

The Hierarchically Tiled Arrays Programming Approach
The Hierarchically Tiled Arrays Programming Approach
The Hierarchically Tiled Arrays Programming Approach

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
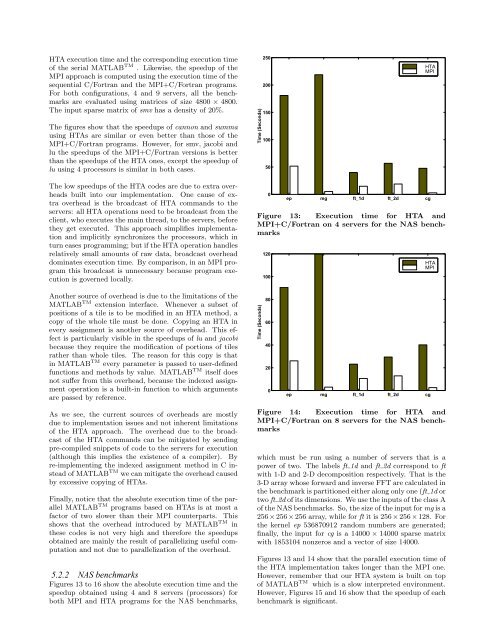
HTA execution time and the corresponding execution timeof the serial MATLAB TM . Likewise, the speedup of theMPI approach is computed using the execution time of thesequential C/Fortran and the MPI+C/Fortran programs.For both configurations, 4 and 9 servers, all the benchmarksare evaluated using matrices of size 4800 × 4800.<strong>The</strong> input sparse matrix of smv has a density of 20%.<strong>The</strong> figures show that the speedups of cannon and summausing HTAs are similar or even better than those of theMPI+C/Fortran programs. However, for smv, jacobi andlu the speedups of the MPI+C/Fortran versions is betterthan the speedups of the HTA ones, except the speedup oflu using 4 processors is similar in both cases.Time (Seconds)25020015010050HTAMPI<strong>The</strong> low speedups of the HTA codes are due to extra overheadsbuilt into our implementation. One cause of extraoverhead is the broadcast of HTA commands to theservers: all HTA operations need to be broadcast from theclient, who executes the main thread, to the servers, beforethey get executed. This approach simplifies implementationand implicitly synchronizes the processors, which inturn eases programming; but if the HTA operation handlesrelatively small amounts of raw data, broadcast overheaddominates execution time. By comparison, in an MPI programthis broadcast is unnecessary because program executionis governed locally.0ep mg ft_1d ft_2d cgFigure 13: Execution time for HTA andMPI+C/Fortran on 4 servers for the NAS benchmarks120100HTAMPIAnother source of overhead is due to the limitations of theMATLAB TM extension interface. Whenever a subset ofpositions of a tile is to be modified in an HTA method, acopy of the whole tile must be done. Copying an HTA inevery assignment is another source of overhead. This effectis particularly visible in the speedups of lu and jacobibecause they require the modification of portions of tilesrather than whole tiles. <strong>The</strong> reason for this copy is thatin MATLAB TM every parameter is passed to user-definedfunctions and methods by value. MATLAB TM itself doesnot suffer from this overhead, because the indexed assignmentoperation is a built-in function to which argumentsare passed by reference.Time (Seconds)806040200ep mg ft_1d ft_2d cgAs we see, the current sources of overheads are mostlydue to implementation issues and not inherent limitationsof the HTA approach. <strong>The</strong> overhead due to the broadcastof the HTA commands can be mitigated by sendingpre-compiled snippets of code to the servers for execution(although this implies the existence of a compiler). Byre-implementing the indexed assignment method in C insteadof MATLAB TM we can mitigate the overhead causedby excessive copying of HTAs.Finally, notice that the absolute execution time of the parallelMATLAB TM programs based on HTAs is at most afactor of two slower than their MPI counterparts. Thisshows that the overhead introduced by MATLAB TM inthese codes is not very high and therefore the speedupsobtained are mainly the result of parallelizing useful computationand not due to parallelization of the overhead.5.2.2 NAS benchmarksFigures 13 to 16 show the absolute execution time and thespeedup obtained using 4 and 8 servers (processors) forboth MPI and HTA programs for the NAS benchmarks,Figure 14: Execution time for HTA andMPI+C/Fortran on 8 servers for the NAS benchmarkswhich must be run using a number of servers that is apower of two. <strong>The</strong> labels ft 1d and ft 2d correspond to ftwith 1-D and 2-D decomposition respectively. That is the3-D array whose forward and inverse FFT are calculated inthe benchmark is partitioned either along only one (ft 1d ortwo ft 2d of its dimensions. We use the inputs of the class Aof the NAS benchmarks. So, the size of the input for mg is a256 ×256 ×256 array, while for ft it is 256 ×256 ×128. Forthe kernel ep 536870912 random numbers are generated;finally, the input for cg is a 14000 × 14000 sparse matrixwith 1853104 nonzeros and a vector of size 14000.Figures 13 and 14 show that the parallel execution time ofthe HTA implementation takes longer than the MPI one.However, remember that our HTA system is built on topof MATLAB TM which is a slow interpreted environment.However, Figures 15 and 16 show that the speedup of eachbenchmark is significant.








