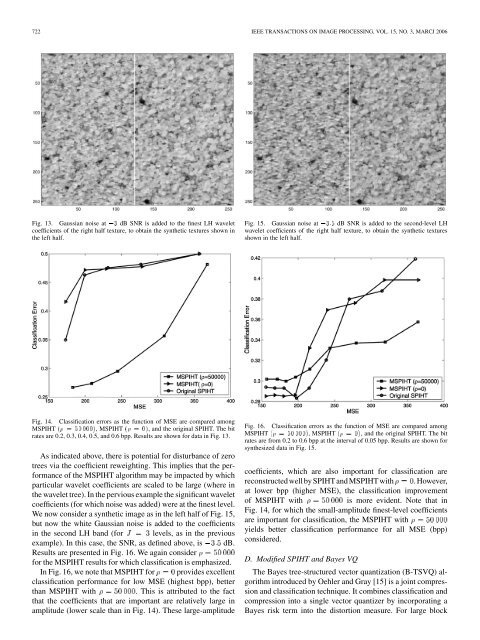
722 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 3, MARCJ 2006Fig. 13. Gaussian noise at 03 dB SNR is added to the finest LH waveletcoefficients of the right half texture, to obtain the synthetic textures shown inthe left half.Fig. 15. Gaussian noise at 03:5 dB SNR is added to the second-level LHwavelet coefficients of the right half texture, to obtain the synthetic texturesshown in the left half.Fig. 14.Classification errors as the function of <strong>MSE</strong> are compared amongM<strong>SPIHT</strong> ( = 50000), M<strong>SPIHT</strong> ( =0), <strong>and</strong> the original <strong>SPIHT</strong>. The bitrates are 0.2, 0.3, 0.4, 0.5, <strong>and</strong> 0.6 bpp. Results are shown <strong>for</strong> data in Fig. 13.As indicated above, there is potential <strong>for</strong> disturbance of zerotrees via the coefficient reweighting. This implies that the per<strong>for</strong>manceof the M<strong>SPIHT</strong> algorithm may be impacted by whichparticular wavelet coefficients are scaled to be large (where inthe wavelet tree). In the pervious example the significant waveletcoefficients (<strong>for</strong> which noise was added) were at the finest level.We now consider a synthetic image as in the left half of Fig. 15,but now the white Gaussian noise is added to the coefficientsin the second LH b<strong>and</strong> (<strong>for</strong> levels, as in the previousexample). In this case, the SNR, as defined above, is dB.Results are presented in Fig. 16. We again consider<strong>for</strong> the M<strong>SPIHT</strong> results <strong>for</strong> which classification is emphasized.In Fig. 16, we note that M<strong>SPIHT</strong> <strong>for</strong> provides excellentclassification per<strong>for</strong>mance <strong>for</strong> low <strong>MSE</strong> (highest bpp), betterthan M<strong>SPIHT</strong> with . This is attributed to the factthat the coefficients that are important are relatively large inamplitude (lower scale than in Fig. 14). These large-amplitudeFig. 16.Classification errors as the function of <strong>MSE</strong> are compared amongM<strong>SPIHT</strong> ( = 50000), M<strong>SPIHT</strong> ( =0), <strong>and</strong> the original <strong>SPIHT</strong>. The bitrates are from 0.2 to 0.6 bpp at the interval of 0.05 bpp. Results are shown <strong>for</strong>synthesized data in Fig. 15.coefficients, which are also important <strong>for</strong> classification arereconstructedwell by <strong>SPIHT</strong><strong>and</strong> M<strong>SPIHT</strong> with . However,at lower bpp (higher <strong>MSE</strong>), the classification improvementof M<strong>SPIHT</strong> withis more evident. Note that inFig. 14, <strong>for</strong> which the small-amplitude finest-level coefficientsare important <strong>for</strong> classification, the M<strong>SPIHT</strong> withyields better classification per<strong>for</strong>mance <strong>for</strong> all <strong>MSE</strong> (bpp)considered.D. <strong>Modified</strong> <strong>SPIHT</strong> <strong>and</strong> Bayes VQThe Bayes tree-structured vector quantization (B-TSVQ) algorithmintroduced by Oehler <strong>and</strong> Gray [15] is a joint compression<strong>and</strong> classification technique. It combines classification <strong>and</strong>compression into a single vector quantizer by incorporating aBayes risk term into the distortion measure. For large block
CHANG AND CARIN: MODIFIED <strong>SPIHT</strong> ALGORITHM FOR IMAGE CODING 723Fig. 17. Training imagery <strong>for</strong> B-TSVQ, with labeled “urban” <strong>and</strong> “rural”classes.sizes, B-TSVQ per<strong>for</strong>mance approaches the theoretical rate-distortionbound [5]. TSVQ has the limitations of computationalcomplexity, a requirement of knowledge of the posterior probability,<strong>and</strong> it also requires the availability of a large trainingset. In image processing, the VQ block size is usually 4 4orsmaller because of computational constraints [20].In our first comparison, we consider the measured imageryin Fig. 4, with the “true” segmentation defined as discussedabove (dictated by the results of the HMT segmentation). TheM<strong>SPIHT</strong> results are extensions from Fig. 