

ALU Design 4-bit Ripple Carry Adder RCA Equations
ALU Design 4-bit Ripple Carry Adder RCA Equations
ALU Design 4-bit Ripple Carry Adder RCA Equations

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
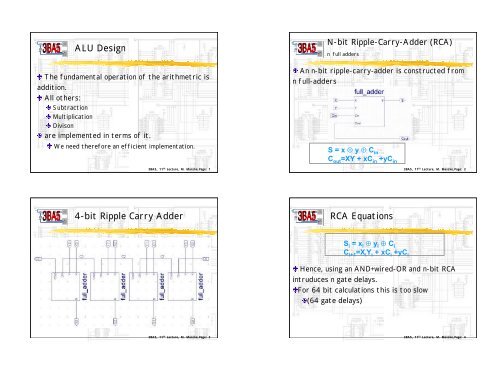
<strong>ALU</strong> <strong>Design</strong><br />
The fundamental operation of the arithmetric is<br />
addition.<br />
All others:<br />
Subtraction<br />
Multiplication<br />
Divison<br />
are implemented in terms of it.<br />
We need therefore an efficient implementation.<br />
3BA5, 11 th Lecture, M. Manzke,Page: 1<br />
N-<strong>bit</strong> <strong>Ripple</strong>-<strong>Carry</strong>-<strong>Adder</strong> (<strong>RCA</strong>)<br />
n full adders<br />
An n-<strong>bit</strong> ripple-carry-adder is constructed from<br />
n full-adders<br />
S = x ¯ y ¯ C in<br />
C out =XY + xC in +yC in<br />
3BA5, 11 th Lecture, M. Manzke,Page: 2<br />
4-<strong>bit</strong> <strong>Ripple</strong> <strong>Carry</strong> <strong>Adder</strong><br />
<strong>RCA</strong> <strong>Equations</strong><br />
S i = x i ¯ y i ¯ C i<br />
C i+1 =X i Y i + xC i +yC i<br />
Hence, using an AND+wired-OR and n-<strong>bit</strong> <strong>RCA</strong><br />
intruduces n gate delays.<br />
For 64 <strong>bit</strong> calculations this is too slow<br />
(64 gate delays)<br />
3BA5, 11 th Lecture, M. Manzke,Page: 3<br />
3BA5, 11 th Lecture, M. Manzke,Page: 4
<strong>Carry</strong> Lookahead<br />
Boolean Expression<br />
C i+1 = x i y i + C i (x i + y i )<br />
C 1 = x 0 y 0 + C 0 (x 0 + y 0 )<br />
C 2 = x 1 y 1 + C 1 (x 1 + y 1 )<br />
= x 1 y 1 + [x 0 y 0 + C 0 (x 0 + y 0 )](x 1 + y 1 )<br />
with g i = x i y i<br />
p i = x i + y i<br />
Generate <strong>Carry</strong><br />
<strong>Carry</strong> Propagate<br />
C i+1 = g i + p i C i<br />
<strong>Carry</strong> Lookahead<br />
Boolean Expression<br />
C 1 = x 0 y 0 + C 0 (x 0 + y 0 )<br />
= g 0 + C 0 p 0<br />
C 2 = x 1 y 1 + C 1 (x 1 + y 1 )<br />
= x 1 y 1 + [x 0 y 0 + C 0 (x 0 + y 0 )](x 1 + y 1 )<br />
= g 1 + p 1 g 0 + p 0 p 1 C 0<br />
C 3 = g 2 + p 2 g 1 + p 1 p 2 g 0 + p 0 p 1 p 2 C 0<br />
C 4 = g 3 + p 3 g 2 + p 2 p 3 g 1 + p 1 p 2 p 3 g 0 + p 0 p 1 p 2 p 3 C 0<br />
C i+1 = g i + p i C i<br />
3BA5, 11 th Lecture, M. Manzke,Page: 5<br />
3BA5, 11 th Lecture, M. Manzke,Page: 6<br />
4-<strong>bit</strong> <strong>Carry</strong> Lookahead <strong>Adder</strong><br />
C 4 <strong>Carry</strong> Block<br />
C 4 = g 3 + p 3 g 2 + p 2 p 3 g 1 + p 1 p 2 p 3 g 0 + p 0 p 1 p 2 p 3 C 0<br />
3BA5, 11 th Lecture, M. Manzke,Page: 7<br />
