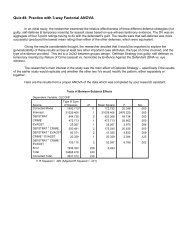
Mean Vectors and Covariance Matrices
Mean Vectors and Covariance Matrices
Mean Vectors and Covariance Matrices

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
The Exponent Term<br />
• The term in the exponent (without the − 1 ) is called the squared<br />
2<br />
Mahalanobis Distance<br />
d 2 x p = x T p − μ T Σ −1 x T p − μ<br />
‣ Sometimes called the statistical distance<br />
‣ Describes how far an observation is from its mean vector, in<br />
st<strong>and</strong>ardized units<br />
‣ Like a multivariate Z score (but, if data are MVN, is actually distributed as a<br />
χ 2 variable with DF = number of variables in X)<br />
‣ Can be used to assess if data follow MVN<br />
PSYC 943: Lecture 11 38