12, <strong>for</strong><strong>and</strong> . The M<strong>SPIHT</strong> results are computed adaptively onthe imagery in Fig. 4, without any a priori training data. By contrast,the B-TSVQ requires training data to design the tree-structuredcodebook <strong>and</strong> to build the associated classifier (a look-uptable, that maps a code to a texture). In Fig. 17, we present separatetraining data, from the “rural” <strong>and</strong> “urban” classes, usedto train the B-TSVQ algorithm. These data are distinct examplesfrom the same USC-SIPI database from which Fig. 4 wasacquired. We consider a bit rate of 0.35 bit/pixel. To achievethis bit rate we run the required number of M<strong>SPIHT</strong> iterations,while <strong>for</strong> B-TSVQ the bit rate is dictated by the number of thecodes <strong>and</strong> size of each block. We here consider a codebook ofsize 49, <strong>and</strong> each block is of size 4 4. The M<strong>SPIHT</strong> classificationis based upon two wavelet levels, to be consistent withthe 4 4 blocks used by B-TSVQ. However, to improve codingefficiency, the M<strong>SPIHT</strong> is run <strong>for</strong> levels (only two ofwhich are used in the classifier). To run M<strong>SPIHT</strong> with ,wefirst run the iterative algorithm in Section III-C <strong>for</strong> . Thewavelet <strong>and</strong> scaling coefficients are then weighted as so determined.The subsequent three wavelet levels are then per<strong>for</strong>medon these weighted coefficients.We also show M<strong>SPIHT</strong> results <strong>for</strong> a classifier based on threelevels, corresponding to 8 8 blocks. The results in Fig. 18, <strong>for</strong>both M<strong>SPIHT</strong> <strong>and</strong> B-TSVQ, are computed by controlling theLagrange multiplier that dictates the balance between concentratingon <strong>MSE</strong> <strong>and</strong> classification error. The results indicate thatM<strong>SPIHT</strong> has better compression per<strong>for</strong>mance than B-TSVQ(smaller <strong>MSE</strong>), but B-TSVQ has more sensitivity to the Lagrangian-driventradeoff between <strong>MSE</strong> <strong>and</strong> classification (althoughin these results the B-TSVQ <strong>MSE</strong> does not change substantiallyas the Lagrange multiplier changes).Fig. 18. Classification error as a function of <strong>MSE</strong>, at a bit rate of 0.35 bpp.For both B-TSVQ <strong>and</strong> M<strong>SPIHT</strong> the variation in classification error <strong>and</strong> <strong>MSE</strong> iscontrolled by adjusting a respective Lagrange multiplier. Results are shown <strong>for</strong>data in Fig. 4.Fig. 19. Classification error as the function of <strong>MSE</strong> with Lagrangianmultipliers increasing are compared between B-TSVQ <strong>and</strong> M<strong>SPIHT</strong> at bit ratesof 0.35 bpp. Results are shown <strong>for</strong> data in Fig. 13.To complement the results discussed above (Fig. 4), <strong>for</strong> whichthere may be some uncertainty as to actual “truth,” we also considersynthetic data. In Fig. 19, we study the tradeoff between<strong>MSE</strong> <strong>and</strong> classification error <strong>for</strong> B-TSVQ <strong>and</strong> M<strong>SPIHT</strong> <strong>for</strong> thebit rate 0.35 bit/pixel, <strong>for</strong> the data in Fig. 13, which <strong>for</strong> B-TSVQcorresponds to a codebook of size 49, <strong>for</strong> blocks of size 4 4.Again, the M<strong>SPIHT</strong> classification is based upon two waveletlevels, to be consistent with the 4 4 blocks used by B-TSVQ,<strong>and</strong> to improve coding efficiency the M<strong>SPIHT</strong> is run <strong>for</strong>levels. We also show M<strong>SPIHT</strong> results <strong>for</strong> a classifier based onthree levels, corresponding to 8 8 blocks. Separate trainingdata with the same statistics were used to build the codes <strong>for</strong>the B-TSVQ. When comparing results <strong>for</strong> 4 4 blocks, we notethat the M<strong>SPIHT</strong> algorithm per<strong>for</strong>ms best <strong>for</strong> high classificationerror (lower <strong>MSE</strong>), with this attributed to the fact that theM<strong>SPIHT</strong> algorithm is effectively employing larger block sizes