

kombiniertes data mining – klassifikation unter verwendung von ...
kombiniertes data mining – klassifikation unter verwendung von ...
kombiniertes data mining – klassifikation unter verwendung von ...

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Kombiniertes Data Mining <strong>–</strong> Klassifikation anhand <strong>von</strong> Hilfsinformationen<br />
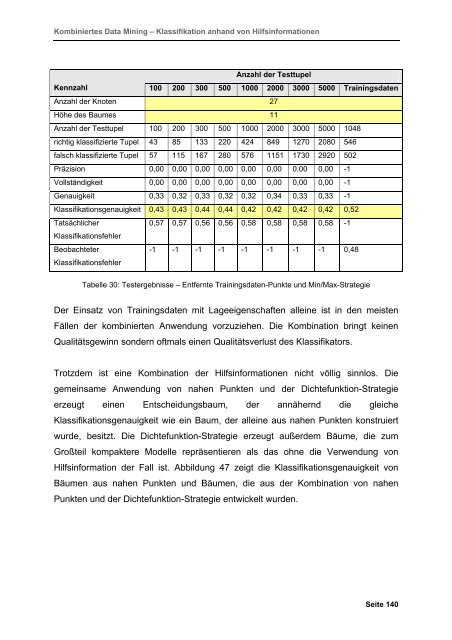
Anzahl der Testtupel<br />
Kennzahl 100 200 300 500 1000 2000 3000 5000 Trainingsdaten<br />
Anzahl der Knoten 27<br />
Höhe des Baumes 11<br />
Anzahl der Testtupel 100 200 300 500 1000 2000 3000 5000 1048<br />
richtig klassifizierte Tupel 43 85 133 220 424 849 1270 2080 546<br />
falsch klassifizierte Tupel 57 115 167 280 576 1151 1730 2920 502<br />
Präzision 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 -1<br />
Vollständigkeit 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 -1<br />
Genauigkeit 0,33 0,32 0,33 0,32 0,32 0,34 0,33 0,33 -1<br />
Klassifikationsgenauigkeit 0,43 0,43 0,44 0,44 0,42 0,42 0,42 0,42 0,52<br />
Tatsächlicher<br />
Klassifikationsfehler<br />
Beobachteter<br />
Klassifikationsfehler<br />
0,57 0,57 0,56 0,56 0,58 0,58 0,58 0,58 -1<br />
-1 -1 -1 -1 -1 -1 -1 -1 0,48<br />
Tabelle 30: Testergebnisse <strong>–</strong> Entfernte Trainingsdaten-Punkte und Min/Max-Strategie<br />
Der Einsatz <strong>von</strong> Trainingsdaten mit Lageeigenschaften alleine ist in den meisten<br />
Fällen der kombinierten Anwendung vorzuziehen. Die Kombination bringt keinen<br />
Qualitätsgewinn sondern oftmals einen Qualitätsverlust des Klassifikators.<br />
Trotzdem ist eine Kombination der Hilfsinformationen nicht völlig sinnlos. Die<br />
gemeinsame Anwendung <strong>von</strong> nahen Punkten und der Dichtefunktion-Strategie<br />
erzeugt einen Entscheidungsbaum, der annähernd die gleiche<br />
Klassifikationsgenauigkeit wie ein Baum, der alleine aus nahen Punkten konstruiert<br />
wurde, besitzt. Die Dichtefunktion-Strategie erzeugt außerdem Bäume, die zum<br />
Großteil kompaktere Modelle repräsentieren als das ohne die Verwendung <strong>von</strong><br />
Hilfsinformation der Fall ist. Abbildung 47 zeigt die Klassifikationsgenauigkeit <strong>von</strong><br />
Bäumen aus nahen Punkten und Bäumen, die aus der Kombination <strong>von</strong> nahen<br />
Punkten und der Dichtefunktion-Strategie entwickelt wurden.<br />
Seite 140






