Repeated Measures ANOVA
Repeated Measures ANOVA
Repeated Measures ANOVA

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
<strong>Repeated</strong>-<strong>Measures</strong><br />
Analysis of Variance
Types of Within-Subject Designs<br />
PTrue “Within-Subjects” Design<br />
Each subject is measured under each treatment<br />
condition<br />
E.g., effects of amount of background noise on a<br />
memory task (e.g., no background noise, 10 db,<br />
20db)<br />
P<strong>Repeated</strong> <strong>Measures</strong> Design<br />
Each subject is measured at two or more points in<br />
time<br />
E.g., effects of exercise on heart rate (rest, after 1<br />
min on treadmill, after 5 min on treadmill)
Types of Within-Subject Designs<br />
PProfile Analysis<br />
Scores on different tests (DVs), which are<br />
comparably scaled, are compared<br />
E.g., comparing scores on scales of the MMPI<br />
PMatched Subjects Designs<br />
A type of within-subject design where instead of<br />
having subjects participate in all levels of the IV,<br />
different subjects, which are matched a priori on<br />
relevant variables, are compared<br />
E.g., do subjects differ in reading speed under<br />
different types of lighting, after matching subjects<br />
on a priori reading speed
The Logical Background for a<br />
<strong>Repeated</strong>-<strong>Measures</strong> <strong>ANOVA</strong><br />
# The repeated measures analysis of<br />
variance applies to research situations<br />
using within-subject designs<br />
Including repeated measures designs, profile<br />
analysis and matched subject designs<br />
# Some of the logic and formulae for the<br />
repeated measures <strong>ANOVA</strong> are identical<br />
to the independent measures <strong>ANOVA</strong><br />
However, the repeated measures <strong>ANOVA</strong><br />
includes a second stage of analysis in which<br />
variability due to individual differences is<br />
removed from the error term.
Individual Differences<br />
Between Subjects<br />
# The repeated measures design<br />
automatically eliminates individual<br />
differences from the between treatments<br />
variability because the same subjects are<br />
used in every condition<br />
# Further, individual differences (which can<br />
be quantified) are eliminated from the<br />
denominator of the F test<br />
# The result is a test statistic similar to the<br />
independent measures F ratio but with all<br />
individual differences removed
Comparing Independent-<br />
<strong>Measures</strong> and <strong>Repeated</strong>-<br />
<strong>Measures</strong> <strong>ANOVA</strong><br />
# When individual differences are removed<br />
from the denominator of the F test, what<br />
results is a more ‘powerful’ test of the<br />
research hypothesis (i.e., that the means<br />
differ)<br />
In other words, the denominator is smaller<br />
# This advantage can be very important in<br />
situations where large individual<br />
differences would otherwise obscure the<br />
treatment effect in an independentmeasures<br />
study
Variability in a Within-Subjects /<br />
<strong>Repeated</strong> <strong>Measures</strong> Design<br />
PSubjects - variability due to consistent<br />
differences between the subjects<br />
Not usually an important effect to analyze since it<br />
only shows that subjects differ on the DV<br />
PTreatment - variability due to differences<br />
between the levels of the DV<br />
PError - Interaction between the subjects and<br />
levels of the IV<br />
Or in G&W terms, the overall within-subject<br />
variability minus the subject variability
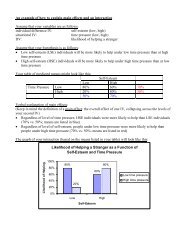
Why is the Treatment X Subjects<br />
Interaction an Appropriate Error<br />
Term?<br />
PMore consistent scores of subjects across<br />
the levels of the IV results in less error (more<br />
confidence that the treatment was effective)<br />
100<br />
80<br />
60<br />
40<br />
20<br />
0<br />
1st Qtr<br />
2nd Qtr<br />
80<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
0<br />
1st Qtr<br />
2nd Qtr<br />
s1 s2 s3 s4<br />
s1 s2 s3 s4<br />
s1 10 40<br />
s2 20 50<br />
s3 50 100<br />
s4 15 40<br />
s1 10 40<br />
s2 20 30<br />
s3 50 30<br />
s4 15 80
Understanding the F-ratio
Null and Alternate Hypotheses<br />
# The null hypothesis is that the means are<br />
all equal<br />
H o : ì 1 = ì 2 = ... = ì k<br />
For example, with three groups: H o : ì 1 = ì 2 = ì 3<br />
# The alternative hypothesis is that at least<br />
one of the means is different from another<br />
Again, H o : ì 1 ì 2 ... ì k would not be an<br />
acceptable way to write the alternate hypothesis
