

Important Discrete and Continuous Probability Distributions
Important Discrete and Continuous Probability Distributions
Important Discrete and Continuous Probability Distributions

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
BMED2803, BV<br />
<strong>Probability</strong> <strong>Distributions</strong><br />
<strong>Discrete</strong> <strong>Distributions</strong><br />
Binomial Distribution<br />
A simple Bernoulli r<strong>and</strong>om variable Y is dichotomous with P (Y = 1) = p <strong>and</strong> P (Y = 0) =<br />
1 − p for some 0 ≤ p ≤ 1. It is denoted as Y ∼ Ber(p). Suppose an experiment consists of n<br />
independent trials (Y 1 , . . . , Y n ) in which two outcomes are possible (e.g., success or failure),<br />
with P (success) = P (Y = 1) = p for each trial. If X = x is defined as the number of<br />
successes (out of n), then X = Y 1 + Y 2 + . . . + Y n <strong>and</strong> there are ( )<br />
n<br />
x arrangements of x<br />
successes <strong>and</strong> n − x failures, each having the same probability p x (1 − p) n−x . X is a binomial<br />
r<strong>and</strong>om variable with probability mass function<br />
( n<br />
x)<br />
p X (x) =<br />
p x (1 − p) n−x , x = 0, 1, . . . , n.<br />
This is denoted by X ∼ Bin(n, p). From the moment generating function m X (t) = (pe t +<br />
(1 − p)) n , we obtain µ = IEX = np <strong>and</strong> σ 2 = VarX = np(1 − p).<br />
The cumulative distribution for a binomial r<strong>and</strong>om variable is not simplified beyond the<br />
sum; i.e., F (x) = ∑ i≤x p X (i). However, interval probabilities can be computed in MATLAB<br />
using binocdf(x,n,p), which computes the cumulative distribution function at value x.<br />
The probability mass function is also computed in MATLAB using binopdf(x,n,p). A<br />
“quick-<strong>and</strong>-dirty” plot of a binomial PDF can be achieved through the MATLAB function<br />
binoplot.<br />
1<br />
0.2<br />
0.15<br />
0.1<br />
0.05<br />
0.9<br />
0.8<br />
0.7<br />
0.6<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(a)<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(b)<br />
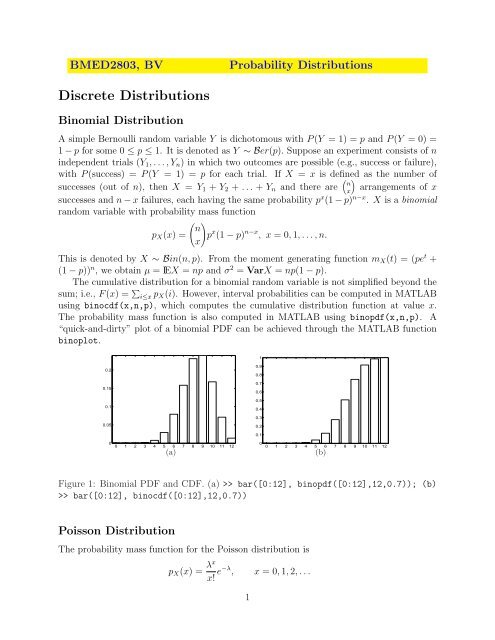
Figure 1: Binomial PDF <strong>and</strong> CDF. (a) >> bar([0:12], binopdf([0:12],12,0.7)); (b)<br />
>> bar([0:12], binocdf([0:12],12,0.7))<br />
Poisson Distribution<br />
The probability mass function for the Poisson distribution is<br />
p X (x) = λx<br />
x! e−λ , x = 0, 1, 2, . . .<br />
1
This is denoted by X ∼ Poi(λ). From m X (t) = exp{λ(e t − 1)}, we have IEX = λ <strong>and</strong><br />
VarX = λ; the mean <strong>and</strong> the variance coincide.<br />
The sum of a finite independent set of Poisson variables is also Poisson. Specifically, if<br />
X i ∼ Poi(λ i ), then Y = X 1 + . . . + X k is distributed as Poi(λ 1 + . . . + λ k ). Furthermore,<br />
the Poisson distribution is a limiting form for a binomial model, i.e.,<br />
lim<br />
n,np→∞,λ<br />
( n<br />
x<br />
)<br />
p x (1 − p) n−x = 1 x! λx e −λ . (1)<br />
MATLAB comm<strong>and</strong>s for Poisson CDF, PDF, quantile, <strong>and</strong> a r<strong>and</strong>om number are: poisscdf,<br />
poisspdf, poissinv, <strong>and</strong> poissrnd.<br />
0.2<br />
0.9<br />
0.8<br />
0.15<br />
0.1<br />
0.05<br />
0.7<br />
