

The Power of Belady's Algorithm in Register Allocation for Long ...
The Power of Belady's Algorithm in Register Allocation for Long ...
The Power of Belady's Algorithm in Register Allocation for Long ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
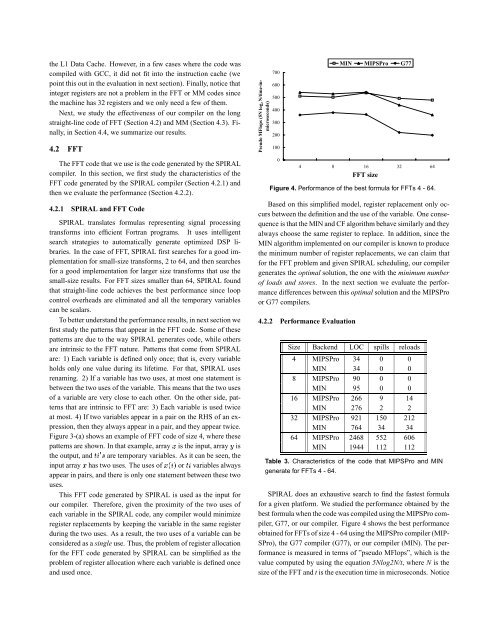
the L1 Data Cache. However, <strong>in</strong> a few cases where the code wascompiled with GCC, it did not fit <strong>in</strong>to the <strong>in</strong>struction cache (wepo<strong>in</strong>t this out <strong>in</strong> the evaluation <strong>in</strong> next section). F<strong>in</strong>ally, notice that<strong>in</strong>teger registers are not a problem <strong>in</strong> the FFT or MM codes s<strong>in</strong>cethe mach<strong>in</strong>e has 32 registers and we only need a few <strong>of</strong> them.Next, we study the effectiveness <strong>of</strong> our compiler on the longstraight-l<strong>in</strong>e code <strong>of</strong> FFT (Section 4.2) and MM (Section 4.3). F<strong>in</strong>ally,<strong>in</strong> Section 4.4, we summarize our results.4.2 FFT<strong>The</strong> FFT code that we use is the code generated by the SPIRALcompiler. In this section, we first study the characteristics <strong>of</strong> theFFT code generated by the SPIRAL compiler (Section 4.2.1) andthen we evaluate the per<strong>for</strong>mance (Section 4.2.2).4.2.1 SPIRAL and FFT CodeSPIRAL translates <strong>for</strong>mulas represent<strong>in</strong>g signal process<strong>in</strong>gtrans<strong>for</strong>ms <strong>in</strong>to efficient Fortran programs. It uses <strong>in</strong>telligentsearch strategies to automatically generate optimized DSP libraries.In the case <strong>of</strong> FFT, SPIRAL first searches <strong>for</strong> a good implementation<strong>for</strong> small-size trans<strong>for</strong>ms, 2 to 64, and then searches<strong>for</strong> a good implementation <strong>for</strong> larger size trans<strong>for</strong>ms that use thesmall-size results. For FFT sizes smaller than 64, SPIRAL foundthat straight-l<strong>in</strong>e code achieves the best per<strong>for</strong>mance s<strong>in</strong>ce loopcontrol overheads are elim<strong>in</strong>ated and all the temporary variablescan be scalars.To better understand the per<strong>for</strong>mance results, <strong>in</strong> next section wefirst study the patterns that appear <strong>in</strong> the FFT code. Some <strong>of</strong> thesepatterns are due to the way SPIRAL generates code, while othersare <strong>in</strong>tr<strong>in</strong>sic to the FFT nature. Patterns that come from SPIRALare: 1) Each variable is def<strong>in</strong>ed only once; that is, every variableholds only one value dur<strong>in</strong>g its lifetime. For that, SPIRAL usesrenam<strong>in</strong>g. 2) If a variable has two uses, at most one statement isbetween the two uses <strong>of</strong> the variable. This means that the two uses<strong>of</strong> a variable are very close to each other. On the other side, patternsthat are <strong>in</strong>tr<strong>in</strong>sic to FFT are: 3) Each variable is used twiceat most. 4) If two variables appear <strong>in</strong> a pair on the RHS <strong>of</strong> an expression,then they always appear <strong>in</strong> a pair, and they appear twice.Figure 3-(a) shows an example <strong>of</strong> FFT code <strong>of</strong> size 4, where thesepatterns are shown. In that example, array