

Handwritten Word Spotting in Old Manuscript Images using Shape ...
Handwritten Word Spotting in Old Manuscript Images using Shape ...
Handwritten Word Spotting in Old Manuscript Images using Shape ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
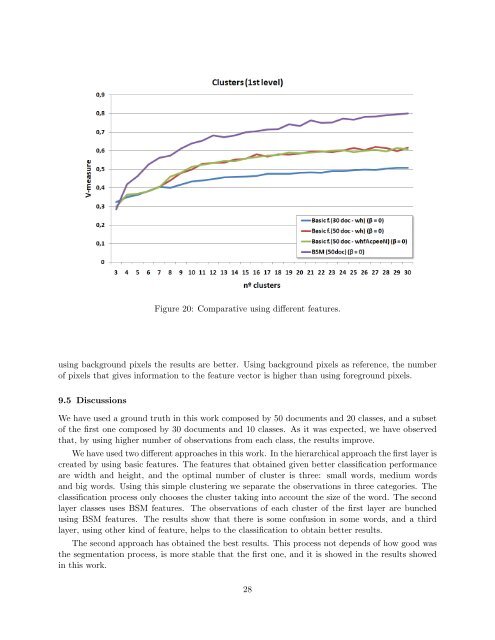
Figure 20: Comparative us<strong>in</strong>g different features.<br />
us<strong>in</strong>g background pixels the results are better. Us<strong>in</strong>g background pixels as reference, the number<br />
of pixels that gives <strong>in</strong>formation to the feature vector is higher than us<strong>in</strong>g foreground pixels.<br />
9.5 Discussions<br />
We have used a ground truth <strong>in</strong> this work composed by 50 documents and 20 classes, and a subset<br />
of the first one composed by 30 documents and 10 classes. As it was expected, we have observed<br />
that, by us<strong>in</strong>g higher number of observations from each class, the results improve.<br />
We have used two different approaches <strong>in</strong> this work. In the hierarchical approach the first layer is<br />
created by us<strong>in</strong>g basic features. The features that obta<strong>in</strong>ed given better classification performance<br />
are width and height, and the optimal number of cluster is three: small words, medium words<br />
and big words. Us<strong>in</strong>g this simple cluster<strong>in</strong>g we separate the observations <strong>in</strong> three categories. The<br />
classification process only chooses the cluster tak<strong>in</strong>g <strong>in</strong>to account the size of the word. The second<br />
layer classes uses BSM features. The observations of each cluster of the first layer are bunched<br />
us<strong>in</strong>g BSM features. The results show that there is some confusion <strong>in</strong> some words, and a third<br />
layer, us<strong>in</strong>g other k<strong>in</strong>d of feature, helps to the classification to obta<strong>in</strong> better results.<br />
The second approach has obta<strong>in</strong>ed the best results. This process not depends of how good was<br />
the segmentation process, is more stable that the first one, and it is showed <strong>in</strong> the results showed<br />
<strong>in</strong> this work.<br />
28