0.6<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(a)<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(b)<br />
Figure 2: Poisson PDF <strong>and</strong> CDF. (a) >> bar([0:12], poisspdf([0:12],3)); (b) >><br />
bar([0:12], poisscdf([0:12],3))<br />
Negative Binomial Distribution<br />
Suppose we are dealing with i.i.d. trials again, this time counting the number of failures<br />
observed until a fixed number of successes (k) occur. If we observe k consecutive successes at<br />
the start of the experiment, for example, the count is X = 0 <strong>and</strong> P X (0) = p k , where p is the<br />
probability of success. If X = x, we have observed x failures <strong>and</strong> k successes in x + k trials.<br />
There are ( )<br />
x+k<br />
x different ways of arranging those x + k trials, but we can only be concerned<br />
with ( the ) arrangements in which the last trial ended in a success. So there are really only<br />
x+k−1<br />
arrangements, each equal in probability. With this in mind, the probability mass<br />
x<br />
function is<br />
( ) k + x − 1<br />
p X (x) =<br />
p k (1 − p) x , x = 0, 1, 2, . . .<br />
x<br />
This is denoted by X ∼ N B(k, p).<br />
From its moment generating function<br />
(<br />
) k<br />
p<br />
m(t) =<br />
,<br />
1 − (1 − p)e t<br />
2
the expectation of a negative binomial r<strong>and</strong>om variable is IEX = k(1 − p)/p <strong>and</strong> variance<br />
VarX = k(1 − p)/p 2 . MATLAB comm<strong>and</strong>s for negative binomial CDF, PDF, quantile, <strong>and</strong><br />
a r<strong>and</strong>om number are: nbincdf, nbinpdf, nbininv, <strong>and</strong> nbinrnd.<br />
0.2<br />
0.18<br />
0.16<br />
0.14<br />
0.12<br />
0.9<br />
0.8<br />
0.7<br />
0.6<br />
0.1<br />
0.5<br />
0.08<br />
0.4<br />
0.06<br />
0.3<br />
0.04<br />
0.2<br />
0.02<br />
0.1<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(a)<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(b)<br />
Figure 3: Negative Binomial PDF <strong>and</strong> CDF. (a) >> bar([0:12],<br />
nbinpdf([0:12],4,0.6)); (b) >> bar([0:12], nbincdf([0:12],4,0.6))<br />
Geometric Distribution<br />
The special case of negative binomial for k = 1 is called the geometric distribution, that<br />
is, in repeated independent trials we are interested in the number of failures before the first<br />
success.<br />
R<strong>and</strong>om variable X has geometric Ge(p) distribution if its probability mass function is<br />
p X (x) = p(1 − p) x , x = 0, 1, 2, . . .<br />
If X has geometric Ge(p) distribution, its expected value is IEX = (1 − p)/p <strong>and</strong> variance<br />
VarX = (1 − p)/p 2 . The geometric r<strong>and</strong>om variable can be considered as the discrete<br />
analog to the (continuous) exponential r<strong>and</strong>om variable because it possesses a “memoryless”<br />
property. That is, if we condition on X ≥ m for some non-negative integer m, then for<br />
n ≥ m, P (X ≥ n|X ≥ m) = P (X ≥ n − m). MATLAB comm<strong>and</strong>s for geometric CDF,<br />
PDF, quantile, <strong>and</strong> a r<strong>and</strong>om number are: geocdf, geopdf, geoinv, <strong>and</strong> geornd.<br />
Hypergeometric Distribution<br />
Suppose a box contains m balls, k of which are white <strong>and</strong> m − k of which are gold. Suppose<br />
