

Ãberdeckende Klassifikation
Ãberdeckende Klassifikation
Ãberdeckende Klassifikation

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
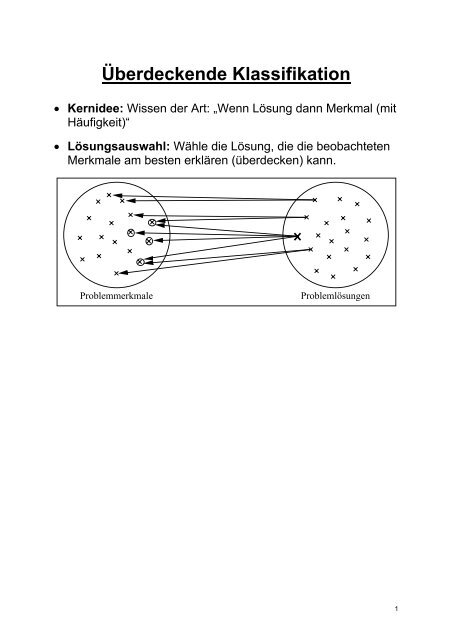
Überdeckende <strong>Klassifikation</strong>• Kernidee: Wissen der Art: „Wenn Lösung dann Merkmal (mitHäufigkeit)“• Lösungsauswahl: Wähle die Lösung, die die beobachtetenMerkmale am besten erklären (überdecken) kann.ProblemmerkmaleProblemlösungen1
Beispiele zur überdeckenden<strong>Klassifikation</strong>Luftfilterverstopft+ +Abgase schwarzGasgemischzu fett+ +Verbrennungfehlerhaft+ +Benzinverbrauchzu hochBenzinfilterverstopft– –zu wenig+ + + +BenzinHöchstleistungnicht erreichtRisikofaktoren+ +Arteriosklerose+ +Aufregung+Koronarsklerose(Angina Pectoris)*Nitroglycerin+ +erhöhterBlutbedarf+ +unzureichendeBlutversorgungdes Herzens+ +– –erniedrigterBlutbedarf+ ++ +AnstrengungBrustschmerzRuhe2
Komplexitätsstufen1. Wissensrepräsentation (mit Beispiel):1. Einfache Überdeckungsrelationen: Lösung Merkmal, z.B.Angina Pectoris (AP) belastungsabhängiger Brustschmerz (bB)2. Gewichte der Merkmale, z.B. Gewicht (bB): wichtig3. Häufigkeiten der Überdeckungsrelationen wie „immer“, oft, ...z.B. Häufigkeit von AP bB: meistens4. Berücksichtigung ähnlicher Merkmale bei Überdeckungsrelationen,z.B. bei Normalverteilungen numerischer MerkmaleErkl(AP)z.B. Schmerzstärke bB auf Skala 1-10:gutAP kann 3-5 gut; 2 sowie 6-7 mäßig; mäßigschlecht1 sowie 8-10 nur schlecht erklären.1 2 3 4 5 6 7 8 9 105. Schweregrade der Lösungen und Überdeckungsrelationenz.B. Schweregrade: je ausgeprägter AP, desto stärker bBv(bB)6. Zeitliche Entwicklung, z.B. stabile AP instabile AP Herzinfarktzu 1.-4.: „Kausaler Diagnose-Score“2. Problemlösungsmethoden• Merkmalsgesteuerte Propagierung: „Kausaler Diagnose-Score“• Bayes’sche Netze (s. Vorlesung „Künstliche Intelligenz“)• Berechnung von Mehrfachüberdeckungen• Simulative Überdeckungsverfahren3
Kausaler Diagnose-ScoreZweck, AnwendbarkeitZweckWähle die beste Lösung aus einer Menge von Alternativen aus,indem das Lösungsobjekt gewählt wird, das die vorhandenenBeobachtungen am besten erklären (überdecken) kann.Anwendbarkeit• Allgemeine Eignung von kausalen Diagnose-Scores: Siekennen die typischen Merkmale der Diagnosen.• Die Merkmalserfassung ist standardisiert, d.h. es ist nichtnotwendig, gezielt Untersuchungen zur Erfassung speziellerMerkmale zu indizieren. Falls dies erforderlich ist, benötigenSie das Zusatzmodul „Untersuchungsindikation“.• Die Einzelmerkmale sind relativ unabhängig voneinanderund haben für sich bereits eine gewisse Aussagekraft. Fallsdies nicht gilt, sollten sie zunächst zu höherwertigen„Merkmalsabstraktionen“ aggregiert, bevor sie diagnostischinterpretiert werden. Dazu benötigen Sie das Zusatzmodul„Datenabstraktion“. Das ist insbesondere bei Benutzern mitgeringem Vorwissen oder der Interpretation vorgegebenerMeßdaten sinnvoll.• Kausale Diagnosescores eignen sich sowohl zum Herleiteneiner Lösung (Single Fault Assumption) als auch zumHerleiten mehrerer Lösungen.4
