

Designing Packet Buffers with Statistical Guarantees
Designing Packet Buffers with Statistical Guarantees
Designing Packet Buffers with Statistical Guarantees

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
<strong>Designing</strong> <strong>Packet</strong> <strong>Buffers</strong> <strong>with</strong> <strong>Statistical</strong> <strong>Guarantees</strong><br />
Gireesh Shrimali, Isaac Keslassy, Nick McKeown<br />
Computer Systems Laboratory, Stanford University,<br />
Stanford, CA 94305-9030<br />
{gireesh, keslassy, nickm}@stanford.edu<br />
Abstract -- <strong>Packet</strong> buffers are an essential part of routers. In highend<br />
routers these buffers need to store a large amount of data at very<br />
high speeds. To satisfy these requirements, we need a memory <strong>with</strong> the<br />
the speed of SRAM and the density of DRAM. A typical solution is to<br />
use hybrid packet buffers built from a combination of SRAM and<br />
DRAM, where the SRAM holds the heads and tails of per-flow packet<br />
FIFOs and the DRAM is used for bulk storage. The main challenge<br />
then is to minimize the size of the SRAM while providing reasonable<br />
performance guarantees. In this paper, we analyze a commonly used<br />
hybrid architecture from a statistical perspective, and ask the following<br />
question: if the packet buffer designer is willing to tolerate a certain<br />
drop probability, then how small can the SRAM get? To do so, we<br />
introduce an analytical model for representing the SRAM buffer occupancy,<br />
and derive drop probabilities as a function of SRAM size under<br />
a wide range of statistical traffic patterns. As a consequence of our<br />
analysis we show that, for low drop probability, the required SRAM<br />
size is proportional to the number of flows.<br />
I. INTRODUCTION<br />
<strong>Packet</strong> buffers in high-performance routers are challenging to design<br />
because of two factors: memory speed and memory size.<br />
<strong>Packet</strong>s belonging to different flows (for example, these flows may<br />
correspond to different IP source-destination pairs) arrive and depart at<br />
line rate, and are typically stored in per-flow queues. Consecutive packets<br />
may belong to different flows in an unpredictable manner. This<br />
requires that the buffer be able to store as well as retrieve packets at line<br />
rates in an unpredictable memory access order. Thus, the buffer has to<br />
match a raw bandwidth (in bits/s) as well as a memory random access<br />
speed (in packets/s) of at least twice the line rate.<br />
In addition, a rule of thumb indicates that, for TCP to work well, the<br />
buffer should be able to store an amount of data equal to the product of<br />
the line rate and the average round-trip-time [1]. While it has been<br />
recently challenged [2], this rule of thumb is still widely used.<br />
Therefore, both the speed and size of the memory grow linearly <strong>with</strong><br />
the line rate.<br />
As an example, consider a 40Gbits/s linecard. This requires the buffer<br />
to match a raw bandwidth of 80Gbits/s. In addition, assuming a constant<br />
stream of 40-byte packets, which corresponds to minimum size IP packets<br />
containing TCP ACKs, the buffer must read and write a packet every<br />
8ns. This translates to one memory operation every 4ns, or a random<br />
access speed of 250Mpackets/s. Finally, assuming an average round-trip<br />
time of 0.25s [3], the buffer must hold 10Gbits.<br />
We now investigate the properties of two popular commercially available<br />
memories - SRAM and DRAM - to see if they match these requirements.<br />
Arriving<br />
Cells<br />
R<br />
b cells<br />
1<br />
Q<br />
Tail Cache<br />
Large DRAM<br />
SRAM<br />
Head Cache<br />
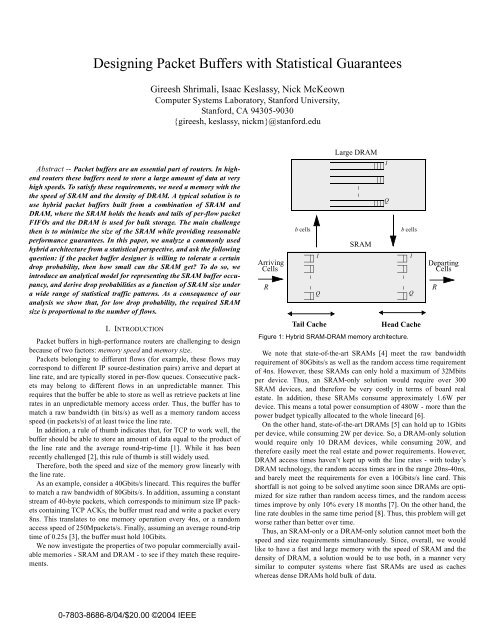
Figure 1: Hybrid SRAM-DRAM memory architecture.<br />
Departing<br />
Cells<br />
We note that state-of-the-art SRAMs [4] meet the raw bandwidth<br />
requirement of 80Gbits/s as well as the random access time requirement<br />
of 4ns. However, these SRAMs can only hold a maximum of 32Mbits<br />
per device. Thus, an SRAM-only solution would require over 300<br />
SRAM devices, and therefore be very costly in terms of board real<br />
estate. In addition, these SRAMs consume approximately 1.6W per<br />
device. This means a total power consumption of 480W - more than the<br />
power budget typically allocated to the whole linecard [6].<br />
On the other hand, state-of-the-art DRAMs [5] can hold up to 1Gbits<br />
per device, while consuming 2W per device. So, a DRAM-only solution<br />
would require only 10 DRAM devices, while consuming 20W, and<br />
therefore easily meet the real estate and power requirements. However,<br />
DRAM access times haven’t kept up <strong>with</strong> the line rates - <strong>with</strong> today’s<br />
DRAM technology, the random access times are in the range 20ns-40ns,<br />
and barely meet the requirements for even a 10Gbits/s line card. This<br />
shortfall is not going to be solved anytime soon since DRAMs are optimized<br />
for size rather than random access times, and the random access<br />
times improve by only 10% every 18 months [7]. On the other hand, the<br />
