

url - Universität zu Lübeck
url - Universität zu Lübeck
url - Universität zu Lübeck

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
118 CHAPTER 6. THE INDEX SELECTION PROBLEM<br />
For the first two measurements we set up artificial workloads based on XMark<br />
data [104]. XMark produces scalable and highly structured data so that a multitude<br />
of different and reasonable queries are expressible. The test document has<br />
a size of 11 MB.<br />
Test Scenario 1<br />
For the first set we created two different classes of querying database operations:<br />
The first class A contained person-based queries while the second class B consisted<br />
of queries that operate on the items to be sold at the auction. Afterwards,<br />
we constructed several workloads with different distributions of the operations<br />
from A and B. The first workload only had operations from class A while the<br />
ongoing workloads have a growing percentage of operations from B. The last<br />
workload consists analogously of operations from B only. This scenario simulates<br />
a change in the typical usage of the database. All workloads have 100 operations<br />
in total.<br />
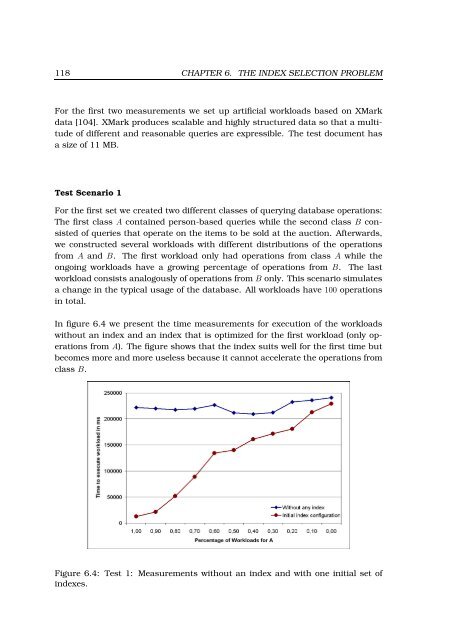
In figure 6.4 we present the time measurements for execution of the workloads<br />
without an index and an index that is optimized for the first workload (only operations<br />
from A). The figure shows that the index suits well for the first time but<br />
becomes more and more useless because it cannot accelerate the operations from<br />
class B.<br />
Figure 6.4: Test 1: Measurements without an index and with one initial set of<br />
indexes.













