br />
Por una parte <strong>de</strong>bido a la resolución <strong>de</strong> los mo<strong>de</strong>los numéricos que no permiten<br />
obtener predicciones locales precisas en puntos geográficos <strong>de</strong> interés.<br />
Y por otra parte, los mo<strong>de</strong>los estadísticos no incluyen suficiente información<br />
sobre los fenómenos físicos que intervienen en estos procesos, por ello, se<br />
han mostrado ineficientes <strong>de</strong>s<strong>de</strong> un punto <strong>de</strong> vista operativo.<br />
Por tanto, la predicción local <strong>de</strong> fenómenos meteorológicos y la mejora<br />
<strong>de</strong> la resolución <strong>de</strong> las salidas <strong>de</strong> los mo<strong>de</strong>los numéricos (pue<strong>de</strong> interpretarse<br />
como una interpolación) son problemas <strong>de</strong> gran interés tanto teórico como<br />
práctico. A<strong>de</strong>más los distintos sectores económicos pue<strong>de</strong>n verse favorecidos<br />
por los avances en este área (a la aplicación <strong>de</strong> predicción <strong>de</strong> cosechas,<br />
<strong>de</strong>sastres naturales, etc.). En la literatura científica los problemas anteriores<br />
se enmarcan en término inglés “downscaling” (disminución <strong>de</strong> escala, o<br />
aumento <strong>de</strong> resolución) que, en realidad, son problemas <strong>de</strong> interpolación, en<br />
los que se trata <strong>de</strong> obtener valores en puntos locales a partir <strong>de</strong> las salidas<br />
<strong>de</strong> baja resolución <strong>de</strong> los mo<strong>de</strong>los numéricos.<br />
Cada vez es mayor la disponibilidad <strong>de</strong> datos proce<strong>de</strong>ntes <strong>de</strong> observaciones<br />
(por ejemplo, la red <strong>de</strong> estaciones <strong>de</strong>l Instituto Nacional <strong>de</strong> Meteorología<br />
dispone <strong>de</strong> observaciones diarias en más <strong>de</strong> 6000 estaciones distribuidas<br />
iii
IV<br />
por la geografía española); estos datos proporcionan valiosa información estadística<br />
<strong>de</strong> la climatología local. También existen diferentes re-análisis <strong>de</strong><br />
mo<strong>de</strong>los numéricos que contienen las situaciones atmosféricas dadas por un<br />
mismo mo<strong>de</strong>lo numérico para un período suficientemente amplio <strong>de</strong> tiempo.<br />
(por ejemplo el re-análisis ERA-40 realizado por el ECMWF cubre <strong>de</strong>s<strong>de</strong> el<br />
año 1958, comienzo <strong>de</strong> la predicción numérica con or<strong>de</strong>nadores, hasta la actualidad).<br />
Y por último, también están disponibles diariamente numerosas<br />
predicciones numéricas, <strong>de</strong> la circulación atmosférica, realizadas por distintos<br />
centros meteorológicos. Con toda esta información se pue<strong>de</strong>n <strong>de</strong>sarrollar<br />
sofisticados mo<strong>de</strong>los <strong>de</strong> predicción local.<br />
En esta Tesis se presentan nuevos métodos híbridos <strong>de</strong> predicción local<br />
(downscaling) que combinan las salidas <strong>de</strong> los mo<strong>de</strong>los numéricos con la información<br />
estadística contenida en las observaciones locales. Para ello se han<br />
aplicado distintas técnicas estadísticas, tanto clásicas como mo<strong>de</strong>rnas, a este<br />
problema, estudiando la forma óptima <strong>de</strong> combinar esta información <strong>de</strong>s<strong>de</strong><br />
el punto <strong>de</strong> vista <strong>de</strong> la pericia y valor económico <strong>de</strong> los mo<strong>de</strong>los propuestos.<br />
También se han tratado <strong>de</strong> cubrir los tres aspectos necesarios para que el<br />
trabajo <strong>de</strong>sarrollado pueda ser accesible y útil al público general. En primer<br />
lugar, se ha llevado a cabo un estudio teórico que ha permitido <strong>de</strong>sarrollar<br />
métodos y algoritmos <strong>de</strong> predicción meteorológica local; <strong>de</strong>spués se ha trabajado<br />
en la implementación eficiente <strong>de</strong> los métodos resultantes utilizando<br />
software científico en el marco <strong>de</strong> las tecnologías actuales <strong>de</strong> la información;<br />
y finalmente, se ha llevado a cabo una puesta a punto operativa <strong>de</strong>l producto<br />
(contando con el apoyo <strong>de</strong>l Instituto Nacional <strong>de</strong> Meteorología) produciendo<br />
predicciones operativas <strong>de</strong>s<strong>de</strong> enero <strong>de</strong>l 2002, y realizando una validación<br />
exhaustiva <strong>de</strong> los resultados obtenidos.<br />
El trabajo presentado en esta Tesis ha sido <strong>de</strong>sarrollado <strong>de</strong>ntro <strong>de</strong>l grupo<br />
<strong>de</strong> investigación AIMet (Inteligencia Artificial en Meteorología) <strong>de</strong> la<br />
Universidad <strong>de</strong> Cantabria (http://grupos.unican.es/ai/meteo). El autor<br />
agra<strong>de</strong>ce la ayuda económica <strong>de</strong> la Universidad <strong>de</strong> Cantabria, <strong>de</strong>l Instituto<br />
Nacional <strong>de</strong> Meteorología (Ministerio <strong>de</strong> Medio Ambiente) y <strong>de</strong> la Dirección<br />
General <strong>de</strong> Ciencia y Tecnología en forma <strong>de</strong> becas y proyectos <strong>de</strong> investigación<br />
(MCYT REN2000-1572, REN2003-09853-C02-01). A<strong>de</strong>más agra<strong>de</strong>ce al<br />
Instituto Geofísico <strong>de</strong> Perú, al European Center for Medium-Range Weather<br />
Forecast (ECMWF) y al INM por la disponibilidad <strong>de</strong> datos, que ha<br />
permitido llevar a cabo este trabajo.<br />
Por último agra<strong>de</strong>cer a Blanca por estar siempre a mi lado apoyándome<br />
durante todos estos años, a Jose, Rafa, Miguel, Carmen y Cristina tanto<br />
por su amistad, como por su colaboración en el trabajo <strong>de</strong> esta Tesis, y a<br />
Enrique por su confianza. Por supuesto, reconocer el apoyo por parte <strong>de</strong><br />
mi familia, sin olvidar el <strong>de</strong> todos aquellos profesores, y no-profesores, que<br />
supieron <strong>de</strong>spertar en mi esa curiosidad por la Ciencia.<br />
Antonio S. Cofiño<br />
Santan<strong>de</strong>r, 20 <strong>de</strong> Septiembre <strong>de</strong> 2003
Índice general<br />
Prefacio<br />
III<br />
Índice general<br />
V<br />
1. Organización y Aportaciones <strong>de</strong> la Tesis 1<br />
1.1. Estructura <strong>de</strong> la Tesis . . . . . . . . . . . . . . . . . . . . . . 1<br />
1.2. Oportunidad <strong>de</strong> la Tesis . . . . . . . . . . . . . . . . . . . . . 2<br />
1.3. Principales Aportaciones . . . . . . . . . . . . . . . . . . . . . 3<br />
1.4. Trabajo Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . 6<br />
1.5. Algunos Acrónimos y Terminología Utilizados . . . . . . . . . 7<br />
I Estado <strong>de</strong>l Conocimiento 9<br />
2. Mo<strong>de</strong>los y Datos Atmosféricos 11<br />
2.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11<br />
2.2. Las Ecuaciones <strong>de</strong> la Atmósfera . . . . . . . . . . . . . . . . . 12<br />
2.2.1. Filtrado <strong>de</strong> Soluciones Triviales . . . . . . . . . . . . . 15<br />
2.3. Resolución Numérica <strong>de</strong> las Ecuaciones . . . . . . . . . . . . . 15<br />
2.3.1. Asimilación <strong>de</strong> Datos . . . . . . . . . . . . . . . . . . . 16<br />
2.3.2. Parametrización: Procesos Físicos <strong>de</strong> Escala Menor . . 17<br />
2.4. Tipos <strong>de</strong> Mo<strong>de</strong>los . . . . . . . . . . . . . . . . . . . . . . . . . 18<br />
2.4.1. Mo<strong>de</strong>los Globales <strong>de</strong> Circulación General . . . . . . . 19<br />
2.4.2. Mo<strong>de</strong>los Regionales . . . . . . . . . . . . . . . . . . . 20<br />
2.4.3. Mo<strong>de</strong>los Mesoscalares . . . . . . . . . . . . . . . . . . 21<br />
2.5. Estado Actual <strong>de</strong> la Predicción Operativa . . . . . . . . . . . 22<br />
2.6. Futuro <strong>de</strong> la Predicción Numérica . . . . . . . . . . . . . . . . 26<br />
2.7. Datos Climatológicos y Meteorológicos . . . . . . . . . . . . . 27<br />
2.7.1. Re<strong>de</strong>s <strong>de</strong> Observación . . . . . . . . . . . . . . . . . . 27<br />
v
VI<br />
ÍNDICE GENERAL<br />
2.7.2. Datos Paleoclimáticos . . . . . . . . . . . . . . . . . . 29<br />
2.7.3. Simulaciones <strong>de</strong> Mo<strong>de</strong>los Numéricos . . . . . . . . . . 30<br />
3. Minería <strong>de</strong> Datos y Aprendizaje Automático 33<br />
3.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33<br />
3.2. Componentes Principales . . . . . . . . . . . . . . . . . . . . 34<br />
3.2.1. Elección <strong>de</strong>l Número <strong>de</strong> Componentes . . . . . . . . . 40<br />
3.2.2. Efectos <strong>de</strong> la Escala Temporal . . . . . . . . . . . . . 42<br />
3.3. Técnicas <strong>de</strong> <strong>Agrupamiento</strong> . . . . . . . . . . . . . . . . . . . . 43<br />
3.3.1. Técnicas Jerárquicas . . . . . . . . . . . . . . . . . . . 43<br />
3.3.2. Técnicas Particionales . . . . . . . . . . . . . . . . . . 47<br />
3.4. Re<strong>de</strong>s Auto-Organizativas (SOM) . . . . . . . . . . . . . . . . 48<br />
3.5. Re<strong>de</strong>s <strong>Neuronales</strong> Multicapa . . . . . . . . . . . . . . . . . . . 55<br />
3.5.1. Estructura y Funcionamiento <strong>de</strong> las Re<strong>de</strong>s <strong>Neuronales</strong> 55<br />
3.5.2. Aprendizaje y Validación . . . . . . . . . . . . . . . . 57<br />
3.5.3. Perceptrones (Re<strong>de</strong>s <strong>de</strong> una Capa) . . . . . . . . . . . 58<br />
3.5.4. Perceptrones Multi-Capa . . . . . . . . . . . . . . . . 63<br />
4. Validación <strong>de</strong> Predicciones Probabilísticas 69<br />
4.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69<br />
4.2. Aspectos <strong>de</strong> la Calidad <strong>de</strong> una Predicción . . . . . . . . . . . 71<br />
4.3. Medidas <strong>de</strong> Validación <strong>de</strong> Predicciones Probabilísticas . . . . 74<br />
4.3.1. Brier Score . . . . . . . . . . . . . . . . . . . . . . . . 74<br />
4.3.2. Brier Skill Score . . . . . . . . . . . . . . . . . . . . . 75<br />
4.4. Validación <strong>de</strong> Predicciones Categóricas . . . . . . . . . . . . . 76<br />
II Aportaciones <strong>de</strong> la Tesis 85<br />
5. Predicción Local a Corto Plazo. Técnicas <strong>de</strong> <strong>Agrupamiento</strong> 87<br />
5.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87<br />
5.2. Técnicas Estadísticas para Series Temporales . . . . . . . . . 89<br />
5.2.1. Series Caóticas. Técnicas <strong>de</strong> Inmersión (Embedding). . 91<br />
5.3. Técnicas Híbridas (Downscaling Estadístico) . . . . . . . . . . 95<br />
5.3.1. Técnicas Globales Lineales y <strong>Neuronales</strong> . . . . . . . . 97<br />
5.3.2. Técnicas Locales basadas en Análogos . . . . . . . . . 98<br />
5.3.3. Comparación <strong>de</strong> Técnicas Estándar en el Corto Plazo 99<br />
5.4. Técnicas basadas en <strong>Agrupamiento</strong> y Clasificación . . . . . . 101<br />
5.4.1. Nuevo Método <strong>de</strong> Downscaling para el Corto Plazo . . 102<br />
5.4.2. Validación y Comparación con Otros Métodos . . . . . 104<br />
6. Predicción por Conjuntos. Re<strong>de</strong>s Auto-Organizativas 113<br />
6.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113<br />
6.2. Predictibilidad y Predicción por Conjuntos . . . . . . . . . . 114<br />
6.3. Aplicación <strong>de</strong> las Re<strong>de</strong>s Auto-Organizativas . . . . . . . . . . 117<br />
6.3.1. Medidas <strong>de</strong> Dispersión y Predictibilidad . . . . . . . . 120
ÍNDICE GENERAL<br />
VII<br />
6.4. Aplicación en la Predicción a Medio Plazo . . . . . . . . . . . 121<br />
6.5. Predicción Mensual y Estacional . . . . . . . . . . . . . . . . 126<br />
6.5.1. Predicción Local <strong>de</strong> Precipitación durante El Niño . . 130<br />
7. Implementación Operativa. PROMETEO 137<br />
7.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137<br />
7.2. Estructura <strong>de</strong> la Aplicación. Sistema Operativo en el INM . . 139<br />
7.2.1. Configuración e Inicialización <strong>de</strong>l Sistema . . . . . . . 139<br />
7.2.2. Explotación Operativa . . . . . . . . . . . . . . . . . . 142<br />
7.2.3. Acceso Web a las Predicciones . . . . . . . . . . . . . 144<br />
7.2.4. Proceso <strong>de</strong> validación. Retro-alimentación <strong>de</strong>l Sistema 149<br />
7.3. MeteoLab: Toolbox Meteorológica para Matlab . . . . . . . . 150<br />
7.4. Validación Operativa <strong>de</strong> Prometeo. . . . . . . . . . . . . . . . 154<br />
7.5. Computación Distribuida en la Web. Tecnología GRID . . . . 160<br />
7.5.1. Estructura <strong>de</strong> la tecnología GRID . . . . . . . . . . . 161<br />
7.5.2. Tecnologías GRID en Meteorología . . . . . . . . . . . 163<br />
7.5.3. Prometeo en un Entorno GRID . . . . . . . . . . . . . 164<br />
7.5.4. Paralelización GRID <strong>de</strong>l <strong>Agrupamiento</strong> . . . . . . . . 166<br />
Bibliografía 171
CAPÍTULO 1<br />
Organización y Aportaciones <strong>de</strong> la Tesis<br />
En este capítulo se <strong>de</strong>scribe la organización <strong>de</strong> la Tesis y se presentan<br />
las principales aportaciones <strong>de</strong> la misma, así como las futuras líneas <strong>de</strong><br />
investigación. También se analiza la oportunidad e interés <strong>de</strong> la investigación<br />
realizada en el marco actual <strong>de</strong> la predicción meteorológica.<br />
1.1. Estructura <strong>de</strong> la Tesis<br />
Esta Tesis está organizada en dos partes. La primera <strong>de</strong> ellas <strong>de</strong>scribe el<br />
estado <strong>de</strong>l conocimiento relativo a los temas tratados y está organizada en<br />
tres capítulos. El Capítulo 2 <strong>de</strong>scribe brevemente la mo<strong>de</strong>lización numérica<br />
<strong>de</strong> la atmósfera, prestando especial atención a las características <strong>de</strong> los<br />
mo<strong>de</strong>los operativos utilizados por los distintos servicios meteorológicos. En<br />
este capítulo también se <strong>de</strong>scriben los datos meteorológicos, tanto <strong>de</strong> salidas<br />
<strong>de</strong> mo<strong>de</strong>los como <strong>de</strong> observaciones, que serán utilizados en esta Tesis. El<br />
Capítulo 3 introduce algunas técnicas <strong>de</strong> análisis y manipulación estadística<br />
<strong>de</strong> estos datos (técnicas <strong>de</strong> minería <strong>de</strong> datos) que serán utilizadas para<br />
el <strong>de</strong>sarrollo <strong>de</strong> los mo<strong>de</strong>los locales <strong>de</strong> predicción; en este capítulo se hace<br />
énfasis en los métodos estadísticos y neuronales <strong>de</strong> agrupamiento que son<br />
utilizados posteriormente en el problema <strong>de</strong> la predicción local <strong>de</strong> fenómenos<br />
meteorológicos. Por último, el Capítulo 4 <strong>de</strong>scribe las principales medidas<br />
<strong>de</strong> validación utilizadas por la comunidad científica para pronósticos meteorológicos<br />
probabilísticos, sobre los que versa esta Tesis.<br />
En la segunda parte <strong>de</strong> la Tesis se <strong>de</strong>scriben las aportaciones realizadas<br />
en el campo <strong>de</strong> la predicción local <strong>de</strong> fenómenos meteorológicos. Esta<br />
parte está organizada en tres capítulos; el primero <strong>de</strong> ellos (Cap. 5) aborda<br />
el problema <strong>de</strong>s<strong>de</strong> la perspectiva <strong>de</strong> la predicción estadística local (downscaling<br />
estadístico) a corto plazo, mostrando un análisis comparativo <strong>de</strong> las<br />
distintas técnicas empleadas hasta la fecha y presentando un nuevo método<br />
1
2 1. ORGANIZACIÓN Y APORTACIONES DE LA TESIS<br />
basado en técnicas <strong>de</strong> agrupamiento adaptativo. En el Capítulo 6 se generaliza<br />
el método <strong>de</strong> downscaling estadístico anterior, utilizando re<strong>de</strong>s autoorganizativas<br />
para el problema <strong>de</strong> la predicción por conjuntos, trabajando<br />
en el marco <strong>de</strong> la predicción a medio plazo y estacional. Se muestra cómo las<br />
re<strong>de</strong>s auto-organizativas permiten interpretar <strong>de</strong> forma natural la dispersión<br />
<strong>de</strong> los miembros <strong>de</strong>l conjunto <strong>de</strong> predicciones, permitiendo introducir una<br />
medida <strong>de</strong> predictibilidad asociada a la predicción.<br />
Por último, el Capítulo 7 <strong>de</strong>scribe los <strong>de</strong>talles sobre la implementación<br />
<strong>de</strong> los métodos presentados en esta Tesis y las tecnologías utilizadas para<br />
su <strong>de</strong>sarrollo. El producto final es una herramienta genérica, fácilmente<br />
adaptable a distintos problemas <strong>de</strong>nominada PROMETEO. En particular se<br />
ilustra la adaptación <strong>de</strong> esta herramienta en el Instituto Nacional <strong>de</strong> Meteorología<br />
para la predicción local a corto plazo en una red <strong>de</strong> 2500 estaciones<br />
meteorológicas. También se estudia la adaptación <strong>de</strong> esta herramienta a un<br />
entorno GRID con el objetivo <strong>de</strong> hacer completamente interactivo su uso,<br />
paralelizando sobre la Web aquellas partes con mayor carga computacional.<br />
1.2. Oportunidad <strong>de</strong> la Tesis<br />
La predicción local con técnicas <strong>de</strong> aumento <strong>de</strong> resolución dinámica y<br />
estadística (downscaling) es actualmente una <strong>de</strong> las principales inquietu<strong>de</strong>s<br />
<strong>de</strong> la comunidad meteorológica internacional. Esta inquietud ha surgido, en<br />
parte, por la necesidad <strong>de</strong> trasladar a una escala regional los resultados obtenidos<br />
en numerosos proyectos que integran mo<strong>de</strong>los globales <strong>de</strong> circulación<br />
tanto en la predicción estacional como en la creación <strong>de</strong> posibles escenarios<br />
<strong>de</strong> cambio climático. Por otra parte, la aplicación <strong>de</strong> estos proyectos a distintos<br />
sectores <strong>de</strong> producción <strong>de</strong> la sociedad (agrario, industrial, energético,<br />
turismo, etc.) requiere trabajar con variables en superficie que involucran<br />
procesos físicos parametrizados en los mo<strong>de</strong>los numéricos, dificultando su<br />
predicción. A<strong>de</strong>más, la resolución necesaria para estas aplicaciones suele ser<br />
mucho mayor que la ofrecida por lo propios mo<strong>de</strong>los numéricos. Y por ello,<br />
las técnicas <strong>de</strong> downscaling son una pieza clave para po<strong>de</strong>r trasladar a los<br />
sectores <strong>de</strong> producción los resultados meteorológicos obtenidos por estos<br />
proyectos.<br />
Por ejemplo, proyectos llevados a cabo en el V Programa Marco <strong>de</strong> la UE<br />
han contemplado paquetes especiales para el <strong>de</strong>sarrollo y la implementación<br />
<strong>de</strong> técnicas <strong>de</strong> downscaling:<br />
DEMETER (Development of a European Multimo<strong>de</strong>l Ensemble system<br />
for seasonal to inTERannual prediction) que ha <strong>de</strong>sarrollado un<br />
sistema <strong>de</strong> predicción estacional multi-mo<strong>de</strong>lo:<br />
www.ecmwf.int/research/<strong>de</strong>meter/<br />
STARDEX (Statistical and Regional dynamical Downscaling of Extremes<br />
for European regions):<br />
www.cru.uea.ac.uk/cru/projects/star<strong>de</strong>x/
1.3. PRINCIPALES APORTACIONES 3<br />
A<strong>de</strong>más <strong>de</strong> haber jugado un papel importante hasta la fecha, las técnicas <strong>de</strong><br />
downscaling también seguirán <strong>de</strong>sempeñando un papel activo en el futuro<br />
cercano. Por ejemplo el proyecto integrado ENSEMBLES (ENSEMBLEbased<br />
Predictions of Climate Changes and their Impacts) <strong>de</strong>l VI Programa<br />
Marco <strong>de</strong> la UE (2004-2008) cuenta con paquetes <strong>de</strong> downscaling estadístico<br />
y dinámico. Es, por tanto, un momento idóneo para <strong>de</strong>sarrollar nuevas<br />
técnicas <strong>de</strong> downscaling que puedan ser capaces <strong>de</strong> adaptarse a distintas<br />
aplicaciones y rangos temporales. Todo esto lleva a afirmar que el trabajo<br />
<strong>de</strong>sarrollado en esta Tesis es oportuno en el contexto actual.<br />
Por otra parte, el trabajo llevado a cabo para la implementación operativa<br />
<strong>de</strong> los métodos <strong>de</strong>sarrollados se encuadra en el contexto actual <strong>de</strong> las tecnologías<br />
<strong>de</strong> la información. En el VI Programa Marco (www.mcyt.es/vipm/)<br />
se promueve la integración <strong>de</strong> la I+D europea para alcanzar masas críticas,<br />
lograr economías <strong>de</strong> escala y distribuir mejor los recursos disponibles. Se<br />
plantea la necesidad <strong>de</strong> interconectar centros <strong>de</strong> excelencia europeos y <strong>de</strong>sarrollar<br />
centros virtuales, así como <strong>de</strong> apoyar la creación, funcionamiento y<br />
acceso a gran<strong>de</strong>s infraestructuras. Existe por tanto una clara sintonía entre<br />
estos objetivos y el paradigma que plantea el GRID Computing analizado en<br />
esta Tesis (acceso a recursos computacionales distribuidos geográficamente<br />
a través <strong>de</strong> la red <strong>de</strong> alta velocidad). Esta ha sido una <strong>de</strong> las líneas temáticas<br />
priorizada en las primeras llamadas a proyectos <strong>de</strong>l VI programa marco, en<br />
concreto <strong>de</strong>ntro <strong>de</strong> la <strong>de</strong>nominación “Complex Problem Solving” don<strong>de</strong> la<br />
meteorología y biología tienen un papel predominante.<br />
1.3. Principales Aportaciones<br />
En esta Tesis se han <strong>de</strong>sarrollado, implementado, y validado nuevos<br />
métodos <strong>de</strong> predicción meteorológica local en distintas escalas temporales.<br />
Para ello se han combinando las salidas <strong>de</strong> los mo<strong>de</strong>los numéricos <strong>de</strong> la<br />
atmósfera, con la información estadística contenida en registros históricos<br />
locales (downscaling estadístico). En concreto, en este trabajo se ha <strong>de</strong>sarrollado<br />
un nuevo método aplicando las técnicas estadísticas y neuronales,<br />
<strong>de</strong> agrupamiento y clasificación, más apropiada para los distintos alcances<br />
temporales <strong>de</strong> la predicción: predicción a corto plazo (<strong>de</strong> uno a tres días),<br />
predicción a plazo medio (hasta 10 días) y predicción estacional (con meses<br />
<strong>de</strong> antelación). En los dos últimos casos los mo<strong>de</strong>los atmosféricos son sistemas<br />
<strong>de</strong> predicción por conjuntos, que caracterizan la incertidumbre asociada<br />
a las condiciones iniciales y a la imprecisión <strong>de</strong>l mo<strong>de</strong>lo, integrando el mismo<br />
para un conjunto <strong>de</strong> condiciones iniciales obtenidas perturbando la condición<br />
inicial. El método <strong>de</strong>sarrollado en este trabajo ha permitido caracterizar la<br />
predictibilidad (confianza) <strong>de</strong> cada situación a partir <strong>de</strong> la dispersión <strong>de</strong>l<br />
conjunto <strong>de</strong> predicciones sobre una red auto-organizativa. De esta forma,<br />
en el medio plazo y en la predicción estacional, el método resultante proporciona<br />
no sólo una predicción, sino una estimación <strong>de</strong> la confianza en<br />
la misma. Se muestran validaciones exhaustivas realizadas en la Península
4 1. ORGANIZACIÓN Y APORTACIONES DE LA TESIS<br />
Ibérica (latitu<strong>de</strong>s medias) y en Perú (latitu<strong>de</strong>s tropicales).<br />
En todo el <strong>de</strong>sarrollo <strong>de</strong> la Tesis se han tratado <strong>de</strong> cubrir los tres aspectos<br />
necesarios para que el trabajo final pueda ser operativo y accesible al público<br />
en general. En primer lugar, se ha llevado a cabo un estudio teórico que<br />
ha permitido <strong>de</strong>sarrollar métodos y algoritmos; a continuación, se ha trabajado<br />
en la implementación eficiente <strong>de</strong> los métodos resultantes utilizando<br />
software científico en el marco <strong>de</strong> las tecnologías actuales <strong>de</strong> la información;<br />
finalmente, se ha llevado a cabo una puesta a punto operativa <strong>de</strong>l producto,<br />
contando con el apoyo <strong>de</strong>l Instituto Nacional <strong>de</strong> Meteorología.<br />
A continuación se <strong>de</strong>scriben más en <strong>de</strong>talle las principales aportaciones<br />
realizadas:<br />
1. Se ha <strong>de</strong>sarrollado un nuevo método <strong>de</strong> predicción local (downscaling)<br />
para la predicción a corto plazo empleando una técnica <strong>de</strong> agrupamiento<br />
pon<strong>de</strong>rado basada en el algoritmo <strong>de</strong> k-medias. Este método<br />
es, computacionalmente, menos costoso y más eficiente, que el método<br />
estándar <strong>de</strong> análogos (vecinos cercanos) utilizado frecuentemente en la<br />
literatura. Se han llevado a cabo diversos experimentos <strong>de</strong> comparación<br />
con otras técnicas, consi<strong>de</strong>rando la precipitación y la racha máxima <strong>de</strong><br />
viento diarias sobre una red <strong>de</strong> 98 estaciones en la Península Ibérica, y<br />
un período <strong>de</strong> tiempo apropiado para que los resultados sean significativos<br />
(1998-99). Esta comparaciones han mostrado la superioridad <strong>de</strong>l<br />
nuevo método para la predicción <strong>de</strong> eventos <strong>de</strong> baja frecuencia (eventos<br />
raros o extremos) y un comportamiento similar para eventos más<br />
frecuentes (ver Cofiño et al., 2001a; Gutiérrez et al., 2004a).<br />
2. Se ha generalizado el método anterior, utilizando re<strong>de</strong>s auto-organizativas<br />
para trabajar con sistemas <strong>de</strong> predicción por conjuntos, <strong>de</strong> forma<br />
que, éstos <strong>de</strong>finen un histograma en la retícula <strong>de</strong> la red que permite<br />
caracterizar la dispersión <strong>de</strong> los miembros y llevar a cabo la predicción<br />
local <strong>de</strong> forma consistente. Con este esquema se ha <strong>de</strong>mostrado que<br />
existe una relación entre la dispersión <strong>de</strong> la red auto-organizativa (medida<br />
como suma <strong>de</strong> <strong>de</strong>sviación típica mas entropía <strong>de</strong> la probabilidad<br />
resultante) y el error <strong>de</strong> las predicciones, <strong>de</strong> forma que dispersiones<br />
gran<strong>de</strong>s tienen asociados errores mayores. Esta técnica se ha aplicado<br />
en:<br />
La predicción por conjuntos a medio plazo en la península Ibérica.<br />
En este caso se ha mostrado que las predicciones locales obtenidas<br />
son mejores para el caso <strong>de</strong> la predicción por conjuntos que las<br />
obtenidas por un mo<strong>de</strong>lo tradicional con un sólo miembro (ver<br />
Cofiño et al., 2003a).<br />
La predicción estacional latitu<strong>de</strong>s tropicales (más concretamente<br />
en Perú). En este caso se ha <strong>de</strong>mostrado que es posible pre<strong>de</strong>cir<br />
anomalías positivas <strong>de</strong> precipitación en eventos fuertes <strong>de</strong> El<br />
Niño. Este trabajo se ha llevando a cabo en el marco <strong>de</strong>l Proyecto
1.3. PRINCIPALES APORTACIONES 5<br />
DEMETERwww.ecmwf.int/research/<strong>de</strong>meter <strong>de</strong>l V Programa<br />
Marco (ver Cofiño et al., 2003d; Gutiérrez et al., 2004).<br />
3. Los algoritmos y métodos propuestos en esta Tesis, así como algunos<br />
algoritmos estándar, han sido implementados en un paquete (toolbox)<br />
<strong>de</strong> Matlab <strong>de</strong>nominado MeteoLab que permite diseñar fácilmente, en<br />
un entorno gráfico, diferentes tipos <strong>de</strong> experimentos <strong>de</strong> predicción local,<br />
y validar los resultados obtenidos. Este sistema pue<strong>de</strong> ser integrado<br />
fácilmente en el ciclo operativo <strong>de</strong> producción aplicado a un problema<br />
<strong>de</strong> predicción local particular. En concreto, trabajando en colaboración<br />
con el INM se ha <strong>de</strong>sarrollado un prototipo operativo (PROME-<br />
TEO) para la predicción local <strong>de</strong> distintos meteoros (precipitación,<br />
racha máxima <strong>de</strong> viento, nieve, tormenta, etc.) en 2500 estaciones distribuidas<br />
en las distintas cuencas hidrográficas Españolas. El sistema<br />
<strong>de</strong>sarrollado se encuentra operativo y produce un total <strong>de</strong> 160000 predicciones<br />
diarias (consultar meteo.macc.unican.es/prometeo).<br />
Para hacer accesibles estas predicciones al público en general, se ha<br />
<strong>de</strong>sarrollado una aplicación Web <strong>de</strong> forma que se puedan consultar las<br />
predicciones en tiempo real, y que incluso éstas puedan ser verificadas<br />
obteniendo distintos índices <strong>de</strong> calidad. Para ello, se ha hecho uso <strong>de</strong><br />
las tecnologías <strong>de</strong> la información vigentes que, por una parte, permiten<br />
acce<strong>de</strong>r a bases <strong>de</strong> datos (para almacenar las predicciones) y, por<br />
otra, permiten ejecutar la aplicación con unos parámetros concretos<br />
<strong>de</strong> interés (región geográfica, patrón atmosférico, etc...).<br />
Figura 1.1: Web <strong>de</strong> PROMETEO http://meteo.macc.unican.es/prometeo/<br />
4. También se han llevado a cabo los primeros experimentos utilizando la<br />
tecnología emergente GRID que permite acce<strong>de</strong>r <strong>de</strong> forma uniforme a
6 1. ORGANIZACIÓN Y APORTACIONES DE LA TESIS<br />
recursos <strong>de</strong> almacenamiento y computacionales distribuidos geográficamente<br />
por toda la Web (ver, como referencia, www.gridforum.org).<br />
Este entorno permite dotar <strong>de</strong> interactividad al sistema Prometeo <strong>de</strong>sarrollado,<br />
permitiendo que distintos usuarios puedan configurar en<br />
tiempo real la aplicación según sus necesida<strong>de</strong>s. Para ello, se ha paralelizado<br />
alguna <strong>de</strong> las partes más costosas <strong>de</strong>l sistema (en concreto<br />
las técnicas <strong>de</strong> agrupamiento) para analizar el comportamiento y las<br />
necesida<strong>de</strong>s en este nuevo entorno. Estos experimentos, <strong>de</strong>scritos en<br />
la Sección 7.5, han mostrado que ninguno <strong>de</strong> los esquemas <strong>de</strong> paralelización<br />
empleados es óptimo en todos los casos, sino que según las<br />
características <strong>de</strong> los recursos disponibles en el entorno <strong>de</strong> cada ejecución<br />
unos resultan más eficientes que otros (potencia <strong>de</strong> cálculo,<br />
memoria, latencias y anchos <strong>de</strong> banda <strong>de</strong> la red, etc.); esto plantea<br />
la necesidad <strong>de</strong> <strong>de</strong>sarrollar una nueva generación <strong>de</strong> técnicas <strong>de</strong> paralelización<br />
que se adapten a los recursos disponibles durante su ejecución.<br />
Este trabajo se está llevando a cabo en el marco <strong>de</strong>l Proyecto<br />
CrossGrid www.crossgrid.org <strong>de</strong>l V Programa Marco <strong>de</strong> la UE (ver<br />
Cofiño et al., 2003b; Gutiérrez et al., 2003).<br />
1.4. Trabajo Futuro<br />
El trabajo <strong>de</strong> esta Tesis tiene su continuidad en el proyecto integrado<br />
ENSEMBLES <strong>de</strong>l VI Programa Marco (2004-2008). Este proyecto reúne a<br />
los principales centros y grupos europeos <strong>de</strong> investigación meteorológica para<br />
abordar el problema <strong>de</strong> cambio climático y sus impactos, <strong>de</strong>sarrollando<br />
un sistema multi-mo<strong>de</strong>lo <strong>de</strong> predicción por conjuntos. El grupo <strong>de</strong> investigación<br />
<strong>de</strong> Inteligencia Artificial en Meteorología (AIMet) <strong>de</strong> la Universidad <strong>de</strong><br />
Cantabria participa en este proyecto, en el que, entre otras, se aplicarán las<br />
técnicas <strong>de</strong>sarrolladas en esta Tesis para la caracterización probabilística <strong>de</strong><br />
posibles escenarios <strong>de</strong> cambio climático. Por tanto, la principal línea futura<br />
<strong>de</strong> investigación será la adaptación <strong>de</strong> los métodos y herramientas <strong>de</strong>sarrollados<br />
a este marco <strong>de</strong> trabajo con nuevos alcances temporales, variables y<br />
características.<br />
Otra línea futura <strong>de</strong> investigación es analizar <strong>de</strong> forma más exhaustiva<br />
la conveniencia <strong>de</strong> distintas representaciones <strong>de</strong> los patrones atmosféricos<br />
utilizados en el trabajo (por ejemplo usando EOFs obtenidas <strong>de</strong> un análisis<br />
<strong>de</strong> correlación canónica y que, por tanto, no sean genéricas sino que estén<br />
asociadas con las observaciones). También el uso <strong>de</strong> ERA-40 como re-análisis<br />
<strong>de</strong> referencia y un estudio comparativo con el re-análisis ERA-15 usado en<br />
esta Tesis.<br />
También se planea seguir avanzando en el portal <strong>de</strong> la aplicación PRO-<br />
METEO, introduciendo las predicciones a medio plazo obtenidas con la red<br />
auto-organizativa. En esta dirección se seguirá <strong>de</strong>sarrollando y probando la<br />
aplicación GRID que permitirá evaluar la conveniencia actual <strong>de</strong> esta nueva<br />
tecnología en distintos problemas <strong>de</strong> meteorología .
1.5. ALGUNOS ACRÓNIMOS Y TERMINOLOGÍA UTILIZADOS 7<br />
1.5. Algunos Acrónimos y Terminología Utilizados<br />
ARPS. Advanced Regional Prediction System,www.caps.ou.edu/ARPS.<br />
BS. Brier Score; error cuadrático medio <strong>de</strong> la probabilidad predicha<br />
menos la probabilidad observada (ver Cap. 4).<br />
BSS. Brier Skill Score; índice <strong>de</strong> pericia que se obtiene como 1 −<br />
BSP/BSR, don<strong>de</strong> BSP es el BS <strong>de</strong> la predicción y BSR es el BS <strong>de</strong><br />
un sistema <strong>de</strong> referencia, normalmente la climatología (ver Cap. 4).<br />
COAMPS. US Navy‘s Coupled Ocean/Atmosphere Mesoscale Prediction<br />
System, www.nrlmry.navy.mil/projects/coamps.<br />
CP. Componente principal (ver Sec. 3.2).<br />
Downscaling. Mejora <strong>de</strong> resolución (o interpolación) <strong>de</strong> una predicción<br />
<strong>de</strong> un mo<strong>de</strong>lo numérico efectuada en una rejilla.<br />
ECMWF. Centro europeo para predicción a plazo medio (European<br />
Center for Medium-Range Weather Forecast), www.ecmwf.org.<br />
ENSO. Patrón <strong>de</strong> oscilación <strong>de</strong> El Niño-Pacífico Sur (El Niño-Southern<br />
Oscillation) (ver Sec. 3.2 y 6.5).<br />
EOF. Función empírica ortogonal (Empirical Ortogonal Function) (ver<br />
Sec. 3.2).<br />
EPS. Sistema <strong>de</strong> predicción por conjuntos (Ensemble Prediction System).<br />
HIRLAM. Mo<strong>de</strong>lo <strong>de</strong> área limitada <strong>de</strong> alta resolución (High Resolution<br />
Limited Area Mo<strong>de</strong>l) hirlam.knmi.nl.<br />
INM. Instituto Nacional <strong>de</strong> Meteorología, www.inm.es.<br />
LAN. Red <strong>de</strong> área local (Local Area Network).<br />
MM5. Penn State/NCAR Mesoscale Mo<strong>de</strong>l, box.mmm.ucar.edu/mm5.<br />
NAO. Oscilación <strong>de</strong>l Atlántico Norte (North Atlantic Oscillation) (ver<br />
Sec. 3.2 y 6.5).<br />
NCEP. National Centers for Environmental Prediction:<br />
www.ncep.noaa.gov.<br />
NHC. National Hurricane Center, www.nhc.noaa.gov.<br />
Patrón. Estructura numérica con una cierta organización <strong>de</strong> sus elementos<br />
(por ejemplo, una estructura matricial o tensorial relativa a<br />
una rejilla sobre una region geográfica concreta). Para su tratamiento<br />
matemático los patrones serán consi<strong>de</strong>rados vectores, <strong>de</strong>scomponiendo
8 1. ORGANIZACIÓN Y APORTACIONES DE LA TESIS<br />
su estructura <strong>de</strong> forma apropiada, y componiéndola <strong>de</strong> nuevo cuando<br />
sea necesario.<br />
Re-análisis. Experimento <strong>de</strong> simulación numérica <strong>de</strong> la circulación<br />
atmosférica para un largo período <strong>de</strong> tiempo con un mismo mo<strong>de</strong>lo<br />
numérico, asimilando toda la información disponible (ver Sec. 2.7.3).<br />
RMSE. Error cuadrático medio (Root Mean Square Error).<br />
ROC, curva. Relative Operating Characteristic. Curva obtenida a partir<br />
<strong>de</strong> los aciertos y las falsas alarmas <strong>de</strong> un sistema <strong>de</strong> predicción<br />
binario (ver Cap. 4).<br />
RSM. Mo<strong>de</strong>lo regional espectral <strong>de</strong>l NCEP (Regional Spectral Mo<strong>de</strong>l).<br />
SLP. Presión a nivel <strong>de</strong>l mar (Sea Level Pressure).<br />
SOM. Re<strong>de</strong>s auto-organizativas (Self-Organizing Maps) para agrupamiento<br />
y visualización <strong>de</strong> datos (ver sec. 3.4).<br />
SST. Temperatura <strong>de</strong> la superficie <strong>de</strong>l agua <strong>de</strong>l mar (Sea Surface Temperature).<br />
UTC. Coor<strong>de</strong>nadas universales <strong>de</strong> tiempo (Universal Time Coordinates).<br />
WAN. Red <strong>de</strong> área extendida (Wi<strong>de</strong> Area Network), en contraposición<br />
a las LAN.
Parte I<br />
Estado <strong>de</strong>l Conocimiento<br />
9
CAPÍTULO 2<br />
Mo<strong>de</strong>los y Datos Atmosféricos<br />
2.1. Introducción<br />
El esfuerzo investigador llevado a cabo en las tres últimas décadas ha permitido<br />
un gran avance en el <strong>de</strong>sarrollo <strong>de</strong> mo<strong>de</strong>los <strong>de</strong> circulación atmosférica<br />
que incorporan las parametrizaciones <strong>de</strong> los fenómenos físicos relevantes,<br />
a<strong>de</strong>cuados a las escalas espaciales a que dichos mo<strong>de</strong>los se aplican. Por otra<br />
parte, la aplicación operativa <strong>de</strong> estos mo<strong>de</strong>los ha sido posible gracias a la<br />
disponibilidad <strong>de</strong> mejores y más complejos sistemas <strong>de</strong> observación (subsistema<br />
<strong>de</strong> observación terrestre: SYNOP, SHIP, TEMP, AIREP, DRIBU,<br />
etc. y subsistema espacial: SATEM, SATOB, etc., disponibles varias veces<br />
al día). Estos datos observacionales pue<strong>de</strong>n ser asimilados en los mo<strong>de</strong>los<br />
gracias al <strong>de</strong>sarrollo y uso sucesivo <strong>de</strong> métodos <strong>de</strong> interpolación óptima y<br />
métodos <strong>de</strong> asimilación variacionales 3D y 4D, puestos a punto con el fin<br />
<strong>de</strong> establecer con la menor incertidumbre posible las condiciones iniciales a<br />
partir <strong>de</strong> las cuales se integran los mo<strong>de</strong>los <strong>de</strong> predicción.<br />
Como resultado <strong>de</strong> este esfuerzo, se dispone en la actualidad <strong>de</strong> eficientes<br />
mo<strong>de</strong>los atmosféricos que se utilizan para la elaboración <strong>de</strong> un amplio abanico<br />
<strong>de</strong> predicciones con distintos alcances temporales. Por una parte, para<br />
la predicción a corto y medio plazo se utilizan mo<strong>de</strong>los numéricos <strong>de</strong> área<br />
limitada y alta resolución; por otra, los mo<strong>de</strong>los acoplados océano-atmósfera<br />
<strong>de</strong> circulación general se aplican para la predicción <strong>de</strong> anomalías en la<br />
predicción estacional y para la preparación <strong>de</strong> escenarios climatológicos en<br />
función <strong>de</strong> diversos supuestos <strong>de</strong> forzamiento radiativo (duplicación <strong>de</strong>l nivel<br />
<strong>de</strong> CO 2 , etc.).<br />
En este capítulo se <strong>de</strong>scriben brevemente las características más importantes<br />
<strong>de</strong> los mo<strong>de</strong>los y procesos numéricos involucrados en la predicción<br />
numérica <strong>de</strong>l tiempo. Las salidas <strong>de</strong> estos mo<strong>de</strong>los se utilizan en el resto <strong>de</strong><br />
11
12 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
la Tesis como datos <strong>de</strong> entrada, o predictores, en los distintos métodos propuestos.<br />
En la Sección 2.2 se <strong>de</strong>scriben brevemente los principales procesos<br />
físicos que intervienen en la dinámica atmosférica. En la Sec. 2.3 se analizan<br />
algunos aspectos y limitaciones <strong>de</strong> la resolución numérica <strong>de</strong> estas ecuaciones.<br />
Por ejemplo, la Sec. 2.3.1 analiza el problema <strong>de</strong> la asimilación <strong>de</strong> datos,<br />
y la Sec. 2.3.2 <strong>de</strong>scribe las parametrizaciones introducidas en el mo<strong>de</strong>lo (y<br />
en la discretización <strong>de</strong>l esquema numérico) para incluir los procesos físicos<br />
<strong>de</strong> menor escala que escapan a la resolución <strong>de</strong> la discretización (turbulencia,<br />
etc.). En la Sec. 2.4 se <strong>de</strong>scriben las características (resolución, alcance,<br />
etc.) <strong>de</strong> los principales tipos <strong>de</strong> mo<strong>de</strong>los utilizados en predicción operativa,<br />
y en la Sec. 2.5 se <strong>de</strong>scribe el estado actual <strong>de</strong> las predicciones operativas<br />
que se obtienen diariamente con estos mo<strong>de</strong>los; por otra parte, la Sec. 2.6<br />
se comentan brevemente las líneas <strong>de</strong> mayor interés en este campo <strong>de</strong> cara<br />
al futuro. Finalmente, la Sección 2.7 <strong>de</strong>scribe los datos climatológicos (observaciones)<br />
y meteorológicos (simulaciones <strong>de</strong> mo<strong>de</strong>los) que se utilizan en<br />
esta Tesis.<br />
2.2. Las Ecuaciones <strong>de</strong> la Atmósfera<br />
El objetivo <strong>de</strong> esta sección es dar una breve <strong>de</strong>scripción <strong>de</strong> las ecuaciones<br />
que <strong>de</strong>scriben la dinámica <strong>de</strong> la atmósfera, con el único objetivo <strong>de</strong><br />
que proporcione al lector una visión general sobre la complejidad <strong>de</strong> los mo<strong>de</strong>los<br />
involucrados en la predicción numérica <strong>de</strong>l tiempo. Para un estudio<br />
<strong>de</strong>tallado, existen numerosos libros <strong>de</strong> meteorología dinámica con excelentes<br />
explicaciones y ejemplos <strong>de</strong> las <strong>de</strong>ducciones y <strong>de</strong>scripciones físicas <strong>de</strong><br />
las ecuaciones (ver, por ejemplo, Holton, 1992; Barry and Chorley, 1998;<br />
Kalnay, 2003).<br />
Des<strong>de</strong> un punto <strong>de</strong> vista físico, la atmósfera pue<strong>de</strong> ser consi<strong>de</strong>rada como<br />
una mezcla <strong>de</strong> gases y agua en sus distintos estados. Esta mezcla está en<br />
movimiento <strong>de</strong>ntro <strong>de</strong> un campo gravitatorio sobre una esfera en rotación y<br />
calentada por el Sol. En este sistema se <strong>de</strong>ben cumplir la ecuación <strong>de</strong> estado<br />
<strong>de</strong> los gases y las leyes <strong>de</strong> conservación <strong>de</strong> energía, masa y momento. Algunas<br />
<strong>de</strong> estas leyes se traducen en ecuaciones que relacionan las <strong>de</strong>rivadas<br />
totales <strong>de</strong> ciertas magnitu<strong>de</strong>s físicas en el tiempo. Estas <strong>de</strong>rivadas son normalmente<br />
<strong>de</strong>scompuestas en sus términos locales y advectivo. Por ejemplo,<br />
consi<strong>de</strong>rando el campo <strong>de</strong> velocida<strong>de</strong>s v = (u, v, w) asociado al sistema <strong>de</strong><br />
referencia (x, y, z) se tendrá:<br />
df<br />
dt = ∂f<br />
∂t + ∂f dx<br />
∂x dt + ∂f dy<br />
∂y dt + ∂f dz<br />
∂z dt = ∂f<br />
∂t<br />
+ v · ∇f (2.1)<br />
don<strong>de</strong> f(x, y, z, t). Esta ecuación indica que la <strong>de</strong>rivada total en el tiempo<br />
(Lagrangiana o individual) <strong>de</strong> una función, viene dada por la <strong>de</strong>rivada local<br />
en el tiempo (parcial, o Euleriana) mas los cambios <strong>de</strong>bidos al término <strong>de</strong><br />
advección.
2.2. LAS ECUACIONES DE LA ATMÓSFERA 13<br />
Según la ecuación <strong>de</strong> conservación <strong>de</strong> masa, la variación total en el<br />
tiempo <strong>de</strong> la masa en una parcela <strong>de</strong> aire es nula (dM/dt = 0). La<br />
masa <strong>de</strong> aire contenida en un volumen ∆x∆y∆z es:<br />
M = ρ∆x∆y∆z (2.2)<br />
don<strong>de</strong> ρ es la <strong>de</strong>nsidad <strong>de</strong>l aire. Consi<strong>de</strong>rando la ecuación<br />
1 dM<br />
M dt<br />
= 0, (2.3)<br />
sustituyendo (2.2) y aplicando (2.1) se tiene la ecuación <strong>de</strong> conservación<br />
<strong>de</strong> masa<br />
ya que ∂u/∂x = ∆x −1 d∆x/dt.<br />
1 dρ<br />
ρ dt + ∇ · v = 0 ⇔ ∂ρ = −∇ · (ρ v), (2.4)<br />
∂t<br />
La ecuación <strong>de</strong> conservación <strong>de</strong> vapor <strong>de</strong> agua indica que la cantidad<br />
total <strong>de</strong> vapor <strong>de</strong> agua en una parcela <strong>de</strong> aire se conserva, excepto<br />
cuando esta se mueve sobre fuentes (evaporación E) o sumi<strong>de</strong>ros (con<strong>de</strong>nsación<br />
C):<br />
dq<br />
dt = E − C (2.5)<br />
don<strong>de</strong> q es la proporción en masa <strong>de</strong> vapor <strong>de</strong> agua en la parcela <strong>de</strong><br />
aire (g/kg). Si a esta ecuación la multiplicamos por ρ, la expandimos<br />
según (2.1) y la sumamos la ecuación <strong>de</strong> conservación <strong>de</strong> masa (2.4)<br />
multiplicada por q, queda<br />
∂ρ q<br />
∂t<br />
= −∇ · (ρ v q) + ρ (E − C). (2.6)<br />
De la misma forma que se ha incluido una ecuación <strong>de</strong> conservación<br />
para el vapor <strong>de</strong> agua, se podría incluir cualquier otra ecuación <strong>de</strong> conservación<br />
para otros elementos como agua líquida, ozono, etc., mientras<br />
también se incluyan sus correspondientes fuentes y sumi<strong>de</strong>ros.<br />
La ecuación <strong>de</strong> estado <strong>de</strong> los gases i<strong>de</strong>ales aplicada a la atmósfera impone<br />
la siguiente relación entre las variables <strong>de</strong> estado termodinámicas:<br />
p α = R T, (2.7)<br />
don<strong>de</strong> p es la presión (mb ó Hpa), T la temperatura ( o C ó K), R es la<br />
constante <strong>de</strong> los gases i<strong>de</strong>ales, y α es el volumen específico (m 3 /kg),<br />
inverso <strong>de</strong> la <strong>de</strong>nsidad ρ (kg/m 3 ).<br />
Conservación <strong>de</strong> energía: El foco principal <strong>de</strong> calor para la atmósfera<br />
es la superficie terrestre (calentada por el Sol), entendiendo como tal<br />
tierra y océano. El calor recibido por la atmósfera se emplea en variar
14 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
su temperatura, su <strong>de</strong>nsidad o ambas cosas a la vez. Si se aplica una<br />
tasa <strong>de</strong> calor Q por unidad <strong>de</strong> masa a una parcela <strong>de</strong> aire (cal/sg), esta<br />
energía es empleada en aumentar la energía interna C v T y producir<br />
un trabajo <strong>de</strong> expansión<br />
dT<br />
Q = C v<br />
dt + pdα dt , (2.8)<br />
don<strong>de</strong> los coeficientes <strong>de</strong> calor específico a volumen constante (C v ) y a<br />
presión constante (C p ) se relacionan mediante C p = C v +R. Haciendo<br />
uso <strong>de</strong> la ecuación <strong>de</strong> estado se pue<strong>de</strong> obtener un forma alternativa <strong>de</strong><br />
la ecuación <strong>de</strong> conservación <strong>de</strong> energía:<br />
Conservación <strong>de</strong>l Momento:<br />
dv<br />
dt<br />
Q = C p<br />
dT<br />
dt − αdp dt . (2.9)<br />
= −α∇p − ∇φ + F − 2Ω × v; (2.10)<br />
La aceleración sobre la unidad <strong>de</strong> masa es <strong>de</strong>bida a cuatro fuerzas:<br />
gradiente <strong>de</strong> presión (−α∇p), gravedad aparente (−∇φ), rozamiento<br />
(F) y Coriolis (−2Ω × v).<br />
Por tanto, resumiendo lo anterior se tienen siete ecuaciones y siete incógnitas:<br />
v = (u, v, w), T, p, ρ = 1/α y q:<br />
dv<br />
dt<br />
= −α∇p − ∇φ + F − 2Ω × v (2.11)<br />
∂ρ<br />
∂t<br />
= −∇ · (ρ v) (2.12)<br />
p α = R T (2.13)<br />
dT<br />
Q = C p<br />
dt − αdp dt<br />
(2.14)<br />
∂ρ q<br />
∂t<br />
= −∇ · (ρ v q) + ρ (E − C) (2.15)<br />
A las ecuaciones anteriores se las suele <strong>de</strong>nominar ecuaciones primitivas,<br />
y representan el sistema que gobierna la dinámica <strong>de</strong> la atmósfera. El<br />
objetivo <strong>de</strong> la predicción numérica <strong>de</strong>l tiempo es obtener el estado <strong>de</strong> la<br />
circulación atmosférica en un tiempo futuro. Para ello es necesario disponer<br />
<strong>de</strong> un mo<strong>de</strong>lo numérico capaz <strong>de</strong> integrar las ecuaciones y que incluya<br />
los intercambios energéticos (en la capa límite) más importantes (radiación,<br />
turbulencia, calor latente, etc.). Dada la no linealidad y complejidad <strong>de</strong> las<br />
ecuaciones primitivas, en la práctica se suele recurrir a distintas aproximaciones<br />
que simplifican la resolución numérica y eliminan inestabilida<strong>de</strong>s<br />
numéricas.
2.3. RESOLUCIÓN NUMÉRICA DE LAS ECUACIONES 15<br />
2.2.1. Filtrado <strong>de</strong> Soluciones Triviales<br />
Las simplificaciones más básicas <strong>de</strong> las ecuaciones anteriores ayudan a<br />
enten<strong>de</strong>r las características <strong>de</strong> los tipos <strong>de</strong> ondas básicos presentes en la<br />
atmósfera, que también aparecen en las soluciones más generales. Por ejemplo,<br />
suponiendo que el movimiento es adiabático, rectilíneo, y sin gravedad, se<br />
obtienen como soluciones las ondas sonoras puras que se propagan a través<br />
<strong>de</strong> la compresión <strong>de</strong>l aire. Si se consi<strong>de</strong>ra la aproximación hidrostática (sin<br />
velocidad vertical, w=0), las ondas sonoras sólo se propagan horizontalmente<br />
(ondas <strong>de</strong> Lamb). Por otra parte, si se supone que no hay movimiento<br />
horizontal, pero sí <strong>de</strong>splazamientos verticales (el movimiento se consi<strong>de</strong>ra<br />
adiabático y rectilíneo), entonces el resultado son las ondas gravitatorias<br />
externas: ‘oleaje’ en la superficie libre; y las ondas gravitatorias internas:<br />
cualquier partícula <strong>de</strong> fluido <strong>de</strong>splazada <strong>de</strong> su nivel <strong>de</strong> equilibrio oscila verticalmente<br />
con un periodo típico <strong>de</strong> 100s (frecuencia <strong>de</strong> Brunt-Vaisala). Por<br />
otra parte, consi<strong>de</strong>rando un flujo zonal (v = w = 0) y un campo uniforme <strong>de</strong><br />
<strong>de</strong>nsidad, cualquier perturbación al flujo zonal supone un cambio <strong>de</strong> latitud<br />
y por tanto un cambio en la fuerza <strong>de</strong> Coriolis, que siempre actúa tratando<br />
<strong>de</strong> restaurar el flujo zonal produciendo las llamadas ondas <strong>de</strong> Rossby que se<br />
propagan alre<strong>de</strong>dor <strong>de</strong>l globo con un periodo <strong>de</strong> <strong>de</strong>sarrollo <strong>de</strong> varios días a<br />
una semana y con una longitud <strong>de</strong> onda <strong>de</strong>l or<strong>de</strong>n <strong>de</strong> 3000 km para latitu<strong>de</strong>s<br />
medias (ϕ = 45 o ).<br />
Como interesa que las soluciones obtenidas para la circulación <strong>de</strong> la atmósfera<br />
en un problema operativo muestren el comportamiento <strong>de</strong> interés meteorológico,<br />
es <strong>de</strong>seable eliminar algunas <strong>de</strong> las ondas básicas que no interfieren<br />
con esta dinámica, pero que pue<strong>de</strong>n producir inestabilida<strong>de</strong>s en el mo<strong>de</strong>lo<br />
numérico al ser propagadas (esto ocurre, por ejemplo con las ondas sonoras<br />
y gravitatorias). Este procedimiento <strong>de</strong> selección <strong>de</strong> tipos <strong>de</strong> ondas se<br />
<strong>de</strong>nomina filtrado y consiste en eliminar parcialmente las fuerzas restauradoras<br />
que originan la onda que se <strong>de</strong>sea filtrar. Por ejemplo, la aproximación<br />
hidrostática impi<strong>de</strong> la propagación vertical <strong>de</strong> las ondas sonoras.<br />
Por tanto, los mo<strong>de</strong>los operativos utilizados en la predicción numérica<br />
<strong>de</strong>l tiempo son aproximaciones más o menos completas <strong>de</strong> las ecuaciones<br />
primitivas <strong>de</strong> la atmósfera.<br />
2.3. Resolución Numérica <strong>de</strong> las Ecuaciones<br />
Los mo<strong>de</strong>los atmosféricos <strong>de</strong> circulación se resuelven utilizando técnicas<br />
numéricas que discretizan el espacio y el tiempo. En coor<strong>de</strong>nadas cartesianas<br />
se consi<strong>de</strong>ra una rejilla 4D sobre la que se aplican técnicas <strong>de</strong> elementos<br />
finitos, mientras que en coor<strong>de</strong>nadas esféricas se aplican técnicas espectrales<br />
que consi<strong>de</strong>ran un número finito <strong>de</strong> armónicos esféricos en la predicción<br />
(para introducción a estos métodos ver Kalnay, 2003). En ambos casos, la<br />
precisión <strong>de</strong>l mo<strong>de</strong>lo está fuertemente influenciada por la resolución espacial<br />
(dada directamente por el tamaño <strong>de</strong> rejilla o por el período <strong>de</strong>l modo
16 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
<strong>de</strong> mayor frecuencia). Sin embargo, aumentar la resolución <strong>de</strong>l mo<strong>de</strong>lo es<br />
extremadamente costoso ya que, por ejemplo, duplicar la resolución en el<br />
espacio tridimensional también requiere reducir a la mitad el paso <strong>de</strong> tiempo<br />
para satisfacer las condiciones <strong>de</strong> estabilidad computacional. Por tanto,<br />
el coste computacional total <strong>de</strong> duplicar la resolución crece con un factor<br />
<strong>de</strong> 2 4 = 16. Las técnicas mo<strong>de</strong>rnas <strong>de</strong> discretización intentan obtener un<br />
incremento en la precisión sin tanto coste computacional; estas técnicas son<br />
los esquemas semi-implícitos y semi-lagrangiano en el tiempo. A<strong>de</strong>más, estos<br />
esquemas poseen condiciones <strong>de</strong> estabilidad menos estrictas. Aún así,<br />
existe una constante necesidad <strong>de</strong> aumentar la resolución para obtener una<br />
predicción mejor y más <strong>de</strong>tallada. Esta tarea es la mayor aplicación <strong>de</strong> los<br />
super-or<strong>de</strong>nadores disponibles (www.top500.org).<br />
A pesar <strong>de</strong> los avances logrados en cuanto a la mo<strong>de</strong>lización física <strong>de</strong><br />
la atmósfera y a la resolución numérica <strong>de</strong> los mo<strong>de</strong>los, la notable mejora<br />
en la capacidad <strong>de</strong> predicción se <strong>de</strong>be principalmente a otros factores. Por<br />
ejemplo, Kalnay (2003) <strong>de</strong>scribe los siguientes factores:<br />
Por un lado, el aumento <strong>de</strong> la potencia <strong>de</strong> los super-or<strong>de</strong>nadores permitiendo<br />
resoluciones mucho más finas y menos aproximaciones en los<br />
mo<strong>de</strong>los atmosféricos operacionales.<br />
El aumento <strong>de</strong> la disponibilidad <strong>de</strong> datos, especialmente <strong>de</strong> proce<strong>de</strong>ntes<br />
<strong>de</strong> satélites y aviones sobre los océanos y el hemisferio Sur.<br />
El uso <strong>de</strong> métodos más exactos <strong>de</strong> asimilación <strong>de</strong> datos, lo que resulta<br />
en una mejor condición inicial para los mo<strong>de</strong>los.<br />
La mejora en la representación <strong>de</strong> procesos físicos <strong>de</strong> escala pequeña<br />
en los mo<strong>de</strong>los (nubes, precipitación, transferencia <strong>de</strong> calor en régimen<br />
turbulento, humedad, radiación, etc.).<br />
En las siguientes secciones se analizan estos temas en más <strong>de</strong>talle.<br />
2.3.1. Asimilación <strong>de</strong> Datos<br />
La predicción numérica es un problema <strong>de</strong> condicionas iniciales: dada una<br />
estimación actual <strong>de</strong>l estado <strong>de</strong> la atmósfera, un mo<strong>de</strong>lo numérico simula su<br />
evolución, para obtener una predicción. Esta condición inicial se establece<br />
a partir <strong>de</strong> la interpolación <strong>de</strong> las observaciones disponibles a los puntos <strong>de</strong><br />
rejilla <strong>de</strong>l mo<strong>de</strong>lo, y el proceso <strong>de</strong> obtención es <strong>de</strong>nominado asimilación. Sin<br />
embargo, el principal problema es que la cantidad <strong>de</strong> datos disponibles no<br />
es suficiente para inicializar el mo<strong>de</strong>lo en todos sus grados <strong>de</strong> libertad (por<br />
ejemplo, un mo<strong>de</strong>lo con una resolución típica <strong>de</strong> 1 o <strong>de</strong> resolución horizontal<br />
y 20 niveles verticales podría tener 180 × 360 × 20 = 1.3 × 10 6 puntos <strong>de</strong><br />
rejilla, en cada uno <strong>de</strong> los cuales están <strong>de</strong>finidas 7 variables, con lo que<br />
tendríamos aproximadamente 10 7 grados <strong>de</strong> libertad). Para una ventana<br />
temporal <strong>de</strong> ±3 horas, existen normalmente entre 10 4 y 10 5 observaciones
2.3. RESOLUCIÓN NUMÉRICA DE LAS ECUACIONES 17<br />
<strong>de</strong> la atmósfera, dos ór<strong>de</strong>nes <strong>de</strong> magnitud menor que el número <strong>de</strong> grados<br />
<strong>de</strong> libertad <strong>de</strong>l mo<strong>de</strong>lo. Mas aún, la distribución espacial y temporal <strong>de</strong> las<br />
observaciones no es uniforme, existiendo regiones en Eurasia y Norteamérica<br />
con muchos datos, y regiones en el Hemisferio Sur con pocos datos. Entonces<br />
se hace necesario usar información adicional (llamado fondo, first-guess o<br />
información a priori) para preparar las condiciones iniciales <strong>de</strong> la predicción.<br />
Inicialmente se usaba la climatología como first-guess, pero al mejorar la<br />
pericia <strong>de</strong> las predicciones, se utiliza una predicción a corto plazo como<br />
first-guess en los sistemas <strong>de</strong> asimilación <strong>de</strong> datos operacionales (ciclos <strong>de</strong><br />
análisis).<br />
Para los mo<strong>de</strong>los globales, el first-guess es la predicción <strong>de</strong>l mo<strong>de</strong>lo a<br />
las 6 horas, x b (un array 4-dimensional) que es interpolada a los puntos <strong>de</strong><br />
observación mediante un operador H(x b ) y convertida al mismo tipo que<br />
las variables observadas y o . Las diferencias entre las observaciones y el firstguess<br />
y o −H(x b ) son los incrementos observacionales o mejoras, y el análisis<br />
x a se obtiene añadiendo las mejoras al first-guess <strong>de</strong>l mo<strong>de</strong>lo con unos pesos<br />
W que son <strong>de</strong>terminados en base a las covarianzas <strong>de</strong> los errores estadísticos<br />
<strong>de</strong> la predicción y observación:<br />
x a = x b + W[y o − H(x b )] (2.16)<br />
Los diferentes esquemas <strong>de</strong> análisis están basados en este método: interpolación<br />
óptima, don<strong>de</strong> la matriz <strong>de</strong> pesos se <strong>de</strong>termina minimizando los<br />
errores en cada punto <strong>de</strong> rejilla; los métodos variacionales 3D y 4D, con<br />
funciones <strong>de</strong> coste proporcionales al cuadrado <strong>de</strong> la distancia entre el análisis,<br />
el first-guess y las observaciones (sobre un intervalo temporal o ventana<br />
<strong>de</strong> asimilación para el caso 4D); y más recientemente los filtros <strong>de</strong> Kalman<br />
extendidos (Judd, 2003).<br />
A la vista <strong>de</strong> lo anterior po<strong>de</strong>mos interpretar que el ciclo <strong>de</strong> asimilación <strong>de</strong><br />
datos es una continua integración <strong>de</strong>l mo<strong>de</strong>lo que se va perturbando con las<br />
observaciones <strong>de</strong> tal forma que permanezca los más cerca posible <strong>de</strong>l estado<br />
real <strong>de</strong> la atmósfera. La función <strong>de</strong>l mo<strong>de</strong>lo es transportar información <strong>de</strong><br />
zonas con muchos datos, a zonas con pocos datos y ofrecer una estimación<br />
<strong>de</strong>l estado <strong>de</strong> la atmósfera.<br />
Estos errores imponen una incertidumbre en la predicción que es necesario<br />
cuantificar e i<strong>de</strong>ntificar su origen para po<strong>de</strong>r minimizarla y obtener<br />
una mejor predictibilidad. Esto se vuelve importante en el plazo medio y en<br />
la predicción estacional; para ello se recurre a la predicción por conjuntos<br />
(ensemble forecast), que se analiza en una sección posterior.<br />
2.3.2. Parametrización: Procesos Físicos <strong>de</strong> Escala Menor<br />
A pesar <strong>de</strong> que los mo<strong>de</strong>los numéricos tienen cada vez más resolución,<br />
existen muchos procesos atmosféricos que no pue<strong>de</strong>n ser resueltos <strong>de</strong> manera<br />
explícita a la escala que se utiliza en los mo<strong>de</strong>los (algunos ocurren a escala<br />
molecular, como la radiación, evaporación, rozamiento y turbulencia); por
18 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
tanto, estos procesos no están contemplados en las ecuaciones <strong>de</strong> los mo<strong>de</strong>los<br />
que se usan. Estos procesos juegan un papel crucial en el balance energético<br />
global afectando, por supuesto, a los procesos a gran escala. Por esa razón, la<br />
interacción entre escalas no pue<strong>de</strong> ser ignorada por los mo<strong>de</strong>los, y se recurre<br />
a la parametrización. Así, cuando las ecuaciones son discretizadas sobre<br />
un tamaño <strong>de</strong> rejilla dado (<strong>de</strong> unos pocos a varios cientos <strong>de</strong> kilómetros), se<br />
hace necesario añadir términos “fuentes” y “sumi<strong>de</strong>ros” para tener en cuenta<br />
el balance energético asociado a los fenómenos que escapan a la dinámica<br />
formulada en el mo<strong>de</strong>lo numérico.<br />
La parametrización consiste en reformular a gran escala los efectos <strong>de</strong><br />
pequeña escala (ver, por ejemplo, Beniston, 1998). Una dificultad añadida es<br />
que no siempre está claro a qué escala se asigna un fenómeno <strong>de</strong>terminado;<br />
por ejemplo, un mo<strong>de</strong>lo <strong>de</strong> 50 km no resuelve la circulación <strong>de</strong> brisa, pero<br />
tampoco la ignora completamente, <strong>de</strong> manera que el proceso es doblemente<br />
difícil en estos casos. Como ejemplo, se podría consi<strong>de</strong>rar la ecuación <strong>de</strong><br />
conservación <strong>de</strong> vapor <strong>de</strong> agua en coor<strong>de</strong>nadas <strong>de</strong> presión dada por<br />
∂q<br />
∂t + u∂q ∂x + v ∂q<br />
∂y + w∂q ∂p = E − C + ∂w′ q ′<br />
∂p<br />
(2.17)<br />
don<strong>de</strong> q es la proporción <strong>de</strong> vapor <strong>de</strong> agua y masa <strong>de</strong> aire seco, x e y coor<strong>de</strong>nadas<br />
horizontales, p es la presión, t el tiempo, u y v son las componentes<br />
<strong>de</strong> la velocidad horizontal <strong>de</strong>l aire (viento), w = dp<br />
dt<br />
es la velocidad vertical<br />
en coor<strong>de</strong>nadas <strong>de</strong> presión, y el producto <strong>de</strong> las variables prima representa<br />
el transporte turbulento <strong>de</strong> humedad <strong>de</strong>s<strong>de</strong> las escalas no resueltas por la<br />
rejilla usada en la discretización, con la barra horizontal (q) se representan<br />
promedios espaciales sobre la rejilla <strong>de</strong>l mo<strong>de</strong>lo. A la parte izquierda <strong>de</strong><br />
(2.17) se la <strong>de</strong>nomina “dinámica” <strong>de</strong>l mo<strong>de</strong>lo, y se calcula explícitamente.<br />
La parte <strong>de</strong>recha <strong>de</strong> (2.17) se <strong>de</strong>nomina “física” <strong>de</strong>l mo<strong>de</strong>lo. Para la ecuación<br />
<strong>de</strong> la humedad, incluye los efectos <strong>de</strong> los procesos físicos tales como evaporación<br />
(E) y con<strong>de</strong>nsación (C), y transferencias turbulentas <strong>de</strong> humedad que<br />
tienen lugar a escalas pequeñas que no pue<strong>de</strong>n ser resueltas explícitamente<br />
por la “dinámica”.<br />
2.4. Tipos <strong>de</strong> Mo<strong>de</strong>los<br />
Como ya se ha comentado, la estabilidad numérica <strong>de</strong> los métodos <strong>de</strong><br />
integración impone una restricción entre la resolución temporal y la espacial.<br />
Por tanto, las integraciones con gran resolución espacial requerirán un<br />
paso <strong>de</strong> integración pequeño limitando el alcance operativo <strong>de</strong> las mismas,<br />
mientras que las integraciones <strong>de</strong> mo<strong>de</strong>los <strong>de</strong> baja resolución podrán prolongarse<br />
más en el tiempo. Este hecho ha motivado que operativamente se<br />
consi<strong>de</strong>ren distintos tipos o configuraciones <strong>de</strong> mo<strong>de</strong>los numéricos según el<br />
alcance y resolución <strong>de</strong> la predicción <strong>de</strong>seada. A continuación se <strong>de</strong>scriben<br />
las características <strong>de</strong> algunos <strong>de</strong> estos mo<strong>de</strong>los.