line rate doubles in the same time period [8]. Thus, this problem will get<br />
worse rather than better over time.<br />
Thus, an SRAM-only or a DRAM-only solution cannot meet both the<br />
speed and size requirements simultaneously. Since, overall, we would<br />
like to have a fast and large memory <strong>with</strong> the speed of SRAM and the<br />
density of DRAM, a solution would be to use both, in a manner very<br />
similar to computer systems where fast SRAMs are used as caches<br />
whereas dense DRAMs hold bulk of data.<br />
1<br />
Q<br />
b cells<br />
1<br />
Q<br />
R<br />
0-7803-8686-8/04/$20.00 ©2004 IEEE
A common approach is to use a hybrid SRAM-DRAM architecture<br />
[9][10][11], as shown in Figure 1. We encourage the reader to read [9]<br />
for a detailed background and motivation for this architecture. Under<br />
this architecture, one can envision the memory hierarchy as a large<br />
DRAM containing a set of cell FIFOs <strong>with</strong> the heads and tails of<br />
FIFOs in a dynamically shared SRAM.<br />
The SRAM behaves like a cache, holding packets temporarily<br />
when they first arrive and just prior to their departure. Variable size<br />
packets arrive at the SRAM at rate R. They are segmented into fixedsize<br />
cells and are stored into one of the Q tail FIFOs depending on<br />
their flow ID. Later, a Memory Management Algorithm (MMA)<br />
writes cells into the DRAM in blocks of b cells. Similarly, the MMA<br />
transfers blocks of b cells from the DRAM FIFOs to the corresponding<br />
head FIFOs in the SRAM. Finally, cells from head FIFOs depart<br />
when requested by an external arbiter. Note that the MMA always<br />
transfers b cells at a time - never less - between an SRAM FIFO and<br />
the corresponding DRAM FIFO. By transferring b cells every b timeslots,<br />
it ensures that the DRAM meets the memory speed requirement<br />
in the long run. 1<br />
In this paper, we look at the problem of independently sizing the<br />
tail and head SRAMs from a statistical perspective under a wide range<br />
of arrival traffic patterns. We provide models of the SRAM buffers,<br />
present MMAs that would minimize the SRAM sizes for a given drop<br />
probability, and derive formulas relating SRAM sizes to the drop<br />
probability. As a consequence of our analysis we show that, in order<br />
to provide low drop probability, the required SRAM sizes scales linearly<br />
<strong>with</strong> Q . When Q is large, this linear dependence would make<br />
such a buffer hard to implement. 2 Therefore, we exhibit an inherent<br />
limitation of this architecture.<br />
The rest of the paper is organized as follows. Section II presents a<br />
model of the tail SRAM followed by a detailed analysis. Similarly,<br />
Section III presents a model of the head SRAM along <strong>with</strong> analytical<br />
results. Section IV provides some simulation results and Section V<br />
concludes the paper.<br />
A. Tail SRAM Model<br />
II. ANALYSIS OF THE TAIL SRAM<br />
In this section, we introduce a queueing model for the tail SRAM,<br />
together <strong>with</strong> some simplifying assumptions.<br />
As illustrated in Figure 2, we model the tail SRAM as a single<br />
queue served by a deterministic server of rate 1. For simplicity, we<br />
assume time to be a continuous variable. A similar analysis could be<br />
carried out in discrete time domain as well. We also assume that the<br />
SRAM is dynamically shared among Q queues corresponding to Q<br />
flows.<br />
We denote by A( t)<br />
the cumulative number of cells arriving at the<br />
SRAM in [ 0,<br />
t] . A( t) is assumed to be the sum of Q arrival processes<br />
A i ( t) corresponding to the Q flows; A i ( t) have rates λ i such<br />
that λ ≡∑1<br />
λ . 3 i < We also assume that A i ( t)<br />
are independent and<br />
identically distributed (IID) stationary and ergodic processes. 4 We<br />
similarly denote by D( t)<br />
the cumulative number of departures in<br />
1.<br />
With line rate R, DRAM random access time T, and cell size c, we<br />
define b = 2RT ⁄ c . Thus, T = b time-slots.<br />
2. For example, in edge routers Q can be as large as a million.<br />
3.<br />
In this paper, all the finite sums are over index i over the range 1 to Q.<br />
source 1<br />
A 1 (t)<br />
A Q (t)<br />
source Q<br />
A(t)<br />
Figure 2: The tail SRAM model<br />
+<br />
[ 0,<br />
t] . We then denote L( i,<br />
t)<br />
as the number of cells present in queue<br />
i , and L( t) = L( i,<br />
t)<br />
as the total SRAM occupancy at time t.<br />
To find the drop probability, we start by assuming that the SRAM is<br />
infinite. We then obtain the steady state probability that the sum of<br />
queue sizes exceeds S (i.e., P( L > S)<br />
) as a surrogate for the steady<br />
state overflow probability for an SRAM of size S .<br />
We assume that the MMA works as follows [9]. Whenever the<br />
DRAM is free, it serves an arbitrary queue from the set of all queues i<br />
satisfying L( i,<br />
t) ≥ b . For example, it could service the longest queue<br />
<strong>with</strong> at least b cells, or the oldest queue <strong>with</strong> at least b cells, and so on.<br />
We refer to this MMA as a b-Work Conserving MMA (BWC-<br />