we r<strong>and</strong>omly select <strong>and</strong> remove n balls from the box without replacement, so that when we<br />
finish, there are only m − n balls left. If X is the number of white balls chosen (without<br />
replacement) from n, then<br />
)<br />
p X (x) =<br />
( )( k m−k<br />
x n−x<br />
( m<br />
n) , x ∈ {0, 1, . . . , min{n, k}}.<br />
This is denoted by X ∼ HG(m, k, n).<br />
3
0.4<br />
0.35<br />
0.3<br />
0.25<br />
0.2<br />
0.15<br />
0.1<br />
0.05<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(a)<br />
0.9<br />
0.8<br />
0.7<br />
0.6<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(b)<br />
Figure 4: Geometric PDF <strong>and</strong> CDF. (a) >> bar([0:12], geopdf([0:12],0.4)); (b) >><br />
bar([0:12], geocdf([0:12],0.4))<br />
This probability mass function can be deduced with counting rules. There are ( )<br />
m<br />
n<br />
different ways of selecting the n balls from a box of m. From these (each equally likely),<br />
there are ( )<br />
k<br />
x ways of selecting x white balls from the k white balls in the box, <strong>and</strong> similarly<br />
( ) m−k<br />
n−x ways of choosing the gold balls.<br />
It can be shown that the mean <strong>and</strong> variance for the hypergeometric distribution are,<br />
respectively,<br />
µ = nk<br />
( ) ( ) (m )<br />
nk m − k − n<br />
m <strong>and</strong> σ2 =<br />
.<br />
m m m − 1<br />
MATLAB comm<strong>and</strong>s for Hypergeometric CDF, PDF, quantile, <strong>and</strong> a r<strong>and</strong>om number are:<br />
hygecdf, hygepdf, hygeinv, <strong>and</strong> hygernd.<br />
1<br />
0.25<br />
0.9<br />
0.8<br />
0.2<br />
0.7<br />
0.15<br />
0.6<br />
0.5<br />
0.1<br />
0.4<br />
0.3<br />
0.05<br />
0.2<br />
0.1<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(a)<br />
0<br />
0 1 2 3 4 5 6 7 8 9 10 11 12<br />
(b)<br />
Figure 5: Hypergeometric PDF <strong>and</strong> CDF. (a) >> bar([0:12],<br />
hygepdf([0:12],30,15,12)); (b) >> bar([0:12], hygecdf([0:12],30,15,12))<br />
Multinomial Distribution<br />
The Binomial distribution was based on dichotomizing event outcomes. If the outcomes can<br />
be classified into k ≥ 2 categories, then out of n trials, we have X i outcomes falling in the<br />
4
category i, i = 1, . . . , k. The probability mass function for the vector (X 1 , . . . , X k ) is<br />
p X1 ,...,X k<br />
(x 1 , ..., x k ) =<br />
n!<br />
x 1 ! · · · x k ! p 1 x1 · · · p k<br />
x k<br />
,<br />
where p 1 + . . . + p k = 1, so there are k − 1 free probability parameters to characterize the<br />
multivariate distribution. This is denoted by X = (X 1 , . . . , X k ) ∼ Mn(n, p 1 , . . . , p k ).<br />
The mean <strong>and</strong> variance of X i is the same as a binomial since this is the marginal distribution<br />
of X i , i.e., IE(X i ) = np i , Var(X i ) = np i (1 − p i ). The covariance between X i<br />
<strong>and</strong> X j is Cov(X i , X j ) = −np i p j because IE(X i X j ) = IE(IE(X i X j |X j )) = IE(X j IE(X i |X j ))<br />
<strong>and</strong> conditional on X j = x j , X i is binomial Bin(n − x j , p i /(1 − p j )). Thus, IE(X i X j ) =<br />
IE(X j (n − X j ))p i /(1 − p j ), <strong>and</strong> the covariance follows from this.<br />
<strong>Continuous</strong> <strong>Distributions</strong><br />
Exponential Distribution<br />
