Star Schema ×××¡× × × ×ª×× ×× Star Schema â Example 1 Star Schema
Star Schema ×××¡× × × ×ª×× ×× Star Schema â Example 1 Star Schema
Star Schema ×××¡× × × ×ª×× ×× Star Schema â Example 1 Star Schema

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
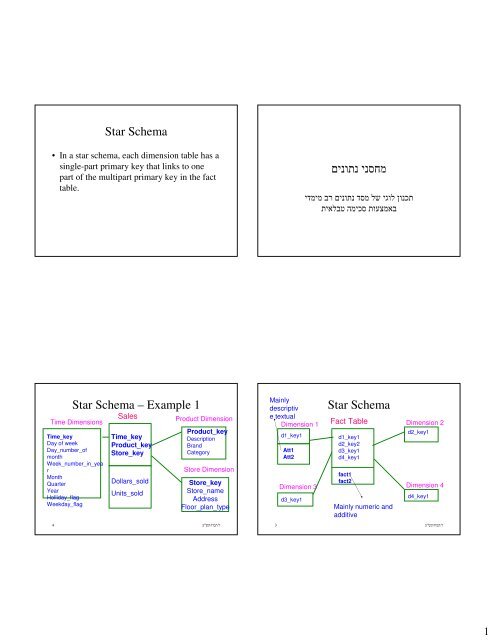
<strong>Star</strong> <strong>Schema</strong><br />
• In a star schema, each dimension table has a<br />
single-part primary key that links to one<br />
part of the multipart primary key in the fact<br />
table.<br />
מחסני נתונים<br />
תכנון לוגי של מסד נתונים רב מימדי<br />
באמצעות סכימה טבלאית<br />
4<br />
<strong>Star</strong> <strong>Schema</strong> – <strong>Example</strong> 1<br />
Time Dimensions<br />
Time_key<br />
Day of week<br />
Day_number_of<br />
month<br />
Week_number_in_yea<br />
r<br />
Month<br />
Quarter<br />
Year<br />
Holliday_flag<br />
Weekday_flag<br />
Sales<br />
Time_key<br />
Product_key<br />
Store_key<br />
Dollars_sold<br />
Units_sold<br />
Product Dimension<br />
Product_key<br />
Description<br />
Brand<br />
Category<br />
Store Dimension<br />
Store_key<br />
Store_name<br />
Address<br />
Floor_plan_type<br />
Mainly<br />
descriptiv<br />
e textual<br />
Dimension 1 Fact Table<br />
Dimension 2<br />
3<br />
d1_key1<br />
Att1<br />
Att2<br />
d2_key1<br />
fact1<br />
Dimension 3<br />
fact2<br />
Dimension 4<br />
d3_key1<br />
<strong>Star</strong> <strong>Schema</strong><br />
d1_key1<br />
d2_key2<br />
d3_key1<br />
d4_key1<br />
Mainly numeric and<br />
additive<br />
d4_key1<br />
ז'/תמוז/תש"ע<br />
ז'/תמוז/תש"ע<br />
1
<strong>Star</strong> <strong>Schema</strong> – <strong>Example</strong> 3<br />
<strong>Star</strong> <strong>Schema</strong> – <strong>Example</strong> 2<br />
Reminder: Normal Forms<br />
Seeks to eliminate data redundancy: transaction that<br />
changes any data only need to touch the database in<br />
one place (optimized for updates)<br />
The Standard Template Query<br />
Select p.brand, sum(f.dollars),sum(f.units)<br />
From sales f, product p, time t<br />
Where f.product_key=p.product_key<br />
And f.time_key = t.time_key<br />
And t.quarter=“1 Q 1995”<br />
Group by p.brand<br />
2
On the other hand …<br />
1. Complexity of query specification is high.<br />
Without normalization it will be much clearer to<br />
user. (Simple queries structures)<br />
2. Poor access efficiency – Normalized design is<br />
the worst, by far, for most query access. A<br />
normalized design is optimized for key- based,<br />
record-at-a-time inquiry or table-level query that<br />
efficiently uses the provided indexes.<br />
Resisting Normalization<br />
1. Eliminate redundancy? – Generally eliminating duplicate rows<br />
is good. However eliminating "redundant" attributes in a star<br />
schema dimension table will actually destroy its high- access<br />
efficiency. Time saving (browsing performance) is much more<br />
critical in data warehouse.<br />
2. Save space? – This corollary to eliminating redundancy is a<br />
holdover from another era. The relative impact of storage on cost<br />
is way down. The loss of access efficiency has far greater cost<br />
impact. Furthermore The Fact table in a dimensional schema is<br />
naturally highly normalized. Disk space saving due to<br />
normalization is typically less than 1%.<br />
3. Support efficient update? Does not apply at all - Data<br />
Warehouse is Nonvolatile: no updates of data (only data<br />
loading). The load methods for relational tables in a star schema<br />
design can actually be more efficient than a load of normalized<br />
transaction and snow- flaked reference data.<br />
Division<br />
Division_id<br />
Division_desc<br />
ER - BCNF<br />
Region<br />
Region_id<br />
Region_desc<br />
Why Normalization of Dimension does<br />
not save space?<br />
– A typical <strong>Example</strong><br />
• Fact Table data size:<br />
• Fact Table index size:<br />
• Largest dim’ table size:<br />
• Savings by normalization:<br />
• Total size before:<br />
• Total size after:<br />
30GB<br />
20GB<br />
0.1GB<br />
0.05GB<br />
51GB<br />
50.5GB.<br />
Dept<br />
Dept_id<br />
Dept_desc<br />
Division_id<br />
Sales Facts<br />
Dept_id<br />
Market_id<br />
Week_id<br />
Sales<br />
Market<br />
Market_id<br />
Market_desc<br />
Region_id<br />
3
Snowflake <strong>Schema</strong><br />
Dimensional (Denormalization)<br />
• In a snowflake schema, one or more dimension<br />
tables are decomposed into multiple tables with<br />
the subordinate dimension tables joined to a<br />
primary dimension table instead of to the fact<br />
table.<br />
• i.e.:A refinement of star schema where some<br />
dimensional hierarchy is normalized into a set of<br />
smaller dimension tables, forming a shape similar<br />
to snowflake<br />
Dept. Lookup<br />
Dept_id<br />
Dept_desc<br />
Division_desc<br />