MMA) since it is work conserving as soon as at least one queue has<br />
occupancy of at least . Because of work conservation, BWC-MMA<br />
minimizes the tail SRAM occupancy among all possible MMAs in<br />
this architecture. Therefore, given a tail SRAM of size S in the hybrid<br />
architecture, BWC-MMA ensures that the drop probability P is minimized.<br />
Equivalently, it minimizes S given a fixed P.<br />
Under BWC-MMA, service to an individual queue depends on the<br />
occupancy of all the queues in the system. Therefore, the queues are<br />
not independent. For example, in one queue is being served, no other<br />
queue<br />
∑<br />
b<br />
can be served at the same time. This makes it hard to analyze<br />
the queues in isolation, and we need to analyze the queue occupancies<br />
together. This analysis is extremely challenging due to the interactions<br />
between the queue occupancies.<br />
B. The Fixed-Batch Decomposition<br />
L(t)<br />
D(t)<br />
In this section, we simplify the analysis by decomposing the sum of<br />
occupancies into elements that can be analyzed independently.<br />
We start by noting that each A i ( t)<br />
can be written down as<br />
A i ( t) = b × MA i ( t)<br />
+ R i ( t)<br />
, (1)<br />
where MA i ( t) and R i ( t)<br />
are the quotient and the remainder after<br />
A i ( t) is divided by b . Now the arrival process A( t)<br />
can be written as<br />
A( t) = A i ( t)<br />
= ∑[ × MA i ( t)<br />
+ R i ( t ) ] . (2)<br />
We can also write<br />
A( t) = b × MA( t)<br />
+ R( t)<br />
, (3)<br />
where MA( t) = MA i ( t)<br />
and R( t) = R i ( t)<br />
are referred to as<br />
the batch arrival process and remainder workload, respectively.<br />
Having defined the arrival process, we now examine the departure<br />
process. Since cells are serviced by fixed batches of b,<br />
4. We believe this independence assumption is reasonable since the traffic<br />
on a high speed WAN link usually comprises of traffic generated by<br />
thousands of independent sources. In addition, in [12] we show that the<br />
drop probability in the IID case upper bounds the corresponding probability<br />
in the non-IID (independent but not identically distributed) case.<br />
Thus, analysis for the IID case suffices for the scope of this paper.<br />
∑<br />
b
D( t) = b × MD( t)<br />
, (4)<br />
where MD( t)<br />
represents the cumulative number of batch departures<br />
in [ 0,<br />
t]<br />
.<br />
Finally, having considered arrivals and departures, we look at the<br />
sum of occupancies L( t)<br />
, which can simply be written down as<br />
L( t) = A( t) – D( t)<br />
. (5)<br />
Substituting for A( t) and D( t)<br />
from Equation (3) and<br />
Equation (4), we get<br />
L( t) = [ b × MA( t)<br />
+ R( t)<br />
] – b × MD( t ) (6)<br />
or<br />
L( t) = b × ML( t)<br />
+ R( t)<br />
, (7)<br />
where ML( t ) = MA( t) – MD( t)<br />
is referred to as the batch workload.<br />
Equation (7) indicates that the system workload L( t)<br />
can be<br />
decomposed into two terms. The first term, b × ML( t)<br />
, is the product<br />
of the batch size and the batch workload. The second term, R( t)<br />
, is<br />
simply the remainder workload.<br />
We now show that the two terms in this decomposition are independent.<br />
This greatly simplifies the analysis since it is now possible to<br />
study them separately. The independence between the batch workload<br />
and the remainder workload is provided by the following theorem.<br />
Theorem 1: The remainder workload is independent of the batch<br />
workload.<br />
Proof: See<br />
Theorem 1 provides what we call the fixed-batch decomposition. It<br />
indicates that the steady state distribution of the system workload can<br />
be derived simply by convolving the steady state distributions of the<br />
remainder and batch workloads, i.e,<br />
Appendix.<br />
f L ( x) = f R ( x) ⊗ f ML ( x ⁄ b , )<br />
(8)<br />
where f L ( x) , f R ( x) , and f ML ( x)<br />
are the steady state probability density<br />
functions (PDF) of system, remainder, and batch workloads,<br />
respectively. Thus, Theorem 1 allows us to translate the general queue<br />
analysis to two more tractable problems.<br />
C. Steady State Distributions<br />
We first derive the steady-state distributions of remainder and batch<br />
workloads. The fixed-batch decomposition can then be used to obtain<br />
the steady-state distribution of the queue occupancy.<br />
1) Steady State Distribution of the Remainder Workload<br />
The steady state distribution of the remainder workload can be<br />
given by the following theorem.<br />
Theorem 2: As the number of flows increases (i.e., Q → ∞ ), the<br />
steady state distribution of the remainder workload tends towards a<br />
Gaussian distribution <strong>with</strong> mean Q( b – 1) ⁄ 2 and variance<br />
Q( b 2 – 1) ⁄ 12 .<br />
Proof: Appendix.<br />
See<br />
2) Steady State Distribution of the Batch Workload<br />
Having derived the steady state distribution of the remainder workload,<br />
we now derive the steady state distribution of the batch workload.<br />
We use the batch queue model shown in Figure 3. In this model,<br />
we analyze arrivals and departures of batches of cells instead of individual<br />
