- Page 1 and 2: The HTK BookSteve YoungGunnar Everm
- Page 3 and 4: II HTK in Depth 454 The Operating E
- Page 5 and 6: 12 Networks, Dictionaries and Langu
- Page 8 and 9: 17.20HSLab . . . . . . . . . . . .
- Page 10 and 11: Part ITutorial Overview1
- Page 12 and 13: 1.1 General Principles of HMMs 31.1
- Page 14 and 15: 1.2 Isolated Word Recognition 5wher
- Page 16 and 17: 1.4 Baum-Welch Re-Estimation 7indep
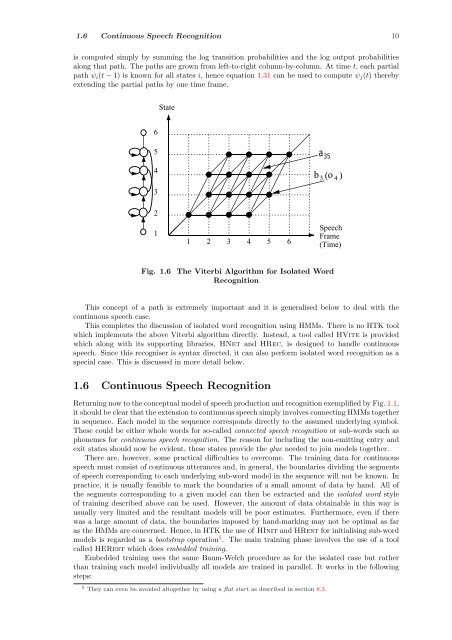
- Page 20 and 21: 1.6 Continuous Speech Recognition 1
- Page 22 and 23: 1.7 Speaker Adaptation 13N-best whi
- Page 24 and 25: 2.2 Generic Properties of a HTK Too
- Page 26 and 27: 2.3 The Toolkit 17HLEHLSDTATSTransc
- Page 28 and 29: 2.4 Whats New In Version 3.2 19full
- Page 30 and 31: 2.4 Whats New In Version 3.2 212.4.
- Page 32 and 33: 3.1 Data Preparation 233.1 Data Pre
- Page 34 and 35: 3.1 Data Preparation 25S0001 ONE VA
- Page 36 and 37: 3.1 Data Preparation 273.1.4 Step 4
- Page 38 and 39: 3.1 Data Preparation 29TIMITPrompts
- Page 40 and 41: 3.2 Creating Monophone HMMs 31 5 2
- Page 42 and 43: 3.2 Creating Monophone HMMs 33and i
- Page 44 and 45: 3.3 Creating Tied-State Triphones 3
- Page 46 and 47: 3.3 Creating Tied-State Triphones 3
- Page 48 and 49: 3.3 Creating Tied-State Triphones 3
- Page 50 and 51: 3.5 Running the Recogniser Live 41W
- Page 52 and 53: 3.6 Adapting the HMMs 43would produ
- Page 54 and 55: Part IIHTK in Depth45
- Page 56 and 57: 4.1 The Command Line 474.1 The Comm
- Page 58 and 59: 4.3 Configuration Files 49Configura
- Page 60 and 61: 4.6 Strings and Names 514.6 Strings
- Page 62: 4.8 Input/Output via Pipes and Netw
- Page 65 and 66: Chapter 5Speech Input/OutputMany to
- Page 67 and 68: 5.2 Speech Signal Processing 58then
- Page 69 and 70:
5.3 Linear Prediction Analysis 60Ce
- Page 71 and 72:
5.5 Vocal Tract Length Normalisatio
- Page 73 and 74:
5.7 Perceptual Linear Prediction 64
- Page 75 and 76:
5.10 Storage of Parameter Files 66w
- Page 77 and 78:
5.11 Waveform File Formats 685.10.2
- Page 79 and 80:
5.11 Waveform File Formats 705.11.5
- Page 81 and 82:
5.12 Direct Audio Input/Output 72Va
- Page 83 and 84:
5.14 Vector Quantisation 74LPC_ELPC
- Page 85 and 86:
5.15 Viewing Speech with HList 76in
- Page 87 and 88:
5.16 Copying and Coding using HCopy
- Page 89 and 90:
5.18 Summary 805.18 SummaryThis sec
- Page 91 and 92:
5.18 Summary 82Module Name Default
- Page 93 and 94:
6.2 Label File Formats 84Orthogonal
- Page 95 and 96:
6.3 Master Label Files 866.3 Master
- Page 97 and 98:
6.3 Master Label Files 88search wit
- Page 99 and 100:
6.4 Editing Label Files 90These few
- Page 101 and 102:
6.4 Editing Label Files 92DC V iy a
- Page 103 and 104:
Chapter 7HMM Definition FilesSpeech
- Page 105 and 106:
7.2 Basic HMM Definitions 96• opt
- Page 107 and 108:
7.2 Basic HMM Definitions 98∼h
- Page 109 and 110:
7.3 Macro Definitions 100∼o 4 2
- Page 111 and 112:
7.3 Macro Definitions 102Once defin
- Page 113 and 114:
7.4 HMM Sets 104∼o 4 ∼s “sta
- Page 115 and 116:
7.4 HMM Sets 106HTool -H mf1 -H mf2
- Page 117 and 118:
7.6 Discrete Probability HMMs 108
- Page 119 and 120:
7.9 Regression Class Trees for Adap
- Page 121 and 122:
