

Effects of Age and Hearing Loss on the ... - Rush University
Effects of Age and Hearing Loss on the ... - Rush University
Effects of Age and Hearing Loss on the ... - Rush University

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
2 SHEFT ET AL. / EAR & HEARING, VOL. 00, NO. 00, 000–000<br />
et al. 1975). Al<strong>on</strong>g with enhancing coherence, modulati<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
<strong>the</strong> voicing fundamental can aid in <strong>the</strong> necessary segmentati<strong>on</strong><br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> syllable <str<strong>on</strong>g>and</str<strong>on</strong>g> word boundaries <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> <strong>on</strong>going speech<br />
stream (Cutler 1976; Spitzer et al. 2007). This modulati<strong>on</strong> has<br />
been shown to benefit speech intelligibility in <strong>the</strong> presence<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> competing interference (Laures & Bunt<strong>on</strong> 2003; Binns &<br />
Culling 2007; Miller et al. 2010).<br />
The effect <str<strong>on</strong>g>of</str<strong>on</strong>g> FM rate <strong>on</strong> auditory streaming is low pass with<br />
coherence dropping rapidly with increasing rate >1 to 2 Hz<br />
(Anstis & Saida 1985). Analysis <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> FM spectrum <str<strong>on</strong>g>of</str<strong>on</strong>g> speech<br />
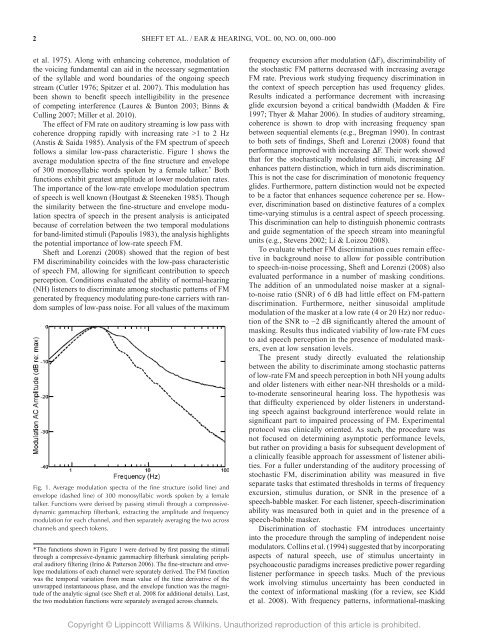
follows a similar low-pass characteristic. Figure 1 shows <strong>the</strong><br />
average modulati<strong>on</strong> spectra <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> fine structure <str<strong>on</strong>g>and</str<strong>on</strong>g> envelope<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> 300 m<strong>on</strong>osyllabic words spoken by a female talker. * Both<br />
functi<strong>on</strong>s exhibit greatest amplitude at lower modulati<strong>on</strong> rates.<br />
The importance <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> low-rate envelope modulati<strong>on</strong> spectrum<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> speech is well known (Houtgast & Steeneken 1985). Though<br />
<strong>the</strong> similarity between <strong>the</strong> fine-structure <str<strong>on</strong>g>and</str<strong>on</strong>g> envelope modulati<strong>on</strong><br />
spectra <str<strong>on</strong>g>of</str<strong>on</strong>g> speech in <strong>the</strong> present analysis is anticipated<br />
because <str<strong>on</strong>g>of</str<strong>on</strong>g> correlati<strong>on</strong> between <strong>the</strong> two temporal modulati<strong>on</strong>s<br />
for b<str<strong>on</strong>g>and</str<strong>on</strong>g>-limited stimuli (Papoulis 1983), <strong>the</strong> analysis highlights<br />
<strong>the</strong> potential importance <str<strong>on</strong>g>of</str<strong>on</strong>g> low-rate speech FM.<br />
Sheft <str<strong>on</strong>g>and</str<strong>on</strong>g> Lorenzi (2008) showed that <strong>the</strong> regi<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> best<br />
FM discriminability coincides with <strong>the</strong> low-pass characteristic<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> speech FM, allowing for significant c<strong>on</strong>tributi<strong>on</strong> to speech<br />
percepti<strong>on</strong>. C<strong>on</strong>diti<strong>on</strong>s evaluated <strong>the</strong> ability <str<strong>on</strong>g>of</str<strong>on</strong>g> normal-hearing<br />
(NH) listeners to discriminate am<strong>on</strong>g stochastic patterns <str<strong>on</strong>g>of</str<strong>on</strong>g> FM<br />
generated by frequency modulating pure-t<strong>on</strong>e carriers with r<str<strong>on</strong>g>and</str<strong>on</strong>g>om<br />
samples <str<strong>on</strong>g>of</str<strong>on</strong>g> low-pass noise. For all values <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> maximum<br />
Fig. 1. Average modulati<strong>on</strong> spectra <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> fine structure (solid line) <str<strong>on</strong>g>and</str<strong>on</strong>g><br />
envelope (dashed line) <str<strong>on</strong>g>of</str<strong>on</strong>g> 300 m<strong>on</strong>osyllabic words spoken by a female<br />