cells. The batch arrival process is the superposition of Q IID<br />
source 1<br />
MA 1 (t)<br />
MA Q (t)<br />
source Q<br />
MA(t)<br />
Figure 3: The batch queue model<br />
+<br />
ML(t)<br />
processes MA i ( t) , <strong>with</strong> total rate λ ⁄ b . Under the BWC-MMA discipline,<br />
the batch queue is serviced by a work-conserving server of rate<br />
1 ⁄ b .<br />
Using Lindley’s recursion [13], the batch workload can be written<br />
as<br />
ML( t) = max 0 ≤ s ≤ t (( MA( t) – MA( s)<br />
)–( t – s) ⁄ b)<br />
. (9)<br />
Equation (9) indicates that, given the steady-state distribution of<br />
the batch arrivals, it is theoretically possible to derive the steady-state<br />
distribution of the batch workload.<br />
For general arrival patterns it is often not easy to find a closed-form<br />
solution. However, for a broad range of arrival traffic patterns, the<br />
superposition of an increasing number of flows can be shown to result<br />
in a steady-state workload distribution that converges towards the<br />
steady-state workload distribution of an M/D/1 queue.<br />
To do so, we first make the following additional assumptions on the<br />
arrival processes A i ( t) . We assume that each A i ( t)<br />
is a simple point<br />
process satisfying the following properties [14]. First, the expected<br />
value of A i ( t) is given by λ i t . Second, a source cannot send more<br />
than one cell at a time. And third, the probability of many cells arriving<br />
in an arbitrarily small interval [ 0,<br />
t] decays fast as t → 0 .<br />
These assumptions are fairly general and apply to a variety of traffic<br />
sources, including Poisson, Gamma, Weibull, Inverse Weibull,<br />
ExpOn-ExpOff, and ParetoOn-ExpOff. These point processes model<br />
a wide range of observed traffic [14], including wide area network<br />
traffic.<br />
Given these assumptions, we can state the following theorem.<br />
Theorem 3: As the number of flows increases (i.e., Q → ∞ ), the<br />
steady state exceedence probability P( ML > x)<br />
of the batch workload<br />
approaches the corresponding exceedence probability <strong>with</strong> a<br />
Poisson source <strong>with</strong> the same load.<br />
Proof: See<br />
Theorem 3 shows that as the number of multiplexed IID sources<br />
increases, the exceedence probability approaches the corresponding<br />
probability assuming Poisson sources, which is known explicitly<br />
through the analysis of the resulting M ⁄ D ⁄ 1 system<br />
Appendix.<br />
[15].<br />
3) Steady State Distribution of the System Workload<br />
MD(t)<br />
Using the fixed-batch decomposition, f L ( x)<br />
can easily be derived<br />
as the convolution of f R ( x) and f ML ( x)<br />
, which were obtained above.<br />
We now provide an intuitive analysis of f L ( x)<br />
for a large number<br />
of flows. 5 For low values of λ , f ML ( x)<br />
behaves like an impulse close<br />
to zero. Since a convolution <strong>with</strong> an impulse at zero produces an output<br />
equal to the input, f L ( x) would very much resemble f R ( x)<br />
for<br />
low values of λ , and therefore be close to a Gaussian.<br />
5. In practice, we start observing the convergence indicated in Theorem 2<br />
and Theorem 3 when the number of flows exceeds 100.
DRAM<br />
L(t)<br />
A(t)<br />
SRAM<br />
Buffer<br />
F<br />
I<br />
F<br />
O<br />
MA ˆ<br />
MD ˆ<br />
( t)<br />
( t)<br />
D(t-LA)<br />
Lookahead Buffer<br />
D(t)<br />
D(t-LA)<br />
LA<br />
Figure 4: Theoretical PDF of L(t) for various loads for Q=1024 and<br />
b=4 (the mean of the Gaussian is 1536)<br />
Figure 4 plots f R ( x) and f L ( x)<br />
as predicted by the theoretical<br />
model and shows that this is indeed the case. At λ = 0.1 , the plots<br />
corresponding to f R ( x) and f L ( x) are indistinguishable. At λ = 0.5 ,<br />
the plots are still very close. The plots then separate out as the load<br />
increases.<br />
The main consequence of this observation is that, even for low<br />
loads, f L ( x)<br />
would result in more than 50% drops for an SRAM size<br />
less than Q( b – 1) ⁄ 2 , the mean of the Gaussian. However, f L ( x)<br />
falls very quickly due to the low variance of the Gaussian, and low<br />
drop probabilities can be obtained close to Q( b – 1) ⁄ 2 . Therefore, to<br />
give reasonable performance guarantees, the SRAM has to be slightly<br />
more than Q( b – 1) ⁄ 2 , or Θ( Qb)<br />
.<br />
A. Head SRAM Model<br />
III. ANALYSIS OF THE HEAD SRAM<br />
As was the case for the tail SRAM, we assume the head SRAM to<br />
be dynamically shared among Q flow queues. However, similarities<br />
<strong>with</strong> the tail SRAM end here. For dynamic sharing to be useful for the<br />
head SRAM, we need to be able to predict the (external) arbiter<br />
request pattern in some way - if we can’t predict the request pattern to<br />
the SRAM, we have to buffer up cells for each queue in a static way<br />
and the advantage of dynamic sharing is lost. Thus, we assume the<br />
presence of a fixed length lookahead buffer, which we use to predict<br />
the request pattern to the SRAM. 6 Note that this assumes that the arbiter<br />
is willing to tolerate a fixed delay LA between the arrival of<br />