2.4. TIPOS DE MODELOS 19<br />
0.1<br />
1<br />
0.3<br />
0.5<br />
1<br />
5<br />
Presion (mb)<br />
3<br />
5<br />
10<br />
50<br />
10<br />
15<br />
20<br />
Nivel<br />
100<br />
200<br />
300<br />
500<br />
1000<br />
25<br />
30<br />
35<br />
40<br />
45<br />
50<br />
60<br />
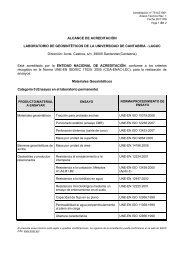
Figura 2.1: Rejilla global <strong>de</strong> 2.5 o <strong>de</strong> resolución en longitud y latitud utilizada<br />
por mo<strong>de</strong>los <strong>de</strong> circulación general sobre todo el globo; el tamaño <strong>de</strong> la rejilla es<br />
144 × 73 = 10512 puntos. (<strong>de</strong>recha) Dos perfiles verticales con 31 y 60 niveles <strong>de</strong><br />
altura geopotencial (expresados en milibares mb, y en números <strong>de</strong> nivel <strong>de</strong>l mo<strong>de</strong>lo,<br />
respectivamente). La altura máxima mostrada (0.1mb) es <strong>de</strong> aproximadamente 64<br />
km.<br />
2.4.1. Mo<strong>de</strong>los Globales <strong>de</strong> Circulación General<br />
Los mo<strong>de</strong>los globales se integran sobre todo el globo por lo que su tratamiento<br />
numérico se realiza en coor<strong>de</strong>nadas esféricas. Por tanto, la resolución<br />
horizontal <strong>de</strong> estos mo<strong>de</strong>los viene caracterizada por el número <strong>de</strong> modos<br />
esféricos que se consi<strong>de</strong>ren en el <strong>de</strong>sarrollo <strong>de</strong> las soluciones; así, un mo<strong>de</strong>lo<br />
truncado a 144 modos se <strong>de</strong>nomina TL144 y tiene una resolución horizontal<br />
<strong>de</strong> 2.5 grados (aprox. 250 km en nuestra latitud). Este truncamiento también<br />
influye en la resolución vertical (número <strong>de</strong> niveles <strong>de</strong> presión) que habrá <strong>de</strong><br />
ser consistente con la resolución espacial y temporal. Así, el mo<strong>de</strong>lo global<br />
operativo en la predicción a corto plazo <strong>de</strong>l ECMWF (European Center for<br />
Medium-Range Weather Forecast, www.ecmwf.int) es un TL511L60 con 60<br />
niveles <strong>de</strong> presión, mientras que el mo<strong>de</strong>lo utilizado para la predicción estacional<br />
es un T63L31 (la resolución horizontal y vertical <strong>de</strong> este mo<strong>de</strong>lo se<br />
muestra en la Fig. 2.1).<br />
Dada su escasa resolución, estos mo<strong>de</strong>los capturan la dinámica sinóptica<br />
<strong>de</strong> la atmósfera y normalmente son utilizados en la predicción mensual y<br />
estacional, y también en las simulaciones <strong>de</strong> escenarios <strong>de</strong> cambio climático.<br />
En algunos casos, lo mo<strong>de</strong>los <strong>de</strong> circulación general son acoplados con mo<strong>de</strong>los<br />
oceánicos para tener caracterizado este término forzante <strong>de</strong> la atmósfera;<br />
en otros casos, dado que la evolución <strong>de</strong> la atmósfera es la componente rápida<br />
<strong>de</strong>l sistema, la temperatura <strong>de</strong>l agua se supone constante (por ejemplo<br />
en la predicción mensual).<br />
Otros términos como la orografía, el uso <strong>de</strong>l suelo, la cubierta <strong>de</strong> hielo,
20 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
etc. se introducen en el mo<strong>de</strong>lo en la misma rejilla utilizada para la predicción.<br />
Por tanto, la orografía <strong>de</strong> los mo<strong>de</strong>los <strong>de</strong> circulación general está muy<br />
suavizada y sólo refleja <strong>de</strong> forma grosera los principales sistemas montañosos<br />
<strong>de</strong>l planeta.<br />
2.4.2. Mo<strong>de</strong>los Regionales<br />
Una solución para aumentar la resolución <strong>de</strong>l mo<strong>de</strong>lo sin incrementar<br />
el coste computacional es consi<strong>de</strong>rar rejillas limitadas a zonas geográficas<br />
<strong>de</strong> especial interés. Por ejemplo, la Fig. 2.2(a) muestra una rejilla <strong>de</strong> 1 o <strong>de</strong><br />
resolución en longitud y latitud centrada en Europa. Debido a su mayor resolución,<br />
los mo<strong>de</strong>los regionales tienen una mayor exactitud para reproducir<br />
fenómenos <strong>de</strong> pequeña escala tales como frentes, y también tienen mejores<br />
forzamientos orográficos que los mo<strong>de</strong>los globales (ver Fig. 2.2(b)). Por otro<br />
lado, al no ser globales, estos mo<strong>de</strong>los tienen la <strong>de</strong>sventaja <strong>de</strong> no ser “autocontenidos”<br />
y, aparte <strong>de</strong> las condiciones iniciales, requieren condiciones <strong>de</strong><br />
contorno en las fronteras <strong>de</strong>l dominio. Estas condiciones <strong>de</strong> contorno necesitan<br />
ser lo más precisas posibles y por ello se toman interpolando la salida <strong>de</strong><br />
un mo<strong>de</strong>lo global. Normalmente las condiciones <strong>de</strong> contorno se actualizan<br />
durante el transcurso <strong>de</strong> la predicción para imponer sobre el mo<strong>de</strong>lo regional<br />
la dinámica sinóptica simulada por el mo<strong>de</strong>lo global.<br />
70<br />
70<br />
60<br />
60<br />
50<br />
50<br />
40<br />
40<br />
30<br />
30 20 10 0 10 20 30<br />
30<br />
30 20 10 0 10 20 30<br />
0 1000 2000 3000 4000 5000<br />
Figura 2.2: Rejilla horizontal <strong>de</strong> resolución 1 o <strong>de</strong> longitud y latitud sobre Europa<br />
(izquierda). Orografía <strong>de</strong>l mo<strong>de</strong>lo para la resolución dada (<strong>de</strong>recha).<br />
m<br />
En algunos casos, se <strong>de</strong>fine una cascada <strong>de</strong> rejillas <strong>de</strong> tamaño <strong>de</strong>creciente<br />
y resolución creciente y las integraciones se realizan <strong>de</strong> forma anidada<br />
aprovechando las salidas <strong>de</strong> una rejilla como condiciones <strong>de</strong> contorno <strong>de</strong> la<br />
siguiente rejilla. Por ejemplo, el NCEP anida un mo<strong>de</strong>lo <strong>de</strong> baja resolución<br />
(eta − 12) con distintas rejillas <strong>de</strong> alta resolución (8 km) sobre zonas <strong>de</strong><br />
interés (ver Fig. 2.3).<br />
Este tipo <strong>de</strong> mo<strong>de</strong>los son los utilizados en la predicción operativa a corto<br />
y medio plazo, don<strong>de</strong> cada servicio meteorológico se centra en su región<br />
<strong>de</strong> influencia, integrando un mo<strong>de</strong>lo regional con una resolución limitada<br />
principalmente por la capacidad <strong>de</strong> cómputo.
2.4. TIPOS DE MODELOS 21<br />
Figura 2.3: Rejillas <strong>de</strong> alta resolución anidadas con el mo<strong>de</strong>lo eta-12 (línea<br />
sólida): Western U.S., Central U.S., Alaska, Hawaii, Puerto Rico. (FUENTE:<br />
NCEP/NOAA).<br />
2.4.3. Mo<strong>de</strong>los Mesoscalares<br />
Más recientemente, la resolución <strong>de</strong> algunos mo<strong>de</strong>los regionales ha aumentado<br />
hasta llegar a unos pocos kilómetros, con objeto <strong>de</strong> mejorar la resolución<br />
<strong>de</strong> fenómenos convectivos locales (tormentas) y otros procesos físicos<br />
<strong>de</strong> pequeña escala. En este caso, las parametrizaciones juegan un papel fundamental<br />
y su calibración para la zona geográfica <strong>de</strong> interés es <strong>de</strong>terminante<br />
para el buen funcionamiento <strong>de</strong>l mo<strong>de</strong>lo. Dada su escasa resolución horizontal,<br />
la formulación <strong>de</strong> estos mo<strong>de</strong>los suele darse en coor<strong>de</strong>nadas cartesianas<br />
y no usan la aproximación hidrostática, la cual <strong>de</strong>ja <strong>de</strong> tener vali<strong>de</strong>z para<br />
escalas horizontales menores <strong>de</strong> 10 km. Así se han <strong>de</strong>sarrollado varios<br />
mo<strong>de</strong>los no-hidrostáticos que se utilizan rutinariamente para la predicción<br />
<strong>de</strong> fenómenos <strong>de</strong> mesoscala. Los más usados son ARPS (Advanced Regional<br />
Prediction System), MM5 (Penn State/NCAR Mesoscale Mo<strong>de</strong>l, Version<br />
5), RSM (NCEP Regional Spectral Mo<strong>de</strong>l) y COAMPS (US Navy‘s Coupled<br />
Ocean/Atmosphere Mesoscale Prediction System). Actualmente, existe una<br />
ten<strong>de</strong>ncia hacia el uso <strong>de</strong> mo<strong>de</strong>los no-hidrostáticos que también pue<strong>de</strong>n ser<br />
usados globalmente.<br />
En la Fig. 2.4 se muestra la orografía <strong>de</strong> la Península Ibérica con una<br />
resolución <strong>de</strong> 0.2 o (aprox. 20 km) y la orografía <strong>de</strong> la Cornisa Cantábrica<br />
con una resolución <strong>de</strong> 0.0083 o (aprox. 1 km). Esta última resolución es la<br />
que permite caracterizar <strong>de</strong> forma apropiada la orografía <strong>de</strong> esta zona.
22 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
Figura 2.4: Orografía <strong>de</strong> la Península Ibérica correspondiente a un mo<strong>de</strong>lo <strong>de</strong> 0.2 o<br />
(superior). Ampliación <strong>de</strong> la zona correspondiente a las Autonomías <strong>de</strong> Cantabria<br />
y Asturias (42.5-43.75N, 3-7 O), con una resolución <strong>de</strong> 0.0083 o .<br />
2.5. Estado Actual <strong>de</strong> la Predicción Operativa<br />
Las distintas predicciones que se preparan diariamente para el público y<br />
otros usuarios especializados en el Instituto Nacional <strong>de</strong> Meteorología (INM,<br />
www.inm.es) y en otros centros meteorológicos europeos (MeteoFrance, UK<br />
MetOffice, etc.) utilizan las salidas <strong>de</strong> los mo<strong>de</strong>los numéricos anteriormente<br />
<strong>de</strong>scritos; a estas se las <strong>de</strong>nomina predicciones operativas y pue<strong>de</strong>n ser <strong>de</strong><br />
distintos tipos <strong>de</strong>pendiendo <strong>de</strong> la escala espacial y temporal <strong>de</strong> su aplicación.<br />
Tradicionalmente las predicciones se han obtenido aplicando un único mo<strong>de</strong>lo,<br />
a partir <strong>de</strong> una condición inicial dada. Sin embargo en las dos últimas<br />
décadas los estudios no-lineales realizados en este campo han mostrado que<br />
es necesario hablar en términos probabilísticos y consi<strong>de</strong>rar los efectos causados<br />
por las distintas fuentes <strong>de</strong> incertidumbre en la evolución <strong>de</strong>l mo<strong>de</strong>lo.<br />
Para ello, hoy día se utilizan distintos esquemas <strong>de</strong> predicción por conjuntos<br />
que perturban las condiciones iniciales, o combinan las salidas <strong>de</strong> distintos<br />
mo<strong>de</strong>los (multi-mo<strong>de</strong>lo), para obtener un conjunto <strong>de</strong> predicciones con el<br />
que anticipar la evolución <strong>de</strong> la atmósfera. A continuación se muestra una<br />
<strong>de</strong>scripción <strong>de</strong>l abanico <strong>de</strong> predicciones que se realizan en distintos centros<br />
meteorológicos <strong>de</strong> forma operativa:
2.5. ESTADO ACTUAL DE LA PREDICCIÓN OPERATIVA 23<br />
El nowcasting (predicción inmediata) marca el primer umbral <strong>de</strong> predicción<br />
y se refiere a la predicción a muy corto plazo (minutos/horas).<br />
En este período <strong>de</strong> alcance, los análisis <strong>de</strong> radar, las imágenes <strong>de</strong> satélite<br />
y las labores <strong>de</strong> vigilancia llevadas a cabo por observadores y predictores<br />
humanos juegan el papel principal, relegando a los mo<strong>de</strong>los<br />
numéricos a un segundo plano. En este umbral <strong>de</strong> predicción se trata <strong>de</strong><br />
pre<strong>de</strong>cir con suficiente <strong>de</strong>talle la intensidad <strong>de</strong> eventos extremos (fuertes<br />
tormentas, etc.), así como la localización geográfica <strong>de</strong> los mismos.<br />
En esta Tesis no se abarca este alcance <strong>de</strong> predicción, pues supone el<br />
estudio <strong>de</strong> técnicas especiales para este tipo <strong>de</strong> fenómenos.<br />
En un segundo nivel, la predicción a corto plazo se entien<strong>de</strong> en un rango<br />
<strong>de</strong> entre 1 y 3 días <strong>de</strong> alcance. En un principio se realiza a nivel<br />
global con una resolución horizontal que oscila entre 0.5 y 1 o . Por ejemplo,<br />
el ECMWF proporciona salidas cada 6 horas sobre todo el globo<br />
con 0.6 o (aprox. 60 km) a partir <strong>de</strong> un mo<strong>de</strong>lo <strong>de</strong> circulación general<br />
T511. Este centro es una organización multinacional que aglutina<br />
esfuerzos <strong>de</strong> los distintos países <strong>de</strong> la comunidad europea para realizar<br />
una predicción base que sirva <strong>de</strong> soporte para el resto <strong>de</strong> servicios<br />
meteorológicos. Las salidas <strong>de</strong> los mo<strong>de</strong>los <strong>de</strong>l ECMWF se utilizan<br />
en los distintos servicios meteorológicos europeos como condiciones <strong>de</strong><br />
contorno para mo<strong>de</strong>los regionales <strong>de</strong> mayor resolución. Por ejemplo,<br />
el producto final <strong>de</strong> predicción operativa en España el INM se obtiene<br />
aplicando el mo<strong>de</strong>lo regional HIRLAM, con una resolución espacial <strong>de</strong><br />
0.2 o , a las salidas <strong>de</strong>l ECMWF (ver Fig. 2.5).<br />
De forma análoga en EEUU el NCEP (National Centers for Environmental<br />
Prediction, www.ncep.noaa.gov) realiza una predicción global<br />
que distribuye libremente a través <strong>de</strong> Internet, y que es luego utilizada<br />
por distintos centros regionales en diversas aplicaciones. Por ejemplo la<br />
Fig. 2.6 muestra el campo <strong>de</strong> precipitación estimado por el mo<strong>de</strong>lo <strong>de</strong>l<br />
NCEP y los campos estimados por el mo<strong>de</strong>lo regional MM5 utilizado<br />
en Meteo Galicia meteo.usc.es con 30 y 10 km <strong>de</strong> resolución.<br />
La predicción por conjuntos a medio plazo abarca el período comprendido<br />
entre los 4 y 15 días <strong>de</strong> alcance. En este período el sistema tradicional<br />
<strong>de</strong> predicción <strong>de</strong>terminista comienza a per<strong>de</strong>r predictibilidad<br />
fruto <strong>de</strong> la no linealidad <strong>de</strong>l mo<strong>de</strong>lo y los efectos <strong>de</strong> la incertidumbre.<br />
Por tanto, en este período la predicción se entien<strong>de</strong> en sentido probabilístico<br />
y se utilizan técnicas como la predicción por conjuntos para<br />
tener en cuenta estos efectos. La predicción por conjuntos se lleva a la<br />
práctica integrando el sistema varias veces utilizando un número arbitrario<br />
<strong>de</strong> condiciones iniciales distintas que se obtienen perturbando<br />
<strong>de</strong> forma apropiada la condición inicial obtenida a partir <strong>de</strong> las observaciones<br />
(ver Sec. 6.2 para más <strong>de</strong>talles). Como resultado, se obtiene<br />
un conjunto <strong>de</strong> predicciones que han <strong>de</strong> procesarse <strong>de</strong> forma apropiada<br />
para obtener una predicción <strong>de</strong> consenso (numérica o probabilística).
24 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
Figura 2.5: (superior) Orografía <strong>de</strong> los mo<strong>de</strong>los HIRLAM <strong>de</strong> 0.5 o y 0.2 o utilizados<br />
por el INM en la predicción operativa. (inferior) Salida <strong>de</strong> precipitación <strong>de</strong>l mo<strong>de</strong>lo<br />
con una resolución <strong>de</strong> 0.5 o (FUENTE: Instituto Nacional <strong>de</strong> Meteorología).<br />
(a)<br />
(b)<br />
(c)<br />
Figura 2.6: Campos <strong>de</strong> precipitación a D + 1 obtenidos con (a) el mo<strong>de</strong>lo AVN<br />
<strong>de</strong>l NCEP; y el mo<strong>de</strong>lo MM5 utilizado por Meteo Galicia con (b) 30 y (c) 10 km<br />
<strong>de</strong> resulución. (FUENTE: Página web <strong>de</strong> Meteo Galicia).
2.5. ESTADO ACTUAL DE LA PREDICCIÓN OPERATIVA 25<br />
En cuanto a los sistemas globales <strong>de</strong> predicción por conjuntos operativos,<br />
<strong>de</strong>s<strong>de</strong> Noviembre <strong>de</strong> 2000 el ECMWF ha puesto en marcha un mo<strong>de</strong>lo<br />
<strong>de</strong> predicción por conjuntos a plazo medio (con alcance <strong>de</strong> 10 días)<br />
basado en 50 integraciones con condiciones iniciales perturbadas y una<br />
integración con condiciones sin perturbar <strong>de</strong> un mo<strong>de</strong>lo TL255L40<br />
(aprox. 80 km <strong>de</strong> resolución en latitu<strong>de</strong>s medias). La resolución <strong>de</strong> este<br />
mo<strong>de</strong>lo es cuatro veces superior a la <strong>de</strong>l mo<strong>de</strong>lo anterior puesto en<br />
marcha en Diciembre <strong>de</strong> 1992 y se ha constatado que este aumento <strong>de</strong><br />
resolución ha mejorado sustancialmente la predicción probabilística <strong>de</strong><br />
la precipitación (ver Buizza et al., 2001, para más <strong>de</strong>talles). Por otra<br />
parte, el NCEP también produce <strong>de</strong> forma operativa predicciones por<br />
conjuntos a medio plazo (hasta 15 días) utilizando el Global Forecast<br />
System mo<strong>de</strong>l (GFS) (ver www.nco.ncep.noaa.gov/pmb/products/).<br />
Paralelamente al crecimiento <strong>de</strong> los recursos computacionales, especialmente<br />
la capacidad <strong>de</strong> cómputo, la resolución <strong>de</strong> los mo<strong>de</strong>los se<br />
va incrementando, permitiendo mejorar la resolución <strong>de</strong> las costosas<br />
simulaciones por conjuntos <strong>de</strong> alcance medio. Por tanto, es previsible<br />
que en el futuro cercano la predicción a corto plazo y la predicción por<br />
conjuntos a plazo medio se fundan en una sola predicción, extendiendo<br />
la aplicabilidad <strong>de</strong> la predicción por conjuntos (<strong>de</strong> hecho, se están dando<br />
ya las primeras experiencias <strong>de</strong> exten<strong>de</strong>r la predicción por conjuntos<br />
al corto plazo, buscando técnicas perturbativas apropiadas).<br />
En la predicción por conjuntos mensual y estacional no se trata <strong>de</strong><br />
pre<strong>de</strong>cir el estado real <strong>de</strong> la atmósfera, sino las anomalías en la circulación<br />
(<strong>de</strong>sviaciones respecto <strong>de</strong>l comportamiento promedio) transcurridas<br />
tras un mes, un trimestre. En este supuesto, la condición<br />
inicial (el estado inicial <strong>de</strong> la atmósfera) no es el factor más importante<br />
para la i<strong>de</strong>ntificación <strong>de</strong> anomalías en la evolución <strong>de</strong> la circulación<br />
atmosférica, sino que existen otros factores más <strong>de</strong>terminantes, como<br />
la temperatura <strong>de</strong>l agua <strong>de</strong>l océano. Por tanto, estos mo<strong>de</strong>los están<br />
acoplados con mo<strong>de</strong>los oceánicos, o tienen forzadas las temperaturas<br />
<strong>de</strong>l agua <strong>de</strong>l mar. Por ejemplo, el ECMWF integra quincenalmente<br />
y hasta 180 días un mo<strong>de</strong>lo <strong>de</strong> predicción por conjuntos <strong>de</strong>nominado<br />
System-II para la elaboración <strong>de</strong> predicciones <strong>de</strong> anomalías climáticas<br />
mensuales y estacionales (en este caso, las distintas condiciones iniciales<br />
se obtienen perturbando positiva y negativamente las temperaturas<br />
<strong>de</strong>l agua <strong>de</strong>l mar). Este mo<strong>de</strong>lo surgió <strong>de</strong> la experiencia llevada a cabo<br />
en el proyecto DEMETER (Development of a European Multimo<strong>de</strong>l<br />
Ensemble system for seasonal to inTERannual prediction) en el que<br />
se construyó un sistema <strong>de</strong> predicción estacional multi-mo<strong>de</strong>lo que integra<br />
seis mo<strong>de</strong>los globales <strong>de</strong> predicción por conjuntos con distintos<br />
esquemas <strong>de</strong> perturbación (www.ecmwf.int/research/<strong>de</strong>meter/). De<br />
hecho, se dispone <strong>de</strong> un re-análisis <strong>de</strong> este sistema multi-mo<strong>de</strong>lo que<br />
abarca el mismo período <strong>de</strong> ERA-40.
26 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
Finalmente, <strong>de</strong>ntro <strong>de</strong>l ámbito <strong>de</strong> la predicción climática, varios centros<br />
climáticos europeos (Centro Hadley en el Reino Unido, Instituto<br />
Max Plank en Alemania, Centro Nacional <strong>de</strong> Investigación <strong>de</strong> Méteo-<br />
France) llevan a cabo integraciones durante 100 o más años bajo diversas<br />
hipótesis <strong>de</strong> forzamiento radiativo para la realización <strong>de</strong> estudios<br />
<strong>de</strong> escenarios climáticos (por ejemplo, los efectos <strong>de</strong> la duplicación <strong>de</strong><br />
las emisiones <strong>de</strong> CO 2 en la atmósfera). En estos casos, los mo<strong>de</strong>los<br />
son globales y están acoplados con mo<strong>de</strong>los oceánicos, por lo que su<br />
resolución es pequeña (entre 2.5 o y 5 o , es <strong>de</strong>cir 250 − 500 km aproximadamente).<br />
2.6. Futuro <strong>de</strong> la Predicción Numérica<br />
Des<strong>de</strong> la perspectiva actual, el futuro <strong>de</strong> la predicción numérica se ve<br />
centrado en los <strong>de</strong>sarrollos teóricos y prácticos para compren<strong>de</strong>r los efectos<br />
<strong>de</strong> la incertidumbre y su propagación en los mo<strong>de</strong>los numéricos; ésto incluye<br />
al proceso <strong>de</strong> asimilación y a los métodos <strong>de</strong> perturbación para predicción<br />
por conjuntos. Según Kalnay (2003), los siguientes problemas marcarán el<br />
futuro próximo <strong>de</strong> la predicción numérica:<br />
Predicciones a corto alcance <strong>de</strong> mo<strong>de</strong>los <strong>de</strong> fenómenos convectivos locales<br />
(tormentas) con capacidad predictiva <strong>de</strong> fenómenos adversos.<br />
Métodos <strong>de</strong> asimilación <strong>de</strong> datos capaces <strong>de</strong> extraer la máxima información<br />
<strong>de</strong> los sistemas <strong>de</strong> observación, especialmente <strong>de</strong> satélites y<br />
radares.<br />
Mejora <strong>de</strong> la utilidad <strong>de</strong> las predicciones a plazo medio, especialmente<br />
a través <strong>de</strong>l uso <strong>de</strong> la predicción por conjuntos.<br />
Sistemas totalmente acoplados <strong>de</strong> atmósfera e hidrología, con el objetivo<br />
<strong>de</strong> realizar mejores predicciones locales <strong>de</strong> la precipitación <strong>de</strong>l<br />
mo<strong>de</strong>lo, y extendido a la predicción <strong>de</strong> caudales <strong>de</strong> ríos.<br />
Un mayor uso <strong>de</strong> mo<strong>de</strong>los atmósfera-océano-tierra en los cuales anomalías<br />
<strong>de</strong> larga duración tales como temperatura <strong>de</strong> la superficie <strong>de</strong>l<br />
mar (SST, Sea Surface Temperature) y humedad <strong>de</strong> suelo, lleven a<br />
mejores predicciones estacionales y climáticas.<br />
Aplicaciones <strong>de</strong> los mo<strong>de</strong>los numéricos en sectores productivos relacionados<br />
con la actividad humana: agricultura, energía, prevención <strong>de</strong><br />
riesgos naturales, etc., y en problemas que afectan a la salud tales como<br />
contaminación atmosférica, transporte <strong>de</strong> contaminantes y radiación<br />
ultravioleta.<br />
Esta Tesis doctoral se centra en alguno <strong>de</strong> estos problemas; en concreto<br />
se analiza la predicción local mediante técnicas híbridas y se aplican los<br />
métodos <strong>de</strong>sarrollados para los sistemas <strong>de</strong> predicción por conjuntos.
2.7. DATOS CLIMATOLÓGICOS Y METEOROLÓGICOS 27<br />
2.7. Datos Climatológicos y Meteorológicos<br />
Los mo<strong>de</strong>los numéricos y las distintas técnicas estadísticas <strong>de</strong> postproceso<br />
se valen <strong>de</strong> las observaciones <strong>de</strong> variables meteorológicas <strong>de</strong> la red<br />
mundial <strong>de</strong> observatorios, e incluso <strong>de</strong> datos paleoclimáticos obtenidos indirectamente<br />
a partir <strong>de</strong> mediciones <strong>de</strong> hielo, anillos <strong>de</strong> árboles, etc. En esta<br />
sección se <strong>de</strong>scriben las fuentes <strong>de</strong> esta cantidad ingente <strong>de</strong> información, que<br />
serán la base para las herramientas <strong>de</strong>sarrolladas en esta Tesis.<br />
2.7.1. Re<strong>de</strong>s <strong>de</strong> Observación<br />
Las observaciones rutinarias <strong>de</strong> la atmósfera (en especial en superficie)<br />
han ido extendiéndose <strong>de</strong> forma contínua <strong>de</strong>s<strong>de</strong> la creación <strong>de</strong> la OMM en<br />
1950, propiciando el marco intergubernamental para el establecimiento <strong>de</strong><br />
re<strong>de</strong>s internacionales <strong>de</strong> observación. El GOS (Global Observing System) es<br />
el sistema coordinado que recopila y comprueba las observaciones <strong>de</strong> variables<br />
atmosféricas y oceánicas (en superficie) a nivel global. El núcleo <strong>de</strong> las<br />
observaciones superficiales consta <strong>de</strong> aproximadamente 10.000 observatorios<br />
que realizan observaciones al menos cada tres horas, y a menudo horariamente.<br />
Las variables observadas son: presión atmosférica, viento, temperatura<br />
<strong>de</strong>l aire y humedad relativa. A<strong>de</strong>más existen unas 1.000 estaciones <strong>de</strong> radiosonda<br />
y más <strong>de</strong> 3.000 aviones que realizan observaciones en varios niveles<br />
<strong>de</strong> la atmósfera. Unos 7.300 barcos, 600 boyas a la <strong>de</strong>riva, 300 boyas fijas y<br />
600 plataformas proporcionan observaciones en los océanos. Estos datos son<br />
utilizados diariamente por los mo<strong>de</strong>los numéricos <strong>de</strong> circulación atmosférica,<br />
asimilando el estado <strong>de</strong> la atmósfera inicial en base a un conjunto <strong>de</strong> estas<br />
observaciones. Por ejemplo, la Figura 2.7 muestra las observaciones utilizadas<br />
un día en el ECMWF para el proceso <strong>de</strong> asimilación (inicialización) <strong>de</strong><br />
su mo<strong>de</strong>lo operativo.<br />
Figura 2.7: Observaciones utilizadas en la asimilación <strong>de</strong> datos <strong>de</strong>l mo<strong>de</strong>lo numérico<br />
<strong>de</strong>l ECMWF. (FUENTE. Página Web <strong>de</strong>l ECMWF).
28 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
El GOS también dispone <strong>de</strong> un subsistema espacial <strong>de</strong> observación, integrado<br />
por cuatro satélites en órbita polar y cinco geoestacionarios, con el<br />
objetivo principal <strong>de</strong> completar la cobertura <strong>de</strong> las observaciones <strong>de</strong> la red<br />
en superficie. El papel <strong>de</strong> las observaciones proce<strong>de</strong>ntes <strong>de</strong> satélites es cada<br />
vez más importante y la asimilación <strong>de</strong> estos datos en los mo<strong>de</strong>los numéricos<br />
es un área <strong>de</strong> intensa investigación. La longitud <strong>de</strong> las series <strong>de</strong> datos<br />
almacenadas es muy variable y oscila entre un par <strong>de</strong> cientos <strong>de</strong> años (para<br />
estaciones históricas), hasta unos pocos años, o meses.<br />
Por otra parte, los distintos servicios meteorológicos nacionales disponen<br />
<strong>de</strong> su propia red <strong>de</strong> observación (algunos <strong>de</strong> cuyas estaciones se integran en<br />
el GOS). Estas re<strong>de</strong>s mucho más <strong>de</strong>nsas abarcan gran variedad <strong>de</strong> variables<br />
climatológicas. Por ejemplo, el Instituto Nacional <strong>de</strong> Meteorología (INM)<br />
dispone <strong>de</strong> una red <strong>de</strong> observatorios que abarca 6735 puntos geográficos en<br />
las distintas cuencas hidrográficas Españolas (ver Fig. 2.8(b)) con mediciones<br />
diarias <strong>de</strong> precipitación y meteoros (tormenta, nieve, granizo, niebla,<br />
lluvia, calima, rocío y escarcha) en el período 1975-2000. Las temperaturas<br />
máxima y mínima se observan en 2281 puntos. A<strong>de</strong>más <strong>de</strong> la red secundaria,<br />
existen algunas estaciones en las que se realizan observaciones por<br />
parte <strong>de</strong> personal cualificado. Estas estaciones correspon<strong>de</strong>n a la red principal<br />
y en la actualidad consta <strong>de</strong> 225 puntos <strong>de</strong> observación en los que se<br />
mi<strong>de</strong> insolación, evaporación, recorrido, dirección y racha máxima <strong>de</strong> viento,<br />
temperaturas medias, y otras variables. Las observaciones se realizan<br />
diariamente, aunque en la red principal se realizan observaciones con mayor<br />
frecuencia (cada 10 min, cuatro veces al día, etc.). En total se tienen<br />
8766 ×(6735 ×9+2281 ×2+225 ×3) ≃ 6 ×10 8 datos incluyendo lagunas en<br />
las observaciones. Si se consi<strong>de</strong>ran 2 bytes por dato habrá en total 1.2 Gb<br />
<strong>de</strong> información.<br />
A continuación se <strong>de</strong>tallan las observaciones disponibles (salvo indicación<br />
expresa, las observaciones son diarias y hacen referencia a un periodo <strong>de</strong> 24<br />
horas comprendidas <strong>de</strong> 7 a 7 h):<br />
Observaciones en la red secundaria o termopluviométrica (Fig. 2.8(d)):<br />
1. Temperaturas extremas máxima y mínima a 1m <strong>de</strong>l suelo (en o C).<br />
2. Precipitación diaria acumulada (en mm ≡ l/m 2 ).<br />
3. Ocurrencia <strong>de</strong> meteoros: nieblas, tormentas, granizo, nieve, escarcha<br />
y rocío.<br />
Observaciones en la red principal (Fig. 2.8(c)). A<strong>de</strong>más <strong>de</strong> incluir las<br />
observaciones anteriores, la red principal posee una serie adicional <strong>de</strong><br />
mediciones.<br />
1. Racha máxima <strong>de</strong> viento, medida <strong>de</strong> 0 a 24 horas a 10m <strong>de</strong>l suelo<br />
(en km/h). La dirección <strong>de</strong> la racha máxima se mi<strong>de</strong> en grados<br />
(tomando como origen el Norte).
2.7. DATOS CLIMATOLÓGICOS Y METEOROLÓGICOS 29<br />
2. Insolación medida <strong>de</strong> 0 a 24 horas (en horas diarias <strong>de</strong> sol). Si es<br />
relativa se mi<strong>de</strong> en% respecto a la insolación máxima teórica <strong>de</strong>l<br />
día.<br />
3. Evaporación Potencial, consi<strong>de</strong>rada como la máxima evaporación<br />
posible, medida <strong>de</strong> 0 a 24 horas (en mm) (existen algunas medidas<br />
en la red secundaria).<br />
4. En la red principal existen otras muchas variables que se podrían<br />
incluir entre las observaciones. Algunas <strong>de</strong> ellas son: Intensidad<br />
máxima y duración <strong>de</strong> precipitación, recorrido <strong>de</strong>l viento, cantidad<br />
y tipo <strong>de</strong> nubosidad, humedad media, y visibilidad.<br />
Las series <strong>de</strong> datos disponibles tienen longitu<strong>de</strong>s variables y contienen lagunas,<br />
pero en términos generales se pue<strong>de</strong> <strong>de</strong>cir que se dispone <strong>de</strong> 50 años <strong>de</strong><br />
información.<br />
(a)<br />
45º N<br />
(b)<br />
NORTE<br />
DUERO<br />
EBRO<br />
CATALUÑA<br />
40º N<br />
TAJO<br />
JÚ CAR<br />
GUADIANA<br />
GUADALQUIVIR<br />
SEGURA<br />
35º N<br />
SUR<br />
10º W 5º W<br />
0º<br />
5º E<br />
(c)<br />
(d)<br />
Figura 2.8: (a) Orografía <strong>de</strong> España y sus (b) cuencas hidrográficas principales.<br />
(c) Red principal <strong>de</strong> estaciones <strong>de</strong>l INM, (d) red termopluviométrica.<br />
2.7.2. Datos Paleoclimáticos<br />
Los datos instrumentales son medidas directas representativas <strong>de</strong> las variables<br />
meteorológicas; sin embargo, las series más largas no pasan <strong>de</strong> unos<br />
pocos cientos <strong>de</strong> años. Para llevar a cabo estudios climáticos a tiempos muy<br />
largos (<strong>de</strong>l or<strong>de</strong>n <strong>de</strong> miles <strong>de</strong> años) es necesario disponer <strong>de</strong> series <strong>de</strong> datos<br />
más largas. Por ello, se han <strong>de</strong>sarrollado distintas técnicas indirectas
30 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
<strong>de</strong> medición a partir <strong>de</strong> indicadores <strong>de</strong> la naturaleza (datos “proxy”). Los<br />
más utilizados se obtienen <strong>de</strong> los árboles (fisiología <strong>de</strong> los anillos, análisis<br />
<strong>de</strong> isótopos, etc.), las catas <strong>de</strong> hielo (composición <strong>de</strong> isótopos, acumulación<br />
y estratificación, etc.), los corales (crecimiento, etc.), sedimentos oceánicos,<br />
fósiles, etc. Por ejemplo las extracciones <strong>de</strong>l hielo profundo <strong>de</strong> glaciares contienen<br />
muestras <strong>de</strong> burbujas <strong>de</strong> aire, polvo, polen, o isótopos <strong>de</strong> oxígeno,<br />
que sirven para reconstruir el clima pasado, <strong>de</strong>l área don<strong>de</strong> fue recogida la<br />
muestra.<br />
2.7.3. Simulaciones <strong>de</strong> Mo<strong>de</strong>los Numéricos<br />
Los campos resultantes <strong>de</strong> las integraciones <strong>de</strong> los mo<strong>de</strong>los numéricos <strong>de</strong>l<br />
tiempo <strong>de</strong>scritos en secciones anteriores caracterizan el estado <strong>de</strong> la atmósfera,<br />
tanto los análisis (estado inicial asimilado <strong>de</strong> la atmósfera), como las predicciones,<br />
y en muchos casos están disponibles para la comunidad investigadora.<br />
Por otra parte, también están disponibles los campos producidos por<br />
diversos proyectos <strong>de</strong> re-análisis que integran un mismo mo<strong>de</strong>lo <strong>de</strong> forma sucesiva<br />
para un período representativo <strong>de</strong> tiempo. Por ejemplo, el primer proyecto<br />
<strong>de</strong> re-análisis global llevado a cabo en el ECMWF se <strong>de</strong>nominó ERA-15<br />
y proporciona los campos <strong>de</strong> análisis y predicciones a corto plazo obtenidos<br />
con un mo<strong>de</strong>lo T106L31 (1.125 grados <strong>de</strong> resolución) para el período comprendido<br />
entre Diciembre-1978 y Febrero-1994. Recientemente, este proyecto<br />
ha sido extendido y ya se dispone <strong>de</strong> información para el período Septiembre<br />
1957 - Agosto 2002 (ERA-40) obtenida con un mo<strong>de</strong>lo <strong>de</strong> mayor resolución<br />
(T159L60, aprox. 0.675 grados). El NCEP también dispone <strong>de</strong> un re-análisis<br />
llevado a cabo con un mo<strong>de</strong>lo T62L28 (1.875 grados <strong>de</strong> resolución) para el<br />
período 1958 hasta la actualidad (para más información sobre actualizaciones<br />
<strong>de</strong>l re-análisis consultar wesley.wwb.noaa.gov/reanalysis2). La lista<br />
completa <strong>de</strong> variables disponibles para el proyecto ERA pue<strong>de</strong> consultarse<br />
en www.ecmwf.org/research/era, mientras que en el caso <strong>de</strong>l NCEP pue<strong>de</strong><br />
consultarse wesley.wwb.noaa.gov/reanalysis.html.<br />
En esta Tesis, se utiliza información <strong>de</strong> cada uno <strong>de</strong> los 4 análisis diarios<br />
<strong>de</strong> ERA-15, a las 00, 06, 12, y 18 horas UTC (Coor<strong>de</strong>nadas Universales <strong>de</strong><br />
Tiempo). El mo<strong>de</strong>lo <strong>de</strong> re-análisis posee información <strong>de</strong> variables en superficie<br />
y en niveles <strong>de</strong> presión, y <strong>de</strong> variables <strong>de</strong>rivadas que no son integradas<br />
directamente en el mo<strong>de</strong>lo. Básicamente las variables utilizadas en altura<br />
son el geopotencial (Z), temperatura (T), velocidad <strong>de</strong>l viento (U y V) y<br />
humedad relativa (H) en los niveles <strong>de</strong> presión <strong>de</strong> 1000, 925, 850, 700, 500,<br />
300 y 200 milibares (mb). A<strong>de</strong>más existen las variables <strong>de</strong> superficie, asociadas<br />
a cada una <strong>de</strong> las variables anteriores, que son: presión media a nivel<br />
<strong>de</strong>l mar (mslp), temperatura a 2 metros (T2), velocidad <strong>de</strong>l viento a 10<br />
metros (U10 y V10) y temperatura <strong>de</strong>l punto <strong>de</strong> rocío (Td). En total son<br />
5569 × 4 × 181 × 360 × 7 × 5 ≃ 5 × 10 10 datos. Estos datos se encuentran<br />
codificados en formato GRIB (WMO) y en total ocupa 100 GBytes <strong>de</strong> información<br />
<strong>de</strong>l re-análisis. En los distintos ejemplos presentados en esta Tesis
2.7. DATOS CLIMATOLÓGICOS Y METEOROLÓGICOS 31<br />
se consi<strong>de</strong>ran distintas regiones y combinaciones horarias <strong>de</strong> campos para<br />
<strong>de</strong>finir el “estado <strong>de</strong> la atmósfera”.<br />
Ejemplo 2.1 (Patrones Atmosféricos). Se <strong>de</strong>sea estudiar la configuración<br />
atmosférica diaria en la península Ibérica. Para po<strong>de</strong>r realizar un estudio<br />
estadístico se pue<strong>de</strong>n utilizar los campos <strong>de</strong> análisis proporcionados<br />
por un re-análisis (por ejemplo ERA-15), en una rejilla apropiada sobre la<br />
región <strong>de</strong> interés, en los distintos niveles <strong>de</strong> altura. Por ejemplo, para caracterizar<br />
el patrón <strong>de</strong> circulación que afecta a la península Ibérica se pue<strong>de</strong>n<br />
utilizar distintas rejillas y escalas temporales:<br />
70ºN<br />
(a)<br />
60ºN<br />
50ºN<br />
40ºN<br />
30ºN<br />
20ºN<br />
40ºW<br />
30º W<br />
20º W<br />
10 º W<br />
0<br />
º<br />
10 º E<br />
º<br />
20 E<br />
30 º E<br />
60º N<br />
(b)<br />
60º N<br />
(c)<br />
50º N<br />
50º N<br />
40º N<br />
40ºN<br />
30ºN<br />
30ºN<br />
20 W<br />
º 10º W<br />
0º<br />
10ºE<br />
20º E<br />
20 W<br />
º 10º W<br />
0º<br />
10ºE<br />
20º E<br />
Figura 2.9: Distintas áreas que cubren la península Ibérica: (a) Rejilla <strong>de</strong> larga<br />
escala (macro-β) <strong>de</strong> 2.5 ◦ × 2.5 ◦ <strong>de</strong> latitud y longitud; (b) rejilla peninsular (mesoα)<br />
1 ◦ × 1 ◦ <strong>de</strong> latitud y longitud; (c) rejilla meso-β 1 ◦ × 1 ◦ para la cuenca Norte <strong>de</strong><br />
la Pensínsula Ibérica (cada una <strong>de</strong> las doce cuencas tiene su propia rejilla).<br />
Mo<strong>de</strong>lo 1: Rejilla <strong>de</strong> 2.5 ◦ × 2.5 ◦ <strong>de</strong> longitud y latitud mostrada en<br />
la Figura 2.9(a). En este caso, los patrones se obtienen combinado los<br />
campos T, H, Z, U y V a las 12h en los niveles 1000mb, 925mb, 850mb,<br />
700mb, 500mb y 300mb:<br />
x 12 = (T 1000<br />
12 , . . .,T 300<br />
12 , H 1000<br />
12 , . . .,H 300<br />
12 , . . .,V 1000<br />
12 , . . .,V 300<br />
12 ), (2.18)<br />
don<strong>de</strong> X j i <strong>de</strong>nota el campo <strong>de</strong> la variable X a la hora i en el nivel j.<br />
Mo<strong>de</strong>lo 2: Rejilla <strong>de</strong> 1.0 ◦ ×1.0 ◦ mostrada en la Figura 2.9(b), cubriendo<br />
la zona <strong>de</strong> estudio. En este caso, se consi<strong>de</strong>ran las mismas variables
32 2. MODELOS Y DATOS ATMOSFÉRICOS<br />
y niveles <strong>de</strong> presión (altura), pero incluyendo una componente temporal<br />
(se toman los campos a las 06h y 30h). Esta componente temporal<br />
compensa la reducción <strong>de</strong> escala <strong>de</strong> la rejilla teniendo en cuenta efectos<br />
<strong>de</strong> bor<strong>de</strong> y <strong>de</strong> contorno que podrían alcanzar la zona <strong>de</strong> la rejilla<br />
durante el período <strong>de</strong> interés.<br />
x = (x 00 ,x 30 ). (2.19)<br />
Mo<strong>de</strong>lo 3: Rejilla <strong>de</strong> 1.0 ◦ × 1.0 ◦ mostrada en la Figura 2.9(c). En este<br />
caso se consi<strong>de</strong>ra un patrón atmosférico concreto para cada una <strong>de</strong><br />
las doce cuencas hidrográficas Españolas. Para ello se combinan los<br />
campos anteriores en un dominio temporal <strong>de</strong> mayor resolución: 06,<br />
12, 18, 24, y 30 UTC. En este caso se cubre el período <strong>de</strong> predicción<br />
con toda la información disponible:<br />
x = (x 06 ,x 12 ,x 18 ,x 24 ,x 30 ). (2.20)<br />
En ambos casos, los patrones obtenidos son <strong>de</strong> una enorme dimensión.<br />
Por ejemplo, en el caso <strong>de</strong> la Fig. 2.9(a) se tienen 17 × 21 (rejilla) ×3 (niveles<br />
<strong>de</strong> presión) ×5 (variables) = 5335 dimensiones para caracterizar un<br />
patrón atmosférico. Sin embargo, como se ilustra en el siguiente capítulo,<br />
estas variables están altamente correlacionadas y, en realidad, la información<br />
que contienen se pue<strong>de</strong> expresar utilizando un número menor <strong>de</strong> grados<br />
<strong>de</strong> libertad (variables).<br />
Junto con los re-análisis <strong>de</strong> mo<strong>de</strong>los numéricos que cubren períodos continuos,<br />
también se han elaborado bases <strong>de</strong> datos <strong>de</strong> observaciones homogeneizadas<br />
sobre rejillas y sin lagunas. Por ejemplo Chen et al. (2002) <strong>de</strong>scribe<br />
la elaboración <strong>de</strong> una base <strong>de</strong> datos con medias mensuales <strong>de</strong> precipitación<br />
en superficie para una rejilla <strong>de</strong> 2.5 o <strong>de</strong> resolución sobre todo el globo. La<br />
resolución <strong>de</strong> esta rejilla hace que sea poco útil para estudios regionales. Sin<br />
embargo, el INM también dispone <strong>de</strong> una rejilla <strong>de</strong> observaciones diarias <strong>de</strong><br />
mayor resolución que abarca el período ERA-15, interpoladas a partir <strong>de</strong> las<br />
observaciones <strong>de</strong> la red secundaria (ver Fig. 2.10).<br />
45.0 ° N<br />
42.5 ° N<br />
40.0 ° N<br />
37.5 ° N<br />
35.0 ° N<br />
10.0 ° W<br />
7.5 ° W<br />
5.0 ° W<br />
2.5 ° W<br />
0.0 °<br />
2.5 ° E<br />
5.0 ° E<br />
Figura 2.10: Rejilla <strong>de</strong> datos <strong>de</strong> precipitación en superficie interpolados <strong>de</strong> la red<br />
secundaria <strong>de</strong> observatorios <strong>de</strong>l INM.
CAPÍTULO 3<br />
Minería <strong>de</strong> Datos y Aprendizaje Automático<br />
3.1. Introducción<br />
El vertiginoso crecimiento <strong>de</strong> la capacidad <strong>de</strong> cálculo y almacenamiento<br />
<strong>de</strong> las computadoras ha producido un incremento exponencial <strong>de</strong> la información<br />
disponible proce<strong>de</strong>nte <strong>de</strong> simulaciones y observaciones atmosféricas,<br />
y ha hecho más fácil y rápido el acceso masivo a la misma (en tiempo real a<br />
través <strong>de</strong> Internet). Distintas bases <strong>de</strong> datos contienen información útil para<br />
diversos problemas, y requieren ser procesadas para sintetizar el conocimiento<br />
relevante para un problema dado. En el ámbito <strong>de</strong> la Meteorología se han<br />
utilizado <strong>de</strong> forma sistemática diversas técnicas Estadísticas para abordar<br />
distintos problemas <strong>de</strong> mo<strong>de</strong>lización y predicción a partir <strong>de</strong> observaciones<br />
y/o <strong>de</strong> salidas <strong>de</strong> mo<strong>de</strong>los numéricos (Ayuso, 1994). Sin embargo, el gran<br />
volumen <strong>de</strong> datos <strong>de</strong>l que se dispone hoy día hace necesario el uso <strong>de</strong> técnicas<br />
más eficientes, optimizadas para trabajar con gran<strong>de</strong>s muestras.<br />
En las dos últimas décadas se ha producido un gran avance en distintas<br />
áreas <strong>de</strong> la Inteligencia Artificial y Bases <strong>de</strong> Datos para <strong>de</strong>sarrollar<br />
técnicas automáticas <strong>de</strong> aprendizaje y extracción <strong>de</strong> conocimiento (ver<br />
Gutiérrez et al., 2004b). El objetivo <strong>de</strong> estas técnicas es preprocesar <strong>de</strong> forma<br />
rápida y fiable la información, capturando distintos patrones <strong>de</strong> conocimiento<br />
(reglas, grupos, grafos <strong>de</strong> <strong>de</strong>pen<strong>de</strong>ncia, etc.) que sean apropiados<br />
para resolver un problema dado, y que resuman la información disponible<br />
haciéndola manejable. Se trata también <strong>de</strong> que estas técnicas operen <strong>de</strong> forma<br />
automática, precisando <strong>de</strong> la mínima intervención humana. En la última<br />
década se ha acuñado el término Minería <strong>de</strong> Datos (Data Mining) para referirse<br />
a este área interdisciplinar que engloba una gran diversidad <strong>de</strong> técnicas.<br />
Para una visión general <strong>de</strong> este campo se refiere al lector a Fayyad et al.<br />
(1996); Witten and Frank (1999). Algunas aplicaciones en Meteorología se<br />
<strong>de</strong>scriben en Cofiño et al. (2003b).<br />
33
34 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
En este capítulo se <strong>de</strong>scriben algunas <strong>de</strong> estas técnicas, que serán utilizadas<br />
posteriormente en la Tesis. Se hará especial énfasis en algunas aplicaciones<br />
en los ámbitos <strong>de</strong> la Meteorología y Climatología relacionadas con<br />
los contenidos <strong>de</strong> esta Tesis:<br />
La regionalización consiste en la i<strong>de</strong>ntificación <strong>de</strong> regiones geográficas<br />
homogéneas con parámetros climatológicos similares (temperaturas,<br />
precipitación, etc.). Tradicionalmente este problema se ha abordado<br />
utilizando distintos criterios geográficos subjetivos, como la división<br />
impuesta por las cuencas hidrográficas, etc. Sin embargo la creciente<br />
disponibilidad <strong>de</strong> datos climatológicos en las últimas décadas (por<br />
ejemplo, las observaciones históricas <strong>de</strong> una red <strong>de</strong> estaciones) ha dado<br />
lugar al <strong>de</strong>sarrollo <strong>de</strong> técnicas <strong>de</strong> regionalización automáticas basadas<br />
en criterios estadísticos (ver Oliver, 1991). En este caso la regionalización<br />
automática se basa en la obtención <strong>de</strong> conjuntos homogéneos <strong>de</strong><br />
estaciones aplicando algún criterio <strong>de</strong> similitud a los datos disponibles.<br />
Por otra parte, la clasificación <strong>de</strong> patrones <strong>de</strong> circulación atmosférica<br />
consiste en obtener los estados característicos (los más frecuentes,<br />
persistentes, etc.) <strong>de</strong> la configuración <strong>de</strong> la atmósfera y clasificar cada<br />
nuevo patrón en base a la división realizada. Para ello se utilizan<br />
los campos numéricos asimilados por los mo<strong>de</strong>los <strong>de</strong> circulación atmosférica<br />
en un cierta rejilla 3D para caracterizar numéricamente la<br />
configuración atmosférica en un instante dado. En particular, los distintos<br />
reanálisis disponibles para un período representativo <strong>de</strong> tiempo<br />
(ver Sec. 2.7.3 para una <strong>de</strong>scripción <strong>de</strong> estos datos) ofrecen una muestra<br />
representativa para realizar este tipo <strong>de</strong> estudio.<br />
En la Sec. 3.2 se introduce la técnica <strong>de</strong> componentes principales y se<br />
ilustra su aplicación para reducir la elevada dimensionalidad <strong>de</strong> los datos,<br />
eliminando información redundante. A continuación, en la Sec. 3.3 se analizan<br />
distintas técnicas <strong>de</strong> agrupamiento; uno <strong>de</strong> estos métodos, las re<strong>de</strong>s<br />
auto-organizativas, se <strong>de</strong>scriben en la Sec. 3.4. Finalmente, la Sec. 3.5 <strong>de</strong>scribe<br />
las re<strong>de</strong>s neuronales <strong>de</strong>s<strong>de</strong> el punto <strong>de</strong> vista <strong>de</strong> los métodos estadísticos<br />
no paramétricos.<br />
3.2. Componentes Principales<br />
El análisis <strong>de</strong> Componentes Principales (CPs) es una técnica estándar<br />
para representar una muestra <strong>de</strong> datos en un espacio <strong>de</strong> menor dimensión<br />
que el original, eliminando la información redundante con la mínima pérdida<br />
<strong>de</strong> variabilidad; en otras palabras, es una técnica eficiente para comprimir información<br />
(Preisendorfer and Mobley, 1988). Este método es especialmente<br />
útil en espacios <strong>de</strong> alta dimensionalidad, don<strong>de</strong> los datos pue<strong>de</strong>n estar correlacionados<br />
en sus distintas componentes (dimensiones) y, por tanto, pue<strong>de</strong>n<br />
contener mucha información redundante en su <strong>de</strong>scripción. Un ejemplo típico
3.2. COMPONENTES PRINCIPALES 35<br />
en Meteorología lo constituye la caracterización <strong>de</strong> los patrones <strong>de</strong> circulación<br />
atmosférica, que vienen dados por los valores <strong>de</strong> una o varias magnitu<strong>de</strong>s<br />
(la presión a nivel <strong>de</strong>l mar, etc.) en una rejilla sobre una cierta zona<br />
<strong>de</strong> interés. Dado que estas magnitu<strong>de</strong>s están correlacionadas espacialmente,<br />
existirá una gran redundancia en esta forma <strong>de</strong> expresar los datos. Por<br />
tanto es necesario disponer <strong>de</strong> técnicas eficientes que permitan “comprimir”<br />
la información, hallando un espacio <strong>de</strong> menor dimensión don<strong>de</strong> los patrones<br />
proyectados conserven ciertos estadísticos <strong>de</strong> la muestra. La técnica <strong>de</strong> componentes<br />
principales reduce la dimensión <strong>de</strong>l espacio preservando el máximo<br />
<strong>de</strong> varianza <strong>de</strong> la muestra. Para ello, la base <strong>de</strong>l nuevo espacio se forma<br />
con aquellos vectores don<strong>de</strong> la muestra proyectada presenta mayor varianza.<br />
Los vectores <strong>de</strong> esta base (o Funciones Empíricas Ortogonales, EOF) son <strong>de</strong><br />
enorme utilidad en Meteorología, pues son los patrones dominantes (en el<br />
sentido <strong>de</strong> la variabilidad que representan <strong>de</strong> la muestra).<br />
Se parte <strong>de</strong> una muestra <strong>de</strong> m realizaciones <strong>de</strong> un vector<br />
x k = (x k1 , ..., x kn ) T , k = 1, . . .,m, (3.1)<br />
<strong>de</strong>finido en un espacio n-dimensional con base canónica {e 1 , . . .,e n }. Se<br />
<strong>de</strong>sea obtener un subespacio <strong>de</strong> dimensión d < n, dado por una nueva base<br />
{f 1 , . . .,f d } (siendo cada f j una combinación lineal <strong>de</strong> los vectores e i <strong>de</strong> la<br />
base canónica). El criterio para obtener este subespacio es que la muestra<br />
proyectada<br />
d∑<br />
¯x k = f i c ki , (3.2)<br />
i=1<br />
tenga una varianza máxima. El cálculo matemático para obtener los vectores<br />
óptimos f i es sencillo y consiste en estimar la matriz <strong>de</strong> varianzas y<br />
covarianzas a partir <strong>de</strong> la muestra <strong>de</strong> datos. Los autovectores (o Funciones<br />
Ortogonales Empíricas , EOFs) <strong>de</strong> esta matriz son los nuevos vectores f i y<br />
los correspondientes autovalores indican la varianza explicada (la varianza<br />
<strong>de</strong> la muestra proyectada sobre el vector). Los coeficientes <strong>de</strong> cada elemento<br />
<strong>de</strong> la muestra en la nueva base se <strong>de</strong>nominan Componentes Principales<br />
(CPs).<br />
Dada la muestra (3.1), se pue<strong>de</strong> estimar la matriz <strong>de</strong> varianzas y covarianzas<br />
C x , don<strong>de</strong> cada elemento σ ij representa la covarianza <strong>de</strong> los datos<br />
entre la variable i y la j <strong>de</strong>l espacio original:<br />
σ ij =< (x ki − µ i )(x kj − µ j ) > k ; µ i =< x ki > k , µ j =< x kj > k . (3.3)<br />
Esta matriz <strong>de</strong> varianzas y covarianzas es cuadrada y simétrica por lo que<br />
se pue<strong>de</strong> calcular una nueva base ortogonal encontrando sus autovalores λ i<br />
(que serán reales y distintos) y los correspondientes autovectores f i :<br />
C x f i = λ i f i . (3.4)<br />
Es fácil resolver este problema cuando n es pequeño pero, a medida que<br />
aumenta la dimensión, el problema se complica <strong>de</strong>bido al posible mal condicionamiento<br />
<strong>de</strong> la matriz. En estos casos es necesario aplicar métodos
36 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
numéricos eficientes como la Descomposición en Valores Sigulares (SVD),<br />
que proporciona una factorización <strong>de</strong> la matriz C x <strong>de</strong> la forma (ver Press et al.<br />
(1992) para más <strong>de</strong>talles):<br />
Σ x = P Λ P T , (3.5)<br />
don<strong>de</strong> Λ es una matriz diagonal que contiene los autovalores λ i (or<strong>de</strong>nados<br />
<strong>de</strong> forma <strong>de</strong>creciente) <strong>de</strong> C x , y las columnas <strong>de</strong> P son los correspondientes<br />
autovectores f i . A<strong>de</strong>más P es una matriz ortogonal y P T es su inversa. De<br />
esta manera, si hacemos la proyección:<br />
¯x k = P T x k =<br />
⎛<br />
⎜<br />
⎝<br />
f 11<br />
.<br />
f n1<br />
⎞ ⎛<br />
. . . f 1n<br />
⎟ ⎜<br />
. ⎠ ⎝<br />
. . . f nn<br />
⎞<br />
x 1k<br />
⎟<br />
. ⎠ (3.6)<br />
x nk<br />
se tendrá el elemento <strong>de</strong> la muestra proyectado sobre la base <strong>de</strong> autovectores<br />
<strong>de</strong> C x , mientras que la proyección inversa se obtendrá mediante x k = P¯x k .<br />
Esta proyección tiene las siguientes propieda<strong>de</strong>s:<br />
Componentes incorrelacionadas: < ¯x ki ¯x kj > k = 0, i ≠ j.<br />
V ar(¯x i ) = λ i , i = 1, . . .,n.<br />
∑ ni=1<br />
V ar(x i ) = ∑ n<br />
i=1 V ar(¯x i ) = ∑ n<br />
i=1 λ i .<br />
Dado que los vectores se eligen en or<strong>de</strong>n <strong>de</strong>creciente <strong>de</strong> varianza, es posible<br />
hacer un recorte <strong>de</strong> dimensiones reteniendo la máxima cantidad posible <strong>de</strong><br />
varianza (obviamente, si se quiere conservar toda la varianza habrá que<br />
tomar d = n). Si se toman sólo las d primeras EOFs, cada elemento <strong>de</strong> la<br />
muestra se podrá expresar aproximadamente como:<br />
⎛<br />
x k ≈ QQ T x k =<br />
⎜<br />
⎝<br />
f 11<br />
.<br />
.<br />
f 1n<br />
⎞<br />
. . . f d1 ⎛<br />
.<br />
⎜<br />
⎝<br />
⎟<br />
. ⎠<br />
. . . f dn<br />
⎞<br />
f 11 . . .... f 1n<br />
⎟<br />
. . ⎠x k , (3.7)<br />
f d1 . . .... f dn<br />
don<strong>de</strong> Q representa a la matriz P truncada a los d primeros autovectores.<br />
El vector ¯x k = Q T x k <strong>de</strong> dimensión d×1 contendrá las CPs <strong>de</strong>l patrón x k , es<br />
<strong>de</strong>cir, las componentes <strong>de</strong>l vector en el nuevo espacio <strong>de</strong> dimensión d. Para<br />
recuperar la dimensión original, el vector <strong>de</strong> CPs se proyectará mediante<br />
Q¯x k , obteniendo una aproximación <strong>de</strong>l vector original (mejor cuanto mayor<br />
sea la dimensión d <strong>de</strong>l espacio proyector).<br />
Maximizar la varianza es equivalente a minimizar la norma cuadrática<br />
<strong>de</strong> los residuos ¯x k − x k .<br />
V ar(x k ) = V ar(x k + Q¯x k − Q¯x k ) = V ar(x k − Q¯x k ) + V ar(Q¯x k ) (3.8)
3.2. COMPONENTES PRINCIPALES 37<br />
Por tanto, la técnica <strong>de</strong> componentes principales obtiene la proyección lineal<br />
óptima en sentido <strong>de</strong> máxima varianza explicada y <strong>de</strong> mínimo error <strong>de</strong><br />
reconstrucción.<br />
Para eliminar los problemas <strong>de</strong>bidos a las distintas escalas <strong>de</strong> cada una <strong>de</strong><br />
las componentes <strong>de</strong>l vector, es conveniente estandarizar los datos como paso<br />
previo a realizar el análisis. De esta forma se evita que las variables <strong>de</strong> mayor<br />
varianza se hagan dominantes en el análisis. En el caso <strong>de</strong> datos atmosféricos<br />
se han <strong>de</strong> estandarizar por separado los valores correspondientes a cada<br />
punto <strong>de</strong> rejilla, <strong>de</strong> forma que la variabilidad <strong>de</strong>l patrón en toda la extensión<br />
espacial sea homogénea. Otro procedimiento consiste en utilizar la matriz <strong>de</strong><br />
correlaciones en lugar <strong>de</strong> la <strong>de</strong> varianza-covarianza para realizar el análisis<br />
(Noguer, 1994).<br />
Recientemente se han <strong>de</strong>scrito en la literatura extensiones no lineales <strong>de</strong><br />
esta técnica que proyectan los datos a través <strong>de</strong> combinaciones no lineales <strong>de</strong><br />
las variables originales maximizando la varianza explicada o minimizando el<br />
error cuadrático (re<strong>de</strong>s neuronales <strong>de</strong> cuello <strong>de</strong> botella, Kramer (1991), etc.).<br />
Los métodos resultantes tienen mayor flexibilidad que las técnicas lineales,<br />
pero la mejora que ofrecen no justifica algunas <strong>de</strong>ficiencias, como la carencia<br />
<strong>de</strong> propieda<strong>de</strong>s como la ortogonalidad <strong>de</strong> la base.<br />
Ejemplo 3.1 (EOFs y CPs <strong>de</strong> Patrones Atmosféricos). En este ejemplo<br />
se aplica la técnica <strong>de</strong> componentes principales para hallar los patrones<br />
<strong>de</strong> presión a nivel <strong>de</strong>l mar (Sea Level Pressure, SLP) dominantes en tres<br />
zonas <strong>de</strong>l globo (ver Fig. 3.1), con características diferentes <strong>de</strong> circulación<br />
atmosférica y oceánica. Para ello, se han consi<strong>de</strong>rado medias <strong>de</strong>cenales <strong>de</strong><br />
patrones diarios <strong>de</strong> SLP en tres rejillas distintas que <strong>de</strong>finen la región <strong>de</strong>l<br />
Atlántico Norte (AN), la región <strong>de</strong>l Pacífico Sur (PS), y la zona <strong>de</strong> América<br />
Austral (Austral), respectivamente. Los datos disponibles cubren el período<br />
1979-1993 correspondiente al re-análisis ERA-15. La siguiente tabla muestra<br />
la varianza explicada por las cuatro primeras EOF en cada caso, ilustrando<br />
las diferencias entre las distintas zonas:<br />
AN PS Austral<br />
EOF 1 32.91 59.90 25.90<br />
EOF 2 19.14 12.71 22.62<br />
EOF 3 14.40 7.69 20.52<br />
EOF 4 8.86 5.26 9.86<br />
Acumulado 75.31 85.66 78.90<br />
En los tres casos existe una enorme redundancia en los datos, y una<br />
proporción muy pequeña <strong>de</strong> las variables permite explicar una alto porcentaje<br />
<strong>de</strong> la varianza. La zona <strong>de</strong>l PS es la que mayor redundancia muestra (la<br />
primera EOF explica cerca <strong>de</strong>l 60% <strong>de</strong> la varianza), mientras que las zonas<br />
AN y Austral presentan una varianza acumulada similar; sin embargo, esta<br />
varianza está igualmente distribuida entre las tres primeras EOFs en el caso<br />
Austral, mientras que <strong>de</strong>cae uniformemente en el AN. Esto nos muestra
38 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
que la presión en los trópicos tiene mucha más correlación espacial que en<br />
latitu<strong>de</strong>s medias y, a su vez, la correlación en latitu<strong>de</strong>s medias se expresa <strong>de</strong><br />
forma distinta en distintas regiones <strong>de</strong>l globo.<br />
45 ° N<br />
0 °<br />
45 ° S<br />
135 ° W<br />
90 ° W<br />
45 ° W<br />
0 °<br />
Figura 3.1: Zonas geográficas correspondientes al Atlántico Norte, Pacífico Sur, y<br />
América Austral. Las rejillas (2.5 o × 2.5 o ) muestran los puntos <strong>de</strong> grid utilizados<br />
para caracterizar los patrones <strong>de</strong> presión a nivel <strong>de</strong>l mar.<br />
La Fig. 3.2 muestra las cuatro primeras EOFs para la zona NAO y la zona<br />
Austral. Estos patrones maximizan la varianza proyectada <strong>de</strong> la muestra<br />
y, por tanto, <strong>de</strong>finen los fenómenos sinópticos más relevantes que explican la<br />
variabilidad climática. Por ejemplo, la primera EOF <strong>de</strong> la zona AN correspon<strong>de</strong><br />
al patrón <strong>de</strong> variabilidad anual <strong>de</strong> la presión, mientras que la segunda<br />
EOF correspon<strong>de</strong> al patrón <strong>de</strong> la NAO (North Atlantic Oscillation), y las<br />
siguientes están relacionadas con patrones como la EA (East Atlantic In<strong>de</strong>x),<br />
AO (Artic Oscillation), etc. (ver, por ejemplo, Corte-Real et al., 1999;<br />
Rodríguez-Fonseca and Serrano, 1991, para una <strong>de</strong>tallada <strong>de</strong>scripción <strong>de</strong> estos<br />
patrones <strong>de</strong> teleconexión).<br />
La evolución temporal <strong>de</strong> las CPs nos da un i<strong>de</strong>a <strong>de</strong> la frecuencia <strong>de</strong><br />
variación temporal <strong>de</strong> los fenómenos caracterizados por la correspondiente<br />
EOF. Por ejemplo la Figura 3.3 muestra la evolución <strong>de</strong> la CPs para la<br />
región <strong>de</strong>l AN. Pue<strong>de</strong> observarse la frecuencia anual <strong>de</strong> la primera EOF,<br />
mientras que las restantes presentan variabilida<strong>de</strong>s temporales más complejas,<br />
relacionadas con las oscilaciones <strong>de</strong> los correspondientes patrones.
1032<br />
3.2. COMPONENTES PRINCIPALES 39<br />
1029<br />
1084<br />
1066<br />
1047<br />
1121<br />
1102<br />
1049<br />
995<br />
1006<br />
1027<br />
1070<br />
1060<br />
1016<br />
1010<br />
973<br />
1081<br />
992<br />
1038<br />
1016<br />
1006<br />
995<br />
1021<br />
1001<br />
1031<br />
982<br />
1011<br />
1021<br />
992<br />
972<br />
962<br />
953<br />
993 1000<br />
981<br />
1025<br />
1013<br />
1013<br />
1019<br />
1006<br />
1038<br />
1025<br />
1032<br />
1019<br />
1006<br />
1040<br />
1025<br />
946<br />
931<br />
915<br />
1009<br />
993<br />
978<br />
962<br />
899<br />
884<br />
1009<br />
1032<br />
1024<br />
979<br />
994<br />
1009<br />
1017<br />
964<br />
986<br />
971<br />
1002<br />
986<br />
1034<br />
1047<br />
1022<br />
1021<br />
1034<br />
1060<br />
1022<br />
996<br />
1009<br />
984<br />
971<br />
958<br />
1021<br />
1013<br />
1005<br />
998<br />
990<br />
1005<br />
1013<br />
966<br />
1021<br />
958<br />
982<br />
974<br />
Figura 3.2: Cuatro primeras EOF correspondientes al área geográfica <strong>de</strong>l Atlántico<br />
Norte (AN) y <strong>de</strong> América Austral (Austral).
