

The Power of Belady's Algorithm in Register Allocation for Long ...
The Power of Belady's Algorithm in Register Allocation for Long ...
The Power of Belady's Algorithm in Register Allocation for Long ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
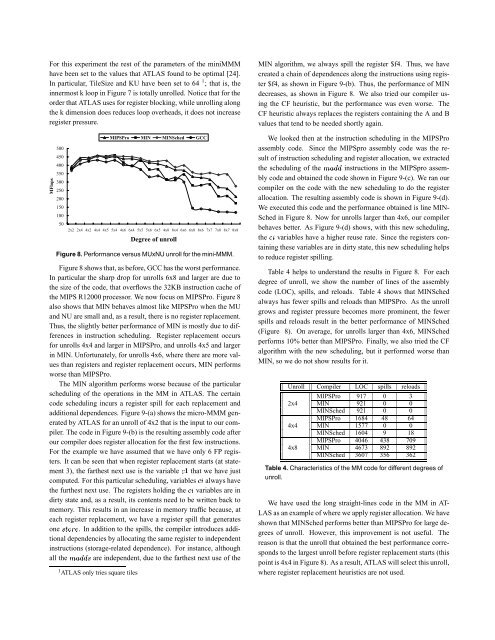
For this experiment the rest <strong>of</strong> the parameters <strong>of</strong> the m<strong>in</strong>iMMMhave been set to the values that ATLAS found to be optimal [24].In particular, TileSize and KU have been set to 64 1 ; that is, the<strong>in</strong>nermost k loop <strong>in</strong> Figure 7 is totally unrolled. Notice that <strong>for</strong> theorder that ATLAS uses <strong>for</strong> register block<strong>in</strong>g, while unroll<strong>in</strong>g alongthe k dimension does reduces loop overheads, it does not <strong>in</strong>creaseregister pressure.MFlopsMIPSPro MIN MINSched GCC500450400350300250200150100502x2 2x4 4x2 4x4 4x5 5x4 4x6 6x4 5x5 5x6 6x5 4x8 8x4 6x6 6x8 8x6 7x7 7x8 8x7 8x8Degree <strong>of</strong> unrollFigure 8. Per<strong>for</strong>mance versus MUxNU unroll <strong>for</strong> the m<strong>in</strong>i-MMM.Figure 8 shows that, as be<strong>for</strong>e, GCC has the worst per<strong>for</strong>mance.In particular the sharp drop <strong>for</strong> unrolls 6x8 and larger are due tothe size <strong>of</strong> the code, that overflows the 32KB <strong>in</strong>struction cache <strong>of</strong>the MIPS R12000 processor. We now focus on MIPSPro. Figure 8also shows that MIN behaves almost like MIPSPro when the MUand NU are small and, as a result, there is no register replacement.Thus, the slightly better per<strong>for</strong>mance <strong>of</strong> MIN is mostly due to differences<strong>in</strong> <strong>in</strong>struction schedul<strong>in</strong>g. <strong>Register</strong> replacement occurs<strong>for</strong> unrolls 4x4 and larger <strong>in</strong> MIPSPro, and unrolls 4x5 and larger<strong>in</strong> MIN. Un<strong>for</strong>tunately, <strong>for</strong> unrolls 4x6, where there are more valuesthan registers and register replacement occurs, MIN per<strong>for</strong>msworse than MIPSPro.<strong>The</strong> MIN algorithm per<strong>for</strong>ms worse because <strong>of</strong> the particularschedul<strong>in</strong>g <strong>of</strong> the operations <strong>in</strong> the MM <strong>in</strong> ATLAS. <strong>The</strong> certa<strong>in</strong>code schedul<strong>in</strong>g <strong>in</strong>curs a register spill <strong>for</strong> each replacement andadditional dependences. Figure 9-(a) shows the micro-MMM generatedby ATLAS <strong>for</strong> an unroll <strong>of</strong> 4x2 that is the <strong>in</strong>put to our compiler.<strong>The</strong> code <strong>in</strong> Figure 9-(b) is the result<strong>in</strong>g assembly code afterour compiler does register allocation <strong>for</strong> the first few <strong>in</strong>structions.For the example we have assumed that we have only 6 FP registers.It can be seen that when register replacement starts (at statement3), the farthest next use is the variable ½ that we have justcomputed. For this particular schedul<strong>in</strong>g, variables always havethe furthest next use. <strong>The</strong> registers hold<strong>in</strong>g the variables are <strong>in</strong>dirty state and, as a result, its contents need to be written back tomemory. This results <strong>in</strong> an <strong>in</strong>crease <strong>in</strong> memory traffic because, ateach register replacement, we have a register spill that generatesone ×ØÓÖ. In addition to the spills, the compiler <strong>in</strong>troduces additionaldependencies by allocat<strong>in</strong>g the same register to <strong>in</strong>dependent<strong>in</strong>structions (storage-related dependence). For <strong>in</strong>stance, althoughall the Ñ× are <strong>in</strong>dependent, due