

Extraction and Integration of MovieLens and IMDb Data - APMD
Extraction and Integration of MovieLens and IMDb Data - APMD
Extraction and Integration of MovieLens and IMDb Data - APMD

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
<strong>Extraction</strong> <strong>and</strong> <strong>Integration</strong> <strong>of</strong> <strong>MovieLens</strong> <strong>and</strong> <strong>IMDb</strong> <strong>Data</strong> – Technical Report<br />
10<br />
− Aggregate tasks build aggregations (P’ in Figure 13) for storing existing values <strong>of</strong> a specific attribute, i.e.<br />
master tables (e.g. movie genres). Tasks are implemented as SQL operations <strong>of</strong> the form:<br />
INSERT INTO P’ (<br />
SELECT column1,... columnK<br />
FROM P-ref<br />
GROUP BY column1,... columnK;<br />
The following sub-sections describe the specific tasks <strong>of</strong> each data set.<br />
2.3.1. ETL process for the large data set<br />
The large data set was quite consistent: no duplicates were found, no violations to referential constraints were<br />
detected. However, we detected <strong>and</strong> solved some minor anomalies:<br />
− Genres were represented as multi-valued attributes (pipe-separated lists) in source files. Normalization<br />
routines were performed.<br />
− ZIP codes contained letters <strong>and</strong> ZIP intervals. We ignored such errors <strong>and</strong> stored values as Strings.<br />
− Master tables for ages <strong>and</strong> occupations were created from scratch in order to associate descriptions to age<br />
ranges <strong>and</strong> occupation ids.<br />
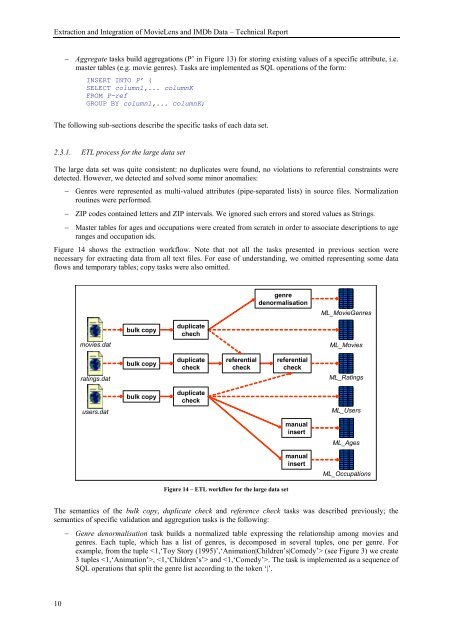
Figure 14 shows the extraction workflow. Note that not all the tasks presented in previous section were<br />
necessary for extracting data from all text files. For ease <strong>of</strong> underst<strong>and</strong>ing, we omitted representing some data<br />
flows <strong>and</strong> temporary tables; copy tasks were also omitted.<br />
movies.dat<br />
ratings.dat<br />
users.dat<br />
bulk copy<br />
bulk copy<br />
bulk copy<br />
duplicate<br />
chech<br />
duplicate<br />
check<br />
duplicate<br />
check<br />
referential<br />
check<br />
genre<br />
denormalisation<br />
Figure 14 – ETL workflow for the large data set<br />
referential<br />
check<br />
manual<br />
insert<br />
manual<br />
insert<br />
ML_MovieGenres<br />
ML_Movies<br />
ML_Ratings<br />
ML_Users<br />
ML_Ages<br />
ML_Occupations<br />
The semantics <strong>of</strong> the bulk copy, duplicate check <strong>and</strong> reference check tasks was described previously; the<br />
semantics <strong>of</strong> specific validation <strong>and</strong> aggregation tasks is the following:<br />
− Genre denormalisation task builds a normalized table expressing the relationship among movies <strong>and</strong><br />
genres. Each tuple, which has a list <strong>of</strong> genres, is decomposed in several tuples, one per genre. For<br />
example, from the tuple (see Figure 3) we create<br />
3 tuples , <strong>and</strong> . The task is implemented as a sequence <strong>of</strong><br />
SQL operations that split the genre list according to the token ‘|’.