40 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
40<br />
20<br />
0<br />
-20<br />
-40<br />
40<br />
20<br />
0<br />
-20<br />
-40<br />
CP1<br />
CP2<br />
40<br />
20<br />
0<br />
-20<br />
-40<br />
20<br />
CP3<br />
CP4<br />
0<br />
-20<br />
0 750 1500 2250 3000 3750 4500 5250<br />
day number<br />
Figura 3.3: Evolución temporal <strong>de</strong> las cuatro primeras CPs en la zona <strong>de</strong>l AN.<br />
3.2.1. Elección <strong>de</strong>l Número <strong>de</strong> Componentes<br />
Una cuestión importante en la práctica es <strong>de</strong>terminar el número <strong>de</strong> CPs<br />
que <strong>de</strong>ben tomarse para un <strong>de</strong>terminado problema, <strong>de</strong> forma que haya un<br />
equilibrio entre la reducción <strong>de</strong> información <strong>de</strong>seada y la calidad <strong>de</strong> la aproximación<br />
resultante. Una forma objetiva <strong>de</strong> seleccionar el número necesario<br />
<strong>de</strong> CPs es imponer un umbral para el error <strong>de</strong> reconstrucción obtenido (el<br />
error residual). Por ejemplo, la Figura 3.4 muestra el error <strong>de</strong> reconstrucción<br />
(Root Mean Square Error, RMSE) frente al porcentaje <strong>de</strong> CPs utilizadas<br />
para el patrón atmosférico Mo<strong>de</strong>lo 2 <strong>de</strong>l Ejemplo 2.1 (estandarizando las<br />
variables antes <strong>de</strong> aplicar el algoritmo). En la figura se muestran los errores<br />
separadamente para cada variable. A pesar <strong>de</strong> que las CPs se han obtenido<br />
globalmente combinando todas las variables, los errores <strong>de</strong> reconstrucción<br />
son similares para todas ellas. Sólo en el caso <strong>de</strong> consi<strong>de</strong>rar un número pequeño<br />
<strong>de</strong> CPs se pue<strong>de</strong>n apreciar diferencias en los errores <strong>de</strong> reconstrucción,<br />
siendo éstos inferiores en patrones más suaves (por ejemplo Z o T).<br />
Por ejemplo, se pu<strong>de</strong> adoptar como criterio que los errores <strong>de</strong> reconstrucción<br />
sean inferiores a los errores <strong>de</strong> asimilación habituales en los mo<strong>de</strong>los<br />
numéricos. En la Fig. 3.4 se observa que utilizando tan sólo un 10 % <strong>de</strong> las<br />
variables originales se tiene un error <strong>de</strong> reconstrucción menor <strong>de</strong>l 2 % <strong>de</strong> la<br />
<strong>de</strong>sviación estándar <strong>de</strong> los campos 3D, cifra inferior a los errores promedio<br />
<strong>de</strong> asimilación. Un criterio alternativo para seleccionar el número apropiado<br />
<strong>de</strong> componentes principales sería utilizar la distancia promedio entre los<br />
patrones vecinos en una base <strong>de</strong> datos <strong>de</strong> re-análisis.<br />
Otro criterio más práctico para seleccionar el número óptimo <strong>de</strong> CPs<br />
sería elegir el que proporcione mejores resultados <strong>de</strong> validación cuando se<br />
aplique un método concreto. En esta Tesis se aborda el problema <strong>de</strong> la
3.2. COMPONENTES PRINCIPALES 41<br />
RMSE of standarized fields<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0.02<br />
0.01<br />
Z<br />
T<br />
U<br />
V<br />
RH<br />
0<br />
10 15 20 25<br />
0<br />
0 5 10 15 20 25<br />
% of Principal Components<br />
Figura 3.4: Error RMSE <strong>de</strong> reconstrucción para cada una <strong>de</strong> las cinco variables<br />
en el Mo<strong>de</strong>lo 1 (el error es calculado para los campos 3D normalizados) frente al<br />
número <strong>de</strong> CPs (variando <strong>de</strong>s<strong>de</strong> 1 % <strong>de</strong> la dimensión <strong>de</strong>l vector original, al 25 %).<br />
predicción meteorológica probabilística local utilizando distintas técnicas <strong>de</strong><br />
agrupamiento. Por tanto, un criterio a seguir para elegir el número óptimo<br />
<strong>de</strong> CPs sería en base al menor error <strong>de</strong> validación. Por ejemplo, la Fig.<br />
3.5 muestra la evolución <strong>de</strong>l índice <strong>de</strong> pericia <strong>de</strong> Brier (Brier Skill Score,<br />
BSS; ver Cap. 4) en función <strong>de</strong>l número <strong>de</strong> CPs consi<strong>de</strong>radas al aplicar un<br />
método estándar <strong>de</strong> predicción local <strong>de</strong>nominado k-NN (ver Cap. 5). Esta<br />
figura indica que el número <strong>de</strong> componentes relevantes para el método es<br />
sustancialmente bajo (menor <strong>de</strong> 25 para umbrales bajos <strong>de</strong> precipitación).<br />
Así mismo, se observa que a medida que el evento es más raro (por ejemplo<br />
Precip > 20mm), el número <strong>de</strong> componentes óptimo se incrementa sustancialmente.<br />
Este ejemplo ilustra que el número <strong>de</strong> componentes principales<br />
relevantes <strong>de</strong>pen<strong>de</strong> sustancialmente <strong>de</strong>l problema que se <strong>de</strong>sea resolver y <strong>de</strong>l<br />
método utilizado para su resolución.<br />
0.5<br />
0.4<br />
0.3<br />
BSS<br />
0.2<br />
0.1<br />
> 0.1mm<br />
> 2mm<br />
> 10mm<br />
> 20mm<br />
0<br />
0 25 50 75 100 125 150<br />
Número <strong>de</strong> CPs<br />
Figura 3.5: Evolución <strong>de</strong>l Brier Skill Score (BSS) para la predicción <strong>de</strong> los eventos<br />
Precip > 0.1mm, 2, 10, y 20mm.
42 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
3.2.2. Efectos <strong>de</strong> la Escala Temporal<br />
La escala temporal <strong>de</strong> los datos viene dada por el tipo <strong>de</strong> estudio que<br />
se <strong>de</strong>see realizar. En estudios <strong>de</strong> tipo climático, que sólo analizan patrones<br />
sinópticos promedio semanales o mensuales <strong>de</strong> gran escala, el número <strong>de</strong><br />
componentes tomadas suele ser reducido, y cada una <strong>de</strong> las EOFs resultantes<br />
se analiza en el contexto <strong>de</strong> los distintos patrones <strong>de</strong> teleconexión, buscando<br />
una interpretación <strong>de</strong>l patrón resultante, como se mostró en el Ejemplo 3.1.<br />
En cambio, cuando se llevan a cabo estudios sobre regiones más reducidas<br />
y con patrones <strong>de</strong> mayor variabilidad temporal (diarios, horarios, etc.) el<br />
número <strong>de</strong> CPs crece <strong>de</strong> forma consi<strong>de</strong>rable, ya que la correlación espacial<br />
<strong>de</strong> los patrones disminuye. En el siguiente ejemplo, se ilustra este hecho.<br />
Ejemplo 3.2 (Componentes Principales y Escala Temporal). Un<br />
ejemplo más notorio lo constituyen los datos <strong>de</strong> observaciones en un red<br />
<strong>de</strong> estaciones sobre una zona <strong>de</strong> interés. Se consi<strong>de</strong>ran las 100 estaciones<br />
climáticas <strong>de</strong> la red principal <strong>de</strong>l INM mostradas en la Fig. 2.8, tomando<br />
patrones diarios formados por los correspondientes 100 valores diarios <strong>de</strong><br />
temperatura, precipitación, o <strong>de</strong> racha máxima <strong>de</strong> viento. En la Figura 3.6<br />
se muestra el porcentaje <strong>de</strong> varianza explicada en función <strong>de</strong>l número <strong>de</strong> CPs<br />
tomadas para el patrón atmosférico <strong>de</strong>l Ejemplo 2.1 (Mo<strong>de</strong>lo 2) consi<strong>de</strong>rado<br />
en la sección anterior, y los patrones <strong>de</strong> observaciones <strong>de</strong> temperatura,<br />
precipitación y racha máxima.<br />
% Varianza explicada<br />
100<br />
80<br />
60<br />
40<br />
20<br />
0<br />
0 20 40 60 80 100<br />
%CPs<br />
(c) Temperatura máxima<br />
100<br />
(a) Patrones diarios<br />
(a)<br />
Estado <strong>de</strong> la Atmósfera<br />
Temperatura máxima<br />
Racha máxima<br />
Precipitación<br />
% Varianza explicada<br />
100<br />
80<br />
60<br />
40<br />
20<br />
Precipitación/24h<br />
Precipitación/10días<br />
Precipitación/30días<br />
Precipitación/90días<br />
0<br />
0 20 40 60 80 100<br />
%CPs<br />
(d) Racha máxima<br />
100<br />
(b) Precipitación<br />
% Varianza explicada<br />
90<br />
80<br />
70<br />
60<br />
50<br />
40<br />
Temperatura máxima/24h<br />
Temperatura máxima/10días<br />
Temperatura máxima/30días<br />
30<br />
0 20 40 60 80 100<br />
%CPs<br />
% Varianza explicada<br />
80<br />
60<br />
40<br />
Racha máxima/24h<br />
Racha máxima/10días<br />
20<br />
Racha máxima/30días<br />
Racha máxima/90días<br />
0<br />
0 20 40 60 80 100<br />
%CPs<br />
Figura 3.6: Porcentaje <strong>de</strong> varianza explicada en función <strong>de</strong>l número <strong>de</strong> EOFs<br />
consi<strong>de</strong>ras para patrones atmosféricos, temperatura, precipitación y racha máxima.
3.3. TÉCNICAS DE AGRUPAMIENTO 43<br />
En esta figura pue<strong>de</strong> verse que el patrón atmosférico está altamente correlacionado<br />
y, por tanto, el porcentaje <strong>de</strong> varianza explicado con unas pocas<br />
CPs es muy elevado; por el contrario, la precipitación y la racha máxima<br />
presentan una menor correlación espacial y requieren <strong>de</strong> un número mayor<br />
<strong>de</strong> EOFs para ser representados a<strong>de</strong>cuadamente. La temperatura muestra un<br />
comportamiento intermedio.<br />
Por otra parte, las Figuras 3.6(b)-(d) muestran el aumento <strong>de</strong> la correlación<br />
espacial al consi<strong>de</strong>rar promedios temporales (medias diarias, <strong>de</strong>cenal,<br />
mensual y estacional) <strong>de</strong> esas mismas variables. Por tanto, a medida que<br />
crece la escala temporal don<strong>de</strong> el patrón está promediado, <strong>de</strong>crece el número<br />
<strong>de</strong> CPs necesario para alcanzar un umbral requerido. Por tanto, estudios <strong>de</strong><br />
escala estacional, o <strong>de</strong> cambio climático, que trabajan con promedios mensuales<br />
<strong>de</strong> las variables requerirán un número menor <strong>de</strong> CPs que estudios que<br />
requieran el uso <strong>de</strong> patrones diarios.<br />
3.3. Técnicas <strong>de</strong> <strong>Agrupamiento</strong><br />
En esta sección se <strong>de</strong>scriben brevemente las técnicas clásicas y mo<strong>de</strong>rnas<br />
<strong>de</strong> agrupamiento que son utilizadas en numerosas disciplinas para dividir<br />
un conjunto <strong>de</strong> datos en subconjuntos homogéneos siguiendo algún criterio<br />
<strong>de</strong> similitud (ver An<strong>de</strong>rberg, 1973, para una <strong>de</strong>scripción <strong>de</strong>tallada <strong>de</strong> estos<br />
métodos). Una primera división <strong>de</strong> estas técnicas se pue<strong>de</strong> establecer en base<br />
a su carácter jerárquico o particional, según las características <strong>de</strong>l proceso<br />
seguido para construir los grupos.<br />
3.3.1. Técnicas Jerárquicas<br />
Las técnicas <strong>de</strong> agrupamiento jerárquico son iterativas y proce<strong>de</strong>n uniendo<br />
grupos pequeños (técnicas aglomerativas), o dividiendo grupos gran<strong>de</strong>s<br />
(técnicas divisivas), don<strong>de</strong> el concepto <strong>de</strong> tamaño viene dado por la medida<br />
<strong>de</strong> similitud utilizada (correlación, distancia, información mutua, etc.).<br />
Dentro <strong>de</strong> estos métodos <strong>de</strong>stacan los llamados SHAN, que comparten las<br />
siguientes características:<br />
Secuencial (Sequential): el mismo algoritmo es aplicado iterativamente<br />
a los grupos disponibles.<br />
Jerárquico (Hierarchical): la secuencia <strong>de</strong> uniones <strong>de</strong> grupos se representa<br />
mediante una estructura <strong>de</strong> árbol.<br />
Aglomerativa (Agglomerative): inicialmente cada punto <strong>de</strong>l conjunto<br />
<strong>de</strong> datos es asignado a un grupo distinto; y el algoritmo proce<strong>de</strong><br />
uniendo los grupos mas similares hasta que el criterio <strong>de</strong> parada es<br />
alcanzado.<br />
Sin-solapamiento (Non-overalpping): ningún elemento pue<strong>de</strong> pertenecer<br />
simultáneamente a dos grupos diferentes.
44 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
Varias alternativas son posibles, <strong>de</strong>pendiendo <strong>de</strong> la métrica utilizada para<br />
<strong>de</strong>finir la similitud entre grupos. Por un lado, el método conocido como “enlace<br />
promedio” <strong>de</strong>fine una distancia inter-grupo como la distancia promedio<br />
entre todos los posibles pares <strong>de</strong> elementos en los dos grupos comparados.<br />
Este método tien<strong>de</strong> a formar grupos con varianzas similares. Por otro lado, el<br />
“enlace <strong>de</strong> Ward” mezcla aquellos pares <strong>de</strong> grupos que minimizan la dispersión<br />
<strong>de</strong>l grupo resultante. En este caso, el cuadrado <strong>de</strong> la distancia Euclí<strong>de</strong>a<br />
es tomada como medida <strong>de</strong> diferencia (para más <strong>de</strong>talles sobre la aplicación<br />
<strong>de</strong> estos métodos en Meteorología consultar Kalkstein et al. (1987)). A<br />
continuación, se <strong>de</strong>scribe el método <strong>de</strong> Ward como ejemplo <strong>de</strong> estas técnicas.<br />
Dado un conjunto <strong>de</strong> datos {v 1 , v 2 , . . .,v n }, este método <strong>de</strong>scompone la<br />
varianza total V en varianzas intragrupo, para los grupos actuales C i con<br />
centroi<strong>de</strong>s c i y peso, o masa, m i (en un paso <strong>de</strong> iteración dado) y la varianza<br />
entre grupos:<br />
V = ∑ m q ||c q − c|| 2 + ∑ ∑<br />
m i ||v i − c q || 2 , (3.9)<br />
q<br />
q i∈C q<br />
don<strong>de</strong> c es el centroi<strong>de</strong> global (media <strong>de</strong> los datos).<br />
Si dos grupos C i y C j , con masas m i y m j respectivamente, son unidos<br />
en un solo grupo, D, con masa m i + m j y centroi<strong>de</strong><br />
d = m ic i + m j c j<br />
m i + m j<br />
, (3.10)<br />
entonces la varianza V ij <strong>de</strong> C i y C j respecto a D pue<strong>de</strong>n ser <strong>de</strong>scompuestas<br />
por la ecuación<br />
V ij = m i ||c i − d|| 2 + m j ||c j − d|| 2 + m||d − c|| 2 . (3.11)<br />
El último término es el único que permanece constante si cambiamos C i y<br />
C j por el centro <strong>de</strong> gravedad D. Entonces, la reducción <strong>de</strong> la varianza será:<br />
Usando (3.10), se tiene:<br />
∆V ij = m i ||c i − d|| 2 + m j ||c j − d|| 2 . (3.12)<br />
∆V ij<br />
= m i ||c i − m ic i + m j c j<br />
|| 2 + m j ||c j − m ic i + m j c j<br />
|| 2<br />
m i + m j<br />
m i + m j<br />
m i m j<br />
= ||c i − c j || 2 . (3.13)<br />
m i + m j<br />
Luego la estrategia seguida por este método es la unión, en cada paso, <strong>de</strong><br />
grupos C i y C j que minimiza ∆V ij (inicialmente cada punto es consi<strong>de</strong>rado<br />
como un solo grupo). Así que se pue<strong>de</strong> consi<strong>de</strong>rar ∆V ij como la medida <strong>de</strong><br />
disimilitud. Notar que los elementos con menos peso son los primeros en<br />
unirse entre sí.<br />
El algoritmo <strong>de</strong> agrupamiento pue<strong>de</strong> ser representado gráficamente mediante<br />
un “<strong>de</strong>ndrograma” (un árbol representando en diferentes niveles la<br />
jerarquía <strong>de</strong> uniones <strong>de</strong> los grupos individuales o grupos en diferentes pasos).
3.3. TÉCNICAS DE AGRUPAMIENTO 45<br />
Ejemplo 3.3 (Regionalización Automática). Una <strong>de</strong> las primeras clasificaciones<br />
climatológicas basadas en criterios estadísticos es la <strong>de</strong>bida a<br />
Köppen (1918), que <strong>de</strong>finió un conjunto <strong>de</strong> climas basado en combinaciones<br />
<strong>de</strong> umbrales para la precipitación y temperatura en las distintas estaciones<br />
<strong>de</strong>l año (ver Oliver, 1991, para una <strong>de</strong>scripción histórica <strong>de</strong> las técnicas <strong>de</strong><br />
clasificación climática). Esta clasificación aún continúa vigente y es el punto<br />
<strong>de</strong> partida <strong>de</strong> estudios más sistemáticos <strong>de</strong> regionalización. En fechas más<br />
recientes, las técnicas basadas en métodos <strong>de</strong> agrupamiento han mostrado<br />
ser simples y eficientes para este problema (ver Fovell and Fovell, 1993).<br />
A la hora <strong>de</strong> aplicar técnicas <strong>de</strong> agrupamiento para el problema <strong>de</strong> la regionalización,<br />
primero hay que <strong>de</strong>cidir qué variables van a consi<strong>de</strong>rarse para<br />
<strong>de</strong>finir la climatología local <strong>de</strong> las distintas estaciones. Existen numerosas<br />
fuentes <strong>de</strong> información que permiten y discriminar a<strong>de</strong>cuadamente distintas<br />
regiones con climatologías homogéneas: geográficas (como longitud, latitud,<br />
elevación, pertenencia a cuencas hidrográficas), estadísticas (temperaturas<br />
extremas, medias mensuales, precipitación acumulada, humedad relativa,<br />
etc.). Las técnicas <strong>de</strong> agrupamiento permiten realizar <strong>de</strong> forma automática<br />
distintos experimentos combinando estas variables. En el siguiente ejemplo<br />
se muestra una sencilla aplicación consi<strong>de</strong>rando sólamente información relativa<br />
a la precipitación (ésta es la variable esencial en problemas hidrológicos,<br />
agrícolas y ecológicos). Cada estación es representada por un vector<br />
que caracteriza su climatología local. En este ejemplo, cada estación está caracterizada<br />
por un vector v = (mp v , mp i ), don<strong>de</strong> mp v y mp i son las medias<br />
estacionales <strong>de</strong> precipitación para verano e invierno, respectivamente.<br />
Se consi<strong>de</strong>ran datos <strong>de</strong> 30 años para un conjunto <strong>de</strong> 54 estaciones <strong>de</strong> la<br />
península Ibérica (ver Fig. 3.7(a)).<br />
44<br />
(a)<br />
(b)<br />
40<br />
36<br />
Norte<br />
Duero<br />
Tajo<br />
Guadiana<br />
Guadalquivir<br />
Mediterraneo<br />
Ebro<br />
-10 -5 0 5 -10 -5 0 5<br />
Figura 3.7: (a) Red <strong>de</strong> 54 estaciones automáticas en España; (b) Estaciones correspondientes<br />
a cada una <strong>de</strong> las siete cuencas hidrográficas principales: Norte, Duero,<br />
Tajo, Guadiana, Guadalquivir-Sur, Mediterraneo, y Ebro.<br />
En todos los casos, las observaciones <strong>de</strong> precipitación diaria están disponibles<br />
<strong>de</strong> 1970 a 2000, sin falta <strong>de</strong> datos ni lagunas. La Fig. 3.8 muestra los<br />
grupos obtenidos aplicando el algoritmo <strong>de</strong> Ward consi<strong>de</strong>rando un máximo<br />
<strong>de</strong> 7 grupos. La razón para este criterio <strong>de</strong> parada es la coinci<strong>de</strong>ncia con las<br />
siete cuencas hidrográficas principales <strong>de</strong> la Península (ver Fig. 3.7(b)).<br />
La Figura 3.8 ilustra la capacidad <strong>de</strong> discriminación <strong>de</strong> la variable <strong>de</strong>
46 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
44<br />
42<br />
40<br />
38<br />
36<br />
10 5 0 5<br />
1 LA CORUÑA<br />
1 ROZAS<br />
1 PARAYAS<br />
1 SANTANDER<br />
1 SONDICA<br />
1 GIJON<br />
1 OVIEDO<br />
1 ORENSE<br />
1 SAN SEBASTIÁN<br />
1 FUENTERRABÍA<br />
2 NAVACERRADA<br />
1 SANTIAGO<br />
1 VIGO<br />
5 SEVILLA_A<br />
5 SEVILLA_B<br />
5 JEREZ<br />
5 TARIFA<br />
5 MÁLAGA<br />
7 VITORIA<br />
7 PAMPLONA<br />
1 PONFERRADA<br />
2 LEÓN<br />
2 BURGOS<br />
2 SORIA<br />
2 SEGOVIA<br />
2 VALLADOLID_A<br />
2 VALLADOLID_B<br />
4 BADAJOZ<br />
4 HINOJOSA<br />
4 CIUDAD REAL<br />
6 MURCIA_A<br />
6 MURCIA_B<br />
6 CARTAGENA<br />
6 MURCIA_C<br />
6 ALICANTE_A<br />
6 ALICANTE_B<br />
7 LOGROÑO<br />
7 DAROCA<br />
7 ZARAGOZA<br />
3 CÁCERES<br />
4 HUELVA<br />
6 VALENCIA_A<br />
6 VALENCIA_B<br />
6 CASTELLÓN<br />
7 TORTOSA<br />
7 HUESCA<br />
3 MADRID<br />
5 GRANADA<br />
2 SALAMANCA<br />
2 ÁVILA<br />
2 ZAMORA<br />
3 MADRID<br />
3 TOLEDO<br />
5 ALMERÍA<br />
Figura 3.8: Análisis <strong>de</strong> agrupamiento mediante el enlace <strong>de</strong> Ward <strong>de</strong> 54 estaciones<br />
en la Península Ibérica caracterizado por el promedio <strong>de</strong> precipitación en Invierno<br />
y Verano. El <strong>de</strong>ndrograma representa los diferentes grupos a un cierto nivel <strong>de</strong><br />
profundidad, en el eje horizontal, y las distancias don<strong>de</strong> los elementos son unidos<br />
en diferentes niveles jerárquicos, en el eje vertical.
3.3. TÉCNICAS DE AGRUPAMIENTO 47<br />
precipitación promediada. Los símbolos en las figuras correspon<strong>de</strong>n a los diferentes<br />
grupos obtenidos, y el <strong>de</strong>ndrograma muestra el proceso aglomerativo.<br />
La lista <strong>de</strong> estaciones correspondientes a un grupo es dada bajo el correspondiente<br />
símbolo en el <strong>de</strong>ndrograma; el número prece<strong>de</strong>nte a los nombres<br />
<strong>de</strong> las estaciones correspon<strong>de</strong> a la cuenca hidrográfica a la que pertenece la<br />
estación (Norte, Duero, Tajo, Guadiana, Guadalquivir-Sur, Mediterraneo,<br />
Ebro). En esta figura se pue<strong>de</strong> ver como la cuenca Norte es claramente separada<br />
<strong>de</strong>l resto <strong>de</strong> cuencas (esta es la principal separación climatológica en<br />
la Península Iberica, que correspon<strong>de</strong> con un clima “oceánico-húmedo” <strong>de</strong><br />
acurdo con la clasificación <strong>de</strong> Köppen). La única excepción correspon<strong>de</strong> a<br />
“Navacerrada” la cual se encuentra en una zona montañosa que presenta<br />
condiciones climatológicas parecidas a las estaciones <strong>de</strong> la cuenca Norte (al<br />
menos en promedio).<br />
Por otra parte, el grupo etiquetado con una estrella correspon<strong>de</strong> a una<br />
región con un clima “semiárido”. Finalmente los dos grupos restantes correspon<strong>de</strong>n<br />
a regiones con clima “verano seco subtropical”. En este caso el grupo<br />
etiquetado por “+” se encuentra básicamente en la cuenca <strong>de</strong>l Guadalquivir<br />
y Sur (con alguna excepción), y el grupo etiquetado con un cuadrado esta<br />
disperso sobre toda la Península Ibérica.<br />
Este ilustrativo ejemplo <strong>de</strong>l procedimiento <strong>de</strong> clasificación por agrupamiento<br />
automático correspon<strong>de</strong> bastante bien con la regionalización estándar<br />
<strong>de</strong> Köppen para la Península Ibérica.<br />
3.3.2. Técnicas Particionales<br />
Los métodos <strong>de</strong> agrupamiento más convenientes para un gran número<br />
<strong>de</strong> patrones en un espacio alto-dimensional son los métodos <strong>de</strong> ajuste <strong>de</strong><br />
centroi<strong>de</strong>s iterativos. El método más común es el algoritmo <strong>de</strong> las k-medias<br />
(ver Hastie et al., 2001). Dado un grupo <strong>de</strong> vectores reales d-dimensionales<br />
X = {x 1 , . . .,x n }, y un número prescrito <strong>de</strong> grupos m, el algoritmo <strong>de</strong> las<br />
m-medias calcula un conjunto <strong>de</strong> prototipos d-dimensionales, o centroi<strong>de</strong>s,<br />
{v 1 , . . .,v m } cada uno <strong>de</strong> ellos caracterizando a un grupo <strong>de</strong> datos C i ⊂ X<br />
formado por los vectores para los cuales v i es el prototipo más cercano. Esta<br />
tarea es realizada siguiendo un procedimiento iterativo, el cual comienza<br />
con un conjunto inicial <strong>de</strong> centroi<strong>de</strong>s v 0 1 , . . .,v0 m, elegidos aleatoriamente<br />
(ver Peña et al., 1999, para una <strong>de</strong>scripción y comparación <strong>de</strong> diferentes<br />
procedimientos <strong>de</strong> inicialización). El objetivo <strong>de</strong>l algoritmo es minimizar<br />
globalmente la distancia intra-grupos:<br />
∑<br />
i=1,...,m<br />
∑<br />
x j ∈C i<br />
‖x j − v i ‖ 2 (3.14)<br />
Ya que una búsqueda exhaustiva <strong>de</strong>l mínimo es prohibitiva, se calcula un<br />
mínimo local mediante un ajuste iterativo <strong>de</strong> los centroi<strong>de</strong>s <strong>de</strong> los grupos, y<br />
re-asignando cada patrón al centroi<strong>de</strong> más cercano. En la iteración (r + 1)-<br />
ésima, cada uno <strong>de</strong> los vectores x j es asignado al grupo i-ésimo, don<strong>de</strong>
48 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
i = argmin c ‖ x j − vi c ‖, y los prototipos son actualizados por medio <strong>de</strong> los<br />
correspondientes patrones:<br />
vi<br />
r+1 = ∑<br />
x j /#C i ,<br />
x j ∈C i<br />
don<strong>de</strong> #C i <strong>de</strong>nota el número <strong>de</strong> elementos en C i . Bajo ciertas condiciones,<br />
el proceso iterativo anterior converge <strong>de</strong>spués <strong>de</strong> R iteraciones, y los centros<br />
finales vi<br />
R son los prototipos (centroi<strong>de</strong>s). Cada uno <strong>de</strong> los centroi<strong>de</strong>s v i<br />
representa un grupo C i formado por los patrones más cercanos a vi<br />
R que a<br />
cualquier otro centroi<strong>de</strong>. El algoritmo <strong>de</strong> m-medias consiste en los siguientes<br />
pasos:<br />
1. Seleccionar el número <strong>de</strong> grupos <strong>de</strong>seados m.<br />
2. Inicializar los centros <strong>de</strong> los grupos (p.e. aleatoriamente).<br />
3. Repetir:<br />
a) Asignar cada vector (patrón atmosférico) al grupo más cercano.<br />
b) Re-calcular los centros <strong>de</strong> cada grupo, para que sean la media <strong>de</strong><br />
los patrones <strong>de</strong> los patrones asignados a ese grupo.<br />
Ejemplo 3.4 (Clasificación <strong>de</strong> Patrones Atmosféricos). Se consi<strong>de</strong>ran<br />
los 5500 patrones atmosféricos <strong>de</strong>l re-análisis ERA-15 <strong>de</strong>finidos en el<br />
Ejemplo 2.1 en distintas rejillas (Mo<strong>de</strong>los 1 y 2); para reducir la dimensionalidad<br />
<strong>de</strong>l espacio, se toman las primeras 100 componentes principales (ver<br />
Ejemplo 3.1) y se consi<strong>de</strong>ran distintos números <strong>de</strong> grupos m = 100, 200, y<br />
400, que correspon<strong>de</strong>n a distintos tamaños promedio <strong>de</strong> grupo: aproximadamente<br />
50, 25, y 15, respectivamente. Por ejemplo, las Figs. 3.9 (a) y (b)<br />
muestran los prototipos obtenidos al aplicar el algoritmo con m = 100 para<br />
los Mo<strong>de</strong>los 1 y 3, respectivamente.<br />
3.4. Re<strong>de</strong>s Auto-Organizativas (SOM)<br />
Las re<strong>de</strong>s auto-organizativas (Self-Organizing Maps, SOM) son técnicas<br />
<strong>de</strong> agrupamiento especialmente indicadas para trabajar en espacios <strong>de</strong> alta<br />
dimensionalidad, ya que permiten organizar y visualizar los datos <strong>de</strong> forma<br />
intuitiva y eficiente proyectándolos en un espacio arbitrario (normalmente<br />
una red 2-dimensional). Existen distintos métodos empíricos y/o subjetivos<br />
para visualizar datos meteorológicos (ver Macedo et al. (2000)), pero las<br />
SOM tienen una serie <strong>de</strong> ventajas que serán utilizadas en esta Tesis (ver<br />
Cap. 6).<br />
A pesar <strong>de</strong> que esta técnica surgió en el contexto <strong>de</strong> la computación<br />
neuronal (Kohonen, 2000), las SOM son una generalización <strong>de</strong> la técnica<br />
<strong>de</strong> m-medias <strong>de</strong>scrita en la sección anterior. En este caso, cada uno <strong>de</strong> los<br />
centroi<strong>de</strong>s (o prototipos) <strong>de</strong> la SOM tiene asociados dos vectores: uno en el
3.4. REDES AUTO-ORGANIZATIVAS (SOM) 49<br />
(a)<br />
PC2<br />
PC1<br />
(b)<br />
PC2<br />
PC1<br />
Figura 3.9: <strong>Agrupamiento</strong> <strong>de</strong>l re-análisis ERA-15 con el algoritmo <strong>de</strong> k-<br />
medias consi<strong>de</strong>rando 100 grupos para (a) Mo<strong>de</strong>lo 1, (b) Mo<strong>de</strong>lo 3. El grafo<br />
muestra los patrones diarios y los centroi<strong>de</strong>s proyectados en el espacio <strong>de</strong> las<br />
dos primeras componentes principales. Las líneas <strong>de</strong> separación entre diferentes<br />
grupos también se muestran (estas líneas correspon<strong>de</strong>n al diagrama<br />
<strong>de</strong> Voronoi asociado a los centroi<strong>de</strong>s).
50 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
espacio <strong>de</strong> los datos y otro en el espacio base bidimensional <strong>de</strong> proyección.<br />
La característica <strong>de</strong> esta técnica es la inclusión <strong>de</strong> un núcleo espacial <strong>de</strong><br />
vecindad cuyo efecto es mantener unidos en el espacio <strong>de</strong> los datos aquellos<br />
centroi<strong>de</strong>s vecinos en el espacio 2D. La amplitud <strong>de</strong>l núcleo <strong>de</strong>crece durante<br />
el entrenamiento alternando la noción <strong>de</strong> vecindad <strong>de</strong> global a local,<br />
<strong>de</strong> forma que cuando finaliza el entrenamiento los centroi<strong>de</strong>s vecinos están<br />
también cercanos en el espacio 2D. De esta forma, el proceso <strong>de</strong> aprendizaje<br />
proyecta la estructura topológica <strong>de</strong>l espacio original en un espacio prefijado<br />
(una red 2D). En los últimos años, han sido numerosas las aplicaciones que<br />
han utilizado las ventajas <strong>de</strong> esta técnica (ver Oja and Kaski, 1999, y las<br />
referencias incluidas). En Meteorología la aplicación ha sido más reciente<br />
(ver Hewitson and Crane, 2002).<br />
Como se muestra en la Figura 3.10, una SOM esta formada por un número<br />
arbitrario <strong>de</strong> grupos C 1 , . . .,C m , localizados sobre una red regular en un<br />
espacio <strong>de</strong> baja dimensión, usualmente una red 2D para propósitos <strong>de</strong> visualización<br />
(en este caso m = s × s). El vector p k = (i, j) representa la<br />
posición <strong>de</strong>l grupo C k sobre la red, don<strong>de</strong> 1 ≤ i, j ≤ s. Mas aún, cada uno<br />
<strong>de</strong> los grupos C k tiene asociado un vector prototipo c k = (c k1 , . . .,c kd ), el<br />
cual <strong>de</strong>scribe la posición <strong>de</strong>l centro <strong>de</strong>l grupo sobre espacio d-dimensional <strong>de</strong><br />
los datos (miles <strong>de</strong> dimensiones o, cientos <strong>de</strong> componentes principales para<br />
patrones atmosféricos). Por ejemplo, si se consi<strong>de</strong>ran los dos patrones atmosféricos<br />
analizados en el Ejemplo 3.1, se tendrán espacios <strong>de</strong> dimensiones<br />
10710 (Mo<strong>de</strong>lo 1) y 8100 (Mo<strong>de</strong>lo 2).<br />
1000<br />
T 12<br />
.<br />
.<br />
.<br />
300<br />
T 12<br />
.<br />
.<br />
.<br />
1000<br />
V 12<br />
.<br />
.<br />
.<br />
300<br />
V 12<br />
ORIGINAL DATA<br />
u 1<br />
1<br />
u 2<br />
1<br />
.<br />
.<br />
.<br />
1<br />
u 4050<br />
...<br />
u 1<br />
5445<br />
u 2<br />
5445 v 1<br />
1<br />
.<br />
.<br />
.<br />
5445<br />
u 4050<br />
PCA<br />
COMPRESSED DATA<br />
v 2<br />
1<br />
.<br />
.<br />
.<br />
1<br />
v 600<br />
...<br />
v 1<br />
5445<br />
v 2<br />
5445<br />
.<br />
.<br />
.<br />
5445<br />
v 600<br />
w 1,1<br />
w 1,2<br />
w 1,600<br />
w 22,1<br />
w 22,2<br />
w 22,600<br />
5 x 5 SOM<br />
C 2 C 3 C 4 C 5<br />
C 1<br />
C 25<br />
C 6 C 7 C 8 C 9 C 10<br />
C 11 C 12 C 13 C 14 C 15<br />
C 16 C 17 C 18 C 19 C 20<br />
C 21 C 22 C 23 C 24<br />
Figura 3.10: Esquema <strong>de</strong> una SOM operando sobre las componentes principales<br />
asociados a los patrones <strong>de</strong> datos <strong>de</strong>l re-análisis. En este caso, consi<strong>de</strong>ramos<br />
25 neuronas organizadas en una red 2D, las cuales llevan a 25 grupos<br />
diferentes con datos similares a las correspondientes neuronas vecinas.<br />
Siguiendo un procedimiento similar al algoritmo <strong>de</strong> m-medias los vectores<br />
<strong>de</strong> la SOM son inicializados a valores aleatorios. El objetivo <strong>de</strong>l algoritmo<br />
<strong>de</strong> entrenamiento es adaptar iterativamente los vectores prototipo, <strong>de</strong> forma<br />
que el prototipo final represente a un grupo <strong>de</strong> datos (aquellos que están<br />
más cerca al prototipo). Lo que hace a la SOM diferente <strong>de</strong> otros algoritmos<br />
<strong>de</strong> agrupamiento es que el proceso <strong>de</strong> entrenamiento incluye un mecanismo
3.4. REDES AUTO-ORGANIZATIVAS (SOM) 51<br />
<strong>de</strong> adaptación tal que los grupos vecinos en la red 2D son también similares<br />
en el espacio real, mientras que grupos más distantes en la red son más<br />
distintos.<br />
Un <strong>de</strong> las implementación <strong>de</strong>l algoritmo <strong>de</strong> entrenamiento se realiza en<br />
ciclos sucesivos; en cada ciclo se analiza cada uno <strong>de</strong> los vectores v i calculando<br />
el prototipo más cercano (o “ganador”) c ki , como aquel que minimiza<br />
la distancia al vector <strong>de</strong> datos:<br />
||v i − c ki || = min k ||v i − c k ||, k = 1, . . .,m. (3.15)<br />
Después <strong>de</strong> cada ciclo, los prototipos se recalculan en base al centroi<strong>de</strong> <strong>de</strong>l<br />
grupo correspondiente y <strong>de</strong> los grupos vecinos:<br />
c j =<br />
∑ ni=1<br />
v i h(||p j − p ki ||)<br />
∑ ni=1 , j = 1, . . .,m. (3.16)<br />
h(||p j − p ki ||)<br />
don<strong>de</strong> la función h(||p 1 −p 2 ||) es un núcleo <strong>de</strong> vecindad que mi<strong>de</strong> las distancias<br />
<strong>de</strong> los grupos en la red 2D y <strong>de</strong>termina la tasa <strong>de</strong> cambio <strong>de</strong> un prototipo<br />
en base a los grupos vecinos (normalmente se usa una función Gaussiana:<br />
h(x) = exp(−x/s(t)))). El radio <strong>de</strong> vecindad s(t) <strong>de</strong>crece monótonamente<br />
en el tiempo, suavizando las restricciones topológicas (se suele elegir un<br />
<strong>de</strong>caimiento lineal a cero para estas funciones). Para una <strong>de</strong>scripción <strong>de</strong>tallada<br />
<strong>de</strong> diferentes implementaciones <strong>de</strong>l método, el lector pue<strong>de</strong> consultar<br />
Oja and Kaski (1999).<br />
Hay que tener en cuenta que la ventaja <strong>de</strong> tener los grupos organizados<br />
en la red tiene un coste, ya que comparada con la técnica estándar <strong>de</strong><br />
m-medias, la SOM pier<strong>de</strong> parte <strong>de</strong> la variabilidad <strong>de</strong> los grupos, en favor<br />
<strong>de</strong> la restricción topológica impuesta. Esto se <strong>de</strong>be a que en los métodos<br />
clásicos los centroi<strong>de</strong>s se mueven libremente en el espacio y sólo tienen que<br />
minimizar la varianza intra-grupos, mientras que en una SOM la relación<br />
<strong>de</strong> vecindad entre centroi<strong>de</strong>s supone un recorte <strong>de</strong> libertad <strong>de</strong> movimiento.<br />
Es <strong>de</strong>cir, si no es necesario disponer <strong>de</strong> una topología para los prototipos es<br />
más conveniente y sencillo utilizar un algoritmo estándar, pero si se quieren<br />
estudiar transiciones o posiciones relativas entre diferentes prototipos,<br />
entonces la SOM resulta <strong>de</strong> gran utilidad.<br />
Ejemplo 3.5 (Clasificación <strong>de</strong> Patrones Atmosféricos). Los problemas<br />
<strong>de</strong> regionalización y clasificación ya han sido abordados con técnicas<br />
<strong>de</strong> agrupamiento en ejemplos anteriores. La ventaja <strong>de</strong> utilizar una SOM es<br />
que, a<strong>de</strong>más <strong>de</strong> obtener los grupos, se obtendrá también una organización<br />
<strong>de</strong> vecindad <strong>de</strong> los mismos. Ésto proporciona una útil visualización <strong>de</strong> las<br />
posibles transiciones e interrelaciones entre clases. En la Fig. 3.11 se muestra<br />
el resultado <strong>de</strong> aplicar este algoritmo a los dos mo<strong>de</strong>los atmosféricos <strong>de</strong>l<br />
Ejemplo 3.4 consi<strong>de</strong>rando re<strong>de</strong>s <strong>de</strong> 100 = 10 × 10 prototipos. En esta figura<br />
se pue<strong>de</strong>n observar los centroi<strong>de</strong>s finales, así como la red proyectada en el<br />
espacio <strong>de</strong> los datos (sólo se muestran las dos primeras CPs).
52 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
(a)<br />
PC1<br />
(b)<br />
PC2<br />
PC2<br />
PC1<br />
Figura 3.11: Proyección sobre las dos primeras CPs <strong>de</strong> los patrones atmosféricos<br />
<strong>de</strong> ERA-15 <strong>de</strong>finidos con los (a) Mo<strong>de</strong>lo 1 y (b) Mo<strong>de</strong>lo 3, junto con la rejilla <strong>de</strong> la<br />
SOM resultante <strong>de</strong>spués <strong>de</strong>l entrenamiento.
3.4. REDES AUTO-ORGANIZATIVAS (SOM) 53<br />
La Figura 3.12 muestra los patrones atmosféricos <strong>de</strong> los prototipos resultantes<br />
(temperatura en 500mb) para el primer cuadrante <strong>de</strong> la cuadrícula.<br />
Esta figura muestra que los patrones cercanos en la cuadrícula son parecidos<br />
entre sí, mientras que los lejanos correspon<strong>de</strong>n a situaciones diferentes.<br />
Cada prototipo representa un grupo <strong>de</strong> días cuyo patrón atmosférico (según<br />
el mo<strong>de</strong>lo utilizado) es cercano al prototipo.<br />
Figura 3.12: Campos <strong>de</strong> temperatura en 500mb correspondientes a los prototipos<br />
<strong>de</strong> una subrejilla 5 × 5 <strong>de</strong> la SOM mostrada en la Figura 3.11.<br />
Ejemplo 3.6 (Clasificación <strong>de</strong> Fenómenos Adversos). En este ejemplo,<br />
se analiza el problema <strong>de</strong> la clasificación <strong>de</strong> situaciones atmosféricas relacionadas<br />
con fenómenos adversos <strong>de</strong> precipitación: Precip > 40mm/24h<br />
en alguno <strong>de</strong> los observatorios <strong>de</strong> la red <strong>de</strong> estaciones completas <strong>de</strong>l INM en<br />
la Península y Baleares. La clasificación se ha restringido a aquellas fechas<br />
en las que se ha observado un fenómeno adverso según la <strong>de</strong>finición anterior.<br />
Se ha realizado una clasificación en 16 clases con una SOM para el período<br />
1979-1993, consi<strong>de</strong>rando la configuración <strong>de</strong> los patrones atmosféricos dada<br />
por el Mo<strong>de</strong>lo 1 <strong>de</strong>l Ejemplo 2.1. La Figuras 3.13 muestra los campos<br />
<strong>de</strong> geopotencial en 1000mb para los prototipos <strong>de</strong> los grupos obtenidos; por<br />
otra parte, la Fig. 3.14 muestra los patrones <strong>de</strong> precipitación asociados a<br />
cada grupo; estos patrones se han obtenido interpolando los valores <strong>de</strong> las<br />
estaciones <strong>de</strong> la red <strong>de</strong> estaciones completas <strong>de</strong>l INM. En esta figura pue<strong>de</strong>n<br />
observarse modos claros <strong>de</strong> precipitación en Galicia, Levante, etc., mostrando<br />
la conexión entre los patrones atmosféricos y la fenomenológica.
54 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
Figura 3.13: Campos <strong>de</strong> geopotencial en 1000mb correspondientes a los prototipos<br />
<strong>de</strong> una SOM 4 × 4 entrenada con los días <strong>de</strong>l período ERA-15 asociados a<br />
precipitaciones fuertes en superficie.<br />
(19) [16 95]mm/24h (9) [19 54]mm/24h (10) [20 80]mm/24h (15) [12 110]mm/24h<br />
(11) [17 71]mm/24h (13) [16 88]mm/24h (16) [22 87]mm/24h (9) [17 90]mm/24h<br />
(7) [17 87]mm/24h (8) [21 80]mm/24h (43) [15 105]mm/24h (20) [14 59]mm/24h<br />
(6) [15 47]mm/24h (7) [22 93]mm/24h (17) [14 139]mm/24h (17) [13 82]mm/24h<br />
Figura 3.14: Patrones fenomenológicos <strong>de</strong> precipitaciones fuertes asociados a los<br />
grupos <strong>de</strong> la SOM. Entre paréntesis se muestra el número <strong>de</strong> elementos <strong>de</strong> cada<br />
grupo y entre corchetes el rango <strong>de</strong> precipitación observada.
3.5. REDES NEURONALES MULTICAPA 55<br />
3.5. Re<strong>de</strong>s <strong>Neuronales</strong> Multicapa<br />
La computación paralela y las re<strong>de</strong>s neuronales son dos nuevos paradigmas<br />
que han <strong>de</strong>spertado en los últimos años un gran interés. El elemento<br />
clave <strong>de</strong> estos paradigmas es una nueva estructura computacional compuesta<br />
<strong>de</strong> un gran número <strong>de</strong> pequeños elementos procesadores interconectados<br />
(neuronas) trabajando en paralelo, en contraposición al proceso en serie<br />
tradicional. Actualmente, las re<strong>de</strong>s neuronales han probado su valía para<br />
resolver problemas complejos en diversos campos, incluyendo la predicción<br />
meteorológica y oceánica (Schizas et al., 1994; Hsieh and Tang, 1998) y se<br />
han <strong>de</strong>sarrollado diversas extensiones <strong>de</strong> estos mo<strong>de</strong>los para cubrir <strong>de</strong>ficiencias<br />
en los mismos y especializarlos en problemas concretos; por ejemplo,<br />
las re<strong>de</strong>s funcionales han surgido como una generalización <strong>de</strong> estos mo<strong>de</strong>los<br />
para po<strong>de</strong>r incluir conocimiento cualitativo <strong>de</strong>l problema en la estructura<br />
<strong>de</strong> la red (ver Castillo et al., 1999, para más <strong>de</strong>talles); por otra parte, los<br />
algoritmos genéticos han sido aplicados para optimizar la estructura <strong>de</strong> la<br />
red (Cofiño et al., 2003c), etc.<br />
En esta sección se <strong>de</strong>scribe un tipo particular <strong>de</strong> re<strong>de</strong>s (las re<strong>de</strong>s multicapa),<br />
que tienen especial interés en esta tesis por su interpretación como<br />
técnicas no paramétricas <strong>de</strong> regresión no lineal (para una <strong>de</strong>scripción más<br />
general, incluyendo otros tipos <strong>de</strong> re<strong>de</strong>s, ver Hastie et al., 2001).<br />
3.5.1. Estructura y Funcionamiento <strong>de</strong> las Re<strong>de</strong>s <strong>Neuronales</strong><br />
En analogía a los mo<strong>de</strong>los biológicos, los mo<strong>de</strong>los computacionales <strong>de</strong><br />
re<strong>de</strong>s neuronales están compuestos por un número <strong>de</strong> unida<strong>de</strong>s simples <strong>de</strong><br />
proceso (neuronas) conectadas entre sí en base a una topología <strong>de</strong>finida. La<br />
funcionalidad <strong>de</strong> la red neuronal viene dada por la topología <strong>de</strong> conexión <strong>de</strong><br />
las neuronas, por la función concreta que realice cada neurona (actividad<br />
neuronal), y por los pesos <strong>de</strong> conexión <strong>de</strong> unas neuronas con otras. La topología<br />
<strong>de</strong> conexión y la actividad neuronal <strong>de</strong>finen el tipo <strong>de</strong> red neuronal<br />
concreta (multicapa, competitiva, etc.), y los pesos <strong>de</strong> las conexiones son<br />
los parámetros que, ajustados a un problema concreto, permiten a la red<br />
“apren<strong>de</strong>r” y generalizar el conocimiento aprendido. En este sentido, las re<strong>de</strong>s<br />
neuronales pue<strong>de</strong>n ser consi<strong>de</strong>rados mo<strong>de</strong>los estadísticos no paramétricos<br />
<strong>de</strong> regresión local.<br />
La Figura 3.5.1(a) muestra la topología concreta <strong>de</strong> conexión <strong>de</strong> una red<br />
neuronal multicapa y la Figura 3.5.1(b) muestra una <strong>de</strong>scripción <strong>de</strong>tallada<br />
<strong>de</strong> la actividad neuronal (analizada en más <strong>de</strong>talle en la siguiente sección).<br />
En este caso, el aprendizaje <strong>de</strong> los pesos <strong>de</strong> las conexiones se realiza en base<br />
a un conjunto <strong>de</strong> datos entrada-salida dado (aprendizaje supervisado).<br />
Las neuronas son los elementos procesadores <strong>de</strong> la red neuronal y realizan<br />
un sencillo cálculo con las entradas para obtener un valor <strong>de</strong> salida:<br />
n∑<br />
n∑<br />
y i = f( w ij x j − θ i ) = f( w ij x j ), (3.17)<br />
j=1<br />
j=0
56 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
(a)<br />
Inputs<br />
Outputs<br />
x 1<br />
w i1<br />
-1<br />
θ i<br />
(b)<br />
w<br />
x i2 2<br />
w i=0<br />
Σ<br />
in<br />
x n<br />
n<br />
wij x j f( )<br />
n<br />
Σ wij x j<br />
i=0<br />
Figura 3.15: (a)Red neuronal multicapa y (b) la función procesadora <strong>de</strong> una<br />
única neurona.<br />
don<strong>de</strong> f(x) es la función activación y θ i es el umbral <strong>de</strong> activación <strong>de</strong> la neurona.<br />
Obsérvese que el umbral <strong>de</strong> activación se pue<strong>de</strong> incluir en el sumatorio<br />
consi<strong>de</strong>rando una nueva neurona auxiliar x 0 = −1 conectada a y i con un<br />
peso w i0 = θ i . Por tanto, la salida <strong>de</strong> una neurona y i se obtiene simplemente<br />
transformando la suma pon<strong>de</strong>rada <strong>de</strong> las entradas que recibe usando la función<br />
<strong>de</strong> activación (ver Fig. 3.5.1(b)). Las funciones <strong>de</strong> activación continuas<br />
más populares son:<br />
Funciones lineales: Son funciones que dan una salida lineal:<br />
f(x) = x; x ∈ R.<br />
Funciones sigmoidales: Son funciones monótonas acotadas que dan una<br />
salida gradual no lineal para las entradas. Las funciones sigmoidales<br />
más populares son:<br />
1. La función logística <strong>de</strong> 0 a 1 (ver Figura 3.16):<br />
f c (x) =<br />
1<br />
1 + e−c x.<br />
2. La función tangente hiperbólica <strong>de</strong> −1 a 1 (similar a la función<br />
logística, pero con el nuevo rango):<br />
f c (x) = tanh(c x).<br />
Funciones núcleo: Localizadas alre<strong>de</strong>dor <strong>de</strong> un punto, como la distribución<br />
Gaussiana.
3.5. REDES NEURONALES MULTICAPA 57<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
c=0.5<br />
c=1<br />
c=2<br />
0.2<br />
0<br />
-10 -5 0 5 10<br />
Figura 3.16: Función <strong>de</strong> activación sigmoidal logística f c (x) = (1 + e −c x ) −1 .<br />
3.5.2. Aprendizaje y Validación<br />
Una <strong>de</strong> las principales propieda<strong>de</strong>s <strong>de</strong> las re<strong>de</strong>s neuronales es su capacidad<br />
<strong>de</strong> apren<strong>de</strong>r a partir <strong>de</strong> unos datos. Una vez que ha sido elegida la<br />
arquitectura <strong>de</strong> red para un problema particular, los pesos <strong>de</strong> las conexiones<br />
se ajustan para codificar la información contenida en un conjunto <strong>de</strong> datos<br />
<strong>de</strong> entrenamiento. Las re<strong>de</strong>s multicapa son apropiadas para problemas <strong>de</strong><br />
aprendizaje supervisado, don<strong>de</strong> se dispone <strong>de</strong> un conjunto <strong>de</strong> patrones <strong>de</strong> entrenamiento<br />
<strong>de</strong> la forma (x p ,y p ) = (x 1p , . . .,x mp ; y 1p , . . .,y np ), p = 1, . . .,a,<br />
don<strong>de</strong> se conocen los patrones <strong>de</strong> salida y p correspondientes a cada conjunto<br />
<strong>de</strong> patrones <strong>de</strong> entrada x p y se <strong>de</strong>sea que la red sea capaz <strong>de</strong> reproducir estos<br />
patrones con el menor error posible. Este problema se reduce a obtener los<br />
pesos apropiados utilizando algún algoritmo <strong>de</strong> aprendizaje apropiado.<br />
Una vez terminado el proceso <strong>de</strong> aprendizaje y calculados los pesos <strong>de</strong> la<br />
red neuronal, es importante comprobar la calidad <strong>de</strong>l mo<strong>de</strong>lo resultante. Por<br />
ejemplo, en el caso <strong>de</strong> aprendizaje supervisado, una medida <strong>de</strong> la calidad<br />
pue<strong>de</strong> darse en términos <strong>de</strong> los errores entre los valores <strong>de</strong> salida <strong>de</strong>seados y<br />
los obtenidos por la red neuronal. Algunas medidas estándar <strong>de</strong>l error son:<br />
1. La suma <strong>de</strong> los cuadrados <strong>de</strong> los errores (Sum of Square Errors, SSE),<br />
<strong>de</strong>finida como<br />
n∑<br />
‖ y p − ŷ p ‖ 2 . (3.18)<br />
p=1<br />
2. La raíz cuadrada <strong>de</strong>l error cuadrático medio (Root Mean Square Error,<br />
RMSE) <strong>de</strong>finida como<br />
n∑<br />
√ ‖ y p − ŷ p ‖ 2 /n. (3.19)<br />
p=1<br />
3. El error máximo,<br />
máx ‖ y p − ŷ p ‖ . (3.20)<br />
p=1,...,n
58 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
También es <strong>de</strong>seable realizar una validación cruzada para obtener una<br />
medida <strong>de</strong> la calidad <strong>de</strong> predicción <strong>de</strong>l mo<strong>de</strong>lo. Con este propósito, los datos<br />
disponibles se pue<strong>de</strong>n dividir en dos partes: una parte <strong>de</strong>stinada al entrenamiento<br />
<strong>de</strong> la red y otra parte a la validación. Cuando el error <strong>de</strong> validación es<br />
significativamente mayor que el error <strong>de</strong> entrenamiento, entonces se produce<br />
un problema <strong>de</strong> sobreajuste durante el proceso <strong>de</strong> entrenamiento que pue<strong>de</strong><br />
ser <strong>de</strong>bido a un excesivo número <strong>de</strong> parámetros.<br />
3.5.3. Perceptrones (Re<strong>de</strong>s <strong>de</strong> una Capa)<br />
Los perceptrones son las arquitecturas más simples y consisten en una<br />
capa <strong>de</strong> entrada, {x 1 , . . .,x m }, y una <strong>de</strong> salida, {y 1 , . . .,y n }, <strong>de</strong> forma que las<br />
neuronas <strong>de</strong> la capa <strong>de</strong> salida están conectadas con las <strong>de</strong> entrada y no hay<br />
conexiones entre las neuronas <strong>de</strong> una misma capa (ver Rosenblat, 1962). Para<br />
indicar el número <strong>de</strong> entradas y <strong>de</strong> salidas, este tipo <strong>de</strong> re<strong>de</strong>s suelen <strong>de</strong>notarse<br />
<strong>de</strong> forma abreviada mediante m : n. Los perceptrones suelen <strong>de</strong>nominarse<br />
también re<strong>de</strong>s <strong>de</strong> retro-propagación <strong>de</strong> una única capa.<br />
En un perceptrón, una unidad <strong>de</strong> salida típica, ŷ j , realiza el cálculo:<br />
m∑<br />
ŷ j = f( β ji x i ) = f(β T j x), j = 1, . . .,n. (3.21)<br />
i=0<br />
don<strong>de</strong> f(·) es la función <strong>de</strong> activación y β j el correspondiente vector <strong>de</strong> peso.<br />
Se <strong>de</strong>nota mediante ŷ p = f(β j T x p ) al valor <strong>de</strong> salida obtenido insertando<br />
el correspondiente patrón <strong>de</strong> entrada en la red (3.21).<br />
Algoritmos <strong>de</strong> Aprendizaje<br />
En los algoritmos <strong>de</strong> aprendizaje para este tipo <strong>de</strong> re<strong>de</strong>s se usan método<br />
<strong>de</strong> optimización matemática para obtener los pesos β j que minimizan una<br />
cierta función <strong>de</strong> error. Obsérvese que los pesos son los únicos parámetros<br />
<strong>de</strong>sconocidos <strong>de</strong> la red y son los que proporcionan flexibilidad a la misma<br />
para ajustarse a distintas situaciones caracterizadas por un conjunto <strong>de</strong> patrones<br />
entrada-salida.<br />
Los algoritmos <strong>de</strong> aprendizaje se basan en minimizar la suma <strong>de</strong> los<br />
cuadrados <strong>de</strong> los errores (otras medidas distintas <strong>de</strong> error han dado lugar a<br />
algoritmos <strong>de</strong> aprendizaje diferentes que se comentan más a<strong>de</strong>lante):<br />
E(β) = 1 ∑<br />
(y jp − ŷ jp ) 2 = 1 ∑<br />
||y p − ŷ p || (3.22)<br />
2<br />
2<br />
j,p<br />
p<br />
= 1 ∑<br />
(y jp − f( ∑ β jiˆx ip )) 2 = 1 ∑<br />
||y p − f(β T ˆx p )|| (3.23)<br />
2<br />
2<br />
j,p i<br />
p<br />
Dado que esta función es no lineal, no existe ningún método exacto para<br />
obtener su solución (los pesos óptimos), aunque recientemente Castillo et al.<br />
(2002) han presentado un nuevo método <strong>de</strong> aprendizaje para este tipo <strong>de</strong>
3.5. REDES NEURONALES MULTICAPA 59<br />
re<strong>de</strong>s que transform al función <strong>de</strong> error haciéndola lineal en los parámetros<br />
<strong>de</strong>l mo<strong>de</strong>lo (los pesos).<br />
Uno <strong>de</strong> los algoritmos <strong>de</strong> optimización más simples para este problema<br />
es el método <strong>de</strong>l <strong>de</strong>scenso <strong>de</strong> gradiente (también llamado “regla <strong>de</strong>lta” en<br />
este caso). Se trata <strong>de</strong> un algoritmo iterativo que en cada etapa trata <strong>de</strong><br />
modificar incrementalmente los pesos <strong>de</strong> forma que se obtenga un error<br />
menor (inicialmente se toma un valor aleatorio <strong>de</strong> los pesos). En este caso<br />
concreto el incremento <strong>de</strong> los pesos se obtiene en base a los vectores en los<br />
que la función <strong>de</strong> error disminuye más rápidamente, que correspon<strong>de</strong> con<br />
el opuesto <strong>de</strong>l gradiente <strong>de</strong> la función <strong>de</strong> error respecto <strong>de</strong> los pesos, − ∇E<br />
(método <strong>de</strong>l <strong>de</strong>scenso <strong>de</strong> gradiente). Por tanto, en cada paso <strong>de</strong> iteración cada<br />
uno <strong>de</strong> los pesos β ji se modifica mediante un incremento ∆β ji proporcional<br />
al gradiente <strong>de</strong>l error:<br />
∆β ji<br />
= −η ∂E(β)<br />
∂β ji<br />
= −η ∑ p<br />
(y jp − ŷ jp ) ∂ŷ jp<br />
∂β ji<br />
= −η ∑ p<br />
(y jp − ŷ jp )f ′ ( ∑ i<br />
β ji x ip )x jp , (3.24)<br />
∆β j = −η∇E(β) = −η ∑ p<br />
(y jp − ŷ jp )f ′ (β T j x p )x jp , (3.25)<br />
don<strong>de</strong> el parámetro η es la tasa <strong>de</strong> aprendizaje, es <strong>de</strong>cir, la constante que<br />
regula la intensidad <strong>de</strong> la variación incremental <strong>de</strong> los pesos (obsérvese que la<br />
aproximación <strong>de</strong> la superficie <strong>de</strong> error mediante el gradiente es sólo válida en<br />
un sentido local y, por tanto, el rango <strong>de</strong> la tasa <strong>de</strong> aprendizaje está limitado<br />
por este hecho).<br />
Algunas funciones <strong>de</strong> activación permiten <strong>de</strong>finir su <strong>de</strong>rivada en función<br />
<strong>de</strong> sí mismas, simplificando la fórmula (3.24) al no involucrar <strong>de</strong>rivadas<br />
formales:<br />
1<br />
f(s) =<br />
1 + e −c s ⇒ f ′ (s) = c f(s)(1 − f(s)),<br />
o<br />
f(s) = tanh(c s) ⇒ f ′ (s) = c (1 − f(s) 2 ).<br />
Si la función <strong>de</strong> activación fuese lineal (f(s) = s), las salidas <strong>de</strong> la red<br />
dadas en (3.21) se reducirían a una combinación lineal <strong>de</strong> las entradas, resultando<br />
los siguientes incrementos <strong>de</strong> los pesos:<br />
∆β ji = −η ∂E<br />
∂β ji<br />
= η ∑ p<br />
(y jp − ŷ jp )x ip , (3.26)<br />
que proporcionan la solución global <strong>de</strong>l problema lineal (obsérvese que este<br />
problema pue<strong>de</strong> resolverse en un sólo paso con técnicas <strong>de</strong> optimización<br />
lineal, no siendo necesario el uso <strong>de</strong> una técnica iterativa).
60 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
Mejoras y Modificaciones<br />
Han sido varias las modificaciones propuestas en la literatura con el propósito<br />
<strong>de</strong> mejorar la eficiencia <strong>de</strong> los métodos <strong>de</strong> aprendizaje anteriores. A<br />
continuación se <strong>de</strong>scriben las más populares:<br />
Término <strong>de</strong> inercia. Este término extra se introduce en la expresión<br />
<strong>de</strong> ∆β ji para acelerar la convergencia teniendo en cuenta no sólo el<br />
gradiente local, sino las distintas ten<strong>de</strong>ncias en la “superficie” <strong>de</strong> error.<br />
Con ello se evita que la red caiga en pequeños mínimos locales. La<br />
nueva regla <strong>de</strong> actualización viene dada por<br />
∆β ji = −η ∂E<br />
∂w ji<br />
+ µ∆ ′ β ji ,<br />
don<strong>de</strong> ∆ ′ β ji hace referencia a los valores previos <strong>de</strong> ∆β ji (en el paso<br />
<strong>de</strong> iteración previo) y µ es el parámetro <strong>de</strong> inercia.<br />
Tasa <strong>de</strong> aprendizaje variable. En el método <strong>de</strong> <strong>de</strong>scenso <strong>de</strong> gradiente,<br />
la tasa <strong>de</strong> aprendizaje es constante en todo el proceso <strong>de</strong> entrenamiento.<br />
Pero la eficiencia <strong>de</strong>l algoritmo es muy sensible a la elección <strong>de</strong> la<br />
tasa <strong>de</strong> aprendizaje; si la tasa es muy gran<strong>de</strong> el algorimo oscila y se<br />
vuelve inestable, y si es <strong>de</strong>masiado pequeño la convergencia es muy<br />
lenta. Tampoco es posible saber cual es el valor más conveniente <strong>de</strong><br />
la tasa antes <strong>de</strong> comenzar el entrenamiento, e incluso pue<strong>de</strong> cambiar<br />
durante el proceso <strong>de</strong> aprendizaje. Una tasa <strong>de</strong> aprendizaje adaptativa<br />
consiste en variar ésta según la complejidad local <strong>de</strong> la superficie <strong>de</strong><br />
error.<br />
Métodos <strong>de</strong> regularización. Estos métodos incluyen términos <strong>de</strong> la función<br />
<strong>de</strong> error que penalizan pesos gran<strong>de</strong>s:<br />
r∑<br />
E(β) = p − ŷ p )<br />
p=1(y 2 + λ ∑ i,j<br />
β 2 ji, (3.27)<br />
don<strong>de</strong> λ es un parámetro <strong>de</strong> regularización, que controla el equilibrio<br />
entre el mo<strong>de</strong>lo ajustado y la penalización. El efecto <strong>de</strong> esta regularización<br />
<strong>de</strong> los pesos es suavizar la función <strong>de</strong> error, ya que los pesos<br />
gran<strong>de</strong>s están usualmente asociados a valores <strong>de</strong> salida altos (para<br />
una <strong>de</strong>scripción más <strong>de</strong>tallada <strong>de</strong>s<strong>de</strong> un punto <strong>de</strong> vista estadístico ver<br />
Hoerl and Kennard, 1970). Esta técnica también está relacionada con<br />
el método <strong>de</strong> <strong>de</strong>scomposición <strong>de</strong> los pesos que consiste en recortar las<br />
conexiones <strong>de</strong> la red que tengan poca importancia (pesos muy bajos).<br />
Ejemplo 3.7 (Clasificación con Perceptrones). En este ejemplo se ilustra<br />
la aplicación <strong>de</strong>l perceptrón al problema <strong>de</strong> la clasificación. Concretamente<br />
el problema consistirá en la clasificación <strong>de</strong> la mezcla <strong>de</strong> dos nubes<br />
gaussianas con <strong>de</strong>sviación 0.5 y medias 0.5 y -0.5, respectivamente (ver Fig.
3.5. REDES NEURONALES MULTICAPA 61<br />
3.17). Una primera aproximación al problema <strong>de</strong> clasificación es realizar una<br />
clasificación lineal, consi<strong>de</strong>rando una función <strong>de</strong> activación lineal f(x) = x.<br />
En este caso, el óptimo <strong>de</strong> la red neuronal es óptimo en el sentido <strong>de</strong> mínimos<br />
cuadrados y se muestra en la Fig. 3.18.<br />
2<br />
1.5<br />
1<br />
0.5<br />
0<br />
−0.5<br />
−1<br />
−1.5<br />
−2<br />
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2<br />
Figura 3.17: Muestra <strong>de</strong> 100 puntos obtenida <strong>de</strong> la mezcla <strong>de</strong> dos distribuciones<br />
gaussianas <strong>de</strong> <strong>de</strong>sviación 0.5 y media 0.5 y -0.5<br />
2<br />
0.4<br />
0.3<br />
1.5<br />
1<br />
0.5<br />
0<br />
0.1<br />
0.2<br />
−0.7<br />
−0.6<br />
−0.5<br />
−0.4<br />
−0.3<br />
2<br />
1.5<br />
1<br />
0.5<br />
0.6<br />
0.7<br />
0.8<br />
−0.2<br />
−0.1<br />
0.5<br />
0<br />
0.9<br />
1<br />
0.4<br />
0.3<br />
0<br />
−0.5<br />
−1<br />
0.5<br />
0<br />
0.1<br />
0.2<br />
−0.5<br />
−1<br />
−2<br />
−1<br />
2<br />
−1.5<br />
1.6<br />
1.7<br />
1.1<br />
1.5<br />
1.4<br />
1.3<br />
1.2<br />
0.6<br />
0.7<br />
0.8<br />
0.9<br />
1<br />
−2<br />
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2<br />
0<br />
1<br />
2 −2<br />
0<br />
Figura 3.18: Superficie generada por el perceptrón lineal<br />
Para obtener un criterio <strong>de</strong> separación no lineal se pue<strong>de</strong> consi<strong>de</strong>rar<br />
un perceptrón con una función <strong>de</strong> activación sigmoidal; en este ejemplo se<br />
utiliza la función sigmoidal. El óptimo obtenido se muestar en la Fig. 3.19.<br />
Obsérvese que en este último ejemplo la red es equivalente a un mo<strong>de</strong>lo <strong>de</strong><br />
regresión o clasificación logística.