KDS: BeispielGewicht Kiefer Tanne FichteNadeln = ja G5 (32) ++ ++ ++Nadeln = neinG5Rundliche Zapfen G3 (8) ++Längliche Zapfen G3 ++ ++-- hängend G4 (16) ++-- stehend G4 ++ ++Lange Nadeln G4 ++Kurze Nadeln G4 ++ ++-- eher scheitelförmig G3 + ++-- rundum G3 + ++Geborstene Rinde G3 ++ ++ ++Glatte RindeG3Rötliche Stammfarbe G3 +Weißliche Stammfarbe G4braun/graue Stammfarbe G3 + ++ ++5
StrukturKDS: Struktur und TeilnehmerUntersuchungaktiviere-Startfrage (Fragen)StartfragenFrageAntworttypAntwortaltern. v WertebereichAbnormitätGewichtWertaktiviere-Folgefrage (Fragen)lässt-sich-erklären (Lö., Pkte)gewichte (Punkte)stelle-Frage (selbst)prüfe-Antwort (selbst)kann_erklären(Bed., Häuf.)erklärbar_durch(Bed., Häuf.)erklärtFolgefragen(Bedingung)ErläuterungVorschlagKonto+Konto-neutralLösungpräsentiere (selbst)hole-gewicht (Fall)berechne-Überdeckungsgrad ()Teilnehmer:Lösung (Diagnose):- repräsentiert eine Problemlösung- enthält allgemeine Informationen zur Problemlösung- enthält ein Liste von Merkmalen (mit Bedingung über Wertund Häufigkeitsangabe), die es erklären kann.- Die in einem konkreten Fall erklärten Merkmale werden aufeiner Liste „erklärt“ gespeichert.- besitzt ein Erklärungskonto (Konto+), das dieErklärungsfähigkeit der Lösung aufsummiert. (AnmerkungD3: Falls Merkmale nur teilweise erklärt sind, wird der nichterklärte Rest auf einem „Konto-neutral“ gespeichert).Untersuchung (Frageklasse):- bewirkt systematische Datenerfassung zur Lösungsfindung- besteht aus einer Liste von Startfragen.Frage (Merkmal, Symptom)- besteht aus einem Fragetext und Antwortalternativen, ggf.mit Erläuterungen,- enthält Verweise mit Bedingungen auf Folgefragen- enthält Gewicht und Abnormität pro Antwortalternative- enthält Verweise mit Bedingungen auf Lösungen, durch diesie erklärbar ist (invers zu Lösung; kann-erklären).6
KDS: Interaktionen:eineUntersuchung:eine Frage Fall :eine Lösungstart()prüfe-Antwort()aktiviere-Startfragen()stelle-Frage()aktiviere-Folgefrage()prüfe-Antwort()stelle-Frage()gewichte()lässt-sich-erklären()hole-gewicht()präsentiere()1. Beim Systemaufruf werden die Untersuchungen aktiviert.2. Die aktuelle Untersuchung aktiviert ihre Startfragen.3. Die Startfragen werden dem Benutzer gestellt. Aufgrund seinerAntworten und der Bedingungen werden eventuell Folgefragengestellt. Die Erklärungsbedürftigkeit wird aus Gewichtund Abnormität des Wertes berechnet (hole-Gewicht), anden „Fall“ und - abhängig von der Häufigkeit bei „kannerklären“ - an die zugehörigen Lösungen übertragen.4. Für jede Lösung werden das positive und das neutraleErklärungskonto (konto+, konto-neutral) sowie die Liste dererklärten Merkmale aktualisiert.5. Als Ergebnis werden die besten n Lösungen mit ihrerprozentualen Erklärungsfähigkeit ausgegeben und ggf.Mengen von Mehrfachlösungen berechnet.7