3BA5, 11 th Lecture, M. Manzke,Page: 8
<strong>Carry</strong> Lookahaed <strong>Adder</strong><br />
Groups of Input Bits<br />
C i+1 = g i + p i g i-1 + p i p i-1 g i-2 + … + p i p i-1 …p 0 C 0<br />
This requires just two gate delays:<br />
One to generate g i and p i<br />
Another to AND them<br />
Again we can use wired OR<br />
But, it requires AND gates with a fan in of n<br />
In practice we can only efficiently build single gates<br />
with a limited fan-in<br />
we build the lookahead circuit as a multi-level circuit<br />
3BA5, 11 th Lecture, M. Manzke,Page: 9<br />
For example, let fan-in = 4 and define:<br />
G i ’ A carry out is generated in the i th group of four input <strong>bit</strong>s<br />
P i ’ A carry out is propagated by the i th group of four input <strong>bit</strong>s<br />
G 0 ’ = g 3 + p 3 g 2 + p 2 p 3 g 1 + p 1 p 2 p 3 g 0<br />
P 0 ’ = p 0 p 1 p 2 p 3<br />
C 4 = G 0 ’ + C 0 P 0 ’<br />
C 8 = G 1 ’ + P 1 ’G 0 ’ + P 0 ’P 1 ’C 0<br />
C 12 = G 2 ’ + P 2 ’G 1 ’ + P 1 ’P 2 ’G 0 ’ + P 0 ’P 1 ’P 2 ’C 0<br />
3BA5, 11 th Lecture, M. Manzke,Page: 10<br />
C 4 = G 0 ’ + C 0 P 0 ’<br />
Genetate G’’ and Propagate P’’<br />
C 8 = G 1 ’ + P 1 ’G 0 ’ + P 0 ’P 1 ’C 0<br />
3BA5, 11 th Lecture, M. Manzke,Page: 12<br />
The next level of genetate G’’ and propagate P’’<br />
terms will caover 16 <strong>bit</strong>s<br />
G’’ = G 3 ’ + P 3 ’G 2 ’ + P 3 ’P 2 ’G 1 ’ + P 3 ’P 2 ’P 1 ’G 0<br />
P’’ = P 3 ’P 2 ’P 1 ’P 0<br />
3BA5, 11 th Lecture, M. Manzke,Page: 11
64-<strong>bit</strong> <strong>Adder</strong> Propergation Delay<br />
<strong>Carry</strong> Save <strong>Adder</strong> (CSA)<br />
We can implement a 64-<strong>bit</strong> adder using AND-or logic<br />
with a fan-in = 4 and a maximum propergation delay of:<br />
t pmax = 3(G 1 ’) + 2(G 1 ’’) + 2(C 48 ) + 2(C 60 ) + 3(S 63 )<br />
= 12 gate delays<br />
Compare this with <strong>RCA</strong> using AND-wiredOR which<br />
requires 64 gate delays.<br />
If we add a third layer (G’’’, P’’’) we can construct<br />
a 4x64 = 256 <strong>bit</strong> adder with maximum delay:<br />
t pmax = 3 + 2 + 2 + 2 + 2 + 2 + 3<br />
= 16 gate delays<br />
3BA5, 11 th Lecture, M. Manzke,Page: 13<br />
In situations where we have a lot of numbers to add:<br />
Multiplication (adding partial products)<br />
Accumulation Loop<br />
We can defer the propergation of carries until the<br />
last last addition.<br />
S = X + Y + Z + W<br />
= (X + Y + Z) + W -- CSA 1<br />
= 2 x C1 + S1 + W -- CSA 2<br />
= 2 x C2 + S2 -- CLA<br />
= S3<br />
3BA5, 11 th Lecture, M. Manzke,Page: 14