62 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
2<br />
1.5<br />
1<br />
0.5<br />
0.2<br />
0.1<br />
0.3<br />
0.4<br />
0.5<br />
0.7<br />
0.6<br />
0.8<br />
2<br />
1.5<br />
1<br />
0.5<br />
0<br />
−0.5<br />
−1<br />
−1.5<br />
0.9<br />
0.1<br />
0.2<br />
−2<br />
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2<br />
0.3<br />
0.4<br />
0.5<br />
0.7<br />
0.6<br />
0.8<br />
0.9<br />
0<br />
−0.5<br />
−1<br />
−2<br />
−1<br />
0<br />
1<br />
2 −2<br />
0<br />
2<br />
2<br />
1<br />
0<br />
−1<br />
−2<br />
2<br />
−1<br />
1<br />
0<br />
0<br />
1<br />
−1<br />
2 −2<br />
Figura 3.19: Superficie generada por el perceptrón sigmoidal no lineal.<br />
Ejemplo 3.8 (Clasificación <strong>de</strong> Patrones <strong>de</strong> Precipitación). En este<br />
ejemplo se aplican las mismas técnicas que en el ejemplo anterior para<br />
clasificar patrones atmosféricos en base a la precipitación local asociada en<br />
un cierta estación (la ciudad <strong>de</strong> Santan<strong>de</strong>r). Para ello se ha consi<strong>de</strong>rado<br />
el patrón atmosférico <strong>de</strong>finido en el Ejemplo 2.1 (ver Fig. 2.9(a)). En la<br />
Fig. 3.20 se muestran dos gráficas 2D correspondientes a distintas combinaciones<br />
<strong>de</strong> componentes principales <strong>de</strong> estos patrones. Se han dibujado con<br />
símbolos distintos aquellos patrones que correspon<strong>de</strong>n a eventos <strong>de</strong> precipitación<br />
(Precip > 0.5mm) en la localidad <strong>de</strong> Santan<strong>de</strong>r. En la primera figura<br />
pue<strong>de</strong> observarse que el po<strong>de</strong>r <strong>de</strong> discriminación <strong>de</strong> las dos primeras CPs es<br />
muy bajo, mientras que la segunda figura muestra cómo la tercera CP aporta<br />
información que permite discriminar parcialmente ambas categorías. Dado<br />
que las CPs siguen distribuciones aproximadamente normales, el parecido<br />
<strong>de</strong> este problema con el anteriormente expuesto es notable. En secciones<br />
posteriores se analiza este problema en <strong>de</strong>talle.
3.5. REDES NEURONALES MULTICAPA 63<br />
CP2<br />
10<br />
20<br />
30<br />
40<br />
30<br />
20<br />
10<br />
0<br />
40<br />
40 20 0 20 40<br />
CP1<br />
CP3<br />
10<br />
20<br />
30<br />
40<br />
30<br />
20<br />
10<br />
0<br />
40<br />
40 20 0 20 40<br />
CP2<br />
Figura 3.20: Gráficos <strong>de</strong> (a) CP1 vs CP2 y (b) CP2 vs CP3 mostrando en distintas<br />
clases los eventos lluvia (Precip > 0.5mm) y no lluvia en Santan<strong>de</strong>r.<br />
3.5.4. Perceptrones Multi-Capa<br />
A<strong>de</strong>más <strong>de</strong> una capa <strong>de</strong> entrada y una <strong>de</strong> salida, un perceptrón multicapa<br />
tiene capas internas ocultas. Los nodos <strong>de</strong> la capa <strong>de</strong> entrada alimentan<br />
la red distribuyendo hacia <strong>de</strong>lante las señales <strong>de</strong> entrada. Cada nodo en<br />
las capas ocultas y <strong>de</strong> salida recibe una entrada <strong>de</strong> los nodos <strong>de</strong> las capas<br />
previas y calcula un valor <strong>de</strong> salida para la siguiente capa. La adición <strong>de</strong><br />
capas ocultas proporciona a este tipo <strong>de</strong> arquitectura suficiente flexibilidad<br />
para resolver muchos problemas en los que los perceptrones simples fallan.<br />
Para cada una <strong>de</strong> las salidas, y i , un perceptrón multi-capa calcula una<br />
función y i = F i (x 1 , . . .,x m ) <strong>de</strong> las entradas <strong>de</strong> la forma:<br />
y i = f( ∑ i<br />
β ji f( ∑ k<br />
α ik x kp )). (3.28)<br />
Se ha <strong>de</strong>mostrado que un perceptrón con dos capas ocultas pue<strong>de</strong> aproximar<br />
con un grado <strong>de</strong> exactitud dado cualquier conjunto <strong>de</strong> funciones<br />
F i (x 1 , . . .,x n ). Cuando estas funciones son continuas entonces una única<br />
capa oculta es suficiente. Esto resuelve parcialmente uno <strong>de</strong> los principales<br />
<strong>de</strong>fectos <strong>de</strong> los perceptrones multi-capa: el diseño <strong>de</strong> una estructura <strong>de</strong> red<br />
apropiada para un problema dado. Ahora, el problema se reduce a elegir<br />
un número apropiado <strong>de</strong> unida<strong>de</strong>s ocultas para ajustar el mo<strong>de</strong>lo evitando<br />
el problema <strong>de</strong> sobreajuste. La solución a este problema habrá <strong>de</strong> lograse<br />
mediante un procedimiento <strong>de</strong> prueba y error en la mayoría <strong>de</strong> los casos.<br />
El método <strong>de</strong> aprendizaje más popular para perceptrones multi-capa es<br />
conocido como retro-propagación (backpropagation) y está basado en minimizar<br />
la función que da el error cuadrático total usando el método <strong>de</strong>l<br />
<strong>de</strong>scenso <strong>de</strong> gradiente.
64 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
El Algoritmo <strong>de</strong> Retro-propagación<br />
Supóngase que se tienen unos conjuntos <strong>de</strong> entradas {x 1p , . . .,x mp } y sus<br />
correspondientes salidas {y 1p , . . .,y np }, p = 1, . . .,a, como patrones <strong>de</strong> entrenamiento.<br />
Como en el caso <strong>de</strong>l perceptrón simple, se consi<strong>de</strong>ra la función<br />
que da el error cuadrático total:<br />
E(α, β) = 1 ∑<br />
(y jp − f( ∑ 2<br />
j,p i<br />
= ∑ p<br />
β ji f( ∑ k<br />
α ik x kp ))) 2<br />
||y p − f(β T f(α T x p ))|| (3.29)<br />
don<strong>de</strong> β tiene por columnas los vectores <strong>de</strong> pesos <strong>de</strong> la neurona j-ésima <strong>de</strong><br />
la capa <strong>de</strong> salida, y α los <strong>de</strong> la k-ésima neurona <strong>de</strong> la capa oculta.<br />
El algoritmo <strong>de</strong> retro-propagación está basado en la misma i<strong>de</strong>a <strong>de</strong>l <strong>de</strong>scenso<br />
<strong>de</strong> gradiente usado en el método <strong>de</strong> la regla <strong>de</strong>lta. Por tanto, se han <strong>de</strong><br />
cambiar los pesos <strong>de</strong> forma que se <strong>de</strong>scienda por la pendiente <strong>de</strong> la función<br />
<strong>de</strong> error:<br />
∆β ik = −η ∂E ; ∆α kj = −η ∂E , (3.30)<br />
∂β ik ∂α kj<br />
don<strong>de</strong> el término η es el parámetro <strong>de</strong> aprendizaje, relacionado con el índice<br />
<strong>de</strong>l peso cambiante.<br />
Como (3.29) involucra los pesos <strong>de</strong> las neuronas ocultas y las <strong>de</strong> salida,<br />
el problema <strong>de</strong> actualizar iterativamente los pesos no es tan simple como en<br />
el caso <strong>de</strong> los perceptrones <strong>de</strong> una capa. Una solución a este problema fue<br />
dada con el algoritmo <strong>de</strong> retro-propagación <strong>de</strong> dos pasos (ver, por ejemplo,<br />
Rumelhart and McClelland, 1986). En primer lugar, la entrada <strong>de</strong> un patrón<br />
x p se propaga hacia <strong>de</strong>lante obteniendo el valor <strong>de</strong> las unida<strong>de</strong>s ocultas, ĥp,<br />
y la salida, ŷ p , y, por tanto, el error asociado. Los valores obtenidos se usan<br />
luego para actualizar los pesos β ik <strong>de</strong> la capa <strong>de</strong> salida usando (3.29). Más<br />
tar<strong>de</strong>, los pesos obtenidos se utilizarán para actualizar los pesos <strong>de</strong> la capa<br />
oculta, α kj , usando (3.29) para propagar hacia atrás los errores anteriores.<br />
La forma final <strong>de</strong> algoritmo resulta como sigue:<br />
1. Iniciar los pesos con valores aleatorios.<br />
2. Elegir un patrón <strong>de</strong> entrenamiento y propagarlo hacia a<strong>de</strong>lante obteniendo<br />
los valores ĥp y ŷ p para las neuronas <strong>de</strong> las capas ocultas y <strong>de</strong><br />
salida.<br />
3. Calcular el error asociado a las unida<strong>de</strong>s <strong>de</strong> salida:<br />
δ jp = (y jp − ŷ jp )f ′ (β T j ĥp).<br />
4. Calcular el error asociado a las unida<strong>de</strong>s ocultas:<br />
ψ jp = ∑ k<br />
δ jp β jk f ′ (α T k x p ).
3.5. REDES NEURONALES MULTICAPA 65<br />
5. Calcular:<br />
y<br />
∆β jk = η ĥk δ jp ,<br />
∆α ki = −η ∑ j<br />
x ip δ jp ψ jp ,<br />
y actualizar los pesos <strong>de</strong> acuerdo con los valores obtenidos.<br />
6. Repetir los pasos anteriores para cada patrón <strong>de</strong> entrenamiento.<br />
Ejemplo 3.9 (Sistemas no Lineales: El Sistema <strong>de</strong> Lorenz). En los<br />
últimos años, el análisis <strong>de</strong> sistemas no lineales ha cobrado un fuerte interés.<br />
Uno <strong>de</strong> los fenómenos más sorpren<strong>de</strong>ntes relacionados con estos sistemas<br />
es la aparición <strong>de</strong>l caos <strong>de</strong>terminista, caracterizado por su sensibilidad<br />
a las perturbaciones en las condiciones iniciales, que resulta en un<br />
comportamientos aparentemente impre<strong>de</strong>cible y errático <strong>de</strong>l sistema que se<br />
<strong>de</strong>sarrolla sobre un soporte fractal en su espacio <strong>de</strong> fases llamado atractor<br />
(ver Grassberger and Procaccia, 1983, para más <strong>de</strong>talles). Los mo<strong>de</strong>los <strong>de</strong><br />
circulación atmosférica contienen términos no lineales, por lo que la teoría<br />
<strong>de</strong>l caos ha tenido notable repercusión en este campo; <strong>de</strong> hecho, el caos fue<br />
analizado por primera vez por Lorenz (1963) en las ecuaciones <strong>de</strong> un mo<strong>de</strong>lo<br />
atmosférico simplificado:<br />
˙u(t) = (ẋ,ẏ, ż) = F(u(t)) = (σ(y − x), −x z + r x − y, x y − bz). (3.31)<br />
Lorenz <strong>de</strong>dujo estas ecuaciones cuando estudiaba la posibilidad <strong>de</strong> pre<strong>de</strong>cir<br />
la formación <strong>de</strong> tornados y otras estructuras convectivas tan frecuentes en la<br />
naturaleza y en tan diversas escalas. Las ecuaciones que <strong>de</strong>scriben este experimento<br />
tienen en cuenta los tres efectos más importantes que aparecen en<br />
formaciones convectivas: la fuerza <strong>de</strong>bida al gradiente térmico, la viscosidad<br />
y la difusión térmica.<br />
Las variables (x, y, z) <strong>de</strong> la ecuación (3.31), forman lo que se <strong>de</strong>nomina<br />
el espacio <strong>de</strong> fases o <strong>de</strong> estados (cada punto <strong>de</strong> este espacio es un estado o<br />
fase <strong>de</strong>l sistema). Por ejemplo, para los valores <strong>de</strong> los parámetros σ = 10,<br />
b = 8/3, y r = 28, el sistema presenta una dinámica caótica. Partiendo <strong>de</strong> la<br />
condición inicial (x(0), y(0), z(0)) = (−10, −5, 35) y utilizando un método <strong>de</strong><br />
integración <strong>de</strong> Runge-Kutta <strong>de</strong> cuarto or<strong>de</strong>n y paso <strong>de</strong> integración τ = 10 −2<br />
se obtiene la evolución <strong>de</strong>l sistema en el espacio <strong>de</strong> fases (Fig. 3.21). Por otra<br />
parte, la Fig. 3.22 muestra la evolución en el tiempo <strong>de</strong> las tres variables.<br />
Dado que estos sistemas son <strong>de</strong>terministas, pue<strong>de</strong>n ser predichos a corto<br />
plazo utilizando una técnica <strong>de</strong> ajuste no paramétrico para inferir la estructura<br />
funcional <strong>de</strong>l sistema a partir <strong>de</strong> los datos disponibles. Sin embargo,<br />
dada la sensibilidad <strong>de</strong> estos sistemas a las perturbaciones en sus condiciones<br />
iniciales, una predicción a largo plazo sólo es posible en términos<br />
probabilísticos.<br />
En este ejemplo se analiza la eficiencia <strong>de</strong> las re<strong>de</strong>s multicapa para pre<strong>de</strong>cir<br />
la dinámica caótica <strong>de</strong>l sistema <strong>de</strong> Lorenz. Para ello, se consi<strong>de</strong>ra la
¡£<br />
¤£<br />
¡£<br />
£<br />
¥£<br />
¦£<br />
¡£<br />
¤£<br />
66 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
zn<br />
yn<br />
xn<br />
Figura 3.21: Atractor <strong>de</strong>l sistema <strong>de</strong> Lorenz.<br />
x(t)<br />
¡¢<br />
y(t)<br />
¡£ ¢£¢¡£¡¢ ¤£<br />
z(t)<br />
t<br />
¢ ¡£ ¡¢ ¤£<br />
Figura 3.22: Series temporales para cada una <strong>de</strong> las tres variables <strong>de</strong>l sistema.<br />
serie temporal obtenida integrando el sistema. Esto es equivalente a extraer<br />
una muestra <strong>de</strong>l sistema a intervalos <strong>de</strong> tiempo equi-espaciados t n = n τ,<br />
n = 0, 1, 2, . . .. Se está interesado en la aproximación <strong>de</strong>l mo<strong>de</strong>lo funcional<br />
F a partir <strong>de</strong> una serie u 0 ,u 1 , . . .,u N . En este caso, el mo<strong>de</strong>lo inferido<br />
será <strong>de</strong> la forma u n+p = f(u n ), don<strong>de</strong> f estará dada en términos <strong>de</strong> F, <strong>de</strong>l<br />
tiempo <strong>de</strong> muestreo τ, y <strong>de</strong>l horizonte <strong>de</strong> predicción p.<br />
Para este propósito se consi<strong>de</strong>ra una red multicapa con funciones <strong>de</strong><br />
activación sigmoidales para las capas ocultas y lineales para la capa <strong>de</strong> salida.<br />
El proceso <strong>de</strong> entrenamiento es llevado a cabo consi<strong>de</strong>rando pares entrada–<br />
salida <strong>de</strong> la forma (u n ,u n+p ), don<strong>de</strong> p es el horizonte <strong>de</strong> predicción. Al<br />
tratarse <strong>de</strong> un sistema continuo se han consi<strong>de</strong>rado distintas re<strong>de</strong>s multicapa<br />
3 : a : 3 con una única capa oculta con a neuronas, a<strong>de</strong>más <strong>de</strong> tres neuronas<br />
<strong>de</strong> entrada (x n , y n , z n ) y tres neuronas <strong>de</strong> salida (x n+1 , y n+1 , z n+1 ). Para<br />
cada una <strong>de</strong> estas re<strong>de</strong>s (con a variando entre 1 y 20) se realizaron diez<br />
experimentos con diferentes pesos iniciales; en cada caso se tomó la mejor<br />
solución como el mo<strong>de</strong>lo neuronal aproximado representativo. Por ejemplo,<br />
la Figura 3.23(a) muestra los errores obtenidos para la variable <strong>de</strong> predicción
3.5. REDES NEURONALES MULTICAPA 67<br />
0.1<br />
(a) 0.1<br />
xn-xn<br />
0<br />
0<br />
-0.1<br />
0.015<br />
-0.1<br />
200 400 600 800 1000<br />
(b)<br />
0.015<br />
xn-xn<br />
0<br />
0<br />
-0.015<br />
-0.015<br />
200 400 600 800 1000<br />
Figura 3.23: Residuos x n − ˆx n para dos mo<strong>de</strong>los neuronales con (a) seis y (b)<br />
quince neuronas en la capa oculta. Las re<strong>de</strong>s neuronales han sido entrenadas con<br />
los 500 primeros puntos y una validación cruzada se realiza con los 500 últimos.<br />
Ningún sobreajuste se pue<strong>de</strong> apreciar en ninguno <strong>de</strong> los mo<strong>de</strong>los.<br />
n<br />
x con el mejor mo<strong>de</strong>lo <strong>de</strong> red <strong>de</strong> 6 neuronas en la capa oculta para ˆx n+1 :<br />
0.34<br />
−3768.18 −<br />
1 + e 9.31+0.53 xn−0.68 yn−0.21 + 0.92<br />
−<br />
zn 1 + e7.64−0.121 xn−0.149 yn−0.13 zn<br />
2.75<br />
1 + e 6.19+0.15 xn+0.0451 yn−0.09 − 2.04<br />
+ (3.32)<br />
zn 1 + e1.13+0.06 xn+0.0119 yn−0.06 zn<br />
7164.31<br />
1 + e −0.12+0.00021 xn−0.0002 yn+0.000021 − 63.52<br />
,<br />
zn 1 + e−0.24+0.08 xn−0.016 yn+0.0049 zn<br />
El error cuadrático medio (RMSE) obtenido por esta red fue <strong>de</strong> 0.133 para<br />
el proceso <strong>de</strong> aprendizaje y <strong>de</strong> 0.149 para la validación. Estos resultados<br />
muestran que no se produce sobreajuste en los datos.<br />
A pesar <strong>de</strong>l buen comportamiento <strong>de</strong> la red <strong>de</strong> seis neuronas ocultas para<br />
la predicción a un paso, no está claro que el mo<strong>de</strong>lo neuronal obtenido pueda<br />
reproducir la dinámica <strong>de</strong>l sistema <strong>de</strong> Lorenz. La Figura 3.24 ilustra este hecho<br />
mostrando la evolución <strong>de</strong> la red neuronal para dos condiciones iniciales<br />
distintas; en el primer caso, el sistema neuronal converge a una trayectoria<br />
periódica (Fig. 3.24(a)), mientras que en el segundo caso converge a un<br />
punto fijo (Fig. 3.24(b)); ninguno <strong>de</strong> ellos refleja el comportamiento caótico<br />
<strong>de</strong>l sistema <strong>de</strong> Lorenz.<br />
Cuando se aumenta el número <strong>de</strong> neuronas en la capa oculta por encima<br />
<strong>de</strong> diez, el error disminuye y el comportamiento dinámico <strong>de</strong>l mo<strong>de</strong>lo neuronal<br />
obtenido se asemeja al sistema caótico original. Por ejemplo, la Figura<br />
3.23(b) muestra el error <strong>de</strong> entrenamiento y <strong>de</strong> test asociados a una red<br />
multicapa con 15 neuronas en la capa oculta (este error es un or<strong>de</strong>n <strong>de</strong> magnitud<br />
menor que el asociado con el mo<strong>de</strong>lo <strong>de</strong> 6 neuronas mostrado en (a)).
68 3. MINERÍA DE DATOS Y APRENDIZAJE AUTOMÁTICO<br />
(a)<br />
10 20<br />
0<br />
-10<br />
-20<br />
(b)<br />
10 20<br />
0<br />
-10<br />
-20<br />
10 20 -10<br />
40<br />
40<br />
z<br />
30<br />
20<br />
10<br />
0<br />
-10<br />
x<br />
0 10<br />
y<br />
z<br />
30<br />
20<br />
10<br />
0<br />
-10<br />
x<br />
0 10<br />
Figura 3.24: Evolución en el espacio <strong>de</strong> fases <strong>de</strong> un mo<strong>de</strong>lo neuronal 3 : 6 : 3 con<br />
dos condiciones iniciales diferentes. La parte sombreada en el fondo correspon<strong>de</strong> a<br />
la órbita caótica original y se muestra con propósito ilustrativo.<br />
y<br />
El RMSE <strong>de</strong>l entrenamiento y test fueron <strong>de</strong> 0.0221 y 0.0237, respectivamente,<br />
los cuales indican que no hubo sobre-ajuste. La Figura 3.25 muestra<br />
la evolución <strong>de</strong> los sistemas original y neuronal, comenzando en la misma<br />
condición inicial. El punto don<strong>de</strong> ambos sistemas comienzan a separarse<br />
(≈ t = 3) es aproximadamente el umbral impuesto por el comportamiento<br />
caótico en la precisión numérica <strong>de</strong> los cálculos realizados.<br />
(a)<br />
(b)<br />
z<br />
-20 -1001020 -20 -1001020<br />
40<br />
40<br />
30<br />
30<br />
z<br />
20<br />
20<br />
10<br />
10<br />
-10 y<br />
-10 0 0 10<br />
x<br />
10<br />
x<br />
(c)<br />
15<br />
x<br />
10<br />
-5 05<br />
-10<br />
-15<br />
0 1 2 3 4 5<br />
(d)<br />
y<br />
15<br />
x<br />
10<br />
-5 05<br />
-10<br />
-15<br />
0 1 2 3 4 5<br />
t n x 102<br />
Figura 3.25: Evolución en el espacio <strong>de</strong> fase <strong>de</strong> (a) el mo<strong>de</strong>lo <strong>de</strong> Lorenz y (b) un<br />
mo<strong>de</strong>lo neuronal aproximado con 15 neuronas ocultas.<br />
Finalmente, si se sigue incrementando el número <strong>de</strong> neuronas en la capa<br />
oculta por encima <strong>de</strong> veinte el error <strong>de</strong> entrenamiento continúa <strong>de</strong>creciendo,<br />
pero los mo<strong>de</strong>los neuronales comienza a sobre-ajustarse a los datos. Como<br />
consecuencia, el comportamiento <strong>de</strong> estos mo<strong>de</strong>los presenta diferencias<br />
significativas con el sistema original (la mayoría <strong>de</strong> las veces los mo<strong>de</strong>los<br />
neuronales divergen asimptóticamente).
CAPÍTULO 4<br />
Validación <strong>de</strong> Sistemas Probabiĺısticos <strong>de</strong> Predicción<br />
Meteorológica<br />
4.1. Introducción<br />
Cada variable meteorológica y cada tipo <strong>de</strong> predicción requieren unos<br />
métodos <strong>de</strong> validación apropiados. En este capítulo se analizan las medidas<br />
<strong>de</strong> validación utilizadas a lo largo <strong>de</strong> la Tesis (para una introducción más<br />
general, se refiere al lector a Jolliffe and Stephenson, 2003). Una predicción<br />
es probabilística cuando la salida es una distribución <strong>de</strong> probabilidad sobre<br />
el rango <strong>de</strong> valores o categorías <strong>de</strong> la variable. La forma específica <strong>de</strong> esta<br />
distribución vendrá dada por las características <strong>de</strong> la variable analizada. Por<br />
ejemplo, la temperatura sigue una distribución normal y, por tanto, una predicción<br />
probabilística vendrá dada por la media y la varianza. Los meteoros<br />
son eventos binarios (nieve/no nieve) y su predicción se especifica en base<br />
a un única probabilidad. En otros casos, la situación es más complicada,<br />
especialmente en la precipitación, que es una variable mixta con carácter<br />
discreto (lluvia/no lluvia) y continuo (cantidad <strong>de</strong> lluvia). En este caso la<br />
predicción probabilística se pue<strong>de</strong> dar <strong>de</strong> varias formas; la forma más sencilla<br />
es mediante una probabilidad <strong>de</strong> precipitación por intervalos, discretizando<br />
la variable en todo su rango (Fig. 4.1); otra forma es consi<strong>de</strong>rar la variable<br />
ocurrencia <strong>de</strong> precipitación (que se distribuye aproximadamente según una<br />
Gamma) y dar una predicción probabilística especificando su media (Fig.<br />
4.2). Esta misma distribución proporciona la probabilidad <strong>de</strong> cualquier evento<br />
discreto que se quiera consi<strong>de</strong>rar como, por ejemplo, que la precipitación<br />
supere un cierto umbral. Estos son los tipos <strong>de</strong> predicciones probabilísticas<br />
que se consi<strong>de</strong>ran en esta Tesis y cada uno <strong>de</strong> ellos tiene sus propias medidas<br />
<strong>de</strong> validación.<br />
Se pue<strong>de</strong>n diseñar sistemas <strong>de</strong> predicción probabilística elementales como<br />
la persistencia(τ), don<strong>de</strong> la probabilidad <strong>de</strong> la variable observada o(t) para<br />
69
70 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
0.6<br />
0.5<br />
Probabilidad<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
[0, 1) mm [1, 5) mm [5, 15) mm >15 mm<br />
Precipitación<br />
Figura 4.1: Predicción probabilística <strong>de</strong> precipitación discretizada.<br />
Probabilidad<br />
Prob. acumulada<br />
0.10<br />
0.08<br />
0.06<br />
0.04<br />
0.02<br />
PDF<br />
0<br />
0 5 10 15 20 25 30 35 40 45<br />
Precipitacion (mm)<br />
1<br />
0.83<br />
0.8<br />
0.6<br />
0.4<br />
CDF<br />
0.2<br />
La prob. <strong>de</strong> superar 15 mm es <strong>de</strong>l 17%<br />
0<br />
0 5 10 15 20 25 30 35 40 45<br />
Precipitacion (mm)<br />
Figura 4.2: Funciones <strong>de</strong> <strong>de</strong>nsidad y distribución <strong>de</strong>l fenómeno “ocurrencia <strong>de</strong><br />
precipitación”. La probabilidad <strong>de</strong> que la precipitación supere un umbral se obtiene<br />
fácilmente a partir <strong>de</strong> la función <strong>de</strong> distribución.<br />
el instante t viene dada por los valores anteriores (o(t − 1), . . .,o(t − τ));<br />
y la climatología, que pue<strong>de</strong> ser <strong>de</strong>finida como la climatología estacional,<br />
mensual, diaria, etc., don<strong>de</strong> la distribución para el instante t viene dada por<br />
los valores ocurridos en un cierto subconjunto <strong>de</strong>l registro histórico.<br />
Son numerosos los aspectos que se pue<strong>de</strong>n tener en cuenta para analizar<br />
la calidad <strong>de</strong> un sistema <strong>de</strong> predicción, especialmente en los sistemas <strong>de</strong><br />
predicción probabilística. Sin embargo, no hay ninguna medida <strong>de</strong> validación<br />
que proporcione una información completa <strong>de</strong> la calidad <strong>de</strong>l sistema, sino que<br />
cada índice <strong>de</strong> validación <strong>de</strong>scribe algún atributo particular <strong>de</strong> la relación<br />
entre observaciones y predicciones. Algunos <strong>de</strong> estos atributos caracterizan a<br />
un único sistema, mientras que otros son comparativos e indican la diferencia<br />
entre sistemas <strong>de</strong> predicción distintos (o entre un sistema y otro sistema <strong>de</strong><br />
referencia como la climatología o la persistencia).
4.2. ASPECTOS DE LA CALIDAD DE UNA PREDICCIÓN 71<br />
4.2. Aspectos <strong>de</strong> la Calidad <strong>de</strong> una Predicción<br />
Murphy and Winkler (1987) establecen que toda la información <strong>de</strong> una<br />
validación está contenida en la distribución conjunta <strong>de</strong> predicciones o y observaciones<br />
ô: P(o,ô). En el caso particular <strong>de</strong> variables discreta (con estados<br />
o categorías C 0 , . . ., C d ), esta información se pue<strong>de</strong> representar mediante una<br />
tabla <strong>de</strong> contingencia:<br />
Observación<br />
C 0 C 1 . . . C d<br />
C 0 P 00 P 01 . . . P 0d<br />
Predicción C 1 P 10 P 11 . . . P 1d<br />
. . . . . .<br />
C d P d0 P d1 . . . P dd<br />
que permite obtener distintos índices <strong>de</strong> validación en base a la información<br />
condicional o marginal asociada a la misma: P(o|ô), P(ô|o), P(ô), P(o);<br />
a pesar <strong>de</strong> las relaciones obvias que existen entre estas probabilida<strong>de</strong>s, su<br />
interpretación y utilidad meteorológica es muy distinta y, por ello, cada<br />
índice aporta información interesante <strong>de</strong>s<strong>de</strong> un punto <strong>de</strong> vista diferente.<br />
Una vez que se tiene la distribución conjunta formada por las predicciones<br />
y las observaciones P(o,ô), se pue<strong>de</strong>n examinar sus características <strong>de</strong><br />
varias formas:<br />
Se pue<strong>de</strong>n analizar globalmente las correspon<strong>de</strong>ncias entre pares <strong>de</strong><br />
observación-predicción; es <strong>de</strong>cir, se analiza la distribución conjunta<br />
total. El Brier Score pertenece a este grupo.<br />
Se pue<strong>de</strong> condicionar el análisis a valores concretos <strong>de</strong> la predicción.<br />
La fiabilidad, la resolución y la <strong>de</strong>finición pertenecen a este grupo.<br />
P(o,ô) = P(o|ô)P(ô). (4.1)<br />
Se pue<strong>de</strong> condicionar el análisis a valores concretos <strong>de</strong> la observación.<br />
La discriminación (área ROC, etc.) es <strong>de</strong> este tipo.<br />
P(ô, o) = P(ô|o)P(o). (4.2)<br />
Estos tres tipos <strong>de</strong> análisis <strong>de</strong> la distribución conjunta permiten examinar<br />
diferentes aspectos <strong>de</strong> la calidad <strong>de</strong> las predicciones, llamados atributos <strong>de</strong><br />
la predicción. Murphy (1993) i<strong>de</strong>ntifica una serie <strong>de</strong> atributos importantes<br />
para una predicción (numérica o probabilística):<br />
Sesgo o <strong>de</strong>sviación sistemática (bias): Referido a la concordancia<br />
entre la predicción media y la observación media; un sesgo positivo indica<br />
una sobreestimación <strong>de</strong>l valor a pre<strong>de</strong>cir, mientras un sesgo negativo<br />
indica una subestimación (por ejemplo, se predice menos cantidad<br />
<strong>de</strong> lluvia <strong>de</strong> la que realmente ocurre).
72 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
Asociación: Indica el grado <strong>de</strong> relación lineal entre observación y<br />
predicción. La covarianza y la correlación, son medidas <strong>de</strong> asociación.<br />
Precisión(accuracy): Relativa a la concordancia entre el valor previsto<br />
y el observado realmente, promediada sobre una muestra <strong>de</strong> parejas<br />
individuales <strong>de</strong> predicciones y observaciones. Medidas <strong>de</strong> precisión son,<br />
por ejemplo, el error absoluto medio, el error cuadrático medio, y el<br />
Brier Score (BS).<br />
Habilidad(skill) o precisión relativa: Es la precisión <strong>de</strong> un sistemas<br />
respecto a la obtenida con otro <strong>de</strong> referencia (por ejemplo, climatología<br />
o persistencia). Se <strong>de</strong>finen <strong>de</strong> modo que un valor positivo (negativo)<br />
indica que el sistema es más (menos) preciso que el <strong>de</strong> referencia. El<br />
Brier Skill Score (BSS) es el más conocido.<br />
Fiabilidad(reliability) o bias condicional: Para que un sistema sea fiable,<br />
la probabilidad prevista y la observada <strong>de</strong>ben coincidir lo máximo<br />
posible en todo el rango <strong>de</strong> probabilidad; cuando no es así se habla <strong>de</strong><br />
bias condicionado. La fiabilidad se refiere a un <strong>de</strong>terminado evento y<br />
se representa gráficamente dibujando la curva <strong>de</strong> probabilidad prevista<br />
frente a probabilidad observada (climatológica) para intervalos <strong>de</strong> 5<br />
ó 10 % (ver Fig. 4.3). Cuanto más cerca esté <strong>de</strong> la diagonal más fiable<br />
será el sistema <strong>de</strong> predicción probabilística.<br />
probabilidad observada<br />
probabilidad observada<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
(a) Fiabilida<strong>de</strong>s individuales<br />
184 localida<strong>de</strong>s <strong>de</strong> la Península,<br />
Baleares y Canarias<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
probabilidad prevista<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
(c) Fiabilida<strong>de</strong>s individuales<br />
184 localida<strong>de</strong>s <strong>de</strong> la Península,<br />
Baleares y Canarias<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
probabilidad prevista<br />
probabilidad observada<br />
probabilidad observada<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
(b) Fiabilidad media<br />
Evento: Precipitación > 0.1 mm<br />
%<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
probabilidad prevista<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
(d) Fiabilidad media<br />
Evento: Precipitación > 20 mm<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
probabilidad prevista<br />
Figura 4.3: Curvas <strong>de</strong> fiabilidad individuales y promedio para (a)-(b) Precip ><br />
0.1mm y (c)-(d) Precip > 20mm.
4.2. ASPECTOS DE LA CALIDAD DE UNA PREDICCIÓN 73<br />
Cuando se analiza la fiabilidad <strong>de</strong> distintas predicciones (por ejemplo,<br />
distintos observatorios), utilizar el promedio es un concepto engañoso,<br />
ya que las fiabilida<strong>de</strong>s individuales generalmente son peores,<br />
como ocurre cuando se promedian errores. La fiabilidad media únicamente<br />
indica si el sistema subestima o sobreestima en promedio. En la<br />
Fig. 4.3 se muestran las fiabilida<strong>de</strong>s obtenidas al aplicar un método <strong>de</strong><br />
predicción local a 184 observatorios Españoles. Las Figs. (a)-(b) están<br />
asociadas al evento Precip > 0.1mm, mientras que (c)-(d) correspon<strong>de</strong>n<br />
a Precip > 20mm. Se aprecia que la fiabilidad es mayor/menor en<br />
probabilida<strong>de</strong>s extremas/intermedias; en este caso, el promedio resulta<br />
ser aceptablemente representativo <strong>de</strong> las fiabilida<strong>de</strong>s individuales, ya<br />
que todas subestiman. A<strong>de</strong>más se ve como se <strong>de</strong>teriora la fiabilidad a<br />
medida que el evento es más raro.<br />
Es muy importante estudiar la fiabilidad <strong>de</strong> los sistemas para diferentes<br />
eventos, ya que los eventos raros casi nunca se predicen con<br />
probabilida<strong>de</strong>s altas, manifestando una fuerte pérdida <strong>de</strong> fiabilidad<br />
que <strong>de</strong>be ser corregida, como en la Fig. 4.3 (c)-(d). Existen diversas<br />
técnicas para realizar estas correcciones, entre las que se encuentran<br />
las <strong>de</strong> inflado que básicamente consisten en hacer un cambio <strong>de</strong> escala<br />
para aumentar la varianza estimada hasta su valor real. Existen versiones<br />
más sofisticadas, como la <strong>de</strong>l expan<strong>de</strong>d downscaling, don<strong>de</strong> la<br />
corrección se realiza mediante correlación canónica (Burguer, 1996).<br />
Estas técnicas paramétricas <strong>de</strong> inflado tienen como contrapartida que<br />
el error <strong>de</strong>l estimador corregido siempre es mayor que el <strong>de</strong>l estimador<br />
original (ver von Storch, 1999, para más <strong>de</strong>talles).<br />
Definición: Es la distribución <strong>de</strong> las probabilida<strong>de</strong>s predichas. La <strong>de</strong>finición<br />
se representa mediante un histograma que representa las frecuencias<br />
<strong>de</strong> las probabilida<strong>de</strong>s previstas. Es <strong>de</strong>seable que el histograma<br />
tenga forma <strong>de</strong> ’U’ <strong>de</strong> manera que prediga pocas veces valores ambiguos<br />
en torno a 0.5 (ver Fig. 4.4).<br />
0.6<br />
0.5<br />
Frecuencia<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1<br />
Probabilidad Prevista<br />
Figura 4.4: En negro la <strong>de</strong>finición i<strong>de</strong>al y en blanco un ejemplo <strong>de</strong> <strong>de</strong>finición real.
74 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
4.3. Medidas <strong>de</strong> Validación <strong>de</strong> Predicciones Probabiĺısticas<br />
Si se tiene un conjunto <strong>de</strong> observaciones o 1 , o 2 , ..., o n sobre las que se<br />
realizan las predicciones ô 1 , ô 2 , ...,ô n , los índices <strong>de</strong> validación más habituales<br />
son los <strong>de</strong> precisión y habilidad, ya que proporcionan una medida numérica<br />
<strong>de</strong> la calidad <strong>de</strong> la predicción realizada.<br />
4.3.1. Brier Score<br />
El Brier Score(BS) (Brier, 1950) es una medida clásica <strong>de</strong> la calidad<br />
(precisión) <strong>de</strong> una predicción probabilística para una variable discreta. Es<br />
una distancia medida en unida<strong>de</strong>s <strong>de</strong> probabilidad para la ocurrencia <strong>de</strong> las<br />
distintas categorías <strong>de</strong> la variable.<br />
BS =< (p i − o i ) 2 > i , (4.3)<br />
don<strong>de</strong> p i = P(ô i = 1), y o i es 1 si ocurre el evento y 0 en caso contrario. El<br />
valor <strong>de</strong> BS es nulo para una predicción perfecta.<br />
Es muy usual utilizar la <strong>de</strong>scomposición <strong>de</strong>l Brier score como suma <strong>de</strong><br />
tres componentes; para realizar la <strong>de</strong>scomposición se utiliza el siguiente argumento<br />
(véase Murphy, 1973):<br />
(p i − o i ) 2 = f i (p i − 1) 2 + (1 − f i )p 2 i , (4.4)<br />
don<strong>de</strong> f i = p(o i = 1|p i ) es el número <strong>de</strong> casos observados <strong>de</strong> entre los<br />
previstos con probabilidad p i . Por tanto,<br />
BS = BS f − BS r + I, (4.5)<br />
don<strong>de</strong> BS f es la componente <strong>de</strong> fiabilidad cuya expresión es:<br />
BS f =< (p i − f i ) 2 > (4.6)<br />
BS r es la componente <strong>de</strong> resolución cuya expresión es:<br />
BS r =< (f i − p c ) 2 > (4.7)<br />
p c es la probabilidad climática <strong>de</strong>l evento. Por último I es la componente <strong>de</strong><br />
incertidumbre cuya expresión es:<br />
I = 1 M<br />
M∑<br />
(p c − o i ) 2 = P c (1 − P c ). (4.8)<br />
i=1<br />
I es el Brier Score <strong>de</strong> un sistema <strong>de</strong> predicción climatológico.<br />
El BS da una i<strong>de</strong>a <strong>de</strong>l error cometido en una predicción, pero no dice nada<br />
acerca <strong>de</strong> la dificultad <strong>de</strong> dicha predicción. La dificultad <strong>de</strong> una predicción<br />
está muy asociada con su rareza, cuanto más infrecuente sea, es más difícil<br />
<strong>de</strong> pre<strong>de</strong>cir; por ejemplo, es mucho mas difícil pre<strong>de</strong>cir lluvia en Almería que<br />
en Santan<strong>de</strong>r. Por otra parte, si el evento es muy raro, como por ejemplo
4.3. MEDIDAS DE VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS 75<br />
la lluvia en Almería, un sistema sin utilidad que siempre diga que no va a<br />
llover (como la climatología o la persistencia) tendría un BS casi nulo por<br />
lo que sería casi imposible <strong>de</strong> superar por un sistema <strong>de</strong> mayor utilidad. Es<br />
<strong>de</strong>cir, cuando está muy <strong>de</strong>scompensada la frecuencia <strong>de</strong> ocurrencia y <strong>de</strong> no<br />
ocurrencia, el BS sólo es representativo <strong>de</strong>l evento más frecuente.<br />
Precipitación > [0.1−2−10−20] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
0.7<br />
Brier Score Climatología<br />
Brier Score Predicción<br />
Brier Skill Score<br />
0.6<br />
probabilidad climatológica<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
−0.1 0 0.1 0.2 0.3 0.4 0.5 0.6<br />
Score<br />
Figura 4.5: Brier Scores y Brier Skill Scores correspondientes a un sistema <strong>de</strong> predicción<br />
para 184 estaciones completas y cuatro eventos <strong>de</strong> precipitación. A medida<br />
que el error es inferior al error climatológico el BSS aumenta, los valores máximos<br />
se dan para p c = 0.5.<br />
4.3.2. Brier Skill Score<br />
Como se ve en la fig.4.5, el BS da una i<strong>de</strong>a muy particular <strong>de</strong>l comportamiento<br />
<strong>de</strong> un sistema <strong>de</strong> predicción ya que <strong>de</strong>pen<strong>de</strong> fuertemente <strong>de</strong> la<br />
frecuencia <strong>de</strong>l evento, <strong>de</strong> la localidad don<strong>de</strong> se aplica y <strong>de</strong> la serie utilizada.<br />
Por tanto, si se quiere conocer correctamente la calidad <strong>de</strong>l sistema, se<br />
tendrían que especificar todos y cada uno <strong>de</strong> los valores <strong>de</strong>l BS para cada<br />
localidad y para cada evento, resultando una matriz <strong>de</strong> datos diferente<br />
para cada período consi<strong>de</strong>rado. Para evitar este problema se pue<strong>de</strong> obtener<br />
una medida <strong>de</strong> validación relativa, en lugar <strong>de</strong> absoluta, consi<strong>de</strong>rando<br />
un sistema <strong>de</strong> predicción <strong>de</strong> referencia (como la climatología o la persistencia)<br />
(Talagrand, 1997). A estas medidas relativas se las <strong>de</strong>nomina índices <strong>de</strong><br />
pericia (Skill Scores, SS) y se calculan <strong>de</strong> la siguiente forma:<br />
SS = P(o = 1|p) − P(o = 1|p c)<br />
1 − P(o = 1|p c )<br />
(4.9)
76 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
don<strong>de</strong> p es el sistema <strong>de</strong> predicción que se <strong>de</strong>sea validar, p c es el sistema<br />
<strong>de</strong> referencia, y P(o = 1|p) es la probabilidad <strong>de</strong> que se produzca el evento<br />
dado que el sistema lo predice con probabilidad p.<br />
Teniendo en cuenta que el BS es equivalente a 1 − P(o = 1|p), se pue<strong>de</strong><br />
obtener un índice <strong>de</strong> pericia a partir <strong>de</strong> (4.9). Este índice se <strong>de</strong>nomina Brier<br />
Skill Score (BSS):<br />
BSS = 1 − BS p<br />
BS c<br />
, (4.10)<br />
don<strong>de</strong> BS p es el BS <strong>de</strong>l sistema <strong>de</strong> predicción y BS c el BS <strong>de</strong> la climatología<br />
(u otro sistema <strong>de</strong> referencia). La interpretación es sencilla: Si BSS > 0,<br />
entonces el sistema <strong>de</strong> predicción es mejor que el climatológico; en cambio,<br />
si BSS < 0 el sistema no mejora la climatología. En el caso <strong>de</strong> que BSS = 1<br />
se tendría una predicción perfecta.<br />
4.4. Validación <strong>de</strong> Predicciones Categóricas<br />
Cuando la predicción se refiere a la ocurrencia o no-ocurrencia <strong>de</strong> las<br />
categorías <strong>de</strong> una variable discreta, se habla <strong>de</strong> predicciones categóricas. Las<br />
predicciones categóricas se verifican utilizando tablas <strong>de</strong> contingencia, que<br />
se construyen combinando todas las posibilida<strong>de</strong>s entre categoría prevista y<br />
categoría observada.<br />
Este tipo <strong>de</strong> predicciones son populares para variables binarias (por ejemplo,<br />
Precip > 0.1mm). En este caso, dada una predicción probabilística<br />
P(Precip > 0.1mm) = p, se pue<strong>de</strong> asociar una predicción categórica consi<strong>de</strong>rando<br />
un cierto umbral <strong>de</strong> probabilidad u p para <strong>de</strong>terminar la ocurrencia<br />
o no <strong>de</strong>l evento. Por ejemplo, si se toma u p = 0.5 se <strong>de</strong>terminará la ocurrencia<br />
<strong>de</strong>l evento si la probabilidad es superior a 0.5 y se <strong>de</strong>terminará la no<br />
ocurrencia en caso contrario. En el caso binario, las tablas <strong>de</strong> contingencia<br />
están <strong>de</strong>terminadas por cuatro parámetros:<br />
Observado<br />
Si No<br />
Previsto Si α β<br />
No γ δ<br />
Para variables binarias <strong>de</strong>finidas a partir <strong>de</strong> una variable continua, utilizando<br />
un umbral, se tiene una tabla <strong>de</strong> contingencia diferente para cada valor <strong>de</strong>l<br />
umbral utilizado u p ; por tanto, α, β, γ y δ <strong>de</strong>pen<strong>de</strong>n <strong>de</strong> u p .<br />
Si se quieren contrastar dos sistemas <strong>de</strong> predicción, para un <strong>de</strong>terminado<br />
rango <strong>de</strong> operación, los criterios globales como el BSS pue<strong>de</strong>n inducir a<br />
equivocaciones a la hora <strong>de</strong> elegir el mejor sistema. Cuando se toman <strong>de</strong>cisiones,<br />
se pue<strong>de</strong>n cometer dos tipos <strong>de</strong> errores: falsa alarma y omisión,<br />
conocidos como errores <strong>de</strong> Tipo I y Tipo II respectivamente. Generalmente<br />
en Meteorología, se consi<strong>de</strong>ra que la omisión es un error más grave que la<br />
falsa alarma y esto conduce a que el error más frecuente es, el <strong>de</strong> Tipo I.
4.4. VALIDACIÓN DE PREDICCIONES CATEGÓRICAS 77<br />
Sin embargo si se producen muchas falsas alarmas se pier<strong>de</strong> credibilidad.<br />
Un aspecto importante a tener en cuenta es que la importancia relativa <strong>de</strong><br />
estos dos errores es diferente para diferentes usuarios. Por ello, hay que tener<br />
en cuenta los requerimientos específicos <strong>de</strong>l usuario a quien va dirigida la<br />
predicción.<br />
A continuación se <strong>de</strong>scriben algunas <strong>de</strong> las medidas más utilizadas. Para<br />
indicar su rango <strong>de</strong> valores y el valor óptimo, se utilizará la notación: [a,b]<br />
don<strong>de</strong> se indica el rango y el valor óptimo (en negrita).<br />
Precisión [0,1]:<br />
ACC =<br />
α + δ<br />
α + β + γ + δ<br />
(4.11)<br />
Realmente mi<strong>de</strong> la proporción <strong>de</strong> aciertos, y pue<strong>de</strong> ser maximizada prediciendo<br />
siempre la categoría más común. En regiones don<strong>de</strong> el evento<br />
es muy raro, se hace prácticamente la unidad <strong>de</strong>bido al gran número<br />
<strong>de</strong> aciertos negativos (no aporta información para eventos raros). La<br />
precisión <strong>de</strong> un sistema que nunca predice el evento es:<br />
ACC no =<br />
δ<br />
γ + δ = 1 − p c (4.12)<br />
0.7<br />
0.6<br />
Precipitación > [0.1−2−10−20] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
Sistema I (10%)<br />
Sistema II (50%)<br />
Vigo<br />
Vigo<br />
Sistema NO (100%)<br />
probabilidad climatológica<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
Región Húmeda<br />
0.1<br />
Región Arida<br />
0<br />
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1<br />
Precisión(ACC)<br />
Figura 4.6: Se constata una fuerte <strong>de</strong>pen<strong>de</strong>ncia entre la precisión y la rareza <strong>de</strong>l<br />
evento para diferentes umbrales <strong>de</strong> predicción en diferentes localida<strong>de</strong>s. El sistema<br />
II resulta ser el más preciso en todo el rango. La recta negra representa a la precisión<br />
<strong>de</strong>l sistema que nunca predice la ocurrencia <strong>de</strong>l evento.<br />
En la figura 4.6 queda claro que atendiendo a la precisión, el sistema<br />
con el umbral <strong>de</strong> predicción <strong>de</strong>l 50 % es mejor; a<strong>de</strong>más, se ve que un<br />
promedio global <strong>de</strong> ACC para todas las localida<strong>de</strong>s estaría fuertemente
78 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
sesgado en favor <strong>de</strong> las regiones áridas, por lo que el empleo <strong>de</strong> éste<br />
índice no es aconsejable para ello.<br />
Critical Success In<strong>de</strong>x ó Threat Score [0,1]:<br />
CSI =<br />
α<br />
α + β + γ<br />
(4.13)<br />
Es similar a la precisión, pero se han quitando los aciertos negativos.<br />
Aunque es más equilibrado que el ACC, sus mayores valores se dan<br />
en aquellas localida<strong>de</strong>s don<strong>de</strong> el evento es más común. El CSI <strong>de</strong> un<br />
sistema que nunca predice el evento es nulo, mientras que el CSI <strong>de</strong><br />
un sistema que siempre lo predice es:<br />
CSI si =<br />
α<br />
α + β = p c (4.14)<br />
Al igual que la precisión, es muy inestable para eventos raros.<br />
0.7<br />
0.6<br />
Precipitación > [0.1−2−10−20] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
Sistema I (10%)<br />
Sistema II (50%)<br />
Sistema SI (0%)<br />
probabilidad climatológica<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
Región Húmeda<br />
0.1<br />
Región Arida<br />
0<br />
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8<br />
Critical Success In<strong>de</strong>x(CSI)<br />
Figura 4.7: Nuevamente se constata una notable <strong>de</strong>pen<strong>de</strong>ncia respecto a la rareza<br />
<strong>de</strong>l evento para diferentes umbrales <strong>de</strong> predicción en diferentes localida<strong>de</strong>s. La línea<br />
negra correspon<strong>de</strong> al sistema que siempre predice el evento.<br />
En la figura 4.7 no queda claro qué sistema es mejor según el criterio<br />
<strong>de</strong>l CSI ya que el sistema II con el umbral <strong>de</strong> predicción <strong>de</strong>l 50 % es<br />
mejor en zonas húmedas mientras que el sistema I con el 10 % resulta<br />
mejor para zonas áridas, o equivalentemente para eventos raros; como<br />
en el caso <strong>de</strong>l ACC, no es recomendable un promedio global <strong>de</strong> CSI<br />
para toda las localida<strong>de</strong>s ya que es muy inestable en la zona <strong>de</strong> eventos<br />
raros.
4.4. VALIDACIÓN DE PREDICCIONES CATEGÓRICAS 79<br />
Hit Rate(HIR) [0,1]:<br />
HIR(u p ) = P(p ≥ u p |o = 1) =<br />
α<br />
α + γ<br />
(4.15)<br />
Es una medida <strong>de</strong> precisión, que mi<strong>de</strong> la probabilidad <strong>de</strong> <strong>de</strong>tección; es<br />
<strong>de</strong>cir, pre<strong>de</strong>cir eventos que realmente se han observado.<br />
False Alarm Rate(FAR) [0, 1]:<br />
FAR(u p ) = P(p ≥ u p |o = 0) =<br />
β<br />
β + δ<br />
(4.16)<br />
También es una medida <strong>de</strong> precisión, que mi<strong>de</strong> la proporción <strong>de</strong> fallos<br />
cuando se predice positivamente un evento. Obsérvese que el concepto<br />
habitual <strong>de</strong> falsa alarma es un suceso que se ha predicho, pero luego no<br />
ha ocurrido; sin embargo, en este caso, el evento que condiciona es na<br />
no ocurrencia <strong>de</strong>l evento. Con este cambio se consigue que cualquier<br />
usuario tendrá un criterio <strong>de</strong> comparación referido siempre a la incertidumbre<br />
climatológica <strong>de</strong>l evento, que es un invariante estadístico<br />
in<strong>de</strong>pendiente <strong>de</strong>l tipo <strong>de</strong> sistema <strong>de</strong> predicción empleado.<br />
Curvas ROC (Relative Operating Characteristics)<br />
Las Curvas ROC permiten validar <strong>de</strong> forma uniforme los sistemas <strong>de</strong><br />
predicción categóricos basados en umbrales <strong>de</strong> probabilidad. Se obtienen<br />
representando los valores FAR frente a los HIR para diferentes<br />
umbrales <strong>de</strong> probabilidad u p . Sobre ellas se pue<strong>de</strong>n comparar dos sistemas<br />
diferentes, para los niveles relativos <strong>de</strong> falsas alarmas y omisiones<br />
que más convengan al usuario.<br />
Hay que tener en cuenta cómo se categoriza respecto a u p ; si tomamos<br />
u p = 0, el evento se predice siempre, y por tanto FAR(0) = 1 y<br />
HIR(0) = 1. En cambio si se toma u p = 1, el evento sólo será predicho<br />
cuando éste genere valores <strong>de</strong> p = u p = 1, por lo que no necesariamente<br />
FAR(100) = 0 y HIR(100) = 0. Por contra, si la <strong>de</strong>finición <strong>de</strong> los<br />
umbrales fuese menor o igual en vez <strong>de</strong> mayor o igual, tendríamos que<br />
la curva ROC pasa necesariamente por (0, 0).<br />
La curva ROC para el PPS climatológico<br />
Es sencillo simular un sistema <strong>de</strong> predicción climatológico utilizando<br />
una variable uniforme que genere 0 con probabilidad (1 − p c ) y 1 con<br />
probabilidad p c . La tabla <strong>de</strong> contingencia resultante sería:<br />
Observado<br />
Si No<br />
Previsto Si p 2 c<br />
No p c (1 − p c )<br />
p c (1 − p c )<br />
(1 − p c ) 2
80 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
en este caso:<br />
HIR(p c ) = FAR(p c ) = p c (4.17)<br />
Y si se utiliza un umbral u p , se obtienen fácilmente dos puntos: el (0, 0)<br />
y el (1, 1), ya que en este caso, el pronóstico climático es 0 ó 1, por<br />
tanto, se consi<strong>de</strong>ra que la curva ROC <strong>de</strong> los sistemas climatológicos<br />
siempre está sobre la diagonal.<br />
En la figura 4.8 se ve cómo reduciendo el valor <strong>de</strong>l umbral u p , se<br />
consigue aumentar el HIR con poco aumento <strong>de</strong> FAR hasta que, <strong>de</strong>pendiendo<br />
<strong>de</strong>l sistema <strong>de</strong> predicción, un pequeño aumento en el HIR<br />
produce un gran aumento en el FAR. Operando con un umbral inferior<br />
a la probabilidad climatológica, el sistema comete más falsas alarmas<br />
que aciertos, ya que la pendiente <strong>de</strong> la curva ROC se hace menor que<br />
la diagonal.<br />
Precipitación > [0.1] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
Sistema I (10%)<br />
0.8<br />
Sistema III (up=pc)<br />
Precipitación > [2] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
Sistema I (10%)<br />
0.8<br />
Sistema III (up=pc)<br />
HIR<br />
0.6<br />
0.4<br />
Sistema II (50%)<br />
HIR<br />
0.6<br />
0.4<br />
Sistema II (50%)<br />
0.2<br />
0.2<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
FAR<br />
Precipitación > [10] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
FAR<br />
Precipitación > [20] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
0.8<br />
Sistema III (up=pc)<br />
0.8<br />
HIR<br />
0.6<br />
0.4<br />
Sistema I (10%)<br />
HIR<br />
0.6<br />
0.4<br />
Sistema III (up=pc)<br />
0.2<br />
0.2<br />
Sistema I (10%)<br />
Sistema II (50%)<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
FAR<br />
0 Sistema II (50%)<br />
0 0.2 0.4 0.6 0.8 1<br />
FAR<br />
Figura 4.8: Ejemplo <strong>de</strong> curvas ROC promediadas para cuatro eventos <strong>de</strong> precipitación.<br />
Se han reasaltado los umbrales correspondientes a distintos sistemas.<br />
Para cada umbral <strong>de</strong> probabilidad, el mejor sistema será aquel cuya<br />
tasa HIR sea más alta para un mismo nivel <strong>de</strong> FAR. El criterio más<br />
empleado es el <strong>de</strong>l área bajo la curva ROC, <strong>de</strong> forma que es mejor<br />
aquel sistema que mayor área cubre bajo su curva ROC. Por ejemplo,<br />
la Fig. 4.9 muestra las áreas bao la curva ROC para las predicciones<br />
sobre 196 estaciones <strong>de</strong> la Península consi<strong>de</strong>radas anteriormente. Se<br />
pone claramente <strong>de</strong> manifiesto que lo que para algunas estaciones es<br />
un evento raro, para otras es muy común. Asimismo, el área ROC
4.4. VALIDACIÓN DE PREDICCIONES CATEGÓRICAS 81<br />
aumenta exponencialmente con la probabilidad climatológica.<br />
Precipitación > [0.1] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
0.6<br />
Precipitación > [2] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
0.5<br />
probabilidad climatológica<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
probabilidad climatológica<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
Eventos Raros<br />
0<br />
0.5 0.6 0.7 0.8 0.9 1<br />
Roc Area<br />
Eventos Raros<br />
0<br />
0.5 0.6 0.7 0.8 0.9 1<br />
Roc Area<br />
Precipitación > [10] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
0.2<br />
Precipitación > [20] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
0.1<br />
probabilidad climatológica<br />
0.15<br />
0.1<br />
0.05<br />
Eventos Raros<br />
probabilidad climatológica<br />
0.08<br />
0.06<br />
0.04<br />
0.02<br />
Eventos Raros<br />
0<br />
0.5 0.6 0.7 0.8 0.9 1<br />
Roc Area<br />
0<br />
0.5 0.6 0.7 0.8 0.9 1<br />
Roc Area<br />
Figura 4.9: Areas ROC frente a la frecuencia climatológica <strong>de</strong> cuatro eventos <strong>de</strong><br />
precipitación parar 196 estaciones en la Península.<br />
Valor Económico [-inf,1]<br />
Un potencial usuario <strong>de</strong> un sistema <strong>de</strong> predicción pue<strong>de</strong> tomar alguna<br />
acción preventiva <strong>de</strong>pendiendo <strong>de</strong> la probabilidad <strong>de</strong> que un <strong>de</strong>terminado<br />
evento ocurra. Adoptar la acción preventiva supone un coste C<br />
in<strong>de</strong>pendientemente <strong>de</strong> que el evento suceda o no; por otro lado, si<br />
ocurre el evento y no se toma ninguna acción se produce una pérdida<br />
P. El usuario necesita un criterio sencillo que le permita adoptar la<br />
estrategia que minimice los gastos.<br />
Una curva ROC indica, para cada u p , la relación entre la tasa HIR y<br />
la tasa FAR <strong>de</strong> un <strong>de</strong>terminado sistema <strong>de</strong> predicción. Como se mencionó<br />
anteriormente, esta información por sí sola no es completa ya<br />
que es muy importante especificar la probabilidad <strong>de</strong> ocurrencia <strong>de</strong>l<br />
evento, es <strong>de</strong>cir, su probabilidad climática, que marca el límite a partir<br />
<strong>de</strong>l cual el valor <strong>de</strong> falsas alarmas supera al <strong>de</strong> aciertos en valor absoluto.<br />
Es obvio que no todos los usuarios admiten el mismo número <strong>de</strong><br />
falsas alarmas. Por un lado, cuantas más falsas alarmas pueda admitir<br />
el usuario, conseguirá mayor número <strong>de</strong> aciertos con el mismo sistema;<br />
sin embargo, por otra parte, el número <strong>de</strong> falsas alarmas no pue<strong>de</strong><br />
crecer in<strong>de</strong>finidamente ya que <strong>de</strong>s<strong>de</strong> un punto <strong>de</strong> vista económico, la<br />
alarma conlleva la toma <strong>de</strong> acciones preventivas que tienen un coste
82 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS<br />
C, mientras que la omisión <strong>de</strong> un evento conlleva unas pérdidas P, <strong>de</strong><br />
tal manera que si un evento se presenta con probabilidad P c , el gasto<br />
generado por las acciones preventivas nunca <strong>de</strong>berá superar el límite<br />
P ∗ P c . La tabla <strong>de</strong> gasto sería:<br />
Observado<br />
Si No<br />
Acción Si α . Coste β . Coste<br />
Preventiva No γ . Pérdida δ . 0<br />
De acuerdo con la tabla, el gasto <strong>de</strong>l sistema sería:<br />
Utilizando (4.15) y (4.16) queda:<br />
G = αC + βC + γP (4.18)<br />
G = HIRP c C + FAR(1 − P c )C + (1 − HIR)P c P (4.19)<br />
Si el sistema fuese perfecto, entonces HIR = 1 y FAR = 0 por lo que:<br />
G perfecto = P c C (4.20)<br />
y utilizando como sistema <strong>de</strong> referencia el climatológico se tendría:<br />
G climatico = min[C, P c P] (4.21)<br />
ya que como se dijo anteriormente, el gasto generado por las acciones<br />
preventivas nunca <strong>de</strong>berá superar el límite P P c .<br />
Definiendo el valor económico como la diferencia <strong>de</strong>l gasto, respecto a<br />
un sistema perfecto, <strong>de</strong>l sistema que se preten<strong>de</strong> validar frente a un<br />
sistema climatológico, se tiene:<br />
V =<br />
G − G climatico<br />
G perfecto − G climatico<br />
(4.22)<br />
sustituyendo y poniendo V en función <strong>de</strong> R = C/P, es <strong>de</strong>cir, <strong>de</strong> la<br />
relación Coste-Pérdidas:<br />
V = HIRP cR + FAR(1 − P c )R + (1 − HIR)P c − min[R, P c ]<br />
P c R − min[R, P c ]<br />
(4.23)<br />
• Ya que tanto HIR como FAR <strong>de</strong>pen<strong>de</strong>n <strong>de</strong>l umbral <strong>de</strong> probabilidad<br />
(u p ), V es función <strong>de</strong> u p y R: V = V (u p , R) es <strong>de</strong>cir, existe<br />
una curva V = f(R) para cada valor <strong>de</strong> u p .<br />
• Para cada valor <strong>de</strong> R existe un único valor <strong>de</strong> u p que maximiza<br />
el valor económico <strong>de</strong>l sistema.
4.4. VALIDACIÓN DE PREDICCIONES CATEGÓRICAS 83<br />
• El valor económico máximo se produce cuando R = P c para cualquier<br />
u p .<br />
• Cuando R < P c y a medida que R disminuye, el sistema pier<strong>de</strong><br />
rápidamente su valor económico ya que el coste <strong>de</strong> la acción preventiva<br />
se hace tan pequeño que llega a ser rentable una acción<br />
preventiva permanente haciendo que el sistema sea obsoleto.<br />
• Del mismo modo si R > P c , y a medida que R aumenta, el sistema<br />
pier<strong>de</strong> más lentamente su valor económico a costa <strong>de</strong> ir aumentando<br />
u p para reducir las falsas alarmas hasta que, incapaz <strong>de</strong><br />
soportar más falsas alarmas, vuelve a hacerse obsoleto.<br />
Valor Economico<br />
Valor Economico<br />
Precipitación > [0.1] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
HK Score<br />
Pc: 0.28 HK Score(Pc)<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
R = Coste/Perdidas<br />
Precipitación > [10] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
HK Score<br />
Pc: 0.04<br />
HK Score(Pc)<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
I<br />
I<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
R = Coste/Perdidas<br />
II<br />
II<br />
Valor Economico<br />
Valor Economico<br />
Precipitación > [2] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
HK Score<br />
Pc: 0.17<br />
HK Score(Pc)<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
R = Coste/Perdidas<br />
Precipitación > [20] mm, 184 localida<strong>de</strong>s, PPS: ProMeteo<br />
1<br />
HK Score<br />
Pc: 0.01<br />
HK Score(Pc)<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
I<br />
I<br />
II<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
R = Coste/Perdidas<br />
II<br />
Figura 4.10: Curvas <strong>de</strong> valor económico para diferentes eventos. Para costes bajos<br />
es mejor el sistema I, pero para costes altos es mejor el sistema II.<br />
La validación <strong>de</strong> predicciones realizadas sobre un dominio espacial (una<br />
región, rejilla, o conjunto <strong>de</strong> estaciones) se suelen realizar promediando resultados<br />
espacialmente, o hallando los percentiles espaciales (sobre las estaciones)<br />
<strong>de</strong> los índices. Recientemente se han presentado distintas técnicas que<br />
no promedian los resultados. Por ejemplo Briggs and Levine (1997) presentan<br />
una medida utilizando wavelets para caracterizar la estructura espacial<br />
<strong>de</strong> los errores.