KDS: Konsequenzen• Vorteile:- Kausale Diagnose-Scores benutzen leicht verfügbaresWissen, das sich häufig in der Literatur findet. Es musskein negatives Wissen formalisiert werden.- Sie sind änderungsfreundlich.- Mehrfachdiagnosen lassen sich gut herleiten- Das Bewertungswissen von Diagnose-Scores lässt sichaufgrund seiner regulären Struktur durch Tabellen gutvisualisieren und eingeben und ist leicht verständlich.• Probleme:- Ein Nachteil im Vergleich zu Diagnose-Scores ist diegeringere Trennschärfe, u.a. weil keine negative Bewertungenbenutzt werden.- Falls Merkmalskombinationen zu überproportional starkenDiagnosebewertungen führen, eignen sich Einzelbewertungennicht.- Da es kein einfaches Konzept für Schwellen zur Ermittlungdes Status von Diagnosen gibt, sind Diagnose-Diagnose-Beziehungen nicht leicht zu realisieren.8
KDS: Implementierung in D3a) Eingabe der Diagnosen in der Diagnosehierarchie,b) der Frageklassen (Untersuchungen) in Symptomhierarchie.c) und der Startfrageklassen im Formular „zur Wissensbasis“.d) Eingabe der Fragen, Antwortalternativen, Folgefragen(regeln)zu einer Frageklasse im Entscheidungsbaumeditor.e) Eingabe von Multimedia-Dokumenten (html) in derAttributtabelle zu den betroffenen Objekten.f) Eingabe von Fragetexten und textuellen Erklärungen zuFragen in der Attributtabelle.g) Eingabe von Gewichten und Abnormitäten zu Fragen in derAttributtabelle.h) Eingabe der relevanten Problemmerkmale für jede Diagnoseim Editor „Regelelemente“.i) Eingabe der eigentlichen Diagnose-Bewertungen in derüberdeckenden Übersichtstabelle für eine oder mehrereausgewählte Diagnosen. Die Defaultkonfiguration enhält 7Häufigkeits-Kategorien mit folgender Semantik:p7 = immer: Merkmal kommt zu 100% bei Lösung vorp6 = fast immer: Merkmal kommt zu 95% bei Lösung vorp5 = weitaus meistens: Merkmal kommt zu 80% bei Lösung vorp4 = mehrheitlich: Merkmal kommt zu 64% bei Lösung vorp3 = häufig: Merkmal kommt zu 40% bei Lösung vorp2 = manchmal: Merkmal kommt zu 20% bei Lösung vorp1 = selten: Merkmal kommt zu 10% bei Lösung vorp0 = egal Keine positive oder negative Beziehungzwischen Merkmal und Lösung9
KDS: Beispiel aus D310
Berechnung von MehrfachüberdeckungenBasisalgorithmus: Probiere alle Kombinationen von Diagnosenaus, die alle beobachteten Merkmale überdecken. Dabei ist dieReihenfolge des Ausprobierens kritisch (Suchstrategien):1. Breitensuche nach Kardinalitäten: Erst alle 1-elementigen,dann alle 2-elementigen Mengen usw. Verbesserung: Betrachtenur Diagnosen, die mindestens ein Merkmal überdecken.2. Breitensuche nach Apriori-Wahrscheinlichkeiten: Erst dieMenge (egal welcher Kardinalität) mit der höchsten Apriori-Wahrscheinlichkeit, dann mit der zweithöchsten usw.Verbesserung: s.o.3. Hill-Climbing nach Überdeckungsgrad: Nehme erst dieDiagnose, die die meisten (wichtigsten) Merkmale überdeckt,füge dann diejenige hinzu, die von den restlichen Merkmalendie meisten (wichtigsten) überdeckt usw.4. Bestensuche: Grundstrategie nach 3., aber es werden mehrereNachfolger gemäß Kriterien aus 1, 2 und 3 generiert.11