Computation of the F ratio<br />
Total Variability and Degrees of Freedom
Computation of the F ratio<br />
Error Variability and Degrees of Freedom
Computation of the F ratio<br />
Between Treatment Variability and Degrees of Freedom
Computation of the F ratio<br />
Mean Squares and F test<br />
P Note that H o is rejected if:<br />
F F á, df(Between Treatments), df(Error)
Measuring Effect Size for the<br />
<strong>Repeated</strong>-<strong>Measures</strong> Analysis of<br />
Variance<br />
# In addition to determining whether the<br />
mean differences are significant with a<br />
hypothesis test, it is also recommended<br />
that you determine the size of the mean<br />
differences by computing a measure of<br />
effect size<br />
The common technique for measuring effect<br />
size for an analysis of variance is to compute<br />
the percentage of variance that is accounted for<br />
by the treatment effects
Measuring Effect Size for the<br />
<strong>Repeated</strong>-<strong>Measures</strong> Analysis of<br />
Variance (cont.)<br />
# In the context of <strong>ANOVA</strong> this percentage<br />
is identified as ç 2<br />
Before computing ç 2 , however, it is customary to<br />
remove variability due to individual differences<br />
between the subjects
Assumptions of the One-Way<br />
Within-Subjects Design<br />
PSubjects are randomly and independently<br />
selected<br />
PScores in each treatment condition are<br />
normally distributed<br />
PHomogeneity of Variances & Covariances<br />
(Compound Symmetry) / Sphericity
Sphericity<br />
P Sphericity is violated as the treatment<br />
difference variances are unequal
Notes on the Sphericity<br />
Assumption<br />
PLike the homogeneity of variance assumption<br />
for between subjects designs, sphericity is<br />
commonly violated<br />
PViolations of the assumption of sphericity can<br />
severely bias the F statistic<br />
More specifically, when the sphericity assumption<br />
is violated the F test becomes too liberal, or in<br />
other words, the probability of a Type I error<br />
becomes much larger than á
Options for Counteracting the<br />
Effects of Violations of Sphericity<br />
PAdjusted df tests<br />
Reduce the number of numerator and<br />
denominator degrees of freedom to increase the<br />
size of the critical value (or reduce the size of the<br />
p-value) and thus reduce the number of Type I<br />
errors<br />
Greenhouse-Geisser<br />
– Calculates the degree to which the sphericity<br />
assumption is violated and then adjusts the degrees of<br />
freedom accordingly<br />
– The Greenhouse-Geisser adjustment to the <strong>ANOVA</strong> F<br />
test is included as routine output in SPSS
Psych Grads Example<br />
PDr. White would like to know if the “social life”<br />
of York Psychology students changes as a<br />
function of the number of years they have<br />
been in the program (á=.01)<br />
PH o : ì First Year = ì Second Year = ì Third Year<br />
PH 1 : There are no differences among the<br />
means
Example
Example<br />
Error SS and MS
Example<br />
Between Treatment SS and MS
Example<br />
F test and Conclusions<br />
PF crit (á=.01, df between-treatment = 2, df within-treatment = 16) = 6.23<br />
PTherefore, since F > F crit we reject the null<br />
hypothesis and conclude that there is a<br />
significant difference between 1st, 2nd and<br />
3rd year students in terms of the quality of<br />
their social life
Effect Size<br />
P Therefore, .763 (or 76.3%) of the variability in<br />
social life scores can be attributed to the year<br />
of the program<br />
This would definitely be a large effect<br />
But ... this is made up data so don’t try too hard<br />
to make sense of the results
Post Hoc Tests<br />
P Somehow Gravetter & Wallnau forgot to<br />
mention how you are supposed to know<br />
exactly where differences among the<br />
conditions exist<br />
PIn fact, it is very simple because we just use<br />
multiple paired t-tests to determine exactly<br />
which groups differ<br />
The reason we use a “separate” test (specifically<br />
error term) for each pairwise comparison is that<br />
the problems with sphericity are very severe, but<br />
they do not affect “two group” comparisons
Post Hoc Tests<br />
P1st year vs 2nd year<br />
t (8) = 1.00, p = .347<br />
Social lives do not differ between 1st and 2nd<br />
year students<br />
P1st year vs 3rd year<br />
t (8) = 7.23, p < .001<br />
Social lives are better in 3rd year than in 1st year<br />
P1st year vs 2nd year<br />
t (8) = 6.93, p < .001<br />
Social lives are better in 3rd year than in 2nd year