Ü is the <strong>in</strong>put, array Ý isthe output, and Ø ¼ × are temporary variables. As it can be seen, the<strong>in</strong>put array Ü has two uses. <strong>The</strong> uses <strong>of</strong> Ü´µ or Ø variables alwaysappear <strong>in</strong> pairs, and there is only one statement between these twouses.This FFT code generated by SPIRAL is used as the <strong>in</strong>put <strong>for</strong>our compiler. <strong>The</strong>re<strong>for</strong>e, given the proximity <strong>of</strong> the two uses <strong>of</strong>each variable <strong>in</strong> the SPIRAL code, any compiler would m<strong>in</strong>imizeregister replacements by keep<strong>in</strong>g the variable <strong>in</strong> the same registerdur<strong>in</strong>g the two uses. As a result, the two uses <strong>of</strong> a variable can beconsidered as a s<strong>in</strong>gle use. Thus, the problem <strong>of</strong> register allocation<strong>for</strong> the FFT code generated by SPIRAL can be simplified as theproblem <strong>of</strong> register allocation where each variable is def<strong>in</strong>ed onceand used once.Pseudo MFlops (5N log 2 N/time-<strong>in</strong>microseconds)7006005004003002001000MIN MIPSPro G774 8 16 32 64FFT sizeFigure 4. Per<strong>for</strong>mance <strong>of</strong> the best <strong>for</strong>mula <strong>for</strong> FFTs 4 - 64.Based on this simplified model, register replacement only occursbetween the def<strong>in</strong>ition and the use <strong>of</strong> the variable. One consequenceis that the MIN and CF algorithm behave similarly and theyalways choose the same register to replace. In addition, s<strong>in</strong>ce theMIN algorithm implemented on our compiler is known to producethe m<strong>in</strong>imum number <strong>of</strong> register replacements, we can claim that<strong>for</strong> the FFT problem and given SPIRAL schedul<strong>in</strong>g, our compilergenerates the optimal solution, the one with the m<strong>in</strong>imum number<strong>of</strong> loads and stores. In the next section we evaluate the per<strong>for</strong>mancedifferences between this optimal solution and the MIPSProor G77 compilers.4.2.2 Per<strong>for</strong>mance EvaluationSize Backend LOC spills reloads4 MIPSPro 34 0 0MIN 34 0 08 MIPSPro 90 0 0MIN 95 0 016 MIPSPro 266 9 14MIN 276 2 232 MIPSPro 921 150 212MIN 764 34 3464 MIPSPro 2468 552 606MIN 1944 112 112Table 3. Characteristics <strong>of</strong> the code that MIPSPro and MINgenerate <strong>for</strong> FFTs 4-64.SPIRAL does an exhaustive search to f<strong>in</strong>d the fastest <strong>for</strong>mula<strong>for</strong> a given plat<strong>for</strong>m. We studied the per<strong>for</strong>mance obta<strong>in</strong>ed by thebest <strong>for</strong>mula when the code was compiled us<strong>in</strong>g the MIPSPro compiler,G77, or our compiler. Figure 4 shows the best per<strong>for</strong>manceobta<strong>in</strong>ed <strong>for</strong> FFTs <strong>of</strong> size 4 - 64 us<strong>in</strong>g the MIPSPro compiler (MIP-SPro), the G77 compiler (G77), or our compiler (MIN). <strong>The</strong> per<strong>for</strong>manceis measured <strong>in</strong> terms <strong>of</strong> ”pseudo MFlops”, which is thevalue computed by us<strong>in</strong>g the equation 5Nlog2N/t, where N is thesize <strong>of</strong> the FFT and t is the execution time <strong>in</strong> microseconds. Notice