The probability density function for an exponential r<strong>and</strong>om variable is<br />
f X (x) = 1 β e−x/β , x > 0, β > 0.<br />
An exponentially distributed r<strong>and</strong>om variable X is denoted by X ∼ E(β). Its moment<br />
generating function is m(t) = 1/(1 − βt) for t < 1/β, <strong>and</strong> the mean <strong>and</strong> variance are β <strong>and</strong><br />
β 2 , respectively. This distribution has several interesting features - for example, its failure<br />
rate, defined as<br />
r X (x) =<br />
f X(x)<br />
1 − F X (x) ,<br />
is constant <strong>and</strong> equal to 1/β.<br />
The exponential distribution has an important connection to the Poisson distribution.<br />
Suppose we measure i.i.d. exponential E(β) outcomes (X 1 , X 2 , . . .), <strong>and</strong> define S n = X 1 +<br />
. . . + X n . For any positive value t, it can be shown that P (S n < t < S n+1 ) = p Y (n), where<br />
p Y (n) is the probability mass function for a Poisson r<strong>and</strong>om variable Y with parameter t/β.<br />
Similar to a geometric r<strong>and</strong>om variable, an exponential r<strong>and</strong>om variable has the memoryless<br />
property because for t > x, P (X ≥ t|X ≥ x) = P (X ≥ t − x).<br />
The median value, representing a typical observation, is roughly 70% of the mean, showing<br />
how extreme values can affect the population mean. This is easily shown because of the ease<br />
at which the inverse CDF is computed:<br />
p ≡ F X (x; β) = 1 − e −x/β<br />
⇐⇒ F X −1 (p) ≡ x p = −β log(1 − p).<br />
MATLAB comm<strong>and</strong>s for Exponential CDF, PDF, quantile, <strong>and</strong> a r<strong>and</strong>om number are:<br />
expcdf, exppdf, expinv, <strong>and</strong> exprnd. For example, the CDF of r<strong>and</strong>om variable X with<br />
E(3) distribution evaluated at x = 2 is calculated in MATLAB as expcdf(2, 3).<br />
Often, the exponential r<strong>and</strong>om variable is parameterized by a reciprocal of its scale,<br />
λ = 1/β. In that case, the density is given by<br />
f X (x) = λe −λx , x > 0, λ > 0.<br />
5
1<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
−1 0 1 2 3 4 5 6<br />
(a)<br />
0.9<br />
0.8<br />
0.7<br />
0.6<br />
0.5<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
−1 0 1 2 3 4 5 6<br />
(b)<br />
Figure 6: Exponential PDF <strong>and</strong> CDF. (a) >> x=0:0.01:6; plot(x, exppdf(x,2));<br />
(b)>> plot(x, expcdf(x,2))<br />
Gamma Distribution<br />
The gamma distribution is an extension of the exponential distribution. R<strong>and</strong>om variable<br />
X has gamma Ga(α, β) distribution if its probability density function is given by<br />
f X (x) =<br />
1<br />
β α Γ(α) xα−1 e −x/β , x > 0, α > 0, β > 0.<br />
The moment generating function is m(t) = (1/(1 − βt)) α , so in the case α = 1, gamma is<br />
precisely the exponential distribution. From m(t) we have IEX = αβ <strong>and</strong> VarX = αβ 2 .<br />
If X 1 , . . . , X n are generated from an exponential distribution with scale parameter β,<br />
it follows from m(t) that Y = X 1 + . . . + X n is distributed gamma with parameters n<br />
<strong>and</strong> β; that is, Y ∼ Ga(n, β). As we mentioned, exponential E(β) distribution is Ga(1, β),<br />
Erlang distribution (used in queueing theory) is Ga(α, 1) <strong>and</strong> χ 2 -distribution with k degrees<br />
