

GUPT: Privacy Preserving Data Analysis Made Easy - Computer ...
GUPT: Privacy Preserving Data Analysis Made Easy - Computer ...
GUPT: Privacy Preserving Data Analysis Made Easy - Computer ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
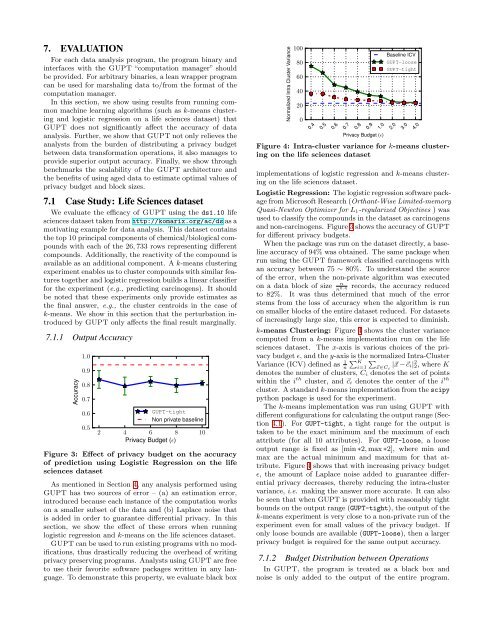
7. EVALUATIONFor each data analysis program, the program binary andinterfaces with the <strong>GUPT</strong> “computation manager” shouldbe provided. For arbitrary binaries, a lean wrapper programcan be used for marshaling data to/from the format of thecomputation manager.In this section, we show using results from running commonmachine learning algorithms (such as k-means clusteringand logistic regression on a life sciences dataset) that<strong>GUPT</strong> does not significantly affect the accuracy of dataanalysis. Further, we show that <strong>GUPT</strong> not only relieves theanalysts from the burden of distributing a privacy budgetbetween data transformation operations, it also manages toprovide superior output accuracy. Finally, we show throughbenchmarks the scalability of the <strong>GUPT</strong> architecture andthe benefits of using aged data to estimate optimal values ofprivacy budget and block sizes.7.1 Case Study: Life Sciences datasetWe evaluate the efficacy of <strong>GUPT</strong> using the ds1.10 lifesciences dataset taken from http://komarix.org/ac/ds as amotivating example for data analysis. This dataset containsthe top 10 principal components of chemical/biological compoundswith each of the 26, 733 rows representing differentcompounds. Additionally, the reactivity of the compound isavailable as an additional component. A k-means clusteringexperiment enables us to cluster compounds with similar featurestogether and logistic regression builds a linear classifierfor the experiment (e.g., predicting carcinogens). It shouldbe noted that these experiments only provide estimates asthe final answer, e.g., the cluster centroids in the case ofk-means. We show in this section that the perturbation introducedby <strong>GUPT</strong> only affects the final result marginally.7.1.1 Output AccuracyAccuracy1.00.90.80.70.60.5<strong>GUPT</strong>-tightNon private baseline2 4 6 8 10<strong>Privacy</strong> Budget (ɛ)Figure 3: Effect of privacy budget on the accuracyof prediction using Logistic Regression on the lifesciences datasetAs mentioned in Section 4, any analysis performed using<strong>GUPT</strong> has two sources of error – (a) an estimation error,introduced because each instance of the computation workson a smaller subset of the data and (b) Laplace noise thatis added in order to guarantee differential privacy. In thissection, we show the effect of these errors when runninglogistic regression and k-means on the life sciences dataset.<strong>GUPT</strong> can be used to run existing programs with no modifications,thus drastically reducing the overhead of writingprivacy preserving programs. Analysts using <strong>GUPT</strong> are freeto use their favorite software packages written in any language.To demonstrate this property, we evaluate black boxNormalized Intra Cluster Variance1008060402000.40.50.60.70.80.91.02.03.04.0<strong>Privacy</strong> Budget (ɛ)Baseline ICV<strong>GUPT</strong>-loose<strong>GUPT</strong>-tightFigure 4: Intra-cluster variance for k-means clusteringon the life sciences datasetimplementations of logistic regression and k-means clusteringon the life sciences dataset.Logistic Regression: The logistic regression software packagefrom Microsoft Research (Orthant-Wise Limited-memoryQuasi-Newton Optimizer for L 1-regularized Objectives ) wasused to classify the compounds in the dataset as carcinogensand non-carcinogens. Figure 3 shows the accuracy of <strong>GUPT</strong>for different privacy budgets.When the package was run on the dataset directly, a baselineaccuracy of 94% was obtained. The same package whenrun using the <strong>GUPT</strong> framework classified carcinogens withan accuracy between 75 ∼ 80%. To understand the sourceof the error, when the non-private algorithm was executednon a data block of size records, the accuracy reducednto 82%. It was thus determined 0.4that much of the errorstems from the loss of accuracy when the algorithm is runon smaller blocks of the entire dataset reduced. For datasetsof increasingly large size, this error is expected to diminish.k-means Clustering: Figure 4 shows the cluster variancecomputed from a k-means implementation run on the lifesciences dataset. The x-axis is various choices of the privacybudget ɛ, and the y-axis∑is the normalized Intra-ClusterVariance (ICV) defined as 1 K∑n i=1 ⃗x∈C i|⃗x −⃗c i| 2 2, where Kdenotes the number of clusters, C i denotes the set of pointswithin the i th cluster, and ⃗c i denotes the center of the i thcluster. A standard k-means implementation from the scipypython package is used for the experiment.The k-means implementation was run using <strong>GUPT</strong> withdifferent configurations for calculating the output range (Section4.1). For <strong>GUPT</strong>-tight, a tight range for the output istaken to be the exact minimum and the maximum of eachattribute (for all 10 attributes). For <strong>GUPT</strong>-loose, a looseoutput range is fixed as [min ∗2, max ∗2], where min andmax are the actual minimum and maximum for that attribute.Figure 4 shows that with increasing privacy budgetɛ, the amount of Laplace noise added to guarantee differentialprivacy decreases, thereby reducing the intra-clustervariance, i.e. making the answer more accurate. It can alsobe seen that when <strong>GUPT</strong> is provided with reasonably tightbounds on the output range (<strong>GUPT</strong>-tight), the output of thek-means experiment is very close to a non-private run of theexperiment even for small values of the privacy budget. Ifonly loose bounds are available (<strong>GUPT</strong>-loose), then a largerprivacy budget is required for the same output accuracy.7.1.2 Budget Distribution between OperationsIn <strong>GUPT</strong>, the program is treated as a black box andnoise is only added to the output of the entire program.