7.11 The HMM Definition Language 11
- Page 123 and 124:
7.11 The HMM Definition Language 11
- Page 125 and 126:
Chapter 8HMM Parameter Estimationth
- Page 127 and 128:
8.1 Training Strategies 118Labelled
- Page 129 and 130:
8.2 Initialisation using HInit 120P
- Page 131 and 132:
8.3 Flat Starting with HCompV 122da
- Page 133 and 134:
8.4 Isolated Unit Re-Estimation usi
- Page 135 and 136:
8.5 Embedded Training using HERest
- Page 137 and 138:
8.6 Single-Pass Retraining 1288.6 S
- Page 139 and 140:
8.8 Parameter Re-Estimation Formula
- Page 141 and 142:
8.8 Parameter Re-Estimation Formula
- Page 143 and 144:
Chapter 9HMM AdaptationSpeaker Inde
- Page 145 and 146:
9.1 Model Adaptation using MLLR 136
- Page 147 and 148:
9.2 Model Adaptation using MAP 138
- Page 149 and 150:
9.3 Using HEAdapt 1409.3 Using HEAd
- Page 151 and 152:
9.4 MLLR Formulae 142Mthe model set
- Page 153 and 154:
Chapter 10HMM System RefinementHHED
- Page 155 and 156:
10.3 Parameter Tying and Item Lists
- Page 157 and 158:
10.4 Data-Driven Clustering 148When
- Page 159 and 160:
10.5 Tree-Based Clustering 150TC 10
- Page 161 and 162:
10.6 Mixture Incrementing 152QS "L_
- Page 163 and 164:
10.8 Miscellaneous Operations 154
- Page 165 and 166:
11.2 Using Discrete Models with Spe
- Page 167 and 168:
11.3 Tied Mixture Systems 158Speech
- Page 169 and 170:
11.4 Parameter Smoothing 160used, t
- Page 171 and 172:
12.1 How Networks are Used 162HBuil
- Page 173 and 174:
12.2 Word Networks and Standard Lat
- Page 175 and 176:
12.3 Building a Word Network with H
- Page 177 and 178:
12.4 Bigram Language Models 168wher
- Page 179 and 180:
12.6 Testing a Word Network using H
- Page 181 and 182:
¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡ ¡¡
- Page 183 and 184:
12.8 Word Network Expansion 174(a)
- Page 185 and 186:
12.9 Other Kinds of Recognition Sys
- Page 187 and 188:
Chapter 13Decoding?silonetwo...zero
- Page 189 and 190:
13.2 Decoder Organisation 180When u
- Page 191 and 192:
13.3 Recognition using Test Databas
- Page 193 and 194:
13.4 Evaluating Recognition Results
- Page 195 and 196:
13.5 Generating Forced Alignments 1
- Page 197 and 198:
13.7 Recognition using Direct Audio
- Page 199 and 200:
13.8 N-Best Lists and Lattices 190V
- Page 201 and 202:
Chapter 14Fundamentals of languagem
- Page 203 and 204:
14.1 n-gram language models 194prob
- Page 205 and 206:
14.2 Statistically-derived Class Ma
- Page 207 and 208:
14.3 Robust model estimation 198Dis
- Page 209 and 210:
14.5 Overview of n-Gram Constructio
- Page 211 and 212:
14.6 Class-Based Language Models 20
- Page 213 and 214:
15.1 Database preparation 204you ma
- Page 215 and 216:
15.2 Mapping OOV words 20615.2 Mapp
- Page 217 and 218:
15.4 Testing the LM perplexity 2080
- Page 219 and 220:
15.6 Model interpolation 210may set
- Page 221 and 222:
15.7 Class-based models 212together
- Page 223 and 224:
15.8 Problem solving 214$ LPlex -u
- Page 225 and 226:
Chapter 16Language Modelling Refere
- Page 227 and 228:
16.4 Class Map Files 218The first t
- Page 229 and 230:
16.5 Gram Files 220Notice that the
- Page 231 and 232:
16.7 Word LM file formats 22216.7.1
- Page 233 and 234:
16.8 Class LM file formats 22416.8.
- Page 235 and 236:
16.9 Language modelling tracing 226
- Page 237 and 238:
16.11 Compile-time configuration pa
- Page 239 and 240:
Part IVReference Section230
- Page 241 and 242:
17.1 Cluster 23217.1 Cluster17.1.1
- Page 243 and 244:
17.1 Cluster 23417.1.3 TracingClust
- Page 245 and 246:
17.2 HBuild 23617.2.3 TracingHBuild
- Page 247 and 248:
17.3 HCompV 238-l s The string s mu
- Page 249 and 250:
17.4 HCopy 240-t n Set the line wid
- Page 251 and 252:
17.5 HDMan 24217.5 HDMan17.5.1 Func
- Page 253 and 254:
17.5 HDMan 24417.5.3 TracingHDMan s
- Page 255 and 256:
17.6 HEAdapt 246-m f Set the minimu
- Page 257 and 258:
17.7 HERest 24817.7 HERest17.7.1 Fu
- Page 259 and 260:
17.7 HERest 250-w f Any mixture wei
- Page 261 and 262:
17.8 HHEd 252For example,stateComp
- Page 263 and 264:
17.8 HHEd 254FA varscaleComputes an
- Page 265 and 266:
17.8 HHEd 256where V s is the dimen
- Page 267 and 268:
17.8 HHEd 258mixture(m) all mixture
- Page 269 and 270:
17.9 HInit 26017.9 HInit17.9.1 Func
- Page 271 and 272:
17.10 HLEd 26217.10 HLEd17.10.1 Fun
- Page 273 and 274:
17.10 HLEd 26417.10.3 TracingHLEd s
- Page 275 and 276:
17.12 HLMCopy 26617.12 HLMCopy17.12
- Page 277 and 278:
17.13 HLRescore 268-p f Set the wor
- Page 279 and 280:
17.14 HLStats 27017.14.3 UseHLStats
- Page 281 and 282:
17.15 HParse 272Note that C style c
- Page 283 and 284:
17.15 HParse 274HParse will then re
- Page 285 and 286:
17.16 HQuant 276where vqFile is the
- Page 287 and 288:
17.17 HRest 278-v f This sets the m
- Page 289 and 290:
17.18 HResults 280WORD: %Corr=63.91
- Page 291 and 292:
17.18 HResults 28217.18.3 TracingHR
- Page 293 and 294:
17.20 HSLab 28417.20 HSLab17.20.1 F
- Page 295 and 296:
17.20 HSLab 286Load Load a speech d
- Page 297 and 298:
17.21 HSmooth 28817.21 HSmooth17.21
- Page 299 and 300:
17.22 HVite 29017.22 HVite17.22.1 F
- Page 301 and 302:
17.22 HVite 292-v f Enable word end
- Page 303 and 304:
17.23 LAdapt 29417.23.3 TracingLAda
- Page 305 and 306:
17.25 LFoF 29617.25 LFoF17.25.1 Fun
- Page 307 and 308:
17.26 LGCopy 298-r s Set the root n
- Page 309 and 310:
17.28 LGPrep 30017.28 LGPrep17.28.1
- Page 311 and 312:
17.28 LGPrep 302-r s Set the root n
- Page 313 and 314:
17.30 LMerge 30417.30 LMerge17.30.1
- Page 315 and 316:
17.32 LNorm 30617.32 LNorm17.32.1 F
- Page 317 and 318:
17.33 LPlex 30817.33.3 TracingLPlex
- Page 319 and 320:
Chapter 18Configuration VariablesTh
- Page 321 and 322:
18.1 Configuration Variables used i
- Page 323 and 324:
18.2 Configuration Variables used i
- Page 325 and 326:
19.1 Generic Errors 316HCopy 1000-1
- Page 327 and 328:
19.2 Summary of Errors by Tool and
- Page 329 and 330:
19.2 Summary of Errors by Tool and
- Page 331 and 332:
19.2 Summary of Errors by Tool and
- Page 333 and 334:
19.2 Summary of Errors by Tool and
- Page 335 and 336:
19.2 Summary of Errors by Tool and
- Page 337 and 338:
19.2 Summary of Errors by Tool and
- Page 339 and 340:
19.2 Summary of Errors by Tool and
- Page 341 and 342:
19.2 Summary of Errors by Tool and
- Page 343 and 344:
Chapter 20HTK Standard Lattice Form
- Page 345 and 346:
20.4 Field Types 336segments = ":"
- Page 347 and 348:
20.5 Example SLF file 338J=24 S=19
- Page 349 and 350:
Index 340default, 48format, 49types
- Page 351 and 352:
Index 342SILMARGIN, 72SILSEQCOUNT,
- Page 353 and 354:
Index 344output lattice format, 189
- Page 355:
Index 346USEHAMMING, 59USEPOWER, 62