Sales Facts<br />
Dept_id<br />
Market_id<br />
Week_id<br />
Sales<br />
Market Lookup<br />
Market_id<br />
Market_desc<br />
Region_desc<br />
Snowflake <strong>Schema</strong><br />
Sales<br />
Snowflake <strong>Schema</strong><br />
Large Hierarchy<br />
Customer<br />
Time_key<br />
Customer_Key<br />
15<br />
amount<br />
Customer_Key<br />
Demo_Key<br />
Name<br />
…<br />
Demographic<br />
Demo_Key<br />
Income_Level<br />
Age_Level<br />
Sex<br />
ז'/תמוז/תש"ע<br />
4
Sales<br />
Time_key<br />
Customer_Key<br />
Demo_Key<br />
18<br />
amount<br />
Mini-Dimension<br />
Customer<br />
Customer_Key<br />
Name<br />
…<br />
Demographic<br />
Demo_Key<br />
Income_Level<br />
Age_Level<br />
Sex<br />
ז'/תמוז/תש"ע<br />
<strong>Star</strong> schemas or Snowflake schemas?<br />
• Both star and snowflake schemas can represents the<br />
same dimensional models; the difference is in their<br />
RDBMS implementations.<br />
• Snowflake schemas support ease of dimension<br />
maintenance because they are more normalized.<br />
• <strong>Star</strong> schemas are easier for direct user access and<br />
often support simpler and more efficient queries.<br />
• The decision to model a dimension as a star or<br />
snowflake depends on the nature of the dimension<br />
itself, such as how frequently it changes and which<br />
of its elements change, and often involves<br />
evaluating tradeoffs between ease of use and ease<br />
of maintenance.<br />
• In most designs, star schemas are preferable to<br />
snowflake schemas because they involve fewer joins<br />
for information retrieval.<br />
• Surrogate keys<br />
– A surrogate key is the primary key for a dimension table and is<br />
independent of any keys provided by source data systems.<br />
– Surrogate keys are created and maintained in the data warehouse and<br />
should not encode any information about the contents of records;<br />
– automatically increasing integers make good surrogate keys.<br />
– The original key for each record may be carried in the dimension<br />
table but is not used as the primary key.<br />
– Benefits:<br />
• a layer of isolation between DW and the source system;<br />
• Simple: numeric keys<br />
• Can handle ambiguous ID’s.<br />
– Drawback: increased ETL processing<br />
Dimensions Keys<br />
• Using Original Operational keys<br />
– Benefit: reduced transformation effort<br />
– Drawbacks:<br />
• Compound and textual keys;<br />
• Dependency on the source systems (OLTP); for instance what<br />
happen if the operational system create new key when customer<br />
change address, while we don’t want to create a “new” customer.<br />
• Ambiguous ID’s coming from different sources;<br />
– Multiple application systems<br />
– World wide companies with many branches: each branch uses its<br />
own customer’s counting.<br />
– companies that have done mergers or acquisitions.<br />
5
Time/Date Dimension<br />
• For hourly time granularity, the hour<br />
breakdown can be incorporated into the date<br />
dimension or placed in a separate dimension.<br />
• Business needs influence this design decision.<br />
• If the main use is to extract contiguous<br />
chunks of time that cross day boundaries (for<br />
example 11/24/2000 10 p.m. to 11/25/2000 6<br />
a.m.), then it is easier if the hour and day are<br />
in the same dimension.<br />
• However, it is easier to analyze cyclical and<br />
recurring daily events if they are in separate<br />
dimensions.<br />
• Unless there is a clear reason to combine date<br />
and hour in a single dimension, it is generally<br />
better to keep them in separate dimensions!<br />
Time/Date Dimension<br />
• A date dimension with one record per day will suffice if users do<br />
not need time granularity finer than a single day. A date by day<br />
dimension table will contain 365 records per year (366 in leap<br />
years).<br />
• A separate time dimension table should be constructed if a fine<br />
time granularity, such as minute or second, is needed. A time<br />
dimension table of one-minute granularity will contain 1,440 rows<br />
for a day, and a table of seconds will contain 86,400 rows for a<br />
day. If exact event time is needed, it should be stored in the fact<br />
table.<br />
• When a separate time dimension is used, the fact table contains<br />
one foreign key for the date dimension and another for the time<br />
dimension. Separate date and time dimensions simplify many<br />
filtering operations. For example, summarizing data for a range of<br />
days requires joining only the date dimension table to the fact<br />
table. Analyzing cyclical data by time period within a day requires<br />
joining just the time dimension table. The date and time dimension<br />
tables can both be joined to the fact table when a specific time<br />
range is needed.<br />
6