requests and the delivery of cells from the SRAM.<br />
We use the scheme shown in Figure 5. Incoming requests ( D( t)<br />
)<br />
from an external arbiter enter the lookahead buffer to the right and<br />
exit to the left after a fixed delay LA . Based on the requests in the<br />
lookahead buffer and the cells in the SRAM, read requests ( MDˆ<br />
( t)<br />
)<br />
are made to the DRAM so as to ensure that the cells ( A( t)<br />
) are written<br />
to the SRAM before the requests exit the lookahead buffer and<br />
cells are read from the SRAM.<br />
Similar to Section II.A, we define L( i,<br />
t)<br />
as the number of cells<br />
present in queue i , and L( t) = L( i,<br />
t)<br />
as the total SRAM occupancy<br />
at time t. We then define LR( i,<br />
t)<br />
to be the number of requests<br />
for queue i in the lookahead buffer, and DEF( i,<br />
t)<br />
to be the deficit<br />
∑<br />
6.<br />
This is inspired by the lookahead scheme in [9].<br />
(number of arbiter requests for which a DRAM request has not been<br />
made) for queue i at time t . A queue is defined to be critical at time<br />
t if DEF( i,<br />
t) < 0 .<br />
We assume that the MMA works as follows [9]. Starting from an<br />
empty SRAM, whenever the DRAM is free, it serves the earliest critical<br />
queue from the set of critical queues, provided there is space in the<br />
SRAM. If there are no critical queues then it doesn’t do anything.<br />
In reference to Figure 5, the MMA operation can be described as<br />
follows. When an arbiter request arrives, the deficit of the corresponding<br />
queue is calculated. If the queue has gone critical, a read request is<br />
is queued at the fetch FIFO, which is served in batches of b cells at<br />
rate 1 ⁄ b . We now define FD( t)<br />
to be the delay through the fetch<br />
FIFO.<br />
We refer to this MMA as a Deficit Work Conserving MMA (DWC-<br />
MMA) since it is work conserving as soon as at least one queue has<br />
gone critical. Because of the work conservation, DWC-MMA minimizes<br />
the head SRAM occupancy among all possible MMAs in this<br />
architecture. Therefore, given a head SRAM of size S in the hybrid<br />
architecture, DWC-MMA ensures that the drop probability P is minimized.<br />
Equivalently, it minimizes S given a fixed P.<br />
In what follows we relate the (request) drop probability from the<br />
head SRAM to the size of the lookahead buffer ( LA ) as well as the<br />
size of the SRAM ( S ). This analysis can be extremely challenging<br />
due to the interactions between the lookahead buffer and the SRAM.<br />
B. Analysis of Head SRAM<br />
The analysis of this complex system can be simplified as follows.<br />
Observe that a request may not be served (or dropped) due to two reasons.<br />
First, the lookahead buffer may not be deep enough to bring in<br />
the required cells into the SRAM by the time the request traverses to<br />
the end of the lookahead buffer. Second, even if the lookahead buffer<br />
is deep enough, the SRAM may not be big enough to store the incoming<br />
cells from the DRAM.<br />
We refer to the overflowing of the lookahead buffer and head<br />
SRAMs as events E1 and E2 , respectively. Now, the (request) drop<br />
probability from the head SRAM of size S , using a lookahead buffer<br />
of size LA , can be given by the following<br />
P( S,<br />
LA) = P( E1 ∪ E2)<br />
, (10)<br />
or<br />
Figure 5: The head SRAM buffer model<br />
P( S,<br />
LA) ≤ P( E1) + P( E2)<br />
. (11)
We again assume infinite buffers and use P( FD > LA)<br />
and<br />
P( L > S) as surrogates for P( E1) and P( E2)<br />
, respectively. This lets<br />
us rewrite Equation (11) as<br />
P( S,<br />
LA) ≤ P( FD > LA) + P( L > S)<br />
. (12)<br />
Thus, we can analyze P( FD > LA) and P( L > S)<br />
separately to get<br />
an upper bound on the drop probability of the head SRAM. It turns<br />
out that both of these can be analyzed in a way very similar to the tail<br />
SRAM.<br />
C. A Model of the Queue<br />
∑ ∑<br />
Similar to Section II we can develop a model for the head SRAM<br />
that is easy to analyze. We denote the request arrival process to the<br />
SRAM by D( t) , where D( t)<br />
is the cumulative number of requests<br />
arriving in [ 0,<br />
t] . D( t)<br />
is further assumed to be generated by the<br />
superposition of Q arrival processes D i ( t) , where D i ( t)<br />
is the<br />
cumulative number of requests sent for flow i in [ 0,<br />
t] . Each D i ( t)<br />
is assumed to have rate λ i , <strong>with</strong><br />
∑λ λ i = < 1 . In addition, we<br />
assume that the request arrival processes D i ( t)<br />
satisfy the assumptions<br />
stated the cell arrival processes A i ( t)<br />
in Section II.<br />
We start by noting that each D i ( t)<br />
can be written down as the following<br />
D i ( t) = b × MD i ( t)<br />
+ R i ( t)<br />
, (13)<br />
where R i ( t) and MD i ( t) are the remainder and quotient after D i ( t)<br />
is divided by b .<br />
Now, similar to Equation (3), the multiplexed process D( t)<br />
can be<br />
written as<br />
D( t) = b × MD( t)<br />
+ R( t)<br />
, (14)<br />
where MD( t) = MD i ( t)<br />
and R( t) = R i ( t)<br />
.<br />
We now define a derivative process that is more useful in analyzing<br />