84 4. VALIDACIÓN DE PREDICCIONES PROBABILÍSTICAS
Parte II<br />
Aportaciones <strong>de</strong> la Tesis<br />
85
CAPÍTULO 5<br />
Predicción Local en el Corto Plazo con Técnicas <strong>de</strong><br />
<strong>Agrupamiento</strong><br />
5.1. Introducción<br />
En la actualidad, los servicios meteorológicos utilizan mo<strong>de</strong>los atmosféricos<br />
operativos que simulan con bastante precisión la dinámica <strong>de</strong> la atmósfera<br />
a gran escala sobre rejillas <strong>de</strong> una resolución aproximada <strong>de</strong> 50 a 100 km<br />
(ver Cap. 2). Estos mo<strong>de</strong>los permiten pre<strong>de</strong>cir con bastante pericia el comportamiento<br />
sinóptico <strong>de</strong> la atmósfera en el corto plazo (hasta tres días <strong>de</strong><br />
antelación). Sin embargo, estos mo<strong>de</strong>los poseen menos pericia para pre<strong>de</strong>cir<br />
ciertas variables, como la precipitación, que <strong>de</strong>pen<strong>de</strong>n <strong>de</strong> procesos físicos<br />
complejos, como la formación <strong>de</strong> nubes, evaporación, orografía, turbulencia,<br />
etc., que tienen una escala menor que los mo<strong>de</strong>los (o incluso carecen <strong>de</strong> una<br />
escala característica) y cuya física no es fácil <strong>de</strong> resolver. Esto obliga a incluir<br />
estos procesos en los mo<strong>de</strong>los mediante parametrizaciones, que aproximan<br />
los efectos <strong>de</strong> estos fenómenos a la escala <strong>de</strong> la rejilla empleada (ver Sec.<br />
2.3.2). Por tanto, la predicción a corto plazo <strong>de</strong> meteoros como la precipitación,<br />
niebla, tormenta, etc., es todavía un problema a resolver con enorme<br />
interés científico, social y económico.<br />
En la literatura se han propuesto diferentes métodos para abordar este<br />
problema <strong>de</strong>s<strong>de</strong> distintas perspectivas, utilizando no sólo las predicciones<br />
<strong>de</strong> los mo<strong>de</strong>los numéricos, sino también las series temporales <strong>de</strong> observaciones<br />
disponibles en la región o localidad <strong>de</strong> interés. Estos métodos podrían<br />
clasificarse en tres gran<strong>de</strong>s grupos:<br />
Las técnicas <strong>de</strong> predicción estadística para series temporales, que se<br />
basan únicamente en la información proce<strong>de</strong>nte <strong>de</strong> las observaciones<br />
históricas <strong>de</strong> los meteoros en las localida<strong>de</strong>s o puntos geográficos don<strong>de</strong><br />
87
88 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
se <strong>de</strong>sea realizar la predicción. Con esta información se pue<strong>de</strong>n estimar<br />
mo<strong>de</strong>los estadísticos <strong>de</strong> predicción (mo<strong>de</strong>los autoregresivos, <strong>de</strong><br />
Markov, etc.) que pue<strong>de</strong>n ser posteriormente utilizados para pre<strong>de</strong>cir<br />
futuros valores y ten<strong>de</strong>ncias. Estos métodos son estadísticos y no utilizan<br />
las salidas numéricas <strong>de</strong> los mo<strong>de</strong>los <strong>de</strong> circulación atmosférica.<br />
Por otra parte, las técnicas <strong>de</strong> downscaling dinámico (o incremento<br />
dinámico <strong>de</strong> resolución) tienen como propósito aumentar la resolución<br />
<strong>de</strong> los mo<strong>de</strong>los atmosféricos globales, anidando a éstos un mo<strong>de</strong>lo atmosférico<br />
regional o mesoescalar limitado a la zona <strong>de</strong> interés. Para<br />
ello se usan los campos <strong>de</strong>l mo<strong>de</strong>lo global como condiciones <strong>de</strong> contorno<br />
para el mo<strong>de</strong>lo regional o mesoescalar <strong>de</strong> mayor resolución, el cual<br />
incluye parametrizaciones adaptadas a la zona. Por tanto, la predicción<br />
local se limita a los valores <strong>de</strong> algunas variables que proporciona<br />
el mo<strong>de</strong>lo (temperatura, precipitación, etc.) en los puntos <strong>de</strong> rejilla<br />
en superficie. Estos métodos son esencialmente numéricos (basados<br />
en la integración <strong>de</strong> mo<strong>de</strong>los <strong>de</strong> circulación atmosférica), aunque en<br />
ocasiones se utilizan técnicas estadísticas, como los filtros <strong>de</strong> Kalman<br />
(Bergman and Delleur, 1985), para eliminar la influencia <strong>de</strong> los errores<br />
sistemáticos <strong>de</strong>l mo<strong>de</strong>lo global.<br />
Finalmente, los llamados métodos <strong>de</strong> downscaling estadístico son técnicas<br />
híbridas que combinan las salidas <strong>de</strong> los mo<strong>de</strong>los numéricos con la<br />
información estadística <strong>de</strong> las observaciones. Estas técnicas se basan<br />
en la relación que existe entre los campos atmosféricos previstos por<br />
un mo<strong>de</strong>lo numérico <strong>de</strong>l tiempo y los meteoros realmente ocurridos<br />
localmente. Esta relación se pue<strong>de</strong> analizar estadísticamente utilizando<br />
los registros históricos <strong>de</strong> observaciones disponibles (en una región<br />
o punto <strong>de</strong> interés) y los correspondientes campos atmosféricos simulados<br />
por algún proyecto <strong>de</strong> re-análisis (ver Sec. 2.7). Estos métodos<br />
también pue<strong>de</strong>n consi<strong>de</strong>rarse técnicas <strong>de</strong> interpolación avanzadas, pues<br />
estiman el valor <strong>de</strong> una variable en un punto a partir <strong>de</strong> los valores en<br />
una rejilla que lo contiene.<br />
En esta Tesis se analizan las técnicas estadísticas <strong>de</strong> series temporales y<br />
las híbridas que combinan éstas con predicciones <strong>de</strong> los mo<strong>de</strong>los atmosféricos<br />
globales (el lector interesado en el downscaling dinámico pue<strong>de</strong> consultar las<br />
referencias incluidas en la Sec. 2.4). En concreto, se presentan algunos resultados<br />
comparativos que muestran la superioridad <strong>de</strong> los mo<strong>de</strong>los híbridos<br />
y se introduce un nuevo método, basado en técnicas <strong>de</strong> agrupamiento, que<br />
mejora a los algoritmos actuales en velocidad <strong>de</strong> cómputo y en la pericia <strong>de</strong><br />
las predicciones <strong>de</strong> eventos poco probables.<br />
En la Sec. 5.2 se <strong>de</strong>scriben las técnicas <strong>de</strong> predicción estadística lineales y<br />
no lineales estándar para series temporales, y se muestran sus aplicaciones en<br />
el ámbito <strong>de</strong> la Meteorología. A continuación, la Sec. 5.3 <strong>de</strong>scribe en <strong>de</strong>talle<br />
el problema <strong>de</strong>l downscaling y analiza las técnicas lineales, neuronales y
5.2. TÉCNICAS ESTADÍSTICAS PARA SERIES TEMPORALES 89<br />
locales que han sido propuestas en la literatura para abordar este problema.<br />
Finalmente, la Sec. 5.4 <strong>de</strong>scribe un nuevo método <strong>de</strong>sarrollado en esta Tesis<br />
y compara su eficiencia con otras técnicas en el marco <strong>de</strong> la predicción a<br />
corto plazo.<br />
5.2. Técnicas Estadísticas para Series Temporales<br />
La predicción local <strong>de</strong> meteoros pue<strong>de</strong> abordarse como un problema <strong>de</strong><br />
series temporales: Dada una serie <strong>de</strong> observaciones x 1 , . . .,x N <strong>de</strong> una cierta<br />
variable (por ejemplo, la precipitación diaria en una localidad), se <strong>de</strong>sea pre<strong>de</strong>cir<br />
el estado futuro <strong>de</strong> la misma x N+1 , . . .. En la actualidad se dispone <strong>de</strong><br />
series históricas homogéneas y suficientemente largas (ver Sec. 2.7), por lo<br />
que es posible aplicar técnicas estándar <strong>de</strong> series temporales a este problema.<br />
Por ejemplo, las técnicas lineales autoregresivas tratan <strong>de</strong> explicar la estructura<br />
<strong>de</strong> la serie temporal <strong>de</strong> forma que el valor actual <strong>de</strong> la serie <strong>de</strong>penda<br />
<strong>de</strong> los valores inmediatamente anteriores y <strong>de</strong> una componente aleatoria ɛ n<br />
<strong>de</strong> media zero y varianza σ 2 (ver, por ejemplo, Box and Jenkins, 1976). Así,<br />
un proceso x n se dice que es un proceso autoregresivo <strong>de</strong> or<strong>de</strong>n p (AR(p)) si<br />
x n = α 1 x n−1 + α 2 x n−2 + ... + α p x n−p + ɛ n , (5.1)<br />
don<strong>de</strong> α 1 , . . .,α p son los parámetros <strong>de</strong>l mo<strong>de</strong>lo. Suponiendo que el proceso<br />
es estacionario y <strong>de</strong> varianza finita, estos parámetros pue<strong>de</strong>n obtenerse a<br />
partir las ecuaciones <strong>de</strong> Yule-Walker, que relacionan la función <strong>de</strong> autocorrelación<br />
ρ(k) con los parámetros <strong>de</strong>l mo<strong>de</strong>lo:<br />
p∑<br />
ρ(k) = α m ρ(k − m). (5.2)<br />
m=1<br />
Aparte <strong>de</strong> los mo<strong>de</strong>los autoregresivos, han sido propuestas numerosas variantes<br />
<strong>de</strong> mo<strong>de</strong>los <strong>de</strong> series temporales en la literatura, cada una <strong>de</strong> las<br />
cuales incorpora un nuevo elemento para mo<strong>de</strong>lizar el comportamiento <strong>de</strong> la<br />
serie: Mo<strong>de</strong>los <strong>de</strong> media móvil (MA), que incorporan efectos <strong>de</strong> retraso en<br />
los términos aleatorios; mo<strong>de</strong>los ARMA, que son combinación <strong>de</strong> los mo<strong>de</strong>los<br />
autoregresivos y <strong>de</strong> los <strong>de</strong> media móvil; mo<strong>de</strong>los ARIMA, que permiten<br />
tratar series no estacionarias en la media; SARIMA, que incluyen componentes<br />
periódicas estacionales, etc. (ver Chatfield, 2003, para una <strong>de</strong>scripción<br />
actualizada <strong>de</strong> estos mo<strong>de</strong>los).<br />
Estos mo<strong>de</strong>los han sido aplicados en Meteorología con cierto éxito en<br />
escalas <strong>de</strong> tiempo mensual o estacional, don<strong>de</strong> los promedios <strong>de</strong> las variables<br />
son aproximadamente gaussianos. Por ejemplo, Zwiers and von Storch<br />
(1990) emplean un mo<strong>de</strong>lo AR para la mo<strong>de</strong>lización <strong>de</strong>l patrón El Niño/Oscilación<br />
<strong>de</strong>l Sur (ENSO); por otra parte Verma et al. (2002) utilizan un mo<strong>de</strong>lo<br />
ARIMA para caracterizar medias mensuales <strong>de</strong> precipitación. Sin embargo,<br />
dado que la mayoría <strong>de</strong> las variables meteorológicas son no gaussianas en el<br />
corto plazo, estas técnicas son ina<strong>de</strong>cuadas para la predicción local aplicada
90 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
a esta escala temporal. Para solventar este problema, se han introducido<br />
distintas extensiones no lineales <strong>de</strong> los mo<strong>de</strong>los autoregresivos; por ejemplo,<br />
Buhamra et al. (2003) analizan en <strong>de</strong>talle las propieda<strong>de</strong>s <strong>de</strong> distintas<br />
extensiones basadas en re<strong>de</strong>s neuronales; por otra parte, Furundzic (1998)<br />
aplica con cierto éxito uno <strong>de</strong> estos mo<strong>de</strong>los autoregresivos neuronales para<br />
la predicción <strong>de</strong> escorrentías (ver Masters, 1995, para una <strong>de</strong>scripción general<br />
<strong>de</strong> este tipo <strong>de</strong> técnicas). Sin embargo, como se verá más a<strong>de</strong>lante,<br />
estos mo<strong>de</strong>los no consiguen alcanzar la pericia <strong>de</strong> otras técnicas híbridas <strong>de</strong><br />
predicción local.<br />
En el ámbito <strong>de</strong> la predicción probabilística también han sido aplicadas<br />
distintas técnicas estocásticas para pronosticar la probabilidad <strong>de</strong><br />
un cierto evento meteorológico (por ejemplo la ocurrencia o no <strong>de</strong> lluvia<br />
“Precip > 0.5mm”; <strong>de</strong> vientos fuertes “Racha > 80km/h”, etc.). Las ca<strong>de</strong>nas<br />
<strong>de</strong> Markov han sido utilizadas profusamente en este campo, comenzando<br />
con Gabriel and Neumann (1962) que <strong>de</strong>sarrollaron un mo<strong>de</strong>lo probabilístico<br />
<strong>de</strong> precipitación para Tel Aviv. Posteriormente, el uso <strong>de</strong> estos<br />
mo<strong>de</strong>los se ha extendido a la predicción <strong>de</strong> eventos más complejos, como<br />
el día <strong>de</strong> comienzo <strong>de</strong> lluvias (el primer día que lloverá a partir <strong>de</strong> la fecha<br />
actual), o el primer día que se superará un cierto umbral <strong>de</strong> precipitación<br />
(Stern, 1982). Estos mo<strong>de</strong>los estocásticos también se han combinado<br />
con técnicas <strong>de</strong> simulación (tipo Monte Carlo) para generar simulaciones<br />
numéricas <strong>de</strong> series <strong>de</strong> precipitación. Para cada día, primero se simula la<br />
ocurrencia o no <strong>de</strong> lluvia utilizando un mo<strong>de</strong>lo <strong>de</strong> Markov (generalmente<br />
<strong>de</strong> or<strong>de</strong>n uno); en el caso <strong>de</strong> ocurrencia, se simula a continuación un valor<br />
numérico para la misma a partir <strong>de</strong> la distribución empírica <strong>de</strong> la cantidad<br />
<strong>de</strong> precipitación. Estos métodos se conocen como generadores <strong>de</strong> tiempo<br />
(weather generators) (ver Wilby and Wilks, 1999, y las referencias incluidas).<br />
A<strong>de</strong>más <strong>de</strong> las ca<strong>de</strong>nas <strong>de</strong> Markov, también han sido aplicados otros<br />
métodos estocásticos a estos problemas: procesos continuos puntuales (point<br />
process) (Rodriguez-Iturbe et al., 1987), procesos <strong>de</strong> renovación (Markov renewal<br />
process) (Faufoula-Georgiou and Lettenmaier, 1987), etc.<br />
Para ilustrar la aplicación <strong>de</strong> estas técnicas en la predicción local se<br />
ha realizado un sencillo experimento consistente en pronosticar la probabilidad<br />
<strong>de</strong>l evento “Precip > 0.5mm” (es <strong>de</strong>cir, ocurrencia <strong>de</strong> lluvia). Se<br />
ha consi<strong>de</strong>rado la serie diaria <strong>de</strong> precipitaciones en Santan<strong>de</strong>r durante los<br />
inviernos (Noviembre-Enero) <strong>de</strong>l período 1979-2000. Con esta serie se han<br />
ajustado los parámetros <strong>de</strong> un mo<strong>de</strong>lo autoregresivo neuronal (una red multicapa<br />
5:3:1, con activación sigmoidal <strong>de</strong> rango [0, 1] en la salida; ver Sec.<br />
3.5) y un mo<strong>de</strong>lo <strong>de</strong> Markov <strong>de</strong> or<strong>de</strong>n 5. Las entradas <strong>de</strong> la red neuronal<br />
son los valores numéricos <strong>de</strong> la precipitación en los cinco días previos al día<br />
<strong>de</strong> predicción y su salida es la probabilidad <strong>de</strong> ocurrencia <strong>de</strong>l evento binario<br />
Precip > 0.5mm (ceros y unos en la muestra <strong>de</strong> entrenamiento); por<br />
otra parte, la ca<strong>de</strong>na <strong>de</strong> Markov es generada consi<strong>de</strong>rando la serie <strong>de</strong> datos<br />
binaria obtenida discretizando la serie según la ocurrencia o no ocurrencia<br />
<strong>de</strong>l evento. Los resultados se comparan con los obtenidos por una técnica
5.2. TÉCNICAS ESTADÍSTICAS PARA SERIES TEMPORALES 91<br />
híbrida <strong>de</strong> downscaling estadístico que combina la información <strong>de</strong> las series<br />
temporales con las salidas <strong>de</strong> mo<strong>de</strong>los numéricos atmosféricos globales (se<br />
trata <strong>de</strong> una técnica basada en vecinos cercanos, que se <strong>de</strong>scribirá en la Sec.<br />
5.4). La Fig. 5.1 muestra el valor real (observación), así como las probabilida<strong>de</strong>s<br />
predichas por los mo<strong>de</strong>los anteriores para los tres meses <strong>de</strong> invierno<br />
<strong>de</strong>l año 2001. Esta figura pone <strong>de</strong> manifiesto la utilidad <strong>de</strong> las salidas <strong>de</strong> los<br />
mo<strong>de</strong>los atmosféricos numéricos <strong>de</strong> predicción, combinados con las técnicas<br />
estadísticas (downscaling estadístico). Una comparación más extensa <strong>de</strong><br />
estas técnicas pue<strong>de</strong> encontrarse en Gutiérrez et al. (2002c).<br />
Observacioón Local Neuronal Markov<br />
probabilidad<br />
1<br />
0.8<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
10 20 30 40 50 60 70 80 90<br />
día<br />
Figura 5.1: Valor observado y probabilida<strong>de</strong>s predichas con un mo<strong>de</strong>lo neuronal,<br />
una ca<strong>de</strong>na <strong>de</strong> Markov y un método híbrido (local) para la ocurrencia <strong>de</strong> precipitación<br />
durante los tres meses <strong>de</strong> invierno <strong>de</strong>l año 2001.<br />
5.2.1. Series Caóticas. Técnicas <strong>de</strong> Inmersión (Embedding).<br />
En los últimos años, el análisis <strong>de</strong> series temporales caóticas ha cobrado<br />
un fuerte interés <strong>de</strong>bido a sus múltiples aplicaciones (ver, por ejemplo,<br />
Abarbanel, 1995). Las técnicas clásicas autoregresivas <strong>de</strong> análisis <strong>de</strong> series<br />
temporales <strong>de</strong>scritas en la sección anterior han sido generalizadas teniendo<br />
en cuenta las propieda<strong>de</strong>s dinámicas <strong>de</strong> los sistemas caóticos. Des<strong>de</strong> un<br />
punto <strong>de</strong> vista práctico, el avance más importante en este campo ha sido la<br />
llamada técnica <strong>de</strong> inmersión o embedding (Sauer, 1994), que supone que la<br />
serie temporal proviene <strong>de</strong> un sistema dinámico <strong>de</strong>terminista (por ejemplo,<br />
una ecuación diferencial) <strong>de</strong>finido en un conjunto <strong>de</strong> variables que componen<br />
su espacio <strong>de</strong> fases:<br />
dx(t)<br />
= F(x(t)), (5.3)<br />
dt<br />
Una serie temporal x 1 ,x 2 , . . .,x N tomada <strong>de</strong>l sistema caótico respon<strong>de</strong>rá<br />
a la relación funcional <strong>de</strong>l sistema (5.3). Por tanto, con técnicas apropiadas<br />
se podrá obtener un mo<strong>de</strong>lo aproximado <strong>de</strong>l mismo. Sin embargo, en<br />
la práctica no suele ser posible medir todas las variables que componen el<br />
espacio <strong>de</strong> fases <strong>de</strong> un sistema, sino que sólo se tiene acceso a observables<br />
<strong>de</strong>rivados <strong>de</strong> estas variables o(t) = G(x(t)); por ejemplo, no se pue<strong>de</strong>n medir
92 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
todos los grados <strong>de</strong> libertad que componen la atmósfera, pero se dispone <strong>de</strong><br />
la medición <strong>de</strong> algunas variables <strong>de</strong>rivadas (precipitación, temperatura, etc.)<br />
en puntos concretos. En estos casos, la técnica <strong>de</strong>l <strong>de</strong>lay-embedding ofrece<br />
una forma <strong>de</strong> reconstruir un espacio <strong>de</strong> fases topológicamente equivalente al<br />
original, tomando vectores <strong>de</strong> retrasos temporales <strong>de</strong>l observable <strong>de</strong> la forma:<br />
(o(t), o(t−τ), ..., o(t−(m−1)τ)), don<strong>de</strong> o(t) es el valor <strong>de</strong>l observable en<br />
el tiempo t y los parámetros τ y m son el salto y la dimensión <strong>de</strong> embedding,<br />
respectivamente. Bajo ciertas condiciones (Sauer, 1994), existe un difeomorfismo<br />
(aplicación biyectiva, diferenciable y con inversa diferenciable) entre<br />
el espacio <strong>de</strong> fases original y el espacio <strong>de</strong> embedding resultante, <strong>de</strong> forma<br />
que la evolución <strong>de</strong>l sistema en el espacio <strong>de</strong> fases pue<strong>de</strong> ser <strong>de</strong>terminada<br />
a partir <strong>de</strong> una función en el espacio <strong>de</strong> embedding. De este modo se tiene<br />
una relación funcional <strong>de</strong> la forma:<br />
o(t) = G(x(t)) = H(o(t − τ), ..., o(t − (m − 1)τ)), (5.4)<br />
don<strong>de</strong> H será la función compuesta dada por el difeomorfismo G, la función<br />
<strong>de</strong> evolución <strong>de</strong>l sistema dinámico y la función característica <strong>de</strong>l observable.<br />
Los parámetros τ y m han <strong>de</strong> elegirse a<strong>de</strong>cuadamente para que el espacio<br />
resultante sea topológicamente equivalente al espacio <strong>de</strong> fases original. Para<br />
la dimensión <strong>de</strong> embedding se ha hallado la cota teórica m < 2D +1, don<strong>de</strong><br />
D es la dimensión <strong>de</strong>l atractor <strong>de</strong>l sistema original. A este valor <strong>de</strong> m se<br />
le <strong>de</strong>nomina “dimension <strong>de</strong> embedding” <strong>de</strong>l sistema dinámico. El intervalo<br />
temporal τ es arbitrario <strong>de</strong>s<strong>de</strong> el punto <strong>de</strong> vista teórico; sin embargo, una<br />
mala elección obligará a tomar más retrasos <strong>de</strong> los necesarios. En la práctica,<br />
una forma sencilla <strong>de</strong> seleccionar τ es garantizar la in<strong>de</strong>pen<strong>de</strong>ncia lineal entre<br />
sucesivos retrasos; para ello se pue<strong>de</strong> utilizar la función <strong>de</strong> autocorrelación<br />
o la información mutua <strong>de</strong> la serie (ver Abarbanel, 1995, para más <strong>de</strong>talles).<br />
Para ilustrar esta técnica se consi<strong>de</strong>ra el mo<strong>de</strong>lo <strong>de</strong> Lorenz <strong>de</strong>scrito en el<br />
Ejemplo 3.9, y se supone que sólo se dispone <strong>de</strong> un observable <strong>de</strong>l sistema:<br />
Una serie temporal <strong>de</strong> 5000 puntos <strong>de</strong> la variable x, obtenida integrando<br />
el sistema con un método <strong>de</strong> Runge-Kutta <strong>de</strong> cuarto or<strong>de</strong>n y paso <strong>de</strong> integración<br />
∆t = 10 −2 . La Fig. 5.2 muestra una proyección <strong>de</strong>l espacio <strong>de</strong><br />
embedding dado por τ = 10 y m = 4; se observa la similitud topológica con<br />
el atractor real <strong>de</strong>l sistema mostrado en la Fig. 3.21. Por tanto, se pue<strong>de</strong><br />
aplicar una red neuronal para tratar <strong>de</strong> mo<strong>de</strong>lizar la dinámica <strong>de</strong>l sistema<br />
en el espacio <strong>de</strong> retrasos. La Fig. 5.3 muestra el error obtenido por una red<br />
neuronal 4:3:3:1 entrenada para estimar x n utilizando x n−τ , x n−2τ , x n−3τ y<br />
x n−4τ . En este caso, el tiempo <strong>de</strong> predicción es τ (en este ejemplo τ correspon<strong>de</strong><br />
al mínimo retraso tomado: n = 10 ó t = 10 ∗ 10 −2 = 0.1 unida<strong>de</strong>s <strong>de</strong><br />
tiempo).<br />
Si se trata <strong>de</strong> utilizar este mismo mo<strong>de</strong>lo para pre<strong>de</strong>cir el valor <strong>de</strong>l sistema<br />
a tiempos más largos (iterando el sistema con las predicciones obtenidas),<br />
existe un horizonte a partir <strong>de</strong>l cual el sistema aproximado ya no sigue la<br />
misma dinámica <strong>de</strong>l original. Por ejemplo, en la Fig. 5.4 se muestra la predicción<br />
obtenida por la red neuronal para umbrales <strong>de</strong> tiempo mayores. En
5.2. TÉCNICAS ESTADÍSTICAS PARA SERIES TEMPORALES 93<br />
20<br />
xn<br />
0<br />
-15<br />
20<br />
xn-τ<br />
0<br />
-20 -15<br />
0<br />
x n-2τ<br />
20<br />
Figura 5.2: Atractor en el espacio <strong>de</strong> embedding obtenido a partir <strong>de</strong> un serie<br />
temporal <strong>de</strong> la variable x <strong>de</strong>l sistema <strong>de</strong> Lorenz.<br />
15<br />
10<br />
5<br />
xn<br />
0<br />
xn -xn<br />
-5<br />
-10<br />
-15<br />
0.1<br />
0<br />
0.1<br />
1 100 200 300 400 500<br />
n<br />
Figura 5.3: Serie temporal real x n y error obtenido con la estimación ˆx n dada por<br />
una red neuronal 4:3:3:1 (la abscisa <strong>de</strong> la figura inferior está magnificada un factor<br />
50 para claridad <strong>de</strong> la visualización).<br />
xn ,xn<br />
15<br />
10<br />
5<br />
0<br />
-5<br />
-10<br />
-15<br />
20 21 22 23 24 25 26 27<br />
Figura 5.4: Serie original <strong>de</strong>l mo<strong>de</strong>lo <strong>de</strong> Lorenz (trazo grueso) y serie obtenida<br />
prolongando la red neuronal a partir <strong>de</strong> la misma condición inicial.<br />
n
94 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
esta figura, tanto la red neuronal como el sistema <strong>de</strong> Lorenz son inicializados<br />
en un instante <strong>de</strong> tiempo y prolongados <strong>de</strong> forma in<strong>de</strong>pendiente. Las<br />
trayectorias <strong>de</strong> ambos sistemas siguen la misma evolución hasta un tiempo<br />
t = 1.8 en que comienzan a diverger, marcando el umbral <strong>de</strong> predicción en<br />
este caso. En Cofiño et al. (2003b) se presenta un estudio más exhaustivo<br />
sobre la capacidad <strong>de</strong> predicción <strong>de</strong> las re<strong>de</strong>s neuronales en este campo.<br />
Para aplicar este tipo <strong>de</strong> técnicas a datos meteorológicos es necesario<br />
consi<strong>de</strong>rar la atmósfera como un sistema caótico <strong>de</strong> baja dimensión<br />
(Tsonis and Elsner, 1988). Un observable pue<strong>de</strong> ser la temperatura medida<br />
en una estación meteorológica (Oviedo). La Fig. 5.5(a) muestra la serie<br />
temporal <strong>de</strong> la temperatura media horaria registrada en Oviedo entre los<br />
años 1979 y 1993. En la figura sólo se han representado 3 años para observar<br />
con claridad la onda anual, con los correspondiente máximos <strong>de</strong> temperatura<br />
alcanzados en la época estival. En la gráfica superior se ha ampliado una<br />
zona <strong>de</strong> la serie temporal para mostrar la onda diurna.<br />
200<br />
150<br />
100<br />
50<br />
0<br />
30<br />
(a)<br />
1.12 1.13 1.14 1.15 1.16 1.17<br />
x 10 4<br />
20<br />
ºC<br />
10<br />
0<br />
10<br />
(b)<br />
5<br />
0<br />
-5<br />
-10<br />
x 10 4<br />
0 0.5 1 1.5 2 2.5<br />
n<br />
Figura 5.5: Temperatura media horaria tomada en el observatorio <strong>de</strong> Oviedo entre<br />
los años 1979 y 1981.<br />
Como pue<strong>de</strong> observarse en este ejemplo, la situación real cuando se trabaja<br />
con datos meteorológicos no es sencilla, pues la serie contiene varias<br />
componentes periódicas (onda anual, diurna, etc.) y ruido, a<strong>de</strong>más <strong>de</strong> la<br />
componente no lineal. Las componentes periódicas pue<strong>de</strong>n separarse fácilmente<br />
(ver Fig. 5.5(b)), pero el efecto <strong>de</strong>l ruido complica la aplicación <strong>de</strong><br />
la técnica <strong>de</strong> embedding. Por ejemplo, la Fig. 5.6 muestra el espacio <strong>de</strong> inmersión<br />
para el ejemplo <strong>de</strong> la temperatura en Oviedo, consi<strong>de</strong>rando tanto la<br />
señal original, como la señal obtenida eliminando la onda anual. En esta última<br />
figura resulta difícil observar alguna dinámica <strong>de</strong>terminista. Este hecho
5.3. TÉCNICAS HÍBRIDAS (DOWNSCALING ESTADÍSTICO) 95<br />
se pue<strong>de</strong> comprobar <strong>de</strong> forma práctica comparando un mo<strong>de</strong>lo no lineal neuronal<br />
y uno lineal entrenados con los datos. Las distintas pruebas realizadas<br />
no mostraron ninguna diferencia significativa entre ambos mo<strong>de</strong>los.<br />
35<br />
30<br />
(a)<br />
15<br />
10<br />
(b)<br />
25<br />
20<br />
5<br />
T(t)<br />
15<br />
T(t)<br />
0<br />
10<br />
5<br />
5<br />
0<br />
0 5 10 15 20 25 30 35<br />
T(t-6)<br />
10<br />
10 5 0 5 10 15<br />
T(t-6)<br />
Figura 5.6: (a) Espacio <strong>de</strong> inmersión (T(t),T(t −6)) para la serie <strong>de</strong> temperaturas<br />
<strong>de</strong> Oviedo. (b) Espacio <strong>de</strong> inmersión para la serie anterior restando una media móvil<br />
(T(i − 24),T(i),T(i + 24)) para eliminar la componente anual.<br />
Por otra parte, la hipótesis <strong>de</strong> la baja dimensionalidad <strong>de</strong> la atmósfera es<br />
bastante cuestionable (Lorenz, 1991) y los mo<strong>de</strong>los <strong>de</strong>sarrollados no se han<br />
mostrado competitivos con otras técnicas. No obstante, en algunas aplicaciones,<br />
estas técnicas han mostrado una gran utilidad en combinación con<br />
mo<strong>de</strong>los numéricos. Por ejemplo, Pérez-Muñuzuri and Gelpi (2000) presentan<br />
un mo<strong>de</strong>lo <strong>de</strong> predicción basado en esta técnica para la cubierta nubosa,<br />
y muestra como estas predicciones pue<strong>de</strong>n ser utilizadas por un mo<strong>de</strong>lo<br />
numérico mesoscalar (ARPS) para mejorar la capacidad <strong>de</strong> predicción <strong>de</strong>l<br />
mismo.<br />
Los recientes avances en el campo <strong>de</strong>l caos espacio-temporal suponen<br />
una prometedora línea <strong>de</strong> trabajo para po<strong>de</strong>r llegar a mo<strong>de</strong>lizar la dinámica<br />
atmosférica <strong>de</strong> forma más sólida y global (Gollub and Cross, 2000), sin<br />
tener que recurrir a hipótesis simplistas como la baja dimensionalidad <strong>de</strong> la<br />
atmósfera.<br />
5.3. Técnicas Híbridas (Downscaling Estadístico)<br />
En la sección anterior se han <strong>de</strong>scrito distintas técnicas <strong>de</strong> predicción que<br />
se aplican directamente a observaciones (series temporales) para pre<strong>de</strong>cir<br />
ten<strong>de</strong>ncias y/o futuras ocurrencias <strong>de</strong> eventos. Sin embargo, estas técnicas<br />
no aprovechan el conocimiento sobre la dinámica <strong>de</strong> la atmósfera contenido<br />
en los mo<strong>de</strong>los numéricos <strong>de</strong> circulación atmosférica. Las predicciones <strong>de</strong><br />
estos mo<strong>de</strong>los proporcionan los valores <strong>de</strong> un conjunto <strong>de</strong> variables fundamentales<br />
(temperatura, presión, humedad, etc.) para un alcance dado sobre<br />
una rejilla 3D con una cierta resolución horizontal y vertical (ver Sec. 2.4).
96 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
A<strong>de</strong>más, en el nivel <strong>de</strong> superficie, el mo<strong>de</strong>lo también proporciona el valor <strong>de</strong><br />
algunas variables <strong>de</strong>rivadas (precipitación, etc.). Éstas son las variables que<br />
más afectan a la actividad humana y, por tanto, las que tienen mayor interés<br />
práctico. Sin embargo, las predicciones obtenidas por los mo<strong>de</strong>los numéricos<br />
para estas variables también están limitadas por la resolución y por la<br />
parametrizaciones físicas empleadas (que aproximan los efectos <strong>de</strong> algunos<br />
fenómenos como la turbulencia, orografía, etc., que afectan a las variables<br />
<strong>de</strong> superficie; ver Sec. 2.3.2).<br />
Dadas las limitaciones <strong>de</strong> ambas técnicas por separado, se han <strong>de</strong>sarrollado<br />
distintos métodos híbridos para combinar <strong>de</strong> forma apropiada ambas<br />
fuentes <strong>de</strong> información: observaciones (con información estadística sobre la<br />
climatología local) y salidas <strong>de</strong> mo<strong>de</strong>los numéricos (con las predicciones <strong>de</strong>l<br />
estado global <strong>de</strong> la atmósfera). Estas técnicas híbridas son <strong>de</strong>nominadas<br />
métodos <strong>de</strong> downscaling estadístico (ver, por ejemplo, Wilby and Wigley,<br />
1997; Zorita and von Storch, 1999). En este caso, en lugar <strong>de</strong> aumentar la<br />
resolución <strong>de</strong> la rejilla sobre la que se realiza la predicción (downscaling<br />
dinámico), se obtienen predicciones sobre aquellas regiones o puntos geográficos<br />
don<strong>de</strong> se disponga <strong>de</strong> observaciones. La Fig. 5.7 ilustra este problema<br />
para el caso concreto <strong>de</strong> la Cuenca Norte <strong>de</strong> la Península Ibérica.<br />
Figura 5.7: El problema <strong>de</strong> downscaling. La figura superior muestra la rejilla <strong>de</strong> un<br />
mo<strong>de</strong>lo numérico <strong>de</strong> 1 o <strong>de</strong> resolución horizontal (aprox. 100 km) sobre la Península<br />
Ibérica; la figura inferior muestra una ampliación <strong>de</strong> la cornisa Cantábrica <strong>de</strong>tallando<br />
los puntos <strong>de</strong> rejilla <strong>de</strong>l mo<strong>de</strong>lo numérico (‘×’), y los observatorios <strong>de</strong> la red<br />
principal (‘+’) y secundaria (triángulos) <strong>de</strong>l INM don<strong>de</strong> se dispone <strong>de</strong> observaciones<br />
históricas.
5.3. TÉCNICAS HÍBRIDAS (DOWNSCALING ESTADÍSTICO) 97<br />
5.3.1. Técnicas Globales Lineales y <strong>Neuronales</strong><br />
Los métodos híbridos <strong>de</strong> downscaling estadístico se basan en la relación<br />
que existe entre el estado <strong>de</strong> la atmósfera y los fenómenos meteorológicos<br />
observados en superficie y t en un instante <strong>de</strong> tiempo t. El estado <strong>de</strong> la<br />
atmósfera se pue<strong>de</strong> aproximar utilizando un mo<strong>de</strong>lo numérico <strong>de</strong> circulación,<br />
que proporciona los campos atmosféricos x t estimados para un tiempo<br />
t. Por tanto, se pue<strong>de</strong> analizar estadísticamente esta relación utilizando los<br />
registros históricos disponibles en un punto <strong>de</strong> interés, y los correspondientes<br />
campos atmosféricos simulados por un mo<strong>de</strong>lo numérico <strong>de</strong> re-análisis (ver<br />
Sec. 2.7). Este esquema se <strong>de</strong>nomina Perfect-Prog puesto que supone que el<br />
mo<strong>de</strong>lo atmosférico proporciona una representación fi<strong>de</strong>digna <strong>de</strong>l estado <strong>de</strong><br />
la atmósfera que no varía en el tiempo, al menos en la periodo <strong>de</strong>l re-análisis<br />
(ver Wilks, 1995, para una <strong>de</strong>scripción más <strong>de</strong>tallada). De esta forma, se pue<strong>de</strong><br />
entrenar un mo<strong>de</strong>lo global <strong>de</strong> regresión para estimar una relación lineal<br />
entre los datos ŷ t = ax t + b. Así, dado un patrón ˆx predicho por un mo<strong>de</strong>lo<br />
numérico para un cierto alcance, se tendrá una estimación aˆx + b <strong>de</strong>l valor<br />
<strong>de</strong> la variable local esperado. Algunas aplicaciones <strong>de</strong> esta técnica están <strong>de</strong>scritas<br />
en Enke and Spekat (1997) y Billet et al. (1997). Un problema <strong>de</strong> esta<br />
técnica es que, en general, los mo<strong>de</strong>los lineales son difícilmente justificables<br />
para la predicción a corto plazo dada la no normalidad <strong>de</strong> las variables a esta<br />
escala temporal. Las limitaciones <strong>de</strong> los métodos lineales han sido recientemente<br />
superadas consi<strong>de</strong>rando mo<strong>de</strong>los no-lineales más generales ŷ t = f(x t ),<br />
don<strong>de</strong> la forma funcional <strong>de</strong> f es ajustada usando técnicas no paramétricas<br />
mo<strong>de</strong>rnas (por ejemplo, re<strong>de</strong>s neuronales, Gardner and Dorling, 1998;<br />
McGinnis, 1994).<br />
Otra aproximación a este problema supone que los patrones atmosféricos<br />
disponibles no son una representación perfecta <strong>de</strong> la atmósfera, sino que<br />
<strong>de</strong>pen<strong>de</strong>n <strong>de</strong>l mo<strong>de</strong>lo numérico utilizado (por ejemplo, cada cambio realizado<br />
en el mo<strong>de</strong>lo atmosférico operativo con nuevos esquemas <strong>de</strong> asimilación<br />
o parametrizaciones tienen influencia directa en los campos previstos). La<br />
técnica conocida como Mo<strong>de</strong>l Output Statistics (MOS) (Klein and Glahn,<br />
1974) ajusta <strong>de</strong> forma dinámica un mo<strong>de</strong>lo <strong>de</strong> regresión entre los campos<br />
previstos por el mo<strong>de</strong>lo y las observaciones ocurridas, <strong>de</strong> forma que este<br />
mo<strong>de</strong>lo está continuamente actualizándose con las nuevas observaciones y<br />
predicciones disponibles. Este proceso se realiza <strong>de</strong> distintas formas, incluyendo<br />
filtros <strong>de</strong> Kalman (ver Bergman and Delleur, 1985, para más <strong>de</strong>talles).<br />
También han sido propuestas distintas extensiones no lineales <strong>de</strong> estos<br />
mo<strong>de</strong>los utilizando, por ejemplo, re<strong>de</strong>s neuronales (Yuval and Hsieh, 2003;<br />
Marzban, 2003). En este caso, el problema es la necesidad <strong>de</strong> disponer <strong>de</strong><br />
observaciones y salidas <strong>de</strong>l mo<strong>de</strong>lo recientes, que sean representativas <strong>de</strong> la<br />
configuración actual <strong>de</strong>l mismo. Esta imposición limita el número <strong>de</strong> estaciones<br />
sobre el que es posible aplicar las técnicas, ya que no se dispone <strong>de</strong><br />
información en tiempo real para la mayoría <strong>de</strong> las estaciones.<br />
Otro tipo <strong>de</strong> mo<strong>de</strong>los globales aplicados a este problema ha sido el
98 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
Análisis <strong>de</strong> Correlación Canónica (CCA, Canonical Correlation Analysis),<br />
que es una generalización <strong>de</strong> la regresión que tiene en cuenta las <strong>de</strong>pen<strong>de</strong>ncias<br />
espaciales existentes entre los distintos observatorios, tanto lineales<br />
(Bergman and Delleur, 1985), como no lineales (Hsieh, 2001); también<br />
han sido aplicadas recientemente técnicas <strong>de</strong> mo<strong>de</strong>los gráficos probabilísticos<br />
(re<strong>de</strong>s Bayesianas) para la predicción local <strong>de</strong> eventos discretos (ver, por<br />
ejemplo, Cofiño et al., 2002).<br />
El <strong>de</strong>nominador común <strong>de</strong> todos estos métodos es su carácter global (es<br />
<strong>de</strong>cir, se consi<strong>de</strong>ra un único mo<strong>de</strong>lo para analizar todas las situaciones que<br />
puedan presentarse). El método <strong>de</strong> los análogos, o vecinos próximos, supone<br />
una alternativa local a estos mo<strong>de</strong>los.<br />
5.3.2. Técnicas Locales basadas en Análogos<br />
El método <strong>de</strong> análogos introducido por Lorenz (1969) en el marco <strong>de</strong> la<br />
predicción <strong>de</strong> series temporales es una versión particular <strong>de</strong> una metodología<br />
más general llamada técnica <strong>de</strong> vecinos próximos (Nearest Neighbors, NN).<br />
Esta técnica utiliza el “entorno” <strong>de</strong>l patrón atmosférico previsto para entrenar<br />
un mo<strong>de</strong>lo local y obtener una predicción ŷ t . Este entorno viene dado<br />
por una distribución o núcleo <strong>de</strong>finido en el espacio continuo <strong>de</strong> patrones<br />
atmosféricos. En la práctica, el espacio <strong>de</strong> patrones atmosféricos se aproxima<br />
por la muestra aleatoria <strong>de</strong> patrones proporcionada por un re-análisis<br />
suficientemente largo (ver Sec. 2.7.3). Por ejemplo, utilizando ERA-15 se<br />
dispone <strong>de</strong> aproximadamente 5500 patrones atmosféricos diarios para aproximar<br />
el espacio <strong>de</strong> configuraciones atmosféricas. De esta forma, el núcleo se<br />
transforma en un vecindario en el nuevo espacio discreto. Por tanto, los mo<strong>de</strong>los<br />
locales se entrenan en base al conjunto <strong>de</strong> patrones atmosféricos más<br />
cercanos al patrón previsto. Este conjunto se <strong>de</strong>nomina conjunto <strong>de</strong> análogos<br />
y está formado por los k días más próximos al patrón previsto en la base<br />
<strong>de</strong> datos <strong>de</strong>l re-análisis (k nearest neighbors, k-NN). La Fig. 5.8 muestra un<br />
esquema con las componentes fundamentales <strong>de</strong> este tipo <strong>de</strong> algoritmos.<br />
En esta figura pue<strong>de</strong> observarse que es necesaria una base <strong>de</strong> datos con<br />
los patrones atmosféricos y otra con los registros históricos <strong>de</strong> la climatología<br />
local. El algoritmo parte <strong>de</strong> una predicción numérica <strong>de</strong>l patrón atmosférico<br />
previsto, y obtiene una predicción local para los observatorios disponibles.<br />
Las zonas sombreadas representan las componentes <strong>de</strong>l algoritmo implicadas<br />
en la fase operativa <strong>de</strong> obtención <strong>de</strong> predicciones locales.<br />
Algunas aplicaciones <strong>de</strong> este método para la predicción <strong>de</strong> anomalías<br />
climáticas (ver Zorita and von Storch, 1999; Wilby and Wigley, 1997, y sus<br />
referencias) y para la predicción a corto plazo (ver p.e., van <strong>de</strong>n Dool, 1989)<br />
se han presentado en la literatura. En general, se ha <strong>de</strong>mostrado que el método<br />
<strong>de</strong> análogos funciona tan bien como otras técnicas más complicadas <strong>de</strong><br />
downscaling (ver, por ejemplo, Zorita and von Storch, 1999), indicando que<br />
estos métodos <strong>de</strong> “hombre pobre” son alternativas eficientes para diversos<br />
problemas <strong>de</strong> downscaling.
5.3. TÉCNICAS HÍBRIDAS (DOWNSCALING ESTADÍSTICO) 99<br />
ACM FORECAST<br />
1979<br />
1993<br />
...<br />
ATMOSPHERIC<br />
PATTERNS<br />
DATABASE<br />
ERA15<br />
reanalisys<br />
1979-1993<br />
ECMWF<br />
operative mo<strong>de</strong>l<br />
Ensemble of<br />
analog dates<br />
d 1 , ..., d k<br />
1979<br />
...<br />
INM primary<br />
stationÕs network<br />
Estimation: y<br />
1993<br />
LOCAL CLIMATE<br />
RECORDS DATABASE<br />
Figura 5.8: Esquema <strong>de</strong>l algoritmo estándar <strong>de</strong> downscaling por análogos (k-NN).<br />
5.3.3. Comparación <strong>de</strong> Técnicas Estándar en el Corto Plazo<br />
En esta sección se <strong>de</strong>scriben los resultados <strong>de</strong> un experimento llevado a<br />
cabo para comparar entre sí los métodos <strong>de</strong>scritos en las secciones anteriores<br />
aplicados a la predicción a corto plazo. Dado que uno <strong>de</strong> los mo<strong>de</strong>los a<br />
comparar es la regresión lineal se ha <strong>de</strong>cidido seleccionar la variable más<br />
“normal” <strong>de</strong> las que se dispone: la racha máxima diaria <strong>de</strong> viento (Wind).<br />
Los métodos son aplicados para obtener un pronóstico probabilístico <strong>de</strong>l<br />
evento “Wind > 50km/h”.<br />
Se han consi<strong>de</strong>rado las salidas <strong>de</strong>l mo<strong>de</strong>lo operativo <strong>de</strong>l ECMWF con un<br />
alcance <strong>de</strong> 1 día para los meses Diciembre, Enero y Febrero <strong>de</strong>l año 1998.<br />
Obsérvese que no existe solapamiento con los 15 años <strong>de</strong> re-análisis <strong>de</strong> ERA-<br />
15 (1979-1993) que se utilizan conjuntamente con observaciones históricas<br />
<strong>de</strong> ese período para entrenar los mo<strong>de</strong>los. Se probaron diferentes estaciones<br />
<strong>de</strong> la red principal <strong>de</strong> estaciones <strong>de</strong>l INM (ver Fig. 2.8(c)) obteniéndose resultados<br />
similares; en esta sección se ilustran los resultados obtenidos para<br />
Santan<strong>de</strong>r. Una metodología estándar <strong>de</strong> validación para predicciones probabilísticas<br />
es el uso <strong>de</strong> curvas ROC, <strong>de</strong>scrito en el Cap. 4. El cálculo <strong>de</strong><br />
las curvas ROC se basa en la tabla <strong>de</strong> contingencia que viene dada por las<br />
ocurrencias y no ocurrencias reales <strong>de</strong> un evento en función <strong>de</strong> las predichas.<br />
Esta tabla <strong>de</strong> contingencia se caracteriza mediante las llamadas tasa<br />
<strong>de</strong> aciertos o Hit Rate (HIR=p(predicho|ocurrido)) y la tasa <strong>de</strong> falsas alarmas<br />
(FAR=p(predicho|no ocurrido)). El area bajo la curva ROC cuantifica<br />
la pericia <strong>de</strong>l método <strong>de</strong> predicción. Este índice <strong>de</strong> validación tiene ventajas<br />
sobre otros índices, como el Brier Score (BS), pues no <strong>de</strong>pen<strong>de</strong> <strong>de</strong> la<br />
frecuencia <strong>de</strong>l evento (un evento raro o extremo), ya que HIR esta condicionado<br />
a la ocurrencia <strong>de</strong>l evento, mientras que FAR está condicionado a la<br />
no ocurrencia (ver Cap. 4 para más <strong>de</strong>talles sobre validación).
100 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
Con objeto <strong>de</strong> comprobar la importancia <strong>de</strong> la resolución espacial y temporal<br />
<strong>de</strong>l patrón atmosférico, se han realizado las pruebas consi<strong>de</strong>rando una<br />
rejilla global y una local (mostradas en las Fig. 2.9(a) y (c), respectivamente).<br />
En ambos casos se consi<strong>de</strong>ran las diez primeras componentes principales<br />
para representar cada uno <strong>de</strong> los patrones. En las Fig. 5.9(a) y (b) se muestran<br />
las curvas ROC y los Brier Scores (BS) para cuatro algoritmos distintos<br />
consi<strong>de</strong>rando los patrones local y global, respectivamente. Los métodos utilizados<br />
son:<br />
Un mo<strong>de</strong>lo <strong>de</strong> regresión lineal, ajustado para pre<strong>de</strong>cir la probabilidad<br />
<strong>de</strong>l evento Wind > 50km/h en función <strong>de</strong> las componentes principales<br />
<strong>de</strong> los patrones atmosféricos.<br />
Un mo<strong>de</strong>lo <strong>de</strong> red neuronal <strong>de</strong> la forma 10:m:1, don<strong>de</strong> las entradas son<br />
las componentes principales y la salida es la probabilidad <strong>de</strong>l evento.<br />
En este caso se probaron distintos valores <strong>de</strong> m y los mejores resultados<br />
se obtuvieron con m = 5.<br />
La técnica k-NN <strong>de</strong> análogos, utilizando como predictor <strong>de</strong> la probabilidad<br />
<strong>de</strong>l evento la distribución empírica obtenida <strong>de</strong>l conjunto <strong>de</strong><br />
análogos. Se han consi<strong>de</strong>rado cuatro valores diferentes para k (100,<br />
50, 25 y 15), obteniéndose los mejores resultados con k = 50.<br />
1<br />
(a)<br />
1<br />
Metodo<br />
BS<br />
stdBS<br />
local k=NN 0.114 0.029<br />
Lineal 0.146 0.035<br />
Neuronal 0.114 0.035<br />
HIR<br />
HIR<br />
0.5<br />
0<br />
(b)<br />
0.5<br />
Metodo<br />
local k-NN 0.106 0.027<br />
Lineal 0.134 0.029<br />
Neuronal 0.139 0.007<br />
0<br />
0 0.2 0.4 0.6 0.8 1<br />
FAR<br />
Figura 5.9: Curvas ROC y Brier Scores obtenidos para pre<strong>de</strong>cir p(Wind ><br />
50km/h) en Santan<strong>de</strong>r aplicando distintos métodos a los patrones dados por una<br />
rejilla (a) local (Fig. 2.9(c)) y (b) global (Fig. 2.9(a)).<br />
BS<br />
stdBS
5.4. TÉCNICAS BASADAS EN AGRUPAMIENTO Y CLASIFICACIÓN 101<br />
Estos resultados indican que un mo<strong>de</strong>lo lineal es fácilmente mejorable<br />
con un mo<strong>de</strong>lo neuronal. Por otra parte, una técnica local simple <strong>de</strong> vecinos<br />
cercanos (k-NN) permite obtener resultados similares a una técnica complicada<br />
como una red neuronal. En lo referente a la influencia <strong>de</strong> la escala <strong>de</strong>l<br />
patrón en los resultados, se observa que los métodos globales mejoran su<br />
pericia más que el método local cuando se aplican sobre patrones <strong>de</strong>finidos<br />
en rejillas locales, especialmente la red neuronal. Este resultado es lógico<br />
puesto que la reducción <strong>de</strong> escala en el patrón atmosférico tiene un efecto<br />
similar a una localización en los patrones que se utilizan para la predicción.<br />
Una comparación <strong>de</strong> estas técnicas en una escala temporal distinta se pue<strong>de</strong><br />
encontrar en Schoof and Pryor (2001).<br />
Como conclusión se obtiene que los métodos locales basadas en análogos<br />
son las técnicas <strong>de</strong> downscaling estadístico más apropiadas para trabajar<br />
en esta escala temporal (predicción a corto plazo). En la siguiente sección<br />
se presenta un nuevo método <strong>de</strong> downscaling local basado en técnicas <strong>de</strong><br />
agrupamiento y clasificación.<br />
5.4. Técnicas basadas en <strong>Agrupamiento</strong> y Clasificación<br />
Una limitación importante <strong>de</strong> la técnica <strong>de</strong> análogos estándar basada en<br />
k-NN es que consi<strong>de</strong>ra siempre la misma cantidad <strong>de</strong> análogos, sin tener<br />
en cuenta la estructura <strong>de</strong>l espacio don<strong>de</strong> se buscan los vecinos cercanos<br />
<strong>de</strong>l patrón previsto. Este hecho no es consistente con la distribución <strong>de</strong><br />
patrones atmosféricos ya que éstos no siguen una distribución uniforme, sino<br />
que algunas regiones <strong>de</strong>l espacio están más pobladas que otras. La única<br />
regularidad hallada en esta distribución ha sido consi<strong>de</strong>rando una única<br />
estación <strong>de</strong>l año y una dirección radial; en este caso los patrones tienen<br />
una distribución aproximadamente normal (ver Toth, 1991). Por tanto, se<br />
requieren conjuntos <strong>de</strong> análogos <strong>de</strong> tamaño variable que se adapten a las<br />
características <strong>de</strong> la región <strong>de</strong>l espacio don<strong>de</strong> se halle el patrón previsto. Por<br />
otra parte, los algoritmos <strong>de</strong> análogos son computacionalmente costosos, ya<br />
que la búsqueda <strong>de</strong> vecinos involucra el cálculo <strong>de</strong> las distancias <strong>de</strong>l patrón<br />
previsto con todos los patrones <strong>de</strong> la base <strong>de</strong> datos <strong>de</strong> re-análisis.<br />
Los algoritmos <strong>de</strong> agrupamiento proporcionan una solución simple para<br />
estos problemas. Estas técnicas permiten dividir la base <strong>de</strong> datos en grupos<br />
C i , caracterizados por un patrón prototipo v i . Cada grupo resultante pue<strong>de</strong><br />
ser utilizado como conjunto <strong>de</strong> análogos para aquellos patrones que sean<br />
posteriormente clasificados en el grupo (patrones más cercanos a v i , que a<br />
cualquier otro prototipo). Por tanto, el cálculo <strong>de</strong> distancias sólo involucra al<br />
patrón previsto y a los prototipos, lo que reduce significativamente el tiempo<br />
<strong>de</strong> computación. La técnica <strong>de</strong> agrupamiento también resuelve los problemas<br />
causados por las inhomogeneida<strong>de</strong>s <strong>de</strong> la distribución <strong>de</strong> re-análisis, ya<br />
que el número <strong>de</strong> elementos en cada uno <strong>de</strong> los grupos se pue<strong>de</strong> adaptar<br />
automáticamente a la distribución <strong>de</strong> los patrones atmosféricos utilizando<br />
un algoritmo apropiado.
102 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
En la literatura se han aplicado distintas técnicas <strong>de</strong> agrupamiento en<br />
este problema. Por ejemplo, Hughes et al. (1993) <strong>de</strong>scribe una algoritmo <strong>de</strong><br />
downscaling que utiliza una técnica <strong>de</strong> agrupamiento llamada CART (ver<br />
también Zorita et al., 1995). Este algoritmo <strong>de</strong> agrupamiento se basa en un<br />
árbol <strong>de</strong> <strong>de</strong>cisión binario, que se forma dividiendo los valores <strong>de</strong> las variables<br />
<strong>de</strong> entrada (cada uno <strong>de</strong> los valores en un punto <strong>de</strong> rejilla <strong>de</strong> las variables<br />
utilizadas para <strong>de</strong>finir el patrón atmosférico) <strong>de</strong> forma que se obtenga una<br />
separación máxima en la distribución <strong>de</strong> ocurrencia <strong>de</strong>l evento en las hojas<br />
<strong>de</strong>l árbol. Cada nodo terminal <strong>de</strong>l árbol <strong>de</strong> <strong>de</strong>cisión correspon<strong>de</strong> a un grupo.<br />
Esta técnica se ha aplicado <strong>de</strong> forma eficiente a problemas <strong>de</strong> predicción<br />
a largo plazo (en particular, a problemas <strong>de</strong> cambio climático) don<strong>de</strong> los<br />
patrones atmosféricos utilizados tienen baja complejidad (normalmente un<br />
único nivel para una única variable en una rejilla <strong>de</strong> baja resolución: presión<br />
a nivel <strong>de</strong>l mar, altura geopotencial en 500mb, etc.). Por otra parte, estos<br />
problemas requieren un número pequeño <strong>de</strong> clases, dado que sólo requiere<br />
un número más elevado <strong>de</strong> grupos y patrones atmosféricos más complejos,<br />
lo que hace que el proceso <strong>de</strong> construcción <strong>de</strong> árbol binario sea irrealizable<br />
en este caso.<br />
Otra aproximación a este problema ha sido realizada por Cavazos (1997),<br />
aplicando re<strong>de</strong>s auto-organizativas (SOM) como algoritmo <strong>de</strong> agrupamiento,<br />
y consi<strong>de</strong>rando también una aplicación en el medio y largo plazo que requiere<br />
patrones simples y un número reducido <strong>de</strong> grupos. A diferencia <strong>de</strong>l caso<br />
anterior, esta técnica es eficiente para trabajar con un número elevado <strong>de</strong><br />
grupos y con patrones <strong>de</strong> alta dimensión. Sin embargo, este método es una<br />
generalización <strong>de</strong> otro algoritmo <strong>de</strong> agrupamiento más simple (el algoritmo<br />
<strong>de</strong> m-medias), al que aña<strong>de</strong> una restricción para conservar la estructura<br />
topológica <strong>de</strong>l espacio original en el espacio <strong>de</strong> grupos (ver Sec. 3.4). Esta<br />
restricción altera el algoritmo original <strong>de</strong> agrupamiento fijando los grupos<br />
<strong>de</strong> la periferia <strong>de</strong> la distribución a sus vecinos <strong>de</strong>l centro, lo que conlleva a<br />
un <strong>de</strong>cremento <strong>de</strong> la varianza <strong>de</strong> los grupos resultantes y <strong>de</strong> la pericia <strong>de</strong>l<br />
método.<br />
Por tanto, los métodos presentados hasta la fecha no son eficientes para<br />
la predicción a corto plazo. En la siguiente sección se presenta un nuevo<br />
algoritmo <strong>de</strong> downscaling que opera en esta escala <strong>de</strong> tiempo utilizando la<br />
técnica <strong>de</strong> agrupamiento <strong>de</strong> m-medias para seleccionar los grupos <strong>de</strong> patrones<br />
análogos en la base <strong>de</strong> datos <strong>de</strong> re-análisis.<br />
5.4.1. Nuevo Método <strong>de</strong> Downscaling para el Corto Plazo<br />
La Figura 5.10 muestra esquemáticamente la estructura <strong>de</strong> la técnica<br />
<strong>de</strong> downscaling propuesta. Como una primera etapa <strong>de</strong> preproceso, se realiza<br />
el agrupamiento <strong>de</strong> la base <strong>de</strong> datos <strong>de</strong> re-análisis utilizando el método<br />
<strong>de</strong> m-medias (los <strong>de</strong>talles <strong>de</strong> este proceso ya han sido <strong>de</strong>scritos en la Sec.<br />
3.3.2). Esta etapa permite prescindir <strong>de</strong> los datos <strong>de</strong> re-análisis en el resto<br />
<strong>de</strong>l proceso, pues éstos son reemplazados por un número <strong>de</strong>terminado
5.4. TÉCNICAS BASADAS EN AGRUPAMIENTO Y CLASIFICACIÓN 103<br />
1979<br />
1993<br />
...<br />
ATMOSPHERIC<br />
PATTERNS<br />
DATABASE<br />
ERA15<br />
reanalisys<br />
1979-1993<br />
ACM FORECAST<br />
ECMWF<br />
operative mo<strong>de</strong>l<br />
CLUSTERING Find Cluster:<br />
C 1 , ..., C m Ci<br />
Estimation:<br />
y 1 , ..., y m<br />
Inference: y i<br />
1979<br />
...<br />
INM primary<br />
stationÕs network<br />
1993<br />
LOCAL CLIMATE<br />
RECORDS DATABASE<br />
Figura 5.10: Esquema <strong>de</strong>l algoritmo <strong>de</strong> downscaling por agrupamiento. Es necesaria<br />
una base <strong>de</strong> datos <strong>de</strong> patrones atmosféricos y un registro histórico <strong>de</strong> <strong>de</strong> la<br />
climatología local <strong>de</strong> un conjunto <strong>de</strong> estaciones.<br />
<strong>de</strong> grupos C 1 , . . .,C m con sus correspondientes prototipos v 1 , . . .,v m . En<br />
la fase operativa, las únicas distancias que es necesario calcular para obtener<br />
el conjunto <strong>de</strong> análogos <strong>de</strong> un patrón <strong>de</strong> predicción dado x t , son entre<br />
x t y v i , i = 1, . . .,m. Esto supone una reducción sustancial <strong>de</strong> la carga<br />
computacional <strong>de</strong>l algoritmo.<br />
Una vez calculados los grupos C k = {x i1 , . . .,x iq(k) }, don<strong>de</strong> q(k) es el<br />
número <strong>de</strong> patrones <strong>de</strong>l grupo k-ésimo e i 1 , . . .,i q(k) se refieren a las fechas <strong>de</strong><br />
los días en el período <strong>de</strong> re-análisis, se pue<strong>de</strong> obtener una predicción probabilística<br />
local correspondiente a cada uno <strong>de</strong> los grupos para una variable y y<br />
una estación s dadas. Esta predicción se pue<strong>de</strong> obtener a partir <strong>de</strong> la función<br />
<strong>de</strong> probabilidad empírica <strong>de</strong> las observaciones históricas {y s i 1<br />
, . . .,y s i q(k)<br />
}:<br />
P s<br />
i = P(y s > u|C i ) = #{ys i j<br />
> u; j = 1, . . .,q(i)}<br />
. (5.5)<br />
q(i)<br />
Sin embargo, es bien sabido que esta estimación es inestable, especialmente<br />
para grupos <strong>de</strong> tamaño pequeño q(i). Una <strong>de</strong> las alternativas propuestas para<br />
sortear esta limitación es la técnica <strong>de</strong> estimación <strong>de</strong> la función <strong>de</strong> <strong>de</strong>nsidad<br />
utilizando una mezcla <strong>de</strong> núcleos continuos (Hastie et al., 2001). En este<br />
caso, cada observación no se consi<strong>de</strong>ra como un único número, sino como una<br />
función núcleo centrado en el punto (normalmente un núcleo Gaussiano).<br />
φ λ (x, x 0 ) = 1<br />
2πλ 2exp − (x − x 0) 2<br />
.<br />
2λ<br />
El uso <strong>de</strong> esta técnica suaviza la estimación ya que la suma <strong>de</strong> núcleos<br />
Gaussianos tiene el efecto <strong>de</strong> una convolución entre un filtro (el núcleo) y
104 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
la distribución empírica. En este caso, una estimación <strong>de</strong> la probabilidad se<br />
obtiene con la integral <strong>de</strong> la función <strong>de</strong> <strong>de</strong>nsidad:<br />
f(y s ) = 1<br />
q(i)<br />
∑<br />
φ λ (y s , yi s q(i)<br />
j<br />
). (5.6)<br />
j=1<br />
De esta ecuación po<strong>de</strong>mos obtener diferentes estadísticos para la distribución.<br />
En particular, se pue<strong>de</strong> obtener fácilmente una estimación <strong>de</strong> (5.5)<br />
para los diferentes umbrales <strong>de</strong> la variable (ver Cofiño et al., 2001a, para<br />
más <strong>de</strong>talles).<br />
El algoritmo propuesto es computacionalmente eficiente, ya que su funcionamiento<br />
operativo sólo requiere la selección <strong>de</strong>l grupo representativo<br />
para el patrón <strong>de</strong> predicción dado por el mo<strong>de</strong>lo numérico (ver la zona<br />
sombreada <strong>de</strong> la Figura 5.10). Sin embargo, el principal inconveniente es la<br />
reducción <strong>de</strong> varianza y resolución <strong>de</strong> la predicción, <strong>de</strong>bido a la cuantificación<br />
y a los efectos <strong>de</strong> bor<strong>de</strong> asociados (todos los patrones asociados a un mismo<br />
grupo C k tienen asociada la misma predicción Pk s , in<strong>de</strong>pendientemente <strong>de</strong><br />
su posición relativa cercana al centro o al bor<strong>de</strong> <strong>de</strong>l grupo). Por tanto, el<br />
método sólo genera m predicciones diferentes para una estación dada.<br />
Para suavizar este problema se ha consi<strong>de</strong>rado una versión pon<strong>de</strong>rada<br />
<strong>de</strong>l algoritmo, don<strong>de</strong> la predicción se obtiene a partir <strong>de</strong> un número m dado<br />
<strong>de</strong> grupos vecinos:<br />
∑ wc=1<br />
d(c)P<br />
ŷt s t(c)<br />
s = ∑ wc=1 , (5.7)<br />
d(c)<br />
don<strong>de</strong> t(c) es el índice <strong>de</strong>l c-ésimo prototipo más cercano a x t , d(c) es la<br />
distancia <strong>de</strong> v t (c) a x, y p s t(c)<br />
es la estimación <strong>de</strong> la probabilidad obtenida<br />
para el grupo t(c) usando (5.6). En lugar <strong>de</strong> asignar la misma estimación para<br />
todos los patrones en un grupo, ahora se consi<strong>de</strong>ra una suma pon<strong>de</strong>rada <strong>de</strong><br />
las estimaciones asociadas a los grupos más cercanos a un patrón dado. Esta<br />
modificación también resuelve el problema <strong>de</strong> la reducción <strong>de</strong> resolución,<br />
ya que ahora las predicciones no se reducen únicamente a m casos (ver<br />
Gutiérrez et al., 2004a, para más <strong>de</strong>talles).<br />
5.4.2. Validación y Comparación con Otros Métodos<br />
Con objeto <strong>de</strong> validar y obtener la pericia <strong>de</strong>l mo<strong>de</strong>lo para pre<strong>de</strong>cir la<br />
precipitación (Precip) y racha máxima <strong>de</strong> viento (Wind) diarias, se consi<strong>de</strong>rará<br />
el método estándar <strong>de</strong> análogos k-NN como mo<strong>de</strong>lo <strong>de</strong> referencia. En<br />
el análisis se comparan distintos valores <strong>de</strong> los parámetros <strong>de</strong> estos algoritmos.<br />
Por una parte el algoritmo <strong>de</strong> análogos (<strong>de</strong>notado Analog) sólo <strong>de</strong>pen<strong>de</strong><br />
<strong>de</strong>l número <strong>de</strong> análogos consi<strong>de</strong>rado para hacer la predicción (k). Por otra<br />
parte, el algoritmo <strong>de</strong> agrupamiento pon<strong>de</strong>rado (<strong>de</strong>notado como WCluster)<br />
<strong>de</strong>pen<strong>de</strong> <strong>de</strong>l número <strong>de</strong> grupos (m) y <strong>de</strong>l número <strong>de</strong> vecinos pon<strong>de</strong>rados en<br />
la predicción (w). Como la base <strong>de</strong> re-análisis contiene aproximadamente<br />
5000 patrones, se compararán los resultados obtenidos con parámetros k y
5.4. TÉCNICAS BASADAS EN AGRUPAMIENTO Y CLASIFICACIÓN 105<br />
m que cumplan 5000/m = k (así el número promedio <strong>de</strong> patrones en cada<br />
grupo coincidirá con el número <strong>de</strong> análogos consi<strong>de</strong>rado). A<strong>de</strong>más, para<br />
eliminar la reducción <strong>de</strong> varianza que conlleva el proceso <strong>de</strong> pon<strong>de</strong>ración se<br />
mantiene constante la razón m/w, <strong>de</strong> forma que se incremente el número <strong>de</strong><br />
grupos si también se incrementa el número <strong>de</strong> elementos que se utilizan en<br />
la pon<strong>de</strong>ración.<br />
Se han consi<strong>de</strong>rado salidas <strong>de</strong>l mo<strong>de</strong>lo operativo <strong>de</strong>l ECMWF durante<br />
el periodo 1998-1999, con un alcance <strong>de</strong> 1 a 5 días, <strong>de</strong> forma que no exista<br />
solapamiento con los 15 años <strong>de</strong> re-análisis <strong>de</strong> ERA-15 (1979-1993). Se consi<strong>de</strong>ra<br />
la red principal <strong>de</strong> estaciones <strong>de</strong>l INM (ver Fig. 2.8(c)); la predicción<br />
sobre cada estación se obtiene <strong>de</strong> forma in<strong>de</strong>pendiente, promediando los parámetros<br />
<strong>de</strong> validación respectivos en los resultados finales. A<strong>de</strong>más <strong>de</strong> las<br />
medias anuales (período 1998-99), algunos <strong>de</strong> los resultados son <strong>de</strong>sglosados<br />
para cada una <strong>de</strong> las estaciones <strong>de</strong>l año: Invierno (Diciembre, Enero y Febrero:<br />
DEF), Primavera (MAM), Verano (JJA) y Otoño (SON). Se consi<strong>de</strong>ran<br />
distintos eventos binarios dados por los umbrales Precip > 0.1mm, 10mm,<br />
y 20mm, y Wind > 50km/h y 80km/h para obtener las predicciones. Una<br />
metodología estándar <strong>de</strong> validación para este tipo <strong>de</strong> predicciones probabilísticas<br />
es el uso <strong>de</strong> curvas ROC, <strong>de</strong>scrito en el Cap. 4 y en la Sec. 5.3.3.<br />
El area A bajo la curva ROC cuantifica la pericia <strong>de</strong>l método <strong>de</strong> predicción;<br />
el valor 2A − 1 se <strong>de</strong>fine como RSA (ROC Skill Area), y está normalizado<br />
en [0, 1] (el valor 1 se alcanza en una predicción perfecta). Como ya se ha<br />
mencionado, este índice tiene ventajas sobre otros parámetros <strong>de</strong> validación,<br />
como el Brier Score (BS), pues no <strong>de</strong>pen<strong>de</strong> <strong>de</strong> la frecuencia <strong>de</strong>l evento (un<br />
evento raro o extremo).<br />
Al igual que en la comparación realizada en la Sec. 5.3.3, con objeto <strong>de</strong><br />
comprobar la eficiencia <strong>de</strong> los métodos para distintas <strong>de</strong>finiciones <strong>de</strong> patrones<br />
atmosféricos (rejillas <strong>de</strong> distinta amplitud y resolución y escalas temporales<br />
diferentes) se realizan los experimentos en tres mo<strong>de</strong>los distintos mostrados<br />
en la Figura 2.9, que correspon<strong>de</strong>n a tres mo<strong>de</strong>los <strong>de</strong> patrones asociados<br />
a una rejilla global y un instante <strong>de</strong> tiempo (M1), una rejilla que cubre la<br />
Península Ibérica y una ventana <strong>de</strong> tiempo <strong>de</strong> cubre el intervalo <strong>de</strong> predicción<br />
(M2) y una rejilla local con toda la información temporal disponible (M3).<br />
Se han utilizado cuatro valores diferentes para k (100, 50, 25 y 15) y cuatro<br />
valores asociados para m (50, 100, 250, 300, respectivamente). Los mejores<br />
resultados se muestran en las Tablas 5.1 y 5.2 y fueron obtenidos con el<br />
mo<strong>de</strong>lo M3 (el mo<strong>de</strong>lo local <strong>de</strong> la Fig. 2.9(c)) para un número intermedio<br />
<strong>de</strong> elementos k = 50 y m = 100 (en este caso w = 1).<br />
También se consi<strong>de</strong>raron valores diferentes para los parámetros w y m<br />
<strong>de</strong>l método <strong>de</strong> agrupamiento pon<strong>de</strong>rado. La Figura 5.11 muestra el comportamiento<br />
<strong>de</strong>l método pon<strong>de</strong>rado en función <strong>de</strong> sus parámetros; en todos los<br />
casos, la proporción m/w se mantiene cerca <strong>de</strong> 100 (todos ellos son alternativas<br />
al algoritmo <strong>de</strong> m-medias con m = 100). En este caso, una elección<br />
conveniente <strong>de</strong> valores se da para la configuración m = 400 y w = 4 con el<br />
algoritmo <strong>de</strong> m-medias pon<strong>de</strong>radas.
