O Algoritmo Newman-Ziff
O Algoritmo Newman-Ziff
O Algoritmo Newman-Ziff
- No tags were found...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
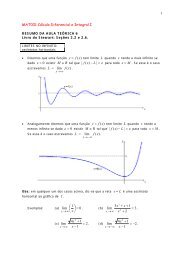
1Seminários de ProbabilidadeO <strong>Algoritmo</strong> <strong>Newman</strong>-<strong>Ziff</strong>Bruno Martins da Costa Fonseca23 de Setembro de 2011Resumo. Apresentaremos nesse seminário um eficiente algoritmo de Monte Carlo recentemente proposto por M.E. J. <strong>Newman</strong> e R. M. <strong>Ziff</strong> para tratar de problemas em percolação, assim como um programa elaborado em Javaque implementa esse algoritmo no intuito de estimar o ponto crítico da percolação de sítios/elos em Z 2 e Z 3 . Nessesentido, abordaremos alguns algoritmos preliminares como o Depth/Breadth-First-Search e Hoshen-Kopelman queforam originalmente empregados para tratar de problemas em que se mantinha fixa a probabilidade p de um sítioestar ocupado. Em seguida, passaremos ao caso mais usual em que se deseja investigar uma propriedade do sistemasobre todo um intervalo de valores para p, onde discutimos a técnica de Hu no contexto de um Método Direto quedetermina o valor dessa propriedade e apresentamos o método de <strong>Newman</strong>-<strong>Ziff</strong> como um aprimoramento desse MétodoDireto. Por fim, encerraremos com uma breve discussão sobre o Método de Reescala Finita (Finite Size Scaling) e suautilização para obter estimativas de certas propriedades do sistema.Tomando a rede Z 2 de modo que cada sítio possui probabilidade p de estarocupado e 1 p de estar desocupado, então estamos interessados na probabilidadep c (1) para a qual surge um cluster C 1 com infinitos sítios ocupadosnessa rede, fenômeno o qual é denominado percolação. No intuito de obtercomputacionalmente uma estimativa para p c (1), tomamosumacaixa⇤ L centradana origem com L sítios em cada lado (e, portanto, com N = L 2 sítios eM =2L(L 1) = 2(N L) elos) para ser uma aproximação de todo Z 2 eassociamoso fenômeno de exitir um cluster C L de sítios ocupados cruzando essa caixa(digamos que verticalmente) ao fenômeno de percolação em Z 2 . Dessa forma, 2C L Lpodemos tomar a probabilidade p c (L) para a qual esse cluster percolador C L surge pela primeira vez em ⇤ Lcomo sendo uma aproximação de p c (1).<strong>Algoritmo</strong>s de Probabilidade FixaOs primeiros algoritmos propostos para tratar de problemas de percolação determinavam uma certa propriedadeQ do sistema (p. ex., tamanho médio de clusters ou existência de um cluster percolador) para uma probabilidadep fixada [2,3]. Em geral, para essa probabilidade p podemos configurar facilmente o estado de cada sítio s 2 ⇤ Ltomando um número aleatório X(s) 2 [0, 1] edeclarandos ocupado caso X(s) apple p edesocupadocasocontrário.Em seguida, para obter informações sobre os clusters nessa configuração particular podemos utilizar algumalgoritmo de busca como Depth/Breadth-First-Search ou algum algoritmo de União-Procura como o algoritmode Hoshen-Kopelman.