the DRAM traffic due to DWC-MMA. The derivative process is<br />
defined as ˆ<br />
D i ( t) = D i ( t) + ( b – 1)<br />
, (15)<br />
which gives<br />
Dˆ<br />
( t) = D( t) + Q( b – 1)<br />
. (16)<br />
Now, breaking Dˆ i ( t) down in the same way as D i ( t)<br />
, we get<br />
Dˆ i ( t) = b × MDˆ i ( t)<br />
+ Rˆ i ( t)<br />
, (17)<br />
where Rˆ i ( t) and MDˆ i ( t) are the remainder and quotient after Dˆ i ( t)<br />
is divided by b . Thus, in a way similar to Equation (14), we get<br />
Dˆ<br />
( t) = b × MDˆ<br />
( t)<br />
+ Rˆ ( t)<br />
, (18)<br />
where MDˆ<br />
( t) = MDˆ i ( t)<br />
and Rˆ ( t) = Rˆ i ( t)<br />
.<br />
. MDˆ<br />
( t)<br />
is precisely the arrival process to the fetch FIFO. This is<br />
due to the fact that, starting from an empty SRAM buffer, arrival<br />
numbering 1,<br />
b + 1,<br />
2b + 1 , … to an SRAM queue result in fetches<br />
from the DRAM.<br />
Now, as mentioned earlier, the fetch FIFO is served at a rate 1 ⁄ b ,<br />
resulting in the departure process MÂ( t) , where MÂ( t)<br />
is related<br />
to the arrival process to the SRAM buffer (i.e. A( t)<br />
) in the following<br />
way<br />
A( t) = b × MA( t)<br />
= b × MÂ( t – b)<br />
. (19)<br />
The first equality in Equation (19) represents the fact that arrivals<br />
to the SRAM always occur in batches of b . The second equality<br />
reflects the fact that<br />
∑ ∑<br />
the there is a fixed delay of b in reading from the<br />
DRAM. Now, noting that the departure process from the SRAM<br />
buffer is given by D( t – LA) , the SRAM buffer occupancy L( t)<br />
can<br />
be given by<br />
L( t) = A( t) – D( t – LA)<br />
. (20)<br />
Using Equation (16) and Equation (19), we can write this as<br />
L( t) = b × MÂ( t – b)<br />
– ( Dˆ<br />
( t – LA) – Q( b – 1)<br />
) . (21)<br />
Substituting for Dˆ<br />
( t)<br />
from Equation (18), we get<br />
L( t) = b × ( MÂ( t – b) – MDˆ<br />
( t – LA)<br />
) + ( Q( b – 1) – Rˆ ( t – LA)<br />
)<br />
(22)<br />
or<br />
L( t) = b × ML( t)<br />
+ RL( t)<br />
, (23)<br />
where<br />
ML( t) = MÂ( t – b) – MDˆ<br />
( t – LA)<br />
(24)<br />
and<br />
RL( t) = Q( b – 1) – Rˆ ( t – LA)<br />
. (25)<br />
Realize that Equation (23) looks strikingly similar to Equation (7) -<br />
in what follows, we show that it can be analyzed in a similar way.<br />
However, for the sake of brevity, we intentionally stay away from<br />
proving theorems that pretty much resemble the ones proved in Section<br />
II, and state the results in an intuitive way.<br />
We start by looking at the steady state distribution of RL( t)<br />
(i.e,<br />
f RL ( x) ). We note that f RL ( x)<br />
can be obtained from the distribution of<br />
Rˆ ( t) (i.e., f Rˆ ( x) ) by first flipping f Rˆ ( x)<br />
around the origin and then<br />
shifting to the right by Q( b – 1)<br />
. 7 In addition, it can be proven, in a<br />
way very similar to Theorem 2, that f Rˆ ( x)<br />
is Gaussian <strong>with</strong> mean<br />
Q( b – 1) ⁄ 2 and variance Q( b 2 – 1) ⁄ 12 . 8 So, for large Q , after<br />
going through the linear transformations mentioned above, f RL ( x)<br />
would pretty much be the same Gaussian as f Rˆ ( x)<br />
.<br />
Now we are ready to look at the distribution of ML( t)<br />
. To do so,<br />
we use the following inequalities<br />
MDˆ<br />
( t) – LA ⁄ b ≤ MDˆ<br />
( t – LA) ≤ MDˆ<br />
( t)<br />
(26)<br />
and<br />
MÂ( t) – 1 ≤ MÂ( t – b) ≤ MÂ( t)<br />
. (27)<br />
In Equation (26), the right hand side inequality is pretty straightforward.<br />
The left hand side inequality comes from the fact that in time<br />
LA there can be at most LA ⁄ b fetch requests. Equation (27) can be<br />
explained in a similar way.<br />
Using Equation (26) and Equation (27) in Equation (24), we get<br />
ML( t) ≤ MÂ( t) – ( MDˆ<br />
( t) – LA ⁄ b)<br />
(28)<br />
or<br />
ML( t) ≤ LA ⁄ b – ( MDˆ<br />
( t) – MÂ( t)<br />
)<br />
(29)<br />
or<br />
ML( t ) ≤ LA ⁄ b – MLˆ ( t)<br />
(30)<br />
where MLˆ ( t) = MDˆ<br />
( t) – MÂ( t)<br />
is the occupancy of the fetch<br />
FIFO. Equation (30) shows that the steady state distribution of<br />
ML( t) (i.e., f ML ( x)<br />
) can be obtained from the distribution of<br />
MLˆ ( t) (i.e., f MLˆ ( x) ) by first flipping f MLˆ ( x)<br />
around the origin and<br />
then shifting to the right by LA ⁄ b . Note that, for IID D i ( t)<br />
, Theorem<br />
3 applies, and f MLˆ ( x)<br />
can be derived as the steady state distribution<br />
of an M ⁄ D ⁄ 1 queue.<br />
At this point, we have the distributions of both the components of<br />
Equation (23). It can be shown, in a way very similar to Theorem 1,<br />
that Rˆ ( t) and MLˆ ( t)<br />
are independent of each other, given the<br />
assumptions on D i ( t) . Since RL( t) and ML( t)<br />
are linear transformations<br />
of Rˆ ( t) and MLˆ ( t)<br />
, they are also independent of each other,<br />
and the PDF of L( t) (i.e., f L ( x)<br />
) can be obtained by convolving<br />
f RL ( x) and f ML ( x)<br />
, i.e.,<br />
f L ( x) = f RL ( x) ⊗ f ML ( x ⁄ b)<br />
. (31)<br />
7. The steady state distribution of Rˆ ( t – LA)<br />
is the same as the steady<br />
state distribution of Rˆ ( t) as t → ∞<br />
8.<br />
While keeping similar assumptions in mind.