106 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
> 0.1mm > 10.0mm > 20.0mm<br />
M1 M2 M3 M1 M2 M3 M1 M2 M3<br />
D+1 Analog 0.647 0.750 0.791 0.602 0.728 0.776 0.480 0.643 0.673<br />
Cluster 0.538 0.682 0.744 0.501 0.627 0.710 0.427 0.583 0.681<br />
WCluster 0.597 0.733 0.783 0.574 0.715 0.769 0.526 0.685 0.781<br />
D+2 Analog 0.633 0.727 0.771 0.586 0.689 0.737 0.474 0.606 0.647<br />
Cluster 0.523 0.669 0.716 0.478 0.602 0.667 0.408 0.535 0.614<br />
WCluster 0.588 0.711 0.763 0.571 0.685 0.736 0.504 0.647 0.729<br />
D+3 Analog 0.572 0.693 0.734 0.572 0.674 0.694 0.467 0.602 0.624<br />
Cluster 0.449 0.640 0.678 0.449 0.576 0.631 0.372 0.513 0.591<br />
WCluster 0.542 0.680 0.726 0.542 0.668 0.706 0.489 0.632 0.675<br />
Tabla 5.1: Roc Skill Area (RSA) para la precipitación usando los mo<strong>de</strong>los M1,<br />
M2 y M3 para un alcance entre 1 y 3 días (D + 1, D + 2 y D + 3). Se muestran<br />
resultados para los tres métodos Analog (k-NN con k = 50), Cluster (m-medias<br />
con m = 100), y WCluster m-medias pon<strong>de</strong>radas con m = 400 y w = 4).<br />
La Tabla 5.1 muestra los valores <strong>de</strong>l RSA promediados anual y espacialmente<br />
para las 98 estaciones, para el caso <strong>de</strong> la precipitación. De forma<br />
similar, la Tabla 5.2 muestra los resultados para el caso <strong>de</strong>l viento. Por otra<br />
parte, las Fig. 5.12 y 5.13 comparan las curvas ROC y los índices RSA correspondientes<br />
a las configuraciones óptimas <strong>de</strong> los algoritmos para un alcance<br />
<strong>de</strong> un día (D+1).<br />
> 50km/h > 80km/h<br />
M1 M2 M3 M1 M2 M3<br />
D+1 Analog 0.576 0.702 0.721 0.500 0.556 0.511<br />
Cluster 0.453 0.609 0.648 0.428 0.511 0.512<br />
WCluster 0.526 0.671 0.716 0.524 0.670 0.697<br />
D+2 Analog 0.574 0.682 0.707 0.491 0.598 0.590<br />
Cluster 0.421 0.583 0.630 0.384 0.521 0.549<br />
WCluster 0.514 0.653 0.708 0.472 0.703 0.706<br />
D+3 Analog 0.562 0.657 0.668 0.476 0.552 0.572<br />
Cluster 0.428 0.567 0.605 0.359 0.497 0.548<br />
WCluster 0.508 0.630 0.656 0.468 0.652 0.620<br />
Tabla 5.2: Roc Skill Area (RSA) para la racha máxima <strong>de</strong> viento. –Ver <strong>de</strong>talles en<br />
el pie <strong>de</strong> la Tabla 5.1.–<br />
A partir <strong>de</strong> estos resultados se pue<strong>de</strong> concluir lo siguiente:<br />
(a) Como era <strong>de</strong> esperar, el método estándar <strong>de</strong> análogos mejora claramente<br />
al método <strong>de</strong> agrupamiento básico;
5.4. TÉCNICAS BASADAS EN AGRUPAMIENTO Y CLASIFICACIÓN 107<br />
0.8<br />
RSA<br />
0.7<br />
0.6<br />
1 2 4 8<br />
w<br />
Wind>50Km/h<br />
Wind>80Km/h<br />
Precip>0.1mm<br />
Precip>20mm<br />
Figura 5.11: Roc skill area (RSA) para precipitación (eventos Precip > 0.1mm y<br />
Precip > 20mm) y racha máxima <strong>de</strong> viento (eventos Wind > 50km/h y Wind ><br />
80km/h) usando la estimación dada en (5.7) con w variando <strong>de</strong>s<strong>de</strong> 1 a 8 y m =<br />
100 ∗ w (con objeto <strong>de</strong> mantener un número promedio <strong>de</strong> elementos cercano a 50).<br />
(b) el método <strong>de</strong> agrupamiento pon<strong>de</strong>rado mejora al método <strong>de</strong> análogos<br />
para umbrales altos <strong>de</strong> precipitaciones y rachas máximas (eventos<br />
extremos: Precip > 20mm, Wind > 80km/h). Para eventos no extremos,<br />
ambos métodos muestran resultados similares. La Figura 5.14<br />
muestra los índices RSA frente a la frecuencia climatológica <strong>de</strong> los<br />
cuatro eventos diferentes en las 98 estaciones consi<strong>de</strong>radas en este estudio.<br />
Esta figura muestra la relación entre el skill <strong>de</strong> la predicción y<br />
la frecuencia <strong>de</strong> la observación <strong>de</strong>l evento en una estación. En el caso<br />
<strong>de</strong> eventos extremos, po<strong>de</strong>mos ver que, a partir <strong>de</strong> las Figuras 5.14<br />
(b) y (d) como el skill <strong>de</strong> la predicción tien<strong>de</strong> a ser menor en aquellas<br />
estaciones en las que la frecuencia <strong>de</strong>l evento es más pequeña (cuanto<br />
más raro es un evento peor pericia tendremos en nuestra predicción).<br />
Sin embargo, po<strong>de</strong>mos ver que, en esta situación, la pericia <strong>de</strong>l downscaling<br />
por agrupamiento pon<strong>de</strong>rado (WCl) es mayor que la <strong>de</strong>l método<br />
estándar <strong>de</strong> los k-vecinos.<br />
(c) Los mejores resultados se obtienen con el mo<strong>de</strong>lo M3, indicando que<br />
la <strong>de</strong>finición óptima para el estado <strong>de</strong> la atmósfera, es un patrón 4D<br />
restringido a un dominio geográfico local; y<br />
(d) la pericia <strong>de</strong>cae con el alcance <strong>de</strong> la predicción usada en la entrada<br />
<strong>de</strong>l downscaling. La Figura 5.15 muestra que este <strong>de</strong>caimiento es más<br />
pronunciado para un alcance <strong>de</strong> 4 días, mostrando un horizonte para<br />
la pericia <strong>de</strong> las predicciones meteorológicas <strong>de</strong> corto alcance.<br />
Los resultados anteriores están basados en un promedio temporal y espacial<br />
que podría ocultar algún aspecto importante <strong>de</strong> las predicciones para<br />
diferentes regiones <strong>de</strong> la Península Ibérica y para diferentes estaciones <strong>de</strong>l<br />
año. Por esta razón, se ha realizado una validación adicional para analizar la
108 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
1<br />
1<br />
1<br />
0.8<br />
0.8<br />
0.8<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
0 0.5 FAR 1<br />
1<br />
(a)<br />
Precip > 0.1mm<br />
Analog (0.647)<br />
WCluster (0.597)<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
0<br />
0 0.5 FAR 1<br />
1<br />
(c)<br />
Precip > 0.1mm<br />
Analog (0.750)<br />
WCluster (0.733)<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
Analog (0.791)<br />
WCluster (0.783)<br />
0<br />
0 0.5 FAR 1<br />
1<br />
(e)<br />
Precip > 0.1mm<br />
0.8<br />
0.8<br />
0.8<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
(b)<br />
Precip > 20mm<br />
Analog (0.480)<br />
WCluster (0.526)<br />
0<br />
0 0.5 FAR 1<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
(d)<br />
Precip > 20mm<br />
Analog (0.643)<br />
WCluster (0.685)<br />
0<br />
0 0.5 FAR 1<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
(f)<br />
Precip > 20mm<br />
Analog (0.773)<br />
WCluster (0.781)<br />
0<br />
0 0.5 FAR 1<br />
Figura 5.12: Curvas ROC y RSA (entre corchetes) para precipitación (eventos<br />
Precip > 0.1mm y Precip > 20mm) usando k-NN con k = 50 (etiqueta Analog), y<br />
m-medias pon<strong>de</strong>radas con m = 400 y w = 4 (etiqueta WCluster) para los mo<strong>de</strong>los:<br />
(a)-(b) M1, (c)-(d) M2, y (e)-(f) M3.<br />
1<br />
1<br />
1<br />
0.8<br />
0.8<br />
0.8<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
(a)<br />
Wind > 50 Km/h<br />
Analog (0.576)<br />
WCluster (0.526)<br />
0<br />
0 0.5 FAR 1<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
(c)<br />
Wind > 50 Km/h<br />
Analog (0.702)<br />
WCluster (0.671)<br />
0<br />
0 0.5 FAR 1<br />
HIR<br />
0.6<br />
0.4<br />
0.2<br />
(e)<br />
Wind > 50 Km/h<br />
Analog (0.721)<br />
WCluster (0.716)<br />
0<br />
0 0.5 FAR 1<br />
1<br />
1<br />
1<br />
0.8<br />
0.8<br />
0.8<br />
0.6<br />
0.6<br />
0.6<br />
HIR<br />
0.4<br />
0.2<br />
(b) 0.4<br />
(d) 0.4<br />
(f)<br />
Wind > 80 Km/h Wind > 80 Km/h Wind > 80 Km/h<br />
Analog (0.500) 0.2 Analog (0.556) 0.2 Analog (0.511)<br />
WCluster (0.524)<br />
WCluster (0.670)<br />
WCluster (0.697)<br />
0<br />
0 0.5 1<br />
FAR<br />
HIR<br />
0<br />
0 0.5 1<br />
FAR<br />
HIR<br />
0<br />
0 0.5 1<br />
FAR<br />
Figura 5.13: Curvas ROC y RSA para Racha Máxima <strong>de</strong> Viento (eventos Wind ><br />
50km/h y Wind > 80km/h). –Ver <strong>de</strong>talles en el pie <strong>de</strong> la Figura. 5.12.–
5.4. TÉCNICAS BASADAS EN AGRUPAMIENTO Y CLASIFICACIÓN 109<br />
Prob Clim.<br />
0.08<br />
0.06<br />
0.04<br />
(b)<br />
Analog (k=50)<br />
WCl (m=100, w=5)<br />
Prob Clim.<br />
0.1<br />
0.08<br />
0.06<br />
0.04<br />
(d)<br />
Analog (k=50)<br />
WCl (m=100, w=5)<br />
0.02<br />
0.02<br />
0<br />
-0.5 0<br />
RSA<br />
0.5 1<br />
0<br />
- 0.5 0<br />
RSA<br />
0.5 1<br />
Prob Clim.<br />
0.6<br />
0.4<br />
(a)<br />
Analog (k=50)<br />
WCl (m=100, w=5)<br />
Prob Clim.<br />
0.4<br />
0.2<br />
(c)<br />
Analog (k=50)<br />
WCl (m=100, w=5)<br />
0.2<br />
0<br />
0.4 0.6 0.8 1<br />
RSA<br />
0<br />
0.2 0.4 0.6 0.8 1<br />
RSA<br />
Figura 5.14: Dibujos <strong>de</strong> dispersión <strong>de</strong> los valores <strong>de</strong>l RSA frente a la frecuencia<br />
climatológica <strong>de</strong>l evento para las 98 estaciones climatológicas: (a) Precip > 0.1mm,<br />
(b) Precip > 20mm, (c) Wind < 50km/h, y (d) Wind < 80km/h.<br />
0.8<br />
0.7<br />
RSA<br />
0.6<br />
0.5<br />
0.4<br />
Analog (0.1mm)<br />
WClus (0.1mm)<br />
Analog (20mm)<br />
WClus (20mm)<br />
1 2 3 4<br />
lead time (days)<br />
5<br />
Figura 5.15: RSA frente al alcance <strong>de</strong> la predicción para la precipitación (eventos<br />
Precip > 0.1mm y Precip > 20mm) usando el método <strong>de</strong> análogos con k = 50 y el<br />
método <strong>de</strong> agrupamiento con m = 400 y w = 4. Para un alcance <strong>de</strong> cuatro dias, se<br />
aprecia un <strong>de</strong>caimiento <strong>de</strong>l skill más pronunciado (se ha utilizado el mo<strong>de</strong>lo M2).
110 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO<br />
distribución espacial <strong>de</strong> los resultados. En particular, la Tabla 5.3 muestra<br />
los valores RSA para las once cuencas hidrográficas en la Península y Baleares<br />
(ver Figura 2.8(b)). Entre las diferentes estaciones, los peores resultados<br />
se dan en Verano en la mayor parte <strong>de</strong> las cuencas. Este hecho pue<strong>de</strong> ser <strong>de</strong>bido<br />
a que la precipitación en verano es <strong>de</strong>bida fundamentalmente a procesos<br />
convectivos que son más difíciles <strong>de</strong> pre<strong>de</strong>cir dado que su escala espacial es<br />
menor que la <strong>de</strong> los frentes que producen lluvia en otras estaciones <strong>de</strong>l año.<br />
En la Figura 5.16 se muestra los resultados diarios correspondientes al<br />
período Septiembre-Noviembre <strong>de</strong> 1998 para la precipitación. Las diferencias<br />
entre estos métodos se caracterizan mediante un diagrama <strong>de</strong> cajas que<br />
muestra los percentiles sobre las 98 estaciones para las pericias <strong>de</strong> cada uno<br />
<strong>de</strong> los días.<br />
BS(WCluster) - BS(Analog)<br />
0.4<br />
0.2<br />
0<br />
-0.2<br />
-0.4<br />
(a) Precip > 0.1mm<br />
-0.6<br />
BS(WCluster) - BS(Analog)<br />
0.4<br />
0.2<br />
0<br />
-0.2<br />
(b) Precip > 10mm<br />
-0.4<br />
1 10 20 30 40 50 60 70 80 90<br />
Day<br />
Figura 5.16: Diagramas <strong>de</strong> terciles para las diferencias <strong>de</strong> Brier Score (BS) entre<br />
los métodos <strong>de</strong> agrupamiento pon<strong>de</strong>rado (WClust con m = 400 y w = 4) y el<br />
método <strong>de</strong> análogos estándar (k-NN con k = 50) para un periodo <strong>de</strong> 90 días (SON,<br />
1998). Cada día, las cajas representan los terciles <strong>de</strong> los índices <strong>de</strong> las 98 estaciones<br />
y las rectas muestran los valores extremos.<br />
Por último, el término “corto plazo” se refiere al hecho <strong>de</strong> que las salidas<br />
<strong>de</strong> los mo<strong>de</strong>los <strong>de</strong> predicción por conjuntos (ensembles) no se usan. La pericia<br />
<strong>de</strong> la predicción <strong>de</strong>cae rápidamente el cuarto día (<strong>de</strong> forma equivalente al <strong>de</strong><br />
los mo<strong>de</strong>los numéricos). Sin embargo el método es susceptible <strong>de</strong> ser aplicado<br />
a la salida <strong>de</strong> la predicción numérica por conjuntos, ya que cada uno <strong>de</strong> los<br />
miembros <strong>de</strong>l ensemble correspon<strong>de</strong>ría a uno <strong>de</strong> los grupos y, por tanto, el<br />
conjunto completo <strong>de</strong>finiría una distribución sobre los grupos, obteniendo<br />
así un mecanismo natural para trabajar con predicciones probabilísticas.<br />
Esta aplicación se <strong>de</strong>talla en el siguiente capítulo.
5.4. TÉCNICAS BASADAS EN AGRUPAMIENTO Y CLASIFICACIÓN 111<br />
> 0.1mm > 20mm<br />
Wi Sp Su Fa Wi Sp Su Fa<br />
Segura kNN 0.831 0.779 0.415 0.808 0.832 0.818 − 0.783<br />
WCl 0.836 0.800 0.476 0.831 0.930 0.977 − 0.829<br />
Baleares kNN 0.717 0.804 0.600 0.726 0.625 0.826 − 0.662<br />
WCl 0.722 0.794 0.624 0.719 0.750 0.831 − 0.774<br />
Catalana kNN 0.808 0.734 0.685 0.727 0.772 0.582 0.305 0.758<br />
WCl 0.817 0.739 0.662 0.714 0.774 0.611 0.512 0.728<br />
Duero kNN 0.800 0.824 0.743 0.818 0.514 0.623 0.594 0.507<br />
WCl 0.789 0.819 0.751 0.808 0.633 0.654 0.676 0.585<br />
Ebro kNN 0.730 0.742 0.648 0.742 0.816 0.676 0.376 0.724<br />
WCl 0.744 0.745 0.674 0.744 0.798 0.808 0.517 0.775<br />
Guadalq. kNN 0.913 0.856 0.556 0.836 0.894 0.584 0.838 0.827<br />
WCl 0.916 0.863 0.701 0.841 0.940 0.661 0.951 0.909<br />
Guadiana kNN 0.842 0.837 0.713 0.833 0.799 0.868 0.258 0.781<br />
WCl 0.842 0.852 0.889 0.857 0.821 0.825 0.378 0.812<br />
Levante kNN 0.855 0.801 0.688 0.794 0.810 0.746 0.851 0.474<br />
WCl 0.873 0.798 0.690 0.805 0.916 0.788 0.948 0.604<br />
Norte kNN 0.869 0.852 0.740 0.819 0.807 0.734 0.741 0.718<br />
WCl 0.870 0.844 0.751 0.806 0.842 0.754 0.835 0.751<br />
Sur kNN 0.815 0.804 0.698 0.783 0.731 0.428 0.892 0.666<br />
WCl 0.840 0.823 0.716 0.790 0.813 0.640 0.964 0.720<br />
Tajo kNN 0.884 0.849 0.725 0.874 0.982 0.525 0.922 0.394<br />
WCl 0.879 0.845 0.741 0.880 0.980 0.885 0.946 0.668<br />
Tabla 5.3: Roc Skill Area (RSA) para la precipitación usando el método <strong>de</strong> análogos<br />
con k = 50 (etiqueta kNN), y <strong>de</strong> agrupamiento pon<strong>de</strong>rado con m = 400 y w = 4<br />
(etiqueta WCl). El signo “-” indica la falta <strong>de</strong> datos <strong>de</strong> validación para ese periodo.
112 5. PREDICCIÓN LOCAL A CORTO PLAZO. TÉCNICAS DE AGRUPAMIENTO
CAPÍTULO 6<br />
Predicción por Conjuntos a Plazo Medio y<br />
Estacional. Re<strong>de</strong>s Auto-Organizativas<br />
6.1. Introducción<br />
La no linealidad <strong>de</strong> los mo<strong>de</strong>los <strong>de</strong> circulación, y su consiguiente sensibilidad<br />
a las distintas fuentes <strong>de</strong> incertidumbre (el estado inicial <strong>de</strong> la atmósfera,<br />
la no exactitud <strong>de</strong>l mo<strong>de</strong>lo numérico, etc.), impone una limitación al alcance<br />
<strong>de</strong> las predicciones <strong>de</strong>terministas y ha obligado a formular el problema <strong>de</strong> la<br />
predicción a plazo medio y estacional, en términos probabilísticos (Lorenz,<br />
1996). Por ello, en el último <strong>de</strong>cenio, se han <strong>de</strong>sarrollado distintos métodos<br />
<strong>de</strong> predicción por conjuntos (ensemble forecast) para tener en cuenta el<br />
crecimiento exponencial <strong>de</strong> las fluctuaciones (errores) producidas por las distintas<br />
fuentes <strong>de</strong> incertidumbre asociadas con la predicción; por una parte,<br />
la incertidumbre producida por las condiciones iniciales (errores <strong>de</strong> observaciones<br />
y <strong>de</strong> análisis <strong>de</strong> los mo<strong>de</strong>los), y por otra la incertidumbre producida<br />
por el mo<strong>de</strong>lo (imperfecciones en la parametrización <strong>de</strong> diversos procesos<br />
físicos, representación <strong>de</strong> la orografía, etc.).<br />
Los métodos <strong>de</strong> predicción por conjuntos, estiman la probabilidad a posteriori<br />
<strong>de</strong> las distintas variables atmosféricas, a partir <strong>de</strong> un conjunto <strong>de</strong><br />
predicciones obtenidas, integrando el mo<strong>de</strong>lo atmosférico con distintas realizaciones<br />
<strong>de</strong> las fuentes <strong>de</strong> incertidumbre. Por una parte, para tener en<br />
cuenta la incertidumbre asociada al estado inicial, se perturban ligeramente<br />
las condiciones iniciales y se integra el mo<strong>de</strong>lo numérico, tantas veces como<br />
miembros tenga el conjunto <strong>de</strong> perturbaciones. Este coste computacional<br />
impone la necesidad <strong>de</strong> equipos más rápidos y potentes, y limita el número<br />
<strong>de</strong> miembros que pue<strong>de</strong>n ser tratados <strong>de</strong> forma operativa (unas <strong>de</strong>cenas).<br />
Este tipo <strong>de</strong> predicción por conjuntos, es el más difundido y el implantado<br />
operativamente en los principales centros meteorológicos. Por otra parte,<br />
113
114 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
para consi<strong>de</strong>rar la incertidumbre causada por el mo<strong>de</strong>lo, se consi<strong>de</strong>ran perturbaciones<br />
en las parametrizaciones (incluida la orografía) y, más generalmente,<br />
se calcula un conjunto <strong>de</strong> predicciones aplicando distintos mo<strong>de</strong>los<br />
(predicción multi-mo<strong>de</strong>lo). Pese a las dificulta<strong>de</strong>s teóricas y computacionales<br />
asociadas con este tipo <strong>de</strong> técnicas, los avances producidos han dado un<br />
enorme impulso a la predicción meteorológica en el plazo medio (entre 4 y 15<br />
días) y a la predicción mensual y estacional. Por ello, estos métodos se han<br />
convertido en un componente central en los gran<strong>de</strong>s centros meteorológicos<br />
mundiales, incluyendo el ECMWF en Europa y el NCEP en EEUU.<br />
Aunque la predicción probabilística, no resulta familiar para los usuarios<br />
finales <strong>de</strong> las predicciones meteorológicas (sectores energético, hidrológico,<br />
agricultura, etc.), ésta posee el valor añadido <strong>de</strong> permitir <strong>de</strong>finir una estrategia<br />
<strong>de</strong> toma <strong>de</strong> <strong>de</strong>cisiones, en base a los costes <strong>de</strong> protegerse <strong>de</strong> los<br />
eventuales efectos <strong>de</strong> una predicción adversa, y a las pérdidas que se producirían<br />
si no se toman las medidas <strong>de</strong> protección. Este esquema <strong>de</strong> valoración<br />
<strong>de</strong> las predicciones probabilísticas <strong>de</strong> un mo<strong>de</strong>lo concreto en un período dado<br />
se obtiene a partir <strong>de</strong> la llamada “curva <strong>de</strong> valor económico”, que muestra<br />
la ganancia <strong>de</strong> la predicción realizada con el mo<strong>de</strong>lo, frente a la predicción<br />
climatológica, y para los distintos valores <strong>de</strong> la razón coste/pérdidas (ver<br />
Cap. 4). De esta forma, es más sencillo obtener el valor <strong>de</strong> las predicciones<br />
meteorológicas, para los distintos sectores socio-económicos <strong>de</strong> aplicación,<br />
permitiendo una mayor difusión y un uso más racional <strong>de</strong> los productos <strong>de</strong><br />
predicción meteorológica por parte <strong>de</strong> los usuarios.<br />
En este capítulo se analizan diversas aplicaciones <strong>de</strong> las re<strong>de</strong>s autoorganizativas<br />
(ver Sec. 3.4) en la predicción por conjuntos. En la Sec. 6.2<br />
se <strong>de</strong>scriben en más <strong>de</strong>talle algunas técnicas <strong>de</strong> este tipo <strong>de</strong> predicciones.<br />
En la Sec. 6.3 se ilustran las aplicaciones <strong>de</strong> las re<strong>de</strong>s auto-organizativas<br />
para visualizar e interpretar el conjunto <strong>de</strong> predicciones, y para obtener predicciones<br />
locales a partir <strong>de</strong>l mismo. En esta sección también se <strong>de</strong>scriben<br />
las ventajas <strong>de</strong> esta técnica frente a los algoritmos <strong>de</strong> agrupamiento presentados<br />
en el capítulo anterior. Una aplicación <strong>de</strong> este método en el plazo<br />
medio se analiza en la Sec. 6.4 y, por último, la Sec. 6.5 aplica el mismo<br />
esquema <strong>de</strong> predicción por conjuntos a la predicción estacional, don<strong>de</strong> se<br />
tratan <strong>de</strong> pre<strong>de</strong>cir los efectos asociados a cambios en los patrones <strong>de</strong> circulación<br />
atmosférica (anomalías <strong>de</strong> temperatura, precipitación, etc.) con varios<br />
meses <strong>de</strong> antelación. En esta sección, se <strong>de</strong>muestra que es posible obtener<br />
predicciones locales durante episodios <strong>de</strong> “El Niño” fuertes, con meses <strong>de</strong><br />
antelación.<br />
6.2. Predictibilidad y Predicción por Conjuntos<br />
Como ya se ha comentado, el problema <strong>de</strong> la predictibilidad <strong>de</strong> los mo<strong>de</strong>los<br />
numéricos <strong>de</strong> circulación atmosférica está asociado con su no linealidad,<br />
ya que cualquier incertidumbre o error introducido en el sistema fluctúa<br />
exponencialmente en el tiempo. Analizado <strong>de</strong> forma general, el origen <strong>de</strong>
6.2. PREDICTIBILIDAD Y PREDICCIÓN POR CONJUNTOS 115<br />
fluctuaciones en estos mo<strong>de</strong>los pue<strong>de</strong> provenir <strong>de</strong> errores en la condición<br />
inicial (caos), <strong>de</strong> reducción <strong>de</strong> variables en el mo<strong>de</strong>lo (ruido) o <strong>de</strong> las parametrizaciones<br />
y condiciones orográficas <strong>de</strong> contorno (<strong>de</strong>sor<strong>de</strong>n).<br />
La dispersión producida por errores en la condición inicial, ha sido el caso<br />
más estudiado en la predicción meteorológica. Se suele analizar aplicando un<br />
método <strong>de</strong> predicción por conjuntos, a mo<strong>de</strong>los numéricos con muchos modos<br />
espaciales (An<strong>de</strong>rson, 1996). Los conjuntos se pue<strong>de</strong>n formar <strong>de</strong> muy diversas<br />
formas, siendo el método <strong>de</strong> vectores singulares (Buizza and Palmer, 1995) o<br />
el método <strong>de</strong> breeding (Pu et al., 1997) los más utilizados para la generación<br />
<strong>de</strong> miembros, a partir <strong>de</strong> perturbaciones específicas <strong>de</strong> las condiciones iniciales.<br />
El método <strong>de</strong> vectores singulares ha sido adoptado por el ECMWF y<br />
el método <strong>de</strong> breeding por el NCEP. Ambos métodos presentan características<br />
muy distintas, y a veces contrarias, pero sus resultados finales, medidos<br />
en valores económicos, no son muy distintos. El método <strong>de</strong> breeding no requiere<br />
gran<strong>de</strong>s esfuerzos computacionales, y es técnicamente muy simple.<br />
Consiste en seguir la evolución lineal en una <strong>de</strong>terminada trayectoria, con<br />
condiciones iniciales aleatorias muy alejada <strong>de</strong>l tiempo <strong>de</strong> observación. El<br />
método <strong>de</strong> vectores singulares es computacionalmente mucho más costoso y<br />
técnicamente más complejo, pues calcula, mediante técnicas <strong>de</strong> componentes<br />
principales, las fluctuaciones lineales más significativas ocurridas en un<br />
alcance <strong>de</strong> predicción dado.<br />
En la práctica, este tipo <strong>de</strong> predicción por conjuntos se realiza, tanto<br />
para la predicción a medio plazo, como para la predicción estacional.<br />
En este período la predicción se entien<strong>de</strong> en sentido probabilístico y cobra<br />
importancia el concepto <strong>de</strong> predictibilidad, y su caracterización para<br />
cada situación (unas situaciones son más pre<strong>de</strong>cibles que otras). En estos<br />
casos, la predicción por conjuntos proporciona una solución práctica, ya que<br />
los miembros <strong>de</strong>l conjunto <strong>de</strong> predicciones, nos proporcionan <strong>de</strong>scripciones<br />
equiprobables <strong>de</strong>l patrón atmosférico previsto, y a partir <strong>de</strong> las cuales se<br />
pue<strong>de</strong> obtener una predicción probabilística, así como una estimación <strong>de</strong> su<br />
predictibilidad.<br />
Por otra parte, la dispersión producida por la no exactitud <strong>de</strong>l mo<strong>de</strong>lo,<br />
y <strong>de</strong> las distintas parametrizaciones, está siendo abordada consi<strong>de</strong>rando<br />
conjuntos <strong>de</strong> predicciones obtenidos por varios mo<strong>de</strong>los (predicción multimo<strong>de</strong>lo).<br />
Quizás la iniciativa más <strong>de</strong>stacada en este ámbito sea la llevada a<br />
cabo en el proyecto DEMETER (Development of a European Multimo<strong>de</strong>l<br />
Ensemble system for seasonal to inTERannual prediction) que está integrado<br />
por seis mo<strong>de</strong>los globales <strong>de</strong> predicción por conjuntos con distintos esquemas<br />
<strong>de</strong> perturbación (www.ecmwf.int/research/<strong>de</strong>meter/) con los que se<br />
aborda el problema <strong>de</strong> la predicción mensual y estacional (Palmer et al.,<br />
2003).<br />
Por ejemplo, uno <strong>de</strong> los casos más comunes <strong>de</strong> predicción estacional por<br />
conjuntos, es el fenómeno <strong>de</strong> El Niño; en concreto, la zona Niño-3 que compren<strong>de</strong><br />
un área <strong>de</strong>l Océano Pacífico entre la latitu<strong>de</strong>s 5N − 5S y longitu<strong>de</strong>s<br />
90W − 150W. El promedio <strong>de</strong> la temperatura <strong>de</strong>l agua <strong>de</strong>l mar en esta re-
116 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
gión, se suele utilizar como indicador <strong>de</strong> la actividad <strong>de</strong> El Niño. La Figura<br />
6.1 muestra las predicciones realizadas por el mo<strong>de</strong>lo estacional, System-II<br />
<strong>de</strong>l ECMWF en (a) Abril y (b) Agosto, para cada uno <strong>de</strong> los miembros <strong>de</strong>l<br />
conjunto <strong>de</strong> predicciones. En ambas figuras se muestra el valor real ocurrido<br />
en trazo discontinuo. En la figura (a) todos los miembros <strong>de</strong> la predicción<br />
indican una anomalía positiva en el futuro. En cambio, en la figura (b) unos<br />
miembros <strong>de</strong>l conjunto indican anomalía positiva, mientras otros indican lo<br />
contrario. En este caso, la situación se supone menos pre<strong>de</strong>cible y la confianza<br />
asociada a la predicción es baja. En la figura inferior se muestra la<br />
probabilidad obtenida a partir <strong>de</strong>l conjunto <strong>de</strong> predicciones, para que la<br />
temperatura en la superficie <strong>de</strong>l mar tenga una anomalía positiva durante<br />
el trimestre septiembre-noviembre <strong>de</strong> 2003.<br />
(a)<br />
(b)<br />
Figura 6.1: Predicción por conjuntos <strong>de</strong>l fenómeno <strong>de</strong> El Niño con un conjunto <strong>de</strong><br />
51 miembros. (a) La predicción realizada en Abril muestra una anomalía positiva<br />
hasta octubre; (b) los miembros <strong>de</strong> la predicción realizada en Julio no coinci<strong>de</strong>n<br />
en una misma predicción. La figura inferior muestra la probabilidad (en tanto por<br />
ciento) predicha el 1 <strong>de</strong> Agosto <strong>de</strong> que la temperatura a 2m se encuentre en el tercil<br />
superior (anomalía positiva) en el período SON 2003. (FUENTE: ECWMF)<br />
Distintas validaciones <strong>de</strong> la predicción probabilística por conjuntos, han<br />
mostrado su superioridad frente a la predicción <strong>de</strong>terminista tradicional<br />
(Zhu et al., 2001). Sin embargo, a pesar <strong>de</strong> que cualitativamente la dispersión<br />
<strong>de</strong>l conjunto parece apropiada, como medida <strong>de</strong> predictibilidad, todavía<br />
no se ha obtenido ningún resultado concluyente relacionando estos conceptos.<br />
En la siguiente sección se muestra que las re<strong>de</strong>s auto-organizativas proporcionan<br />
criterios cualitativos, y cuantitativos, para relacionar predictibilidad<br />
y dispersión <strong>de</strong>l conjunto <strong>de</strong> predicciones.
6.3. APLICACIÓN DE LAS REDES AUTO-ORGANIZATIVAS 117<br />
6.3. Aplicación <strong>de</strong> las Re<strong>de</strong>s Auto-Organizativas<br />
En la Sec. 3.4 se <strong>de</strong>scribieron diversas aplicaciones <strong>de</strong> las re<strong>de</strong>s autoorganizativas<br />
(Self-Organizing Maps, SOM) para la visualización y clasificación<br />
<strong>de</strong> patrones atmosféricos y <strong>de</strong> patrones fenomenológicos (observaciones<br />
en superficie). Esta técnica es una generalización <strong>de</strong> la técnica <strong>de</strong> agrupamiento<br />
<strong>de</strong> m-medias (ver Sec. 3.3.2) y divi<strong>de</strong> el espacio original <strong>de</strong> patrones<br />
(por ejemplo, una base <strong>de</strong> datos <strong>de</strong> re-análisis) en grupos caracterizados<br />
por un patrón prototipo. La diferencia entre la técnicas <strong>de</strong> m-medias y la<br />
SOM consiste en que esta última, lleva a cabo una proyección no lineal <strong>de</strong>l<br />
espacio <strong>de</strong> patrones (<strong>de</strong> muy alta dimensionalidad), en un espacio arbitrario<br />
(normalmente un espacio reticular bidimensional <strong>de</strong> fácil visualización),<br />
conservando la distancia y, por tanto, la noción <strong>de</strong> vecindad. De esta forma,<br />
patrones vecinos en la retícula 2D también son vecinos (similares) en el espacio<br />
real, mientas que los patrones alejados en esta representación reticular,<br />
también se encuentran alejados en el espacio real.<br />
40<br />
T 1000mb<br />
30<br />
20<br />
10<br />
PC2<br />
0<br />
-10<br />
-20<br />
-30<br />
-40<br />
-40 -30 -20 -10 0 10 20 30 40<br />
PC1<br />
T 500mb<br />
Z, (U,V) 500mb<br />
Figura 6.2: Ejemplo <strong>de</strong> una SOM <strong>de</strong> 5 × 5 grupos representada en el espacio<br />
generado por las dos primeras componentes principales <strong>de</strong>l re-análisis ERA-15. Cada<br />
grupo tiene asociado un prototipo proyectado sobre la retícula 5 × 5; en este caso<br />
se muestran tres campos atmoféricos asociados a cada prototipo: temperatura en<br />
500 y 1000 mb y geopotencial y dirección <strong>de</strong> viento en 500 mb.<br />
Por ejemplo, la Fig. 6.2 muestra una retícula 5×5 (25 grupos) proyectada<br />
sobre el espacio <strong>de</strong>finido por las dos primeras componentes principales <strong>de</strong><br />
los patrones atmosféricos <strong>de</strong> ERA-15 (la retícula está proyectada sobre todo<br />
el espacio, pero se muestran solamente las dos primeras componentes para
118 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
facilitar su visualización). Cada punto <strong>de</strong> la retícula representa un prototipo,<br />
que caracteriza al conjunto <strong>de</strong> los patrones atmosféricos que están en su<br />
vecindad (más cerca <strong>de</strong> ese prototipo que <strong>de</strong> ningún otro). Asimismo, cada<br />
uno <strong>de</strong> los prototipos está representado por un punto en la retícula 2D<br />
original, y tiene asociado un conjunto <strong>de</strong> vecinos (los 8 vecinos <strong>de</strong> la retícula<br />
que lo ro<strong>de</strong>an). El entrenamiento <strong>de</strong> la SOM calcula la ubicación óptima <strong>de</strong><br />
los prototipos en el espacio real (agrupamiento), pero, manteniendo la noción<br />
<strong>de</strong> vecindad <strong>de</strong>finida en la retícula original. Por ejemplo, en la Fig. 6.2, se<br />
muestran por separado los valores <strong>de</strong> tres campos atmosféricos (temperatura<br />
en 1000mb, temperatura en 500mb, y geopotencial y dirección <strong>de</strong>l viento en<br />
500mb) asociados a cada uno <strong>de</strong> los prototipos resultantes, <strong>de</strong> entrenar una<br />
SOM 2D reticular 5 × 5 con los patrones atmosféricos <strong>de</strong>l re-análisis ERA-<br />
15, limitados a la región <strong>de</strong>l Atlántico Norte. En esta figura se pue<strong>de</strong> ver<br />
que existe una continuidad en los patrones atmosféricos, mostrados en la<br />
retícula, que refleja la conservación <strong>de</strong> distancias <strong>de</strong> la proyección realizada.<br />
La utilidad <strong>de</strong> este tipo <strong>de</strong> representaciones ha sido puesta <strong>de</strong> manifiesto en<br />
la Sec. 3.4 para la clasificación y visualización <strong>de</strong> patrones <strong>de</strong> tiempo (otras<br />
aplicaciones en Climatología se ilustran en Hewitson and Crane, 2002).<br />
Esta técnica ha sido también utilizada para la predicción local (downscaling<br />
estadístico), permitiendo clasificar los patrones atmosféricos, y estimar<br />
mo<strong>de</strong>los <strong>de</strong> regresión locales para cada uno <strong>de</strong> los grupos resultantes<br />
(Cavazos, 2000). Por una parte, este método podría ser mejorado aplicando<br />
algún método <strong>de</strong> estimación no lineal a los grupos resultantes (ver, por ejemplo,<br />
Fontela-Romero et al., 2002). Sin embargo, la aplicación <strong>de</strong> las SOM en<br />
este ámbito no presenta ninguna ventaja <strong>de</strong>s<strong>de</strong> el punto <strong>de</strong> vista <strong>de</strong> la calidad<br />
<strong>de</strong> la predicción, con respecto al método <strong>de</strong> downscaling por agrupamiento,<br />
presentado en el Capítulo 5. Sin embargo, en la predicción por conjuntos la<br />
SOM aporta un valor añadido, que todavía no ha sido tenido en cuenta en<br />
este ámbito. En esta sección se analiza esa aplicación.<br />
El método <strong>de</strong> predicción local por agrupamiento, <strong>de</strong>scrito en el Capítulo<br />
5 se <strong>de</strong>scribe en la Fig. 5.10, en la muestra un esquema <strong>de</strong> las partes principales.<br />
Esta figura muestra que la generalización <strong>de</strong> esta técnica, a la predicción<br />
por conjuntos, resulta trivial: en lugar <strong>de</strong> trabajar con un único patrón, se<br />
repite el proceso con cada uno <strong>de</strong> los patrones miembro <strong>de</strong> la predicción por<br />
conjuntos, obteniéndose un valor local, previsto a partir <strong>de</strong> las predicciones<br />
asociadas con cada uno <strong>de</strong> los grupos obtenidos, para los miembros. La etapa<br />
<strong>de</strong> agrupamiento, requerida como preproceso <strong>de</strong>l algoritmo, no varía, lo<br />
que varía es la aplicación operativa, ya que sólo es necesario hallar el grupo<br />
correspondiente a cada patrón miembro <strong>de</strong> la predicción. Si en lugar <strong>de</strong> utilizar<br />
una técnica <strong>de</strong> agrupamiento estándar (como m-medias) se utiliza una<br />
SOM en este esquema, se cuenta con la ventaja adicional <strong>de</strong> tener organizados<br />
los grupos en una retícula 2D, don<strong>de</strong> se conserva la misma noción <strong>de</strong><br />
vecindad que en el espacio real <strong>de</strong> patrones. Por tanto, los miembros <strong>de</strong> la<br />
predicción por conjunto <strong>de</strong>finirán una función <strong>de</strong> probabilidad en la retícula<br />
<strong>de</strong> la SOM, que podrá combinarse con las funciones <strong>de</strong> probabilidad feno-
6.3. APLICACIÓN DE LAS REDES AUTO-ORGANIZATIVAS 119<br />
menológicas para ŷ i , obtenidas para cada grupo, para así obtener un valor<br />
final <strong>de</strong> la predicción (ver Fig. 6.3).<br />
1979<br />
1993<br />
...<br />
ATMOSPHERIC<br />
PATTERNS<br />
DATABASE<br />
ERA15<br />
reanalisys<br />
1979-1993<br />
CLUSTERING<br />
C 1 , ..., C m<br />
SELF-ORGANIZING<br />
MAP (SOM)<br />
Topological arrangement<br />
in a 2D lattice (e.g. m=36)<br />
C1 C2 ...<br />
C36<br />
Find Cluster:<br />
C i1<br />
ENSEMBLE<br />
FORECAST<br />
...<br />
f1 f 2 ...<br />
Find Cluster:<br />
C in<br />
1979<br />
...<br />
Daily records:<br />
Precip, wind, ...<br />
Estimation for<br />
each cluster<br />
and station<br />
y 1 , ..., y m<br />
f36<br />
Inference: y i<br />
1993<br />
LOCAL CLIMATE<br />
RECORDS DATABASE<br />
Figura 6.3: Esquema <strong>de</strong>l algoritmo <strong>de</strong> downscaling por agrupamiento generalizado<br />
a la predicción por conjuntos. En este caso, la técnica <strong>de</strong> agrupamiento está basada<br />
en re<strong>de</strong>s auto-organizativas consi<strong>de</strong>rando una retícula 2D.<br />
Por tanto, el uso <strong>de</strong> las SOM como técnica <strong>de</strong> agrupamiento permite<br />
obtener:<br />
Una predicción probabilística y numérica, a partir <strong>de</strong> algún estadístico<br />
central, o algún percentil, <strong>de</strong> la función <strong>de</strong> probabilidad resultante, <strong>de</strong><br />
combinar la probabilidad <strong>de</strong> la SOM y la probabilidad fenomenológica<br />
<strong>de</strong> cada grupo (véase Sec. 5.4.1).<br />
Una medida <strong>de</strong> predictibilidad (o confianza) basándose en algún estadístico<br />
<strong>de</strong> dispersión <strong>de</strong> la probabilidad <strong>de</strong> la SOM. Obsérvese, que<br />
la dispersión estadística <strong>de</strong> la función <strong>de</strong> probabilidad, está relacionada<br />
con la dispersión <strong>de</strong> los patrones <strong>de</strong> los miembros <strong>de</strong> la predicción<br />
por conjuntos, ya que la SOM conserva las distancias <strong>de</strong>l espacio real<br />
en la retícula 2D, que sirve <strong>de</strong> soporte a la función <strong>de</strong> probabilidad.<br />
Por tanto, la dispersión <strong>de</strong> los miembros <strong>de</strong> la predicción en el espacio<br />
real redundará en una mayor dispersión <strong>de</strong> la probabilidad sobre la<br />
retícula <strong>de</strong> la SOM.<br />
Por ejemplo, la Fig. 6.4(a) muestra la función <strong>de</strong> probabilidad <strong>de</strong>finida<br />
en la SOM por los días <strong>de</strong> Invierno (Diciembre-Febrero) <strong>de</strong>l período ERA-<br />
15 (1979-1993), mientras que la la Fig. 6.4(b) muestra la probabilidad correspondiente<br />
al verano (Junio-Agosto). Comparando estas dos figuras se<br />
pue<strong>de</strong> observar que cada una <strong>de</strong> ellas se distribuye en una parte distinta<br />
<strong>de</strong>l soporte, indicando la diferencia entre ambos conjuntos <strong>de</strong> patrones. Por<br />
otra parte, las Fig. 6.4(c) y (d) muestran las probabilida<strong>de</strong>s <strong>de</strong> los invierno
120 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
(a) DJF<br />
0.1<br />
(b) JJA<br />
0.1<br />
0.08<br />
0.08<br />
0.06<br />
0.06<br />
0.04<br />
0.04<br />
0.02<br />
0.02<br />
(c) DJF 1998<br />
0<br />
0.1<br />
(d) DJF 2000<br />
0<br />
0.1<br />
0.08<br />
0.08<br />
0.06<br />
0.06<br />
0.04<br />
0.04<br />
0.02<br />
0.02<br />
0<br />
0<br />
Figura 6.4: Función <strong>de</strong> probabilidad empírica <strong>de</strong>finida sobre la SOM por (a) los<br />
días <strong>de</strong> invierno (Diciembre-Febrero) <strong>de</strong>l período ERA-15 (1979-1993), (b) los días<br />
<strong>de</strong> verano (Junio-Agosto) <strong>de</strong> ERA-15. (c) los días <strong>de</strong> invierno <strong>de</strong>l año 1998 (d) los<br />
días <strong>de</strong> invierno <strong>de</strong>l año 2000.<br />
para los años 1998 y 2000, respectivamente. Estas funciones <strong>de</strong> probabilidad<br />
<strong>de</strong>finen la variabilidad <strong>de</strong> cada uno <strong>de</strong> los años y una comparación con la<br />
Fig. (a) permitiría reflejar lo anomalía <strong>de</strong> la estación correspondiente con<br />
respecto a la climatología. Estas mismas i<strong>de</strong>as se pue<strong>de</strong>n aplicar para el caso<br />
<strong>de</strong> la predicción por conjuntos. En la siguiente sección se analizan distintas<br />
medidas que pue<strong>de</strong>n caracterizar la dispersión <strong>de</strong> la función <strong>de</strong> probabilidad<br />
y comparar dos funciones entre sí.<br />
6.3.1. Medidas <strong>de</strong> Dispersión y Predictibilidad<br />
Aparte <strong>de</strong> las medidas estándar para caracterizar la dispersión <strong>de</strong> una<br />
función <strong>de</strong> probabilidad (por ejemplo, la <strong>de</strong>sviación estándar σ), existen<br />
otras medidas, como la entropía, <strong>de</strong>sarrolladas en el campo <strong>de</strong> la “teoría<br />
<strong>de</strong> la información” con propieda<strong>de</strong>s interesantes para el problema que nos<br />
ocupa (Shannon, 1948).<br />
La entropía es una medida utilizada para caracterizar el <strong>de</strong>sor<strong>de</strong>n y la<br />
pérdida <strong>de</strong> información en distintos problemas (sistemas físicos como mezclas<br />
<strong>de</strong> gases, códigos digitales para comunicaciones, etc.). Des<strong>de</strong> el punto<br />
<strong>de</strong> vista estadístico, la entropía <strong>de</strong> una función <strong>de</strong> probabilidad caracteriza<br />
la uniformidad <strong>de</strong> la misma (para el caso discreto). Dada una función <strong>de</strong><br />
probabilidad (p 1 , . . .,p n ) = (P(c 1 ), . . .,P(c n )) <strong>de</strong>finida sobre una variable<br />
discreta C con n estados (C 1 , . . .,C n ), se <strong>de</strong>fine su entropía como:<br />
H(P) = − ∑ i<br />
p i log b p i = ∑ i<br />
[ ]<br />
1 1<br />
p i log b = E log b<br />
p i P(x)<br />
(6.1)<br />
don<strong>de</strong> la base <strong>de</strong>l logaritmo nos va a <strong>de</strong>terminar la unidad en la que se mi<strong>de</strong><br />
la información <strong>de</strong> los datos (si es 2, la unidad <strong>de</strong> medida es el bit). A partir
6.4. APLICACIÓN EN LA PREDICCIÓN A MEDIO PLAZO 121<br />
<strong>de</strong> esta <strong>de</strong>finición, y consi<strong>de</strong>rando las propieda<strong>de</strong>s <strong>de</strong> una probabilidad, se<br />
pue<strong>de</strong> <strong>de</strong>ducir que H(P) ≥ 0, y será nula cuando toda la probabilidad se<br />
acumule en un sólo estado (la variable tome un único valor).<br />
Otra medida <strong>de</strong> interés es la entropía relativa, también llamada distancia<br />
<strong>de</strong> Kullback-Leibler, que mi<strong>de</strong> la distancia entre dos posibles distribuciones<br />
<strong>de</strong> probabilidad, P y Q, <strong>de</strong> una misma variable aleatoria X. Se <strong>de</strong>fine como:<br />
H(P |Q) = ∑ q i ≠0<br />
p i log p i<br />
q i<br />
(6.2)<br />
como en el caso anterior se tiene que H(P |Q) ≥ 0 y el valor nulo sólo se<br />
alcanza cuando P ≡ Q ⇔ p i = q i ∀i.<br />
Cada una <strong>de</strong> estas medidas, proporciona una caracterización <strong>de</strong> la dispersión<br />
<strong>de</strong> los miembros <strong>de</strong> la predicción por conjuntos, a partir <strong>de</strong> la probabilidad<br />
que <strong>de</strong>finen sobre la SOM. La <strong>de</strong>sviación típica es la más simple<br />
<strong>de</strong> estas caracterizaciones y mi<strong>de</strong> la separación promedio <strong>de</strong> los miembros<br />
<strong>de</strong> la predicción, al patrón medio previsto. Por otra parte, la entropía tiene<br />
en cuenta la mayor, o menor dispersión <strong>de</strong> los miembros, sin consi<strong>de</strong>rar la<br />
distancia a la que se encuentran <strong>de</strong>l centro <strong>de</strong> la probabildiad. Por último,<br />
la entropía relativa <strong>de</strong> la probabilidad, respecto a la probabilidad climatológica,<br />
ofrece una medida <strong>de</strong> la información proporcionada por el mo<strong>de</strong>lo<br />
numérico, o <strong>de</strong> la anomalía <strong>de</strong>l patrón previsto. La conveniencia <strong>de</strong> estas<br />
medidas se analiza en <strong>de</strong>talle en dos aplicaciones concretas: la predicción a<br />
plazo medio y la predicción estacional.<br />
6.4. Aplicación en la Predicción a Medio Plazo<br />
En esta sección se analiza la aplicación <strong>de</strong> la técnica <strong>de</strong> la Sección anterior,<br />
a la predicción por conjuntos <strong>de</strong> plazo medio. Para ello se consi<strong>de</strong>ran<br />
las salidas operativas <strong>de</strong>l mo<strong>de</strong>lo <strong>de</strong> predicción por conjuntos <strong>de</strong>l ECMWF,<br />
para el período DEF 1998 y 2000 (180 días). Para cada uno <strong>de</strong> los días,<br />
este mo<strong>de</strong>lo realiza una predicción hasta D + 9 a partir <strong>de</strong> una condición<br />
inicial, a esta predicción se la <strong>de</strong>nomina control. Después se generan otras<br />
50 predicciones, a partir <strong>de</strong> perturbaciones <strong>de</strong> la condición inicial, aplicando<br />
el método <strong>de</strong> vectores singulares. Por tanto, para cada alcance <strong>de</strong> predicción<br />
entre D + 1 y D + 9 se tienen 51 patrones atmosféricos que se consi<strong>de</strong>ran<br />
igualmente probables, para la <strong>de</strong>scripción <strong>de</strong>l patrón atmosférico previsto.<br />
Tal como se comentó en la sección anterior, cada conjunto <strong>de</strong> 51 patrones<br />
<strong>de</strong>fine una función <strong>de</strong> probabilidad que tiene como soporte la retícula <strong>de</strong><br />
la SOM. Por ejemplo, la Fig. 6.5 muestra las funciones <strong>de</strong> probabilidad<br />
dadas por los 51 patrones para cada uno <strong>de</strong> los alcances obtenidos a partir<br />
<strong>de</strong>l día 24 <strong>de</strong> febrero <strong>de</strong> 1998. Como pue<strong>de</strong> observarse en esta figura, la<br />
predicción para los primeros dos días se centra en un sólo grupo, mientras<br />
que la dispersión comienza a crecer a partir <strong>de</strong>l tercer día, a medida que<br />
aumenta la incertidumbre sobre la predicción. Los dos números que aparecen
122 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
EPS 24/2/1998<br />
H=0 σ=0 0 0<br />
1<br />
1<br />
0.743 0.793<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+1 D+2 D+3<br />
1.612 1.614 2.190 1.571 1.998 1.984<br />
1<br />
1<br />
1<br />
0.5<br />
0<br />
1<br />
0.5<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+4 D+5 D+6<br />
2.433 3.018 2.393 3.441 2.718 3.385<br />
1<br />
1<br />
0<br />
1<br />
0.5<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+7 D+8 D+9<br />
0<br />
Figura 6.5: Probabilida<strong>de</strong>s <strong>de</strong>finidas sobre la SOM por los miembros <strong>de</strong> la predicción<br />
por conjuntos <strong>de</strong>l día 24/2/1998 para los alcances entre D + 1 y D + 9.<br />
sobre la distribución, indican la entropía (izquierda) y la <strong>de</strong>sviación típica<br />
(<strong>de</strong>recha).<br />
Sin embargo, no todas las situaciones son similares a la anterior, ya que<br />
se pue<strong>de</strong> encontrar un período estable don<strong>de</strong> los miembros <strong>de</strong>l conjunto <strong>de</strong><br />
predicciones tienen escasa variabilidad (ver Fig. 6.6), y también una situación<br />
más impre<strong>de</strong>cible, en la que la dispersión es consi<strong>de</strong>rable <strong>de</strong>s<strong>de</strong> el primer<br />
día <strong>de</strong> alcance (ver Fig. 6.7).<br />
A pesar <strong>de</strong> la variabilidad <strong>de</strong> unas situaciones a otras, se pue<strong>de</strong> esperar<br />
que, en promedio, la dispersión <strong>de</strong> las funciones <strong>de</strong> probabilidad crezca a<br />
medida que aumenta el alcance <strong>de</strong> la predicción (y, por tanto, su incertidumbre).<br />
Para constatar este hecho se han calculado los respectivos cuartiles <strong>de</strong><br />
las dispersiones, y para los distintos alcances, consi<strong>de</strong>rando las predicciones<br />
realizadas en los 180 días. Las Figs. 6.8 (a) y (c) muestran la entropía y la<br />
<strong>de</strong>sviación típica <strong>de</strong> la probabilidad para el alcance D. En estas figuras pue<strong>de</strong><br />
observarse que, la <strong>de</strong>sviación tiene algunos valores fuera <strong>de</strong> rango durante los<br />
primeros días <strong>de</strong> la predicción y comienza a saturar a partir <strong>de</strong>l quinto día,<br />
y por otra parte, el comportamiento <strong>de</strong> la entropía es más monótono. Cada<br />
una <strong>de</strong> estas dos medidas da una información distinta sobre la variabilidad<br />
<strong>de</strong> cada uno <strong>de</strong> los patrones. Por ello, se consi<strong>de</strong>ra también un parámetro <strong>de</strong><br />
dispersión <strong>de</strong>finido como la suma <strong>de</strong> los parámetros anteriores. En la Fig.<br />
6.8(d) se muestra que este parámetro presenta la característica <strong>de</strong> satura-
6.4. APLICACIÓN EN LA PREDICCIÓN A MEDIO PLAZO 123<br />
H=0.321 σ=0.297 0.321 0.297 0.670 0.488<br />
1<br />
1<br />
1<br />
EPS 25/1/1988<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+1 D+2 D+3<br />
1.097 1.083 0.415 0.425 0.546 0.798<br />
1<br />
1<br />
0.5<br />
0<br />
1<br />
0.5<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+4 D+5 D+6<br />
1.333 1.477 1.528 1.565 1.626 1.637<br />
1<br />
1<br />
0<br />
1<br />
0.5<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+7 D+8 D+9<br />
Figura 6.6: Probabilida<strong>de</strong>s <strong>de</strong>finidas sobre la SOM por los miembros <strong>de</strong> la predicción<br />
por conjuntos <strong>de</strong>l día 25/1/1998 para los alcances entre D + 1 y D + 9.<br />
0<br />
EPS 19/12/1997<br />
H=0.756 σ=0.693 1.571 3.005 2.172 3.517<br />
1<br />
1<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+1 D+2 D+3<br />
2.205 2.627 2.040 2.870 1.971 2.645<br />
1<br />
1<br />
1<br />
0.5<br />
0<br />
1<br />
0.5<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+4 D+5 D+6<br />
2.629 2.497 2.540 2.529 2.366 3.291<br />
1<br />
1<br />
0<br />
1<br />
0.5<br />
0.5<br />
0.5<br />
0<br />
0<br />
D+7 D+8 D+9<br />
Figura 6.7: Probabilida<strong>de</strong>s <strong>de</strong>finidas sobre la SOM por los miembros <strong>de</strong> la predicción<br />
por conjuntos <strong>de</strong>l día 19/12/1997 para los alcances entre D + 1 y D + 9.<br />
0
124 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
H(P(D))<br />
3<br />
2<br />
1<br />
(a)<br />
H(P(D)|P(D-1))<br />
4<br />
3<br />
2<br />
1<br />
(b)<br />
0<br />
1 2 3 4 5 6 7 8 9<br />
alcance (dias)<br />
0<br />
1 2 3 4 5 6 7 8 9<br />
alcance (dias)<br />
4<br />
6<br />
σ(P(D))<br />
3<br />
2<br />
1<br />
0<br />
(c)<br />
1 2 3 4 5 6 7 8 9<br />
alcance (dias)<br />
Dispersión<br />
5<br />
4<br />
3<br />
2<br />
1<br />
0<br />
(d)<br />
1 2 3 4 5 6 7 8 9<br />
alcance (dias)<br />
Figura 6.8: (a) Entropía <strong>de</strong> la probabilidad para el alcance D, H(P(D)); (b) Entropía<br />
relativa <strong>de</strong> la probabilidad <strong>de</strong> un día, respecto a la probabilidad <strong>de</strong>l día<br />
anterior, H(P(D)|P(D −1)); (c) <strong>de</strong>sviación típica <strong>de</strong> la probabilidad y (d) parámetros<br />
<strong>de</strong> dispersión, <strong>de</strong>finido como la suma <strong>de</strong> la <strong>de</strong>sviación típica y la entropía.<br />
ción <strong>de</strong> la <strong>de</strong>sviación, mientras que reduce el problema <strong>de</strong> los valores fuera<br />
<strong>de</strong> rango. Por último, la Fig. 6.8(c) muestra la entropía relativa <strong>de</strong> un día<br />
respecto al anterior. Como se pue<strong>de</strong> observar en la figura, este valor <strong>de</strong>cae<br />
<strong>de</strong> forma continua a medida que se incrementa el alcance <strong>de</strong> la predicción;<br />
se observa un gran crecimiento incremental <strong>de</strong> la dispersión los primeros<br />
cinco días, mientras que la dispersión aumenta más lentamente a partir <strong>de</strong>l<br />
quinto día <strong>de</strong> alcance. Este hecho coinci<strong>de</strong> con la saturación indicada por la<br />
<strong>de</strong>sviación típica.<br />
La validación <strong>de</strong>l sistema <strong>de</strong> predicción probabilística por conjuntos ha<br />
mostrado ser superior a un sistema <strong>de</strong>terminista clásico basado en una única<br />
integración (ver, por ejemplo, Richardson, 2000) en el medio plazo. A continuación<br />
se comprueba que este resultado también es cierto cuando se utilizan<br />
los patrones atmosféricos para realizar predicciones locales utilizando el<br />
método <strong>de</strong> downscaling <strong>de</strong>scrito en el Capítulo 5. Para ello, se ha entrenado<br />
una SOM consi<strong>de</strong>rando el patrón <strong>de</strong> la Cuenca Norte <strong>de</strong> la Península Ibérica<br />
mostrado en la Fig. 2.9(c) y se ha aplicado el método <strong>de</strong> downscaling <strong>de</strong>scrito<br />
en la Fig. 6.3 para pre<strong>de</strong>cir el evento P(Precip > 0.1mm) en 100 estaciones<br />
<strong>de</strong> la Cuenca Norte. La Fig. 6.9 muestra los Brier Scores (BS) diarios promediados<br />
para todas la estaciones obtenidos con los 50 miembros, perturbados,
6.4. APLICACIÓN EN LA PREDICCIÓN A MEDIO PLAZO 125<br />
1<br />
D+1 1 D+2 1 D+3<br />
0<br />
0<br />
0<br />
0 BS Control 1 0 BS Control 1 0 BS Control 1<br />
1<br />
D+4 1 D+5 1 D+6<br />
BS EPS<br />
BS EPS<br />
0<br />
0<br />
0<br />
0 BS Control 1 0 BS Control 1 0 BS Control 1<br />
1<br />
D+7 1 D+8 1 D+9<br />
BS EPS<br />
BS EPS<br />
BS EPS<br />
BS EPS<br />
BS EPS<br />
BS EPS<br />
BS EPS<br />
0<br />
0<br />
0<br />
0 BS Control 1 0 BS Control 1 0 BS Control 1<br />
Figura 6.9: Brier Score (BS) <strong>de</strong> la predicción local realizada con todos los miembros<br />
<strong>de</strong>l conjunto (BS EPS) y sólo con el control (BS Control) para alcances entre uno<br />
y nueve días. Los valores representados son las medias para todas la estaciones<br />
principales <strong>de</strong> la Cuenca Norte.<br />
<strong>de</strong> la predicción por conjuntos (etiqueta EPS) y una única predicción dada<br />
por el control (el patrón correspondiente a la condición inicial sin perturbar)<br />
(etiqueta control). En esta figura pue<strong>de</strong> verse que el downscaling realizado<br />
con la predicción por conjuntos es claramente superior al downscaling tradicional,<br />
basado en una única predicción entre los días quinto y octavo, siendo<br />
ligeramente mejor el resto <strong>de</strong> los días. En concreto el noveno día el comportamiento<br />
<strong>de</strong>l sistema <strong>de</strong> predicción por conjuntos comienza a per<strong>de</strong>r pericia<br />
respecto al control.<br />
Por último, se muestra que la medida <strong>de</strong> dispersión <strong>de</strong> la probabilidad<br />
<strong>de</strong> la SOM, <strong>de</strong>finida como la suma <strong>de</strong> la <strong>de</strong>sviación típica y <strong>de</strong> la entropía,<br />
está correlacionada con la predictibilidad <strong>de</strong> la situación correspondiente.<br />
Para ello, en la Fig. 6.10 se muestra la dispersión frente al error BS obtenido<br />
en la respectiva predicción realizada, para los distintos alcances <strong>de</strong>l<br />
mo<strong>de</strong>lo. Se pue<strong>de</strong> observar que a partir <strong>de</strong>l tercer día <strong>de</strong> predicción, aparece<br />
una relación entre, la medida <strong>de</strong> dispersión <strong>de</strong>finida a partir <strong>de</strong> la SOM,<br />
y el error que se produce en la predicción (confianza en la predicción, o<br />
predictibilidad). Esta relación indica que el rango <strong>de</strong> errores posibles crece<br />
linealmente al crecer la dispersión (estos resultados se analizan con más<br />
<strong>de</strong>talle en Cofiño et al., 2003a).
126 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
D+1 D+2 D+3<br />
0<br />
0 1 2 3<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
0 2 4<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
0 2 4<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
D+4 D+5 D+6<br />
1 2 3 4 5<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
2 4 6<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
2 4 6<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
D+7 D+8 D+9<br />
0<br />
2 4 6<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
2 4 6<br />
Dispersión<br />
BS<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
2 4 6<br />
Dispersión<br />
Figura 6.10: Brier Score (BS) <strong>de</strong> la predicción local realizada con el conjunto <strong>de</strong><br />
predicciones frente a la medida <strong>de</strong> dispersión (<strong>de</strong>sviación típica mas entropía) para<br />
alcances entre uno y nueve días. Los BS representados son las medias para todas<br />
la estaciones principales <strong>de</strong> la Cuenca Norte.<br />
6.5. Predicción Mensual y Estacional<br />
En secciones anteriores el objetivo <strong>de</strong> la predicción a corto y medio plazo<br />
era estimar numérica o probabilísticamente el valor <strong>de</strong> una cierta variable<br />
atmosférica con una anticipación <strong>de</strong> entre uno y nueve días. Este es el límite<br />
que se suele fijar como umbral <strong>de</strong> predictibilidad <strong>de</strong> la atmósfera 1 , ya que a<br />
tiempos superiores, la no-linealidad <strong>de</strong> los mo<strong>de</strong>los <strong>de</strong> circulación atmosférica,<br />
junto con los errores asociados a las observaciones y las aproximaciones<br />
<strong>de</strong> los mo<strong>de</strong>los utilizados, impi<strong>de</strong>n una predicción numérica acertada. Por<br />
tanto, en principio, los términos “predicción mensual” o “predicción estacional”<br />
pue<strong>de</strong>n parecer incorrectos. Sin embargo, aunque no es posible precisar<br />
el valor concreto <strong>de</strong> una cierta variable con una antelación <strong>de</strong> un mes (o<br />
un trimestre), en ocasiones sí resulta posible dar algún tipo <strong>de</strong> información<br />
útil asociada a la misma; por ejemplo, se podría tratar <strong>de</strong> pre<strong>de</strong>cir si el<br />
valor medio <strong>de</strong>l siguiente mes, o trimestre, será significativamente inferior<br />
o superior a la media climatológica correspondiente (es <strong>de</strong>cir, hablando en<br />
términos <strong>de</strong> precipitación, si se espera un mes o estación más húmeda o<br />
1 El límite <strong>de</strong> la predicción a medio plazo (o la predictibilidad <strong>de</strong> la atmósfera, en otras<br />
palabras) no es un valor fijo que haya sido obtenido teóricamente (obsérvese que a<strong>de</strong>más<br />
este valor oscilará temporal y espacialmente). Sin embargo, se suele consi<strong>de</strong>rar entre 10 y<br />
15 días para fines prácticos <strong>de</strong> la predicción operativa.
6.5. PREDICCIÓN MENSUAL Y ESTACIONAL 127<br />
4<br />
2<br />
0<br />
−2<br />
−4<br />
1900 1905 1910 1915 1920 1925 1930 1935 1940 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000<br />
Figura 6.11: Índice <strong>de</strong> Oscilación <strong>de</strong>l Sur (SOI) durante el siglo XX. El índice <strong>de</strong><br />
un mes se <strong>de</strong>fine como (T − D)/s, don<strong>de</strong> T y D son las anomalías mensuales en<br />
Taití y Darwin, respectivamente y S es la varianza <strong>de</strong> T − D para el mes dado.<br />
seca <strong>de</strong> lo normal). Así pues, en este tipo <strong>de</strong> predicciones, se trabaja con<br />
anomalías (estimaciones <strong>de</strong> <strong>de</strong>sviaciones mensuales, o trimestrales, respecto<br />
<strong>de</strong> la climatología) o con su carácter (positivo, normal, o negativo) y no con<br />
valores concretos <strong>de</strong> las variables.<br />
La razón <strong>de</strong> esta predictibilidad estacional es la existencia <strong>de</strong> patrones<br />
sinópticos persistentes, que influyen en la circulación atmosférica a gran<br />
escala, durante largos períodos <strong>de</strong> tiempo. Algunos <strong>de</strong> estos patrones son<br />
dipolares y su estado (positivo o negativo) se pue<strong>de</strong> caracterizar en base a<br />
un índice. Ejemplos <strong>de</strong> estos patrones son:<br />
NAO (North Atlantic Oscillation) (Wanner et al., 2001), característica<br />
<strong>de</strong> latitu<strong>de</strong>s medias y asociada a un patrón alta/baja presión en<br />
Islandia - baja/alta presión en las Azores (ver Capítulo 3, Fig. 3.1).<br />
Este patrón suele <strong>de</strong>finirse a través <strong>de</strong> un índice que caracteriza su fase<br />
y que es obtenido como la diferencia <strong>de</strong> presiones a nivel <strong>de</strong>l mar en<br />
ambos puntos (o como la componente principal asociada a la primera<br />
EOF <strong>de</strong> la presión en 500 mb <strong>de</strong>l Atlántico Norte; ver Capítulo 3, Figs.<br />
3.2 y 3.3).<br />
La NAO posee una marcada variabilidad interanual lo cual posibilita<br />
una hipotética predicción estacional. A causa <strong>de</strong> su notable impacto<br />
sobre el tiempo y clima <strong>de</strong> Europa, existe un creciente interés en <strong>de</strong>terminar<br />
su predictibilidad estacional e interanual. Por <strong>de</strong>sgracia la NAO<br />
es un fenómeno <strong>de</strong> latitu<strong>de</strong>s medias muy ruidoso, con un espectro <strong>de</strong><br />
potencias casi plano, muy parecido a un ruido blanco, <strong>de</strong> manera que<br />
incluso las predicciones posibles con mo<strong>de</strong>los estadísticos, reproducen<br />
sólo un pequeño rango <strong>de</strong> la varianza total (Wunsch, 1999). Por tanto,<br />
un problema <strong>de</strong> es la predicción <strong>de</strong> este patrón, con mo<strong>de</strong>los <strong>de</strong><br />
circulación atmosférica.<br />
ENSO (El Niño-Southern Oscillation) (Philan<strong>de</strong>r, 1990) es un fenómeno<br />
tropical <strong>de</strong>l Pacífico Sur (ver Capítulo 3, Fig. 3.1) caracterizado por<br />
un calentamiento <strong>de</strong>l agua <strong>de</strong> la superficie <strong>de</strong>l Pacífico central y Este<br />
y por la variación a gran escala asociada <strong>de</strong>l sistema <strong>de</strong> presión<br />
atmosférica <strong>de</strong>l trópico (<strong>de</strong>nominado Oscilación <strong>de</strong>l Sur, SO). Este pa-
128 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
Figura 6.12: Precipitación en el Pacífico durante el episodio fuerte <strong>de</strong> El Niño<br />
(Enero-Marzo <strong>de</strong> 1998). La figura izquierda muestra la precipitación total y la<br />
figura <strong>de</strong>recha la <strong>de</strong>sviación en tanto por uno <strong>de</strong>l valor medio (FUENTE: NCEP)<br />
trón se caracteriza tradicionalmente basándose en las diferencias en las<br />
anomalías en la presión <strong>de</strong>l aire entre Tahiti y Darwin. La variabilidad<br />
<strong>de</strong> este índice se muestra en la Fig. 6.11.<br />
El ciclo ENSO tiene un periodo medio <strong>de</strong> cuatro años, aproximadamente,<br />
aunque en el registro histórico, el periodo ha variado entre dos<br />
y siete años. Entre 1980 y 1990 <strong>de</strong>stacó un ciclo ENSO muy activo, con<br />
cinco episodios <strong>de</strong> El Niño,(1982/83, 1986/87, 1991 −1993, 1994/95, y<br />
1997/98) y tres episodios <strong>de</strong> La Niña (1984/85, 1988/89, 1995/96). En<br />
este periodo también tuvieron lugar dos <strong>de</strong> los episodios más fuertes<br />
<strong>de</strong>l siglo (1982/83 y 1997/98), así como dos periodos consecutivos <strong>de</strong><br />
las condiciones <strong>de</strong> El Niño durante 1991 − 1995 sin una intervención<br />
<strong>de</strong> episodio frío. El episodio más fuerte y reciente <strong>de</strong> La Niña fue en<br />
1988/89, y entre las consecuencias más graves <strong>de</strong>l fenómeno <strong>de</strong> El Niño,<br />
están un fuerte incremento <strong>de</strong> las lluvias producidas sobre el sur <strong>de</strong> los<br />
EEUU y en Perú, lo que provoca <strong>de</strong>structivas inundaciones, así como<br />
sequías en el Pacífico Oeste, a veces asociadas a gran<strong>de</strong>s incendios en<br />
Australia. Por ejemplo, la Fig. 6.12 muestra los efectos <strong>de</strong> El Niño<br />
1998 sobre la precipitación en el Pacífico.<br />
En la Tabla 6.1 <strong>de</strong> citan algunos <strong>de</strong> los patrones mas importantes(para<br />
más <strong>de</strong>talles ver www.cpc.ncep.noaa.gov/products).<br />
A<strong>de</strong>más <strong>de</strong> estos patrones, se han <strong>de</strong>scubierto distintas teleconexiones<br />
entre ellos, que inter-relacionan, <strong>de</strong> forma compleja, sus efectos globales<br />
sobre la circulación atmosférica, en distintas regiones <strong>de</strong>l globo (ver, por<br />
ejemplo, Mo and Livezey, 1986).<br />
Los avances producidos en las técnicas <strong>de</strong> predicción por conjuntos han<br />
dado un enorme impulso a los mo<strong>de</strong>los acoplados océano-atmósfera, <strong>de</strong> predicción<br />
estacional, que actualmente permiten pre<strong>de</strong>cir con cierta fiabilidad<br />
anomalías mensuales o estacionales durante ciertas épocas y en ciertas regiones<br />
<strong>de</strong>l globo (asociadas principalmente a anomalías en la ENSO). Estos<br />
resultados han motivado la puesta en marcha operativa, <strong>de</strong> distintos produc-
6.5. PREDICCIÓN MENSUAL Y ESTACIONAL 129<br />
Índice<br />
EA<br />
EAJET<br />
WP<br />
EP<br />
NP<br />
PNA<br />
EA/WR<br />
SCA<br />
TNH<br />
POL<br />
PT<br />
SZ<br />
ASU<br />
Descripción<br />
Patrón <strong>de</strong>l Atlántico Este<br />
Patrón <strong>de</strong>l chorro <strong>de</strong>l Atlántico Este<br />
Patrón <strong>de</strong>l Pacífico Oeste<br />
Patrón <strong>de</strong>l Pacífico Este<br />
Patrón <strong>de</strong>l Pacífico Norte<br />
Patrón Pacífico-NorteAmérica<br />
Patrón <strong>de</strong>l Atlántico Este-Rusia Oeste<br />
Patrón Escandinavia<br />
Patrón Tropical <strong>de</strong>l Hemisferio Norte<br />
Patrón Polar-Eurasia<br />
Patrón <strong>de</strong> Transición <strong>de</strong>l Pacífico<br />
Patrón Subtropical zonal<br />
Patrón <strong>de</strong> Verano <strong>de</strong> Asia<br />
Tabla 6.1: Algunos patrones atmosféricos más importantes (para más <strong>de</strong>talle<br />
ver www.cpc.ncep.noaa.gov/products).<br />
tos <strong>de</strong> predicción estacional en distintos centros internacionales. Por ejemplo,<br />
el mo<strong>de</strong>lo System-II <strong>de</strong>l ECMWF produce predicciones estacionales operativas.<br />
Asimismo también se dispone <strong>de</strong> un re-análisis (DEMETER), <strong>de</strong> un<br />
conjunto <strong>de</strong> seis mo<strong>de</strong>los Europeos globales <strong>de</strong> predicción por conjuntos con<br />
distintos esquemas <strong>de</strong> perturbación (www.ecmwf.int/research/<strong>de</strong>meter/)<br />
(Palmer et al., 2003).<br />
No sólo se ha puesto <strong>de</strong> manifiesto la posibilidad <strong>de</strong> pre<strong>de</strong>cir en cierta<br />
medida los patrones estacionales <strong>de</strong> circulación sinóptica, sino que también,<br />
se ha mostrado su asociación con anomalías regionales y locales <strong>de</strong> precipitación,<br />
y <strong>de</strong> temperatura, tanto <strong>de</strong> la NAO como <strong>de</strong> la ENSO (ver, por<br />
ejemplo, Hurrell, 1995; Rodríguez-Fonseca and Serrano, 1991). Por ejemplo,<br />
si se consi<strong>de</strong>ra por una parte la temperatura media mensual <strong>de</strong>l agua <strong>de</strong>l<br />
mar (SST) frente a la costa <strong>de</strong> Chicama en el Norte <strong>de</strong> Perú (representante<br />
<strong>de</strong> la oscilación sinóptica <strong>de</strong>l ENSO), la precipitación en la ciudad <strong>de</strong> Piura<br />
(medias mensuales) y el caudal <strong>de</strong>l río Piura, se pue<strong>de</strong> comprobar fácilmente<br />
que existe una relación entre estas variables, que permite trasladar anomalías<br />
Precip. Piura (mm/mes)<br />
1000<br />
500<br />
0<br />
14 16 18 20 22 24 26 28<br />
SST Chicama (ºC)<br />
Figura 6.13: Precipitación mensual media en la ciudad <strong>de</strong> Piura (Perú) vs. temperatura<br />
media mensual <strong>de</strong> la superficie <strong>de</strong>l agua <strong>de</strong>l mar frente a la costa <strong>de</strong> Chicama.
