

Extraction and Integration of MovieLens and IMDb Data - APMD
Extraction and Integration of MovieLens and IMDb Data - APMD
Extraction and Integration of MovieLens and IMDb Data - APMD

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
<strong>Extraction</strong> <strong>and</strong> <strong>Integration</strong> <strong>of</strong> <strong>MovieLens</strong> <strong>and</strong> <strong>IMDb</strong> <strong>Data</strong> – Technical Report<br />
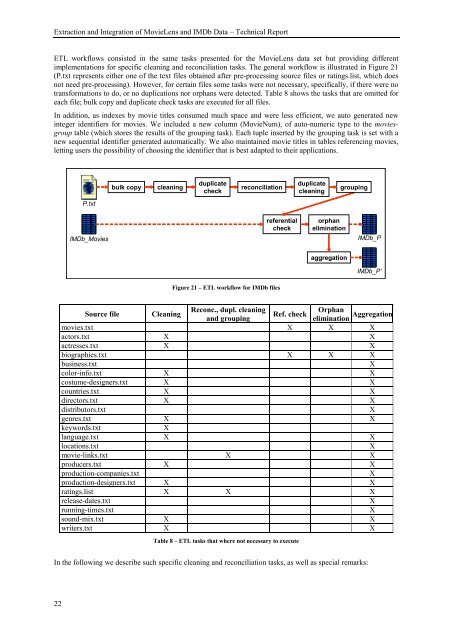
ETL workflows consisted in the same tasks presented for the <strong>MovieLens</strong> data set but providing different<br />
implementations for specific cleaning <strong>and</strong> reconciliation tasks. The general workflow is illustrated in Figure 21<br />
(P.txt represents either one <strong>of</strong> the text files obtained after pre-processing source files or ratings.list, which does<br />
not need pre-processing). However, for certain files some tasks were not necessary, specifically, if there were no<br />
transformations to do, or no duplications nor orphans were detected. Table 8 shows the tasks that are omitted for<br />
each file; bulk copy <strong>and</strong> duplicate check tasks are executed for all files.<br />
In addition, as indexes by movie titles consumed much space <strong>and</strong> were less efficient, we auto generated new<br />
integer identifiers for movies. We included a new column (MovieNum), <strong>of</strong> auto-numeric type to the moviesgroup<br />
table (which stores the results <strong>of</strong> the grouping task). Each tuple inserted by the grouping task is set with a<br />
new sequential identifier generated automatically. We also maintained movie titles in tables referencing movies,<br />
letting users the possibility <strong>of</strong> choosing the identifier that is best adapted to their applications.<br />
22<br />
P.txt<br />
<strong>IMDb</strong>_Movies<br />
bulk copy<br />
cleaning<br />
duplicate<br />
check<br />
Figure 21 – ETL workflow for <strong>IMDb</strong> files<br />
duplicate<br />
reconciliation grouping<br />
cleaning<br />
referential<br />
check<br />
orphan<br />
elimination<br />
aggregation<br />
<strong>IMDb</strong>_P<br />
<strong>IMDb</strong>_P’<br />
Source file Cleaning<br />
Reconc., dupl. cleaning<br />
<strong>and</strong> grouping<br />
Ref. check<br />
Orphan<br />
elimination Aggregation<br />
movies.txt X X X<br />
actors.txt X X<br />
actresses.txt X X<br />
biographies.txt X X X<br />
business.txt X<br />
color-info.txt X X<br />
costume-designers.txt X X<br />
countries.txt X X<br />
directors.txt X X<br />
distributors.txt X<br />
genres.txt X X<br />
keywords.txt X<br />
language.txt X X<br />
locations.txt X<br />
movie-links.txt X X<br />
producers.txt X X<br />
production-companies.txt X<br />
production-designers.txt X X<br />
ratings.list X X X<br />
release-dates.txt X<br />
running-times.txt X<br />
sound-mix.txt X X<br />
writers.txt X X<br />
Table 8 – ETL tasks that where not necessary to execute<br />
In the following we describe such specific cleaning <strong>and</strong> reconciliation tasks, as well as special remarks:




