

Algorithms and Data Structures for External Memory
Algorithms and Data Structures for External Memory
Algorithms and Data Structures for External Memory

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
106 Spatial <strong>Data</strong> <strong>Structures</strong> <strong>and</strong> Range Search<br />
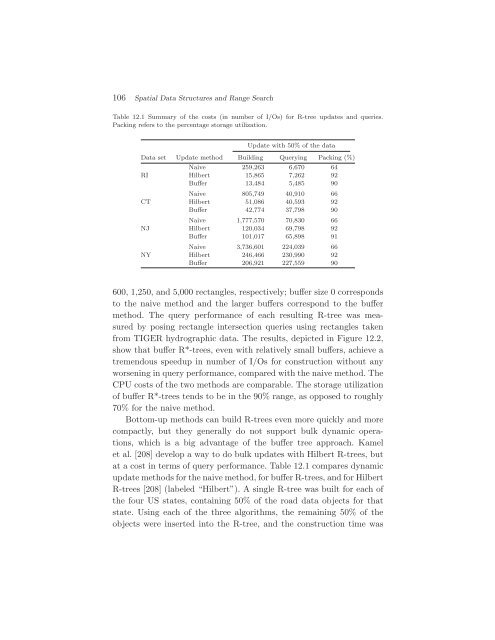
Table 12.1 Summary of the costs (in number of I/Os) <strong>for</strong> R-tree updates <strong>and</strong> queries.<br />
Packing refers to the percentage storage utilization.<br />
Update with 50% of the data<br />
<strong>Data</strong> set Update method Building Querying Packing (%)<br />
RI<br />
CT<br />
NJ<br />
NY<br />
Naive<br />
Hilbert<br />
Buffer<br />
Naive<br />
Hilbert<br />
Buffer<br />
Naive<br />
Hilbert<br />
Buffer<br />
Naive<br />
Hilbert<br />
Buffer<br />
259,263<br />
15,865<br />
13,484<br />
805,749<br />
51,086<br />
42,774<br />
1,777,570<br />
120,034<br />
101,017<br />
3,736,601<br />
246,466<br />
206,921<br />
6,670<br />
7,262<br />
5,485<br />
40,910<br />
40,593<br />
37,798<br />
70,830<br />
69,798<br />
65,898<br />
224,039<br />
230,990<br />
227,559<br />
600, 1,250, <strong>and</strong> 5,000 rectangles, respectively; buffer size 0 corresponds<br />
to the naive method <strong>and</strong> the larger buffers correspond to the buffer<br />
method. The query per<strong>for</strong>mance of each resulting R-tree was measured<br />
by posing rectangle intersection queries using rectangles taken<br />
from TIGER hydrographic data. The results, depicted in Figure 12.2,<br />
show that buffer R*-trees, even with relatively small buffers, achieve a<br />
tremendous speedup in number of I/Os <strong>for</strong> construction without any<br />
worsening in query per<strong>for</strong>mance, compared with the naive method. The<br />
CPU costs of the two methods are comparable. The storage utilization<br />
of buffer R*-trees tends to be in the 90% range, as opposed to roughly<br />
70% <strong>for</strong> the naive method.<br />
Bottom-up methods can build R-trees even more quickly <strong>and</strong> more<br />
compactly, but they generally do not support bulk dynamic operations,<br />
which is a big advantage of the buffer tree approach. Kamel<br />
et al. [208] develop a way to do bulk updates with Hilbert R-trees, but<br />
at a cost in terms of query per<strong>for</strong>mance. Table 12.1 compares dynamic<br />
update methods <strong>for</strong> the naive method, <strong>for</strong> buffer R-trees, <strong>and</strong> <strong>for</strong> Hilbert<br />
R-trees [208] (labeled “Hilbert”). A single R-tree was built <strong>for</strong> each of<br />
the four US states, containing 50% of the road data objects <strong>for</strong> that<br />
state. Using each of the three algorithms, the remaining 50% of the<br />
objects were inserted into the R-tree, <strong>and</strong> the construction time was<br />
64<br />
92<br />
90<br />
66<br />
92<br />
90<br />
66<br />
92<br />
91<br />
66<br />
92<br />
90