of freedom is Ga(k/2, 2). The CDF in MATLAB is gamcdf(x, alpha, beta), <strong>and</strong> the<br />
PDF is gampdf(x, alpha, beta). The function gaminv(p, alpha, beta) computes the<br />
p th quantile of the Ga(α, β).<br />
1<br />
0.9<br />
0.8<br />
0.1<br />
0.7<br />
0.6<br />
0.5<br />
0.05<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
0 2 4 6 8 10 12 14 16 18<br />
(a)<br />
0<br />
0 2 4 6 8 10 12 14 16 18<br />
(b)<br />
Figure 7: Gamma PDF <strong>and</strong> CDF. (a) >> x=0:0.01:18; plot(x, gampdf(x,2,3)); (b)>><br />
plot(x, gamcdf(x,2,3))<br />
6
As in the Exponential distribution there is an alternative parametrization for Gamma<br />
distribution that is often used. In this case the scale parameter β is replaced by a “rate”<br />
parameter λ = 1/β, <strong>and</strong> the corresponding density is given as<br />
f X (x) =<br />
λα<br />
Γ(α) xα−1 e −λx , x > 0, α > 0, λ > 0.<br />
In this parametrization, IEX = α/λ <strong>and</strong> VarX = α/λ 2 .<br />
Normal Distribution<br />
The probability density function for a normal r<strong>and</strong>om variable with mean µ <strong>and</strong> variance σ 2<br />
is<br />
f X (x) =<br />
1<br />
√<br />
2πσ<br />
2 e− 1<br />
2σ 2 (x−µ)2 , ∞ < x < ∞.<br />
The distribution function is computed using integral approximation because no closed form<br />
exists for the anti-derivative; this is generally not a problem for practitioners because most<br />
software packages will compute interval probabilities numerically. For example, in MATLAB,<br />
normcdf(x, mu, sigma) <strong>and</strong> normpdf(x, mu, sigma) find the CDF <strong>and</strong> PDF at x, <strong>and</strong><br />
norminv(p, mu, sigma) computes the inverse CDF with quantile probability p. A r<strong>and</strong>om<br />
variable X with the normal distribution will be denoted X ∼ N (µ, σ 2 ).<br />
The Central Limit Theorem elevates the status of the normal distribution above other<br />
distributions. Despite its difficult formulation, the normal is one of the most important<br />
distributions in all science, <strong>and</strong> it has a critical role to play in nonparametric statistics.<br />
Any linear combination of normal r<strong>and</strong>om variables (independent or with simple covariance<br />
structures) are also normally distributed. In such sums, then, we need only keep track of<br />
the mean <strong>and</strong> variance, since these two parameters completely characterize the distribution.<br />
For example, if X 1 , . . . , X n are i.i.d. N (µ, σ 2 ), then the sample mean ¯X = (X 1 + . . . + X n )/n<br />
has normal N (µ, σ 2 /n) distribution.<br />
Chi-square Distribution<br />
The probability density function for an chi-square r<strong>and</strong>om variable with the parameter k,<br />
called the degrees of freedom, is is<br />
f X (x) = 2−k/2<br />
Γ(k/2) xk/2−1 e −x/2 , − ∞ < x < ∞.<br />
The chi-square distribution (χ 2 ) is a special case of the Gamma distribution with parameters<br />
α = k/2 <strong>and</strong> β = 2. Its mean <strong>and</strong> variance are µ = k <strong>and</strong> σ 2 = 2k.<br />
If Z ∼ N (0, 1), then Z 2 ∼ χ 2 1, that is, a chi-square r<strong>and</strong>om variable with one degree-offreedom.<br />
Furthermore, if U ∼ χ 2 m <strong>and</strong> V ∼ χ 2 n are independent, then U + V ∼ χ 2 m+n.<br />