2Depth/Breadth-First-SearchNos algoritmos de busca Depth/Breadth-First-Search partimos de um sítio original e visitamos todos os demaissítios que estão no mesmo cluster que o sítio original, buscando as informações desejadas sobre esse clusterao longo do processo. Para vislumbrar com mais detalhes a metodologia desses dois algoritmos, permita-meassociar o processo de exploração dos sítios num cluster ao de exploração de uma caverna da seguinte forma [6]:associamos cada sítio ocupado do cluster a um salão de uma certa caverna e cada elo ligando sítios ocupadoscomo sendo túneis ligando esses salões.Depth-First-Search12161431112104135967815Numa exploração do tipo Depth-First-Search partimos do salão de entrada (sítio 1na figura ao lado) e escolhemos um de seus túneis para seguir adiante (escolhemosos elos segundo uma ordenação horária a partir do elo da direita, ou seja: Direita,Abaixo, Esquerda, Acima). No próximo salão (sítio 2) escolhemos novamente umde seus túneis para continuar a exploração. Quando chegarmos a um salão quenão possui túneis (p. ex., sítio 8), retornamos ao último salão visitado que aindapossui túneis exploráveis (sítio 7) para escolher um túnel diferente e continuar aexploração. Seguindo esse procedimento de siga-e-volte pelos túneis visitados podemosexplorar toda a caverna. Observe que em todo momento devemos registraros túneis pelos quais já andamos para que possamos retornar por eles e escolher novos túneis. Enquanto naexploração de cavernas podemos adotar a estratégia do "Labirinto do Minotauro" e carregar conosco um novelode lã que sempre indicará o caminho de onde viemos, no caso computacional podemos registrar num vetor todosos sítios visitados e retornar por esses sítios quando chegarmos a um sítio que não possui vizinhos ocupados.Por outro lado, numa exploração do tipo Breadth-First-Search partimos do salão Breadth-First-Searchde entrada (sítio 1) e percorremos cada um de seus túneis para registrar todosos salões adjacentes (no caso, apenas o sítio 2), os quais constituem um 1o nívelde salões. Para cada salão registrado nesse 1o nível percorremos todos os seustúneis para registrar todos os salões adjacentes, os quais constituem um 2o nívelde salões (sítios 3 e 4). Seguindo esse procedimento de explorar salões nível anível podemos explorar toda a caverna. Observe que em todo momento devemosmanter o registro de quais salões do nível anterior ainda não tiveram seus túneispercorridos, assim como quais salões do próximo nível foram recém descobertos.12 3954 67 10 14118 1213 1516No caso computacional isso pode ser facilmente implementado utilizando uma estrutura de dados do tipoqueue. <strong>Algoritmo</strong>s completos e explicações adicionais tanto do Depth- quanto do Breadth-First-Search podemser encontrados em [6,7].
3<strong>Algoritmo</strong> de Hoshen-KopelmanCluster r1r1 rr2Cluster r2sUm algoritmo do tipo União-Procura que por muito tempo foi central em simulações depercolação consiste na técnica de múltiplos rótulos de Hoshen-Kopelman [3]. Ao invés deinvestigar um cluster por vez como no caso dos algoritmos Depth/Breadth-First-Search, ométodo de Hoshen-Kopelman determina toda a estrutura de clusters registrando em cadasítio um rótulo que indica a qual cluster esse sítio pertence. Para tanto, começamos deum sítio original e visitamos todos os sítios ocupados na ordem usual de visitação (i.e., daesquerda para a direita e de baixo para cima) onde estabelecemos os rótulos da seguinte forma: ao visitarmosum sítio s, configuramosseurótulor como sendo o menor dos rótulos r1,r2 de seus respectivos vizinhos àesquerda e abaixo (já visitados) ou como o próximo rótulo disponível caso esses vizinhos não possuam rótulos[5]. Como os rótulos indicam a qual cluster um dado sítio pertence, então o procedimento anterior declara ques pertence ao cluster de menor rótulo ou então a um novo cluster.Observe no exemplo da figura ao lado que esse método eventualmente estabelecerótulos diferentes para sítios num mesmo cluster, uma vez que um certosítio s (como o assinalado em vermelho na figura) pode pertencer a um clusterpreviamente descoberto mesmo que seus vizinhos à esquerda e abaixo nãopossuam rótulos. Uma forma de corrigir esse problema seria fazer o seguinte:ao visitarmos um sítio s, tomamos [Fase de Procura] o menor dos respectivosrótulos r1,r2 dos vizinhos à esquerda e abaixo do sítio s para configurar[Fase de União] tanto o rótulo de s quanto os rótulos de todos os sítios noconjunto C max = {sítios cujo rótulo é max{r1,r2}}. 1 Embora essa estratégiagaranta que os clusters adjacentes ao sítio s sempre posuem o mesmo rótulo,Hoshen-Kopelman6 6 9 7 76 6 6 86 6 6 6 8 76 6 2 75 2 21 4 2 2 21 1 2 3observe que não é nada eficiente rerotular todos os sítios em C max para cada visita que realizamos. Umaforma de minimizar essa ineficiência seria reduzindo o número de "re-rotulamentos" considerando o conjuntoC min = {sítios cujo rótulo é min{r1,r2}} etomando[FasedeProcura]orótulodomaiordosconjuntosC max ,C min para configurar [Fase de União] tanto o rótulo de s quanto os rótulos de todos os sítios no conjuntomenor.r1Cluster r1Supercluster r1rl[r1]=r1rr2sCluster r2 rl[r2]=r1Agora, podemos eliminar a ineficiência do parágrafo anterior adiando esse processode "re-rotulamento" e registrando num vetor rl de rótulos legítimos quando umcluster de rótulo r énaverdadepartedeumsuperclusterderótulorl[r]. Dessaforma, ao visitarmos um sítio s como na figura (b) ao lado, tomamos [Fase deProcura] o menor dos respectivos rótulos legítimos rl[r1],rl[r2] dos clusters r1,r2para configurar [Fase de União] tanto o rótulo de s quanto o rótulo legítimodaquele cluster que possui o maior rótulo legítimo (p. ex, se rl[r1] éomenorrótulo legítimo, então tomamos rl[r2] = rl[r1]; issoindicaqueoclusterr2 faz1 Sem essa correção o algoritmo de Hoshen-Kopelman é simplesmente um algoritmo de busca, uma vez que não executa nenhumaunião de clusters.
4parte do supercluster rl[r1]).algoritmos podem ser encontrados em [5,7].Uma discussão mais detalhada do método de Hoshen-Kopelman assim como<strong>Algoritmo</strong> de ÁrvoreAo invés de utilizar um rótulo numérico que indica o cluster ao qual cada sítio pertencepodemos adotar um sítio particular (sítio raiz) do cluster para determiná-lono sentido que todos os demais sítios desse cluster apontem direta ou indiretamentepara esse sítio raiz da seguinte forma: ao visitarmos um sítio s, tomamoss[Fase Procura] os sítios raízes sr1,sr2 dos vizinhos à esquerda e abaixo do sítiosr1s, escolhendo,emseguida,[FaseUnião]umdelesparaseraraízdosuperclusterque acaba de ser formado [um critério de escolha adotado é tomar aquele sítioraíz que está mais abaixo e mais à esquerda na rede como, por exemplo, o sítiosr2sr2 da figura ao lado] e fazendo tanto o sítio s quanto o outro sítio raiz [sr1 nafigura] apontarem para o sítio raiz escolhido [setas em azul na figura]. Observe que dessa forma, todos ossítios do supercluster apontam direta ou indiretamente para o sítio raiz do supercluster, de modo que esse sítiocaracterize unicamente o cluster.<strong>Algoritmo</strong>s de Probabilidade VariávelOs métodos da seção anterior foram originalmente utilizados para obter informações acerca da estrutura declusters quando fixamos a probabilidade p de um sítio em ⇤ L estar ocupado. Contudo, questões típicas empercolação envolvem a determinação de uma certa propriedade Q L (p) do sistema ⇤ L para todo um intervaloI =(a, b) de valores dessa probabilidade p. Porexemplo,umapropriedadecentralempercolaçãoequepermitedeterminar p c (L) éaprobabilidadeRL v (p) de existir um cluster percolador vertical na caixa ⇤ L quando aprobabilidade de um sítio estar ocupado é p.Uma forma ingênua de se obter Q L (p) seria utilizar os métodos da seção anterior para determinar Q L (p k ) emcertos p k ’s fixados no intervalo I =(a, b) eaproximarQ L (p) por meio de interpolação. Contudo, a grandedesvantagem desse método é que para obter uma boa aproximação de Q L (p) devemos encontrar Q L (p k ) paramuitos p k ’s (tendendo para infinito), o que torna o cálculo muito mais lento e mesmo assim não elimina o errode nossa aproximação final. Por exemplo, como o processo de configurar o estado de ⇤ L para um dado p k gastatempo da ordem O(N) do número N de sítios em ⇤ L ealgoritmosdebuscacomoosdaseçãoanteriorgastamtempo da ordem O(M) do número M de elos em ⇤ L para determinar a estrutura de cluster dessa configuração,então esse nosso algoritmo ingênuo gastaria um tempo da ordem O(k · (N + M)) (ou simplesmente O(kN) emredes regulares) com k !1.