talker. Functi<strong>on</strong>s were derived by passing stimuli through a compressivedynamic<br />
gammachirp filterbank, extracting <strong>the</strong> amplitude <str<strong>on</strong>g>and</str<strong>on</strong>g> frequency<br />
modulati<strong>on</strong> for each channel, <str<strong>on</strong>g>and</str<strong>on</strong>g> <strong>the</strong>n separately averaging <strong>the</strong> two across<br />
channels <str<strong>on</strong>g>and</str<strong>on</strong>g> speech tokens.<br />
*The functi<strong>on</strong>s shown in Figure 1 were derived by first passing <strong>the</strong> stimuli<br />
through a compressive-dynamic gammachirp filterbank simulating peripheral<br />
auditory filtering (Irino & Patters<strong>on</strong> 2006). The fine-structure <str<strong>on</strong>g>and</str<strong>on</strong>g> envelope<br />
modulati<strong>on</strong>s <str<strong>on</strong>g>of</str<strong>on</strong>g> each channel were separately derived. The FM functi<strong>on</strong><br />
was <strong>the</strong> temporal variati<strong>on</strong> from mean value <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> time derivative <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong><br />
unwrapped instantaneous phase, <str<strong>on</strong>g>and</str<strong>on</strong>g> <strong>the</strong> envelope functi<strong>on</strong> was <strong>the</strong> magnitude<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> analytic signal (see Sheft et al. 2008 for additi<strong>on</strong>al details). Last,<br />
<strong>the</strong> two modulati<strong>on</strong> functi<strong>on</strong>s were separately averaged across channels.<br />
frequency excursi<strong>on</strong> after modulati<strong>on</strong> (∆F), discriminability <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
<strong>the</strong> stochastic FM patterns decreased with increasing average<br />
FM rate. Previous work studying frequency discriminati<strong>on</strong> in<br />
<strong>the</strong> c<strong>on</strong>text <str<strong>on</strong>g>of</str<strong>on</strong>g> speech percepti<strong>on</strong> has used frequency glides.<br />
Results indicated a performance decrement with increasing<br />
glide excursi<strong>on</strong> bey<strong>on</strong>d a critical b<str<strong>on</strong>g>and</str<strong>on</strong>g>width (Madden & Fire<br />
1997; Thyer & Mahar 2006). In studies <str<strong>on</strong>g>of</str<strong>on</strong>g> auditory streaming,<br />
coherence is shown to drop with increasing frequency span<br />
between sequential elements (e.g., Bregman 1990). In c<strong>on</strong>trast<br />
to both sets <str<strong>on</strong>g>of</str<strong>on</strong>g> findings, Sheft <str<strong>on</strong>g>and</str<strong>on</strong>g> Lorenzi (2008) found that<br />
performance improved with increasing ∆F. Their work showed<br />
that for <strong>the</strong> stochastically modulated stimuli, increasing ∆F<br />
enhances pattern distincti<strong>on</strong>, which in turn aids discriminati<strong>on</strong>.<br />
This is not <strong>the</strong> case for discriminati<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> m<strong>on</strong>ot<strong>on</strong>ic frequency<br />
glides. Fur<strong>the</strong>rmore, pattern distincti<strong>on</strong> would not be expected<br />
to be a factor that enhances sequence coherence per se. However,<br />
discriminati<strong>on</strong> based <strong>on</strong> distinctive features <str<strong>on</strong>g>of</str<strong>on</strong>g> a complex<br />
time-varying stimulus is a central aspect <str<strong>on</strong>g>of</str<strong>on</strong>g> speech processing.<br />
This discriminati<strong>on</strong> can help to distinguish ph<strong>on</strong>emic c<strong>on</strong>trasts<br />
<str<strong>on</strong>g>and</str<strong>on</strong>g> guide segmentati<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> speech stream into meaningful<br />
units (e.g., Stevens 2002; Li & Loizou 2008).<br />
To evaluate whe<strong>the</strong>r FM discriminati<strong>on</strong> cues remain effective<br />
in background noise to allow for possible c<strong>on</strong>tributi<strong>on</strong><br />
to speech-in-noise processing, Sheft <str<strong>on</strong>g>and</str<strong>on</strong>g> Lorenzi (2008) also<br />
evaluated performance in a number <str<strong>on</strong>g>of</str<strong>on</strong>g> masking c<strong>on</strong>diti<strong>on</strong>s.<br />