From these results, it can be shown that if X 1 , . . . , X n ∼ N (µ, σ 2 ) <strong>and</strong> ¯X is the sample<br />
mean, then the sample variance S 2 = ∑ i(X i − ¯X) 2 /(n − 1) is proportional to a chi-square<br />
7
<strong>and</strong>om variable with n − 1 degrees of freedom:<br />
(n − 1)S 2<br />
σ 2<br />
∼ χ 2 n−1.<br />
In MATLAB, the CDF <strong>and</strong> PDF for a χ 2 k is chi2cdf(x,k) <strong>and</strong> chi2pdf(x,k). The p th<br />
quantile of the χ 2 k distribution is chi2inv(p,k).<br />
(Student) t - Distribution<br />
R<strong>and</strong>om variable X has Student’s t distribution with k degrees of freedom, X ∼ t k , if its<br />
probability density function is<br />
f X (x) = Γ ( )<br />
k+1 ( ) −<br />
k+1<br />
2<br />
√ 1 + x2 2<br />
, −∞ < x < ∞.<br />
kπ Γ(k/2) k<br />
The t-distribution 1 is similar in shape to the st<strong>and</strong>ard normal distribution except for the<br />
fatter tails. If X ∼ t k , IEX = 0, k > 1 <strong>and</strong> VarX = k/(k − 2), k > 2. For k = 1, Student t<br />
distribution coincides with Cauchy distribution.<br />
The t-distribution has an important role to play in statistical inference. With a set of i.i.d.<br />
X 1 , . . . , X n ∼ N (µ, σ 2 ), we can st<strong>and</strong>ardize the sample mean using the simple transformation<br />
of Z = ( ¯X − µ)/σ ¯X = √ n( ¯X − µ)/σ. However, if the variance is unknown, by using the<br />
same transformation except substituting the sample st<strong>and</strong>ard deviation S for σ, we arrive<br />
at a t-distribution with n − 1 degrees of freedom:<br />
T = ( ¯X − µ)<br />
S/ √ n ∼ t n−1<br />
√<br />
More technically, if Z ∼ N (0, 1) <strong>and</strong> Y ∼ χ 2 k are independent, then T = Z/ Y/k ∼ t k .<br />
In MATLAB, the CDF at x for a t-distribution with k degrees of freedom is calculated as<br />
tcdf(x,k), <strong>and</strong> the PDF is computed as tpdf(x,k). The p th percentile is computed with<br />
tinv(p,k).<br />
F Distribution<br />
R<strong>and</strong>om variable X has F distribution with m <strong>and</strong> n degrees of freedom, denoted as F m,n ,<br />
if its density is given by<br />
f X (x) = mm/2 n n/2<br />
B(m/2, n/2) xm/2−1 (n + mx) −(m+n)/2 , x > 0.<br />
The CDF of F distribution is of no closed form, but it can be expressed in terms of an<br />
incomplete beta-function as<br />
F (x) = 1 − I ν (n/2, m/2), ν = n/(n + mx), x > 0.<br />
1 William Sealy Gosset derived the t-distribution in 1908 under the pen name “Student”. He was a<br />
researcher for Guinness Brewery, which forbid any of their workers to publish “company secrets”.<br />
8
The mean is given by IEX = n/(n − 2), n > 2, <strong>and</strong> the variance by VarX = [2n 2 (m +<br />
n − 2)]/[m(n − 2) 2 (n − 4)], n > 4.<br />
If X ∼ χ 2 m <strong>and</strong> Y ∼ χ 2 n are independent, then (X/m)/(Y/n) ∼ F m,n . Because of this<br />
representation, m <strong>and</strong> n are often called the numerator <strong>and</strong> denominator degrees of freedom.<br />
F <strong>and</strong> beta distributions are connected. If X ∼ Be(a, b), then bX/[a(1 − X)] ∼ F 2a,2b . Also,<br />
if X ∼ F m,n then mX/(n + mX) ∼ Be(m/2, n/2).<br />
The F distribution is one of the most important distributions for statistical inference;<br />