5OMétodoDiretoPodemos contornar a dificuldade do parágrafo anterior utilizando a seguinte técnica [4]: ao invés de fixarmosp para obter Q L (p), fixamosonúmeron de sítios ocupados em ⇤ L para obter um Q L,n ,ouseja,ovalordapropriedade nessa configuração com n sítios ocupados. 2 Observe que, denotando por B(N,n,p) = N n · pn · (1p) N n aprobabilidadedehaverexatamenten sítios ocupados em ⇤ L ,entãopodemosestimarQ L (p) como umamédia dos Q L,n ponderada por B(N,n,p) [5]:Q L (p) =NXB(N,n,p) · Q L,n =n=0NXn=0✓ Nn◆· p n · (1 p) N n · Q L,n . (1)Dessa forma, se pudermos medir nossa propriedade Q L em cada conjunto de configurações onde temos n sítiosocupados para obter nossos Q L,n ’s, então a expressão anterior fornece Q L (p) para todos os valores de p e,portanto, reduzimos o problema anterior de encontrar Q L (p k ) para uma quantidade grande (tendendo prainfinito) de p k ’s a um problema de encontrar uma quantidade finita (igual a N) deQ L,n ’s.Um método direto pra se obter um Q L,n qualquer seria configurar o estado de ⇤ L tomando aleatoriamente nsítios para serem ocupados e, em seguida, proceder da mesma forma que na seção anterior utilizando algumalgoritmo de busca ou união-procura para determinar a estrura de clusters (e, portanto, o valor Q L,n )nessaconfiguração particular de ⇤ L . Como no caso do algoritmo ingênuo, observe que esse método direto gasta umtempo da ordem O(N + M) para obter cada um dos Q L,n e, portanto, como são N valores Q L,n ,gastaráumtempo da ordem O(N ·(N +M)) = O(N 2 +MN) (ou simplesmente O(N 2 ) em redes regulares) para determinarQ L (p).O<strong>Algoritmo</strong><strong>Newman</strong>-<strong>Ziff</strong>O algoritmo proposto por <strong>Newman</strong> e <strong>Ziff</strong> [1,2] aprimora o método direto da seção anterior utilizando uma idéiabem simples: ao invés de recomeçar do zero configurando todo o estado da caixa ⇤ L sempre que mudamos ovalor de n para n +1,podemossimplesmentetomaranovaconfiguração(comn +1 sítios ocupados) comosendo a configuração anterior (com n sítios ocupados) onde escolhemos aleatoriamente um novo sítio descocupadopara ser preenchido. Dessa forma, podemos criar todo um conjunto de configurações para ⇤ L ocupandoaleatoriamente um a um de seus sítios a partir da configuração em que todos os sítios estão desocupados. Comoaestruturadeclustersvariamuitopoucoquandoadicionamosapenasumnovosítioocupadoàconfiguração,então podemos determinar a nova estrutura a partir da antiga apenas com uma pequena quantidade de esforçocomputacional.Ao invés de decidir qual novo sítio será ocupado no exato momento em que mudamos o valor de n para n +1,podemos simplesmente estabelecer no início do procedimento uma ordem aleatória de preenchimento dos sítios2 Na literatura, o conjunto de todos os estados possíveis de ⇤ L para uma probabilidade p fixada é denominado Conjunto Canônicoe o conjunto de todas as configurações possíveis de ⇤ L com exatamente n sítios ocupados é denominado Conjunto Microcanônico.
6de ⇤ L para ser seguida. Para tanto, tomamos um array order de tamanho N com entradas de 1 a N (os sítios darede) e permutamos essas entradas aleatoriamente. Como toda permutação é uma composição de permutaçõesde dois elementos, então isso pode ser feito percorrendo-se o array order de tal modo que para cada índice iescolhemos um índice aleatório j com N i apple j apple N etrocamosasentradasorder[i], order[j] de lugar [comona figura].Seguindo a ordem estabelicida no array order, então para cada novo sítio s ocupado devemos atualizar aestrura de clusters no intuito de obter o valor de Q L,n nessa nova configuração. Podemos fazer isso utilizando oalgoritmo de Hoshen-Kopelman ou de Árvore em que ao invés de olharmos apenas para os vizinhos à esquerdaeabaixodosítioss olhamos para todos os vizinhos de s.Bibliografia[1] M. E. J. <strong>Newman</strong> e R. M. <strong>Ziff</strong>, Phys. Rev. E 64, 016706(2001).[2] M. E. J. <strong>Newman</strong> e R. M. <strong>Ziff</strong>, Phys. Rev. Lett. 85, 4104(2000).[3] J. Hoshen e R. Kopelman, Phys. Rev. B 14, 3438(1976).[4] C.-K. Hu, Phys. Rev. B 46, 6592(1992).[5] H. Gould e J. Tobochnik, An Introduction to Computer Simulation Methods, 2aEdição,Addison-Wesley,Reading, MA (1996).[6] R. Sedgewick e K. Wayne, Algorithms, 4aEdição,Addison-Wesley(2011).[7] A. K. Hartmann e H. Rieger, Optimization Algorithms in Physics, 1aEdição,Willey-VHC(2002).