130 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
sinópticas a anomalías locales (ver Fig. 6.13). Sin embargo, los efectos en<br />
otras regiones cercanas son distintos e incluso opuestos (épocas <strong>de</strong> sequía<br />
asociadas con los episodios fuertes <strong>de</strong> El Niño en la sierra <strong>de</strong> Perú y en el<br />
altiplano).<br />
Con este ejemplo se pone <strong>de</strong> manifiesto la utilidad <strong>de</strong> disponer <strong>de</strong> técnicas<br />
<strong>de</strong> downscaling, que permitan trasladar las anomalías predichas por los<br />
mo<strong>de</strong>los estacionales a anomalías regionales y locales <strong>de</strong> variables <strong>de</strong> interés<br />
para la actividad humana.<br />
6.5.1. Predicción Local <strong>de</strong> Precipitación durante El Niño<br />
Una dificultad para realizar estudios <strong>de</strong> predicción local a partir <strong>de</strong> predicciones<br />
mensuales y estacionales es que, hasta la fecha, no se disponía<br />
<strong>de</strong> una base <strong>de</strong> datos con predicciones durante un período <strong>de</strong> tiempo suficientemente<br />
representativo. Durante los últimos años, el proyecto Europeo<br />
DEMETER ha creado una base <strong>de</strong> datos con las predicciones estacionales<br />
<strong>de</strong> seis mo<strong>de</strong>los acoplados atmósfera-océano con nueve miembros en cada<br />
caso (obtenidos aplicando distintos esquemas perturbativos). Para ello se ha<br />
utilizado información <strong>de</strong>l re-análisis ERA-40 (1957-2002). Los mo<strong>de</strong>los estacionales<br />
se inicializan con los datos <strong>de</strong> ERA40 cuatro veces al año (Febrero,<br />
Mayo, Agosto y Noviembre) y son integrados para un alcance <strong>de</strong> seis meses,<br />
almacenando las variables que proporcionan una <strong>de</strong>tallada <strong>de</strong>scripción <strong>de</strong> la<br />
atmósfera predicha día a día. En esta sección se realiza un estudio sistemático<br />
<strong>de</strong> la predictibilidad estacional en latitu<strong>de</strong>s tropicales, teniendo en cuenta<br />
el fenómeno <strong>de</strong> El Niño.<br />
80 ° W<br />
60 ° W<br />
40 ° W<br />
°<br />
Sausal <strong>de</strong><br />
Culucán<br />
Morropón<br />
20 ° S<br />
40 ° S<br />
60 ° S<br />
Figura 6.14: Localización geográfica <strong>de</strong> Perú y <strong>de</strong> las dos estaciones que se utilizan<br />
en este trabajo.
6.5. PREDICCIÓN MENSUAL Y ESTACIONAL 131<br />
5<br />
0<br />
5<br />
10<br />
15<br />
20<br />
(a)<br />
90 85 80 75 70<br />
5<br />
5<br />
0<br />
0<br />
5<br />
5<br />
10<br />
10<br />
15<br />
(b)<br />
20<br />
85 80 75 70 65<br />
15<br />
(c)<br />
20<br />
85 80 75 70 65<br />
Figura 6.15: Rejillas consi<strong>de</strong>radas para la <strong>de</strong>finición <strong>de</strong>l patrón atmosférico en la<br />
zona Norte <strong>de</strong> Perú.<br />
Para ello, se consi<strong>de</strong>ra la región Norte <strong>de</strong> Perú que se muestra en la Fig.<br />
6.14, don<strong>de</strong> se dispone <strong>de</strong> datos diarios <strong>de</strong> precipitación para dos estaciones:<br />
Sausal <strong>de</strong> Culucán y Morropón.<br />
Para aplicar la técnica basada en re<strong>de</strong>s auto-organizativas <strong>de</strong>scrita en<br />
la Sec. 6.3 se consi<strong>de</strong>ran distintas rejillas sobre la zona <strong>de</strong> interés <strong>de</strong> diferentes<br />
resoluciones y coberturas (ver Fig. 6.15). Sobre cada una <strong>de</strong> ellas se<br />
entrenaron distintas re<strong>de</strong>s auto-organizativas con los patrones <strong>de</strong> re-análisis<br />
<strong>de</strong>l período 1957-2002. Una vez realizado todo el estudio se comprobó que,<br />
<strong>de</strong> nuevo, los mejores resultado se obtuvieron con el patrón local (en este<br />
con la rejilla dinámica <strong>de</strong> la Fig. 6.15(c)). Por ejemplo, la Fig. 6.16 muestra<br />
los histogramas fenomenológicos <strong>de</strong>finidos por la precipitación observada en<br />
8<br />
7<br />
6<br />
5<br />
4<br />
3<br />
2<br />
(a) Morropón<br />
25<br />
20<br />
15<br />
10<br />
5<br />
1 0 1<br />
1 2 3 4 5 6 7 8<br />
1 2 3 4 5 6 7 8<br />
8<br />
7<br />
6<br />
5<br />
4<br />
3<br />
2<br />
(b) Sausal <strong>de</strong> Culucán<br />
2.5<br />
2.0<br />
1.5<br />
1.0<br />
0.5<br />
0<br />
Precip (mm/day)<br />
Figura 6.16: Histogramas fenomenológicos <strong>de</strong> la precipitación en (a) Morropón y<br />
(b) Sausal <strong>de</strong> Culucán obtenidos sobre una SOM (el valor <strong>de</strong> cada grupo se obtiene<br />
como el promedio <strong>de</strong> los días pertenecientes al grupo).
132 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
1979<br />
...<br />
1993<br />
CIRCULATION<br />
PATTERNS<br />
DATABASE<br />
ERA15<br />
reanalisys<br />
1979-1993<br />
CLUSTERING<br />
C 1 , ..., C m<br />
SELF-ORGANIZING<br />
MAP (SOM)<br />
Topological arrangement<br />
in a 2D lattice (e.g. m=36)<br />
C1 C2 ...<br />
DEMETER<br />
multi-mo<strong>de</strong>l<br />
GCM FORECAST<br />
UKMO ECMWF MPI CNRM<br />
5535 PATTERNS<br />
f1 f 2 ...<br />
f1 f 2 ...<br />
f1 f 2 ...<br />
f1 f 2 ...<br />
C36<br />
1979<br />
f36<br />
f36<br />
f36<br />
f36<br />
...<br />
1993<br />
Daily rainfall<br />
observations<br />
LOCAL CLIMATE<br />
RECORDS DATABASE<br />
Estimation for<br />
each cluster<br />
and station:<br />
y 1 , ..., y m<br />
LOCAL FORECAST<br />
Figura 6.17: Esquema <strong>de</strong> downscaling para DEMETER. Cada mo<strong>de</strong>lo produce 9<br />
patrones atmosféricos diarios durante un período <strong>de</strong> seis meses.<br />
cada una <strong>de</strong> las estaciones sobre una SOM entrenada con la rejilla local.<br />
Estas dos “huellas digitales” muestran las distintas formas <strong>de</strong> llover que se<br />
producen en dos estaciones tan cercanas.<br />
En este trabajo se utilizan sólo los mo<strong>de</strong>los <strong>de</strong>l ECMWF, Météo France,<br />
UKMet Office y Max Plank Institute <strong>de</strong> DEMETER, con nueve miembros<br />
en cada uno. Dado que el fenómeno <strong>de</strong> El Niño tiene especial inci<strong>de</strong>ncia<br />
en el Norte <strong>de</strong> Perú a principios <strong>de</strong> año, se consi<strong>de</strong>ran las predicciones <strong>de</strong><br />
los mo<strong>de</strong>los realizadas en Noviembre para el trimestre Diciembre-Febrero;<br />
por tanto, se tratan <strong>de</strong> pre<strong>de</strong>cir las anomalías locales <strong>de</strong> precipitación a<br />
partir <strong>de</strong> predicciones obtenidas entre uno y tres meses <strong>de</strong> anticipación.<br />
En este caso, se tienen varias opciones para combinar esta información. Se<br />
pue<strong>de</strong> consi<strong>de</strong>rar cada mo<strong>de</strong>lo por separado y añadir un nuevo mo<strong>de</strong>lo, que<br />
consiste en la mezcla <strong>de</strong> todos (multi-mo<strong>de</strong>lo), y luego comparar la eficiencia<br />
<strong>de</strong> todos los mo<strong>de</strong>los frente al multi-mo<strong>de</strong>lo. La Fig. 6.17 muestra el proceso<br />
seguido en este caso.<br />
En la Fig. 6.18 se muestran los resultados obtenidos. Para cada trimestre<br />
Diciembre-Febrero <strong>de</strong> cada año <strong>de</strong>l período 1983-1998 se consi<strong>de</strong>raron las<br />
predicciones obtenidas para los 90 días por cada miembro <strong>de</strong> cada mo<strong>de</strong>lo.<br />
Por tanto, cada trimestre se obtuvieron 9 predicciones para cada mo<strong>de</strong>lo <strong>de</strong><br />
las cuales se obtuvo el valor promedio, que es consi<strong>de</strong>rado como la predicción<br />
<strong>de</strong>l mo<strong>de</strong>lo; por otra parte, se consi<strong>de</strong>ró la predicción conjunta dada por<br />
todos los mo<strong>de</strong>los (la media <strong>de</strong> las predicciones <strong>de</strong> cada uno <strong>de</strong> los mo<strong>de</strong>los).<br />
La observación real (cuando está disponible) se muestra en la línea central<br />
con un cuadrado, mientras que la predicción <strong>de</strong>l multi-mo<strong>de</strong>lo se muestra<br />
con una cruz. Las cajas muestran los respectivos cuartiles <strong>de</strong> precipitación en
6.5. PREDICCIÓN MENSUAL Y ESTACIONAL 133<br />
15<br />
10<br />
5<br />
0<br />
200<br />
100<br />
0<br />
MORROPON<br />
Observation<br />
Multi-mo<strong>de</strong>l forecast<br />
ECMWF forecast<br />
UK MetOffice forecast<br />
MPI forecast<br />
CNRM forecast<br />
Analysis: Nov.<br />
Forecast: Dec,Jan,Feb<br />
(missing data)<br />
79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99<br />
SAUSAL DE CULUCAN<br />
79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99<br />
mm (daily)<br />
mm<br />
(DJF average<br />
daily values)<br />
10<br />
5<br />
mm<br />
(DJF average<br />
daily values)<br />
0<br />
200<br />
100<br />
0<br />
Analysis: Nov.<br />
Forecast: Dec,Jan,Feb<br />
mm (daily)<br />
Figura 6.18: Predicción local <strong>de</strong> precipitación en Morropón y Sausal <strong>de</strong> Culucán<br />
para los cuatro mo<strong>de</strong>los y para el multi-mo<strong>de</strong>lo en el período 1983-1998.
134 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
la estación consi<strong>de</strong>rada, para todo el período <strong>de</strong> estudio. Por tanto, cuando<br />
la predicción está por encima <strong>de</strong> cuartil 75, o por <strong>de</strong>bajo <strong>de</strong>l 25, se consi<strong>de</strong>ra<br />
que se está prediciendo una anomalía positiva, o negativa, <strong>de</strong> precipitación,<br />
respectivamente. A partir <strong>de</strong> esta figura se pue<strong>de</strong> observar que el sistema<br />
predice con acierto la anomalía positiva <strong>de</strong> precipitación durante los dos<br />
episodios <strong>de</strong> El Niño fuertes <strong>de</strong> los años 1982/83 y 1997/98.<br />
A<strong>de</strong>más también se ha probado que durante estos dos episodios <strong>de</strong> El<br />
Niño, se podía pre<strong>de</strong>cir la anomalía positiva con mayor anticipación. Por<br />
ejemplo, la Fig. 6.19 muestra las situaciones predichas para los trimestres<br />
Diciembre-Febrero <strong>de</strong> los años 1982/83 y 1997/98 en las estaciones <strong>de</strong> Morropón<br />
y Sausal <strong>de</strong> Culucán, con una anticipación <strong>de</strong> 4-6 meses (predicción<br />
<strong>de</strong> Agosto). En estas figuras pue<strong>de</strong> observarse que sólo el mo<strong>de</strong>lo Francés<br />
CNRM y el multi-mo<strong>de</strong>lo son capaces <strong>de</strong> pre<strong>de</strong>cir la anomalía <strong>de</strong> precipitación<br />
para el año 1982/83 en la estación <strong>de</strong> Morropón, mientras que todos los<br />
mo<strong>de</strong>los proporcionan el valor correcto <strong>de</strong> la anomalía para el año 1997/98<br />
(ver Cofiño et al., 2003d, para más información).<br />
DJF83<br />
DJF98<br />
DJF83<br />
DJF98<br />
Figura 6.19: Predicción local <strong>de</strong> precipitación en Morropón y Sausal <strong>de</strong> Culucán<br />
para los cuatro mo<strong>de</strong>los y para el multi-mo<strong>de</strong>lo en los períodos 1982/83 y 1997/98<br />
obtenidos con la predicción <strong>de</strong> Agosto <strong>de</strong> los mo<strong>de</strong>los (4 meses <strong>de</strong> anticipación).<br />
De forma análoga al estudio realizado en el caso <strong>de</strong> predicción a medio<br />
plazo para caracterizar la predictibilidad <strong>de</strong> las predicciones, en este se<br />
consi<strong>de</strong>ran las probabilida<strong>de</strong>s <strong>de</strong>finidas en la SOM por cada uno <strong>de</strong> los mo<strong>de</strong>los.<br />
La Fig. 6.20 muestra los histogramas <strong>de</strong>finidos sobre la SOM por los
6.5. PREDICCIÓN MENSUAL Y ESTACIONAL 135<br />
DEMETER DJF. H=1.9702<br />
8<br />
6<br />
DEMETER DJF90. H= 2.675<br />
8<br />
6<br />
DEMETER DJF98. H=2.151<br />
8<br />
6<br />
4<br />
4<br />
4<br />
2<br />
2 4 6 8<br />
2<br />
2 4 6 8<br />
2<br />
2 4 6 8<br />
8<br />
SCWF DJF<br />
8<br />
SCWF DJF90<br />
8<br />
SCWF DJF98<br />
6<br />
6<br />
6<br />
4<br />
4<br />
4<br />
2<br />
2<br />
2<br />
8<br />
2 4 6 8<br />
SMPI DJF<br />
8<br />
2 4 6 8<br />
SMPI DJF90<br />
8<br />
2 4 6 8<br />
SMPI DJF98<br />
6<br />
6<br />
6<br />
4<br />
4<br />
4<br />
2<br />
2<br />
2<br />
8<br />
2 4 6 8<br />
UKMO DJF<br />
8<br />
2 4 6 8<br />
UKMO DJF90<br />
8<br />
2 4 6 8<br />
UKMO DJF98<br />
6<br />
6<br />
6<br />
4<br />
4<br />
4<br />
2<br />
2<br />
2<br />
2 4 6 8<br />
2 4 6 8<br />
2 4 6 8<br />
8<br />
CNRM DJF<br />
8<br />
CNRM DJF90<br />
8<br />
CNRM DJF98<br />
6<br />
6<br />
6<br />
4<br />
4<br />
4<br />
2<br />
2<br />
2<br />
2 4 6 8<br />
2 4 6 8<br />
2 4 6 8<br />
Figura 6.20: Histogramas <strong>de</strong>finidos sobre la SOM por los patrones previstos para<br />
el periodo Diciembre-Febrero por el multi-mo<strong>de</strong>lo DEMETER (primera fila) y<br />
cada uno <strong>de</strong> los cuatro mo<strong>de</strong>los individuales. La columna <strong>de</strong> la izquierda muestra<br />
la climatología (periodo 1983-1998); la columna central muestra un año no Niño<br />
(similar a la climatología); la columna <strong>de</strong> la <strong>de</strong>recha muestra el trimestre <strong>de</strong> un año<br />
Niño. En la primera fila se muestran las entropías <strong>de</strong> cada probabilidad.
136 6. PREDICCIÓN POR CONJUNTOS. REDES AUTO-ORGANIZATIVAS<br />
5<br />
4<br />
Entropía relativa<br />
3<br />
2<br />
1<br />
0<br />
82 84 86 88 90 92 94 96 98<br />
Figura 6.21: Entropía relativa <strong>de</strong> cada mo<strong>de</strong>lo cada año respecto a la climatología<br />
<strong>de</strong> DEMETER. Los colores <strong>de</strong> los mo<strong>de</strong>los son los mismos que en figuras anteriores.<br />
Año<br />
patrones previstos para el periodo Diciembre-Febrero por el multi-mo<strong>de</strong>lo<br />
DEMETER (primera fila) y cada uno <strong>de</strong> los cuatro mo<strong>de</strong>los individuales<br />
con 1-3 meses <strong>de</strong> anticipación. La columna <strong>de</strong> la izquierda muestra la climatología<br />
(periodo 1983-1998); la columna central muestra el año no Niño<br />
1989/90 (similar a la climatología); la columna <strong>de</strong> la <strong>de</strong>recha muestra el<br />
trimestre <strong>de</strong>l año Niño 1997/98. La Fig. 6.21 muestra la entropía relativa<br />
<strong>de</strong>l histograma <strong>de</strong> cada mo<strong>de</strong>lo respecto al histograma <strong>de</strong> la climatología <strong>de</strong><br />
DEMETER. En esta figura se pue<strong>de</strong> comprobar que este índice es un buen<br />
indicador <strong>de</strong> la predictibilidad <strong>de</strong> cada situación.<br />
Por último, indicar que un estudio <strong>de</strong> la aplicación <strong>de</strong> esta técnica en<br />
latitu<strong>de</strong>s medias se tienen en (Díaz et al., 2003).
CAPÍTULO 7<br />
Implementación Operativa. El Sistema PROMETEO<br />
7.1. Introducción<br />
En capítulos anteriores se han <strong>de</strong>scrito los aspectos teóricos <strong>de</strong> la predicción<br />
local probabilística en el corto plazo (Cap. 5) y <strong>de</strong> la aplicación <strong>de</strong> las<br />
re<strong>de</strong>s auto-organizativas a la interpretación <strong>de</strong> la predicción por conjuntos<br />
y más concretamente, a la predicción estacional (Cap. 6). En esos capítulos<br />
se ha mostrado la vali<strong>de</strong>z científica <strong>de</strong> los métodos presentados y también<br />
su utilidad práctica en la predicción operativa. Para ello, se han aplicado<br />
los métodos <strong>de</strong>scritos en estos capítulos a la salida <strong>de</strong> mo<strong>de</strong>los numéricos<br />
operativos (ECMWF y HIRLAM) y a diferentes re<strong>de</strong>s <strong>de</strong> observación (INM<br />
y Perú). A<strong>de</strong>más se han validado los resultados obtenidos, comparándolos<br />
con los <strong>de</strong> otros productos operativos existentes. Todos los algoritmos, <strong>de</strong> los<br />
métodos propuestos en estos capítulos, se han implementado utilizando el<br />
paquete <strong>de</strong> cálculo científico Matlab (por sus prestaciones gráficas y científicas,<br />
como se muestra, por ejemplo, en Middleton (2000)) y aquellas partes<br />
que exigen mayor carga computacional se han codificado en C, para luego<br />
po<strong>de</strong>r ser utilizadas <strong>de</strong>s<strong>de</strong> Matlab, <strong>de</strong>bido a que Matlab posee esta facilidad.<br />
Todo ello siempre sobre la i<strong>de</strong>a <strong>de</strong> que el producto final sea genérico, fácilmente<br />
adaptable, que pueda ser integrado fácilmente en el ciclo operativo<br />
<strong>de</strong> producción <strong>de</strong> cualquier centro meteorológico y aplicado a un problema<br />
particular que pueda tener cualquier usuario. Todos estos algoritmos han<br />
sido codificados en un conjunto <strong>de</strong> herramientas para Matlab, <strong>de</strong>nominado<br />
MeteoLab y que se <strong>de</strong>scribe en Sección 7.3, a este conjunto se le pue<strong>de</strong> consi<strong>de</strong>rar<br />
como el núcleo científico que nos permite diseñar diferentes tipos <strong>de</strong><br />
experimentos, para luego su aplicación operativa.<br />
Sin embargo, para que los resultados prácticos <strong>de</strong> esta Tesis tengan máxima<br />
divulgación y sean <strong>de</strong> utilidad para los distintos usuarios y sectores <strong>de</strong><br />
producción (agrario, industrial, energético, turismo, etc.), se ha optado por<br />
137
138 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
la Web como medio <strong>de</strong> divulgación, <strong>de</strong>bido a su gran difusión en la sociedad,<br />
y ser el medio idóneo para este objetivo. Para ello se ha hecho necesario<br />
crear una aplicación Web con la que se puedan consultar las predicciones en<br />
tiempo real y estas puedan ser validadas para un problema dado, <strong>de</strong> forma<br />
que se pueda comprobar la utilidad <strong>de</strong>l sistema. A<strong>de</strong>más, se ha hecho uso<br />
<strong>de</strong> las tecnologías más utilizadas actualmente en Internet que, por una parte,<br />
permiten acce<strong>de</strong>r a bases <strong>de</strong> datos (que almacenarían las predicciones)<br />
y, por otra, permiten ejecutar la aplicación con unos parámetros concretos<br />
<strong>de</strong> interés (región geográfica, patrón atmosférico, etc...) obteniendo las<br />
predicciones como resultado. En la Sec. 7.2.3 se <strong>de</strong>scribe este <strong>de</strong>sarrollo.<br />
Si a<strong>de</strong>más <strong>de</strong> enten<strong>de</strong>r la Web como un medio <strong>de</strong> divulgación, se entien<strong>de</strong><br />
como un medio <strong>de</strong> compartir recursos (potencia <strong>de</strong> cálculo y almacenamiento),<br />
en la que existen productores y consumidores <strong>de</strong> estos recursos, emerge<br />
lo que actualmente se <strong>de</strong>nomina Tecnología GRID, cuyo objetivo es dar soporte<br />
a esta interacción entre productores y consumidores. Bajo esta i<strong>de</strong>a<br />
se han llevado a cabo los primeros experimentos con la tecnología GRID<br />
para permitir una interacción en tiempo real con el sistema, paralelizando<br />
aquellas partes más costosas (componentes principales, agrupamiento, etc.)<br />
y permitiendo el acceso a bases <strong>de</strong> datos distribuidas. Estos experimentos<br />
son <strong>de</strong>scritos en la Sección 7.5.<br />
Todos estos componentes están englobados por un sistema <strong>de</strong>nominado<br />
Prometeo, y cuyo principal fundamento es la organización tanto <strong>de</strong> los datos,<br />
como <strong>de</strong> los procesos que intervienen y <strong>de</strong> todo el flujo <strong>de</strong> información<br />
que intervienen en cualquier experimento o funcionamiento operativo. Como<br />
ejemplo global <strong>de</strong>l sistema, que nos ayudará a enten<strong>de</strong>r su estructura, en la<br />
Sección 7.2 se <strong>de</strong>scribe, la adaptación hecha en colaboración con el Instituto<br />
Nacional <strong>de</strong> Meterología (INM) para la predicción local diaria en una<br />
red <strong>de</strong> 2500 estaciones en la Península, Baleares y Canarias. Esta aplicación<br />
forma parte <strong>de</strong>l ciclo operativo que tiene lugar en el INM y genera diariamente<br />
predicciones operativas con los mo<strong>de</strong>los que se utilizan en el INM<br />
(HIRLAM, con sus respectivas pasadas <strong>de</strong> la 00UTC y 12UTC con alcances<br />
<strong>de</strong> D+0 y D+1 y los alcances <strong>de</strong> D+2 y D+3 <strong>de</strong>l mo<strong>de</strong>lo operativo <strong>de</strong>l<br />
ECMWF cuya pasada es a las 12UTC). Con estas predicciones numéricas<br />
se realizan predicciones locales para las doce cuencas hidrográficas (diez en<br />
la Península, una para Baleares y otra en Canarias), cada una <strong>de</strong> las cuales<br />
tiene asociado su correspondiente patrón atmosférico. En total se realizan<br />
unas 162500 predicciones diarias (5 salidas numéricas, 2500 observatorios,<br />
y 13 predicciones para cada estación: 6 para precipitación y 7 meteoros). A<br />
la vista <strong>de</strong> la magnitud <strong>de</strong> los datos es evi<strong>de</strong>nte que, si el objetivo es que<br />
el sistema funcione en modo operativo interactivamente, es importante la<br />
organización y la estructura <strong>de</strong> los datos para un acceso rápido y eficiente.
7.2. ESTRUCTURA DE LA APLICACIÓN. SISTEMA OPERATIVO EN EL INM 139<br />
7.2. Estructura <strong>de</strong> la Aplicación. Sistema Operativo en el<br />
INM<br />
En esta sección se <strong>de</strong>scribe la estructura <strong>de</strong>l sistema PROMETEO<br />
(PROnóstico METEOrológico) utilizando como ejemplo la versión configurada<br />
para la predicción local diaria en el INM. Se comienza <strong>de</strong>scribiendo la<br />
fase <strong>de</strong> preproceso y las tareas involucradas, y se finaliza con el sistema <strong>de</strong><br />
consulta Web para predicciones operativas. Para evitar problemas <strong>de</strong> confusión<br />
en la <strong>de</strong>scripción <strong>de</strong>l sistema, usaremos únicamente las salidas <strong>de</strong>l<br />
mo<strong>de</strong>lo operativo y el re-análisis ERA-15 <strong>de</strong>l ECMWF. A<strong>de</strong>más, la base <strong>de</strong><br />
datos <strong>de</strong> observaciones estará limitada a aproximadamente 2500 estaciones<br />
operativas <strong>de</strong> la red secundaria <strong>de</strong>l INM. La Fig. 7.1 muestra la estructura<br />
global <strong>de</strong> la aplicación, <strong>de</strong>stacando sus cuatro módulos (A)-(D). En las<br />
siguientes secciones se <strong>de</strong>scriben en <strong>de</strong>talle cada uno <strong>de</strong> estos módulos.<br />
A<br />
SE SE<br />
ECMWF<br />
Reanálisis ERA<br />
B<br />
SE<br />
ECMWF SE<br />
Mo<strong>de</strong>lo operativo<br />
C<br />
operativo<br />
D+1<br />
D+2<br />
D+3<br />
1<br />
dominios<br />
CPLab<br />
2<br />
Cuenca Norte<br />
Cuenca Duero<br />
Cuenca Norte<br />
D+3<br />
Cuenca Duero<br />
D+3<br />
SE SE<br />
SE SĖ ..<br />
...<br />
cluster<br />
3<br />
Predicciones<br />
locales y validación<br />
Observaciones INM<br />
SE<br />
Precip. SE<br />
SE SE<br />
SE<br />
Nieve Tormenta SE<br />
Predicción<br />
Local<br />
D+3<br />
SE pred.<br />
locales<br />
4<br />
SE SE<br />
Validación<br />
5<br />
Validación<br />
D<br />
6<br />
Aplicación Web<br />
Figura 7.1: Estructura global <strong>de</strong> la aplicación PROMETEO con las etapas: (A)<br />
configuración, (B) producción operativa, (C) consulta a través <strong>de</strong> la Web, y (D)<br />
validación.<br />
7.2.1. Configuración e Inicialización <strong>de</strong>l Sistema<br />
En esta sección se <strong>de</strong>scribe la fase inicial <strong>de</strong> configuración y adaptación<br />
<strong>de</strong>l sistema a un entorno concreto (zona geográfica, variables, bases <strong>de</strong> datos,<br />
etc.). El sistema está basado en el método <strong>de</strong>scrito en la Sec. 5.4 y, por tanto,<br />
a ella se remite al lector para consultar <strong>de</strong>talles sobre los algoritmos. Más<br />
en concreto, en esta sección se <strong>de</strong>scriben los elementos que intervienen para<br />
configurar la aplicación para la predicción local en la red secundaria <strong>de</strong>l INM<br />
a partir <strong>de</strong> las predicciones numéricas <strong>de</strong>l ECMWF. En este módulo se utiliza<br />
la base <strong>de</strong> datos <strong>de</strong> re-análisis ERA-15 <strong>de</strong>l ECMWF, <strong>de</strong>scritas en la Sec. 2.7,<br />
que compren<strong>de</strong> el período 1979-1994 (5569 días en total). Primero, se <strong>de</strong>fine
140 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
el patrón que caracterizará el estado <strong>de</strong> la atmósfera para el problema en<br />
cuestión (tarea 1 en Fig. 7.2); a continuación en la tarea 2 se aplica el<br />
algoritmo <strong>de</strong> componentes principales (Sec. 3.2) para reducir la dimensión<br />
<strong>de</strong> los patrones y, finalmente, se aplica la técnica <strong>de</strong> agrupamiento apropiada<br />
sobre cada uno <strong>de</strong> los vectores <strong>de</strong> componentes principales obtenidos (tarea<br />
3). Este módulo es el que contiene el núcleo <strong>de</strong>l sistema y será necesario<br />
ejecutarlo cada vez que queramos para re-adaptarlo a un nuevo problema o<br />
a una nueva situación. Esta tarea se realizará una única vez, previamente a<br />
la fase operativa <strong>de</strong> la aplicación (la obtención diaria <strong>de</strong> predicciones).<br />
Cuenca Norte<br />
SE SE<br />
SE SE<br />
ECMWF<br />
Reanálisis ERA<br />
1<br />
dominios<br />
CPLab<br />
2<br />
Cuenca Duero<br />
SE SĖ ..<br />
cluster<br />
3<br />
Figura 7.2: Módulo <strong>de</strong> configuración e inicialización, con la <strong>de</strong>finición <strong>de</strong>l patrón<br />
atmosférico abarcando un dominio dado (tarea 1), la compresión <strong>de</strong> información<br />
aplicando componentes principales (2), y la ejecución <strong>de</strong> la técnica <strong>de</strong> agrupamiento<br />
apropiada (3).<br />
La figura 7.2 muestra esquemáticamente este módulo. En esta figura<br />
po<strong>de</strong>mos ver la base <strong>de</strong> datos <strong>de</strong> re-análisis y los 3 módulos siguientes:<br />
1. dominios. Es el encargado <strong>de</strong> extraer los datos necesarios para <strong>de</strong>finir<br />
el patrón atmosférico a partir <strong>de</strong> la base <strong>de</strong> datos <strong>de</strong> re-análisis y<br />
aglutinar la información en forma vectorial. En el Ejemplo 2.1 se había<br />
visto la forma <strong>de</strong> <strong>de</strong>finir un patrón atmosférico concreto ilustrando su<br />
aplicación sobre la península ibérica. En el Cap. 5 se mostró que los<br />
mejores resultados <strong>de</strong> predicción local se obtienen con un patrón 4D<br />
<strong>de</strong> área limitada. Por ello, consi<strong>de</strong>ramos 12 dominios distintos (uno<br />
para cada cuenca) tal como se muestra en la Fig. 7.3.<br />
Para ello se ha <strong>de</strong> especificar en un fichero <strong>de</strong> dominio la región geográfica<br />
<strong>de</strong> interés (cuadrícula longitud-latitud, resolución y nodos a<br />
incluir), las variables, las horas <strong>de</strong> análisis, y los niveles <strong>de</strong> presión<br />
(en la figura 7.4 se muestra un ejemplo <strong>de</strong> <strong>de</strong>finición <strong>de</strong> configuración<br />
atmosférica para la Cuenca Norte). Este es el fichero que usa como<br />
entrada el módulo “dominio”.<br />
Este fichero <strong>de</strong>fine un patrón atmosférico <strong>de</strong> 1 o <strong>de</strong> resolución en longitud<br />
y latitud; tres niveles en altura 1000mb, 850mb, y 500mb; cinco<br />
horas <strong>de</strong> análisis 06, 12, 18, 24, y 30 UTC; y cinco variables Temperatura<br />
(T, parámetro 129), geopotencial (Z, parámetro 130), coor<strong>de</strong>nadas<br />
<strong>de</strong>l viento (U y V, parámetros 131 y 132, respectivamente) y humedad
7.2. ESTRUCTURA DE LA APLICACIÓN. SISTEMA OPERATIVO EN EL INM 141<br />
60 N<br />
(a)<br />
50 N<br />
40 N<br />
30 N<br />
20 W<br />
10 W<br />
0<br />
10 E<br />
20 E<br />
(b)<br />
Figura 7.3: (a) Región geográfica <strong>de</strong> la Cuenca Norte utilizada para la aplicación<br />
Prometeo. (b) Observatorios disponibles en la región.<br />
relativa (H, parámetro 157). El patrón 4D resultante es:<br />
x = (x 06 ,x 12 ,x 18 ,x 24 ,x 30 ), (7.1)<br />
don<strong>de</strong> x t = (T 1000<br />
t , T 850<br />
t , T 500<br />
t , . . .,H 1000<br />
t , H 8500<br />
t , H 500<br />
t ).<br />
2. CPLab. Una vez se ha “filtrado” la base <strong>de</strong> datos <strong>de</strong> re-análisis extrayendo<br />
los patrones (Expresión 7.1) con el módulo dominio, se aplica<br />
un análisis <strong>de</strong> componentes principales con el objetivo <strong>de</strong> reducir la<br />
dimensión <strong>de</strong> los patrones. Dado que esta dimensión pue<strong>de</strong> ser muy<br />
elevada y los patrones pue<strong>de</strong>n contener mucha información redundante<br />
(<strong>de</strong>bido a las gran<strong>de</strong>s correlaciones espaciales que existen en los<br />
datos atmosféricos), es probable obtener matrices <strong>de</strong> covarianza mal<br />
condicionadas, que dificulten la aplicación <strong>de</strong> técnicas estándar. En<br />
este módulo se ha utilizado una técnica iterativa para calcular los primeros<br />
valores singulares. Antes <strong>de</strong> aplicar este análisis es necesario<br />
estandarizar los datos para evitar que las variables con mayor magnitud<br />
dominen al resto. Como resultado <strong>de</strong> este proceso obtenemos<br />
datos necesarios para po<strong>de</strong>r aplicar la misma transformación (matriz<br />
<strong>de</strong> transformación, media y <strong>de</strong>sviación <strong>de</strong> los datos) a las salidas <strong>de</strong><br />
otros mo<strong>de</strong>los numéricos, como por ejemplo el operativo <strong>de</strong>l ECMWF,<br />
que se usa en la etapa <strong>de</strong> explotación <strong>de</strong> la aplicación.<br />
3. cluster (k-medias/SOM). Este módulo es el encargado <strong>de</strong> realizar y almacenar<br />
los resultados <strong>de</strong> agrupar los datos <strong>de</strong> re-análisis <strong>de</strong>spués <strong>de</strong>
142 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
lon=-10,-9,-8,-7,-6,-5,-4,-3,-2,-1,0,1,2,3,4<br />
lat=44,43,42,41,40,39,38,37,36<br />
lvl=1000,850,500<br />
tim=06,12,18,24,30<br />
par=129,130,131,132,157<br />
lop=par,tim,lvl<br />
nod=2,3,4,5,6,7,8,9,17,18,19,20,21,22,23,24,32,33,34<br />
src=../SourceDB/era10<br />
Figura 7.4: Definición <strong>de</strong> la configuración atmosférica <strong>de</strong> un patrón que abarca la<br />
cuenca norte en la península ibérica, consi<strong>de</strong>rando para un día, los patrones 4D <strong>de</strong><br />
cinco variables, para 5 horas <strong>de</strong> análisis distintas, en tres niveles <strong>de</strong> altura.<br />
haber sido filtrados y comprimidos. En este módulo se <strong>de</strong>finen el número<br />
<strong>de</strong> grupos que vamos a realizar, y los parámetros <strong>de</strong> entrenamiento<br />
<strong>de</strong>l algoritmo <strong>de</strong> agrupamiento (para k-medias); en el caso <strong>de</strong> utilizar<br />
una SOM también es necesario indicar la topología y el parámetro <strong>de</strong><br />
vecindad. Debido a la exigencia computacional <strong>de</strong> esta tarea, es necesario<br />
guardar los distintos agrupamientos realizados (centros, etc.),<br />
junto con información auxiliar necesaria para su posterior uso.<br />
Por otra parte, los problemas <strong>de</strong> inicialización en los algoritmos iterativos<br />
<strong>de</strong> agrupamiento, hacen conveniente realizar varios entrenamientos<br />
y evaluarlos posteriormente con el módulo <strong>de</strong> validación para contrastar<br />
la calidad <strong>de</strong> cada uno <strong>de</strong> ellos.<br />
En la aplicación para el INM, los procesos anteriores se han aplicado<br />
a cada una <strong>de</strong> las 12 cuencas hidrográficas, almacenando las CPs <strong>de</strong>l reanálisis,<br />
la matriz <strong>de</strong> transformación, y los agrupamientos realizados.<br />
Esta fase <strong>de</strong> configuración e inicialización, es la que exige una mayor<br />
capacidad <strong>de</strong> cómputo y <strong>de</strong> almacenamiento, y la que marcará más a<strong>de</strong>lante<br />
la interactividad <strong>de</strong>l sistema, aplicando otro paradigma <strong>de</strong> computación<br />
(GRID). Toda esta información almacenada, para hacer el sistema interactivo,<br />
es utilizada en el siguiente proceso <strong>de</strong> explotación operativa.<br />
7.2.2. Explotación Operativa<br />
Este módulo es el encargado <strong>de</strong> obtener las predicciones locales. En la<br />
figura 7.5 se pue<strong>de</strong> observar su estructura, incluyendo su tarea principal<br />
predicción local. Este módulo requiere la configuración e inicialización previa<br />
<strong>de</strong>l sistema, que conlleva la <strong>de</strong>finición <strong>de</strong>l dominio (o dominios) y <strong>de</strong><br />
las correspondientes componentes principales y <strong>de</strong>l agrupamiento a utilizar<br />
(línea discontinua <strong>de</strong> la figura).<br />
En esta fase se precisan las salidas diarias (predicciones numéricas) <strong>de</strong><br />
un mo<strong>de</strong>lo operativo. En esta aplicación se utiliza el mo<strong>de</strong>lo operativo <strong>de</strong>l<br />
ECMWF en la pasada <strong>de</strong> las 12 UTC y para un alcance <strong>de</strong> 10 días, con salida
7.2. ESTRUCTURA DE LA APLICACIÓN. SISTEMA OPERATIVO EN EL INM 143<br />
Observaciones INM<br />
SE<br />
Precip. SE<br />
SE SE Nieve<br />
SE<br />
Tormenta SE<br />
SE SE<br />
ECMWF<br />
operativo<br />
Mo<strong>de</strong>lo operativo<br />
D+1<br />
D+2<br />
D+3<br />
dominios<br />
CPLab<br />
Cuenca Norte<br />
D+3<br />
Cuenca Duero<br />
D+3<br />
...<br />
cluster<br />
Predicciones<br />
locales<br />
Predicción<br />
Local<br />
D+3<br />
SE pred.<br />
locales<br />
4<br />
Figura 7.5: Módulo <strong>de</strong> explotación operativa <strong>de</strong> la aplicación Prometeo.<br />
cada 6 horas, y un dominio espacial global. De estas predicciones se extraen<br />
las mismas variables, niveles y área geográfica previamente especificadas en<br />
el módulo dominios. En este caso sólo es necesario disponer <strong>de</strong> la predicción<br />
para el día <strong>de</strong> interés y, por tanto, no es necesaria una base <strong>de</strong> datos, sino<br />
sólo un fichero <strong>de</strong> entrada. Sin embargo, nuestro objetivo es <strong>de</strong>sarrollar una<br />
herramienta interactiva que permita explorar y validar un periodo amplio <strong>de</strong><br />
predicciones. En esta aplicación se han incluido los dos últimos años (2002 y<br />
2003) <strong>de</strong> predicciones (unos 640 días) en la base <strong>de</strong> datos ECMWF operativo.<br />
Esta base <strong>de</strong> datos se completa diariamente con las nuevas predicciones<br />
obtenidas en días sucesivos. Por tanto, por cada día tendremos 10 días <strong>de</strong><br />
alcance <strong>de</strong> predicción, lo que equivale a la misma magnitud <strong>de</strong> datos que en el<br />
reanálisis (100 gigabytes). Debido a la magnitud <strong>de</strong> información manejada<br />
los datos se encuentran almacenados en su formato original (GRIB) para<br />
impedir duplicidad <strong>de</strong> información; a<strong>de</strong>más su lectura y <strong>de</strong>codificación se<br />
encuentra optimizada (in<strong>de</strong>xada) para un rápido acceso a esta (<strong>de</strong>talles sobre<br />
este formato y códigos <strong>de</strong> codificación/<strong>de</strong>codificación pue<strong>de</strong>n encontrarse en<br />
wesley.wwb.noaa.gov/wgrib.html).<br />
Este módulo involucra las siguientes tareas:<br />
(1,2) dominio, CPLab. Al igual que en la fase <strong>de</strong> configuración, se filtran los<br />
datos operativos sobre la región geográfica indicada. Ahora hay que<br />
tener en cuenta que para cada día tenemos distintos alcances (en la<br />
figura se indican los alcances D+1, D+2 y D+3, correspondientes a las<br />
predicciones hechas un día para cada uno <strong>de</strong> los tres días siguientes).<br />
Las componentes principales <strong>de</strong> los patrones atmosféricos resultantes<br />
son obtenidas aplicando las transformaciones calculadas en la fase <strong>de</strong><br />
configuración. Por tanto, este módulo se limita a un simple cálculo<br />
en la fase operativa. Un aspecto importante <strong>de</strong> esta fase es que ahora<br />
no es necesario almacenar la salidas <strong>de</strong>l módulo CPLab ya que sólo se<br />
calculan en tiempo real para obtener la predicción.<br />
(4) Predicción local. Esta es la tarea central <strong>de</strong> la aplicación ya que en<br />
ella se combinan los resultados <strong>de</strong>l agrupamiento (que con<strong>de</strong>nsan los
144 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
datos <strong>de</strong> re-análisis) con las salidas <strong>de</strong> los mo<strong>de</strong>los numéricos (en forma<br />
<strong>de</strong> vectores <strong>de</strong> CPs) y con las observaciones (almacenadas en bases<br />
<strong>de</strong> datos). Todo ello es necesario para obtener una predicción local a<br />
partir <strong>de</strong>l método <strong>de</strong>scrito en la Sec. 5.4. En este módulo también se<br />
realizan las distintas tareas <strong>de</strong> inferencia probabilística y numérica. Por<br />
ejemplo, se obtienen predicciones probabilísticas <strong>de</strong> la precipitación<br />
para distintos umbrales y se obtiene una predicción numérica <strong>de</strong> la<br />
cantidad estimada <strong>de</strong> precipitación (usando tanto la media como un<br />
percentil superior para compensar la pérdida <strong>de</strong> resolución <strong>de</strong>l grupo;<br />
ver Sec. 5.4 para más <strong>de</strong>talles).<br />
Un fichero <strong>de</strong> configuración <strong>de</strong>fine los observatorios <strong>de</strong> la base <strong>de</strong> datos<br />
<strong>de</strong> observaciones don<strong>de</strong> se <strong>de</strong>sea obtener una predicción (2500 en la<br />
aplicación <strong>de</strong>l INM), y asocia cada uno <strong>de</strong> ellos a un dominio (en este<br />
caso, la cuenca hidrográfica a la que pertenece). Estas predicciones se<br />
almacenan posteriormente en la base <strong>de</strong> datos <strong>de</strong> predicciones locales<br />
para un posterior acceso y tratamiento.<br />
Una vez que hemos obtenido las predicciones <strong>de</strong> nuestro sistema, sería<br />
<strong>de</strong>seable po<strong>de</strong>r acce<strong>de</strong>r a ellas <strong>de</strong> forma interactiva. En la siguiente subsección<br />
se explica el módulo encargado <strong>de</strong> establecer un sistema <strong>de</strong> acceso<br />
interactivo a esta base <strong>de</strong> datos <strong>de</strong> predicciones locales, y como veremos más<br />
a<strong>de</strong>lante, <strong>de</strong> acceso a los resultados <strong>de</strong> las validaciones <strong>de</strong> estas predicciones.<br />
7.2.3. Acceso Web a las Predicciones<br />
Un forma versátil <strong>de</strong> acce<strong>de</strong>r a esta información es a través <strong>de</strong> Internet<br />
utilizando un navegador. Para ello, se ha diseñado una aplicación Web para<br />
que usuarios anónimos y autorizados puedan acce<strong>de</strong>r a esta información<br />
usando cualquier navegador <strong>de</strong> internet (ver Fig. 7.6).<br />
Para ello se ha hecho uso <strong>de</strong> tecnología <strong>de</strong> acceso dinámico a bases<br />
<strong>de</strong> datos a través <strong>de</strong> internet. En particular se ha usado tecnología JAVA<br />
www.sun.com/java, tanto servlets como JSP (Java Server Pages), <strong>de</strong>bido a<br />
su difusión, funcionalidad, y carácter abierto <strong>de</strong> su código. El software <strong>de</strong><br />
conexión utilizado ha sido el <strong>de</strong>sarrollado por el grupo <strong>de</strong> trabajo Apache<br />
(www.apache.org) y se <strong>de</strong>nomina Jakarta. Esta tecnología ha permitido <strong>de</strong>sarrollar<br />
una aplicación WEB (módulo 5) con el objetivo <strong>de</strong> que el usuario<br />
pueda interaccionar con los datos <strong>de</strong> la predicción local. En la figura 7.6<br />
se muestra un ejemplo <strong>de</strong> la página web, en la que se pue<strong>de</strong> seleccionar<br />
la información <strong>de</strong>seada para una fecha concreta y mostrarla en un mapa<br />
dinámico don<strong>de</strong> se muestran las probabilida<strong>de</strong>s con un código <strong>de</strong> colores<br />
(en el ejemplo mostrado se muestra la probabilidad <strong>de</strong> que la precipitación<br />
supere los 0.1mm). A<strong>de</strong>más se pue<strong>de</strong> acce<strong>de</strong>r a la información puntual para<br />
una estación concreta sin más que pulsar sobre ella con el ratón.<br />
A continuación se muestran distintos ejemplos <strong>de</strong>l funcionamiento <strong>de</strong>l<br />
sistema.
7.2. ESTRUCTURA DE LA APLICACIÓN. SISTEMA OPERATIVO EN EL INM 145<br />
Figura 7.6: Aplicación Web <strong>de</strong> acceso a predicciones locales <strong>de</strong>l sistema<br />
Prometeo adaptado a la predicción local en la red secundaria <strong>de</strong>l INM<br />
meteo.macc.unican.es/prometeo/<br />
En la figura 7.7 se muestran las predicciones <strong>de</strong> precipitación y tormenta<br />
realizadas la última semana <strong>de</strong> Enero <strong>de</strong> 2003. En concreto el día 30 <strong>de</strong><br />
Enero se registraron gran<strong>de</strong>s nevadas en los sistemas central, pirenaico y en<br />
los picos <strong>de</strong> Europa, así como tormentas en la mitad norte <strong>de</strong> la Península<br />
Ibérica. También se registraron precipitaciones que superaron los 20mm en<br />
algunos puntos <strong>de</strong> Cantabria y el País Vasco. Las predicciones <strong>de</strong>l sistema<br />
reflejan esta situación claramente con un día <strong>de</strong> antelación (son predicciones<br />
a D+1). La figura 7.7 muestra los eventos Precip > 0.5mm (lluvia débil),<br />
Precip > 20mm (lluvia muy fuerte) y Tormena), mientras que la Fig.<br />
7.8 muestra las predicciones <strong>de</strong> nieve, granizo, y la predicción numérica <strong>de</strong><br />
la temperatura máxima, don<strong>de</strong> se observan valores extremadamente bajos<br />
(tener en cuenta que se trata <strong>de</strong>l máximo <strong>de</strong> temperatura en todo un día)<br />
en muchas localida<strong>de</strong>s.<br />
Cabe también <strong>de</strong>stacar la predicción realizada para las islas Baleares en<br />
las que se observaron nevadas en localida<strong>de</strong>s próximas al mar.<br />
En el ejemplo anterior, las predicciones se obtienen con alcance <strong>de</strong> un<br />
día. Sin embargo, tiene interés analizar cómo varían éstas cuando se aumenta<br />
el horizonte <strong>de</strong> predicción. En la primera columna <strong>de</strong> la Fig. 7.9 se muestra<br />
la predicción <strong>de</strong> precipitación débil para el día 19/3/2003, obtenida con 1,<br />
2, y 3 días <strong>de</strong> antelación. En esta figura pue<strong>de</strong> comprobarse que este evento<br />
era altamente pre<strong>de</strong>cible y las predicciones no varían sustancialmente en un<br />
lapso <strong>de</strong> tres días. Sin embargo, existen otras situaciones menos pre<strong>de</strong>cibles<br />
en las que los distintos alcances <strong>de</strong> predicción muestran distintas situaciones.
146 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
Precip > 0.5mm Precip > 20mm Tormenta<br />
1/2/2003<br />
31/1/2003<br />
30/1/2003<br />
29/1/2003<br />
28/1/2003<br />
Figura 7.7: Predicciones probabilísticas <strong>de</strong>l 28/1/2003 al 1/2/2003 a D+1. En<br />
columnas se muestran los eventos P(Precip > 0.5mm), P(Precip > 20mm) y<br />
P(Tormena).
7.2. ESTRUCTURA DE LA APLICACIÓN. SISTEMA OPERATIVO EN EL INM 147<br />
Nieve Granizo Temp. Max.<br />
1/2/2003<br />
31/1/2003<br />
30/1/2003<br />
29/1/2003<br />
28/1/2003<br />
Figura 7.8: Predicciones <strong>de</strong>l 28/1/2003 al 1/2/2003 a D+1. En columnas se muestran<br />
los eventos P(Nieve), P(Granizo) y valor <strong>de</strong> temperatura máxima previsto.
148 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
Por ejemplo, en la segunda columna <strong>de</strong> la Fig. 7.9 se muestran las predicciones<br />
para 7/3/2003; en esta figura pue<strong>de</strong> comprobarse cómo la predicción<br />
se va afinando con el paso <strong>de</strong>l tiempo. La tercera columna <strong>de</strong> la Fig. 7.9<br />
muestra un caso más extremo, en el que las predicciones no coinci<strong>de</strong>n.<br />
Acierto<br />
Perfilado<br />
Fallo<br />
D+2<br />
D+1<br />
D+0<br />
19/3/2003 7/3/2003 5/6/2003<br />
Figura 7.9: Predicciones probabilísticas <strong>de</strong> P(Precip > 0.5mm). En filas se muestran<br />
los distintos alcances <strong>de</strong> la predicción (D+1, D+2 y D+3); la primera columna<br />
correspon<strong>de</strong> a la fecha 19/3/2003, mientras que la segunda correspon<strong>de</strong> a la fecha<br />
7/3/2003 y la tercera 5/6/2003<br />
Otro aspecto interesante <strong>de</strong>l sistema es su reflejo <strong>de</strong> la dinámica y evolución<br />
<strong>de</strong> distintas situaciones sinópticas (como las entradas <strong>de</strong> frentes en<br />
la península). En la figura 7.10 se pue<strong>de</strong> ver la evolución <strong>de</strong> la probabilidad<br />
<strong>de</strong> lluvia débil, <strong>de</strong>s<strong>de</strong> el 24 <strong>de</strong> Marzo <strong>de</strong>l 2003 al 1 <strong>de</strong> Abril <strong>de</strong>l 2003. En<br />
ese período pue<strong>de</strong> observarse (a través <strong>de</strong> sus efectos en la probabilidad <strong>de</strong><br />
lluvia) la entrada <strong>de</strong> un frente por el noroeste <strong>de</strong> la península y su posterior<br />
evolución hasta que finalmente <strong>de</strong>saparece.<br />
Todos los mapas mostrados en esta Sección se han obtenido directamente<br />
<strong>de</strong> la página Web <strong>de</strong>l sistema (meteo.macc.unican.es/prometeo) y han<br />
sido predicciones realizadas en modo operativo, que pue<strong>de</strong>n ser consultadas<br />
en tiempo pasado para comprobar los distintos aspectos, que hemos <strong>de</strong>sarrollado<br />
en esta subsección, <strong>de</strong> las predicciones realizadas por el sistema. Fruto<br />
<strong>de</strong> esta comprobación también surge la necesidad <strong>de</strong> realizar y almacenar<br />
distintos elementos <strong>de</strong> validación, los cuales ofrecen valiosa información que<br />
permite evaluar las distintas configuraciones <strong>de</strong>pendientes <strong>de</strong> los parámetros<br />
<strong>de</strong>l sistema, y que es utilizada para mejorar las predicciones.
7.2. ESTRUCTURA DE LA APLICACIÓN. SISTEMA OPERATIVO EN EL INM 149<br />
Precip > 0.5mm<br />
30/3/2003<br />
31/3/2003<br />
1/4/2003<br />
27/3/2003<br />
28/3/2003<br />
29/3/2003<br />
24/3/2003<br />
25/3/2003<br />
26/3/2003<br />
Figura 7.10: Predicciones probabilísticas <strong>de</strong> P(Precip > 0.5mm) entre el<br />
24/3/2003 y el 1/4/2003 a D+1.<br />
7.2.4. Proceso <strong>de</strong> validación. Retro-alimentación <strong>de</strong>l Sistema<br />
Una parte importante <strong>de</strong> la aplicación es el módulo <strong>de</strong> validación. Este<br />
módulo tiene un valor tanto informativo (mostrando la calidad <strong>de</strong> las distintas<br />
predicciones), como técnico (proporcionando una medida <strong>de</strong> calidad para<br />
tomar <strong>de</strong>cisiones en el momento <strong>de</strong> construir el sistema; por ejemplo, a la<br />
hora <strong>de</strong> seleccionar el número <strong>de</strong> vecinos óptimo, o un agrupamiento eficiente<br />
para el algoritmo). Para que las validaciones sean representativas, es necesario<br />
consi<strong>de</strong>rar un periodo suficientemente largo <strong>de</strong> predicciones operativas.<br />
Para ello, el módulo <strong>de</strong> validación pue<strong>de</strong> ejecutar el módulo <strong>de</strong> producción<br />
operativa para un período dado y almacenar los resultados en la base <strong>de</strong> datos;<br />
o bien pue<strong>de</strong> trabajar con un conjunto <strong>de</strong> fechas ya almacenadas en la<br />
base <strong>de</strong> datos. Como se comentó anteriormente, en el sistema se han cargado<br />
las predicciones <strong>de</strong> los años 2002-2003 y en base a ellas puedan realizarse<br />
las validaciones oportunas. En la Fig. 7.11 se muestra la estructura <strong>de</strong> este<br />
módulo, que acce<strong>de</strong> a las predicciones locales y las valida frente a las observaciones<br />
almacenadas en la base <strong>de</strong> datos. Después <strong>de</strong> aplicar distintos<br />
scores <strong>de</strong> validación (Brier Score, Brier Skill Score, fiabilidad, resolución,<br />
ROC Area, error cuadrático) almacena los resultados en la base <strong>de</strong> datos<br />
validación para cada uno <strong>de</strong> los alcances <strong>de</strong>l mo<strong>de</strong>lo numérico. Los resultados<br />
<strong>de</strong> validación son posteriormente promediados por estación (Invierno,
150 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
Primavera, Verano u Otoño) y también se almacenan las medias anuales y<br />
la climatología <strong>de</strong>l evento, para que el usuario pueda comprobar cual es la<br />
frecuencia <strong>de</strong>l evento.<br />
Observaciones INM<br />
SE SE<br />
SE SE<br />
SE<br />
Nieve Tormenta SE<br />
Precip.<br />
Predicción<br />
Local<br />
5<br />
Validación<br />
SE<br />
pred.<br />
locales<br />
SE SE<br />
Validación<br />
Figura 7.11: Módulo <strong>de</strong> validación <strong>de</strong> la aplicación Prometeo.<br />
Estas validaciones son usadas para <strong>de</strong>cidir que estaciones, <strong>de</strong> todas las<br />
que el INM dispone <strong>de</strong> información, pue<strong>de</strong>n ser usadas con capacidad predictiva,<br />
y por tanto saber cuáles son buenas estaciones <strong>de</strong> observación. No<br />
sólo eso, si no que a un usuario experto le pue<strong>de</strong> interesar conocer qué configuración<br />
atmosférica <strong>de</strong> patrones ofrece mejores resultados <strong>de</strong> validación.<br />
Todo esto se calcula <strong>de</strong> forma simple utilizando este módulo.<br />
En esta sección hemos visto un ejemplo <strong>de</strong> implementación realizado<br />
con el INM, pero todo este sistema posee un núcleo central que permite<br />
diseñar esquemas adaptables a otras regiones y datos. Este sistema facilita<br />
en gran medida esta labor ya que esta diseñada para aprovechar el esquema<br />
<strong>de</strong> Prometeo <strong>de</strong>scrito, y a<strong>de</strong>más ofrecer validaciones en tiempo real a partir<br />
<strong>de</strong> datos <strong>de</strong> mo<strong>de</strong>los operativos, en tiempo real.<br />
7.3. MeteoLab: Toolbox Meteorológica para Matlab<br />
La implementación <strong>de</strong> los módulos <strong>de</strong>scritos en la sección anterior se ha<br />
realizado en Matlabwww.mathworks.com (para las rutinas científicas y gráficas),<br />
combinándolo con lenguaje C para aquellos algoritmos más costosos.<br />
La aplicación final es eficiente para trabajar con gran<strong>de</strong>s volúmenes <strong>de</strong> datos<br />
provenientes <strong>de</strong> diferentes mo<strong>de</strong>los meteorológicos y con un gran número <strong>de</strong><br />
estaciones <strong>de</strong> distintas re<strong>de</strong>s <strong>de</strong> observación. Aparte <strong>de</strong> los módulos operativos,<br />
en todo el proceso <strong>de</strong> <strong>de</strong>sarrollo se han creado en paralelo herramientas<br />
más amistosas e interactivas para un usuario no experto en Matlab, que puedan<br />
ser utilizadas bajo distintos requerimientos <strong>de</strong> investigación <strong>de</strong> forma<br />
cómoda. Para ello, se han <strong>de</strong>finido distintas interfases <strong>de</strong> usuario en Matlab<br />
(otra <strong>de</strong> sus importantes propieda<strong>de</strong>s) <strong>de</strong> forma que se combinen los núcleos
7.3. METEOLAB: TOOLBOX METEOROLÓGICA PARA MATLAB 151<br />
<strong>de</strong> los módulos con otras rutinas gráficas y auxiliares que permitan investigar<br />
cómodamente sobre distintas configuraciones y sobre los resultados <strong>de</strong><br />
los distintos métodos utilizados. El resultado <strong>de</strong> todo este proceso es un<br />
conjunto <strong>de</strong> herramientas para Matlab, <strong>de</strong>nominada MeteoLab que, a<strong>de</strong>más<br />
<strong>de</strong> ser muy versátil y eficiente para un problema general, permite hacer uso<br />
<strong>de</strong>l sistema Prometeo para otros problemas <strong>de</strong> interés.<br />
Figura 7.12: Interfases <strong>de</strong> usuario <strong>de</strong> configuración y <strong>de</strong> predicción local <strong>de</strong> la<br />
Toolbox Meteolab.<br />
En la Figura 7.12 se muestran las interfases <strong>de</strong> usuario para configuración-inicialización<br />
y predicción local que trabajan a partir <strong>de</strong> los mismos<br />
ficheros <strong>de</strong> configuración <strong>de</strong>scritos en la sección anterior. Una característica<br />
importante son las capacida<strong>de</strong>s gráficas <strong>de</strong> esta herramienta, que nos permiten<br />
visualizar en todo momento los distintos resultados <strong>de</strong>l proceso.<br />
Los dos botones finales <strong>de</strong> la interfase <strong>de</strong> predicción permiten visualizar<br />
tanto la predicción realizada en el período especificado, como los resultados<br />
<strong>de</strong> validación (si se dispone <strong>de</strong> observaciones simultáneas). Dado el carácter<br />
espacio-temporal 3D <strong>de</strong> las predicciones (tiempo, longitud y latitud), se han<br />
<strong>de</strong>finido distintas formas <strong>de</strong> visualización <strong>de</strong> estos resultados. Por ejemplo, la<br />
Fig. 7.13 muestra el resultado <strong>de</strong> las predicciones para el período Diciembre-<br />
Febrero <strong>de</strong> 1999 (90 días). El panel superior muestra las observaciones reales<br />
(blanco/negro) <strong>de</strong> una fecha seleccionada. El panel intermedio muestra las
152 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
probabilida<strong>de</strong>s predichas (grises). Por último, el panel inferior muestra la<br />
evolución <strong>de</strong> las probabilida<strong>de</strong>s predichas para una estación dada. En el<br />
ejemplo mostrado se observa que las probabilida<strong>de</strong>s son todas cercanas a<br />
cero o uno, indicando una buena resolución <strong>de</strong>l mo<strong>de</strong>lo. Tanto la fecha <strong>de</strong><br />
los interfases superiores, como la estación <strong>de</strong> la interfase inferior se pue<strong>de</strong><br />
interaccionar pulsando con el ratón sobre una estación, o sobre una fecha en<br />
la figura. La fecha seleccionada se marca con una línea roja vertical, mientras<br />
que la estación se indica en trazo grueso.<br />
Figura 7.13: Predicción. El panel superior muestra las observaciones reales (1<br />
ocurrencia, 0 no ocurrencia); el panel intermedio muestra las probabilida<strong>de</strong>s predichas.<br />
Finalmente, el panel inferior muestra la evolución <strong>de</strong> las probabilida<strong>de</strong>s para<br />
una cierta estación.<br />
No solo se han <strong>de</strong>sarrollado componentes para la predicción si no también<br />
para la validación, que es quizás el elemento que más información pue<strong>de</strong><br />
ofrecer, y por tanto un buen diseño facilita esta tarea <strong>de</strong> extracción <strong>de</strong> información.<br />
En la Fig. 7.14 se muestra la ventana <strong>de</strong> validación para este<br />
período que contiene paneles con BSS espaciales y temporales, así como las<br />
curvas ROC individuales <strong>de</strong> una estación y promedio <strong>de</strong> todas las estaciones.<br />
Por último, en la Fig. 7.15 se muestra la paleta <strong>de</strong> agrupamiento que<br />
permite ejecutar <strong>de</strong> forma interactiva distintos algoritmos <strong>de</strong> agrupamiento<br />
sobre los datos meteorológicos seleccionados, así como visualizar los prototipos<br />
y grupos obtenidos. Esta paleta permite, entre otras cosas, analizar los<br />
efectos <strong>de</strong> los distintos parámetros en el proceso <strong>de</strong> agrupamiento.
7.3. METEOLAB: TOOLBOX METEOROLÓGICA PARA MATLAB 153<br />
Figura 7.14: Validación. (izquierda) BSS individual para cada estación y evolución<br />
temporal <strong>de</strong>l BSS para una estación concreta; (<strong>de</strong>recha) curva ROC individual para<br />
una estación seleccionada y promedio espacial <strong>de</strong> las curvas ROC.<br />
Figura 7.15: Interfase <strong>de</strong> la Toolbox MeteoLab para el problema <strong>de</strong>l agrupamiento.
154 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
7.4. Validación Operativa <strong>de</strong> Prometeo.<br />
En esta sección se muestra una <strong>de</strong>tallada validación <strong>de</strong>l sistema Prometeo<br />
en el período 1987-1988. Para ello se utilizan las medidas estándar<br />
como la pericia, valor económico, etc., <strong>de</strong>scritas en el Capítulo 4. También<br />
se lleva a cabo una comparación <strong>de</strong> este sistema con el método<br />
<strong>de</strong> análogos en dos etapas <strong>de</strong>sarrollado por el Servicio <strong>de</strong> Aplicaciones<br />
Meteorológicas <strong>de</strong>l INM y utilizado actualmente en la predicción diaria<br />
(en los siguiente este sistema se <strong>de</strong>notará AnalogoINM) (Fernán<strong>de</strong>z et al.<br />
(2001), www.inm.es/web/infmet/predi/preci.html). Dado que este último<br />
sistema está diseñado y especializado para la precipitación, se muestran<br />
únicamente los resultados <strong>de</strong> la validación <strong>de</strong> esta variable. El resto<br />
<strong>de</strong> información pue<strong>de</strong> consultarse directamente en la página <strong>de</strong> Prometeo<br />
(meteo.macc.unican.es/prometeo). Para validar ambos métodos se consi<strong>de</strong>ran<br />
los datos <strong>de</strong> precipitación <strong>de</strong> la red <strong>de</strong> estaciones “synop” <strong>de</strong>l INM<br />
mostrada en la Figura 7.16.<br />
45.0 ° N<br />
42.5 ° N<br />
40.0 ° N<br />
37.5 ° N<br />
35.0 ° N<br />
10.0 ° W<br />
7.5 ° W<br />
5.0 ° W<br />
2.5 ° W<br />
0.0 °<br />
2.5 ° E<br />
5.0 ° E<br />
Figura 7.16: Red <strong>de</strong> 88 estaciones “Synop” <strong>de</strong>l INM <strong>de</strong> datos pluviométricos.<br />
Ambos métodos generan sus predicciones aplicando la técnica <strong>de</strong> análogos<br />
(o <strong>de</strong> los vecinos más cercanos) utilizando patrones con distinta información<br />
tomada <strong>de</strong> los campos atmosféricos integrados en ERA-15. Los Brier<br />
Skill Score (BSS), diagramas <strong>de</strong> fiabilidad y resolución, y curvas ROC y <strong>de</strong><br />
valor económico se han obtenido para el conjunto <strong>de</strong> los dos años (anual), y<br />
separadamente para cada estación <strong>de</strong>l año (DEF: Invierno, MAM: Primavera,<br />
JJA: Verano, SON: Otoño). Estas medidas <strong>de</strong> validación se han calculado<br />
para cuatro umbrales distintos <strong>de</strong> la precipitación 0.5, 2, 10 y 20 mm.<br />
Con el fin <strong>de</strong> comprobar la eficiencia <strong>de</strong> ambos métodos en distintas zonas<br />
<strong>de</strong> la península, se calcularon los BSS anuales <strong>de</strong> AnalogoINM y PROME-<br />
TEO para Prec > 0.5mm consi<strong>de</strong>rando como mo<strong>de</strong>lo <strong>de</strong> referencia la climatología<br />
(un valor positivo indicará una superioridad <strong>de</strong>l método frente a la<br />
climatología, mientras que un valor negativo indicará la situación contraria).<br />
Las Figuras 7.17 (a) y (b) muestran la distribución espacial <strong>de</strong> pericias en la<br />
península para los mo<strong>de</strong>los PROMETEO y AnalogoINM, respectivamente.