(a) load=0.5<br />
Figure 6: Theoretical PDF of L(t) for various loads for Q=1024 and<br />
b=4, <strong>with</strong> T=100*load<br />
By analyzing for the distribution of L( t)<br />
we can get one of the<br />
quantities (i.e., P( L > S)<br />
) required by Equation (12). To derive the<br />
other quantity (i.e., P( FD > LA)<br />
) we simply note that the delay<br />
through the constant-service-rate fetch FIFO is directly related to the<br />
occupancy of the FIFO, i.e.,<br />
P( FD > LA) = P( MLˆ<br />
> LA ⁄ b)<br />
. (32)<br />
Thus, by solving for the distributions of RLˆ ( t) and MLˆ ( t)<br />
, we<br />
get both the quantities required by Equation (12).<br />
D. Putting it Together<br />
We have talked about the sizes of the lookahead and SRAM buffers<br />
as independent parameters. However, to get a reasonable value for the<br />
upper bound indicated by Equation (12), we would have to first<br />
choose a value of LA such that P( FD > LA)<br />
is fairly low. Once we<br />
have picked LA , we can then get P( L > S) using LA as a constant.<br />
Note that this value of LA would depend only on the load λ . However,<br />
in the M ⁄ D ⁄ 1 context, the value of LA to achieve low values<br />
of P( FD > LA) may blow up in the limit λ → 1 . So, how do we<br />
choose a value of LA that works for all traffic loads? The solution is<br />
to limit the maximum load and assume that a design has a small speed<br />
up - for example, a maximum λ of 0.9 would require a speed up of<br />
1 ⁄ 0.9 ≅ 1.1 . Now, LA can be chosen for this maximum λ . In fact,<br />
for large Q, the value of LA required to achieve low values of<br />
P( FD > LA) turns out to be much smaller than Q( b – 1) ⁄ 2 .<br />
Figure 6 plots f L ( x)<br />
, as predicted by the theoretical model, for various<br />
values of λ when Q = 1024 , b = 4 , and LA = cλ . We<br />
picked c = 100 by noting that, as long as λ ≤ 0.9 , the steady state<br />
distribution for the M ⁄ D ⁄ 1 queue dies out by the time the queue<br />
occupancy gets to 100λ .<br />
These plots are very similar to the ones in Figure 4, except for a<br />
right shift by LA = cλ . For low values of λ , f ML ( x)<br />
behaves like<br />
an impulse close to LA ⁄ b . Thus, we expect f L ( x)<br />
to very much<br />
resemble a Gaussian centered about Q( b – 1) ⁄ 2 + LA . This would<br />
of course change as λ → 1 , <strong>with</strong> the Gaussian being shifted to the<br />
right and spread out a little. Again, note that in order to provide reasonable<br />
performance guarantees, the head SRAM is required to be<br />
Θ( Qb)<br />
.<br />
(b) load=0.9<br />
Figure 7: Complementary CDF for b=4 and Q=1024<br />
IV. SIMULATIONS<br />
In this section we present some simulation results for the tail<br />
SRAM and compare them to the predictions from Section II. The simulation<br />
results for the head SRAM are similar, and are not presented<br />
here.<br />
Figure 7 plots of the drop probability as a function of the tail<br />
SRAM size when b = 4 and Q = 1024 . These zoomed-out plots<br />
correspond to the prediction from theory and simulation results for<br />
two traffic types: Bernoulli IID Uniform and Bursty Uniform (the<br />
burst lengths are geometrically distributed <strong>with</strong> average burst length<br />
12).<br />
We observe that the plots for λ = 0.5 are pretty much indistinguishable.<br />
In addition, we observe that the plots are very close to the<br />
Gaussian predicted by Theorem 2. Similarly, the plots for λ = 0.9<br />
are very close to each other, <strong>with</strong> the plot from theory upper bounding<br />
the other two for large values of queue occupancy. This shows the<br />
power of Theorem 3 and indicates that the Poisson limit has already<br />
been reached for Q = 1024 .<br />
V. CONCLUSIONS<br />
In this paper we presented a model for providing statistical guarantees<br />
for a hybrid SRAM-DRAM architecture. We used this model to<br />
establish exact bounds relating the drop probability to the SRAM size.<br />
This model may be useful beyond the scope of this paper because it<br />
may apply to many queueing systems <strong>with</strong> fixed batch service. These<br />
systems are increasingly common due to the growing line rates and<br />
the resulting use of parallelism and load-balancing.<br />
Comparing to the deterministic, worst case analysis in [9], which<br />
established Q( b – 1)<br />
as the lower bound on SRAM size, we note that<br />
our results provide an improvement by at most a factor of two. How-
ever, similar to [9], our bounds have a linear dependence on Qb . The<br />
linear dependence on Q could be undesirable in cases where Q is<br />
large.<br />
Thus, our results can also be interpreted as an negative result for<br />
this architecture. This can be stated in the following way: under the<br />
hybrid SRAM-DRAM architecture, Θ( Qb)<br />
is a hard lower bound on<br />
the size of the SRAM, which can not be improved upon under any<br />
realistic traffic pattern.<br />
We believe this to be a characteristic of this architecture - since we<br />
always transfer blocks of b cells, this results in storing Θ( b)<br />
cells<br />
for Θ( Q) flows, resulting in a total storage of Θ( Qb)<br />
. This indicates<br />
that we need to look at alternative architectures if design choices dictate<br />
using SRAM sizes orders of magnitude lower than Θ( Qb)<br />
.<br />
REFERENCES<br />
[1] C. Villamizar and C. Song, “High Performance TCP in ANSNET”,<br />
Computer Communication Review, Vol. 24, No. 5, pp. 45--60, October<br />
1994.<br />
[2] G. Appenzeler, I. Keslassy, and N. McKeown, “Sizing Router <strong>Buffers</strong>”,<br />
accepted at ACM SIGCOMM’04. Available at http://www.stanford.edu/~nickm.<br />