Simulative Überdeckungsverfahren1. Verdachtsgenierung: Generiere plausible Diagnosemengenmit Schweregraden2. Verdachtsüberprüfung mittels Simulation: Simuliere dieAuswirkungen der Diagnosemengen aus Schritt 1.3. Bewertung: Wähle die beste Menge aus (Kriterien sind z.B.beste Überdeckung, minimale Anzahl nicht bestätigterzusätzlicher Merkmalsvorhersagen, höchste Apriori-Wahrscheinlichkeit, minimale Kardinalität).Probleme:• Wie setzt man die Schweregrade der Verdachtsdiagnosen?zweistufiges Verfahren: zunächst Generierung ohne Schweregrade,dann systematische Variation möglicher Schweregrade.• Wie simuliert man Rückkopplungsschleifen?positive Rückkopplungsschleifen: kein Gleichgewichtszustandnegative Rückkopplungsschleifen:1. Approximation2. Unter der Voraussetzung von nur linearen Beziehungen:Der Zuwachs eines Zustandes bewirkt einen proportionalenZuwachs (mit einem Faktor x) beim Nachfolgezustand.Dann gilt: Einfluss (im Gleichgewichtszustand) =Primäreinfluss / (1 – Stärke der Rückkopplungsschleife)Beispiel:Primäreinfluss = +3 +1ABEinfluss im Gleichgewichtszustandnach Rückkopplung:3 / (1 - (-2)) = +1-1 +2C12
Lineare Approximation nicht-linearerBeziehungenTypen von nichtlinearen Beziehungen:• Mehrfach-Beziehungen (z.B. zwischen Pulsfrequenz undHerzminutenvolumen: (1) Pulsfrequenz * Herzschlagvolumen= Herzminutenvolumen; (2) Je höher die Pulsfrequenz, destogeringer das Herzschlagvolumen),• additive Beziehungen,• muliplikative Beziehungen,• nicht-lineare Beziehungen (z.B. Frank-Sterling-Beziehung:Wenn der Blutdruck des einlaufenden Blutes in dieHerzkammer niedrig ist, dann hat steigender Blutdruckstarken Einfluss auf das Schlagvolumen. Wenn der Blutdruckdes einlaufenden Blutes in die Herzkammer hoch ist, dannhat steigender Blutdruck wenig Einfluss auf dasSchlagvolumen),• Beziehungen, die Zeit erfordern (z.B. die Verstärkung derHerzmuskulatur wegen Herzinsuffizienz).Beispiel für lineare Approximation:yf (B)f (x) = yxA BDie Sättigungskurve f (x) = y wird durch drei Intervalle approximiert:FallsxAxf (A)
Funktionale Diagnostik• Kernidee: Wissen über die normale Funktionsweise einesaus Komponenten und Materialien bestehenden Systems.• Lösungsauswahl: Symptome sind Diskrepanzen derMaterialien zwischen erwartetem und beobachtetem Wert.Diagnosen sind Komponenten mit abnormem Verhalten, diedie Diskrepanzen vorhersagen können.• Beispiel:AMult-1XBAdd-1FCMult-2YDEMult-3ZAdd-2G= Komponente= MaterialMaterialien: A, B, C, D, E, X, Y, Z, F, G: Typ Zahl mit Attribut WertKomponenten:Mult-1, Mult-2, Mult-3: Typ Multiplizierer; Verhalten: In1* In2 = OutAdd-1, Add-2: Typ Addierer; Verhalten: In1 + In2 = OutEin Fall:1. Es wird beobachtet: A=2, B=3, C=3, D=2, E=2, F= 10, G=12.2. Daraus folgt eine Diskrepanz bei F (erwartet: 12, beobachtet: 10).3. Fehler-Kandidaten sind: Mult-1, Mult-2, Add-1.4. Bei Simulation der Kandidaten fällt Mult-2 aus.5. Zur Unterscheidung zwischen Mult-1 und Add-1 muss der Wert vonX getestet werden.Bemerkung: Es gibt mehr Fehlertypen als nur Komponentenfehler!14
