- Page 1 and 2: Programming GuideATI Stream Computi
- Page 3 and 4: PrefaceATI STREAM COMPUTINGAbout Th
- Page 5: ATI STREAM COMPUTINGContact Informa
- Page 8 and 9: ATI STREAM COMPUTINGChapter 2Chapte
- Page 10 and 11: ATI STREAM COMPUTINGAppendix DDevic
- Page 12 and 13: ATI STREAM COMPUTINGxiiContentsCopy
- Page 14 and 15: ATI STREAM COMPUTING1.1.3 Synchroni
- Page 16 and 17: ATI STREAM COMPUTINGA stream core i
- Page 18 and 19: ATI STREAM COMPUTINGFigure 1.4Simpl
- Page 20 and 21: ATI STREAM COMPUTING1.3.2 Flow Cont
- Page 22 and 23: ATI STREAM COMPUTINGkernels written
- Page 24 and 25: ATI STREAM COMPUTING1.4.1 Memory Ac
- Page 28 and 29: ATI STREAM COMPUTINGWork-ItemT0XXXX
- Page 30 and 31: ATI STREAM COMPUTINGparallel progra
- Page 32 and 33: ATI STREAM COMPUTINGsuch as a given
- Page 34 and 35: ATI STREAM COMPUTING1.9.2 Second Ex
- Page 36 and 37: ATI STREAM COMPUTINGExample Code 2
- Page 38 and 39: ATI STREAM COMPUTING///////////////
- Page 40 and 41: ATI STREAM COMPUTINGminimized. Note
- Page 42 and 43: ATI STREAM COMPUTING" \n"" // Dump
- Page 44 and 45: ATI STREAM COMPUTING// Create a con
- Page 46 and 47: ATI STREAM COMPUTINGdbg_ptr = (cl_u
- Page 48 and 49: ATI STREAM COMPUTING2.1 Compiling t
- Page 50 and 51: ATI STREAM COMPUTINGOpenCL API Func
- Page 52 and 53: ATI STREAM COMPUTING2-6 Chapter 2:
- Page 54 and 55: ATI STREAM COMPUTING3.3 Sample GDB
- Page 56 and 57: ATI STREAM COMPUTING3-4 Chapter 3:
- Page 58 and 59: ATI STREAM COMPUTINGNameGPRScratchR
- Page 60 and 61: ATI STREAM COMPUTING4.3 Estimating
- Page 62 and 63: ATI STREAM COMPUTING4.3.3 Estimatin
- Page 64 and 65: ATI STREAM COMPUTING4.4.1 Two Memor
- Page 66 and 67: ATI STREAM COMPUTINGTable 4.2 lists
- Page 68 and 69: ATI STREAM COMPUTINGstrides. For in
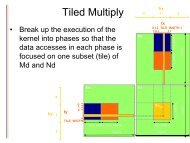
- Page 70 and 71: ATI STREAM COMPUTINGAn inefficient
- Page 72 and 73: ATI STREAM COMPUTINGFigure 4.3Trans
- Page 74 and 75: ATI STREAM COMPUTINGFigure 4.4Two K
- Page 76 and 77:
ATI STREAM COMPUTINGFigure 4.5Effec
- Page 78 and 79:
ATI STREAM COMPUTINGFigure 4.6Unali
- Page 80 and 81:
ATI STREAM COMPUTINGadvantages when
- Page 82 and 83:
ATI STREAM COMPUTING__kernel void l
- Page 84 and 85:
ATI STREAM COMPUTINGTable 4.7Hardwa
- Page 86 and 87:
ATI STREAM COMPUTINGeach of which p
- Page 88 and 89:
ATI STREAM COMPUTINGGP Registers us
- Page 90 and 91:
ATI STREAM COMPUTING4.8.3 Partition
- Page 92 and 93:
ATI STREAM COMPUTINGWork-item 0 1 2
- Page 94 and 95:
ATI STREAM COMPUTINGThe difference
- Page 96 and 97:
ATI STREAM COMPUTINGoperations: eac
- Page 98 and 99:
ATI STREAM COMPUTINGscheduling algo
- Page 100 and 101:
ATI STREAM COMPUTING4.9.5 GPU and C
- Page 102 and 103:
ATI STREAM COMPUTINGTable 4.11Singl
- Page 104 and 105:
ATI STREAM COMPUTINGpowr() 28.7xdiv
- Page 106 and 107:
ATI STREAM COMPUTING4.11 Clause Bou
- Page 108 and 109:
4.12 Additional Performance Guidanc
- Page 110 and 111:
ATI STREAM COMPUTING• When tuning
- Page 112 and 113:
ATI STREAM COMPUTING4-56 Chapter 4:
- Page 114 and 115:
A.3 Querying Extensions for a Devic
- Page 116 and 117:
ATI STREAM COMPUTINGA.7 cl_ext Exte
- Page 118 and 119:
ATI STREAM COMPUTINGBuilt-in functi
- Page 120 and 121:
ATI STREAM COMPUTINGA-8 Appendix A:
- Page 122 and 123:
ATI STREAM COMPUTINGcl_uint numPlat
- Page 124 and 125:
ATI STREAM COMPUTINGB-4 Appendix B:
- Page 126 and 127:
ATI STREAM COMPUTINGC.3 Performance
- Page 128 and 129:
ATI STREAM COMPUTINGGB/s10090807060
- Page 130 and 131:
ATI STREAM COMPUTINGTable D.1Parame
- Page 132 and 133:
ATI STREAM COMPUTINGD-4 Appendix D:
- Page 134 and 135:
ATI STREAM COMPUTINGTermALUARATI St
- Page 136 and 137:
ATI STREAM COMPUTINGTermdouble quad
- Page 138 and 139:
ATI STREAM COMPUTINGTermLDSLERPloca
- Page 140 and 141:
ATI STREAM COMPUTINGTermsamplerSCsc
- Page 142:
ATI STREAM COMPUTINGTermwaterfallwa