

Extraction and Integration of MovieLens and IMDb Data - APMD
Extraction and Integration of MovieLens and IMDb Data - APMD
Extraction and Integration of MovieLens and IMDb Data - APMD

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Verónika Peralta<br />
− Manual insert tasks create new tables by executing a list <strong>of</strong> manually-entered insert operations, for<br />
example:<br />
INSERT INTO ML_Ages (AgeId, MinAge, MaxAge)<br />
VALUES (18, 18, 24);<br />
2.3.2. ETL process for the small data set<br />
We detected <strong>and</strong> solved several anomalies in the small data set:<br />
− We found 18 duplicate titles (with different MovieId). These tuples would cause duplicates when<br />
matching (by title) <strong>IMDb</strong> movies. We kept, arbitrarily, the smaller MovieId <strong>of</strong> each duplicate title.<br />
− There was a movie with title='Unknown' <strong>and</strong> null values for ReleaseYear <strong>and</strong> <strong>IMDb</strong>URL. The movie was<br />
eliminated.<br />
− Ratings <strong>of</strong> eliminated movies were also eliminated. Substituting their MovieId for those <strong>of</strong> the kept<br />
movies would carry to duplicates with contradictory ratings.<br />
− Genres were denormalized in source files (one Boolean attribute for each genre). Normalization routines<br />
were performed.<br />
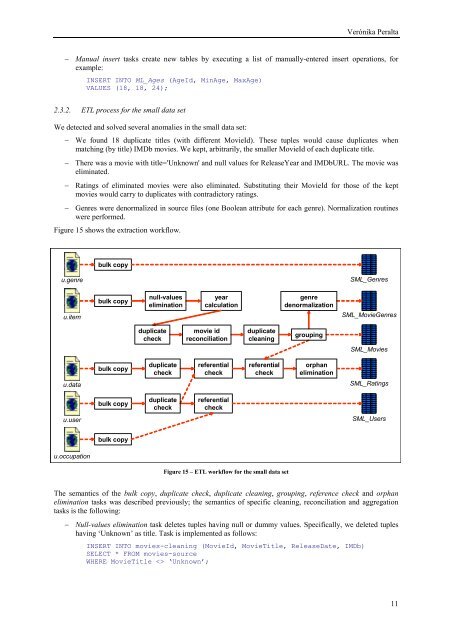
Figure 15 shows the extraction workflow.<br />
u.genre<br />
u.item<br />
u.data<br />
u.user<br />
u.occupation<br />
bulk copy<br />
bulk copy<br />
bulk copy<br />
bulk copy<br />
bulk copy<br />
null-values<br />
elimination<br />
duplicate<br />
check<br />
duplicate<br />
check<br />
duplicate<br />
check<br />
year<br />
calculation<br />
movie id<br />
reconciliation<br />
referential<br />
check<br />
referential<br />
check<br />
duplicate<br />
cleaning<br />
referential<br />
check<br />
Figure 15 – ETL workflow for the small data set<br />
genre<br />
denormalization<br />
grouping<br />
orphan<br />
elimination<br />
SML_Genres<br />
SML_MovieGenres<br />
SML_Movies<br />
SML_Ratings<br />
SML_Users<br />
The semantics <strong>of</strong> the bulk copy, duplicate check, duplicate cleaning, grouping, reference check <strong>and</strong> orphan<br />
elimination tasks was described previously; the semantics <strong>of</strong> specific cleaning, reconciliation <strong>and</strong> aggregation<br />
tasks is the following:<br />
− Null-values elimination task deletes tuples having null or dummy values. Specifically, we deleted tuples<br />
having ‘Unknown’ as title. Task is implemented as follows:<br />
INSERT INTO movies-cleaning (MovieId, MovieTitle, ReleaseDate, <strong>IMDb</strong>)<br />
SELECT * FROM movies-source<br />
WHERE MovieTitle ‘Unknown’;<br />
11