in introductory statistical courses test of equality of variances <strong>and</strong> ANOVA are based on F<br />
distribution. For example, if S 2 1 <strong>and</strong> S 2 2 are sample variances of two independent normal<br />
samples with variances σ 2 1 <strong>and</strong> σ 2 2 <strong>and</strong> sizes m <strong>and</strong> n respectively, the ratio (S 2 1/σ 2 1)/(S 2 2/σ 2 2)<br />
is distributed as F m−1,n−1 .<br />
In MATLAB, the CDF at x for a F distribution with m, n degrees of freedom is calculated<br />
as fcdf(x,m,n), <strong>and</strong> the PDF is computed as fpdf(x,m,n). The p th percentile is computed<br />
with finv(p,m,n).<br />
Beta Distribution<br />
The density function for a beta r<strong>and</strong>om variable is<br />
f X (x) =<br />
1<br />
B(a, b) xa−1 (1 − x) b−1 , 0 < x < 1, a > 0, b > 0,<br />
<strong>and</strong> B is the beta function. Because X is defined only in (0,1), the beta distribution is useful<br />
in describing uncertainty or r<strong>and</strong>omness in proportions or probabilities. A beta-distributed<br />
r<strong>and</strong>om variable is denoted by X ∼ Be(a, b). The Uniform distribution on (0, 1), denoted as<br />
U(0, 1), serves as a special case with (a, b) = (1, 1). The Beta distribution has moments<br />
IEX k =<br />
Γ(a + k)Γ(a + b)<br />
Γ(a)Γ(a + b + k) = a(a + 1) . . . (a + k − 1)<br />
(a + b)(a + b + 1) . . . (a + b + k − 1)<br />
so that IE(X) = a/(a + b) <strong>and</strong> VarX = ab/[(a + b) 2 (a + b + 1)].<br />
In MATLAB, the CDF for a beta r<strong>and</strong>om variable (at x ∈ (0, 1)) is computed with<br />
betacdf(x, a, b) <strong>and</strong> the PDF is computed with betapdf(x, a, b). The p th percentile<br />
is computed betainv(p,a,b). If the mean µ <strong>and</strong> variance σ 2 for a beta r<strong>and</strong>om variable are<br />
known, then the basic parameters (a, b) can be determined as<br />
a = µ<br />
( )<br />
( )<br />
µ(1 − µ)<br />
µ(1 − µ)<br />
− 1 , <strong>and</strong> b = (1 − µ) − 1 . (2)<br />
σ 2 σ 2<br />
Double Exponential Distribution<br />
R<strong>and</strong>om variable X has double exponential DE(µ, β) distribution if its density is given by<br />
f X (x) = 1<br />
2β e−|x−µ|/β , − ∞ < x < ∞, β > 0.<br />
9
The expectation of X is IEX = µ <strong>and</strong> the variance is VarX = 2β 2 . The moment generating<br />
function for the double exponential distribution is<br />
m(t) =<br />
eµt<br />
, |t| < 1/β.<br />
1 − β 2 t2 Double exponential is also called Laplace distribution. If X 1 <strong>and</strong> X 2 are independent exponential<br />
E(β), then X 1 −X 2 is distributed as DE(0, β). Also, if X ∼ DE(0, β) then |X| ∼ E(β).<br />
Often, Double Exponential distribution is parameterized by λ = 1/β.<br />
Cauchy Distribution<br />
The Cauchy distribution is symmetric <strong>and</strong> “bell-shaped” like the normal distribution, but<br />
with much heavier tails. In fact, it is a popular distribution to use in nonparametric robust<br />
procedures <strong>and</strong> simulations because the distribution is so spread out, it has no mean <strong>and</strong> variance<br />
(none of the Cauchy moments exist). Physicists know this as the Lorentz distribution.<br />
If X ∼ Ca(a, b), then X has density<br />
f X (x) = 1 π<br />
b<br />
b 2 + (x − a) 2 , − ∞ < x < ∞<br />