7.4. VALIDACIÓN OPERATIVA DE PROMETEO. 155<br />
0.51<br />
0.46<br />
0.38 0.34<br />
0.31<br />
0.57<br />
0.54<br />
0.52 0.50<br />
0.37<br />
0.51 0.39<br />
0.42<br />
0.56 0.53 0.22<br />
0.41 0.37<br />
0.26<br />
0.31 0.26<br />
0.45<br />
0.33 0.42 0.39<br />
0.45<br />
0.33 0.18 0.29<br />
0.35<br />
0.26<br />
0.36 0.35<br />
0.52 0.33 0.34<br />
0.41 0.48<br />
0.45 0.48 0.30<br />
0.51 0.43<br />
0.48<br />
0.31 0.27<br />
0.52<br />
0.28<br />
0.27<br />
0.50 0.50<br />
0.24<br />
0.37<br />
0.21<br />
0.44 0.30<br />
0.25<br />
0.22<br />
0.48 0.20<br />
0.63 0.13<br />
0.48 0.25<br />
0.50 0.44<br />
0.46 0.44<br />
0.49 0.49<br />
0.27<br />
0.41<br />
0.44<br />
0.49<br />
0.37<br />
0.37 0.35 0.390.31<br />
0.20<br />
(a)<br />
0.33<br />
0.45 0.25 0.26 0.24<br />
0.36<br />
0.44<br />
0.25<br />
0.23 0.22 0.27<br />
0.46<br />
0.31<br />
0.46<br />
0.42<br />
0.51 0.42 0.40<br />
0.29 0.33<br />
0.33<br />
0.35<br />
0.33 0.26<br />
0.25<br />
0.30 0.27<br />
0.29<br />
0.31 0.33<br />
0.35 0.32<br />
0.24 0.22 0.21<br />
0.29<br />
0.27<br />
0.33 0.27<br />
0.37 0.33 0.26<br />
0.34 0.32<br />
0.390.35 0.30<br />
0.38 0.34<br />
0.36 0.24<br />
0.26<br />
0.41<br />
0.21<br />
0.27 0.30<br />
0.19<br />
0.35 0.39 0.28<br />
0.19<br />
0.34 0.22<br />
0.21 0.20<br />
0.39 0.24<br />
0.50<br />
0.20<br />
0.12<br />
0.37 0.37<br />
0.39<br />
0.40 0.30<br />
0.43 0.34<br />
0.19<br />
0.40<br />
0.40<br />
0.44<br />
0.21<br />
(b)<br />
Figura 7.17: BSS para evento <strong>de</strong> precipitación > 0.5mm en el periodo 1987-1988<br />
<strong>de</strong> (a) PROMETEO (BSS medio = 0.392) y (b) AnalogoINM (BSS medio = 0.322);<br />
los valores en negrita en esta última figura indican una pericia mayor que el mo<strong>de</strong>lo<br />
PROMETEO.<br />
A partir <strong>de</strong> estas figuras se pue<strong>de</strong> observar que PROMETEO tiene una<br />
pericia superior en toda la península (con la excepción <strong>de</strong> algunas estaciones<br />
aisladas). La zona don<strong>de</strong> ambos métodos tienen menor pericia es la zona <strong>de</strong>l<br />
Mediterráneo (concretamente en Levante), siendo el Noroeste peninsular la<br />
zona con pericias más elevadas. Para el resto <strong>de</strong> umbrales, los resultados son<br />
similares, aunque la diferencia entre ambos métodos es menor a medida que<br />
el umbral <strong>de</strong> predicción aumenta. La Tabla 7.1 muestra los valores <strong>de</strong> Brier<br />
Skill (BS), así como los BSS medios para ambos métodos.<br />
Para ilustrar la resolución <strong>de</strong> las predicciones, en la figura 7.18 se muestran<br />
los histogramas <strong>de</strong> las distintas probabilida<strong>de</strong>s predichas para el evento<br />
<strong>de</strong> precipitación superior a un umbral, en los casos en los que el evento se observó<br />
(y no se observó), respectivamente. Una predicción perfecta <strong>de</strong>bería <strong>de</strong><br />
estar asociada a una función <strong>de</strong>lta centrada en 1 (y en el 0), respectivamente.<br />
Obsérvese que la predicción en una estación <strong>de</strong>l Noroeste (Monteventoso) es
156 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
Brier Score Brier Skill Score<br />
Umbrales CLIMA M1 M2 M1 M2<br />
0.5 mm 0.1729 0.1171 0.1051 0.322 0.392<br />
2 mm 0.1337 0.0963 0.0886 0.279 0.337<br />
10 mm 0.0512 0.0436 0.0425 0.148 0.169<br />
20 mm 0.0201 0.0186 0.0186 0.074 0.074<br />
Tabla 7.1: BSS <strong>de</strong> los mo<strong>de</strong>los AnalogoINM (M1) y PROMETEO (M2) para los<br />
años 1987 y 1988, tomando la climatología como mo<strong>de</strong>lo <strong>de</strong> referencia en ambos<br />
casos. Distintos umbrales <strong>de</strong> precipitación se muestran en cada una <strong>de</strong> las filas.<br />
claramente superior a una predicción en una estación <strong>de</strong> Levante (Alicante).<br />
250<br />
250<br />
Monteventoso > 0.5 mm<br />
Alicante > 0.5mm<br />
200<br />
P(pred=no| observado =no)<br />
P(pred=si | observado =si)<br />
200<br />
150<br />
150<br />
100<br />
100<br />
50<br />
50<br />
0<br />
300<br />
0<br />
[0,0.1) [0.1,0.2) [0.2,0.3)[0.3,0.4)[0.4,0.5)[0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1)<br />
250<br />
200<br />
Monteventoso > 10 mm<br />
P(pred=no| observado =no)<br />
P(pred=si | observado =si)<br />
150<br />
100<br />
50<br />
0<br />
[0,0.1) [0.1,0.2) [0.2,0.3)[0.3,0.4)[0.4,0.5)[0.5,0.6) [0.6,0.7) [0.7,0.8) [0.8,0.9) [0.9,1)<br />
Figura 7.18: Probabilida<strong>de</strong>s condicionadas <strong>de</strong> la predicción o no <strong>de</strong> un evento,<br />
condicionado a la ocurrencia o no <strong>de</strong>l evento, en la estación “Monteventoso” <strong>de</strong>l<br />
Noroeste peninsular y en la estación “Alicante” <strong>de</strong>l Mediterráneo.<br />
En las figuras 7.19, 7.20, y 7.21 se muestran medidas alternativas al BSS<br />
para validar los pronósticos probabilísticos <strong>de</strong> ambos mo<strong>de</strong>los: las curvas <strong>de</strong><br />
fiabilidad y resolución, las curvas ROC, y las curvas <strong>de</strong> valor económico,<br />
respectivamente. Estas figuras muestran que la fiabilidad <strong>de</strong> ambos métodos<br />
es similar, siendo la pericia superior en el caso <strong>de</strong> Prometeo.<br />
Finalmente, las cuatro últimas figuras muestran las curvas <strong>de</strong> valor<br />
económico para las distintas estaciones <strong>de</strong> los dos años <strong>de</strong> validación.
7.4. VALIDACIÓN OPERATIVA DE PROMETEO. 157<br />
1<br />
1<br />
1<br />
1<br />
0.75<br />
0.75<br />
0.5<br />
0<br />
0 0.25 0.5 0.75<br />
0.5<br />
0<br />
0 0.25 0.5 0.75<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
1<br />
1<br />
1<br />
0.75<br />
0.75<br />
0.5<br />
0<br />
0 0.25 0.5 0.75<br />
0.5<br />
0<br />
0 0.25 0.5 0.75<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.19: Diagramas <strong>de</strong> Fiabilidad y <strong>de</strong> resolución para los años 1987-1988.<br />
1<br />
Prec > 0.5mm<br />
1<br />
Prec > 2mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 10mm<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 20mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.20: Curvas ROC <strong>de</strong> los mo<strong>de</strong>los PROMETEO y AnalogoINM (1987-<br />
1988).
158 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
1<br />
Prec > 0.5mm<br />
1<br />
Prec > 2mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 10mm<br />
1<br />
Prec > 20mm<br />
0.75<br />
0.75<br />
0.5<br />
0.25<br />
0.5<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.21: Valor económico <strong>de</strong> los mo<strong>de</strong>los PROMETEO y AnalogoINM (1987-<br />
1988).<br />
1<br />
Prec > 0.5mm<br />
1<br />
Prec > 2mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 10mm<br />
1<br />
Prec > 20mm<br />
0.75<br />
0.75<br />
0.5<br />
0.25<br />
0.5<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.22: Valor económico <strong>de</strong> los mo<strong>de</strong>los PROMETEO y AnalogoINM para<br />
las Primaveras <strong>de</strong> los años 1987-1988.
7.4. VALIDACIÓN OPERATIVA DE PROMETEO. 159<br />
1<br />
Prec > 0.5mm<br />
1<br />
Prec > 2mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 10mm<br />
1<br />
Prec > 20mm<br />
0.75<br />
0.75<br />
0.5<br />
0.25<br />
0.5<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.23: Valor económico <strong>de</strong> los mo<strong>de</strong>los PROMETEO y AnalogoINM para<br />
los Veranos <strong>de</strong> los años 1987-1988.<br />
1<br />
Prec > 0.5mm<br />
1<br />
Prec > 2mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 10mm<br />
1<br />
Prec > 20mm<br />
0.75<br />
0.75<br />
0.5<br />
0.25<br />
0.5<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.24: Valor económico <strong>de</strong> los mo<strong>de</strong>los PROMETEO y AnalogoINM para<br />
los Otoños <strong>de</strong> los años 1987-1988.
160 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
1<br />
Prec > 0.5mm<br />
1<br />
Prec > 2mm<br />
0.75<br />
0.75<br />
0.5<br />
0.5<br />
0.25<br />
0.25<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
1<br />
Prec > 10mm<br />
1<br />
Prec > 20mm<br />
0.75<br />
0.75<br />
0.5<br />
0.25<br />
0.5<br />
0.25<br />
AnalogoINM<br />
PROMETEO<br />
Clim<br />
0<br />
0 0.25 0.5 0.75 1<br />
0<br />
0 0.25 0.5 0.75 1<br />
Figura 7.25: Valor económico <strong>de</strong> los mo<strong>de</strong>los PROMETEO y AnalogoINM para<br />
los Inviernos <strong>de</strong> los años 1987-1988.<br />
7.5. Computación Distribuida en la Web. Tecnología GRID<br />
En las secciones anteriores se ha <strong>de</strong>scrito al sistema Prometeo en su versión<br />
operativa, que hace uso <strong>de</strong> las tecnologías Web <strong>de</strong>s<strong>de</strong> una perspectiva<br />
cliente-servidor. Las áreas geográficas sobre las que se lleva a cabo la predicción<br />
están prefijadas (España peninsular, y las islas Baleares y Canarias) y el<br />
sistema da acceso al cliente a una base <strong>de</strong> datos con las distintas predicciones<br />
realizadas en las mismas. Una aplicación más interactiva <strong>de</strong> esta aplicación<br />
supondría que el usuario pudiese seleccionar el área <strong>de</strong> interés y proporcionar<br />
la información (observaciones locales) necesaria para realizar la predicción,<br />
todo <strong>de</strong> forma interactiva. Ello supondría ejecutar la aplicación y obtener<br />
las predicciones en tiempo real a partir <strong>de</strong> una petición realizada a través <strong>de</strong><br />
la Web (servicio Web). El problema <strong>de</strong> un servicio Web <strong>de</strong> este tipo es que<br />
requiere la ejecución <strong>de</strong> algunos procesos costosos (como entrenar una SOM<br />
para la región especificada por el usuario) y el acceso a bases <strong>de</strong> datos distribuidas<br />
(la base <strong>de</strong> datos <strong>de</strong> las predicciones numéricas y la base <strong>de</strong> datos<br />
con observaciones <strong>de</strong>l usuario) y la tecnología Web actual no es apropiada<br />
ni eficiente para resolver estos problemas. En concreto, la fase <strong>de</strong> configuración/inicialización<br />
y, en especial, los algoritmos <strong>de</strong> componentes principales<br />
y <strong>de</strong> agrupamiento, son muy exigentes en tiempo <strong>de</strong> computación (por el<br />
gran volumen <strong>de</strong> datos). Más aún, es aconsejable ejecutar repetidas veces el<br />
algoritmo <strong>de</strong> agrupamiento para validar y seleccionar el más eficiente.<br />
Para resolver interactivamente este tipo <strong>de</strong> problemas que requieren
7.5. COMPUTACIÓN DISTRIBUIDA EN LA WEB. TECNOLOGÍA GRID 161<br />
gran<strong>de</strong>s tiempos <strong>de</strong> cómputo, ha surgido en los últimos cinco años una tecnología<br />
llamada GRID. La tecnología GRID preten<strong>de</strong> aprovechar la rapi<strong>de</strong>z<br />
<strong>de</strong> las re<strong>de</strong>s <strong>de</strong> alta velocidad (Internet2 y GEANT) para exten<strong>de</strong>r la i<strong>de</strong>a<br />
<strong>de</strong>l cluster <strong>de</strong> computación, uniendo distintos clusters dispersos geográficamente<br />
mediante una red <strong>de</strong> altas prestaciones. De esta forma se pue<strong>de</strong>n<br />
aprovechar mejor los recursos computacionales y <strong>de</strong> almacenamiento, pudiendo<br />
llevarse a cabo costosos procesos en tiempo real ejecutándolos <strong>de</strong><br />
forma distribuida a través <strong>de</strong> la red. Esta tecnología requiere el <strong>de</strong>sarrollo<br />
<strong>de</strong> software intermedio complejo (middleware) que permita acce<strong>de</strong>r a los recursos<br />
y paralelizar las aplicaciones <strong>de</strong> forma simple (por ejemplo Globus,<br />
www.globus.com), así como <strong>de</strong> técnicas <strong>de</strong> seguridad apropiadas que verifiquen<br />
la i<strong>de</strong>ntidad <strong>de</strong> los usuarios en los distintos clusters y que garanticen la<br />
confi<strong>de</strong>ncialidad <strong>de</strong> datos privados que viajen por la red. Todo este trabajo<br />
está en <strong>de</strong>sarrollo en distintos proyectos Europeos y Estadouni<strong>de</strong>nses (por<br />
ejemplo, el proyecto CrossGrid www.crossgrid.com, en el que se enmarca<br />
el trabajo preliminar presentado en esta sección). En esta Sección se da una<br />
visión sobre que es la tecnología GRID cuales son sus elementos más importantes<br />
y su funcionamiento. A<strong>de</strong>más se introduce cuales son las aplicaciones<br />
GRID en meteorología para luego <strong>de</strong>scribir como Prometeo es un sistema<br />
muy apropiado para utilizar GRID. Por último, se estudia la aplicación <strong>de</strong><br />
los algoritmos <strong>de</strong> agrupamiento a un entorno <strong>de</strong> computación cambiante.<br />
7.5.1. Estructura <strong>de</strong> la tecnología GRID<br />
La tecnología Grid surge en el ámbito <strong>de</strong> la comunidad <strong>de</strong> supercomputación<br />
y está basada en las i<strong>de</strong>as <strong>de</strong> agregar y compartir, utilizando la red<br />
como via <strong>de</strong> comunicación. Con ello se trata <strong>de</strong> dar un salto cuantitativo<br />
en la computación distribuida, equivalente al que se produjo al conseguir<br />
clusters <strong>de</strong> or<strong>de</strong>nadores con capacidad <strong>de</strong> cómputo similar a las máquinas<br />
multiprocesadoras. En ese caso, los or<strong>de</strong>nadores <strong>de</strong>l cluster se comunican<br />
localmente mediante re<strong>de</strong>s <strong>de</strong> alta velocidad, con eficiencias comparables a<br />
las conexiones <strong>de</strong> placas multiprocesadoras. El salto <strong>de</strong> GRID consiste en<br />
permitir que los cluster puedan estar distribuidos geográficamente y conectados<br />
no por una sola red local, sino conjuntamente a través <strong>de</strong> Internet.<br />
Para ello, es necesario generalizar las técnicas y tecnologías <strong>de</strong> paralelización<br />
como, por ejemplo, las basadas en el uso <strong>de</strong> MPI (Message Passing<br />
Interface, www-unix.mcs.anl.gov/mpi/) para que sean eficientes en este<br />
contexto. La primera experiencia <strong>de</strong> este tipo se produjo en 1995 durante<br />
el congreso SuperComputing 95, don<strong>de</strong> se <strong>de</strong>mostró la posibilidad <strong>de</strong> ejecutar<br />
aplicaciones distribuidas <strong>de</strong> diferentes áreas científicas en una red <strong>de</strong><br />
17 centros <strong>de</strong> USA conectados con una red <strong>de</strong> alta velocidad (155 Mbps).<br />
Éste fue el punto <strong>de</strong> partida <strong>de</strong> varios proyectos en diferentes áreas con el<br />
<strong>de</strong>nominador común <strong>de</strong> compartir recursos distribuidos <strong>de</strong> computación. En<br />
Foster and Kesselman (1999) se presenta una analogía con la red eléctrica<br />
(electrical power grid), don<strong>de</strong> el usuario <strong>de</strong>be tener acceso a los recursos
162 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
computacionales en condiciones similares a las que tiene para utilizar la<br />
energía eléctrica; es <strong>de</strong>cir, <strong>de</strong>s<strong>de</strong> cualquier sitio, con un interfase uniforme,<br />
pudiendo confiar en su funcionamiento, y a un coste asequible. Esta i<strong>de</strong>a<br />
marca el <strong>de</strong>sarrollo <strong>de</strong> la supercomputación mo<strong>de</strong>rna a través <strong>de</strong> Internet.<br />
En la actualidad son numerosos los proyectos que se están llevando a cabo<br />
en esta línea, tanto a nivel <strong>de</strong> infraestructura y middleware (EuroGrid<br />
www.eurogrid.org y DataGrid www.eu-datagrid.org), como a nivel <strong>de</strong><br />
aplicaciones (CrossGrid www.crossgrid.org).<br />
En la Fig. 7.26 se muestra un esquema <strong>de</strong> los elementos que intervienen<br />
en un GRID. Dos piezas fundamentales son la autoridad <strong>de</strong> certificación y<br />
el localizador <strong>de</strong> recursos (resource broker). El primer módulo se encarga<br />
<strong>de</strong> gestionar <strong>de</strong> forma segura los certificados <strong>de</strong> usuario que se compartirán<br />
en todas las re<strong>de</strong>s locales para el proceso <strong>de</strong> i<strong>de</strong>ntificación. El localizador<br />
<strong>de</strong> recursos se encarga <strong>de</strong> localizar los recursos óptimos (computacionales y<br />
datos) para llevar a cabo un trabajo solicitado; en otras palabras, es la puerta<br />
a los recursos <strong>de</strong> GRID. Estos recursos se hallan distribuidos en distintas<br />
re<strong>de</strong>s locales (LAN) participantes en el GRID.<br />
Autoridad <strong>de</strong> certificados<br />
servidor <strong>de</strong><br />
certificados<br />
acceso<br />
LAN 1<br />
localizador <strong>de</strong><br />
recursos<br />
LAN UNICAN<br />
LAN INM<br />
Elemento <strong>de</strong><br />
cómputo<br />
Elemento <strong>de</strong><br />
almacenamiento<br />
Interfase <strong>de</strong><br />
usuario<br />
WAN<br />
Elemento <strong>de</strong><br />
almacenamiento<br />
SE SE observaciones<br />
Reanálisis ERA<br />
LAN 2<br />
LAN n<br />
LAN ECMWF<br />
...<br />
Elemento <strong>de</strong><br />
cómputo<br />
Elemento <strong>de</strong><br />
almacenamiento<br />
SE SE<br />
reanálisis<br />
Reanálisis ERA<br />
SE SE<br />
operativo<br />
salidas<br />
operativas<br />
Figura 7.26: Esquema prototipo <strong>de</strong> un entorno GRID, don<strong>de</strong> el componente <strong>de</strong><br />
conexión es una WAN (Wi<strong>de</strong> Area Network): Internet-2, GEANT, etc.<br />
Ejecutar un trabajo en el GRID requerirá lo siguiente:<br />
1. Preparar el código paralelo <strong>de</strong> la aplicación (por ejemplo en MPI para<br />
Globus) <strong>de</strong> forma que pueda compilarse en las distintas plataformas<br />
que intervengan en el GRID. Por ejemplo, la Fig. 7.31 muestra el<br />
código paralelizado <strong>de</strong> algoritmo <strong>de</strong> agrupamiento basado en re<strong>de</strong>s<br />
auto-organizativas (uno <strong>de</strong> los módulos <strong>de</strong>l sistema Prometeo).<br />
2. Disponer <strong>de</strong> un certificado que tenga permisos en distintas re<strong>de</strong>s locales
7.5. COMPUTACIÓN DISTRIBUIDA EN LA WEB. TECNOLOGÍA GRID 163<br />
(LAN) <strong>de</strong>l grid y que esté autorizado por la “autoridad <strong>de</strong> certificados’.<br />
Este certificado será la llave para acce<strong>de</strong>r a los distintos recursos.<br />
3. Ejecutar el localizador <strong>de</strong> recursos con las restricciones <strong>de</strong>seadas (velocidad<br />
mínima <strong>de</strong>l elemento <strong>de</strong> cómputo, tipo <strong>de</strong> sistema operativo,<br />
etc.) y <strong>de</strong>cidir <strong>de</strong>pendiendo <strong>de</strong> las características <strong>de</strong>l algoritmo qué recursos<br />
van a utilizarse.<br />
4. Una vez preparada la petición, se lanza al GRID y se pue<strong>de</strong> realizar<br />
un seguimiento utilizando alguna herramienta <strong>de</strong> monitorización (en<br />
qué máquinas se está ejecutando, etc.).<br />
7.5.2. Tecnologías GRID en Meteorología<br />
Históricamente, la Meteorología ha sido una <strong>de</strong> los principales usuarios<br />
<strong>de</strong> las nuevas tecnologías <strong>de</strong> la Computación, tanto en lo relativo a la capacidad<br />
<strong>de</strong> cálculo, como al almacenamiento <strong>de</strong> gran<strong>de</strong>s volúmenes <strong>de</strong> información<br />
y a su rápida distribución mediante re<strong>de</strong>s <strong>de</strong> alto rendimiento. En<br />
el pasado, muchas <strong>de</strong> las tareas involucradas en este área (integración <strong>de</strong><br />
mo<strong>de</strong>los numéricos <strong>de</strong> predicción, mantenimiento <strong>de</strong> bases <strong>de</strong> datos operativas,<br />
etc.) eran exclusivas <strong>de</strong> gran<strong>de</strong>s centros meteorológicos que disponían<br />
<strong>de</strong> la tecnología necesaria. En la actualidad, la situación es distinta <strong>de</strong>bido al<br />
abaratamiento <strong>de</strong> la tecnología, y diversos grupos <strong>de</strong> investigación públicos<br />
y privados llevan a cabo costosas simulaciones meteorológicas que utilizan<br />
distintas bases <strong>de</strong> datos para realizar tareas tan diversas como: estudios<br />
climatológicos y <strong>de</strong> cambio climático, pronóstico meteorológico local, predicción<br />
<strong>de</strong> viento para la gestión <strong>de</strong> parques eólicos, difusión <strong>de</strong> contaminantes<br />
en el mar y en la atmósfera, etc. Sin embargo, el tipo <strong>de</strong> estudios que pue<strong>de</strong>n<br />
empren<strong>de</strong>r estos grupos en un tiempo reducido está todavía limitado<br />
por los recursos computacionales <strong>de</strong> que disponen (principalmente clusters<br />
<strong>de</strong> or<strong>de</strong>nadores Drake et al. (1995)). Por tanto, la tecnología GRID pue<strong>de</strong><br />
proporcionar un enorme beneficio en este campo, permitiendo abordar<br />
problemas más complejos a los centros <strong>de</strong> investigación y proporcionando<br />
servicios especializados a medida a través <strong>de</strong> Internet. Los centros <strong>de</strong> e-<br />
Ciencia son una iniciativa surgida en el Reino Unido para amparar este<br />
tipo <strong>de</strong> tecnologías, proporcionando el entorno computacional y el soporte<br />
técnico necesarios para dar una cobertura apropiada a los distintos grupos y<br />
empresas con necesidad <strong>de</strong> gestionar recursos a través <strong>de</strong> la red, utilizando<br />
la tecnología GRID como soporte <strong>de</strong> este proceso.<br />
Los temas <strong>de</strong> meteorología han formado y forman parte <strong>de</strong> los distintos<br />
proyectos GRID (Hoffmann, 2001). Uno <strong>de</strong> los primeros <strong>de</strong>sarrollos <strong>de</strong><br />
aplicaciones meteorológicas integradas en Europa en entornos GRID se lleva<br />
a cabo en el proyecto Europeo <strong>de</strong>l V Programa Marco llamado Cross-Grid<br />
(www.crossgrid.org), con una activa participación <strong>de</strong> grupos Españoles<br />
en el ámbito <strong>de</strong> la dispersión <strong>de</strong> contaminantes en la atmósfera y en la<br />
implementación <strong>de</strong> herramientas <strong>de</strong> minería <strong>de</strong> datos para bases <strong>de</strong> datos
164 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
meteorológicas. Fruto <strong>de</strong> estas iniciativas se están resolviendo distintos problemas<br />
<strong>de</strong> migración y adaptación <strong>de</strong> las técnicas y productos existentes<br />
al nuevo entorno GRID, facilitando el trabajo para futuras iniciativas en<br />
este campo. Otra <strong>de</strong> las experiencias piloto en este proyecto es la paralelización<br />
y migración a GRID <strong>de</strong>l mo<strong>de</strong>lo COAMPS en forma <strong>de</strong> servicio Web<br />
en el que el usuario pueda seleccionar interactivamente un área <strong>de</strong> interés,<br />
la resolución horizontal y vertical, y un período <strong>de</strong> predicción, obteniendo<br />
los campos meteorológicos solicitados resultado <strong>de</strong> la integración <strong>de</strong>l mo<strong>de</strong>lo.<br />
Está planeado integrar este servicio web con aplicaciones específicas <strong>de</strong><br />
cálculo <strong>de</strong> contaminates en la atmósfera, cálculo <strong>de</strong> oleaje, y procesamiento<br />
y análisis <strong>de</strong> proyectos <strong>de</strong> re-análisis regionales. En la Fig. 7.27 se muestran<br />
más <strong>de</strong>talles.<br />
Figura 7.27: Esquema previsto <strong>de</strong> integración <strong>de</strong> aplicaciones meteorológicas en el<br />
proyecto Cross-GRID.<br />
Una <strong>de</strong> estas aplicaciones es la utilización <strong>de</strong> técnicas <strong>de</strong> minería <strong>de</strong> datos<br />
a bases <strong>de</strong> datos meteorológicas, y Prometeo es un sistema que engloba parte<br />
<strong>de</strong> estas técnicas.<br />
7.5.3. Prometeo en un Entorno GRID<br />
Debido a las características <strong>de</strong>l sistema Prometo, éstas le hacen apropiado<br />
para el entorno GRID, ya que pue<strong>de</strong> aprovechar tanto recursos compu-
7.5. COMPUTACIÓN DISTRIBUIDA EN LA WEB. TECNOLOGÍA GRID 165<br />
tacionales como <strong>de</strong> almacenamiento distribuido:<br />
Ejecución interactiva <strong>de</strong>finida por el usuario. Cada usuario requiere<br />
una petición concreta <strong>de</strong> la aplicación, que tendrá que ser ejecutada<br />
según sus necesida<strong>de</strong>s <strong>de</strong> forma interactiva (área geográfica, variables<br />
atmosféricas, etc.). Ello supondrá ejecutar el sistema completo (configuración/explotación)<br />
en tiempo real. El tiempo <strong>de</strong> cómputo hace<br />
inviable su uso interactivo con tecnologías web estándar y hace necesario<br />
el uso <strong>de</strong> GRID.<br />
Alto coste computacional, que <strong>de</strong>manda cálculo distribuido masivo, en<br />
lugar <strong>de</strong> computación local en una sola máquina. Todos los algoritmos<br />
están bien <strong>de</strong>finidos y los más costosos <strong>de</strong> ellos (componentes principales<br />
y agrupamiento) son paralelizables. En la Sec. 7.5.4 analizamos<br />
el rendimiento <strong>de</strong> distintas versiones paralelizadas <strong>de</strong> este algoritmo<br />
en un entorno GRID <strong>de</strong> unida<strong>de</strong>s <strong>de</strong> computación y latencias <strong>de</strong> red<br />
heterogéneas.<br />
Acceso masivo a datos distribuidos. Aparte <strong>de</strong> los datos proporcionados<br />
por el usuario, el algoritmo requiere otros datos <strong>de</strong> entrada (reanálisis,<br />
observaciones, etc.) que en principio están distribuidos en distintos<br />
centros. Por ejemplo, la Fig. 7.26 muestra un posible GRID don<strong>de</strong><br />
la Universidad <strong>de</strong> Cantabria, el INM y el ECMWF serían tres <strong>de</strong> las<br />
re<strong>de</strong>s locales, haciendo posible la no replicación <strong>de</strong> datos y el acceso<br />
dinámico a los mismos.<br />
Aplicación paramétrica (parameter driven). Otra característica <strong>de</strong> Prometeo<br />
es que la aplicación forma un núcleo que sólo requiere un conjunto<br />
<strong>de</strong> datos <strong>de</strong> entrada (parámetros) para ejecutar una tarea específica.<br />
Este tipo <strong>de</strong> aplicaciones son manejables en un entorno GRID, tanto<br />
para su réplica en los distintos elementos <strong>de</strong> cómputo, como para su<br />
ejecución.<br />
Las fases más críticas para la implementación <strong>de</strong> Prometeo en un entorno<br />
GRID serían:<br />
1. La paralelización <strong>de</strong> los algoritmos <strong>de</strong> componentes principales y agrupamiento,<br />
teniendo en cuenta las características <strong>de</strong>l entorno GRID.<br />
2. Las inclusión en GRID <strong>de</strong> las bases <strong>de</strong> datos <strong>de</strong> reanálisis, operativa,<br />
y observaciones. En la actualidad no hay una única solución para la<br />
gestión y acceso a bases <strong>de</strong> datos distribuidas en el GRID, sino que se<br />
están planteando distintas alternativas.<br />
En la siguiente sección se muestran resultados <strong>de</strong> la primera tarea. La segunda<br />
tarea está todavía en fase <strong>de</strong> estudio.
166 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
7.5.4. Paralelización GRID <strong>de</strong> los Algoritmos <strong>de</strong> <strong>Agrupamiento</strong><br />
En esta sección se analiza la eficiencia <strong>de</strong> distintas paralelizaciones <strong>de</strong><br />
algoritmos <strong>de</strong> agrupamiento (en particular, <strong>de</strong> la SOM) en un entorno tipo<br />
GRID, don<strong>de</strong> los recursos computacionales disponibles son heterogéneos, y<br />
la velocidad <strong>de</strong> la red es variable <strong>de</strong> unos nodos a otros. Es <strong>de</strong>cir, no se trata<br />
<strong>de</strong> paralelizar el algoritmo teniendo en cuenta unas características estáticas<br />
<strong>de</strong> un cluster, sino tener en cuenta la heterogeneidad y variabilidad <strong>de</strong> estos<br />
factores. En consecuencia, los algoritmos tienen que ser adaptativos según<br />
la situación.<br />
Para <strong>de</strong>sarrollar un algoritmo <strong>de</strong> este tipo se ha comenzado analizando<br />
distintas opciones <strong>de</strong> paralelización <strong>de</strong>l algoritmo <strong>de</strong> la SOM <strong>de</strong>scrito en la<br />
Sec. 3.4 y que constituye la parte con mayor carga computacional <strong>de</strong>l sistema<br />
prometeo. Para este cometido se ha utilizado un cluster <strong>de</strong> 80 maquinas<br />
IBM mo<strong>de</strong>lo x220 server con un procesador Pentium III a una frecuencia <strong>de</strong><br />
1.26 GHz, con 512 MB <strong>de</strong> memoria RAM, y 90 GB <strong>de</strong> disco duro, todas ellas<br />
conectadas con una red Ethernet a 100 Mbps gestionada por dos switch <strong>de</strong><br />
1Gbps en la Figura 7.28 el esquema <strong>de</strong>l cluster. Este cluster es gestionado<br />
por el IFCA (Instituto <strong>de</strong> Física <strong>de</strong> Cantabria) y se pue<strong>de</strong> obtener más información<br />
<strong>de</strong>tallada en grid.ifca.unican.es. Cada uno <strong>de</strong> estos or<strong>de</strong>nadores<br />
constituye una unidad <strong>de</strong> cálculo.<br />
Todos los programas han sido <strong>de</strong>sarrollados en lenguaje C y usando la<br />
implementación <strong>de</strong> la Interfase <strong>de</strong> Paso <strong>de</strong> Mensajes (MPI, Message Passing<br />
Interfase) MPICH-p4 <strong>de</strong>sarrollado por el Argonne National Laboratory<br />
(www-unix.mcs.anl.gov/mpi/mpich). Aunque los resultados mostrados en<br />
esta Sección hayan sido obtenidos a partir <strong>de</strong> esta implementación, pruebas<br />
<strong>de</strong> ejecución, con resultados muy preliminares, se han realizado utilizando<br />
la implementación <strong>de</strong> MPI para Glogus (MPICH-g2). Debido a las inhomogeneida<strong>de</strong>s<br />
<strong>de</strong> comunicación en un entorno GRID, uno <strong>de</strong> los principales<br />
inconvenientes es el tamaño y la cantidad <strong>de</strong> mensajes enviados y recibidos<br />
durante el algoritmo. Así que, elegimos una arquitectura centralizada<br />
<strong>de</strong> maestro-esclavo para evitar el paso <strong>de</strong> una gran cantidad <strong>de</strong> mensajes<br />
entre las unida<strong>de</strong>s <strong>de</strong> cómputo. Mas aún, en un entorno GRID el maestro<br />
<strong>de</strong>bería chequear a las unida<strong>de</strong>s <strong>de</strong> cómputo durante el algoritmo, y tomar<br />
<strong>de</strong>cisiones si cualquiera <strong>de</strong> ellos no funcionase correctamente. Este punto <strong>de</strong><br />
vista es diferente con respecto a otras implementaciones paralelas <strong>de</strong> la SOM<br />
en las cuales se usa un paso masivo <strong>de</strong> mensajes sobre máquinas paralelas.<br />
La forma más simple <strong>de</strong> paralelización <strong>de</strong>l algoritmo <strong>de</strong> la SOM es dividir<br />
los datos, y <strong>de</strong> esta forma la suma en (3.16) pue<strong>de</strong> repartirse entre diferentes<br />
procesadores, como se muestra en la Fig. 7.29(a). Sin embargo, en este caso,<br />
<strong>de</strong>spués <strong>de</strong> cada ciclo completo, los esclavos tienen que enviar los prototipos<br />
al maestro, el cual calcula su actualización, y envía los centros finales a cada<br />
uno <strong>de</strong> los esclavos. Esta no es una implementación eficiente para el entorno<br />
GRID, ya que requiere un paso intensivo <strong>de</strong> datos.<br />
Las Figuras 7.29(b) y (c) muestran dos alternativas diferentes llama-
7.5. COMPUTACIÓN DISTRIBUIDA EN LA WEB. TECNOLOGÍA GRID 167<br />
Figura 7.28: Cluster local <strong>de</strong>l Instituto <strong>de</strong> Física <strong>de</strong> Cantabria (CSIC/Universidad<br />
<strong>de</strong> Cantabria).<br />
das SOM R y SOM C , respectivamente, para distribución computacional <strong>de</strong><br />
recursos con los vectores <strong>de</strong> prototipos replicados (y centralizados). En la Figura<br />
7.31 se muestra el pseudocódigo, <strong>de</strong> estos algoritmos usando la siguiente<br />
notación:<br />
Se consi<strong>de</strong>ra una SOM m = r × r; c k y w k ∈ R d representa el centro<br />
<strong>de</strong>l cluster C k antes y <strong>de</strong>spués <strong>de</strong> aplicar las restricciones topológicas,<br />
respectivamente.<br />
Se utilizan P + 1 procesadores (1 maestro y P esclavos).<br />
T i ⊂ {1, . . .,m}, i = 1, · · ·,P, son los índices <strong>de</strong> los vectores prototipos<br />
asignados al procesador i.<br />
Los diferentes mensajes requeridos para cada uno <strong>de</strong> los esquemas, se muestran<br />
en la Figura 7.29 con líneas discontinuas, las cuales pue<strong>de</strong>n correspon<strong>de</strong>r,<br />
o bien a una iteración <strong>de</strong>l algoritmo, o bien a un ciclo completo. En la<br />
Figura 7.29(b), el tamaño <strong>de</strong> los mensajes es mínimo, pero los prototipos<br />
<strong>de</strong>ben ser replicados y actualizados en cada unidad <strong>de</strong> cómputo (SOM R ).<br />
Por otro lado, en la Figura 7.29(c) se muestra que los cálculos son realizados<br />
únicamente en el maestro, pero para actualizar los centros es necesario<br />
enviar mensajes a los esclavos <strong>de</strong>spués <strong>de</strong> cada ciclo (SOM C ). En ambos<br />
casos, el cálculo <strong>de</strong> distancias <strong>de</strong> 3.15, esta distribuido por igual sobre cada<br />
uno <strong>de</strong> los esclavos. Por tanto, una SOM con m centros podría ser repartida<br />
hasta en P procesos esclavos, cada uno <strong>de</strong> ellos calculando m/P distancias.<br />
Para comprobar la eficiencia <strong>de</strong> estos algoritmos, se han realizado varios<br />
experimentos variando el número <strong>de</strong> centros m, la dimensión <strong>de</strong> los datos d,
168 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
Figura 7.29: Tres esquemas paralelos diferentes para el algoritmo <strong>de</strong> entrenamiento<br />
<strong>de</strong> la SOM: (a) distribución <strong>de</strong> datos (b), SOM R distribución computacional <strong>de</strong> recursos<br />
con los vectores prototipos replicados, (c) SOM C distribución computacional<br />
<strong>de</strong> recursos con los vectores prototipos centralizados.<br />
el tamaño <strong>de</strong> la base <strong>de</strong> datos n, y el número <strong>de</strong> ciclos. La Figura 7.30 muestra<br />
las curvas <strong>de</strong> speedup obtenidas para d = 500, n = 5500 y un tamaño<br />
variable <strong>de</strong> la SOM (<strong>de</strong>s<strong>de</strong> 10 × 5 = 50 a 40 × 40 = 1600 centros, o prototipos);<br />
los centros prototipos, son distribuidos en dos, cuatro y hasta veinte<br />
procesos, obteniendo curvas <strong>de</strong> speedup para los esquemas SOM R y SOM C .<br />
En la Figura 7.30(a) po<strong>de</strong>mos ver como la curva <strong>de</strong> speedup <strong>de</strong>l algoritmo<br />
SOM R tiene una gran <strong>de</strong>pen<strong>de</strong>ncia <strong>de</strong>l tamaño <strong>de</strong> la SOM (m). esto no es<br />
sorpren<strong>de</strong>nte, ya que en cada iteración <strong>de</strong>l algoritmo el maestro calcula la<br />
neurona ganadora y la envía a los esclavos. Este proceso <strong>de</strong> comunicación<br />
arruina por completo el comportamiento paralelo cuando el número <strong>de</strong> centros<br />
es <strong>de</strong>masiado pequeño, ya que el cálculo <strong>de</strong> la distancia es rápido. Por<br />
otro lado, la Fig. 7.30(b) muestra speedup <strong>de</strong>l algoritmo <strong>de</strong> la SOM C . Se<br />
consiguen mejores comportamientos para tamaños <strong>de</strong> SOM pequeños o medianos,<br />
para un número dado <strong>de</strong> unida<strong>de</strong>s procesadoras. Cuando el balance<br />
entre el tiempo <strong>de</strong> paso <strong>de</strong> mensajes y el cálculo en el esclavo, se pier<strong>de</strong> (p.e.<br />
incrementando el numero <strong>de</strong> procesos, y <strong>de</strong> esto, <strong>de</strong>crementando el trabajo<br />
hecho por cada uno <strong>de</strong> los esclavos), el algoritmo se vuelve súbitamente<br />
ineficiente, <strong>de</strong>bido al coste <strong>de</strong> paso <strong>de</strong> mensajes.<br />
Estos resultados muestran que ninguno <strong>de</strong> los esquemas es el más eficiente<br />
para todas las situaciones. Por tanto, para la distribución <strong>de</strong> los primeros<br />
datos y luego la carga computacional es necesaria una estrategia híbrida.<br />
Este esquema adaptativo híbrido es a<strong>de</strong>cuado para el entorno GRID, ya que<br />
la distribución <strong>de</strong> recursos <strong>de</strong> datos y <strong>de</strong> cómputo pue<strong>de</strong> ser hecho <strong>de</strong> acuer-
7.5. COMPUTACIÓN DISTRIBUIDA EN LA WEB. TECNOLOGÍA GRID 169<br />
do a los recursos disponibles en el momento <strong>de</strong> la ejecución <strong>de</strong> cada tarea<br />
en el GRID (ver Gutiérrez et al., 2003, para más <strong>de</strong>talles).<br />
10x5 50x2 50x4 50x8<br />
40x20 40x40 Linear speedup<br />
(a)<br />
speedup<br />
20<br />
18<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
2 4 6 8 10 12 14 16 18 20<br />
processors<br />
10x5 50x2 50x4 50x8<br />
40x20 40x40 Linear speedup<br />
(b)<br />
speedup<br />
20<br />
18<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
2 4 6 8 10 12 14 16 18 20<br />
processors<br />
Figura 7.30: Curvas <strong>de</strong> speedup para (a) SOM R (b) SOM C .
170 7. IMPLEMENTACIÓN OPERATIVA. PROMETEO<br />
(código esclavo)<br />
Inicializar los vectores prototipos en todos los procesadores<br />
for (epoch = 1, · · · ,N epoch )<br />
Inicializar los vectores <strong>de</strong> los centros a 0<br />
para (pattern = 1, · · · ,N pattern )<br />
para (cada j ∈ T i )<br />
calcular distancia d j<br />
fin para<br />
calcular nodo ganador g i en T i<br />
MPI Gather para pasar g i al maestro<br />
{∗ 1 }<br />
end for<br />
{∗ 2 }<br />
para (cada j ∈ T i )<br />
actualizar vector <strong>de</strong> prototipos w j<br />
fin para<br />
fin para<br />
(código maestro)<br />
for (epoch = 1, · · · ,N epoch )<br />
para (pattern = 1, · · · ,N pattern )<br />
MPI Gather para recibir g i <strong>de</strong> cada esclavo<br />
calcular el nodo ganador g<br />
{∗ 3 }<br />
fin para<br />
{∗ 4 }<br />
end for<br />
PARSOM R<br />
{∗ 1 } MPI Recv para recibir el nodo ganador g <strong>de</strong>l Maestro<br />
{∗ 2 } Nill<br />
{∗ 3 } MPI Bcast para comunicar el nodo ganador g a los esclavos<br />
{∗ 4 } Nill<br />
PARSOM C<br />
{∗ 1 } Nill<br />
{∗ 2 } MPI Recv para recibir los vectors <strong>de</strong> los centros <strong>de</strong>l Maestro<br />
{∗ 3 } update center vectors<br />
{∗ 4 } MPI Bcast para comunicar los vectores <strong>de</strong> los centros a cada<br />
esclavo<br />
Figura 7.31: Pseudo-código <strong>de</strong> los algoritmos paralelos para SOM R y SOM C<br />
.
Bibliografía<br />
Abarbanel, H. D. I. (1995). Analysis of Observed Chaotic Data. Springer.<br />
An<strong>de</strong>rberg, M. R. (1973). Cluster Analysis for Applications. Aca<strong>de</strong>mic<br />
Press, New York.<br />
An<strong>de</strong>rson, J. L. (1996). Selection of initial conditions for ensemble forecasts<br />
in a simple perfect mo<strong>de</strong>l framework. Journal of Atmospheric<br />
Sciences, 53:22–35.<br />
Ayuso, J. J. (1994). Predicción Estadística Operativa en el INM, vol. B-<br />
34 of Monografías <strong>de</strong>l Instituto Nacional <strong>de</strong> Meteorología. Ministerio <strong>de</strong><br />
Medio Ambiente, Madrid.<br />
Barry, R. and Chorley, R. (1998). Atmosphere, Weather and Climate.<br />
Routledge, London, 7th ed.<br />
Beniston, M. (1998). From Turbulence to Climate: Numerical Investigations<br />
of the Atmosphere with a Hierarchy of Mo<strong>de</strong>ls. Springer-Verlag.<br />
Bergman, M. J. and Delleur, J. W. (1985). Kalman filter estimation<br />
and prediction of daily streamflow: 1- review, algorithm, and simulation<br />
experiements; 2-application to the potomac river. Water Resources Bulletin,<br />
21(5):815–832.<br />
Billet, J., Delisi, M., Smith, B. G., and Gates, C. (1997). Use of<br />
regression techniques to predict hail size and the probability of large hail.<br />
Weather and Forecasting, 12:154–164.<br />
Box, G. E. P. and Jenkins, F. M. (1976). Time Series Analysis: Forecasting<br />
and Control. Hol<strong>de</strong>n-Day, Oakland, CA, 2nd ed.<br />
Brier, G. W. (1950). Verification of forecasts expressed in terms of probability.<br />
Monthly Weather Review, 78:1–3.<br />
Briggs, W. M. and Levine, R. A. (1997). Wavelets and field forecast<br />
verification. Monthly Weather Review, 125:1329–1341.<br />
171
172 BIBLIOGRAFÍA<br />
Buhamra, S., Smaoui, N., and Gabr, M. (2003). The box-jenkins analysis<br />
and neural networks: prediction and time series mo<strong>de</strong>lling. Applied<br />
Mathematical Mo<strong>de</strong>lling, 27:805–815.<br />
Buizza, R. and Palmer, T. N. (1995). Singular vector structure of the<br />
atmospheric global circulation. Journal of Atmospheric Sciences, 52:1434.<br />
Buizza, R., Richardson, D. S., and Palmer, T. N. (2001). The new<br />
80km high-resolution ECMWF EPS. ECMWF Newsletter, spring:90.<br />
Burguer, G. (1996). Expan<strong>de</strong>d downscaling for generating local weather<br />
scenarios. Climate Research, 7:111–128.<br />
Castillo, E., Cobo, A., Gutiérrez, J. M., and Pruneda, E. (1999). An<br />
Introduction to Functional Networks with Applications. Kluwer Aca<strong>de</strong>mic<br />
Publishers, Boston.<br />
Castillo, E., Fontela-Romero, O., Guijarro-Berdiñas, B., and<br />
Alonso-Betanzos, A. (2002). A global optimum approach for one-layer<br />
neural networks. Neural Computation, 14(6):1429–1449.<br />
Cavazos, T. (1997). Downscaling large-scale circulation to local winter<br />
rainfall in north-eastern mexico. International Journal of Climatology,<br />
17:1069–1082.<br />
Cavazos, T. (2000). Using self-organizing maps to investigate extreme<br />
climate event: An application to wintertime precipitation in the balkans.<br />
Journal of Climate, 13:1718–1732.<br />
Chatfield, C. (2003). The Analysis of Time Series: An Introduction. CRC<br />
Press, 6th ed.<br />
Chen, M., Xie, P., Janowiak, J. E., and Arkin, P. A. (2002). Precipiation:<br />
A 50-yr monthly analysis based on gauge observations. Journal<br />
of Hydrometeorology, 3:249–266.<br />
Cofiño, A. S., Abbott, P., and Gutiérrez, J. M. (2003a). Linguistic<br />
fractal analysis of symbolic sequences. In P. Mitic and et al., eds.,<br />
Chanllenging the Boundaries of Symbolic Computation, pp. 1–8. World<br />
Scientific Publication, Singapore.<br />
Cofiño, A. S., Cano, R., and Gutiérrez, J. M. (2002). Bayesian networks<br />
for probabilistic weather prediction. In Proceedings of the 15th<br />
European Conference on Artificial Intelligence, pp. 695–700. IOS Press.<br />
Cofiño, A. S., Cano, R., Gutiérrez, J. M., and Rodríguez, M. A.<br />
(1999). Prometeo: Un sistema experto para el pronóstico meteorológico<br />
local basado en re<strong>de</strong>s neuronales y cálculo <strong>de</strong> analogías. In Actas <strong>de</strong> las<br />
III Jornadas <strong>de</strong> Transferencia Tecnológica <strong>de</strong> Inteligencia Artificial., pp.<br />
11–19. CAEPIA.
BIBLIOGRAFÍA 173<br />
Cofiño, A. S., Cano, R., López, F. J., Gutiérrez, J. M., and Rodríguez,<br />
M. A. (2001a). Aplicación <strong>de</strong> métodos <strong>de</strong> clasificación al downscaling<br />
estadístico. In Actas <strong>de</strong>l V Simposio Nacional <strong>de</strong> Predicción, pp.<br />
49–50. Instituto Nacional <strong>de</strong> Meteorología, Madrid.<br />
Cofiño, A. S., Ciszak, M., and Gutierrez, J. M. (2003b). A practical<br />
approach to predictability in chaotic systems. Neural networks and<br />
anticipated synchronization. Enviado a Physica A.<br />
Cofiño, A. S. and Gutiérrez, J. M. (2001). Optimal modular feedforward<br />
neural networks based on functional networks. Lecture Notes in<br />
Artificial Intelligence, 2083:308–315.<br />
Cofiño, A. S., Gutiérrez, J. M., and Ivanissevich, M. L. (2003c).<br />
Evolving modular networks with genetic algorithms. application to nonlinear<br />
time series. Enviado a Expert Systems.<br />
Cofiño, A. S., Ivanissevich, M. L., and Gutiérrez, J. M. (2000). An<br />
hybrid evolutive genetic strategy for solving the inverse fractal problem<br />
of ifs mo<strong>de</strong>ls. Lecture Notes in Artificial Intelligence, 1952:467–476.<br />
Cofiño, A. S., Ivanissevich, M. L., and Gutiérrez, J. M. (2001b).<br />
Minimum <strong>de</strong>scription length quality measurues for modular functional<br />
networks. In Actas <strong>de</strong>l VII Congreso Argentino <strong>de</strong> Ciencias <strong>de</strong> la Computación,<br />
pp. 115–125.<br />
Cofiño, A. S., Primo, C., Cano, R., Sordo, C., and Gutiérrez, J. M.<br />
(2003d). Downscaling <strong>de</strong>meter seasonal ensemble precipitation forecasts<br />
in the tropics during el niño episo<strong>de</strong>s. Geophysical Research Abstracts,<br />
5:14586.<br />
Cofiño, A., Cano, R., and Gutiérrez, J. (2003a). Self-organizing maps<br />
for statistical downcaling in ensemble prediction systems. Climate Dynamics<br />
(enviado).<br />
Cofiño, A. S., Gutiérrez, J. M., Jakubiak, B., and Melonek, M.<br />
(2003b). Implementation of data mining techniques for meteorological<br />
applications. In W. Zwieflhofer and N. Kreitz, eds., Realizing Teracomputing,<br />
pp. 215–240. World Scientific.<br />
Corte-Real, J., Quian, B., and Xu, H. (1999). Circulation patterns,<br />
daily precipitation in portugal and implications for climate change simulated<br />
by the second hadley centre gcm. Climate Dynamics, 15:921–935.<br />
Díaz, E., García-Moya, J. A., Cofiño, A. S., and Orfila, B. (2003).<br />
Downscaling techniques applied to outputs of the <strong>de</strong>meter project over<br />
specific mediterranean regions. Geophysical Research Abstracts, 5:986.
174 BIBLIOGRAFÍA<br />
Drake, J., Foster, I., Michalakes, J., Toonen, B., and Worley, P.<br />
(1995). Design and performance of a scalable parallel community climate<br />
mo<strong>de</strong>l. Parallel Computing, December:245–257.<br />
Enke, W. and Spekat, A. (1997). Downscaling climate mo<strong>de</strong>l outputs<br />
into local and regional weather elements by classification and regression.<br />
Climate Research, 8:195–207.<br />
Faufoula-Georgiou, E. and Lettenmaier, D. P. (1987). A markov<br />
renewal mo<strong>de</strong>l for rainfall occurrences. Water Resources Research, 23:875–<br />
884.<br />
Fayyad, U. M., Piatetsky Shapiro, G., Smyth, P., and Uthurusamy,<br />
R. (1996). Advances in Knowledge Discovery and Data Mining. AAAI<br />
Press/The MIT Press, Cambridge, MA.<br />
Fernán<strong>de</strong>z, A., <strong>de</strong>l Hoyo, J., Peral, C., and Mestre, A. (2001). El<br />
sistema <strong>de</strong> predicción analógica <strong>de</strong>l la precipitación en el inm. Publicación<br />
interna <strong>de</strong>l INM.<br />
Fontela-Romero, O., Alonso-Betanzos, A., Castillo, E., Principe,<br />
J. C., and Guijarro-Berdiñas, B. (2002). Local mo<strong>de</strong>ling using<br />
self-organizing maps and single layer neural networks. Lectures Notes in<br />
Computer Science, 2415:945–950.<br />
Foster, I. and Kesselman, C. (1999). The Grid: Blueprint for a New<br />
Computing Infraestructure. Morgan-Kaufmann.<br />
Fovell, R. G. and Fovell, M. Y. C. (1993). Climate zones of the conterminous<br />
united states <strong>de</strong>fined using cluste analysis. Journal of Climate,<br />
6:2103–2135.<br />
Furundzic, D. (1998). Application example of neural networks for time<br />
series analysis: rainfall-runoff mo<strong>de</strong>ling. Signal Processing, 64:383–396.<br />
Gabriel, K. R. and Neumann, J. (1962). A markov chain mo<strong>de</strong>l for<br />
daily rainfall occurrences at Tel Aviv. Quaterly Journal of the Royal<br />
Meteorological Society, 88:90–95.<br />
Gardner, M. W. and Dorling, S. R. (1998). Artificial neural networks<br />
(the multilayer perceptron). A review of applicatios in the atmospheric<br />
sciences. Journal of Applied Meteorology, 39:147–159.<br />
Gollub, J. P. and Cross, M. C. (2000). Chaos in space and time. Nature,<br />
404:710–711.<br />
Grassberger, P. and Procaccia, I. (1983). Characterization of strange<br />
attractors. Physical Review Letters, 50:346–349.
BIBLIOGRAFÍA 175<br />
Gutiérrez, J. M., Cano, R., Cofiño, A. S., and Rodríguez, M. A.<br />
(2004a). Clustering methods for statistical downscaling in short-range<br />
weather forecast. Monthly Weather Review (en prensa).<br />
Gutiérrez, J. M., Cano, R., Cofiño, A. S., and Sordo, C. (2004b).<br />
Re<strong>de</strong>s Probabilística y <strong>Neuronales</strong> para las Ciencias Atmosféricas. Monografías<br />
<strong>de</strong>l Instituto Nacional <strong>de</strong> Meteorología. Ministerio <strong>de</strong> Medio<br />
Ambiente, Madrid. (en prensa).<br />
Gutiérrez, J. M., Cano, R., Cofiño, A. S., and Rodríguez, M. A.<br />
(1999). Re<strong>de</strong>s neuronales y patrones <strong>de</strong> analogías aplicados al downscaling<br />
climático. In La Climatología Española en los Albores <strong>de</strong>l Siglo XXI, pp.<br />
113–121. Asociación Española <strong>de</strong> Climatología.<br />
Gutiérrez, J. M., Cofiño, A. S., Cano, R., and Sordo, C. (2002a).<br />
A generalization of analogue downscaling methods by bayesian networks.<br />
In International Conference on Quatitative Precipitation Forecasting, pp.<br />
87–87. The World Weather Research Programme’s WWRP.<br />
Gutiérrez, J. M., Cofiño, A. S., Cano, R., and Sordo, C. (2002b).<br />
Probabilistic networks for statistical downscaling and spatialisation of meteorological<br />
data. Geophysical Research Abstracts, 4:192.<br />
Gutiérrez, J. M., Cofiño, A. S., and Ivanissevich, M. L. (2001). A<br />
comparison of different evolutive niching strategies for i<strong>de</strong>ntifying a set of<br />
selfsimilar contractions for the ifs inverse problem. Journal of Computer<br />
Science and Technology, 2(5):234–246.<br />
Gutiérrez, J. M., Cofiño, A. S., and Luengo, F. (2003). Grid oriented<br />
implementation of self-organizing maps for data mining in meteorology.<br />
Lecture Notes in Computer Science (en prensa).<br />
Gutiérrez, J. M., Sordo, C., Cano, R., Cofiño, A. S., and Rodríguez,<br />
M. A. (2002c). Dynamic bayesian networks for probabilistic<br />
time series prediction. Geophysical Research Abstracts, 4:284.<br />
Gutiérrez, J., Cofiño, A., Cano, R., and Primo, C. (2004). Analysis<br />
and downscaling multi-mo<strong>de</strong>l seasonal forecasts using self-organizing<br />
maps. Tellus A (en prensa).<br />
Hastie, T., Tibshirani, R., and Friedman, J. (2001). The Elements of<br />
Statistical Learning. Springer, New York.<br />
Hewitson, B. C. and Crane, R. G. (2002). Self-organizing maps: applications<br />
to synoptic climatology. Climate Research, 22(1):13–26.<br />
Hoerl, A. E. and Kennard, R. W. (1970). Ridge regression: biased<br />
estimation for nonorthogonal problems. Technometrics, 12:55–82.
176 BIBLIOGRAFÍA<br />
Hoffmann, G. (2001). Grid computing for meteorology. In W. Zwieflhofer<br />
and N. Kreitz, eds., Developments in Teracomputing, pp. 117–126. World<br />
Scientific.<br />
Holton, J. (1992). An Introduction to Dynamic Meteorology. Aca<strong>de</strong>mic<br />
Press.<br />
Hsieh, W. W. (2001). Nonlinear canonical correlation analysis of the tropical<br />
pacific climate variability using a neural network approach. Journal<br />
of Climate, 14:2528–2539.<br />
Hsieh, W. W. and Tang, B. (1998). Applying neural network mo<strong>de</strong>ls to<br />
prediction and data analysis in meteorology and oceanography. Bulletin of<br />
the American Meteorological Society, 79:1855–1870.<br />
Hughes, J., Lettemaier, D. P., and Guttorp, P. (1993). A stochastic<br />
approach for assessing the effect of changes in regional circulation patterns<br />
on local precipitation. Water Resources Research, 29:3303–3315.<br />
Hurrell, J. W. (1995). Decadal trends in the north atlantic oscillation and<br />
relationships to regional temperature and precipitation. Science, 269:676–<br />
679.<br />
Jolliffe, I. T. and Stephenson, D. B. (2003). Forecast Verification.<br />
John Wiley and Sons.<br />
Judd, K. (2003). Nonlinear state estimation, indistinguishable states, and<br />
the exten<strong>de</strong>d kalman filter. Physica D, 183:273–281.<br />
Kalkstein, L. S., Tan, G., and Skindlov, J. A. (1987). An evaluation of<br />
three clustering procedures for use in synoptic climatological classification.<br />
Journal of Climate and Applied Meteorology, 26:717–730.<br />
Kalnay, E. (2003). Atmospheric Mo<strong>de</strong>ling, Data Assimilation and Predictability.<br />
Cambridge University Press.<br />
Klein, W. H. and Glahn, H. R. (1974). Forecasting local weather by<br />
means of mo<strong>de</strong>l output statistics. Bulletin of the American Meteorological<br />
Society, 55:1217–1227.<br />
Kohonen, T. (2000). Self-Organizing Maps. Springer-Verlag, Berlin, 3rd<br />
ed.<br />
Köppen, W. (1918). Klassifikation <strong>de</strong>r klimate nach temperatur, nie<strong>de</strong>rschlag<br />
und jahreslauf. Petermanns Mitt, 64:193–203.<br />
Kramer, M. A. (1991). Nonlinear principal component analysis using<br />
autoassociative neural networks. Neural Computation, 9(7):1493–1516.<br />
Lorenz, E. N. (1963). Deterministic nonperiodic flow. Physical Review<br />
Letters, 20:130–141.
BIBLIOGRAFÍA 177<br />
Lorenz, E. N. (1969). Atmospheric predictability as revealed by naturally<br />
occuring analogues. Journal of the Atmospheric Sciences, 26:636–646.<br />
Lorenz, E. N. (1991). Dimension of weather and climate attractors. Nature,<br />
353:241–244.<br />
Lorenz, E. N. (1996). The Essence of Chaos. University of Washington<br />
Press.<br />
Macedo, M., Cook, D., and Brown, T. J. (2000). Visual data mining<br />
in atmospheric science data. Data Mining and Knowledge Discovery,<br />
4:69–80.<br />
Marzban, C. (2003). A neural network for post-processing mo<strong>de</strong>l output:<br />
ARPS. Monthly Weather Review, 131(6):1103–1111.<br />
Masters, T. (1995). Neural, Novel and Hybrid Algorithms for Time Series<br />
Prediction. John Wiley & Sons.<br />
McGinnis, D. L. (1994). Predicting snowfall from synoptic circulation: A<br />
comparison of linear regression and neural networks. In B. Hewitson and<br />
R. G. Crane, eds., Neural Nets: Applications in Geography, pp. 79–99.<br />
Kluwer Aca<strong>de</strong>mic Publishers.<br />
Middleton, G. (2000). Data Analysis in the Earth Sciences Using MAT-<br />
LAB. Prentice Hall.<br />
Mo, K. C. and Livezey, R. E. (1986). Tropical-extratropical geopotential<br />
height teleconnections during the northern hemisphere winter. Monthly<br />
Weather Review, 114:2488–2515.<br />
Murphy, A. H. (1973). A new vector partition of probability score. Journal<br />
of Applied Meteorology, 12:595–600.<br />
Murphy, A. H. (1993). What is a good forecast? an essay on the nature<br />
of goodness in weather forecasting. Weather and Forecasting, 8:281–293.<br />
Murphy, A. H. and Winkler, R. L. (1987). A general framework for<br />
forecast verification. Monthly Weather Review, 115:1330–1338.<br />
Noguer, M. (1994). Using statistical techniques to <strong>de</strong>duce local climate<br />
distributions. an application for mo<strong>de</strong>l validation. Meteorological Applications,<br />
1:277–287.<br />
Oja, E. and Kaski, S. (1999). Kohonen Maps. Elsevier, Amsterdam.<br />
Oliver, J. (1991). The history, status and future of climatic classification.<br />
Physical Geography, 12:231–251.
178 BIBLIOGRAFÍA<br />
Palmer, T. N., Alessandri, A., An<strong>de</strong>rsen, U., Cantelaube, P., Davey,<br />
M., Délécluse, P., Déqué, M., Díez, E., Doblas-Reyes, F. J.,<br />
Fed<strong>de</strong>rsen, H., Graham, R., Gualdi, S., Guérémy, J. F., Hagedorn,<br />
R., Hoshen, M., Keenlysi<strong>de</strong>, N., Latif, M., Lazar, A., Maisonnave,<br />
E., Marletto, V., Morse, A. P., Orfila, B., Rogel, P.,<br />
Terres, J. M., and Thomson, M. C. (2003). Development of a european<br />
enseble system for seasonal to inter-annual prediction (DEMETER).<br />
URL http://www.ecmwf.int/research/<strong>de</strong>meter/. Enviado a Bulletin<br />
of the American Meteorological Society.<br />
Peña, J. M., Lozano, J. A., and Larrañaga, P. (1999). An empirical<br />
comparison of four initialization methods for the k-means algorithm.<br />
Pattern Recognition Letters, 20:1027–1040.<br />
Pérez-Muñuzuri, V. and Gelpi, I. R. (2000). Application of nonlinear<br />
forecasting techniques for meteorological mo<strong>de</strong>ling. Annales Geophysicae,<br />
18:1349–1359.<br />
Philan<strong>de</strong>r, S. G. (1990). El Niño, La Niña, and the Southern Oscillation.<br />
Aca<strong>de</strong>mic Press, San Diego.<br />
Preisendorfer, R. W. and Mobley, C. D. (1988). Principal component<br />
analysis in meteorology and oceanography. Elsevier, Amsterdam.<br />
Press, W. H., Teulosky, S. A., Vetterling, W. T., and Flannery,<br />
B. P. (1992). Numerical Recipies. Cambridge University Press, Cambridge,<br />
2nd ed.<br />
Pu, Z.-X., Kalnay, E., Parrish, D., Wu, W., and Toth, Z. (1997). The<br />
use of the bred vectors in the ncep operational 3-dimensional variational<br />
system. Weather and Forecasting, 12:689–695.<br />
Richardson, D. S. (2000). Skill and economic value of the ecmwf ensemble<br />
prediction system. Quaterly Journal of the Royal Meteorological Society,<br />
126:649–668.<br />
Rodríguez-Fonseca, B. and Serrano, E. (1991). Winter 10-day coupled<br />
patterns between geopotential height and iberian peninsula rainfall using<br />
the ecmwf precipitation reanalysis. Journal of Climate, 15:1309–1321.<br />
Rodriguez-Iturbe, I., Cox, D. R., and Isham, V. (1987). Some mo<strong>de</strong>ls<br />
for rainfall based on stochastic point processes. Proc. of the Royeal Society<br />
of London A, 410:269–288.<br />
Rosenblat, F. (1962). Principles of Neurodynamics. Spartan, New York.<br />
Rumelhart, D. E. and McClelland, J. L. (1986). Parallel Distributed<br />
Processing: Explorations in the Microstructure of Cognition. The MIT<br />
Press, Cambridge.
BIBLIOGRAFÍA 179<br />
Sauer, T. (1994). Time series prediction by using <strong>de</strong>lay coordinate embedding.<br />
In A. S. Weigend and N. A. Gershenfeld, eds., Time Series Prediction:<br />
Forecasting the Future and Un<strong>de</strong>rstanding the Past, pp. 175–193.<br />
Addison-Wesley.<br />
Schizas, C. N., Pattichis, C. S., and Michaeli<strong>de</strong>s, S. C. (1994). Artificial<br />
neural networks in weather forecasting. Neural Networks, pp. 219–<br />
230.<br />
Schoof, J. T. and Pryor, S. C. (2001). Downscaling temperature and precipitation:<br />
A comparison of regression-based methods and artificial neural<br />
networks. International Journal of Climatology, 21(7):773–790.<br />
Shannon, C. E. (1948). A mathematical theory of communication. The<br />
Bell System Technical Journal, 27:623–656.<br />
Stern, R. D. (1982). Computing a probability distribution for the start of<br />
the rains from a markov chain mo<strong>de</strong>l for precipitation. Journal of Applied<br />
Meteorology, 21(3):420–422.<br />
Talagrand, O. (1997). Evaluation of probabilistic prediction systems. In<br />
Workshop on predictability, pp. 1–25. ECMWF.<br />
Toth, Z. (1991). Circulation patterns in phase space. A multinormal distribution?<br />
Montly Weather Review, 119:1501–1511.<br />
Tsonis, A. A. and Elsner, J. B. (1988). The wheater atrractor over very<br />
short time scales. Nature, 333:545–547.<br />
van <strong>de</strong>n Dool, H. M. (1989). A new look at weather forecasting though<br />
analogs. Montly Weather Review, 117:2230–2247.<br />
Verma, U., Yadav, M., and Hasija, R. C. (2002). A seasonal arima<br />
mo<strong>de</strong>l for monthly rainfall sequence. In 16th Australian Statistical Conference.<br />
Canberra, Australia.<br />
von Storch, H. (1999). On the use of “inflation”in statistical downscaling.<br />
Journal of Climate, 12:3505–3506.<br />
Wanner, H., Bronnimann, S., Casty, C., Fyalistras, D., Luterbacher,<br />
J., Schmutz, C., Stephenson, D. B., and Xoplaki, E. (2001).<br />
North atlantic oscillation – concepts and studies. Surveys in Geophysics,<br />
22:321–382.<br />
Wilby, R. L. and Wigley, T. M. L. (1997). Downscaling general circulation<br />
mo<strong>de</strong>l output. A review of methods and limitations. Progress in<br />
Physical Geography, 21:530–548.<br />
Wilby, R. L. and Wilks, D. S. (1999). The weather generation game.<br />
A review of stochastic weather mo<strong>de</strong>ls. Progress in Physical Geography,<br />
23:329–357.
180 BIBLIOGRAFÍA<br />
Wilks, D. S. (1995). Statisticaql methods in the atmospheric sciences.<br />
Aca<strong>de</strong>mic Press.<br />
Witten, I. H. and Frank, E. (1999). Data Mining: Practical Machine<br />
Learning Tools and Techniques with Java Implementations. Morgan<br />
Kaufmann.<br />
WMO (1994). Gui<strong>de</strong> to wmo binary co<strong>de</strong> form grib 1. technical report no.<br />
17.<br />
Wunsch, C. (1999). The interpretation of short climate records, with comments<br />
on the north atlantic and southern oscillation. Bulletin of the<br />
American Meteorological Society (BAMS), 80:245–255.<br />
Yuval and Hsieh, W. W. (2003). An adaptive nonlinear MOS scheme for<br />
precipitation forecasts using neural networks. Weather and Forecasting,<br />
18(2):303–310.<br />
Zhu, Y., Toth, Z., Wobus, R., Richardson, D., and Mylne, K.<br />
(2001). On the economic value of ensemble based weather forecasts. Bulletin<br />
of American Meteorological Society, 83:73–85.<br />
Zorita, E., Hughes, J. P., P, L. D., and von Storch, H. (1995). Stochastic<br />
characterization of regional circulation patterns for climate mo<strong>de</strong>l<br />
diagnosis and estimation of local precipitation. Journal of Climate,<br />
8:1023–1042.<br />
Zorita, E. and von Storch, H. (1999). The analog method as a simple<br />
statistical downscaling technique: Comparison with more complicated<br />
methods. Journal of Climate, 12:2474–2489.<br />
Zwiers, F. W. and von Storch, H. (1990). Regime <strong>de</strong>pen<strong>de</strong>nt autoregressive<br />
time series mo<strong>de</strong>lling of the southern oscillation. Journal of<br />
Climate, 3:1347–1363.