The additi<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> an unmodulated noise masker at a signalto-noise<br />
ratio (SNR) <str<strong>on</strong>g>of</str<strong>on</strong>g> 6 dB had little effect <strong>on</strong> FM-pattern<br />
discriminati<strong>on</strong>. Fur<strong>the</strong>rmore, nei<strong>the</strong>r sinusoidal amplitude<br />
modulati<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> masker at a low rate (4 or 20 Hz) nor reducti<strong>on</strong><br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> SNR to −2 dB significantly altered <strong>the</strong> amount <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
masking. Results thus indicated viability <str<strong>on</strong>g>of</str<strong>on</strong>g> low-rate FM cues<br />
to aid speech percepti<strong>on</strong> in <strong>the</strong> presence <str<strong>on</strong>g>of</str<strong>on</strong>g> modulated maskers,<br />
even at low sensati<strong>on</strong> levels.<br />
The present study directly evaluated <strong>the</strong> relati<strong>on</strong>ship<br />
between <strong>the</strong> ability to discriminate am<strong>on</strong>g stochastic patterns<br />
<str<strong>on</strong>g>of</str<strong>on</strong>g> low-rate FM <str<strong>on</strong>g>and</str<strong>on</strong>g> speech percepti<strong>on</strong> in both NH young adults<br />
<str<strong>on</strong>g>and</str<strong>on</strong>g> older listeners with ei<strong>the</strong>r near-NH thresholds or a mildto-moderate<br />
sensorineural hearing loss. The hypo<strong>the</strong>sis was<br />
that difficulty experienced by older listeners in underst<str<strong>on</strong>g>and</str<strong>on</strong>g>ing<br />
speech against background interference would relate in<br />
significant part to impaired processing <str<strong>on</strong>g>of</str<strong>on</strong>g> FM. Experimental<br />
protocol was clinically oriented. As such, <strong>the</strong> procedure was<br />
not focused <strong>on</strong> determining asymptotic performance levels,<br />
but ra<strong>the</strong>r <strong>on</strong> providing a basis for subsequent development <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
a clinically feasible approach for assessment <str<strong>on</strong>g>of</str<strong>on</strong>g> listener abilities.<br />
For a fuller underst<str<strong>on</strong>g>and</str<strong>on</strong>g>ing <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> auditory processing <str<strong>on</strong>g>of</str<strong>on</strong>g><br />
stochastic FM, discriminati<strong>on</strong> ability was measured in five<br />
separate tasks that estimated thresholds in terms <str<strong>on</strong>g>of</str<strong>on</strong>g> frequency<br />
excursi<strong>on</strong>, stimulus durati<strong>on</strong>, or SNR in <strong>the</strong> presence <str<strong>on</strong>g>of</str<strong>on</strong>g> a<br />
speech-babble masker. For each listener, speech-discriminati<strong>on</strong><br />
ability was measured both in quiet <str<strong>on</strong>g>and</str<strong>on</strong>g> in <strong>the</strong> presence <str<strong>on</strong>g>of</str<strong>on</strong>g> a<br />
speech-babble masker.<br />
Discriminati<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> stochastic FM introduces uncertainty<br />
into <strong>the</strong> procedure through <strong>the</strong> sampling <str<strong>on</strong>g>of</str<strong>on</strong>g> independent noise<br />
modulators. Collins et al. (1994) suggested that by incorporating<br />
aspects <str<strong>on</strong>g>of</str<strong>on</strong>g> natural speech, use <str<strong>on</strong>g>of</str<strong>on</strong>g> stimulus uncertainty in<br />
psychoacoustic paradigms increases predictive power regarding<br />
listener performance in speech tasks. Much <str<strong>on</strong>g>of</str<strong>on</strong>g> <strong>the</strong> previous<br />
work involving stimulus uncertainty has been c<strong>on</strong>ducted in<br />
<strong>the</strong> c<strong>on</strong>text <str<strong>on</strong>g>of</str<strong>on</strong>g> informati<strong>on</strong>al masking (for a review, see Kidd<br />
et al. 2008). With frequency patterns, informati<strong>on</strong>al-masking<br />
Copyright © Lippincott Williams & Wilkins. Unauthorized reproducti<strong>on</strong> <str<strong>on</strong>g>of</str<strong>on</strong>g> this article is prohibited.