The moment generating function for Cauchy distribution does not exist but its characteristic<br />
function is IEe iX = exp{iat − b|t|}. The Ca(0, 1) coincides with t-distribution with<br />
one degree of freedom.<br />
The Cauchy is also related to the normal distribution. If Z 1 <strong>and</strong> Z 2 are two independent<br />
N (0, 1) r<strong>and</strong>om variables, then C = Z 1 /Z 2 ∼ Ca(0, 1). Finally, if C i ∼ Ca(a i , b i ) for i =<br />
1, . . . , n, then S n = C 1 + · · · + C n is Cauchy distributed with parameters a S = ∑ i a i <strong>and</strong><br />
b S = ∑ i b i .<br />
Inverse Gamma Distribution<br />
R<strong>and</strong>om variable X is said to have Inverse Gamma IG(α, β) distribution with parameters<br />
α > 0 <strong>and</strong> β > 0 if its density is given by<br />
f X (x) =<br />
1<br />
1<br />
β α e− βx<br />
Γ(α)xα+1 , x ≥ 0, α, β > 0.<br />
The mean <strong>and</strong> variance of X are IEX = 1<br />
β(α−1) , α > 1 <strong>and</strong> VarX = 1<br />
β 2 (α−1) 2 (α−2) , α > 2,<br />
respectively. If X ∼ Ga(α, β) then its reciprocal X −1 is IG(α, β) distributed.<br />
As before, a common parametrization for Inverse Gamma is via rate parameter λ = 1/β<br />
for which<br />
f X (x) =<br />
λ α<br />
Γ(α)x α+1 e− λ x , x ≥ 0, α, λ > 0.<br />
The mean <strong>and</strong> variance of X are IEX =<br />
respectively.<br />
λ , α > 1 <strong>and</strong> VarX = λ 2<br />
, α > 2,<br />
α−1 (α−1) 2 (α−2)<br />
10
Dirichlet Distribution<br />
The Dirichlet distribution is a multivariate version of the Beta distribution in the same way<br />
the multinomial distribution is a multivariate extension of the Binomial. A r<strong>and</strong>om variable<br />
X = (X 1 , . . . , X k ) with a Dirichlet distribution (X ∼ Dir(a 1 , . . . , a k )) has probability density<br />
function<br />
f(x 1 , . . . , x k ) =<br />
Γ(A) ∏ ki=1<br />
Γ(a i )<br />
k∏<br />
a<br />
x i −1 i ,<br />
i=1<br />
where A = ∑ a i , <strong>and</strong> x = (x 1 , . . . , x k ) ≥ 0 is defined on the simplex x 1 + . . . + x k = 1. Then<br />
IE(X i ) = a i<br />
A , σ2 (X i ) = a i(A − a i )<br />
A 2 (A + 1) , <strong>and</strong> Cov(X i, X j ) = − a ia j<br />
A 2 (A + 1) .<br />
The Dirichlet r<strong>and</strong>om variable can be generated from Gamma r<strong>and</strong>om variables Y 1 , . . . , Y k ∼<br />
Ga(a, b) as X i = Y i /S Y , i = 1, . . . , k where S Y = ∑ i Y i . Obviously, the marginal distribution<br />
of a component X i is Be(a i , A − a i ).<br />
Pareto Distribution<br />
The Pareto distribution is named after the Italian economist Vilfredo Pareto. Some examples<br />
in which Pareto distributions provides a good model include: wealth distribution in<br />
individuals, sizes of human settlements; visits to Encyclopedia pages; <strong>and</strong> file size distribution<br />
of Internet traffic which uses the TCP protocol, etc. R<strong>and</strong>om variable X has a Pareto<br />
Pa(x 0 , α) distribution with parameters 0 < x 0 < ∞ <strong>and</strong> α > 0 if its density is given by<br />
f(x) = α x 0<br />
( ) x0 α+1<br />
, x ≥ x0 , α > 0.<br />
x<br />
The mean <strong>and</strong> variance of X are IEX = αx 0 /(α − 1) <strong>and</strong> VarX = αx 2 0/((α − 1) 2 (α − 2)).<br />
If X 1 , . . . , X n ∼ Pa(x 0 , α), then Y = 2x 0<br />
∑ ln(Xi ) ∼ χ 2 with 2n degrees of freedom.<br />
11