[3] Caida, “Round-Trip Time Measurements from CAIDA’s Macroscopic<br />
Internet Topology Monitor”, available at http://www.caida.org/analysis/performance/rtt/walrus0202/.<br />
[4] Samsung, “Samsung K7N323645M NtSRAM”. Available at http://<br />
www.samsung.com/Products/Semiconductor/SRAM/index.htm.<br />
[5] Samsung, “Samsung K4S1G0632M SDRAM”. Available at http://<br />
www.samsung.com/Products/Semiconductor/DRAM/index.htm.<br />
[6] Cisco, “Cisco 12000 Series Two-Port OC-192c/STM-64c POS Line<br />
card”. Available at http://www.cisco.com/en/US/products/hw/routers/<br />
ps167/products_data_sheets_list.html.<br />
[7] D. A. Patterson and J. L. Hennessy, Computer Architecture, A Quantitative<br />
Approach, Section 8.4., pp. 425-432, Morgan Kaufmann, 1996,<br />
[8] K.G. Coffman and A. M. Odlyzko, “Is there a “Moore’s Law” for data<br />
traffic?,” Handbook of Massive Data Sets, eds., Kluwer, 2002, pp. 47-<br />
93.<br />
[9] S. Iyer, R. R. Compella, and N. McKeown, “<strong>Designing</strong> <strong>Buffers</strong> for<br />
Router Line Cards”, Stanford University HPNG Technical Report -<br />
TR02-HPNG-031001, Stanford, CA, 2002.<br />
[10] S. Iyer, R. R. Kompella, and N. McKeown, “Analysis of a Memory Architecture<br />
for Fast <strong>Packet</strong> <strong>Buffers</strong>,” IEEE HPSR’02, Dallas, Texas, May<br />
2001.<br />
[11] J. García, J. Corbal, L. Cerdà and M. Valero, “Design and Implementation<br />
of High-Performance Memory Systems for Future <strong>Packet</strong> <strong>Buffers</strong>,”<br />
Proceedings of the 36th Annual IEEE/ACM International Symposium<br />
on Microarchitecture, p.373, 2003.<br />
[12] G. Shrimali and N. McKeown, “<strong>Statistical</strong> <strong>Guarantees</strong> for <strong>Packet</strong> <strong>Buffers</strong>:<br />
The Monolithic DRAM Case”, Stanford University HPNG Technical<br />
Report - TR04-HPNG-020603, Stanford, CA, 2004.<br />
[13] C.-S. Chang, Performance <strong>Guarantees</strong> in Communication Networks<br />
London, Springer-Verlag, 2000.<br />
[14] J. Cao and K. Ramanan, “A Poisson Limit for Buffer Overflow Probabilities”,<br />
Proceedings of IEEE INFOCOM’02, pp. 994-1003, 2002.<br />
[15] U. Mocci, J. Roberts, and J. Virtamo, Broadband Network Teletraffic:<br />
Final Report of Action COST 242, Springer, Berlin, 1996.<br />
. ∑ ∑<br />
.<br />
result.<br />
For the first part, we start by proving that, for all i,j, R i ( t)<br />
is independent<br />
of MA j ( t) . For i ≠ j , R i ( t) is a function of A i ( t) , MA j ( t)<br />
is<br />
a function of A j ( t) , and A i ( t) is independent of A j ( t)<br />
. Therefore<br />
R i ( t) is independent of MA j ( t) . In addition, R i ( t) and MA j ( t)<br />
are<br />
independent of each other for i = j since A i ( t)<br />
is stationary and<br />
ergodic. Therefore, due to component-wise independence, the derived<br />
processes MA( t) = MA i ( t)<br />
and R( t) = R i ( t)<br />
are independent<br />
of each other. This finishes the first part of the proof.<br />
Now, to prove the second part, we note that D( t) and MD( t)<br />
are<br />
functions of the process MA( t)<br />
, and therefore are independent of<br />
R( t) . Thus, ML( t ) = MA( t) – MD( t)<br />
is also independent of<br />
R( t)<br />
Proof: (Theorem 2) The proof is in two steps. The first part involves<br />
proving that the workload remainders R i ( t)<br />
are IID. The second part<br />
involves the application of the Central Limit Theorem.<br />
For the first part, we note that R i ( t) depends only on A i ( t)<br />
. Since<br />
the parent processes A i ( t)<br />
are independent of each other, the derived<br />
processes R i ( t)<br />
are independent of each other. Also, since the interarrival<br />
times of arrival process A i ( t)<br />
are stationary and ergodic,<br />
R i ( t) would stay at each of the b states <strong>with</strong> equal probability, giving<br />
P( R = x) = 1 ⁄ b,<br />
∀x<br />
. This is precisely the discrete uniform distribution,<br />
Proof: (Theorem 3)We first show that if A i ( t)<br />
are simple and stationary<br />
point processes then MA i ( t)<br />
are simple and stationary point processes.<br />
Remember that each MA i ( t) is generated by taking every b th<br />
sample of the corresponding parent process A i ( t)<br />
. Therefore, in any<br />
time interval, MA i ( t) will have fewer arrivals than A i ( t)<br />
. So if<br />
<strong>with</strong> mean ( b – 1) ⁄ 2 and variance ( b 2 – 1) ⁄ 12 .<br />
Now, R( t) is a sum of Q IID uniformly-distributed random variables,<br />
each <strong>with</strong> mean ( b – 1) ⁄ 2 and variance ( b 2 – 1) ⁄ 12 . By the<br />
Central Limit Theorem, as Q → ∞ , R( t)<br />
tends towards a Gaussian<br />
random variable <strong>with</strong> mean Q( b – 1) ⁄ 2 and variance<br />
Q( b 2 – 1) ⁄ 12<br />
A i ( t)<br />
satisfies properties of a simple point process (Section II.C.2),<br />
then MA i ( t) will too. 9 Thus MA i ( t)<br />
is a simple point process.<br />
The stationarity of MA i ( t) follows from that fact that MA i ( t)<br />
is<br />
generated from A i ( t)<br />
using a fixed sampling rule. Thus, if the characteristics<br />
of the parent process A i ( t)<br />
are stationary (i.e., independent<br />
of time) then the characteristics of MA i ( t)<br />
are stationary.<br />
Thus, all the assumptions stated for A i ( t) are also true for MA i ( t)<br />
.<br />
This allows us to use Theorem 1 in [14] to get the required<br />
APPENDIX<br />
Proof: (Theorem 1) The proof is in two steps. The first part involves<br />
proving the independence of R( t) and MA( t)<br />
. The second part then<br />
proves the independence of R( t) and ML( t ) .<br />
9. Note that<br />
E[ MA i ( t)<br />
] = E[ A i ( t) ⁄ b] = λ i t ⁄ b