to the farthest next use <strong>of</strong> the1 ATLAS only tries square tilesMIN algorithm, we always spill the register $f4. Thus, we havecreated a cha<strong>in</strong> <strong>of</strong> dependences along the <strong>in</strong>structions us<strong>in</strong>g register$f4, as shown <strong>in</strong> Figure 9-(b). Thus, the per<strong>for</strong>mance <strong>of</strong> MINdecreases, as shown <strong>in</strong> Figure 8. We also tried our compiler us<strong>in</strong>gthe CF heuristic, but the per<strong>for</strong>mance was even worse. <strong>The</strong>CF heuristic always replaces the registers conta<strong>in</strong><strong>in</strong>g the A and Bvalues that tend to be needed shortly aga<strong>in</strong>.We looked then at the <strong>in</strong>struction schedul<strong>in</strong>g <strong>in</strong> the MIPSProassembly code. S<strong>in</strong>ce the MIPSpro assembly code was the result<strong>of</strong> <strong>in</strong>struction schedul<strong>in</strong>g and register allocation, we extractedthe schedul<strong>in</strong>g <strong>of</strong> the Ñ <strong>in</strong>structions <strong>in</strong> the MIPSpro assemblycode and obta<strong>in</strong>ed the code shown <strong>in</strong> Figure 9-(c). We ran ourcompiler on the code with the new schedul<strong>in</strong>g to do the registerallocation. <strong>The</strong> result<strong>in</strong>g assembly code is shown <strong>in</strong> Figure 9-(d).We executed this code and the per<strong>for</strong>mance obta<strong>in</strong>ed is l<strong>in</strong>e MIN-Sched <strong>in</strong> Figure 8. Now <strong>for</strong> unrolls larger than 4x6, our compilerbehaves better. As Figure 9-(d) shows, with this new schedul<strong>in</strong>g,the variables have a higher reuse rate. S<strong>in</strong>ce the registers conta<strong>in</strong><strong>in</strong>gthese variables are <strong>in</strong> dirty state, this new schedul<strong>in</strong>g helpsto reduce register spill<strong>in</strong>g.Table 4 helps to understand the results <strong>in</strong> Figure 8. For eachdegree <strong>of</strong> unroll, we show the number <strong>of</strong> l<strong>in</strong>es <strong>of</strong> the assemblycode (LOC), spills, and reloads. Table 4 shows that MINSchedalways has fewer spills and reloads than MIPSPro. As the unrollgrows and register pressure becomes more prom<strong>in</strong>ent, the fewerspills and reloads result <strong>in</strong> the better per<strong>for</strong>mance <strong>of</strong> MINSched(Figure 8). On average, <strong>for</strong> unrolls larger than 4x6, MINSchedper<strong>for</strong>ms 10% better than MIPSPro. F<strong>in</strong>ally, we also tried the CFalgorithm with the new schedul<strong>in</strong>g, but it per<strong>for</strong>med worse thanMIN, so we do not show results <strong>for</strong> it.Unroll Compiler LOC spills reloadsMIPSPro 917 0 32x4 MIN 921 0 0MINSched 921 0 0MIPSPro 1684 48 644x4 MIN 1577 0 0MINSched 1604 9 18MIPSPro 4046 438 7094x8 MIN 4673 892 892MINSched 3607 356 362Table 4. Characteristics <strong>of</strong> the MM code <strong>for</strong> different degrees <strong>of</strong>unroll.We have used the long straight-l<strong>in</strong>es code <strong>in</strong> the MM <strong>in</strong> AT-LAS as an example <strong>of</strong> where we apply register allocation. We haveshown that MINSched per<strong>for</strong>ms better than MIPSPro <strong>for</strong> large degrees<strong>of</strong> unroll. However, this improvement is not useful. <strong>The</strong>reason is that the unroll that obta<strong>in</strong>ed the best per<strong>for</strong>mance correspondsto the largest unroll be<strong>for</strong>e register replacement starts (thispo<strong>in</strong>t is 4x4 <strong>in</strong> Figure 8). As a result, ATLAS will select this unroll,where register replacement heuristics are not used.








