

Direct Numerical Simulation of Autoignition in a Jet in a Cross-Flow ...
Direct Numerical Simulation of Autoignition in a Jet in a Cross-Flow ...
Direct Numerical Simulation of Autoignition in a Jet in a Cross-Flow ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
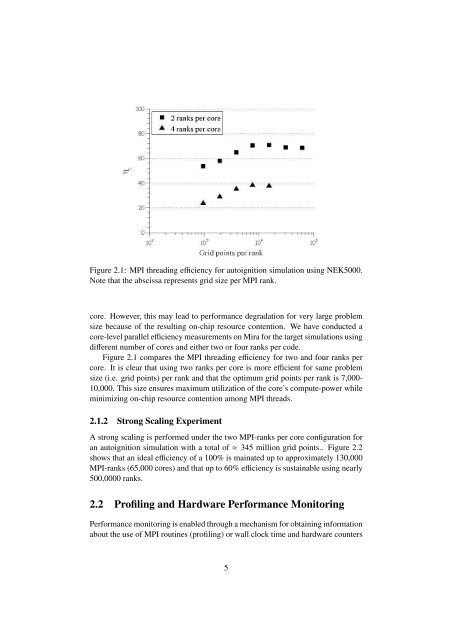
Figure 2.1: MPI thread<strong>in</strong>g efficiency for autoignition simulation us<strong>in</strong>g NEK5000.Note that the abscissa represents grid size per MPI rank.core. However, this may lead to performance degradation for very large problemsize because <strong>of</strong> the result<strong>in</strong>g on-chip resource contention. We have conducted acore-level parallel efficiency measurements on Mira for the target simulations us<strong>in</strong>gdifferent number <strong>of</strong> cores and either two or four ranks per code.Figure 2.1 compares the MPI thread<strong>in</strong>g efficiency for two and four ranks percore. It is clear that us<strong>in</strong>g two ranks per core is more efficient for same problemsize (i.e. grid po<strong>in</strong>ts) per rank and that the optimum grid po<strong>in</strong>ts per rank is 7,000-10,000. This size ensures maximum utilization <strong>of</strong> the core’s compute-power whilem<strong>in</strong>imiz<strong>in</strong>g on-chip resource contention among MPI threads.2.1.2 Strong Scal<strong>in</strong>g ExperimentA strong scal<strong>in</strong>g is performed under the two MPI-ranks per core configuration foran autoignition simulation with a total <strong>of</strong>≈ 345 million grid po<strong>in</strong>ts.. Figure 2.2shows that an ideal efficiency <strong>of</strong> a 100% is ma<strong>in</strong>ated up to approximately 130,000MPI-ranks (65,000 cores) and that up to 60% efficiency is susta<strong>in</strong>able us<strong>in</strong>g nearly500,0000 ranks.2.2 Pr<strong>of</strong>il<strong>in</strong>g and Hardware Performance Monitor<strong>in</strong>gPerformance monitor<strong>in</strong>g is enabled through a mechanism for obta<strong>in</strong><strong>in</strong>g <strong>in</strong>formationabout the use <strong>of</strong> MPI rout<strong>in</strong>es (pr<strong>of</strong>il<strong>in</strong>g) or wall clock time and hardware counters5