Modellbeispiel-1: VergasermotorBenzin-1 Benzinfilter Benzin-2 Luft-2 Luftfilter Luft-1VergaserGasgemisch-1= Komponente= MaterialKraft-1MotorAbgase-1Materialien: Luft-1, Luft-2: Typ Luft mit Attributen Verschmutzungsgrad {dreckig, sauber}und Druck {normal, zu niedrig}Benzin-1, Benzin-2: Typ Benzin mit Attributen Verschmutzungsgrad {dreckig,sauber} und Druck {normal, zu niedrig}Gasgemisch-1: Typ Gasgemisch mit Attribut Verhältnis {zu fett, normal, zu mager}Abgase-1: Typ Abgase mit Attribut Farbe {farblos, schwarz}Kraft-1: Typ Kraft mit Attribut Intensität {normal, zu niedrig}Komponenten: Luftfilter in den Zuständen {Normal, Verstopft, Gerissen} mit Regeln:Normal: Luft-2.Verschmutzungsgrad ::= sauberLuft-2.Druck ::= Luft-1.DruckVerstopft: Luft-2.Verschmutzungsgrad ::= sauberLuft-2.Druck ::= "erniedrige Luft-1.Druck um eine Stufe"Gerissen: Luft-2.Verschmutzungsgrad ::= Luft-1. VerschmutzungsgradLuft-2.Druck ::= Luft-1.DruckBeschreibung der übrigen Komponenten entsprechend.15
Modellbeispiel-2: BlutkreislaufLuft-1Luft-2LungeBlut-4Blut-3linkeHerzkammerrechteHerzkammerBlut-1Blut-2KörperAktivität-1= Komponente= MaterialMaterialien: Blut-1, Blut-2, Typ Blut mit Attributen Sauerstoff {hoch, mittel, niedrig}Blut-3, Blut-4: und Druck {hoch, mittel, niedrig}Luft-1, Luft-2: Typ Luft mit Attribut Sauerstoff{normal, erniedrigt}Aktivität-1: Typ Aktivität mit Attribut Intensität {normal, erniedrigt}Komponenten: Es wird jeweils nur das Normalverhalten der Komponenten beschrieben:linke Herzkammer: Blut-1.Druck ::= hoch; Blut-1.Sauerstoff ::= Blut-4.SauerstoffKörper: Blut-2.Druck ::= niedrig; Blut-2.Sauerstoff ::= niedrigAktivität-1 ::= Blut-1.Sauerstoffgehalt (normal
Problemlösungsmethode ähnlich wiesimulative überdeckende DiagnostikEingabe: Wertebelegungen von Eingangs- und Ausgangs-Materialien,Ausgabe: Zustände von Komponenten.1. Entdeckung von Diskrepanzen: Berechne Werte derAusgangs-Materialien unter der Annahme, dass alleKomponenten im Normalzustand sind, und vergleiche siemit den vorgegebenen Werten. Jede Differenz ist eineDiskrepanz.2. Verdachtsgenerierung: Ermittle für jede Diskrepanz eine"Konfliktmenge", die alle Komponenten und ihre in Fragekommenden Zustände enthält, die direkt oder indirekt ander Berechnung der Diskrepanz beteiligt sind. Bilde "minimaleTreffermengen" aller Konfliktmengen.3. Verdachtsüberprüfung: Jede Treffermenge ist eine Verdachtshypothese,die simuliert wird, indem die entsprechendenZustände von Komponenten verändert werden.4. Differentialdiagnostik: Vergleiche bei jeder Simulation dievorhergesagten mit den beobachteten Zuständen. Kriterienfür die vergleichende Bewertung verschiedener Hypothesensind:a) Herleitung aller beobachteten Diskrepanzenb) Herleitung keiner nicht beobachteten Diskrepanzc) möglichst kleine Menge defekter Komponenten (evtl.gewichtet mit Apriori-Wahrscheinlichkeit der Zustände)Bemerkung: Wenn man kein Wissen über Komponenten hat,gibt es neben dem Normalzustand nur den Zustand „abnorm“,der beliebige (fehlerhafte) Werte seiner Ausgangsmaterialengeneriert. Besser ist es, man gibt mögliche Fehlerzustände mitdezidiertem Fehlverhalten an (s. Modellbeispiel-1), dann ist dieSimulation genauer.17
Beispiel aus D3: Funktionales Modell fürFalzapparat einer Druckmaschine18
Spezifikation des Fehlverhaltens vonKomponenten-Zuständen19







